Slides from my talk at Munich MLOps Community Meetup #7
Every second spent waiting for initializations and obscure delays hindering high-frequency logging, further limited by what you can track, an experiment dies. Wouldn't it be nice to start tracking in nearly zero time? What if we could track more and faster, even handling arbitrarily large, complex Python objects with ease?
In this talk, I will present the results of comparative benchmarks covering Weights & Biases, MLflow, FastTrackML, Neptune, Aim, Comet, and MLtraq. You will learn their strengths and weaknesses, what makes them slow and fast, and what sets MLtraq apart, making it 100x faster and capable of handling tens of thousands of experiments.
The talk will be inspiring and valuable for anyone interested in AI/ML experimentation and portable, safe serialization of Python objects.
![Michele Dallachiesa Data Products & AI Consulting [email protected] MLtraq: Track](https://files.speakerdeck.com/presentations/bb93b2be2b624e369c7c5e1229e03947/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
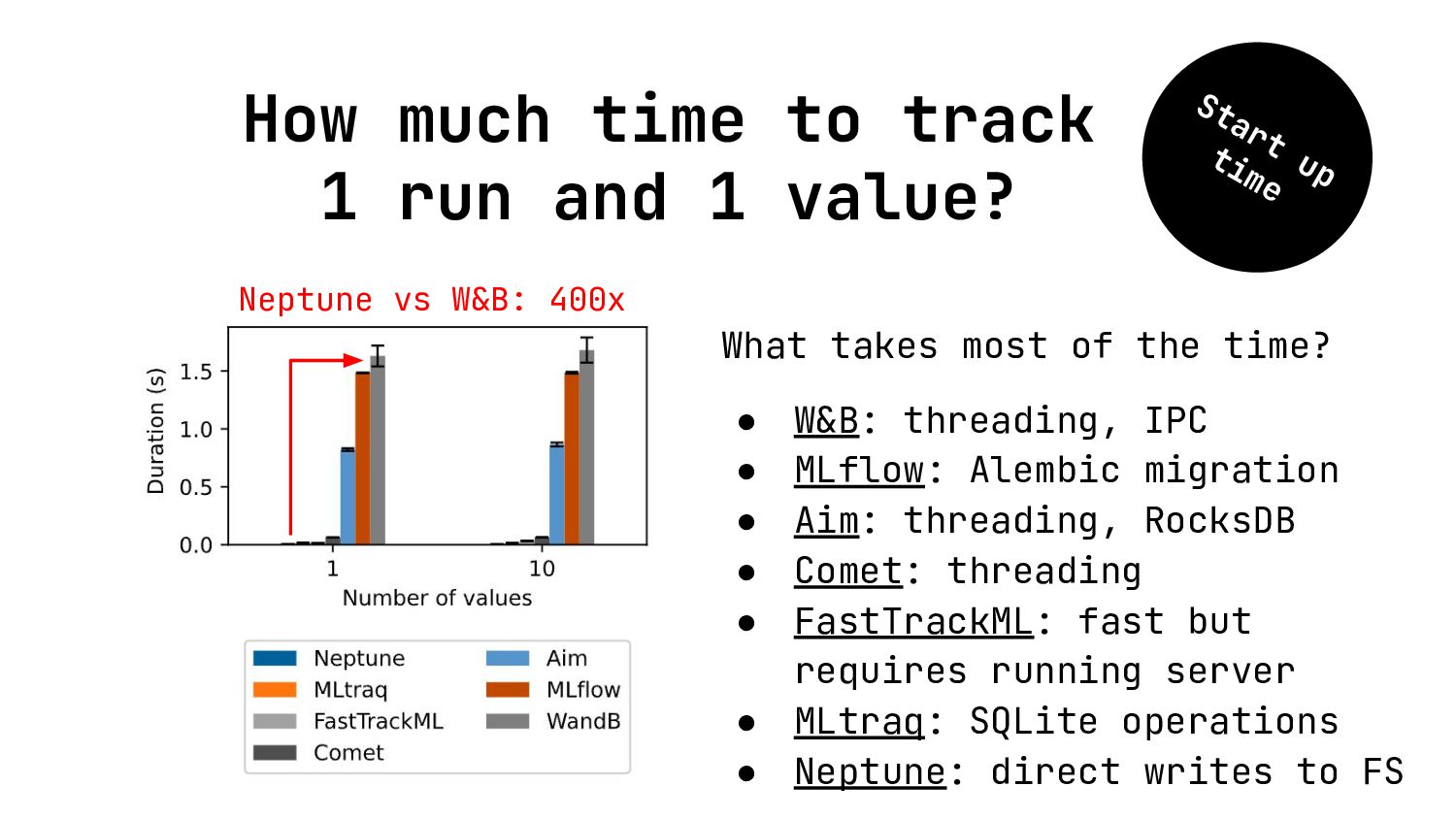{kind=link}
{kind=link}
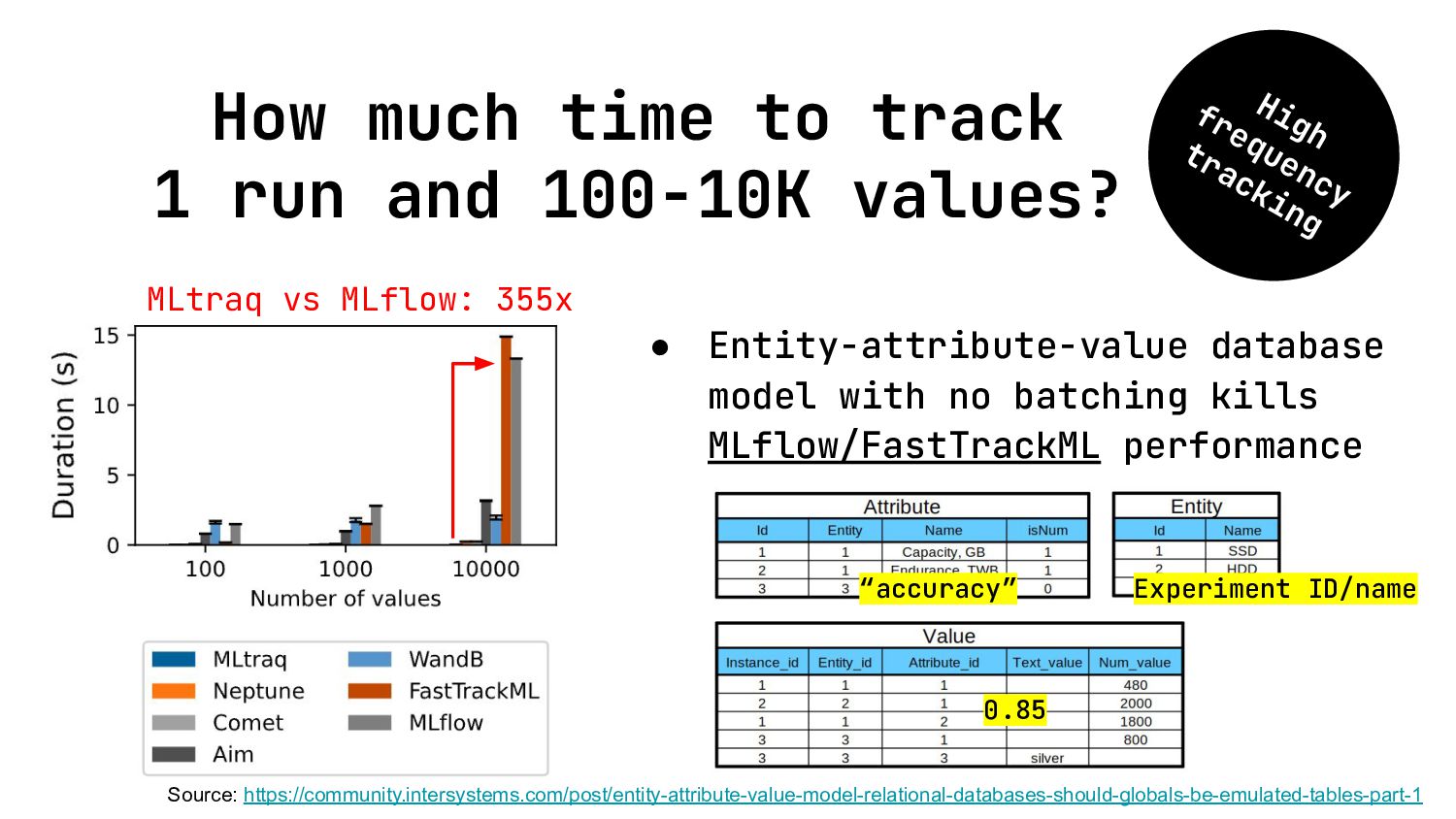{kind=link}
{kind=link}
{kind=link}
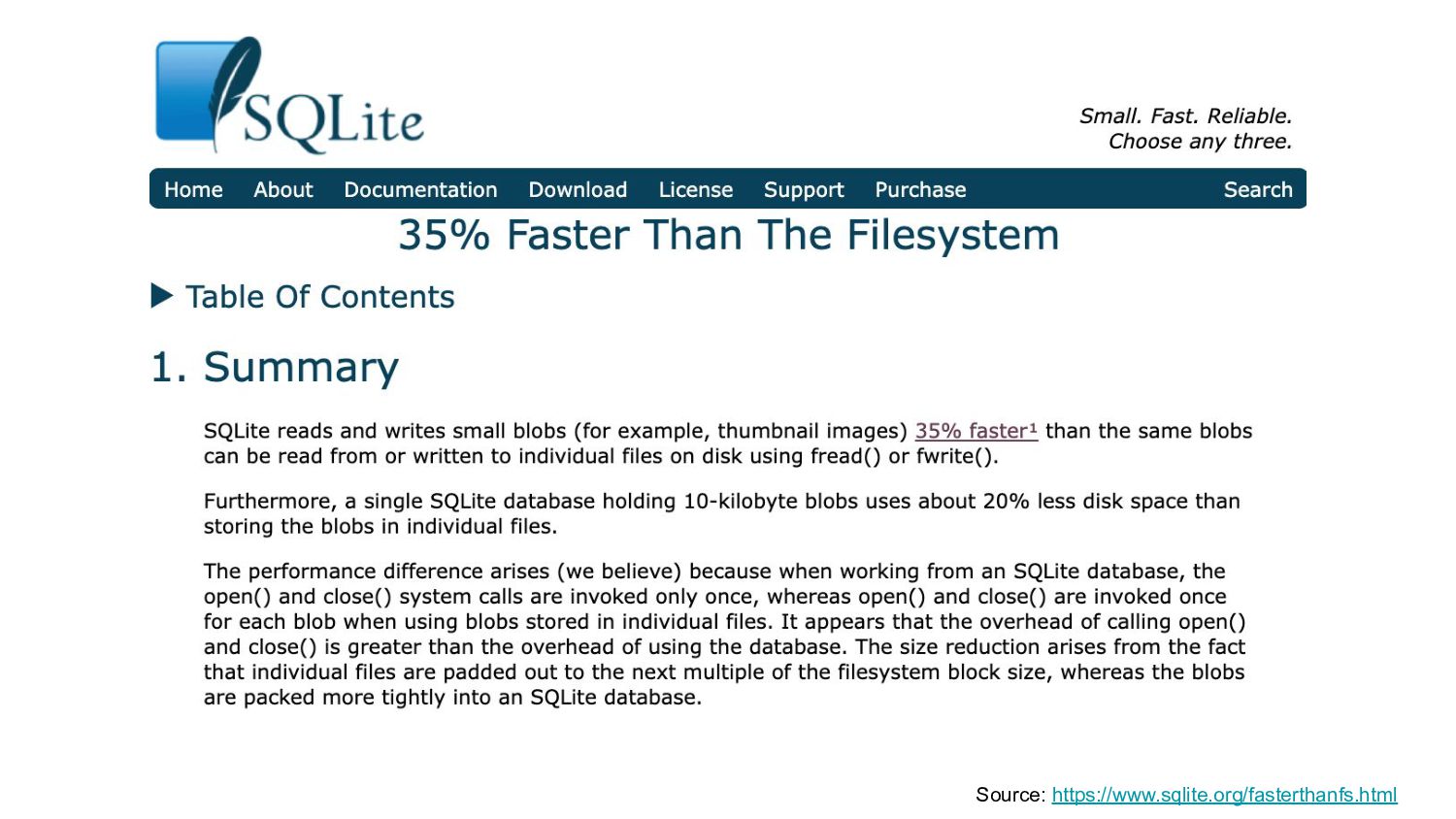{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! Michele Dallachiesa Data Products & AI Consulting [email protected]](https://files.speakerdeck.com/presentations/bb93b2be2b624e369c7c5e1229e03947/slide_22.jpg){kind=link}