Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介_LSC-Eval: A General Framework to Evaluate ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
ShitoRyo
October 21, 2025
Research
32
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介_LSC-Eval: A General Framework to Evaluate Methods for Assessing Dimensions of Lexical Semantic Change Using LLM-Generated Synthetic Data
ShitoRyo
October 21, 2025
More Decks by ShitoRyo
See All by ShitoRyo
Tutorial of Coding Environment for Research by Docker
lexusd
0
49
Computational Approaches for Diachronic Semantic Change Detection_2024_8
lexusd
0
58
論文紹介_Learning Dynamic Contextualised Word Embeddings via Template-based Temporal Adptation
lexusd
0
150
論文紹介_Are Embedded Potatoes Still Vegetables_ On the Limitation of WordNet Embeddings for Lexical Semantics
lexusd
0
160
論文紹介_Interpretable Word Sense Representations via Definition Generation_ The Case of Semantic Change Analysis
lexusd
0
140
論文紹介_Twitter Topic Classification
lexusd
0
120
論文紹介_What is Done is Done_ an Incremental Approach to Semantic Shift Detection
lexusd
0
130
Demoの作り方_研究会チュートリアル
lexusd
0
180
論文紹介_Ruddit_Norms of Offensiveness for English Readdit Comments
lexusd
0
75
Other Decks in Research
See All in Research
COMETAを用いたデータ民主化運動の歴史
sazimai
0
130
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
310
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
240
SLAMはどこまで解決されたのか?
tomonom
0
860
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
160
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
Fukui Shibiten 39 - AI Art
butchi
0
150
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
480
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
390
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
130
260624_NLP-colloquium: Hubness
de9uch1
0
120
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
340
Featured
See All Featured
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Crafting Experiences
bethany
1
230
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Building Adaptive Systems
keathley
44
3.1k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
620
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Producing Creativity
orderedlist
PRO
348
40k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
270
30 Presentation Tips
portentint
PRO
1
350
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
Transcript
Paper Link | 相田さんの紹介資料 ACL 2025 Findings 論文読み会 D1 凌 志棟
概要 • 問題:意味変化の種類を予測したいがデータが不足・言語横断できる評価方法が ない • 提案手法:意味変化の次元ごとに、変化データを合成し擬似的な変化を作る ◦ Sentiment:感情・価値的にネガティブ⇔ポジティブ ◦ Intensity:感情的に弱い(落ち着いている)⇔強い →メリハリ?
◦ Breadth:意味的に似ていない⇔似ている • 実験: ◦ 人工データは次元ごとに変化を反映できるか? →YES ◦ どの手法が一番変化を検出できるか? →次元ごとに違う
<Gay> and its Synonyms in English. [Hamilton+, 2016] gay (1900s)
gay (1990s) 意味変化検出 gay (1950s) flaunting tasteful daft witty bright bisexual lesbian sweet cheerful 結構 (1820s) 結構 (2000s) 布置 (Layout) 構造 (Structure) 充分 · 良好 (splendid) 割と (quite) <結構 (kekko)> and its Synonyms in Japanese. [Ling+, 2023] 3 単語の意味は時代とともに変わることがある タスク:大規模データから意味が変わった単語を検出(基本的に教師なし)
タスク自体の変化 今までの意味変化検出: 単語の意味が変化したのか? = 0 or 1 単語の意味がどれぐらい変化したのか? = [0,
1] 最近の意味変化検出[Aida2024]:意味の種類(変わり方)について、種類を知りたい 本タスクのチャレンジ: • 意味変化の種類をどのように定義 するか • 定義した意味変化の種類をどのように予測・評価 するか
今まで評価が直面する問題点 • 通時コーパス由来のベンチマーク不足 →手法の妥当性が定まらない • 単語の意味のなにが変わったのか 、次元ごとの評価が難しい 先行研究: • [Schlechtweg+2020]
単語がどれぐらい変わったかをアノテーションで算出 ◦ SemEval-2020 Task 1:パターン情報そもそもなかった;データ作成のコストが 高い • [Loureiro+2022] TempoWiC:通時的なWord-in-Context in SNS data ◦ Word-in-Context:単語の2つの用例で、対象単語の意味が同じなのかを判断するタスク • [Cassotti+2024] 単語の(旧語義,新語義)のペアで変化パターンを分類 ◦ Wordnetの語義関係を[Blank, 1997]の変化パターンにマッピング、 メタファーや意味の漂流を扱 わ なかった • [Baes+2024] Sentiment / Intensity / Breadth 三軸で意味変化を分類 ◦ 同著者による理論、今回の手法もこの理論によって設計された
本研究の提案:LSC-Eval 合成データを使用するLanguage Independentな評価フレームワーク • ベンチマーク不足 → LLM (ICL)+辞書で人工データ を作ろう •
次元ごとの評価が難しい → 人工データを既存手法の次元 で評価、適合性を示す Research Question: • 人工データを用いた評価方法は妥当なのか?(ちゃんと変化を起こせるか) • 検出手法の中にどれが一番人工データの変化を検出できるか?
SIBling Framework [Baes+2024] 複数次元での評価尺度で意味変化を区別 • Sentiment:感情・価値的にネガティブ⇔ポジティブ • Intensity:感情的に弱い(落ち着いている)⇔強い • Breadth:意味的に似ていない⇔似ている
3軸でたくさんの変化類型を表示できるはず↓
SIBling Framework 複数次元での評価尺度で意味変化を区別 • Sentiment:感情・価値的にネガティブ⇔ポジティブ ◦ 感情辞書を使用 ◦ Valence∊[1,9] ;
extremely unhappy → extremely happy ◦ 対象単語と共起単語の感情ラベルの平均値 • Intensity:感情的に落ち着いている⇔興奮 ◦ 辞書を使用 ◦ Arousal∊[1,9] ; extremely calm → extremely agitated ◦ Sentimentと同じように算出 • Breadth:意味的に似ていない⇔似ている ◦ 時期内用例文の文ベクトルの Average Pairwise Cosine Distance ◦ なぜ文ベクトルを使うのか …?
LSC-Eval Framework Stage 1 SIBlingの次元にしたがってデータ生成 via ICL/Dic • 対象単語に対して、コーパスから変化次元が中性 (Neutral)となる用例
を抽出しPromptに与える ◦ 後ほどNeutralに変化を注入 • Sentiment/Intensity: 「与えられた用例の中の対 象単語をよりポジティブ / ネガティブ|落ち着く/ 興 奮するに使う用例を生成して」とLLMに聞く • Breadth: 対象単語と同じ上位語(wordnet参考)を 持つ複数の単語の用例から、その単語を対象単語 で置換 ◦ →他の単語の用例を自分にすることで語義を拡張(語義 が多くなる)
Stage 1 Sentiment / Intensity 使用されたPrompt
Stage 1 Sentiment / Intensity Generated Examples 文脈が確かに変わったが、対象単語の語義自体がそこまで変わっていない …? →意味変化の途中状態をモデリングできた?
人間がはっきりわかる|感じる意味変化の境界は?と思ったりした
Breadth 単語置換の例
LSC-Eval Framework Stage 1 1. {Neutral | 人工}データから用例をランダムサン プリング •
Bootstrap Sampling ◦ 全データから50文(重複可)×100回 • Five-year Interval Sampling ◦ 5年分のデータごとに 50文抽出(重複不可)×10回 ◦ 50年分のデータがあるので Time binが10個 2. 人工データ注入割合 Injection Level • 毎回サンプリングした 50文の中にx%が人工 データ x∊[0,20,40,60,80,100] • Stage 2 でモデルのsensitivityを評価
LSC-Eval Framework Stage 1 合成データ統計量 • 心理学関連のコーパス[Vylomova+2019]のみ使 用→ドメインによる変化を除外できる • コーパス時期:1970〜2019;5年区切り •
対象単語:心理学用語 6つ ◦ abuse, anxiety, depression, mental health, mental illness, trauma ◦ 事前に変化ありとわかった単語集から選んだ ◦ →変化を注入するのであれば変化なし単語でもい けるはず?
LSC-Eval Framework Stage 2 Neutral+人工のデータで変化次元ごとに定量化 • Sentiment (0-1): 時期ごとに対象単語と共起単語の値 の平均をとる(正規化される)
• Intensity (0-1): Sentimentと同じく • Breadth (0-1): 時期ごとに、その時期の用例集合に対 して、文ベクトルの Average Pairwise Cosine Distance (APD) を算出(正規化される) ◦ 0=変化なし(時期内の語義が近い); ◦ 1=大きく変化(時期内の語義がバラバラ)
LSC-Eval Framework Stage 2 実験設定 • 次元ごとに比較 ◦ Sentiment: ▪
ABSA (Aspect Based Sentiment Analysis):DeBERTaベースの感情推定モデル ▪ 対象単語の感情を0−1で出力 ◦ Intensity: 当面は比較できる手法がないという( Baselineのみ) ◦ Breadth: ▪ XL-LEXEME (XLL):意味変化検出での最強 Encoderモデル? ▪ MPNet:BERT+XL-NetのSentence Transformer ▪ 文ベクトルを取ってAPDを算出 • Baseline: ◦ SIBlingのスコア(Valence; Arousal; Breadth) ◦ LSC-score: XL-LEXEMEを2つの時期間で算出した意味変化度合
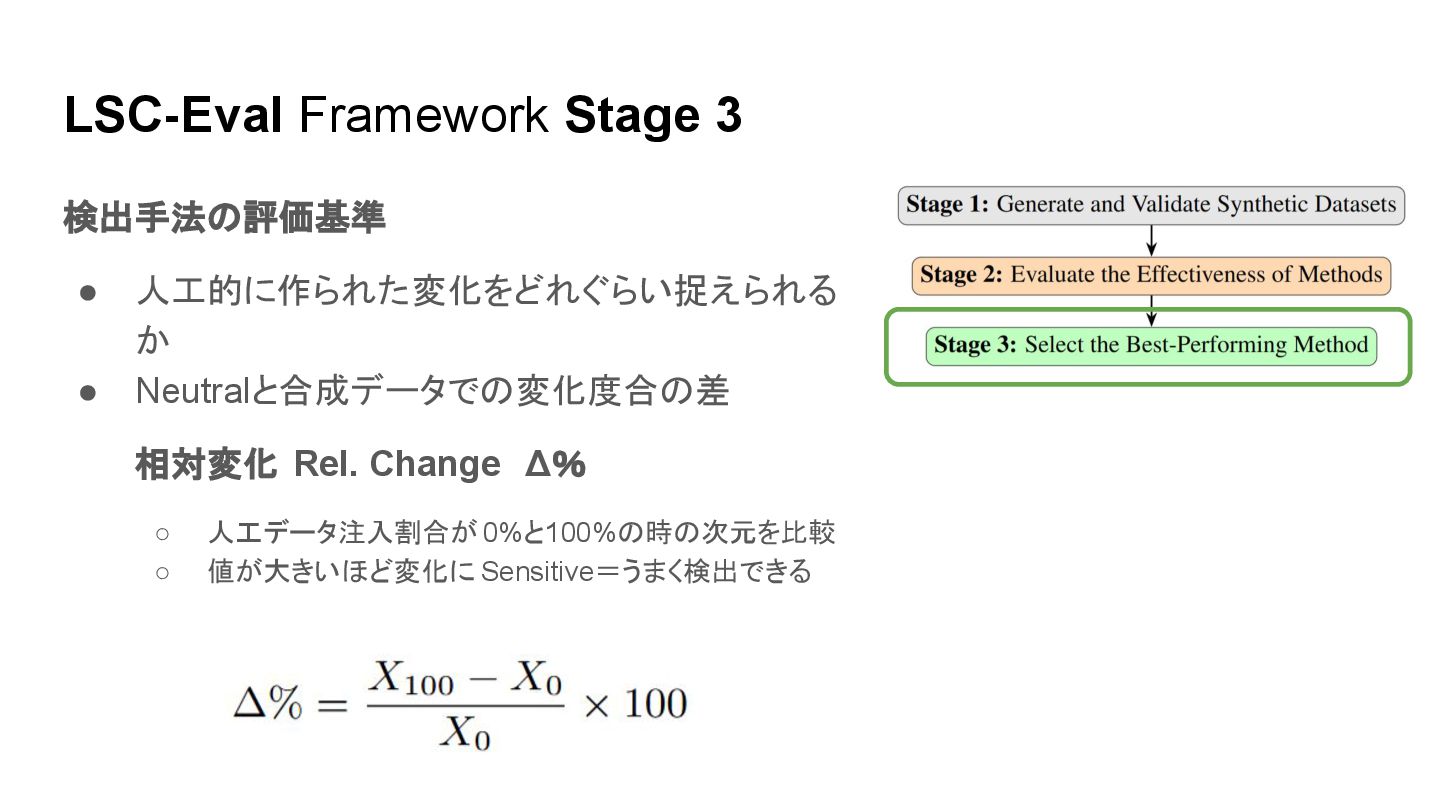
LSC-Eval Framework Stage 3 検出手法の評価基準 • 人工的に作られた変化をどれぐらい捉えられる か • Neutralと合成データでの変化度合の差
相対変化 Rel. Change Δ% ◦ 人工データ注入割合が 0%と100%の時の次元を比較 ◦ 値が大きいほど変化に Sensitive=うまく検出できる
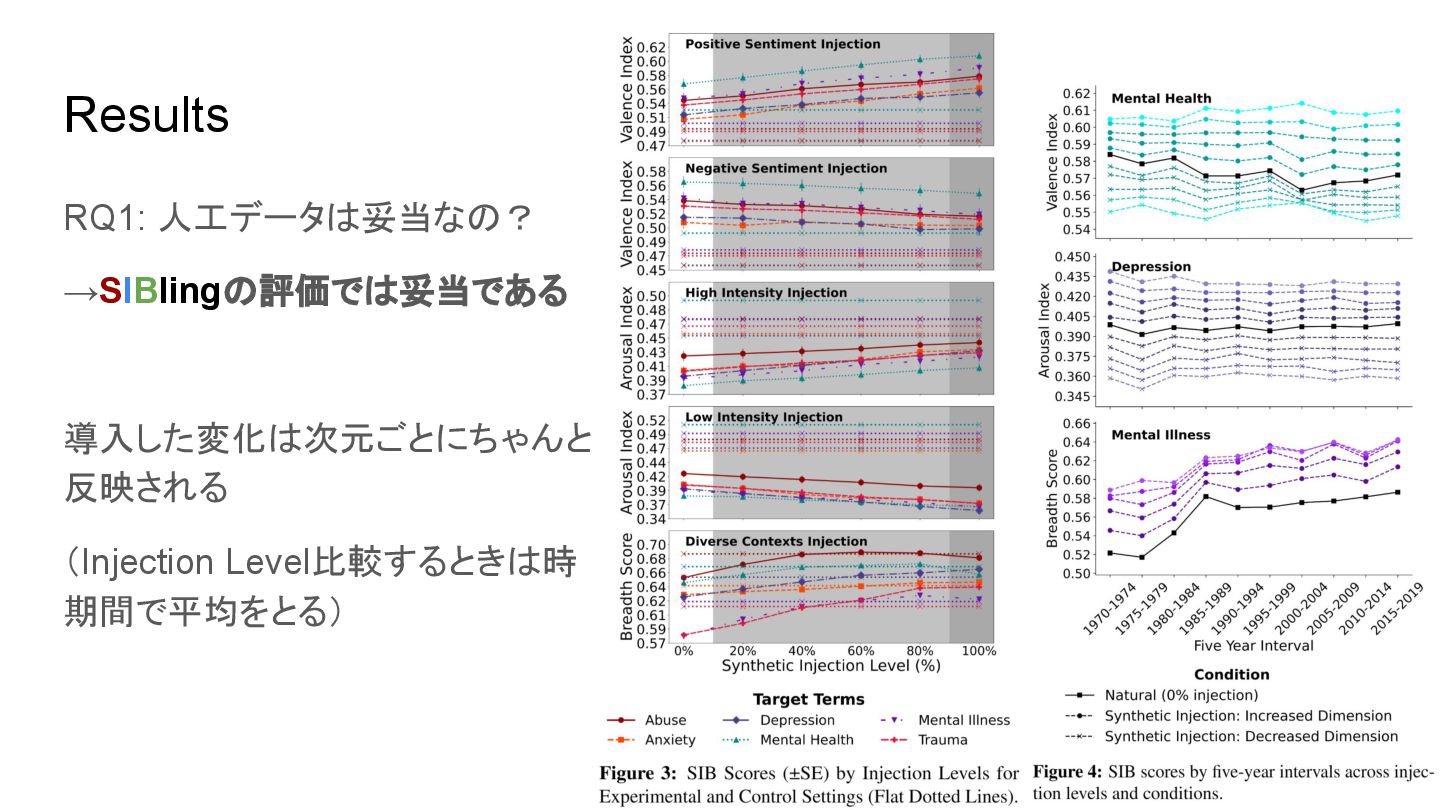
Results RQ1: 人工データは妥当なの? →SIBlingの評価では妥当である 導入した変化は次元ごとにちゃんと 反映される (Injection Level比較するときは時 期間で平均をとる)
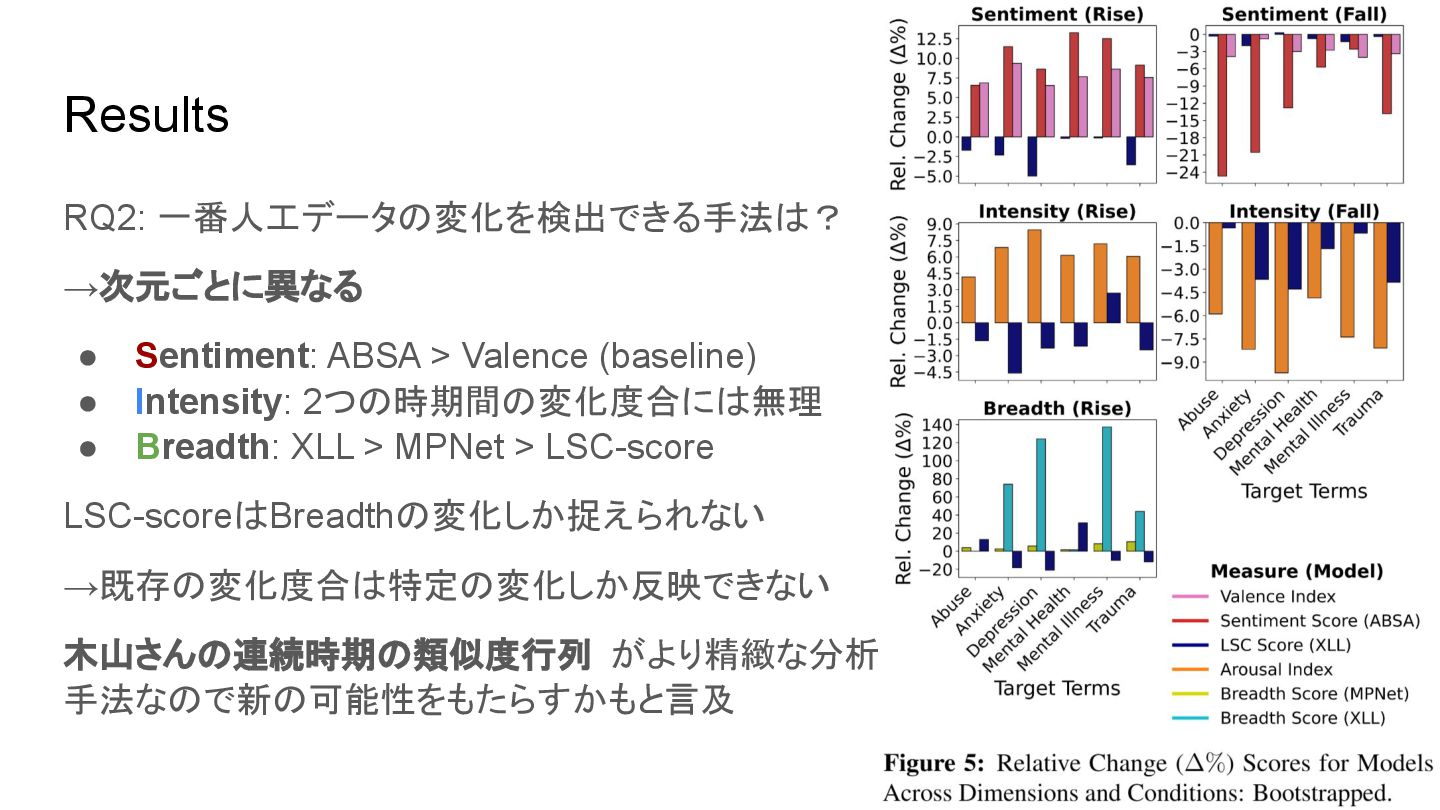
Results RQ2: 一番人工データの変化を検出できる手法は? →次元ごとに異なる • Sentiment: ABSA > Valence (baseline)
• Intensity: 2つの時期間の変化度合には無理 • Breadth: XLL > MPNet > LSC-score LSC-scoreはBreadthの変化しか捉えられない →既存の変化度合は特定の変化しか反映できない 木山さんの連続時期の類似度行列 がより精緻な分析 手法なので新の可能性をもたらすかもと言及
Limitation • Breadthの複雑性 ◦ 本研究は語義の拡張(≒一般化)のみモデリング ◦ どの語義がどう拡張されたかは不明 • Intensityに対する研究は不足 ◦
Intensityに関連するMeiosis(抑言)・Hyperbole(誇張)に言及はない • Metaphor(隠喩)とMetonymy(換喩)を表現できていない
Conclusion・まとめ • 本研究はLSC-Evalという意味変化検出のための評価フレームワークを提案 • LLM+辞書で合成データを生成し、その妥当性を実験で示した • 既存の検出手法を合成データで検証し、限界を示した • 一番の貢献としては:ラベル付き意味変化の正解データの不足を解消 Future
Work • 今後は異なるドメインのコーパスに提案手法を適用 • 特に社会学の研究に適用することが面白そう
{kind=link}
{kind=link}
![<Gay> and its Synonyms in English. [Hamilton+, 2016] gay (1900s)](https://files.speakerdeck.com/presentations/4301898d377f42dd889143c808fd5fa5/slide_2.jpg){kind=link}
{kind=link}
![今まで評価が直面する問題点 • 通時コーパス由来のベンチマーク不足 →手法の妥当性が定まらない • 単語の意味のなにが変わったのか 、次元ごとの評価が難しい 先行研究: • [Schlechtweg+2020]](https://files.speakerdeck.com/presentations/4301898d377f42dd889143c808fd5fa5/slide_4.jpg){kind=link}
{kind=link}
![SIBling Framework [Baes+2024] 複数次元での評価尺度で意味変化を区別 • Sentiment:感情・価値的にネガティブ⇔ポジティブ • Intensity:感情的に弱い(落ち着いている)⇔強い • Breadth:意味的に似ていない⇔似ている](https://files.speakerdeck.com/presentations/4301898d377f42dd889143c808fd5fa5/slide_6.jpg){kind=link}
![SIBling Framework 複数次元での評価尺度で意味変化を区別 • Sentiment:感情・価値的にネガティブ⇔ポジティブ ◦ 感情辞書を使用 ◦ Valence∊[1,9] ;](https://files.speakerdeck.com/presentations/4301898d377f42dd889143c808fd5fa5/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LSC-Eval Framework Stage 1 合成データ統計量 • 心理学関連のコーパス[Vylomova+2019]のみ使 用→ドメインによる変化を除外できる • コーパス時期:1970〜2019;5年区切り •](https://files.speakerdeck.com/presentations/4301898d377f42dd889143c808fd5fa5/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}