主なタスク: Vision-and-Language Navigation ▪ 代表的手法 ▪ REVERIE [Qi+, CVPR20], [Hatori+, ICRA18] クロスモーダル検索 ▪ 主なタスク:ファッション検索,ランドマーク検索 ▪ 代表的手法 ▪ TIRG [Vo+, CVPR19], DCNet [Kim+, AAAI21], FashionIQ [Wu+, CVPR21] → Vision-and-Language + ロボティクスの分野において, クローリング設定を扱う研究は少ない https://yuankaiqi.github.io/REVERIE_Challen ge/static/img/demo.gif
{kind=link}
{kind=link}
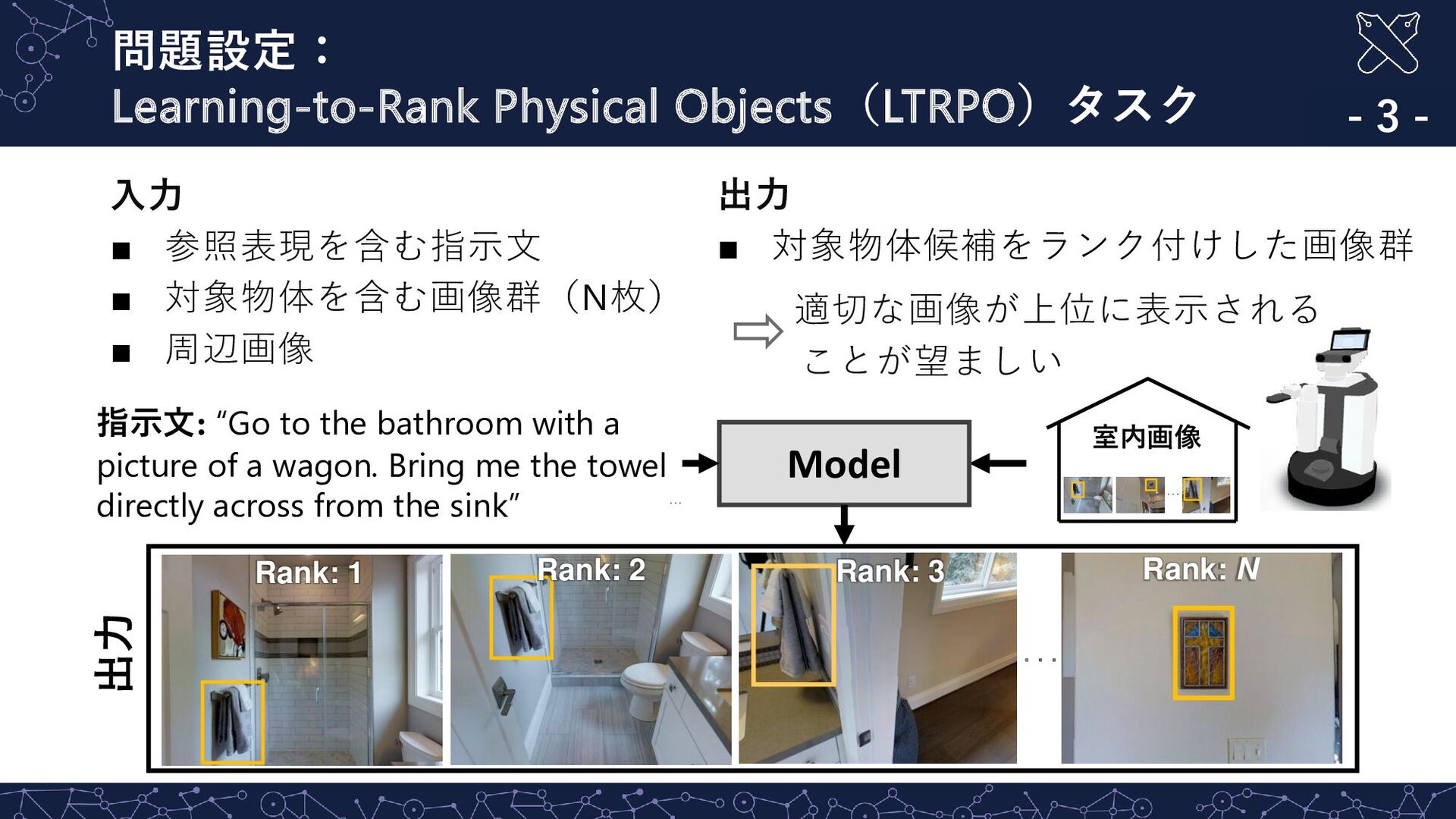{kind=link}
{kind=link}
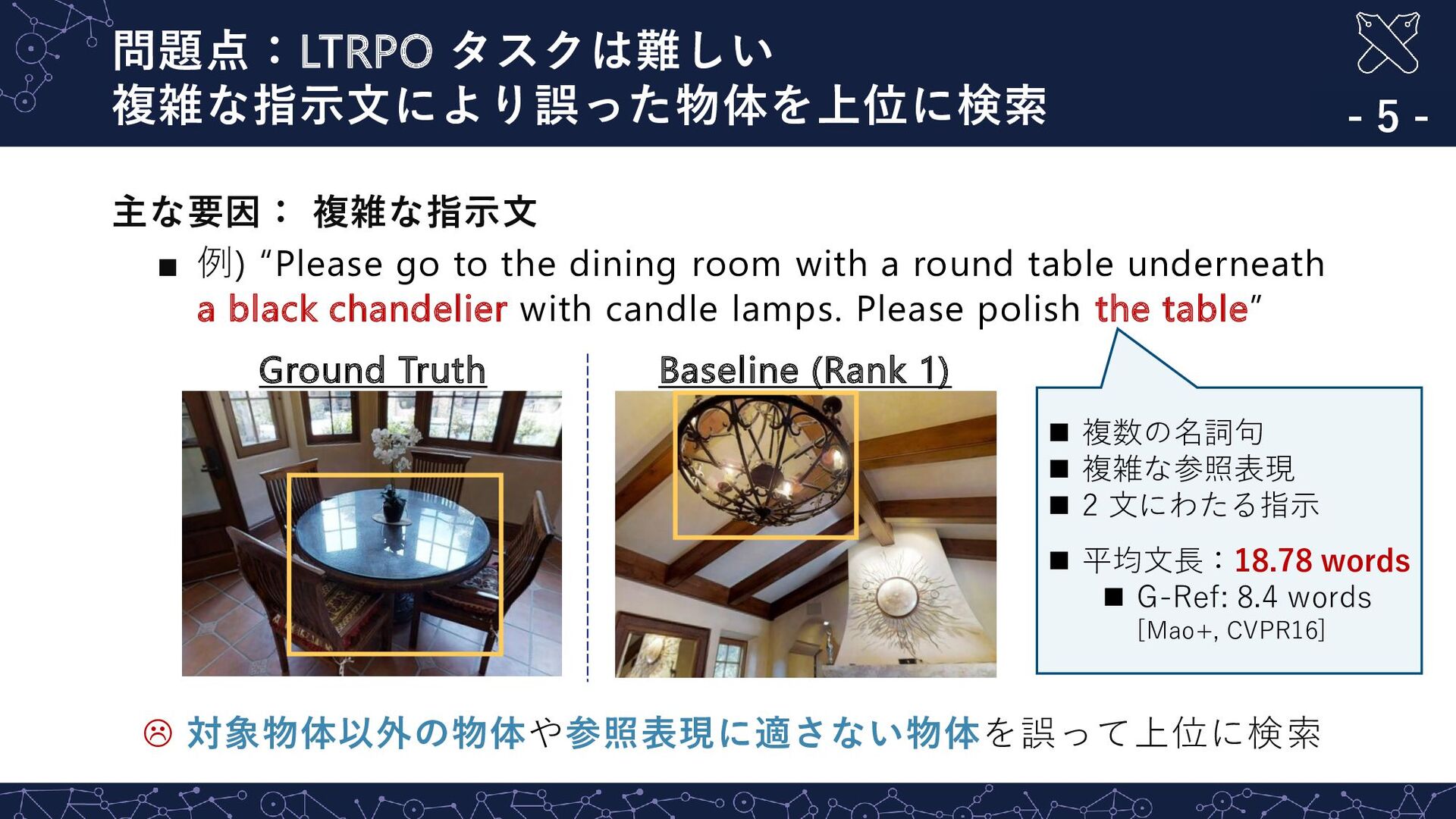{kind=link}
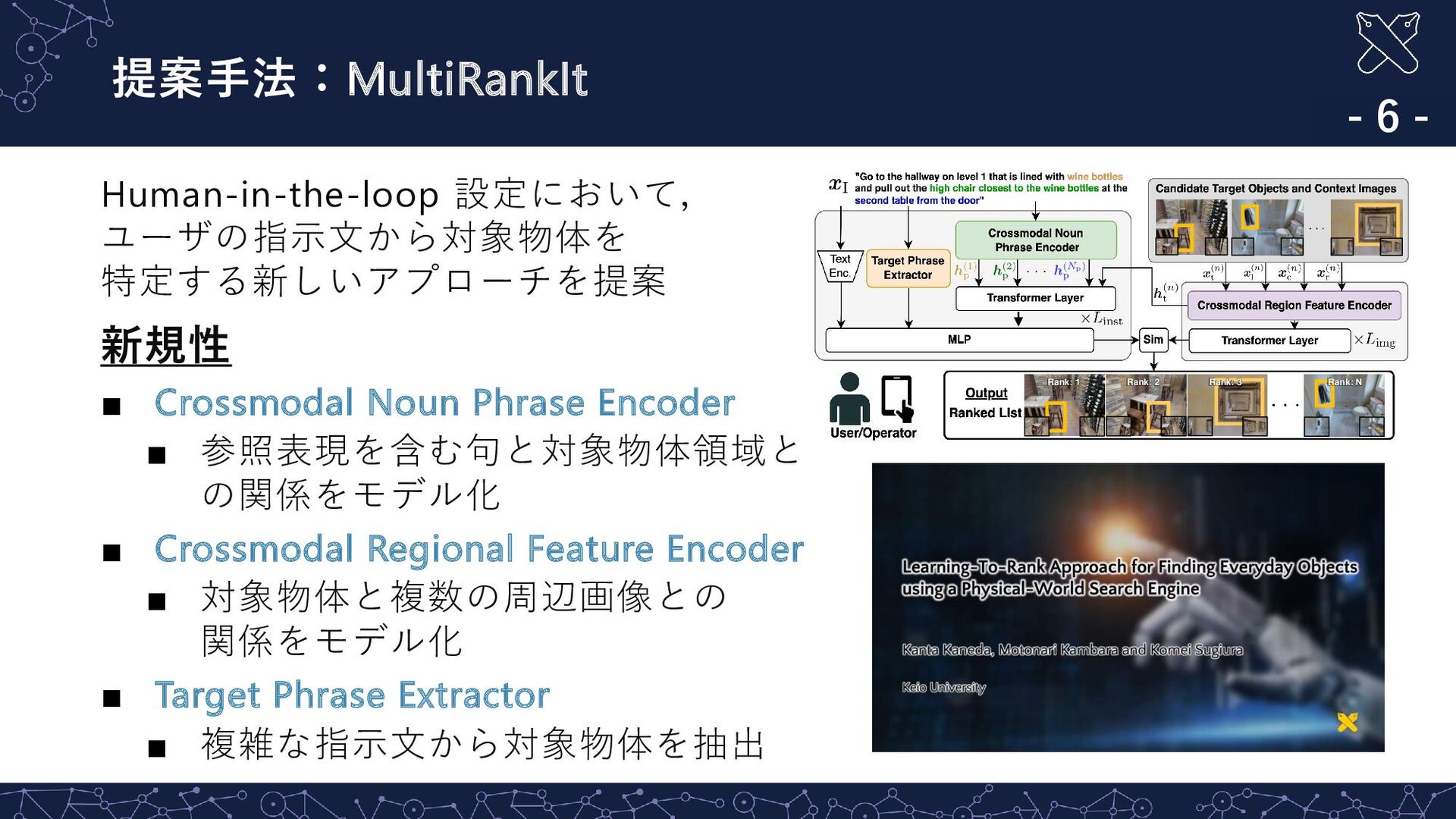{kind=link}
{kind=link}
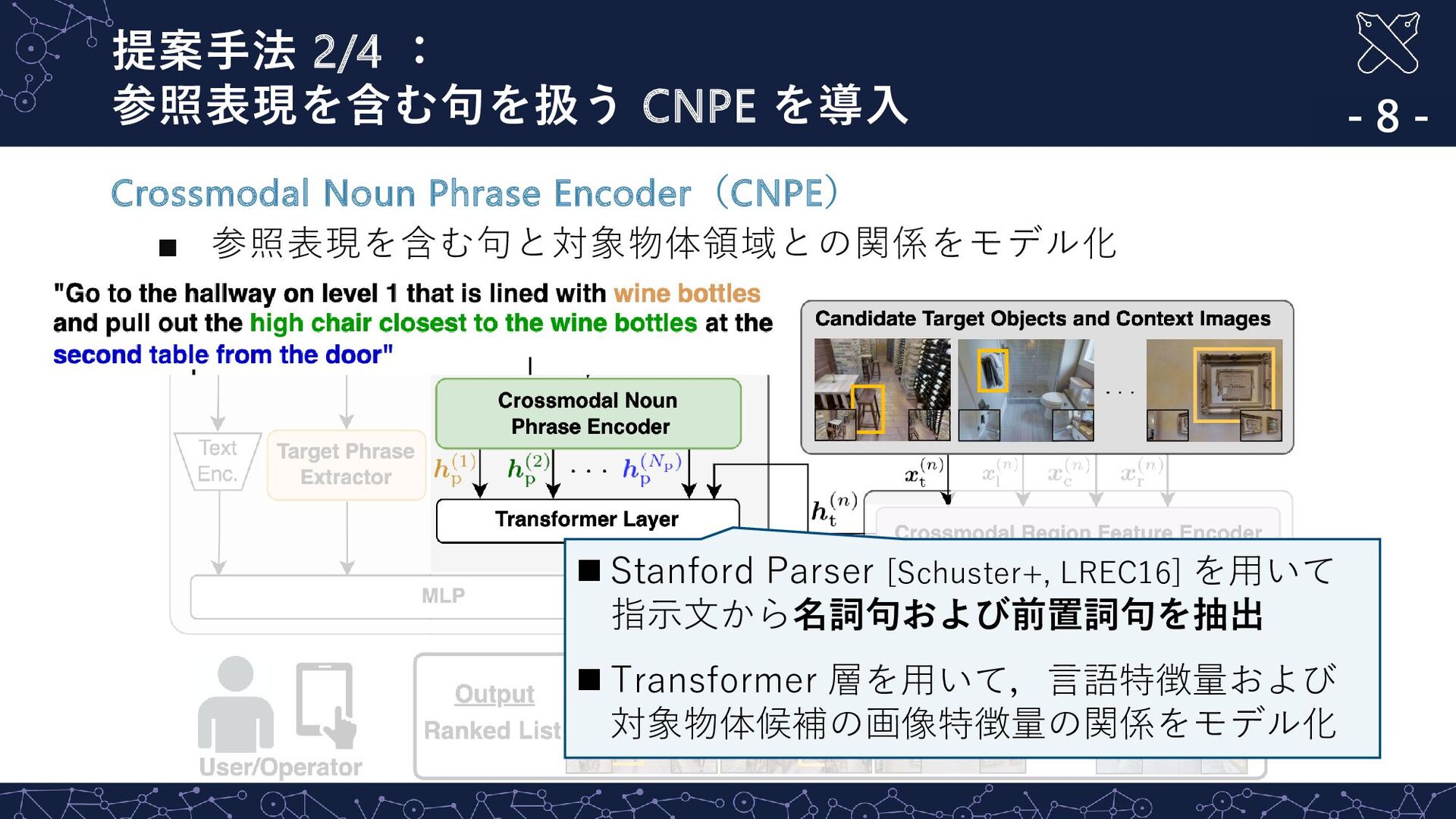{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}