Estimation of the Critical Transition Probability Using Quadratic Polynomial Approximation with Skewness Filtering
Makito Oku (University of Toyama)
2022/12/12
NOLTA 2022
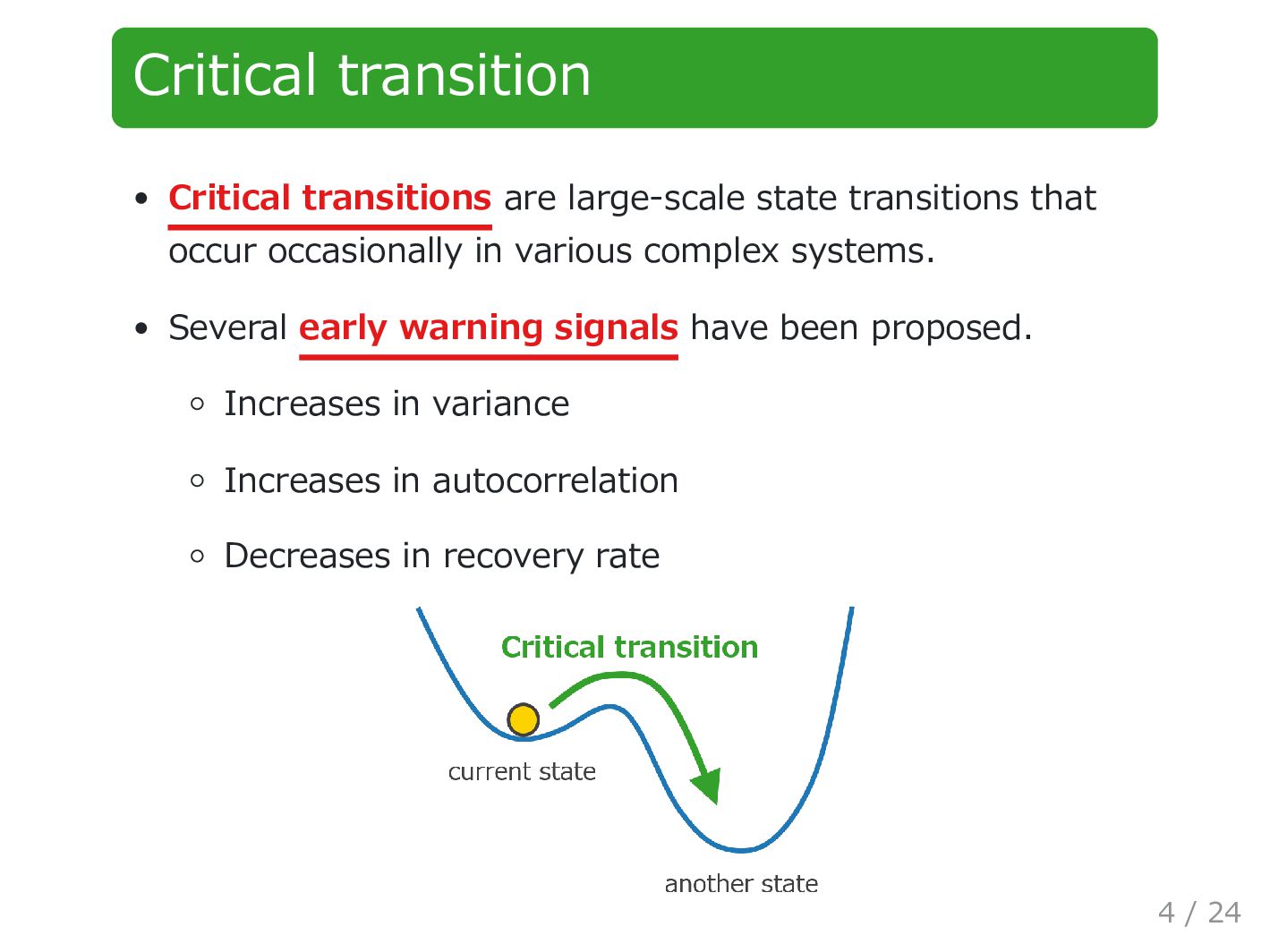
occasionally in various complex systems. Several early warning signals have been proposed. Increases in variance Increases in autocorrelation Decreases in recovery rate 4 / 24
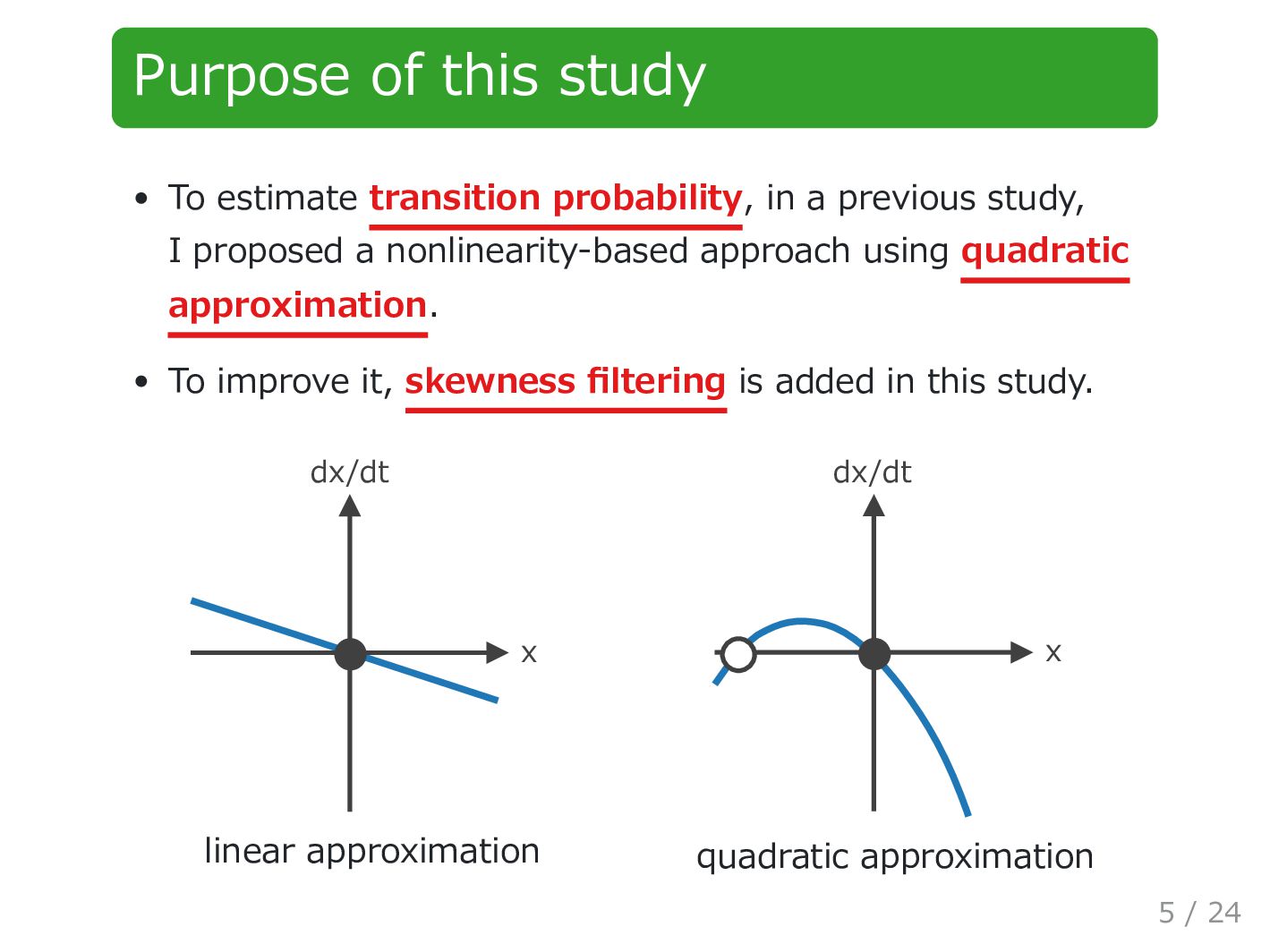
previous study, I proposed a nonlinearity-based approach using quadratic approximation. To improve it, skewness filtering is added in this study. x dx/dt linear approximation x dx/dt quadratic approximation 5 / 24
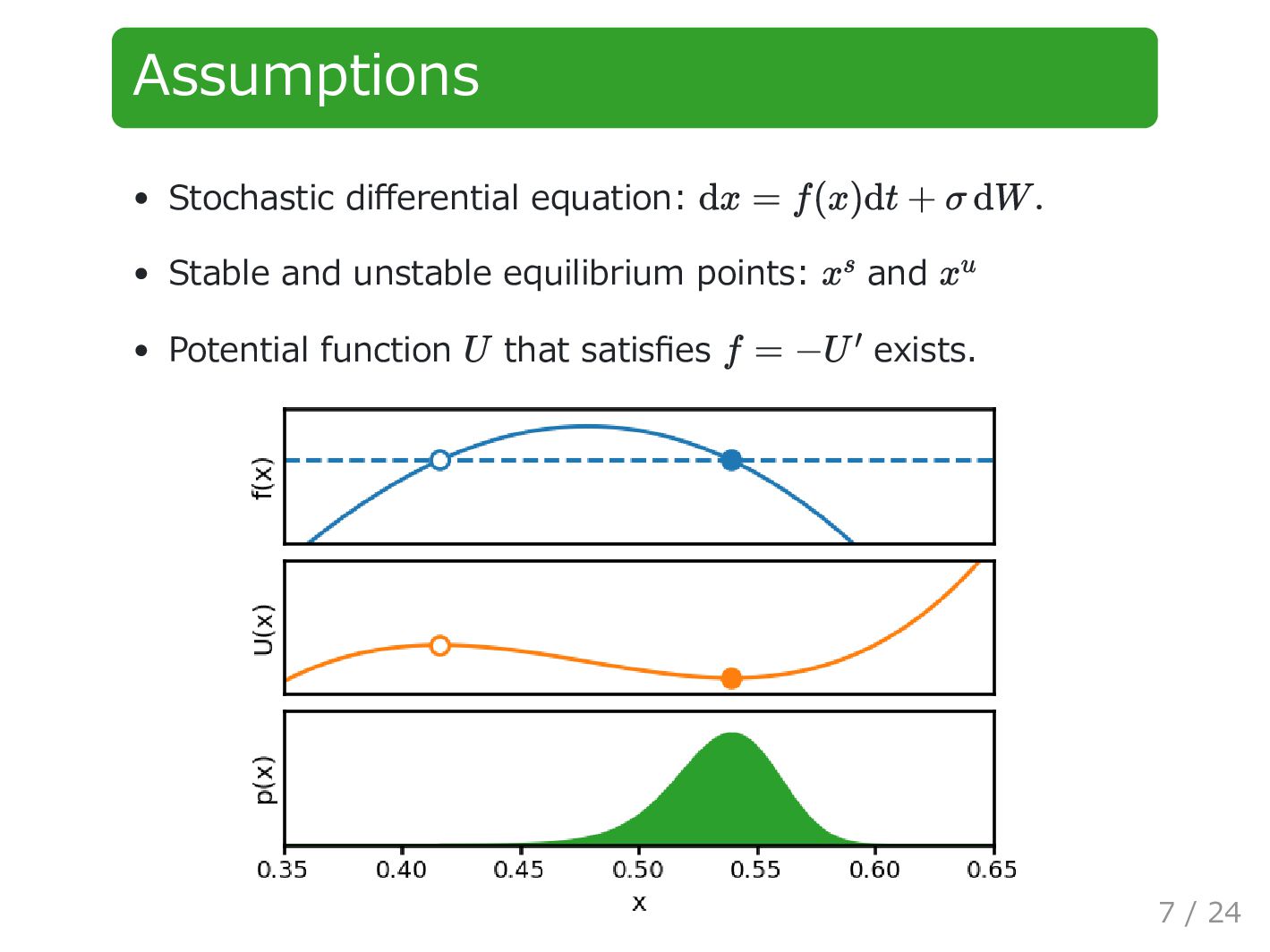
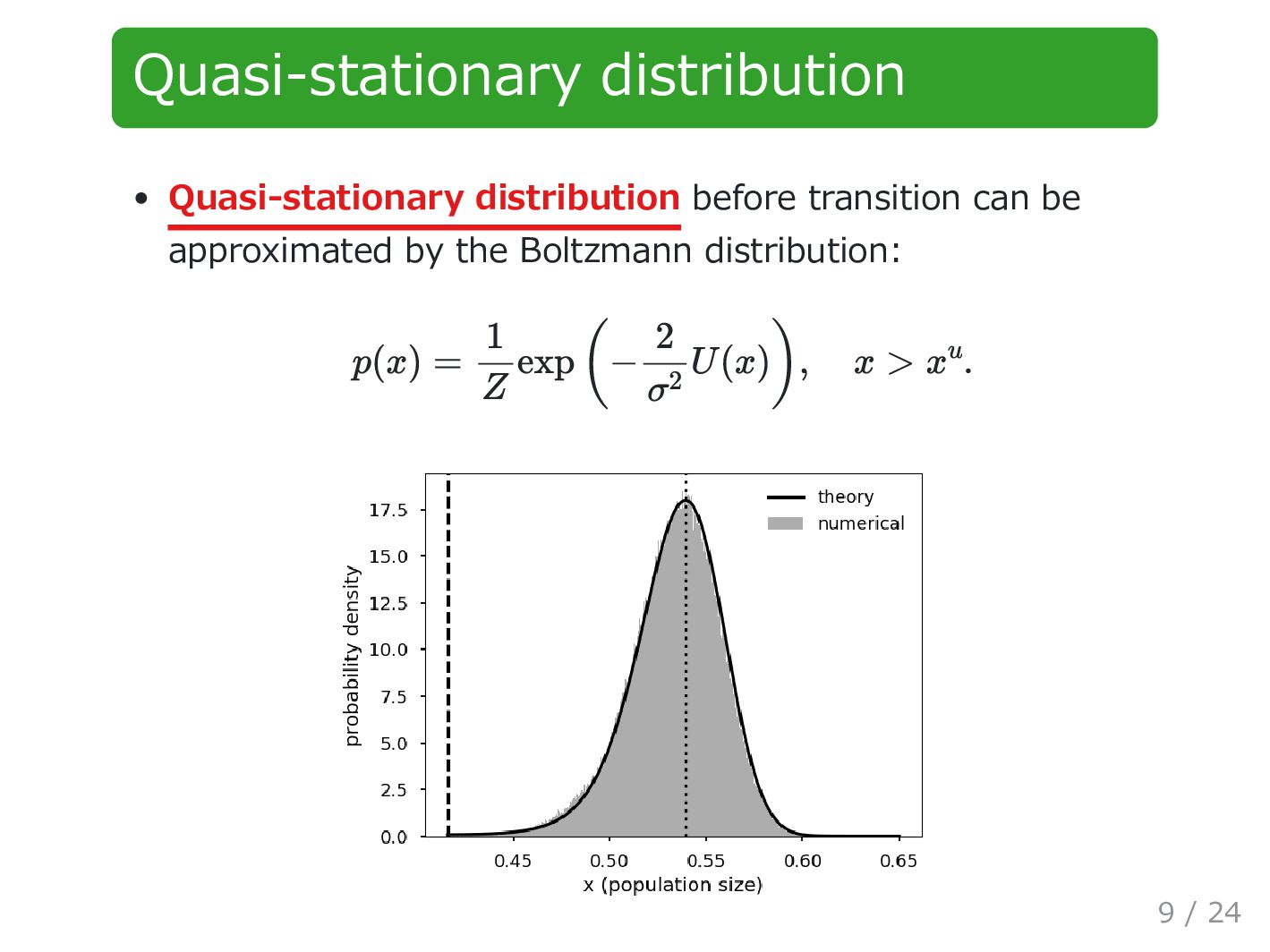
with measurement interval is available. is approximated by a quadratic polynomial: Approach 1: Least squares method (LSM) is obtained by applying LSM to with is calculated as . f σ D = {x1 , … , xN } Δt f f(x) ≈ ^ f(x) = a0 + a1 x + a2 x 2 . ^ f {(xn , Δxn )} Δxn = (xn+1 − xn )/Δt. ^ σ ^ σ = √Δt std(Δx − ^ f(x)) 11 / 24
. Approach2: Maximum likelihood estimation (MLE) is obtained by applying MLE to the observed distribution. The following equation is solved: is calculated in a similar manner as approach 1. g = (2/σ 2 )U ^ g g(x) ≈ ^ g(x) = η1 x + η2 x 2 + η3 x 3 . p(x) = exp(−^ g(x))/Z ^ g = . ⎡ ⎣ 1 2x 3x2 2x 4x2 6x3 3x2 6x3 9x4 ⎤ ⎦ ⎡ ⎣ η1 η2 η3 ⎤ ⎦ ⎡ ⎣ 0 2 6x ⎤ ⎦ ^ σ 12 / 24
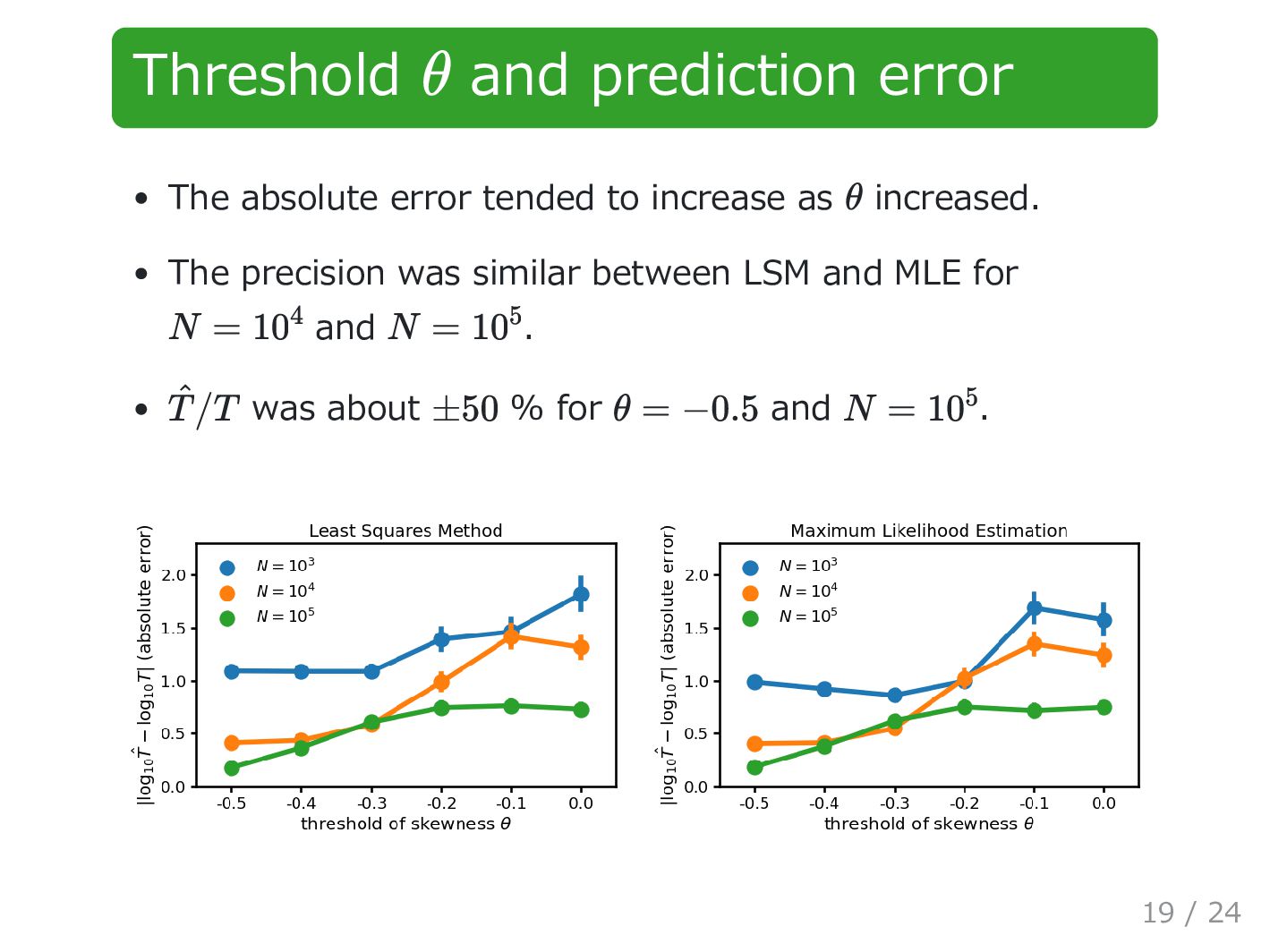
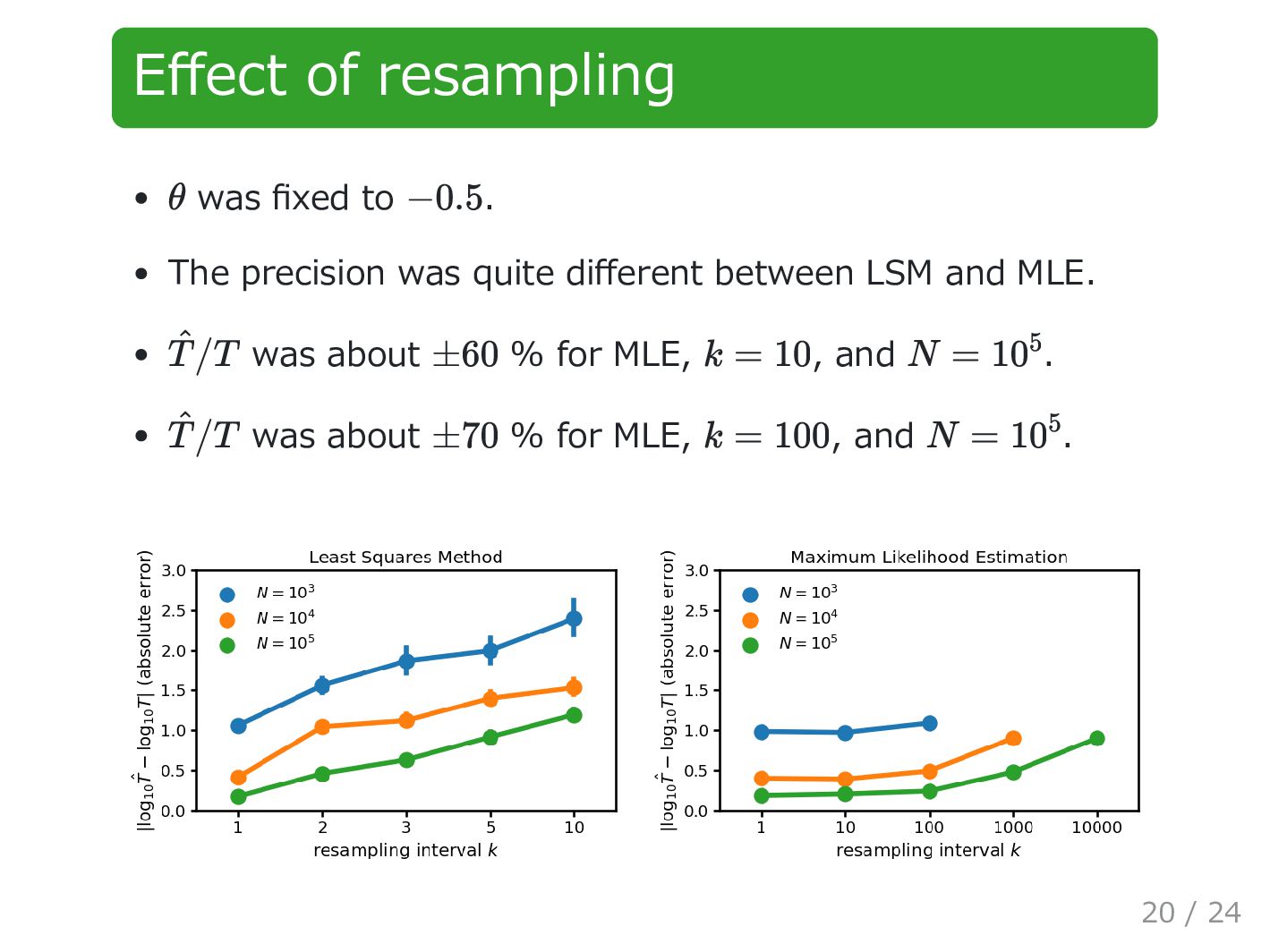
quite different between LSM and MLE. was about % for MLE, , and . was about % for MLE, , and . θ −0.5 ^ T /T ±60 k = 10 N = 10 5 ^ T /T ±70 k = 100 N = 10 5 20 / 24
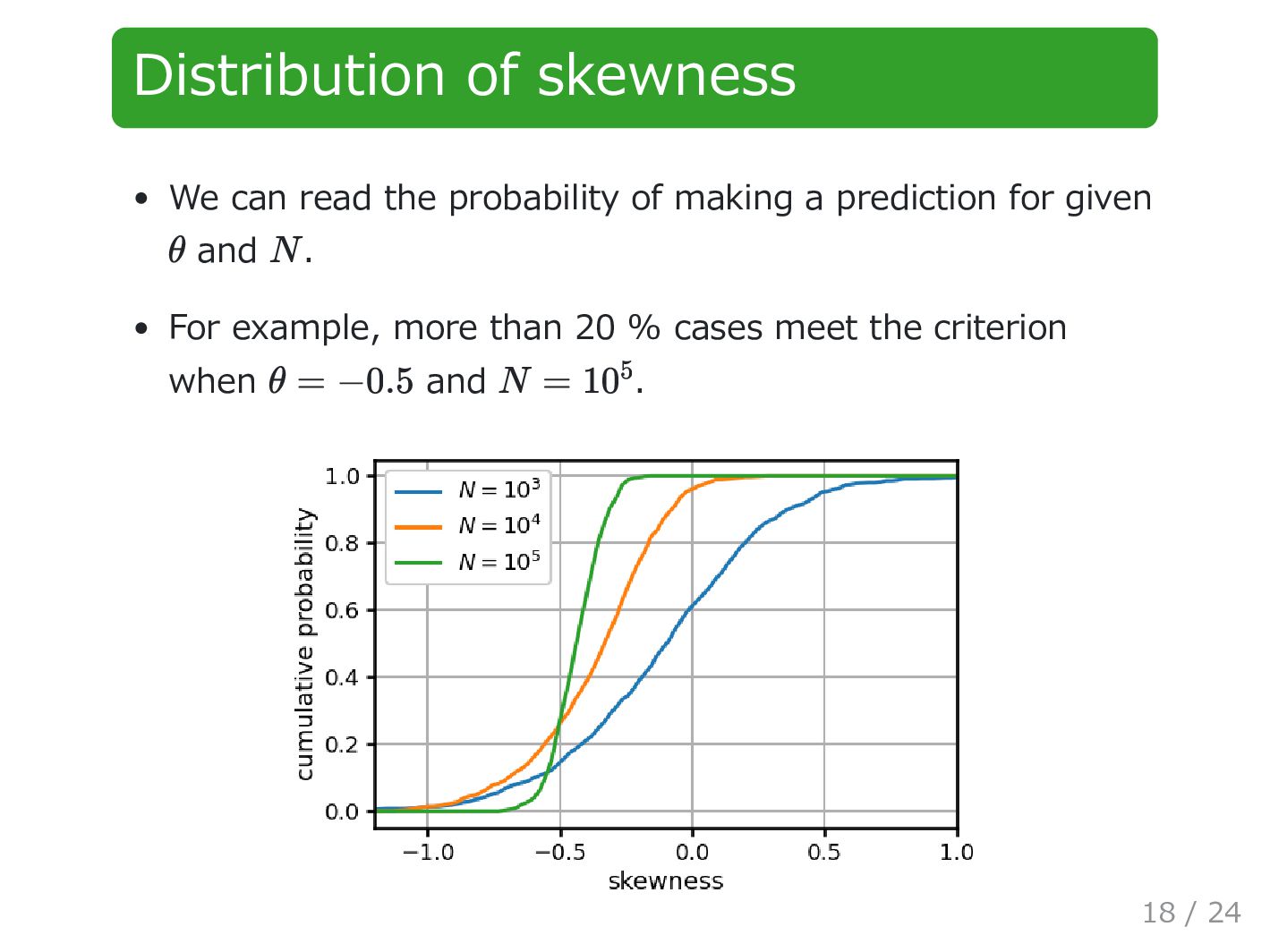
predictions are refrained in most cases. is too large → prediction error becomes huge. Why was MLE better than LSM when resampling was done? They might respond differently to auto-correlations. θ θ θ 22 / 24
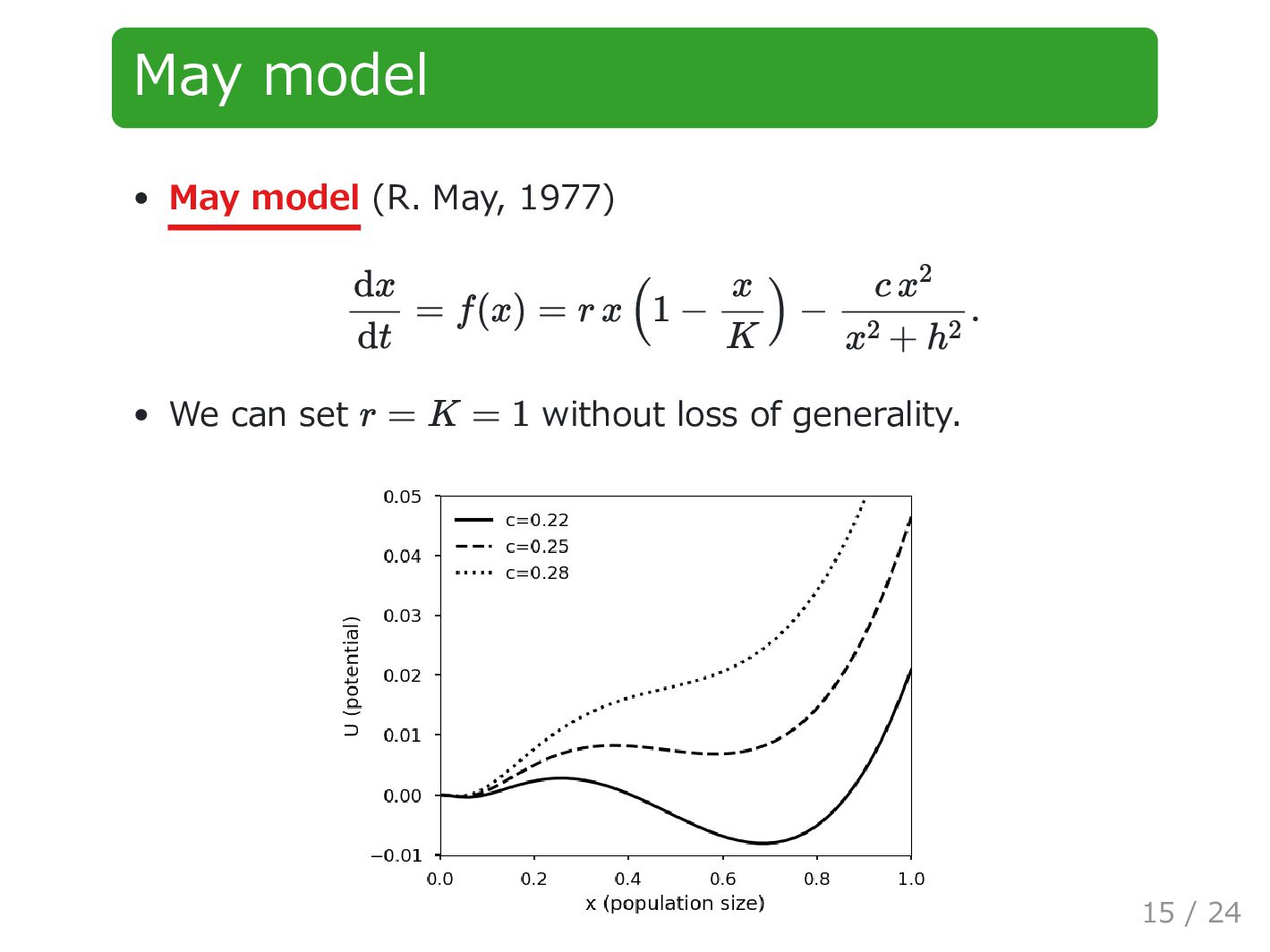
probability using quadratic polynomial approximation with skewness filtering. The proposed method was applied to May model. The results of numerical simulations showed that the proposed method worked well. It was also found that MLE required much less data points than LSM if auto-correlation was weak ( ). k > 1 23 / 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}