to Draft Long-Horizon Plans? Let’s Take TravelPlanner as an Example • Analysis of Plan-based Retrieval for Grounded Text Generation • Diffusion Model for Planning: A Systematic Literature Review • REAPER: Reasoning based Retrieval Planning for Complex RAG Systems • AgentGen: Enhancing Planning Abilities for Large Language Model based Agent via Environment and Task Generation 推論 • Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers • To Code, or Not To Code? Exploring Impact of Code in Pre-training ツール利用 • TOOLSANDBOX: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities • Tulip Agent -- Enabling LLM-Based Agents to Solve Tasks Using Large Tool Libraries • Re-Invoke: Tool Invocation Rewriting for Zero-Shot Tool Retrieval 自己修正 • Internal Consistency and Self-Feedback in Large Language Models: A Survey
Contrastive Learning • The Emerged Security and Privacy of LLM Agent: A Survey with Case Studies • The Art of Refusal: A Survey of Abstention in Large Language Models 心の理論 • MuMA-ToM: Multi-modal Multi-Agent Theory of Mind メモリ • HIAGENT: Hierarchical Working Memory Management for Solving Long-Horizon Agent Tasks with Large Language Model 評価 • VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents • MMAU: A Holistic Benchmark of Agent Capabilities Across Diverse Domains Agent framework • MegaAgent: A Practical Framework for Autonomous Cooperation in Large-Scale LLM Agent Systems • Automated Design of Agentic Systems • Coalitions of Large Language Models Increase the Robustness of AI Agents • Building Machines that Learn and Think with People
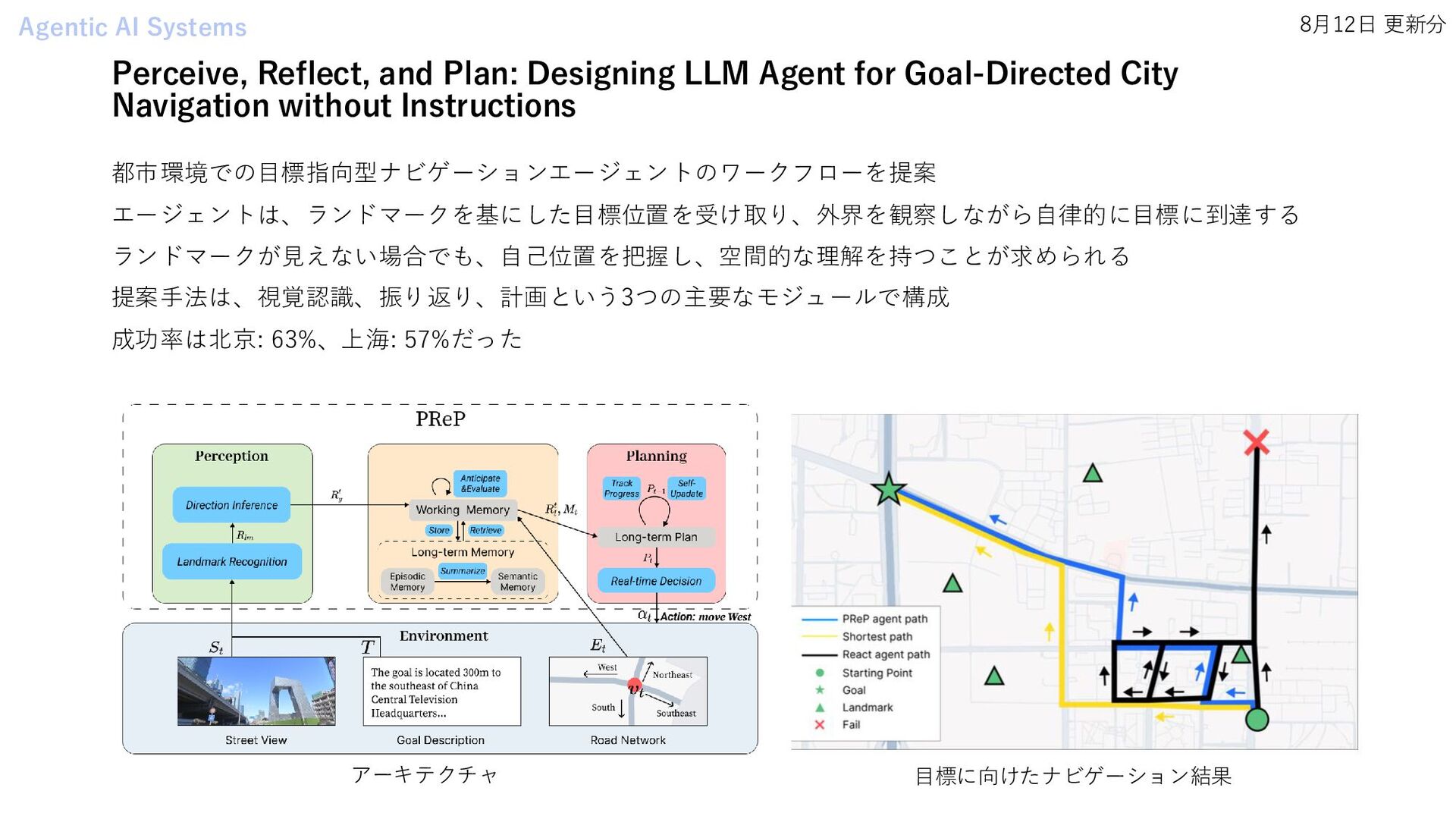
Fully Automated Open-Ended Scientific Discovery • BLADE: Benchmarking Language Model Agents for Data-Driven Science • OpenResearcher: Unleashing AI for Accelerated Scientific Research • Diversity Empowers Intelligence: Integrating Expertise of Software Engineering Agents • LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs • OfficeBench: Benchmarking Language Agents across Multiple Applications for Office Automation • MindSearch 思·索: Mimicking Human Minds Elicits Deep AI Searcher • From LLMs to LLM-based Agents for Software Engineering: A Survey of Current, Challenges and Future • Perceive, Reflect, and Plan: Designing LLM Agent for Goal-Directed City Navigation without Instructions Multi Agent Systems • Text2BIM: Generating Building Models Using a Large Language Model-based Multi-Agent Framework • Can LLMs Beat Humans in Debating? A Dynamic Multi-agent Framework for Competitive Debate • LAMBDA: A Large Model Based Data Agent • MetaOpenFOAM: an LLM-based multi-agent framework for CFD • From Data to Story: Towards Automatic Animated Data Video Creation with LLM-based Multi-Agent Systems
for Productivity in XR • Optimus-1 : Hybrid Multimodal Memory Empowered Agents Excel in Long-Horizon Tasks • RiskAwareBench: Towards Evaluating Physical Risk Awareness for High-level Planning of LLM-based Embodied Agents Computer Controlled Agents • Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents • AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents* • CRAB: Cross-environment Agent Benchmark for Multimodal Language Model Agents
via Environment and Task Generation Microsoftから、エージェントの計画能力を向上させるデータセットを作成するフレーワムワークを提案 多様な環境でPDDLを利用する前提で、段階的に難易度を上げ下げして計画タスクを生成させる 学習は簡単な難易度からおこない、徐々に複雑なタスクを学習させる(カリキュラム学習) Llama3-8Bを学習させ、GPT-3.5を超える性能を示し、特定のタスクではGPT-4をも上回る結果を示す Easy Hard Agent Capabilities:計画 8月12日 更新分
AIから研究をおこない、論文を執筆するAI Scientistを提案 研究アイデアの生成、コードの実装、実験の実行、結果の可視化、論文の執筆、論文レビューを自動化 それぞれ個別の研究が既存にあるので、その手法を活用するとさらに全体の精度が高くなる可能性はある ボトルネックはあれど、エンドツーエンドで動かし切れるレベルに仕上げたのが貢献に思う Agentic AI Systems 8月26日 更新分
この課題は、SFTデータセットに長文出力の例が不足していることに起因している。 AgentWriteというアウトライン計画に基づき、LLMに各段落を順番に生成させるパイプラインを導入し、6kデー タセットを作成した。 Llama-3.1の8BをDPOで学習させ、2万語以上のテキスト生成を可能にした。 Agentic AI Systems 8月26日 更新分
WebPlannerはユーザークエリを複数のサブクエリに分解し、それをWebSearcherに渡す WebSearcherはクエリ拡張し、複数の検索エンジンの結果を統合して、LLMが有益なページを選び要約する MindSearchは3分以内に300以上のウェブページから情報を並行して収集および統合することが可能 Agentic AI Systems 8月12日 更新分
with LLM- based Multi-Agent Systems GPT-4を中心としたデータストーリーを自動生成するためのマルチエージェントシステムを提案 データの分析結果を物語の形式で構成し、顧客に洞察や情報をわかりやすく伝える技術や手法を指す ユーザー提供データを解釈し、データ分析とデザインの2つのエージェントが連携してビデオを生成 データは、洞察抽出、視覚化、ナレーション、アニメーションとして段階的に処理される Multi Agent Systems 8月12日 更新分
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}