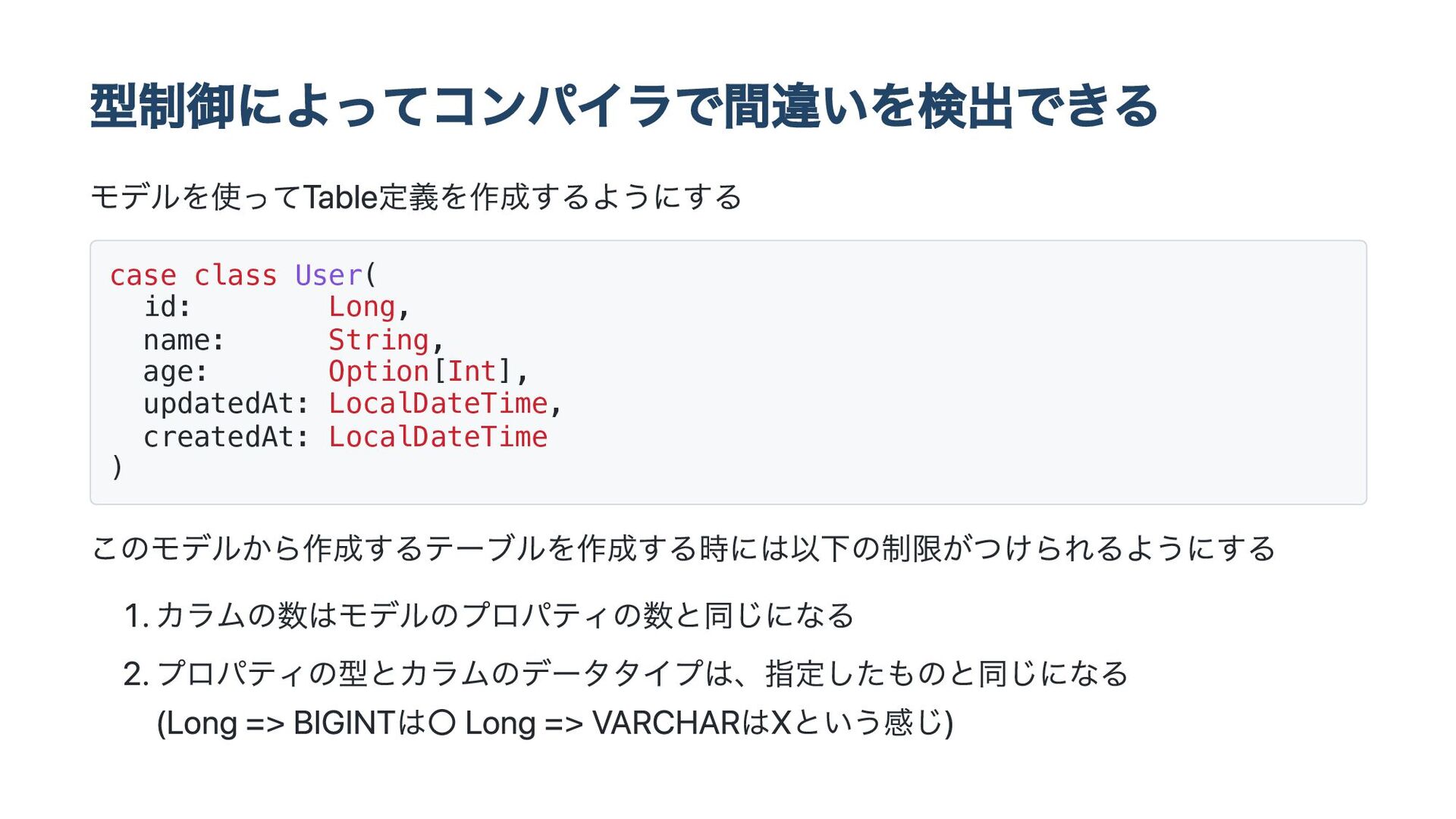
val x = single("hello world") // val x: String = hello world val x = single[String]("hello world") // エラー val x = single["hello world"]("hello world") // ok val x = single[Singleton & String]("hello world") // ok
): ... import scala.compiletime.ops.int.S object Tuples: type IndexOf[T <: Tuple, E] <: Int = T match case E *: _ => 0 case _ *: es => S[IndexOf[es, E]]
override lazy val shaped: ShapedValue[T, TableQuery.Extract[T]] = ShapedValue(table, RepShape[FlatShapeLevel, T, TableQuery.Extract[T]]) override lazy val toNode = shaped.toNode object TableQuery: type Extract[T] = T match case Table[t] => t def apply[T <: Table[?]](table: T): TableQuery[T] = new TableQuery[T](table)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![カラム定義 カラムには型パラメーターを持たせる データタイプや属性はこの型パラメーターと同じにものを受け取るようにしておく trait Column[T]: /** Column Field Name */](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_10.jpg){kind=link}
{kind=link}
![テーブル Tuple Tuple.Mapなどでタプルの各メンバの型 T を F[T] に変換する Mirror モデルとタプルの相互変換を行う Dynamic](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
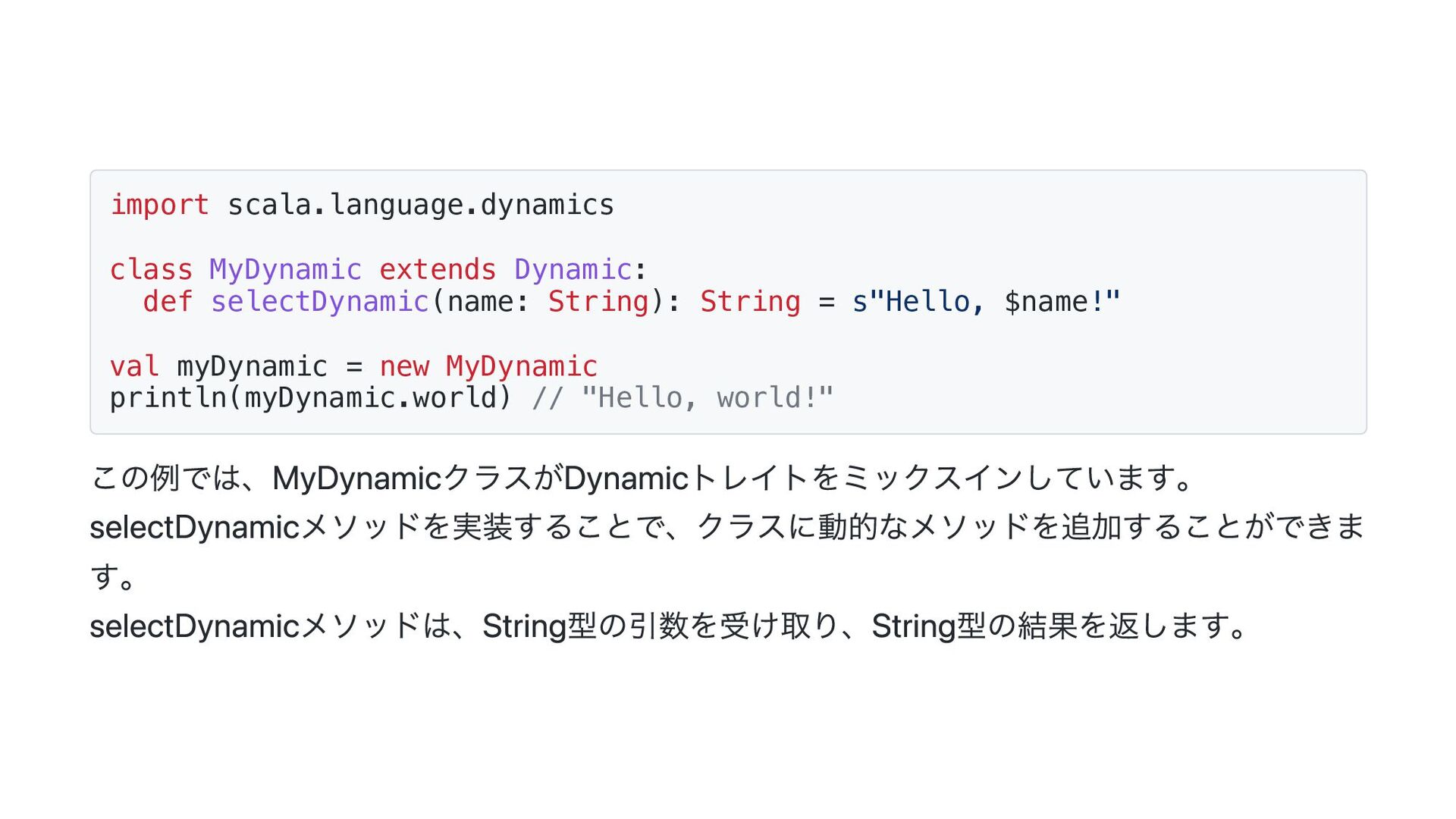
![テーブル テーブルはselectDynamicでフィールド名でカラム情報にアクセスできるようにしておきます private[ldbc] trait Table[P <: Product] extends Dynamic: ...](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_15.jpg){kind=link}
: Tag = x](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_16.jpg){kind=link}
( ... index: ValueOf[Tuples.IndexOf[mirror.MirroredElemLabels, Tag]]](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_17.jpg){kind=link}
![Tableを継承したモデルを定義しておく 引数のcolumnsは、Tuple.Mapを使用して型パラメーターのTupleをColumn型で受け取るよ うにしている (Long, String)というTupleの型が渡された場合に渡せる引数の型は、(Column[Long], Column[String])というTuple型になる object Table extends Dynamic:](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_18.jpg){kind=link}
(using](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_19.jpg){kind=link}
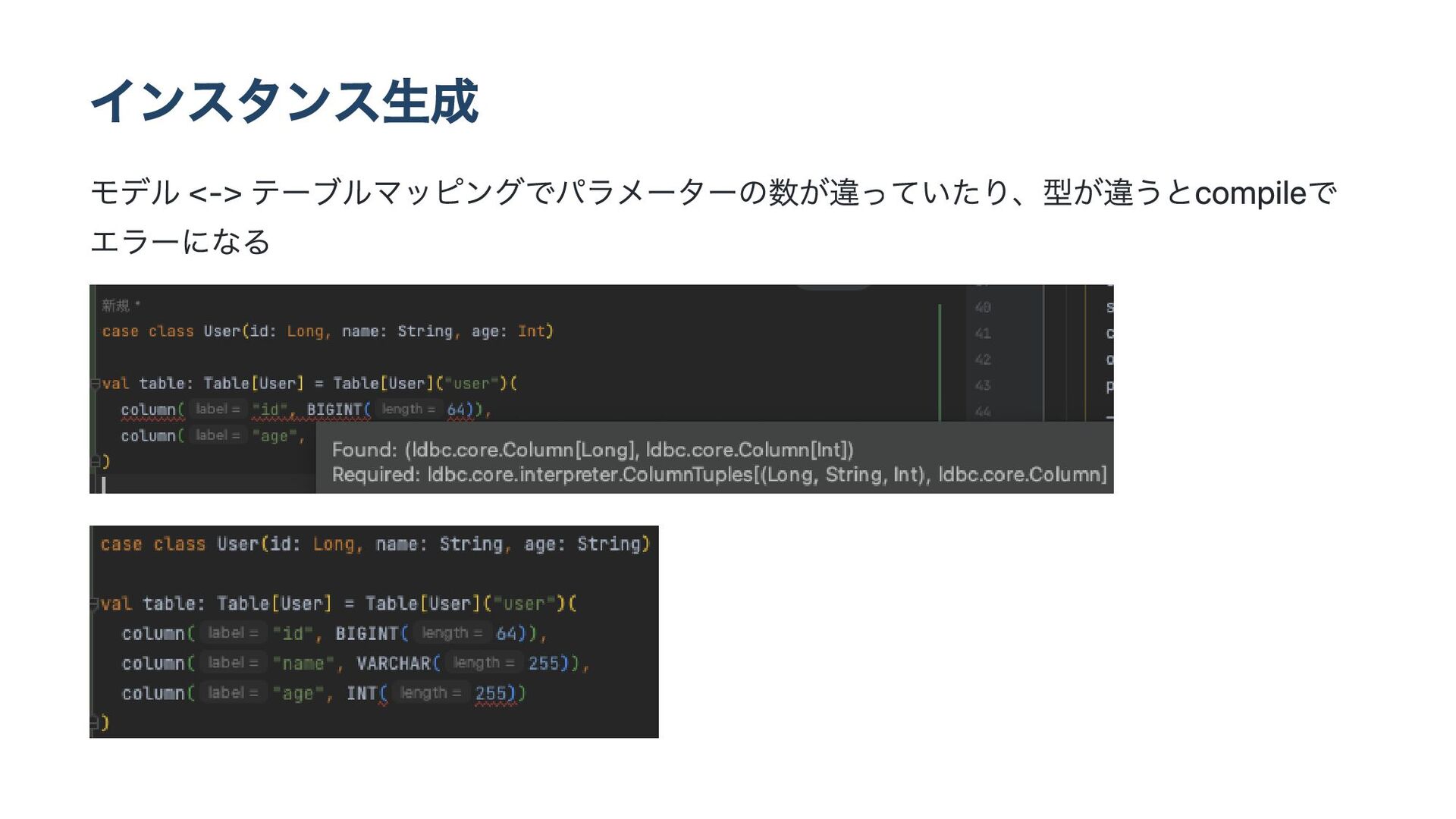
![インスタンス生成 val table: Table[User] = Table[User]("user")( column("id", BIGINT(64), AUTO_INCREMENT, PRIMARY_KEY),](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
( column(“id”, BIGINT(64), AUTO_INCREMENT, PRIMARY_KEY), column(“name”,](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
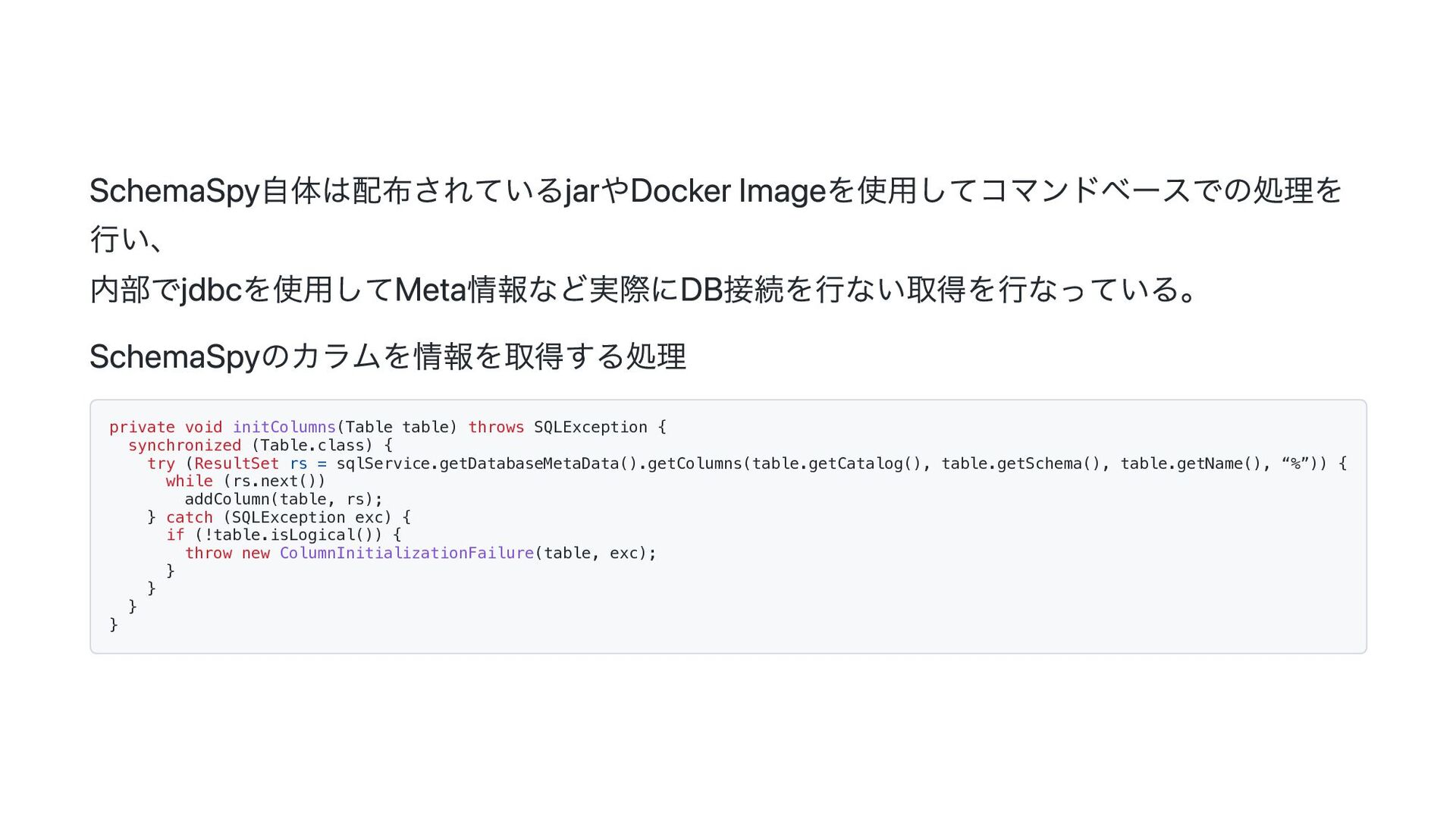
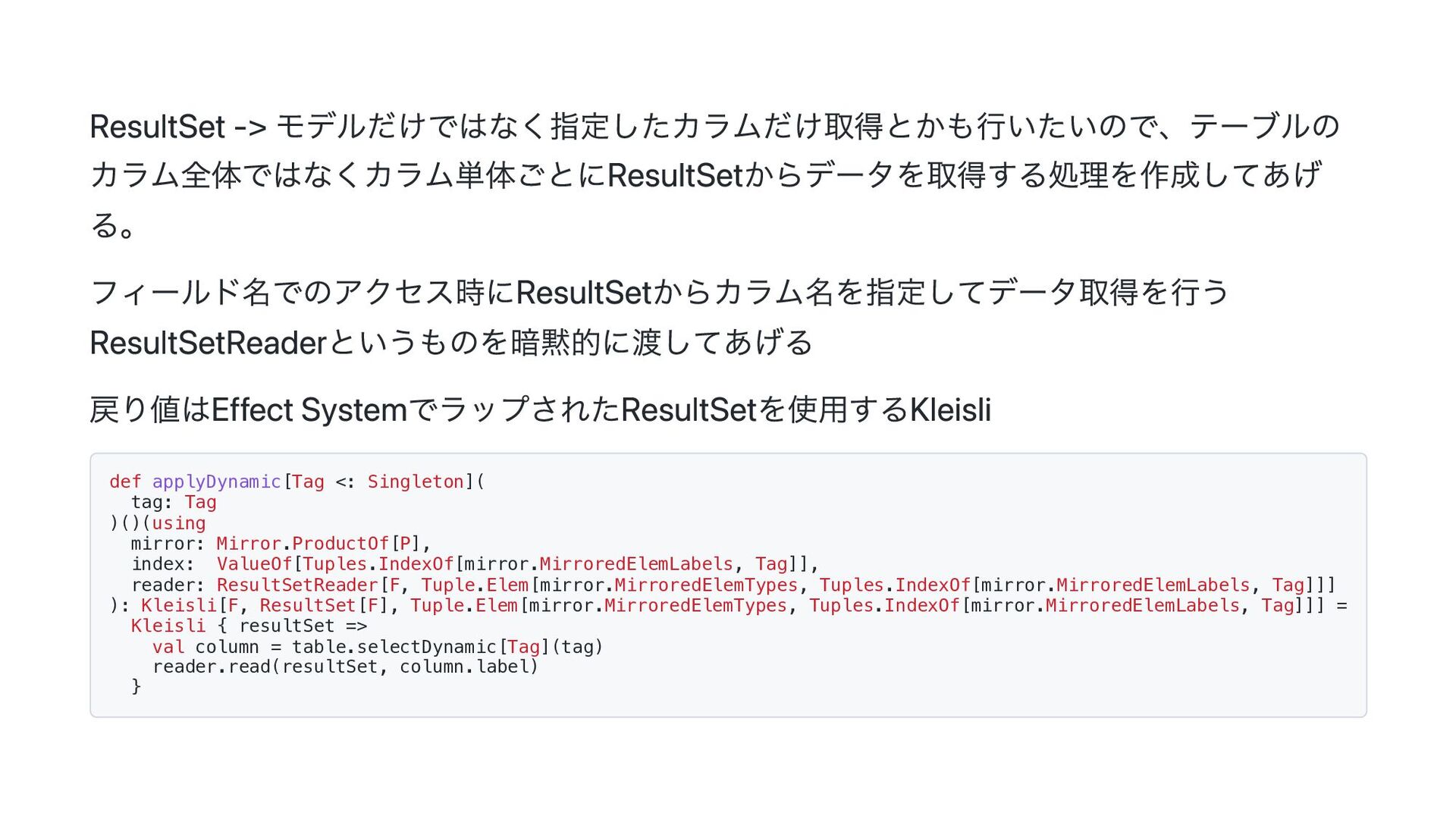
![ResultSetReaderはこんなやつ。 ResultSetからカラム名を指定して取得を行う処理を記載しておく、このとき取得する型はパ ラメーターによって決められるようにしておく。 trait ResultSetReader[F[_], T]: def read(resultSet: ResultSet[F], columnLabel:](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_41.jpg){kind=link}
![あとはScala標準の型とかは予め定義しておき暗黙的に渡せるようにしておく。 定義されていない型が必要になったら、同じように定義してあげれば良い。 given [F[_]]: ResultSetReader[F, String] = ResultSetReader(_.getString) given [F[_]]:](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_42.jpg){kind=link}
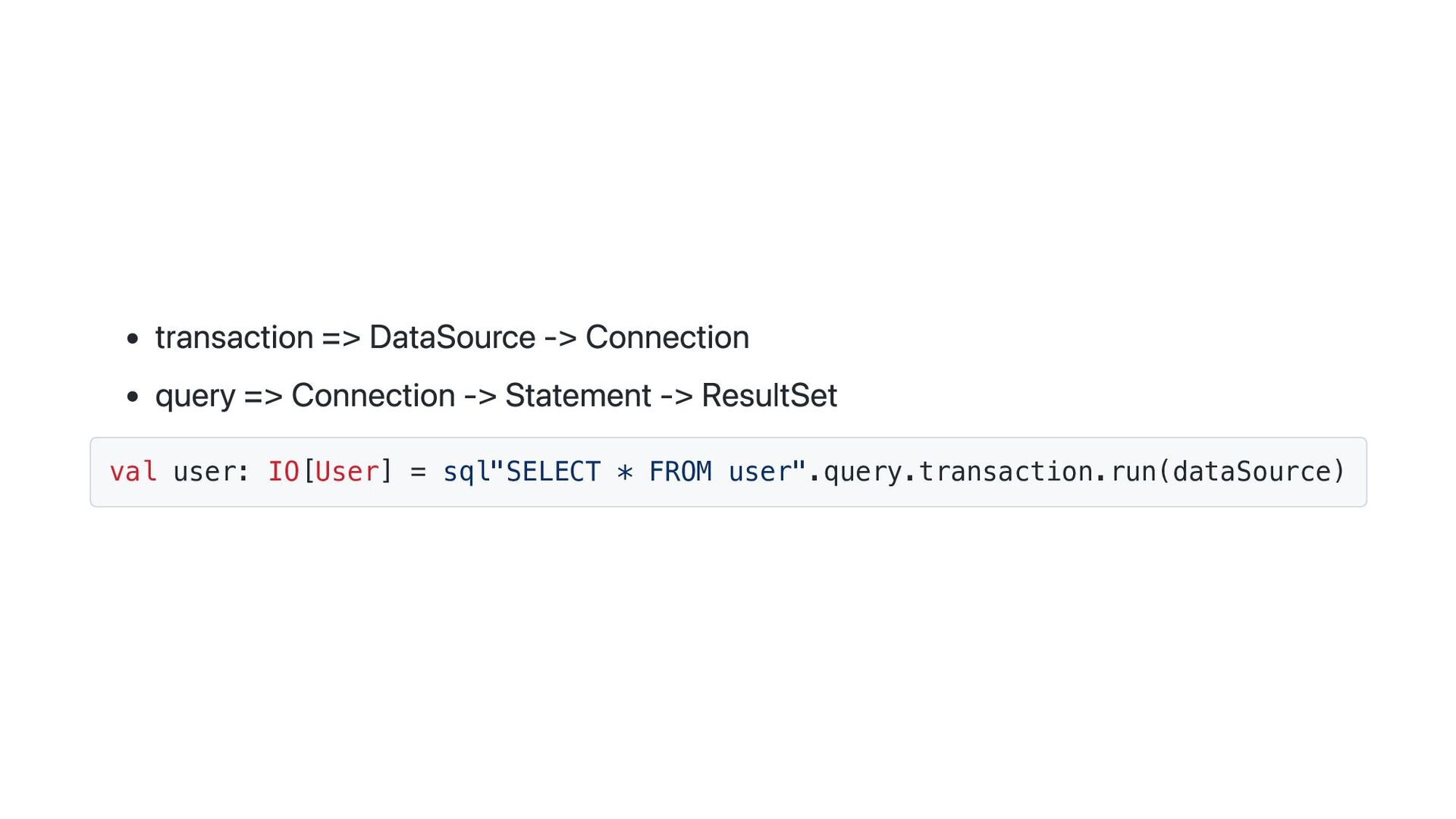
![あとはResultSet -> Userへの変換を行うKleisliを定義してあげる given Kleisli[IO, ResultSet[IO], User] = for id](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
: def id](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_46.jpg){kind=link}
![DB接続はTableQueryとDatabaseを使用して行われる。 val tableQuery = TableQuery[UserTable] val db = Database.forDataSource(...) db.run(tableQuery.filter(_.name](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_47.jpg){kind=link}
![Slickでは、RepとTypedType[T]というものが存在しています。 まず、RepはSlickがデータベーステーブルの列を表現するために使用する型です。Rep型は値 を保持するためのものではなく、データベーステーブルの列に対応するSQL文を生成するた めに使用されます。 val id: Rep[Int] = column[Int]("id") val](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_48.jpg){kind=link}
![次に、TypedType[T]は、Slickがカラムの型を表現するために使用する型です。Slickは、基本 的な型(Int、String、Booleanなど)に加えて、自動生成されたユーザー定義の型や、さまざ まなデータベースシステムでサポートされる型をサポートしています。TypedType[T]は、 Slickがデータベースからデータを読み取るときに使用する型を指定するために使用されま す。 val id: Rep[Int] = column[Int]("id")(summon[TypedType[Int]])](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_49.jpg){kind=link}
{kind=link}
![Slickのテーブル定義の * を分解すると暗黙に変換が行われていることがわかります。 ShapedValueは、Scalaの型とデータベーステーブルの列の値のタプルを表すものです。 val shapedValue: ShapedValue[ (Rep[Option[Long]], Rep[String], Rep[Option[Int]]),](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_51.jpg){kind=link}
{kind=link}
![TupleShapeは、複数のShapeを結合して、タプルのShapeを表現するためのShapeです。 TupleShapeでまずはカラムのリストからShapeのタプルを生成します。 val tupleShape = new TupleShape[ FlatShapeLevel, Tuple.Map[mirror.MirroredElemTypes, RepColumnType],](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_53.jpg){kind=link}
![ここで型をColumn[T]からRep[T]にしてあげる必要があるので、Scala3で追加された型マッ チを使用してColumnが持つTの型を抽出してあげます。 type Extract[T] = T match case Column[t] =>](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_54.jpg){kind=link}
![次にカラムのTupleからRepのTupleを生成する 単純に詰め替えを行う val repColumns: Tuple.Map[mirror.MirroredElemTypes, RepColumnType] = Tuple .fromArray( columns.productIterator](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_55.jpg){kind=link}
![生成されたShapedValueとMirror、Tupleを使用してモデル <-> タプルの変換を定義してあげ る。 val shapedValue = new ShapedValue[Tuple.Map[mirror.MirroredElemTypes, RepColumnType],](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_56.jpg){kind=link}
![自作したテーブル用のTableQueryを作成 class TableQuery[T <: Table[?]](table: T) extends Query[T, TableQuery.Extract[T], Seq]:](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_57.jpg){kind=link}
![Slickで実行する準備ができたので、テーブル定義を自作したものに置き換える val table: Table[User] = Table[User]("user")( column("id", BIGINT(64), AUTO_INCREMENT, PRIMARY_KEY),](https://files.speakerdeck.com/presentations/b7a5d41aa4a24befbefbb984d903f429/slide_58.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}