2020 - July 2025 グループマネージャ@GO April 2019 - March 2020 AI研究開発エンジニア@DeNA April 2010 - March 2019 研究員@三菱電機 March 2010 博士@東北大学 https://gihyo.jp/book/2025/978-4-297-14663-4 Data-Centric AI コミュニティを 運営し定期的に勉強会を開催中
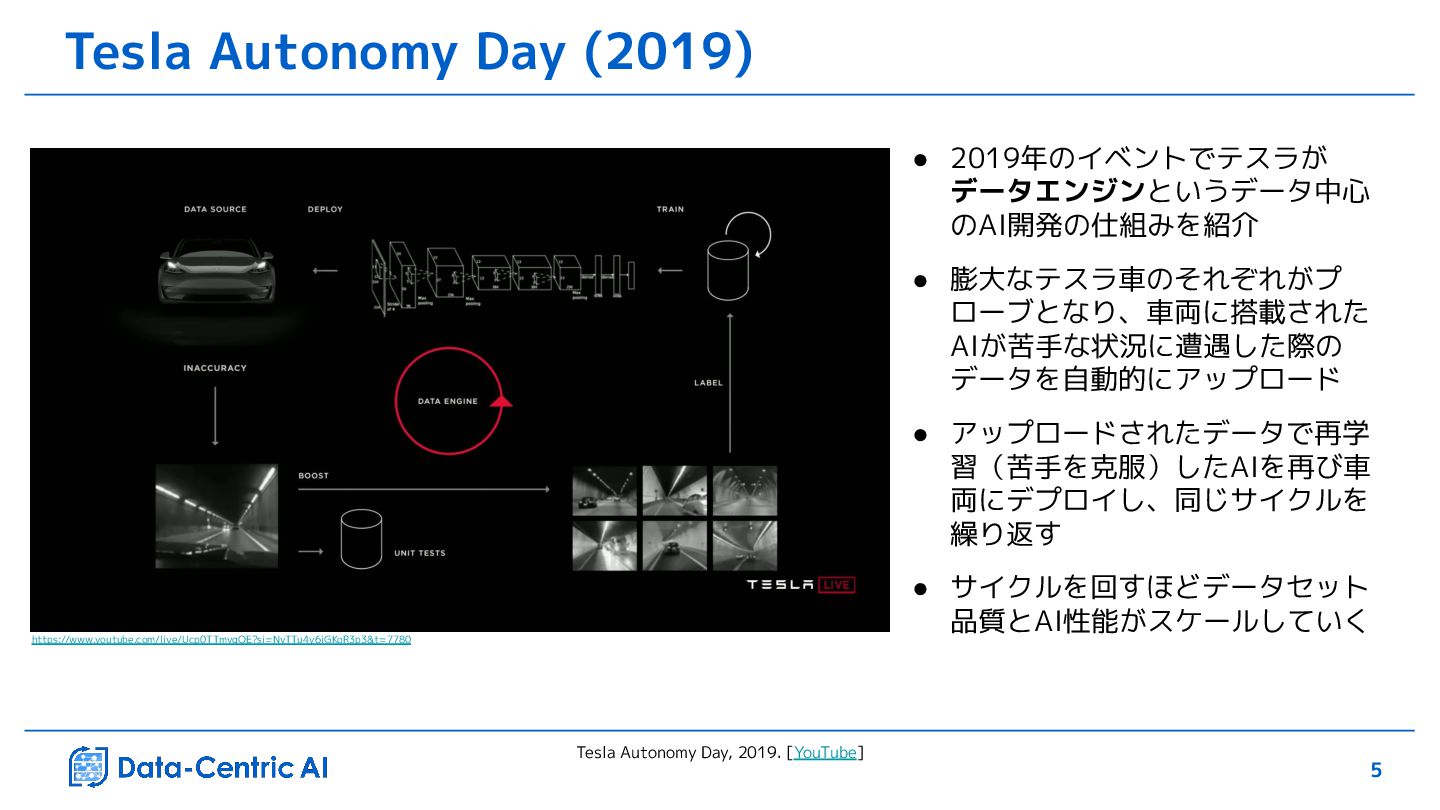
廃止してカメラによる画像認識に置き換え • 画像認識モデルの開発にあたり、モデル性 能が低下する状況のデータを収集するた め、モデル性能が不十分な場合に何が起こ るかをトリガ条件として洗い出し、トリガ 発動時にデータを収集 • カメラとレーダーの結果の不整合など200 種類以上のトリガ条件によって100万本の 動画が収集され、4ヶ月で画像認識モデル の開発を完了 ❏ radar vision mismatch ❏ bounding box jitter ❏ detection flicker ❏ detection in Main camera but not Narrow camera ❏ driver didn't break but tracker thinks CIPV is rapidly decelerating ❏ break lights are detected as on but acceleration is positive ❏ rarely high/low velocity or acceleration ❏ CIPV cuts in / cuts out ❏ CIPV has high lateral velocity ❏ bounding-box derived depth disagrees with network-predicted depth ❏ rarely sloping road surface (hillcrest or dip) ❏ rarely sharp turning road surface ❏ driver breaks sharply on the highway ❏ stop and go traffic ❏ Main or Narrow or both cameras appear to be blinded ❏ driver enters/exits tunnel ❏ objects on the roof (e.g. canoes) ❏ driver brakes harshly and there is a VRU close to us but there is no intersection データ収集のためのトリガの例 A. Karpathy, CVPR Workshop on Autonomous Driving, 2021. [YouTube]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AIによるデータ生成 19 Demystifying Synthetic Data in LLM Pre-training [EMNLP’25] •](https://files.speakerdeck.com/presentations/e1b354252f41446a975b2da2817a142f/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LLMがあれば人間によるラベルは不要か? 24 Keeping Humans in the Loop [ICWSM’25] • 11個のテキストデータセットから27個の二値分類タ](https://files.speakerdeck.com/presentations/e1b354252f41446a975b2da2817a142f/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
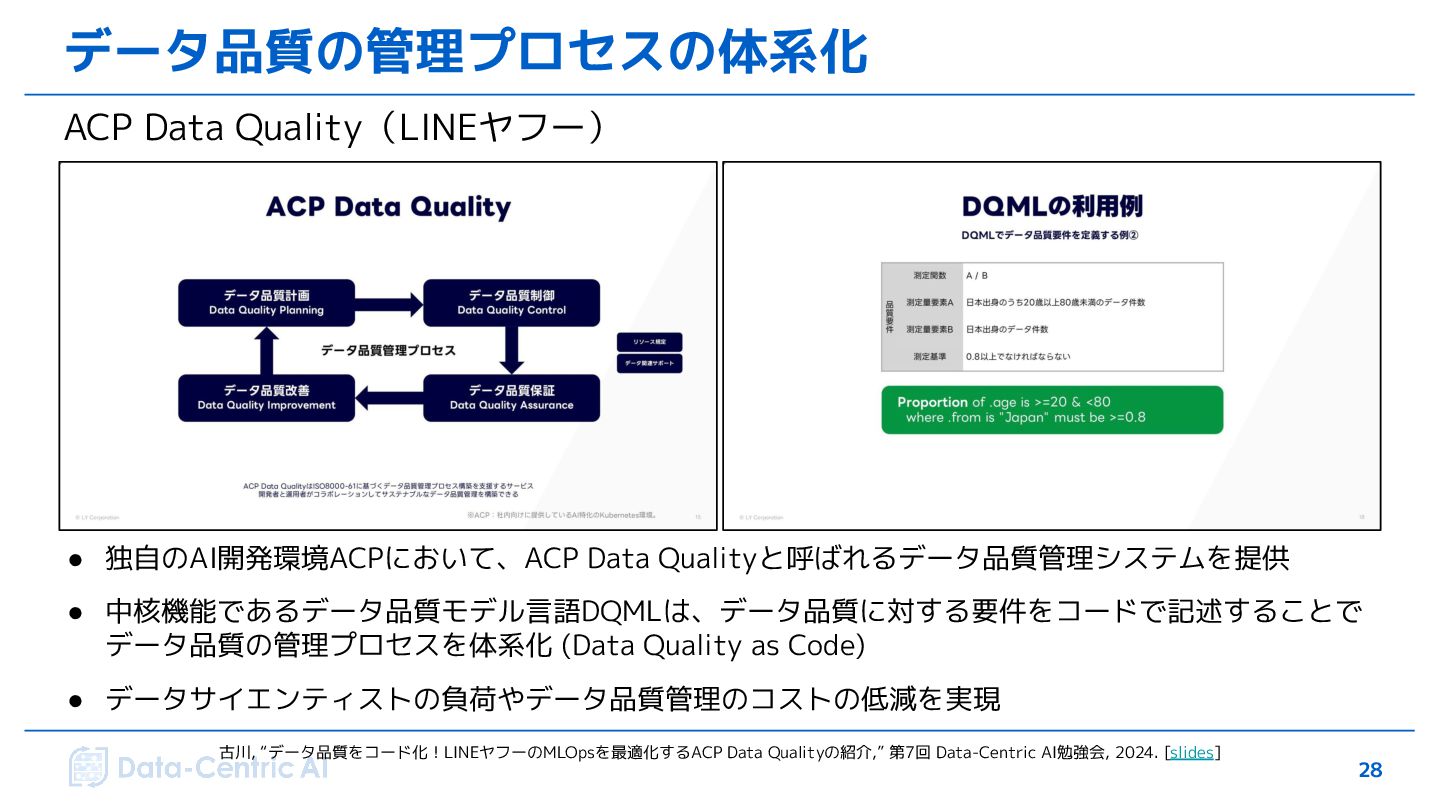{kind=link}
{kind=link}
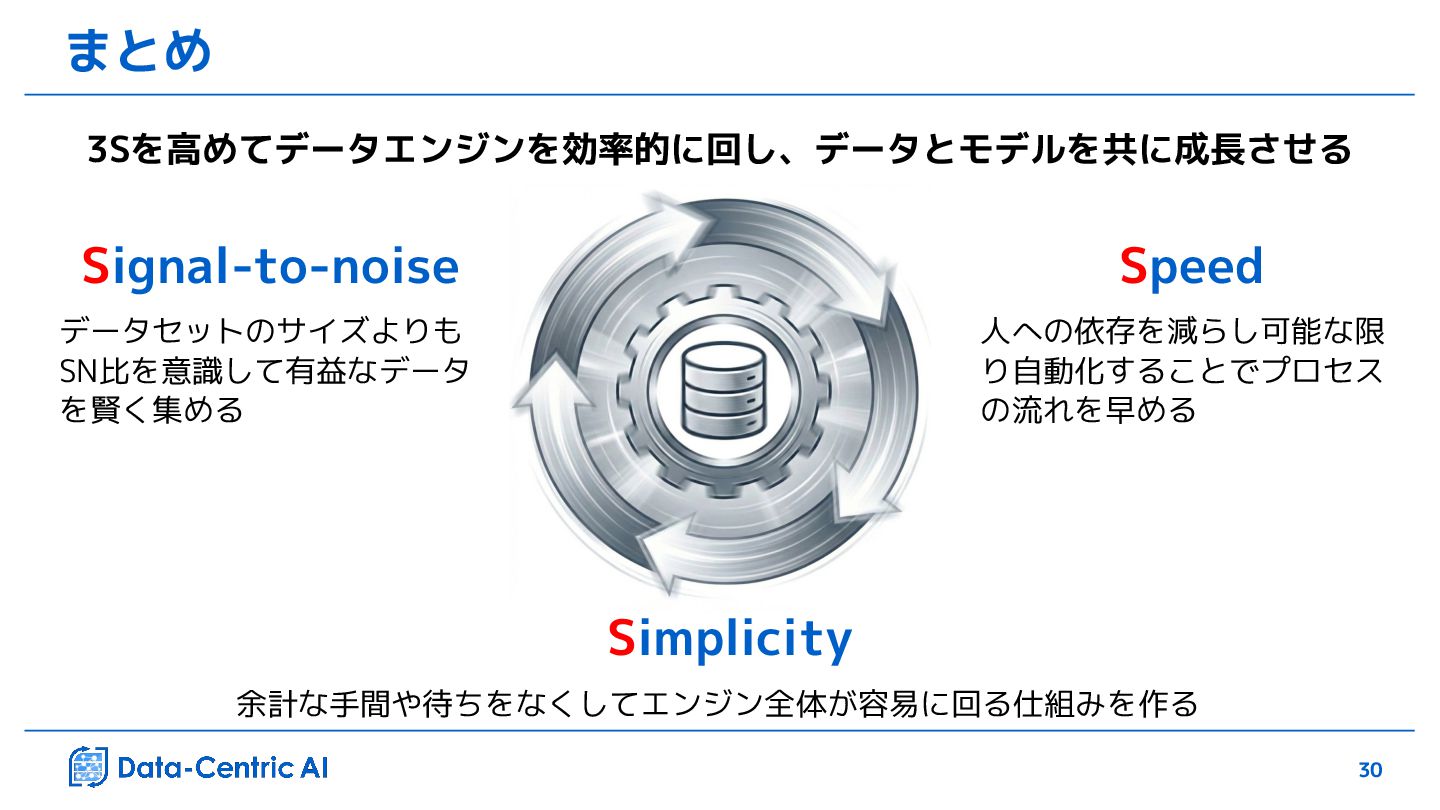{kind=link}