Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[CV勉強会@関東 CVPR2025] VLM自動運転model S4-Driver
Search
Shin-kyoto
July 13, 2025
Research
840
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[CV勉強会@関東 CVPR2025] VLM自動運転model S4-Driver
7/13関東CV勉強会の資料です
Shin-kyoto
July 13, 2025
More Decks by Shin-kyoto
See All by Shin-kyoto
[CV勉強会@関東 世界モデル論文読み会] VLA自動運転model Alpamayo-R1
shinkyoto
0
610
[CV勉強会@関東 ICCV2025] WoTE: End-to-End Driving with Online Trajectory Evaluation via BEV World Model
shinkyoto
0
520
Other Decks in Research
See All in Research
Ankylosing Spondylitis
ankh2054
0
180
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
280
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
180
事後確率分布の共分散について
koide3
0
170
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
150
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
130
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
280
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
360
NLP colloquium: AI Safety Survey
kanekomasahiro
0
830
Featured
See All Featured
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
The agentic SEO stack - context over prompts
schlessera
0
840
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
180
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
The World Runs on Bad Software
bkeepers
PRO
72
12k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
44k
The Cult of Friendly URLs
andyhume
79
6.9k
Tell your own story through comics
letsgokoyo
1
990
Site-Speed That Sticks
csswizardry
13
1.2k
How STYLIGHT went responsive
nonsquared
100
6.2k
Transcript
S4-Driver Scalable Self-Supervised Driving Multimodal Large Language Model with Spatio-Temporal
Visual Representation project page: https://s4-driver.github.io/ arxiv: https://arxiv.org/abs/2505.24139 ※資料中 図表 断り ない限り上記論文から引用
自己紹介 Shin • 趣味で自動運転関連技術を追っています • 自動運転用VLM Planner 分野に興味があり, 自分なり 「こうすべきで
」という仮説作りが 最近 マイブームです ◦ こ 分野がど 程度有望そうな か?・自分 仮説 正しそうな か? を調べている状態です • 自動運転に興味 ある方 , 自動運転AIチャレンジが盛り上がっている で覗いてみてください! ◦ 初学者向け資料などもある で趣味でやりやすいかも? P.S. 「自動運転xVLMで汎化性能向上を目指す」研究で博士後期課程に進学したいと考えております.まだ 研究室選び 段階ですが,ご興味 ある研究者 方がいらっしゃったらぜひお声掛けください. Twitter: @AquaRobot0202
今日紹介する論文 概要 • VLMベース 自動運転Plannerを大規模データで自己教師あり学習 する手法を提案 ◦ VLMが2D表現 みで事前学習している点に目をつけ, BEVFormerやUniAD・VADなどで使われている”pull”型
3D表現学習をVLMへ導入 • Google傘下 Waymoから 論文です 論文中で , - 画像 - 自車両軌道 教師データ みで学習することを Self-supervisedと呼称
[背景] 自動運転xVLM: Edge caseにどう対処するか? • 自動運転におけるEdge case 人間 事前想定を超える ◦
しかし,レベル4以上 自動運転システムで ,運行設計領域外 事象でも Minimal Risk Maneuverによりリスクを最小限にしないといけない • Robot manipulation分野で ,VLM, VLAを使用した手法が汎化性能向上を実現 ◦ 自動運転でもVLMで汎化性能を向上できないか?と考える研究 多い ▲ Edge cases introduced in DriveVLM paper ▲ Edge case reported in autoware discussion
[背景] Vision Language Actionと ? • VLA: 画像・言語・行動を統合的に使うこ とで,汎化性能を手に入れようとする取 り組み
• Robot manipulation分野で ,OpenVLA, Physical Intelligence π0 が有名 https://arxiv.org/abs/2406.09246
[Robot manipulation分野で 例] OpenVLA: An Open-Source Vision-Language-Action Model • Input:
画像, 言語指示(Language Instruction) • Output: Robot action(7次元) • (1)画像・言語特徴量を (2)language embedding spaceにmapping(projector)し, (3)VLMで処理 https://arxiv.org/abs/2406.09246 Robot actionをどう扱っている か? • Robot 動作 0-255に離散化 • llamaに 100 ”special tokens”があり,fine tuning時に新しくtokenを導入可能 • 100で 足りない で,使用頻度 低い順に 256個 tokenを選んできて(least used)上書きする • next-token predictionとして学習
[Robot manipulation分野で 例] OpenVLA: 他 手法よりも汎化性能が高い 見たこと ない背景 見たこと ない
位置,角度 見たこと ない サイズ,形 見たこと ない 物体,指示, 概念 言語で指定された物体 manipulation 学習データ 分布内 タスク, 条件 学習データ 分布外 物体,タスク, 背景,概念 https://arxiv.org/abs/2406.09246 manipulation datasetに 含まれていない概念に対応 e.g.”Taylor Swiftへと缶を動かして”
自動運転xVLM: inputとoutput 例 VLM ※正確に言うと複数 パターンがあります - textに埋め込んでtrajectoryを出力(上記 例) -
float 数値でtrajectoryを出力 - trajectory tokenとしてtrajectoryを出力 Output: 自車 軌道(trajectory, waypoints) Input: 画像とText prompt camera images high-level command historical ego-vehicle states
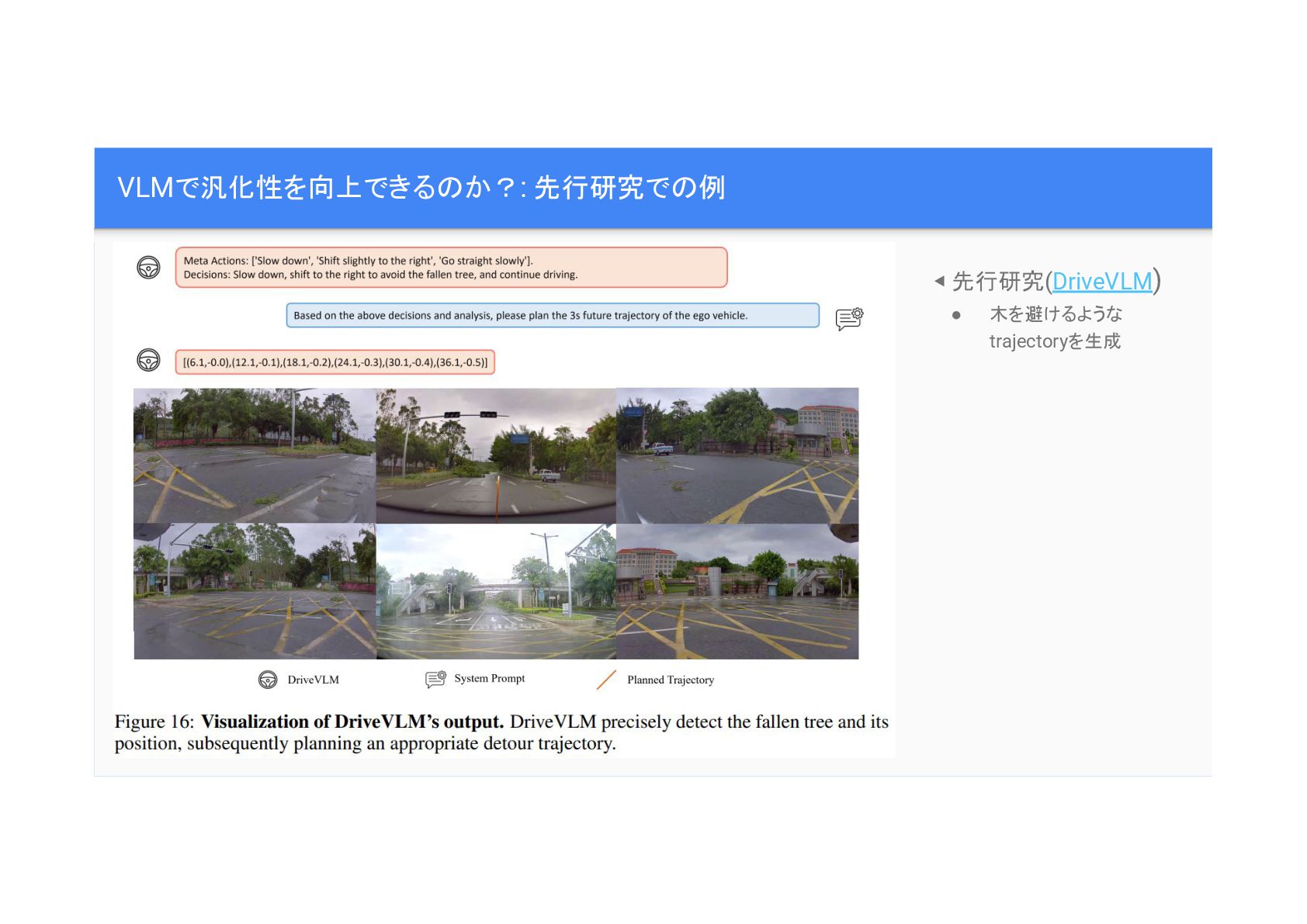
VLMで汎化性を向上できる か?: 先行研究で 例 ◀ 先行研究(DriveVLM) • 木を避けるような trajectoryを生成
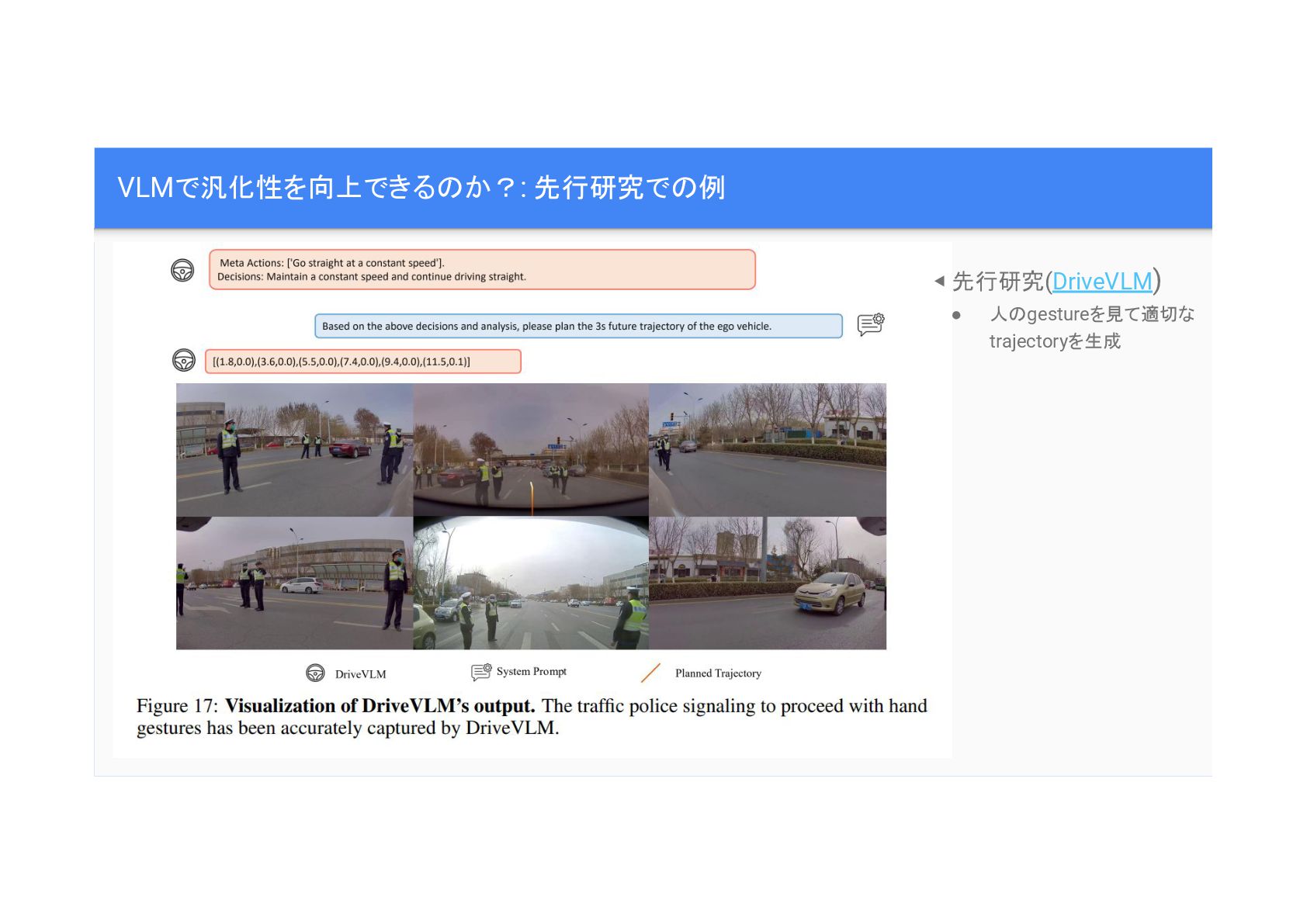
VLMで汎化性を向上できる か?: 先行研究で 例 ◀ 先行研究(DriveVLM) • 人 gestureを見て適切な trajectoryを生成
VLMで汎化性を向上できる か?: 先行研究で 例 ◀ 先行研究(DriveVLM) • 人 gestureを見て適切な trajectoryを生成
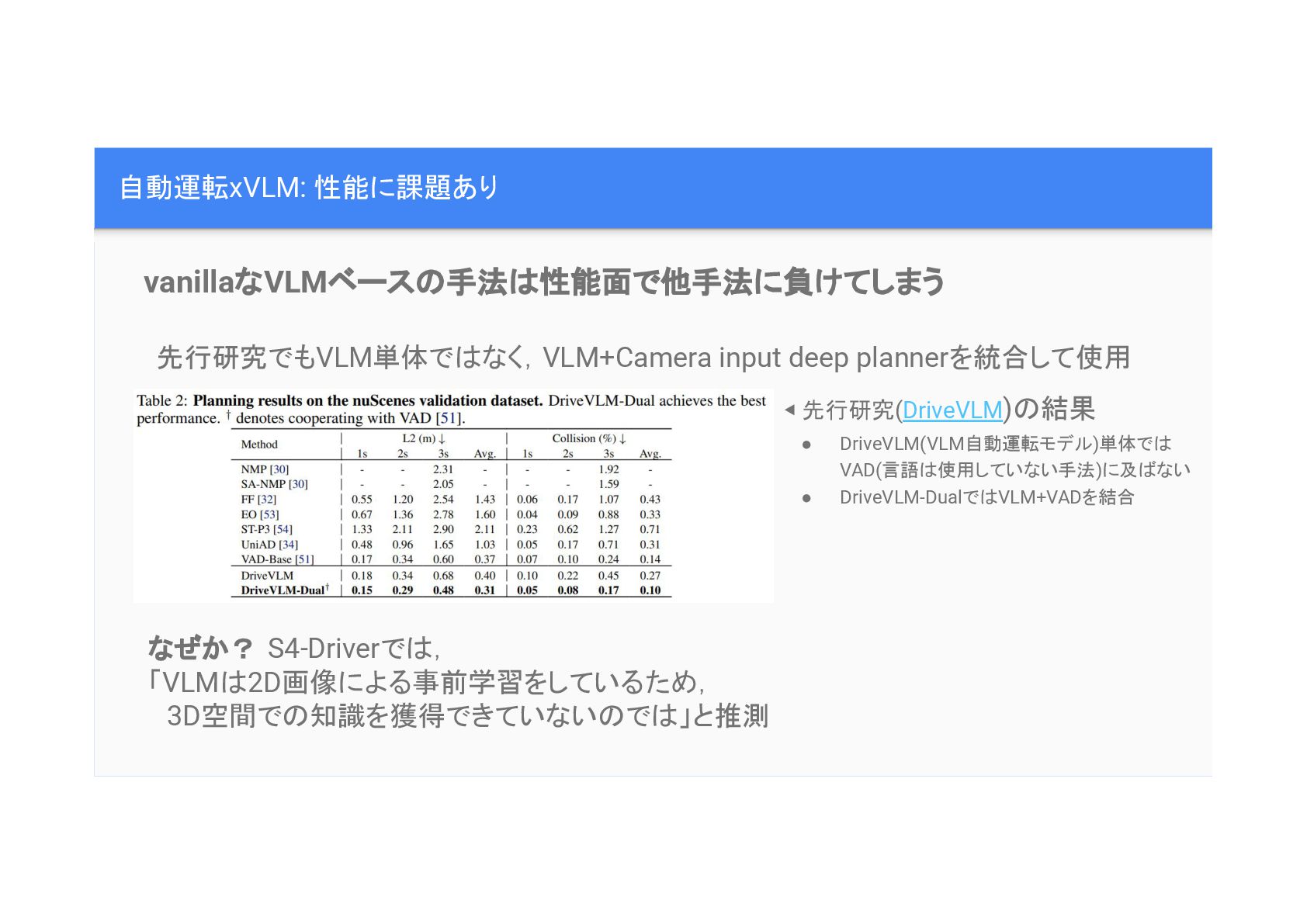
自動運転xVLM: 性能に課題あり ◀ 先行研究(DriveVLM) 結果 • DriveVLM(VLM自動運転モデル)単体で VAD(言語 使用していない手法)に及 ない
• DriveVLM-Dualで VLM+VADを結合 vanillaなVLMベース 手法 性能面で他手法に負けてしまう 先行研究でもVLM単体で なく,VLM+Camera input deep plannerを統合して使用 なぜか? S4-Driverで , 「VLM 2D画像による事前学習をしているため, 3D空間で 知識を獲得できていない で 」と推測
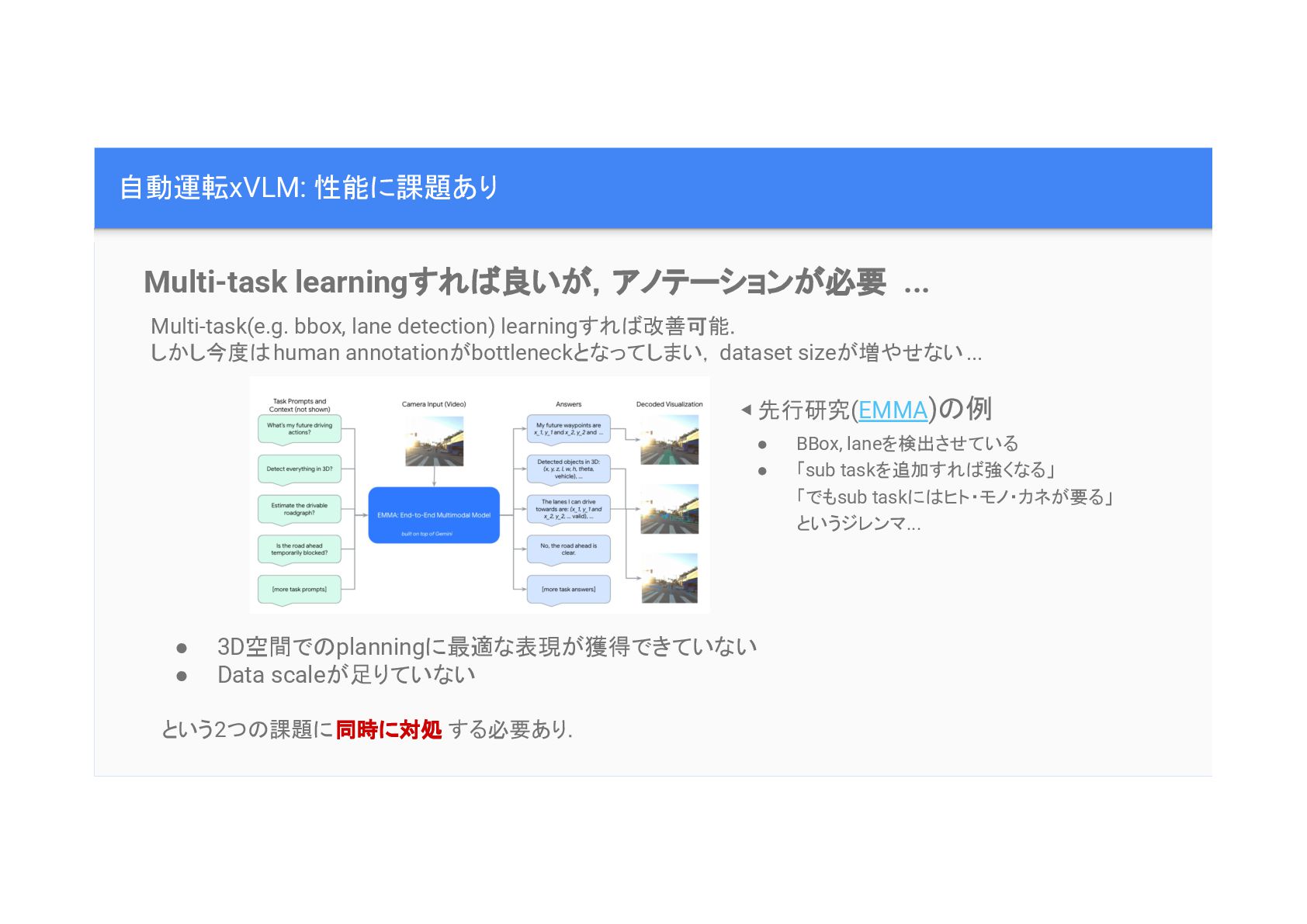
自動運転xVLM: 性能に課題あり Multi-task learningすれ 良いが,アノテーションが必要 ... • 三次元 情報を抽出できていない •
データ量が不足している Multi-task(e.g. bbox, lane detection) learningすれ 改善可能. しかし今度 human annotationがbottleneckとなってしまい,dataset sizeが増やせない... • 3D空間で planningに最適な表現が獲得できていない • Data scaleが足りていない という2つ 課題に同時に対処 する必要あり. ◀ 先行研究(EMMA) 例 • BBox, laneを検出させている • 「sub taskを追加すれ 強くなる」 「でもsub taskに ヒト・モノ・カネが要る」 というジレンマ...
S4-Driver: “pull”型 3D空間で 表現学習 x 巨大なデータセットで 自己教師あり学習 • 三次元 情報を抽出できていない
• データ量が不足している S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Model with Spatio-Temporal Visual Representation • 3D空間で 表現 : Sparse volume representationで対処 ◦ BEVFormerやUniAD・VADなどで使われている”pull”型 3D表現学習をVLMへ導入 • データ量: Self-supervised learningで学習することで対処 ※S4-Driverで ,画像・過去 trajectory・将来 trajectory GT みを使用して学習することを Self-Supervisedと呼称しています ▲Sparse volume representationにより三次元情報を抽出 ▲ 574時間も 巨大なデータセットを構築
[個人的な感想] 自動運転xVLM: 性能に課題あり ◀ 先行研究(DriveVLM) 結果 • DriveVLM(VLM自動運転モデル)単体で VAD(言語 使用していない手法)に及
ない • DriveVLM-Dualで VLM+VADを結合 vanillaなVLMベース 手法 性能面で他手法に負けてしまう • 三次元 情報を抽出できていない • データ量が不足している Multi-task(e.g. bbox, lane detection) learningで改善する. しかし今後 human annotationがbottleneckとなってしまい,dataset sizeが増やせない... そこで以下 2つ 課題に同時に対処する手法を提案 : S4-Driver • 3D空間で planningに最適な表現が獲得できていない • Data scaleが足りていない 個人的な感想 • Open loopな評価だけで判断できる か? • Edge case 対応がVLM 強みな で ?と思うが, Edge case 入ったデータセットで 対応可能性評価ができていない
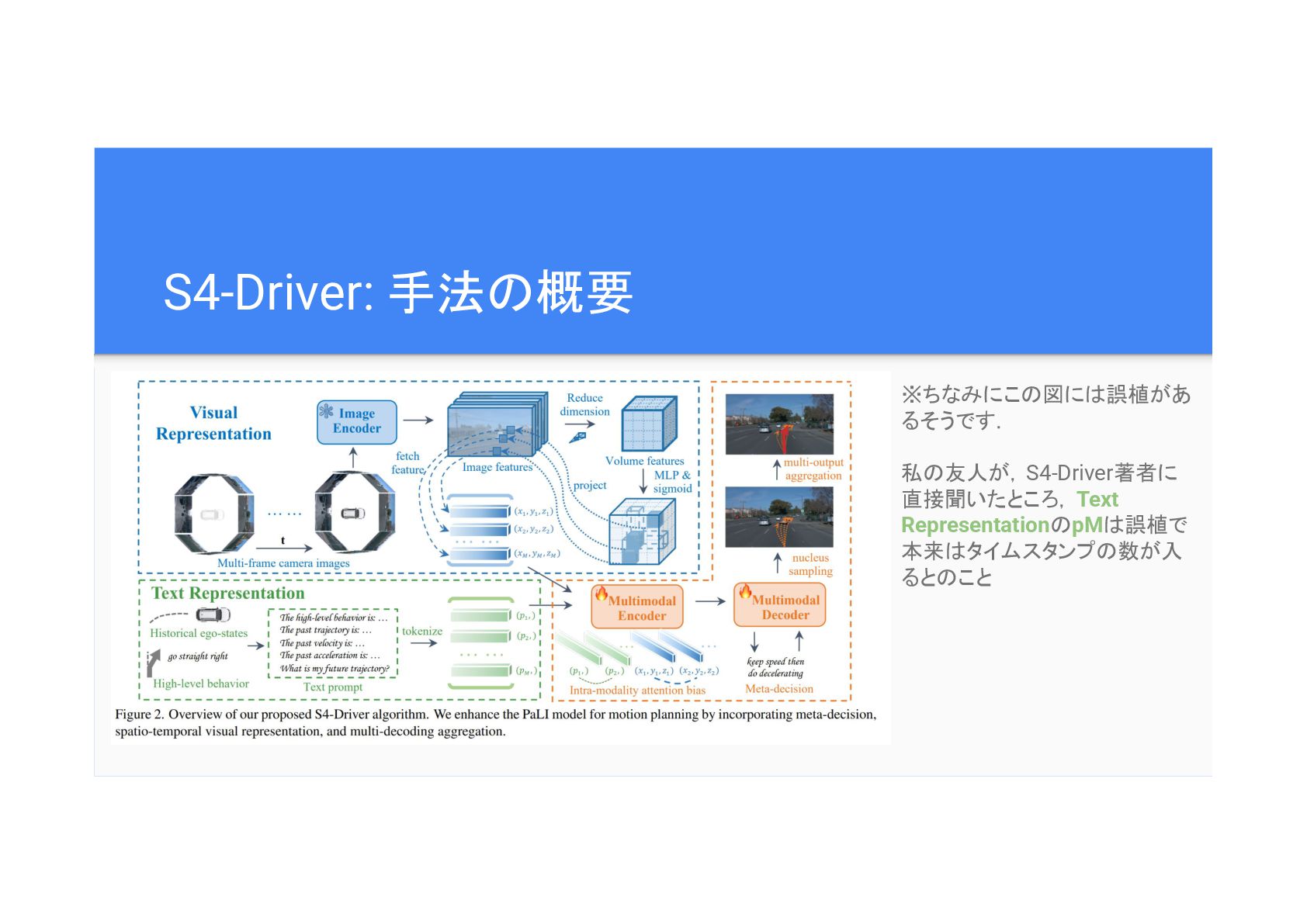
S4-Driver: 手法 概要 ※ちなみにこ 図に 誤植があ るそうです. 私 友人が,S4-Driver著者に 直接聞いたところ,Text
Representation pM 誤植で 本来 タイムスタンプ 数が入 ると こと
S4-Driver: 手法 概要 全体 流れ ①複数フレーム・複数視点 画像を3D表現に変換 ②行動指示(high level command),
過去 軌道を含むtextをtokenize ③Intra-modality(画像同士・text同士) token attention bias追加 ④MLLMに画像とtext tokenを入力し,trajectoryを出力
2D特徴量 抽出 • ViT-G (2B) vision encoderを 使用して各画像 特徴量を 抽出
• 複数時刻における複数視点 画像を使用
2D -> 3D projection • 3D空間 点を2D画像上 点に変換 • 対応点周辺
画像特徴量を をbilinear samplingし,3D 空間 各点 特徴量とする
背景: 2D -> 3D projection: push型とpull型 SimpleBEV, BEVFormer: 3Dから2Dへ “pull”
LSS: 2Dから3Dへ “push” • 2D画像からdepth推定し,BEV特徴量を取得 • depth情報を使って2D画像を3D特徴量に変換 ◦ 2D+depthで3Dへ”押し出す” Simple-BEV: What Really Matters for Multi-Sensor BEV Perception? • 3D volume 中心点を,座標変換行列を使って2D 画像に投影.対応する2D画像特徴量を取得 ◦ 2D特徴量を”引っ張ってきて ” 3D特徴量とする
背景: 2D -> 3D projection: pull型 例: BEVFormer BEVFormer Spatical
Cross Attentionについて , 以下 2つ 資料が大変わかりやすい で参照お願いします! • [CV勉強会@関東 CVPR2023] 自動運転におけるBEVベース物体認識技術 進化 Turing Inc, 棚橋 耕太郎さん • 第27回 画像 認識・理解シンポジウム MIRU2024 自動運転 ため ビジョン技術 デンソーITラボラトリ/東京工業 大学 佐藤 育郎さん BEVFormer で BEV Queryと Spatial Cross Attentionで対応 (deformable attention使用) BEVFormer S4-Driver 評価でbaselineとして用いられている UniADやVAD backboneでも使用 https://arxiv.org/abs/2203.17270 https://arxiv.org/abs/2212.10156
2D -> 3D projection: pull型 方法を採用 Simple-BEV: What Really Matters
for Multi-Sensor BEV Perception? • voxel 座標(x,y,z)を各視点v 画像に投影 • 対応する2D座標(uv, vv)取得 • (uv, vv)周辺 特徴量をbilinear samplingする • voxel 特徴量 ,全視点から local semantic feature 平均とする ▲ 3D座標を2Dに投影し, 投影先 2D特徴量を sampleして平均する 3次元特徴量が抽出できた!-> だが,3次元空間 volume すかすか.もったいない...
voxel 剪定: gate • 3D空間 ほぼすかすか ◦ 無駄なvoxelが多い • planningに有用なdenseなvoxel
だけを選択 • denseかどうかを判定する特徴 量を作成 ◦ gateと呼 れる0~1 値
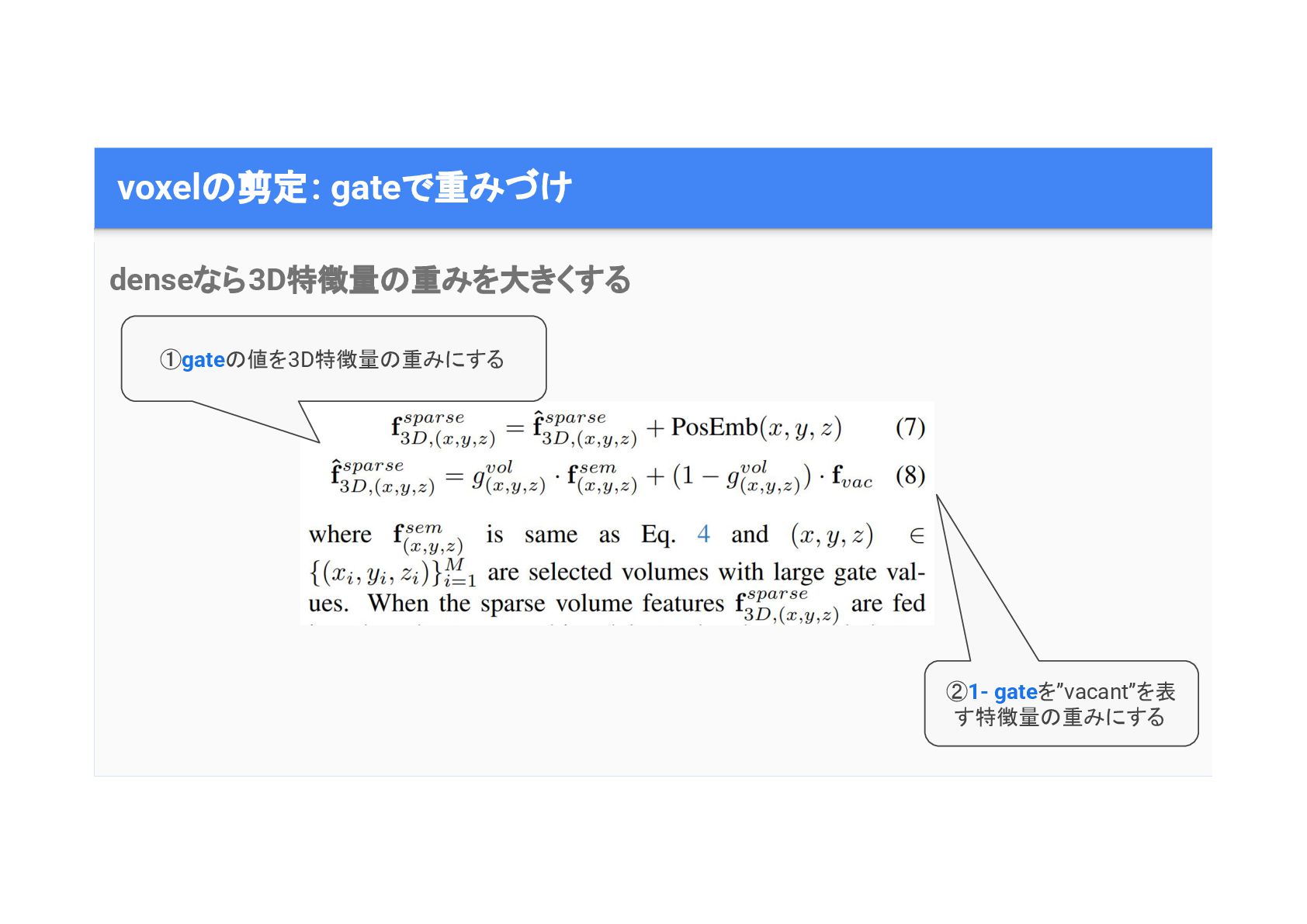
voxel 剪定: gate • 3D空間内 全voxelから,denseなvoxelをM個だけ選 びたい • 2D特徴量から,gate(0~1)という特徴量を得て, そ
値 大小でdensityを判定 3D空間内 ほとんど sparse denseな場所だけ 特徴量を抽出したい motion planningで 道路から離れた物体 詳細な 情報(e.g. 建物や木) 必要ない • gate(0~1)値が小さいvolume ,「empty」もしく 「planningに関係ない」とみなす • gate(0~1)値が小さいvolume 「vacantである」という 情報を表す特徴量 重みを大きくする
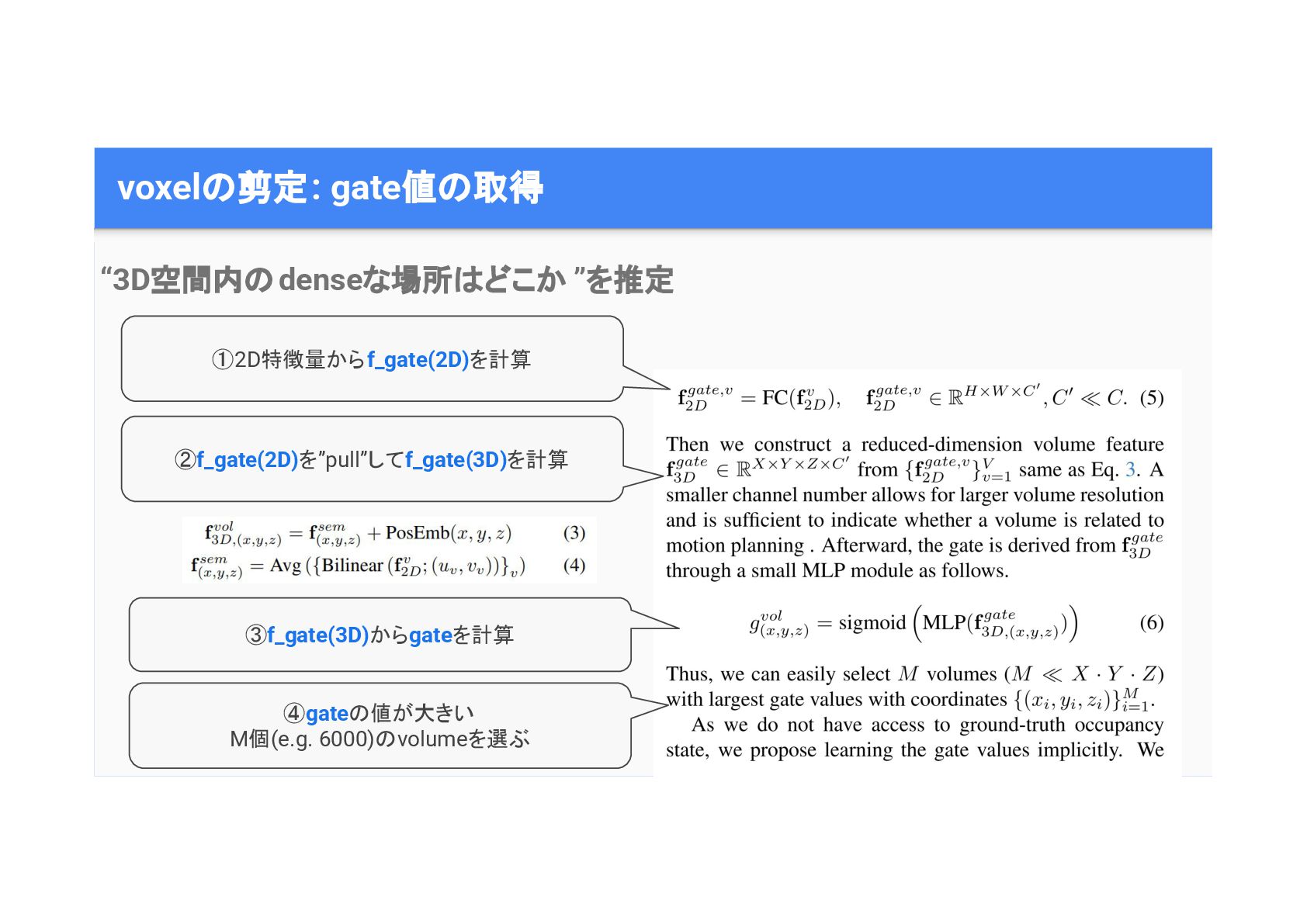
voxel 剪定: gate値 取得 “3D空間内 denseな場所 どこか ”を推定 ①2D特徴量からf_gate(2D)を計算 ②f_gate(2D)を”pull”してf_gate(3D)を計算
③f_gate(3D)からgateを計算 ④gate 値が大きい M個(e.g. 6000) volumeを選ぶ
voxel 剪定: gateで重みづけ denseなら3D特徴量 重みを大きくする ①gate 値を3D特徴量 重みにする ②1- gateを”vacant”を表
す特徴量 重みにする
Visual Representation: 全体 流れ gate • 各frameごとにf_gate(3D)を計算 • concatして処理して,各voxelご と
gate値に変換 特徴量 • 各frameごとに,3D座標を2D空間に投影し,samplingして3D特徴量を計算.gate値 を基にM個選択する • concatして処理して,各voxelごと 3D特徴量に変換
• 行動指示(high level command), 過去 軌道を含むText Prompt を作成 • tokenizeする
Text Representation: 全体 流れ ※ちなみにこ 図に 誤植があるそうです 私 友人が,S4-Driver著者に直接聞いたとこ ろ,Text Representation pM 誤植で 本来 タイムスタンプ 数が入ると こと
Text Representation: Input Prompt 自車両中心 座標系で推論 high-level behavior commandで行動を指示 過去
trajectory, velocity, accelerationを渡す ◀ 6種類 “stop” 信号機 情 報などがleakする可 能性がある で使用 しない
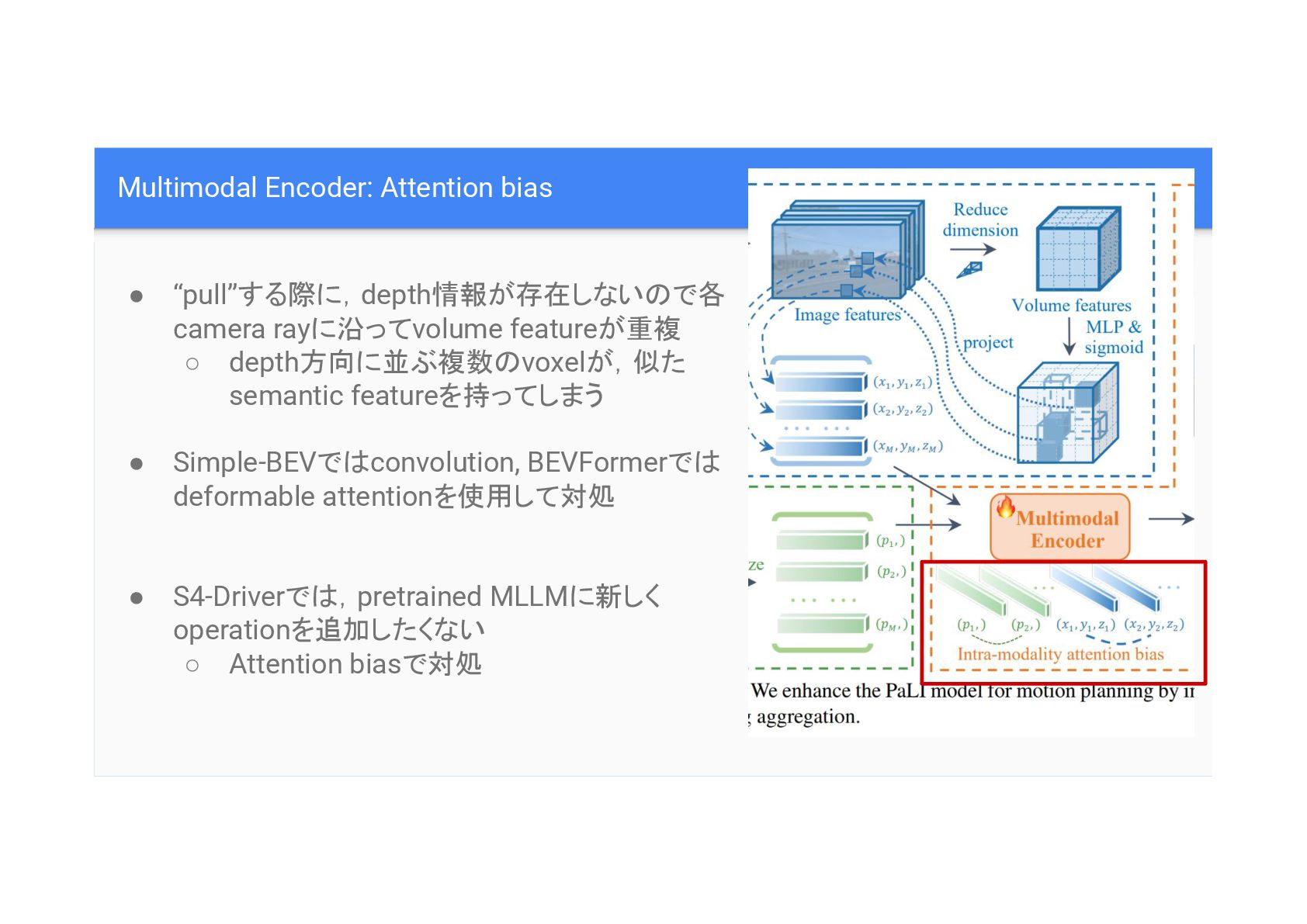
Multimodal Encoder: Attention bias • Multimodal Encoderで画像・textを処理 • S4-Driverで ,MLLM
pretrained encoder に,あまり変更を加えず,token同士 繋がり 情報を含めたい • Intra-modality(画像同士・text同士) token Self-attentionにattention bias追加
Multimodal Encoder: Attention bias • “pull”する際に,depth情報が存在しない で各 camera rayに沿ってvolume featureが重複
◦ depth方向に並ぶ複数 voxelが,似た semantic featureを持ってしまう • Simple-BEVで convolution, BEVFormerで deformable attentionを使用して対処 • S4-Driverで ,pretrained MLLMに新しく operationを追加したくない ◦ Attention biasで対処
画像特徴量 M個 volume同士 Self-attentionを計算 M個 volumeとM個 volume 距離 D [M,M,3]
を作成しQKからb(D)を引く. 距離が近いほどattention weightが大きく, 遠いほどattention weightが小さくなる b(D) = bx(Δx) + by(Δy) + bz(Δz) Multimodal Encoder: Attention bias
depth情報が不足しているため、式 3また 7 lifting処理 で 、各camera rayに沿ってvolume featureが重複してし まいます。こ 空間的な曖昧さ
、畳み込み [20, Simple-BEV] やdeformable attention[31, BEVFormer] ような3D local operationによって軽減できます。しか し、我々 MLLMフレームワークで 、追加 局所演算を 挿入すること economicalで ありません。代わりに、既 存 multimodal encoderにrelative positon biasを組み 込むことで、Self-attentionを調整(tailoring)します。
Attention bias: b() どんな関数? Δを32個 binに分割.近距離 物体に対して高解像度 mx() ,bin から
learnable bias mapping関数 bin-wise biasがある方がADE下がる -128 128 8 -8 0 8 bins 8 bins 16 bins
S4-Driver: 手法 概要 ※こ 図に 誤植があるそうです. 私 友人が,S4-Driver著者に直接聞いたところ,Text Representation pM
誤植で 本来 タイムスタンプ 数が入ると こと ①複数フレーム・複数視点 画像を3D表現に変換 Multimodal Encoder ③Intra-modality (画像同士・text同士) token Self-attention に attention bias追加 ②行動指示 (high level command), 過去 軌道を含むtextを tokenize
CoT: Meta-decision • 2段階 推論を実施 • 1段階目で ,Meta-decisionを推論 ◦ 加速状態:
keep stationary, keep speed, accelerate, decelerate • 2段階目で trajectoriesを推論
trajectory生成: nucleus sampling and aggregation • 簡単な行動に高いconfidenceを割当てがち • nucleus sampling(top-p
sampling, p=0.9)して 16本 trajectoriesを生成し, 16本をaggregationする • 詳細 記載なし: 以下 自分 理解 ◦ 「nucleus samplingして生成」* 16回 ◦ 16本を平均する
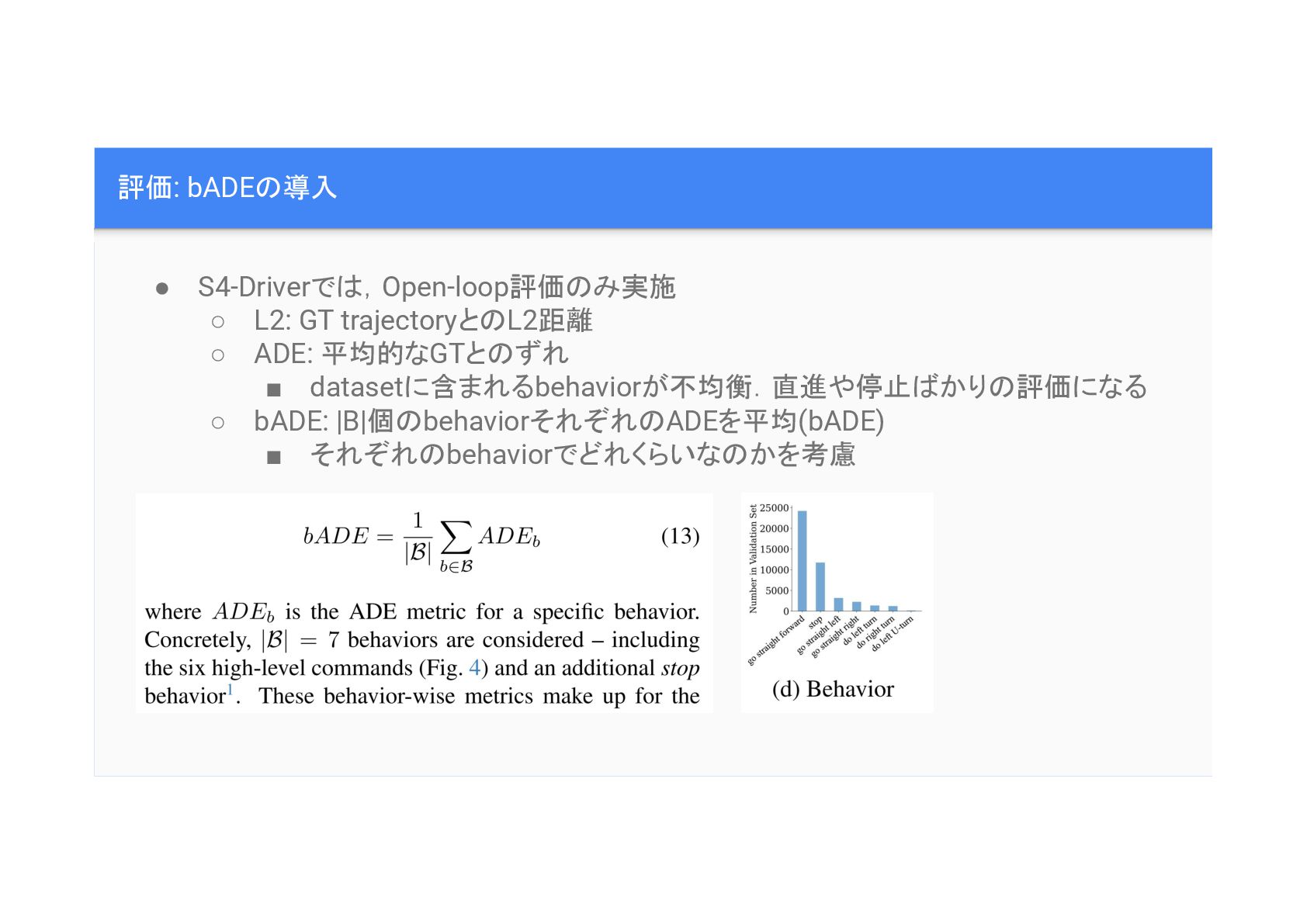
評価: bADE 導入 • Planning 評価 難しい.様々な評価方法,様々な指標がある. • S4-Driverで ,Open-loop評価
み実施. • 加えて,behaviorそれぞれにおけるADE 平均(bADE)を評価指標として提案
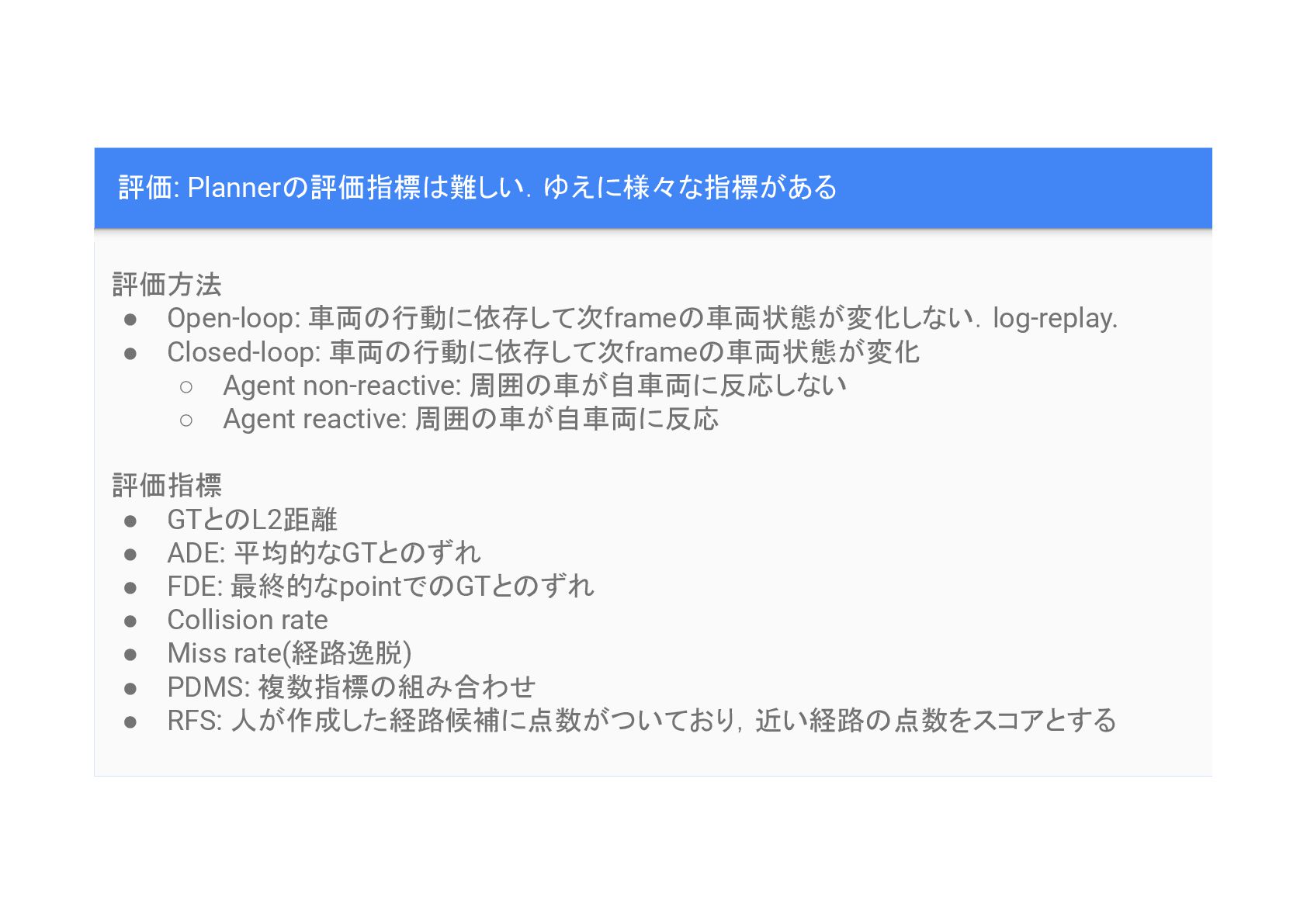
評価: Planner 評価指標 難しい.ゆえに様々な指標がある 評価方法 • Open-loop: 車両 行動に依存して次frame 車両状態が変化しない.log-replay.
• Closed-loop: 車両 行動に依存して次frame 車両状態が変化 ◦ Agent non-reactive: 周囲 車が自車両に反応しない ◦ Agent reactive: 周囲 車が自車両に反応 評価指標 • GTと L2距離 • ADE: 平均的なGTと ずれ • FDE: 最終的なpointで GTと ずれ • Collision rate • Miss rate(経路逸脱) • PDMS: 複数指標 組み合わせ • RFS: 人が作成した経路候補に点数がついており,近い経路 点数をスコアとする
評価: bADE 導入 • S4-Driverで ,Open-loop評価 み実施 ◦ L2: GT
trajectoryと L2距離 ◦ ADE: 平均的なGTと ずれ ▪ datasetに含まれるbehaviorが不均衡.直進や停止 かり 評価になる ◦ bADE: |B|個 behaviorそれぞれ ADEを平均(bADE) ▪ それぞれ behaviorでどれくらいな かを考慮
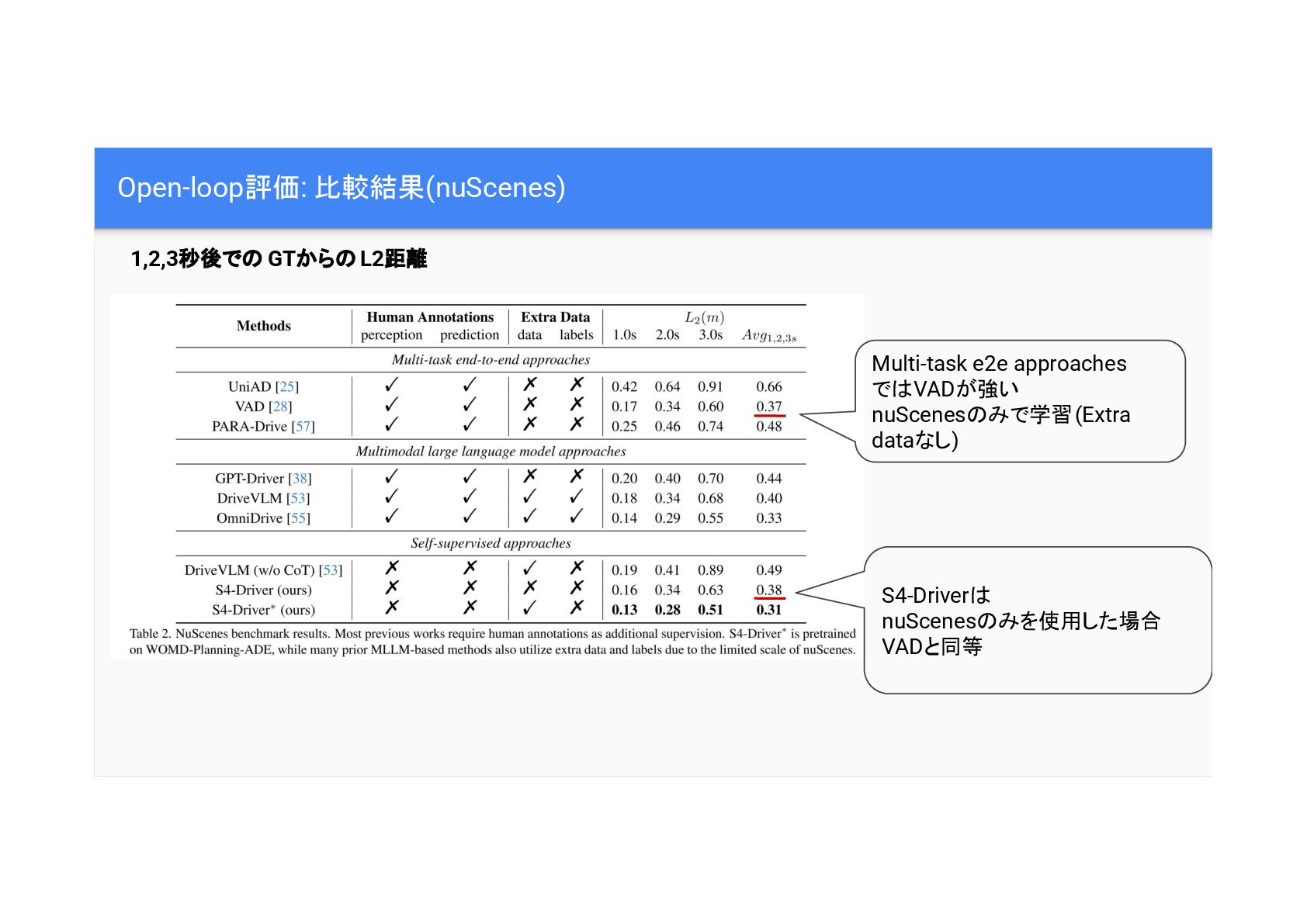
Open-loop評価: 比較結果(nuScenes) Multi-task e2e approaches で VADが強い nuScenes みで学習(Extra dataなし)
1,2,3秒後で GTから L2距離 S4-Driver nuScenes みを使用した場合 VADと同等
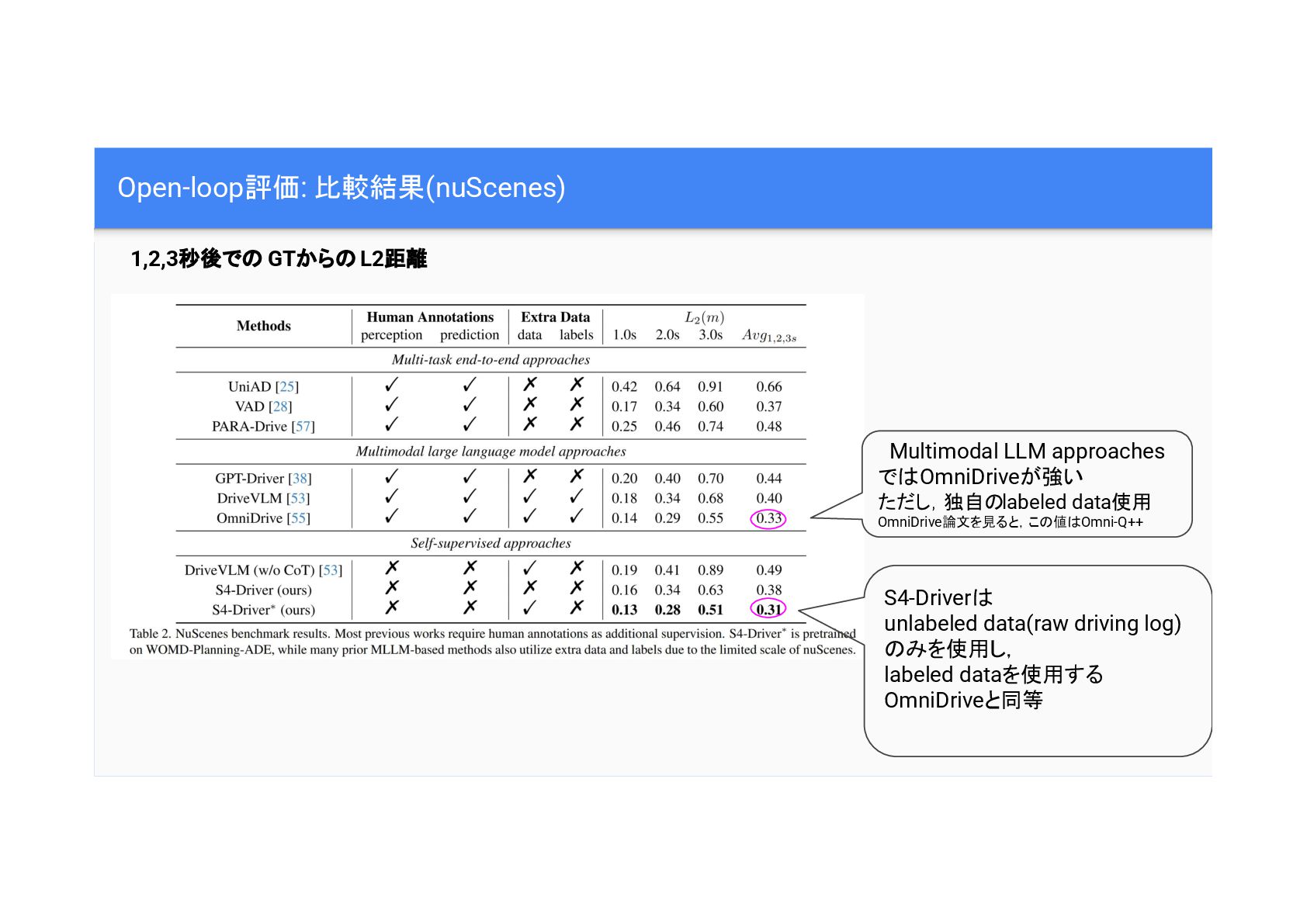
Open-loop評価: 比較結果(nuScenes) Multimodal LLM approaches で OmniDriveが強い ただし,独自 labeled data使用
OmniDrive論文を見ると,こ 値 Omni-Q++ 1,2,3秒後で GTから L2距離 S4-Driver unlabeled data(raw driving log) みを使用し, labeled dataを使用する OmniDriveと同等
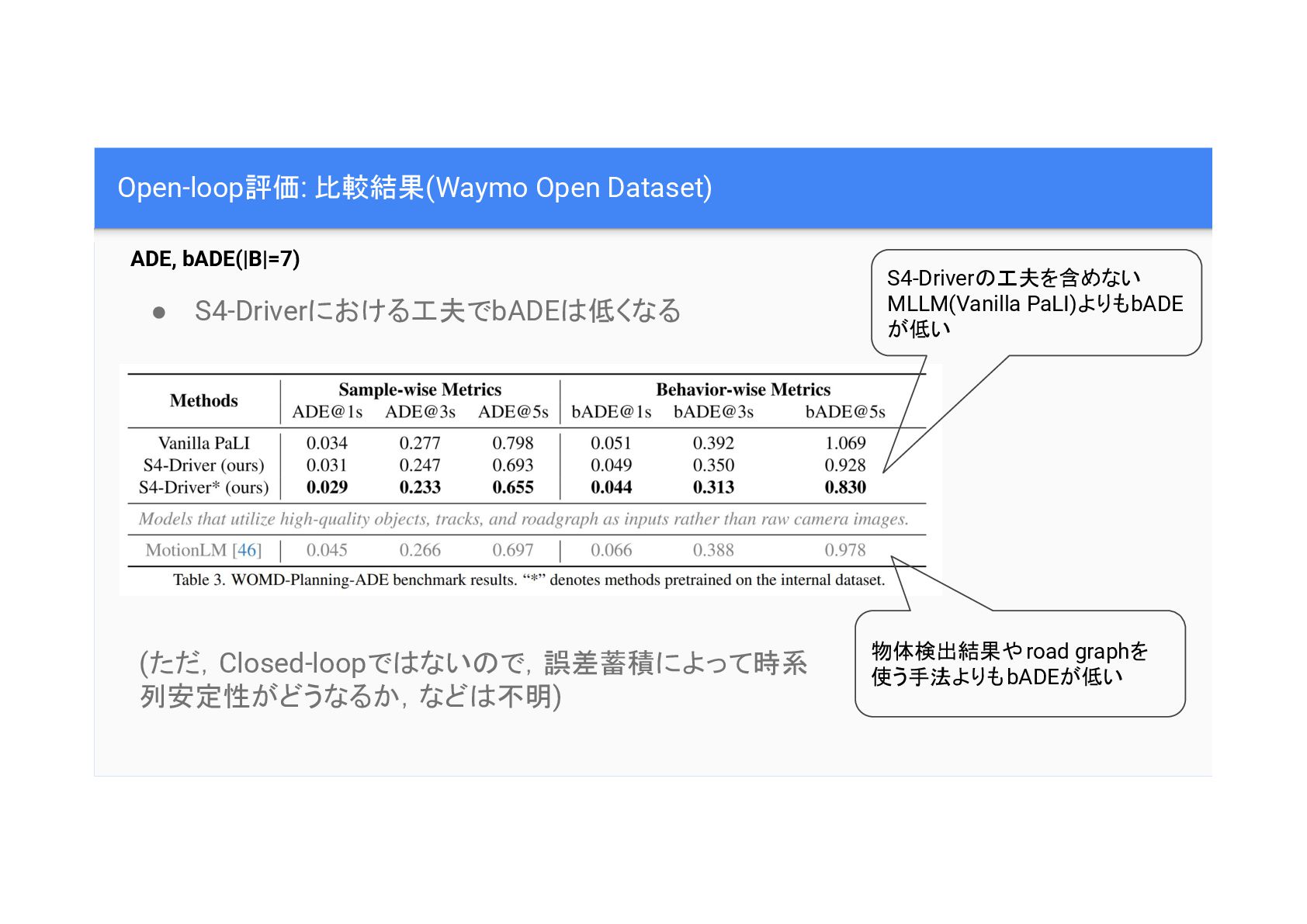
Open-loop評価: 比較結果(Waymo Open Dataset) ADE, bADE(|B|=7) S4-Driver 工夫を含めない MLLM(Vanilla PaLI)よりもbADE
が低い 物体検出結果やroad graphを 使う手法よりもbADEが低い • S4-Driverにおける工夫でbADE 低くなる (ただ,Closed-loopで ない で,誤差蓄積によって時系 列安定性がどうなるか,など 不明)
Open-loop評価: 定性評価 • 左折・直進・U-turnな ど 実行できている ようだ • generalizationが 強み
ずだが, 可視化 一般的な シーン み. ど 程度 edge caseに対応できる か 不明
結論 • S4-Driver ◦ Human annotationを使用せず,スケールする形でVLM系自動運転Planner 性能を 引き出す手法を提案 • 所感
◦ Raw driving data(+heuristic)だけでここまでやれるという かなり有望 ▪ (VLMな でまず offline plannerか階層planner向けだと考えられるが) ◦ 巨大なデータがなけれ 難しいアプローチであることも確か • 気になるポイント ◦ 汎化性能 高さがどれくらい他 手法(OmniDrive, DriveVLM, VAD, UniAD)より 優れている かが気になる ◦ 時系列安定性 どうか? ◦ Open-loop評価 みが実施されているが,Closed-loop評価だとどうなるか? ◦ Appendix motion trajectory tokenization評価も有益.最終的にどれが残るか?
参考資料 論文 • S4-Driver: https://arxiv.org/abs/2505.24139 • BEVFormer: https://arxiv.org/abs/2203.17270 • Simple-BEV:
https://arxiv.org/abs/2206.07959 • UniAD: https://arxiv.org/abs/2212.10156 • VAD: https://arxiv.org/abs/2303.12077 • Senna: https://arxiv.org/abs/2410.22313 • DriveVLM: https://arxiv.org/abs/2402.12289 • EMMA: https://arxiv.org/abs/2410.23262 • OmniDrive: https://arxiv.org/abs/2405.01533 資料 • [CV勉強会@関東 CVPR2023] 自動運転におけるBEVベース物体認識技術 進化 Turing Inc, 棚橋 耕太郎さん • 第27回 画像 認識・理解シンポジウム MIRU2024 自動運転 ため ビジョン技術 デンソーITラボラトリ/東京工業大 学 佐藤 育郎さん • autoware discussion: The interface between Perception and Planning lacks sufficient information
{kind=link}
{kind=link}
{kind=link}
![[背景] 自動運転xVLM: Edge caseにどう対処するか? • 自動運転におけるEdge case 人間 事前想定を超える ◦](https://files.speakerdeck.com/presentations/91d90eb390d9480a9b585adcd7fb41e9/slide_3.jpg){kind=link}
![[背景] Vision Language Actionと ? • VLA: 画像・言語・行動を統合的に使うこ とで,汎化性能を手に入れようとする取 り組み](https://files.speakerdeck.com/presentations/91d90eb390d9480a9b585adcd7fb41e9/slide_4.jpg){kind=link}
![[Robot manipulation分野で 例] OpenVLA: An Open-Source Vision-Language-Action Model • Input:](https://files.speakerdeck.com/presentations/91d90eb390d9480a9b585adcd7fb41e9/slide_5.jpg){kind=link}
![[Robot manipulation分野で 例] OpenVLA: 他 手法よりも汎化性能が高い 見たこと ない背景 見たこと ない](https://files.speakerdeck.com/presentations/91d90eb390d9480a9b585adcd7fb41e9/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[個人的な感想] 自動運転xVLM: 性能に課題あり ◀ 先行研究(DriveVLM) 結果 • DriveVLM(VLM自動運転モデル)単体で VAD(言語 使用していない手法)に及](https://files.speakerdeck.com/presentations/91d90eb390d9480a9b585adcd7fb41e9/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![画像特徴量 M個 volume同士 Self-attentionを計算 M個 volumeとM個 volume 距離 D [M,M,3]](https://files.speakerdeck.com/presentations/91d90eb390d9480a9b585adcd7fb41e9/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}