A presentation for Georgia Southern's TechXpo (so to a bunch of college kids) about database pain, and the differences between classic RDBMS systems and NoSQL stuff.
“state” to another - which means you can have a bunch of rules inside the database to judge the validity of data, and any transaction that doesn’t pass fails and rolls back. Again, not great for performance.
wrong. It’s so fragile that you spend more time redoing it than actually getting any benefit from it. MySQL can do master/master. PostgreSQL ships binary logs via scp. It’s all horrible and gives me grey hairs. Because it was an afterthought and not designed from the beginning. Add-on replication is almost always horrible.
was even more of an afterthought. Most of the time it fails over on accident and breaks replication. And then someone gets woken up to clean up a steaming pile of bad data. And that person isn’t very happy about it.
Finally, some reality! Stop trying to be everything to everyone and solve all types of problems with the same hammer. So when you’re looking at a data store, see which two it can do and which you need for your data!
or “Not Only SQL” - but it’s really a bunch of different data stores that aren’t relational and solve different kinds of problems. And provide some solutions for old school reliability problems.
relational (though you can convince mongodb to do it, you shouldn’t) - Usually have really good replication stories - Let’s look at MongoDB vs traditional MySQL
(but you shouldn’t) They ship bin logs back and forth Fragile Easy to break replication by having conflicting writes committed near the same time on both sides - so split-brain is always a possibility.
node is picked as the primary. - It takes all writes, distributes to the secondaries - If the primary goes down, there’s an election and a new primary is chosen (usually less than 1 second). - New nodes join the replica set and get all the data, then can be elected primary
into the system as core functionality! - Much better failover - Much better reliability - I get to sleep more - Easy to add capacity as the replica set grows (either shard by adding new replica sets or add more nodes to scale reads).
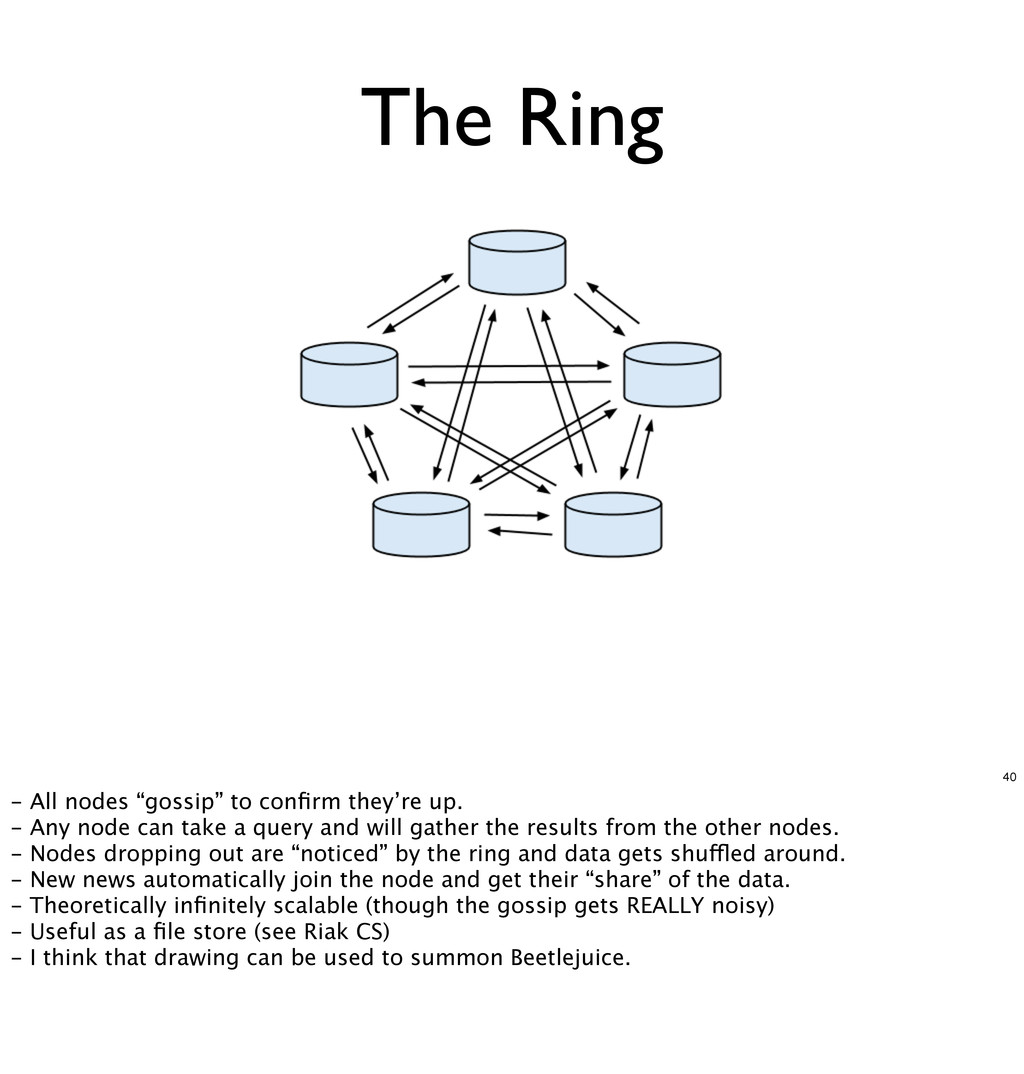
- Document store with very light querying (though the new search stuff is badass) - Super scalable via the “Ring” - Data is automagically replicated around the ring based on configuration - Number of copies
up. - Any node can take a query and will gather the results from the other nodes. - Nodes dropping out are “noticed” by the ring and data gets shuffled around. - New news automatically join the node and get their “share” of the data. - Theoretically infinitely scalable (though the gossip gets REALLY noisy) - Useful as a file store (see Riak CS) - I think that drawing can be used to summon Beetlejuice.
= MySQL replica sets! (kind of) - row-based replication is much more reliable - automatic failover and syncing of new nodes - can be load balanced for reads and writes! - still the same sql everyone’s used to - theoretically any node can take writes - but I don’t trust it
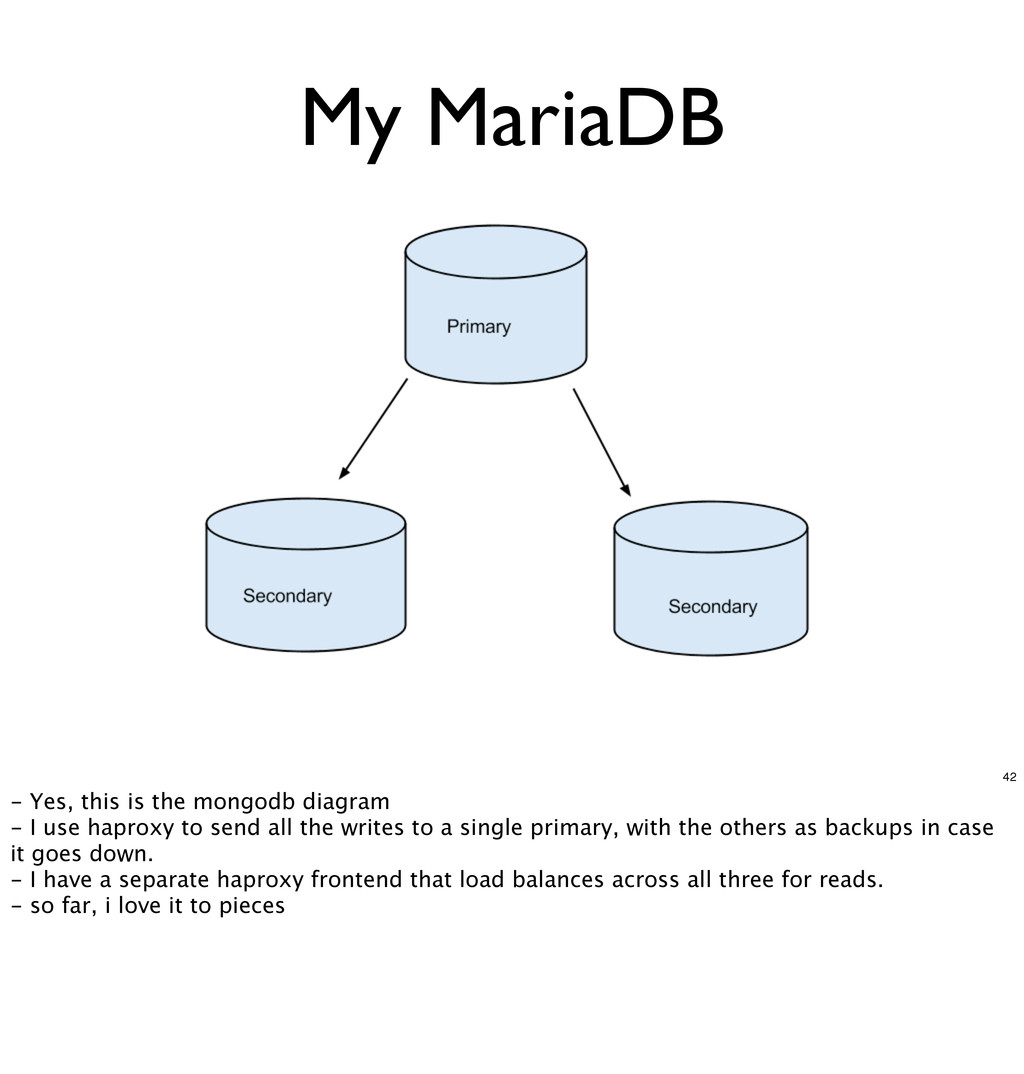
- I use haproxy to send all the writes to a single primary, with the others as backups in case it goes down. - I have a separate haproxy frontend that load balances across all three for reads. - so far, i love it to pieces
- the leastconn balanced pool of readers - mariadb_write_backend - db1 is the primary unless it goes down, then db2 is “promoted” - rails, mariadb_read and mariadb_write are the frontends
limit the types of queries you allow people to perform because they’ll lock things up and stop everyone from accessing it. - You’ll need to find other ways to “protect” the database, like.
to keep common queries away from the database. - If it can be read, it can be cached. - Saves you a ton of money in vertically scaling your database. - You may also need to add other ways to access your data, like say, elasticsearch or solr.
RDBMS! - Use RDBMS if you need transactions and your data truly is relational. - If it’s a document, use a document store - Understand the tradeoffs - Understand how your data will be queried - Don’t forget you can combine technologies to build whatever you need
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! • [email protected] • @kplawver • http://railsmachine.com • http://lawver.net](https://files.speakerdeck.com/presentations/3f73d710246a01317cb4020c2f9a5198/slide_51.jpg){kind=link}