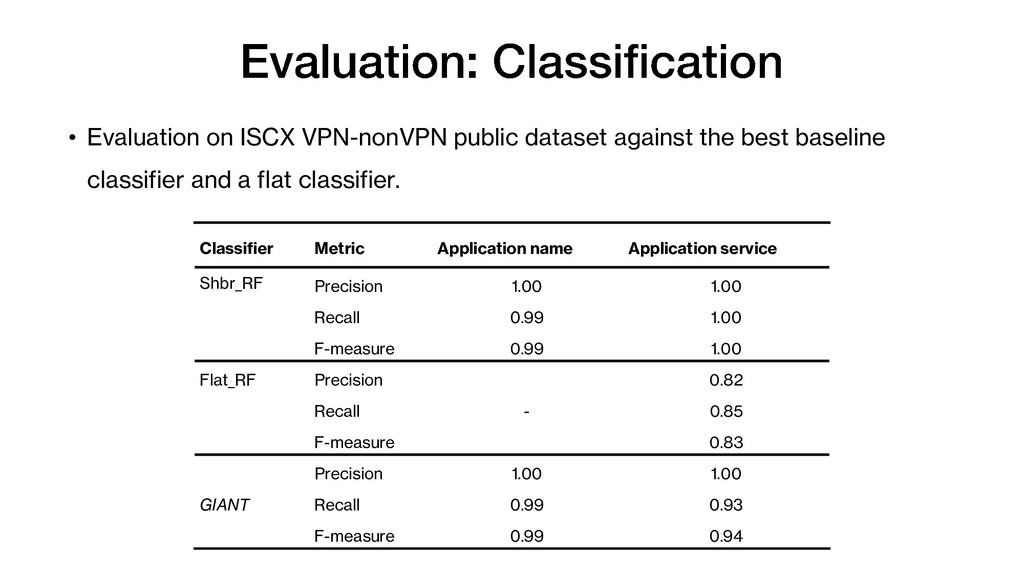
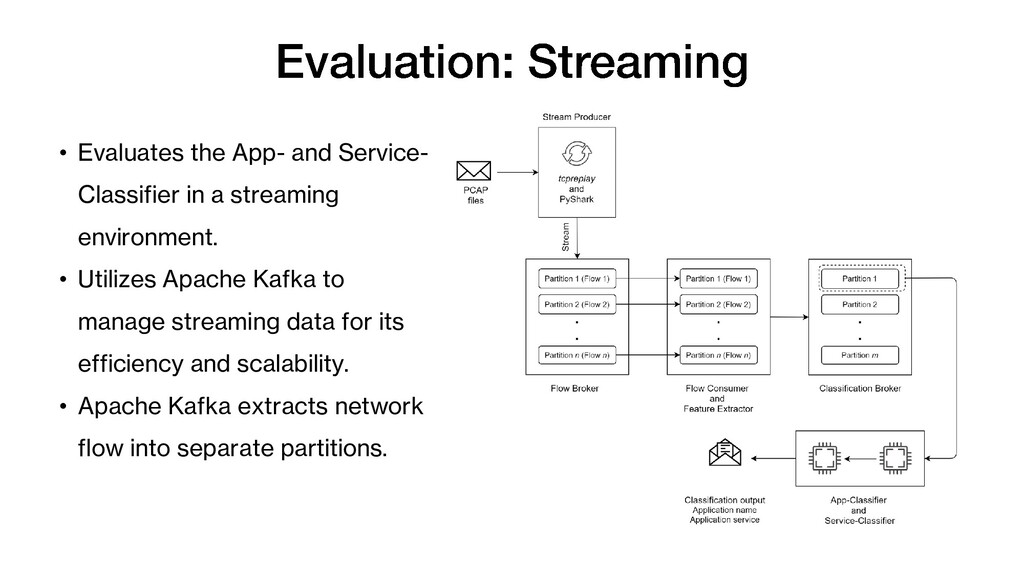
framework for granular network traffic classification. 3. A reliable granular network traffic ground tool. 4. A robust feature set. 5. A context-aware multi-label incremental learner using classifier chain. Publications Zaki, F., Gani, A., Tahaei, H., Furnell, S., & Anuar, N. B. (2021). Grano-GT: A granular ground truth collection tool for encrypted browser-based Internet traffic. Computer Networks, 184, 107617. doi:https://doi.org/10.1016/j.comnet.2020.107617 Zaki, F., Gani, A., & Anuar, N. B. (2020). Applications and use Cases of Multilevel Granularity for Network Traffic Classification. Paper presented at the 2020 16th IEEE International Colloquium on Signal Processing & Its Applications (CSPA), Langkawi, Malaysia. Tahaei, H., Afifi, F., Asemi, A., Zaki, F., & Anuar, N. B. (2020). The rise of traffic classification in IoT networks: A survey. Journal of Network and Computer Applications, 154, 102538. doi:https://doi.org/10.1016/j.jnca.2020.102538 (Secondary contribution) Zaki, F., Afifi, F., Abd Razak, S., Gani, A., & Anuar, N.B. GRAIN: Granular multi-label encrypted traffic classification using classifier chain, Computer Networks (Under Review)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}