Josh Poduska, Chief Data Scientist at Domino Data Lab, and I teamed up to deliver the talk Managing Data Science in the Enterprise at the 2018 Strata Data Conference in New York.
Motivation: why this matters Common challenges to managing data science in the enterprise Guiding principles and framework Process Breakout Exercise: Project pre-flight checklist Break People Breakout Exercise: Team-building plan Managing Technology and X-Factors Summary
new revenue streams, expand into new markets, create and deliver new products. 2 Operational efficiency gains that compound through constant incremental improvement.
Annual Letter to Shareholders: At Amazon, we’ve been engaged in the practical application of machine learning for many years now. Some of this work is highly visible: our autonomous Prime Air delivery drones; the Amazon Go convenience store that uses machine vision to eliminate checkout lines; and Alexa, our cloud- based AI assistant. But much of what we do with machine learning happens beneath the surface. Machine learning drives our algorithms for demand forecasting, product search ranking, product and deals recommendations, merchandising placements, fraud detection, translations, and much more.
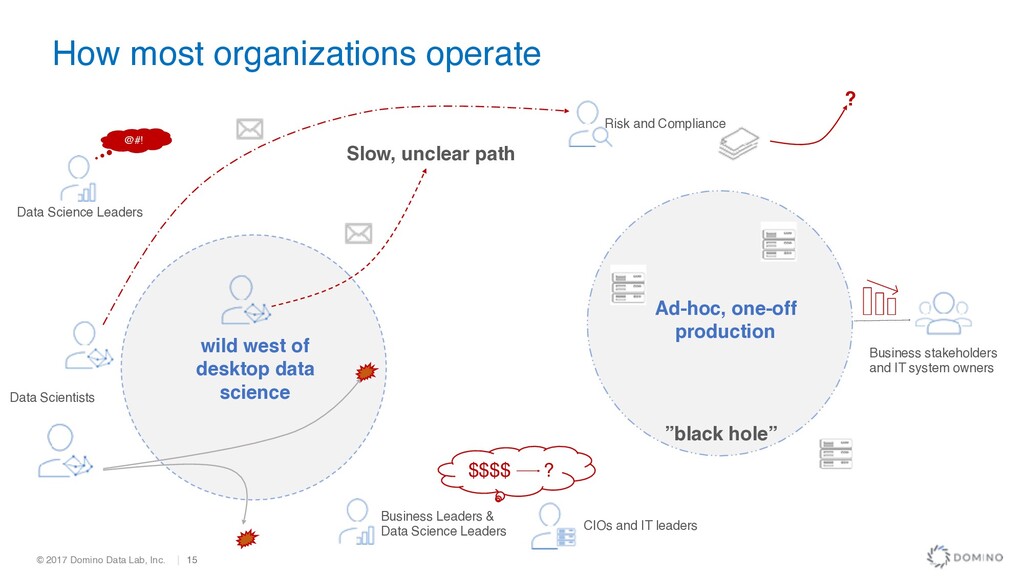
How most organizations operate Data Science Leaders Data Scientists Risk and Compliance Business stakeholders and IT system owners Business Leaders & Data Science Leaders CIOs and IT leaders Slow, unclear path ”black hole” wild west of desktop data science $$$$ ? ? @#!
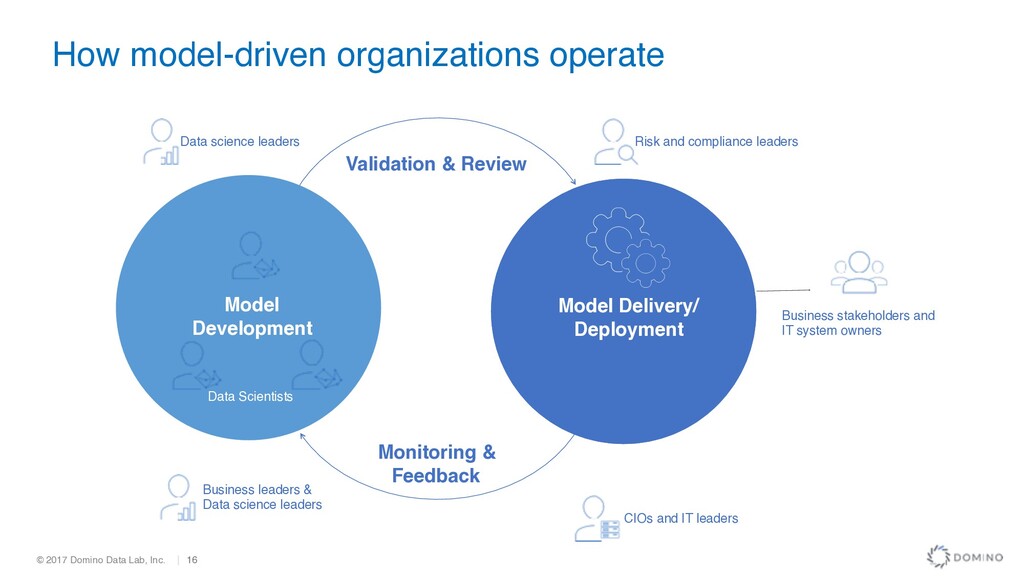
How model-driven organizations operate Data science leaders Risk and compliance leaders Business stakeholders and IT system owners Business leaders & Data science leaders CIOs and IT leaders Validation & Review Monitoring & Feedback Model Development Data Scientists
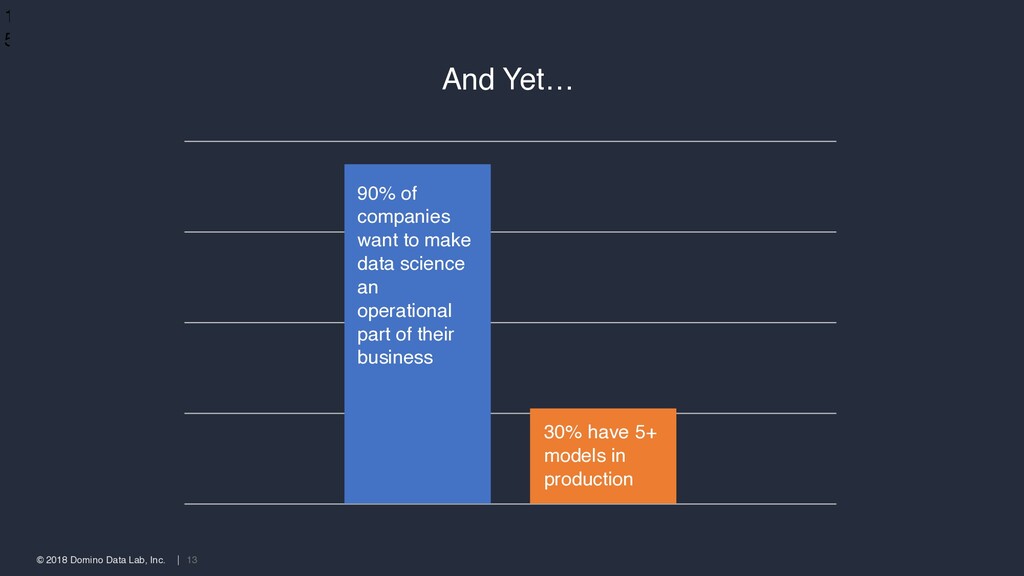
model-backed products into production. Or if they make it into production, companies struggle to measure their impact and drive subsequent improvement.
one tool > Process and culture Any one piece of technology > Producing an answer > Reusable knowledge Mindsets of the most effective data science organizations
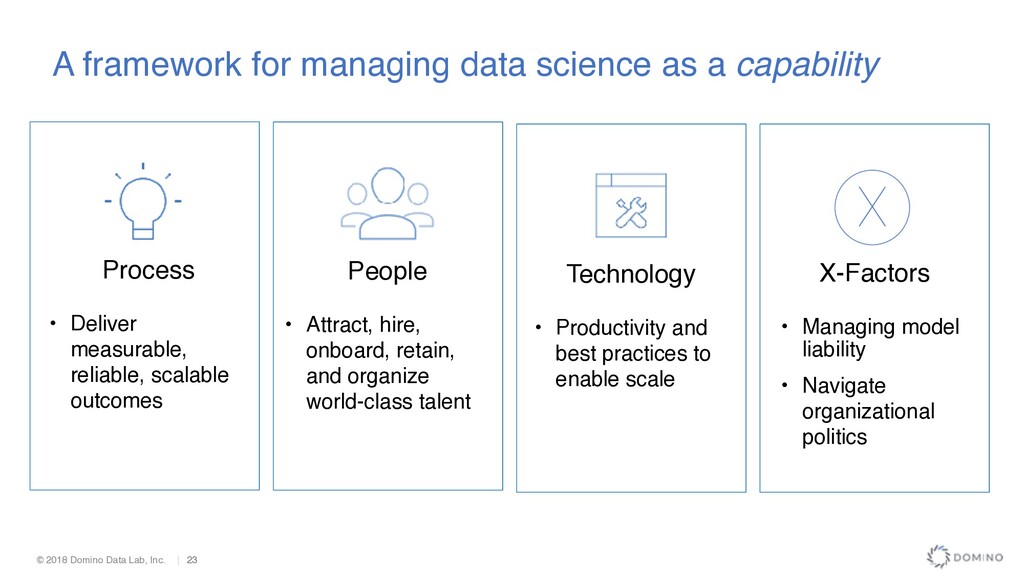
managing data science as a capability People • Attract, hire, onboard, retain, and organize world-class talent Technology • Productivity and best practices to enable scale X-Factors • Managing model liability • Navigate organizational politics Process • Deliver measurable, reliable, scalable outcomes
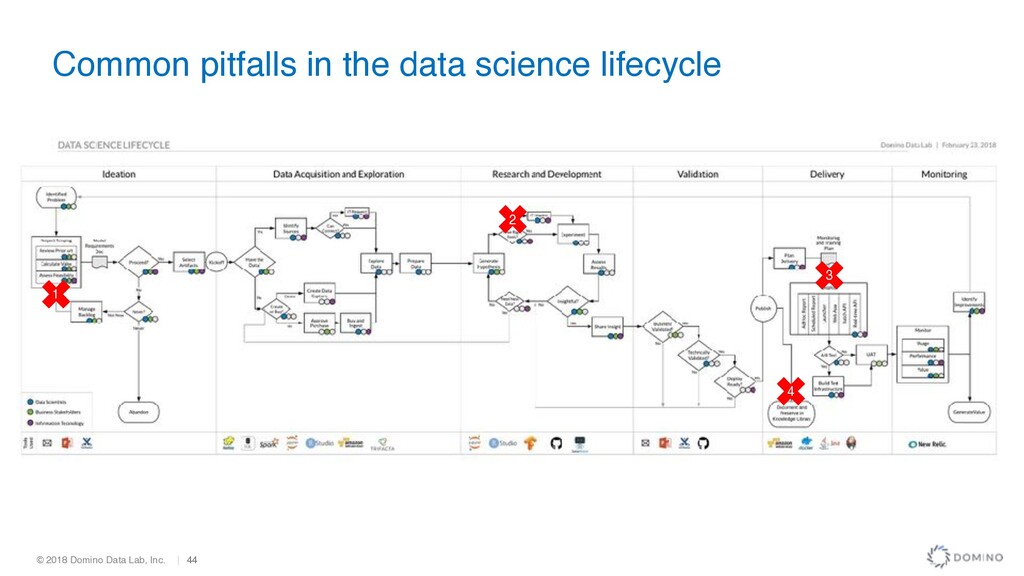
Data -> Analysis -> Product Development -> KPI • Common Pitfalls = Scope creep, loss of stakeholder enthusiasm, no crisp measure of success Better method • Problem -> Relevant KPIs -> Product Requirements -> Analysis Necessary -> Data • Result = Greater focus, lower risk • Business process map • Educate stakeholders on what is possible (avoid perception of magic) • Allow all stakeholders to submit ideas • Publish monthly to all stakeholders, re-prioritize at least quarterly Deciding what we do: engage the business
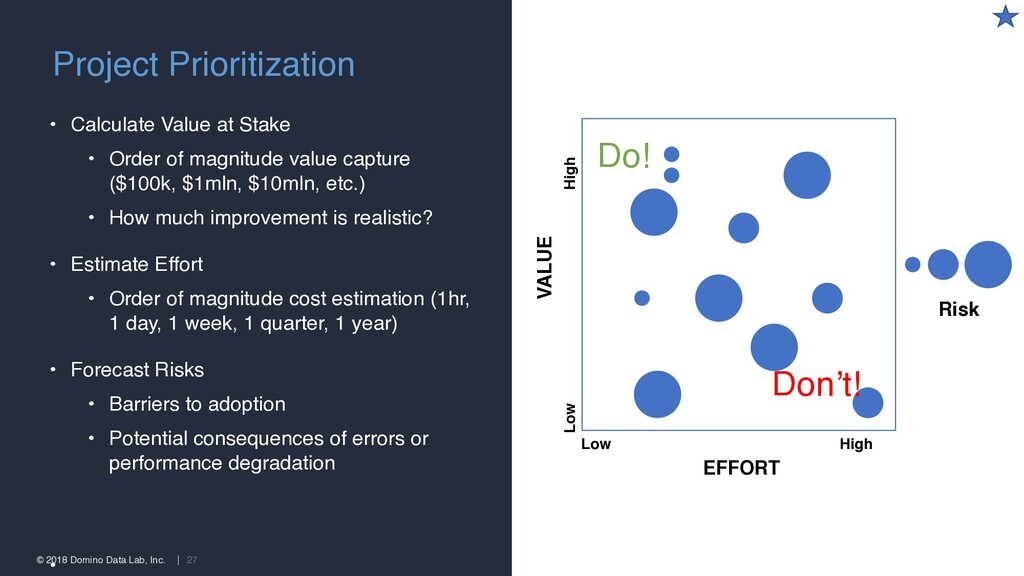
at Stake • Order of magnitude value capture ($100k, $1mln, $10mln, etc.) • How much improvement is realistic? • Estimate Effort • Order of magnitude cost estimation (1hr, 1 day, 1 week, 1 quarter, 1 year) • Forecast Risks • Barriers to adoption • Potential consequences of errors or performance degradation • Project Prioritization Risk EFFORT VALUE Low High Low High Do! Don’t!
never-ending science projects • Overlook linkages between model insight and business action • Focus on what’s easy or clever instead of what’s valuable • Cost estimates fail to consider integration, maintenance, retraining Prioritization Pitfalls
fail because of the math… we fail because we don’t anticipate how the math will be used.” • Time saved here pays 10x in development and 100x in prod • “Product management” principles apply to data science projects just as much as engineering projects Project kick-off
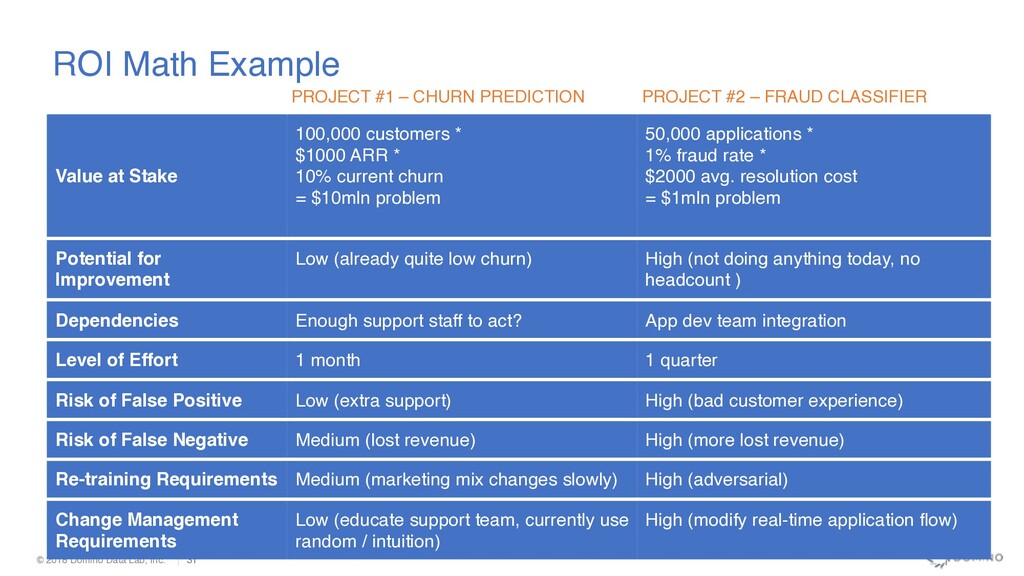
CHURN PREDICTION PROJECT #2 – FRAUD CLASSIFIER Value at Stake 100,000 customers * $1000 ARR * 10% current churn = $10mln problem 50,000 applications * 1% fraud rate * $2000 avg. resolution cost = $1mln problem Potential for Improvement Low (already quite low churn) High (not doing anything today, no headcount ) Dependencies Enough support staff to act? App dev team integration Level of Effort 1 month 1 quarter Risk of False Positive Low (extra support) High (bad customer experience) Risk of False Negative Medium (lost revenue) High (more lost revenue) Re-training Requirements Medium (marketing mix changes slowly) High (adversarial) Change Management Requirements Low (educate support team, currently use random / intuition) High (modify real-time application flow) ROI Math Example
• Define responsible parties from each group: data science, business, DevOps, application dev, compliance, etc. • Common Pitfalls • Lack empathy with goal of actual end user • Throw results “over the fence” to IT with no context Stakeholder Mapping
• Leverage existing sources first to build baseline • Create synthetic data with realistic characteristics • Track engagement with datasets to automatically discover experts • Common Pitfalls • Wait for “perfect” data • Buy external data without clear onboarding plan Data Availability
• Review state of the art — internally and externally • Common Pitfalls • Culture of NIH • Nose-to-the-ground mindsets • No single source of truth Prior Art Review
• Design multiple mock-ups of different form factors • Designate approvers in advance (IT, DS, biz) • Create process flow to precisely show where model will impact • Consider agile approach • Common Pitfalls • Fail to educate end-users • Over-engineer relative to the requirements use case Model Delivery Plan
• Pre-emptively answer “how will we know if this worked?” • Frame in terms of business KPIs not statistical measures • Define needs for holdout groups, A/B testing, etc. • Common Pitfalls • Not knowing when it is “good enough” • Fail to establish testing infrastructure and culture Success Measures
• Consider consequences of errors (e.g., false positives / negatives) • State likely biases in training data • Track ongoing usage to prevent inappropriate consumers • Common Pitfalls • Assume no regulation today will last • Conflate model interpretability with model provenance • Model misuse Risk Mitigation
• Defend the scientific method • Store positive and negative results • Preserve synthesis, intermediate results, code, data, and environment • Common Pitfalls • Repeated quiet failures • Old analysis doesn’t run Wrapping up projects
Checklist: Questions to Ask Business Case What’s the desired outcome of the project, in terms of a business metric? What are the linkages from your project to impacting that ultimate business metric? What is the order-of-magnitude ROI and cost? Stakeholders Lead DS, Proposed Validator, Data Engineers, Product Manager, Business Executive, Business End User (internal or external), Application Developer, DevOps Engineer, Compliance Technology What compute hardware and software infrastructure do you anticipate being necessary? Would your project benefit from specialized or parallelized computing? Data What relevant data exists today? Who are the subject matter experts? What other data would we potentially want to capture, create, or buy externally? Prior Art Who has worked on this business topic before (internal and external)? Who are the relevant experts in the techniques I will likely use? Model Delivery Who will consume this and what form factor will the final product take (report, app, API)? What dependencies or resources will you require to deliver work this way (e.g., IT)? What are other possible delivery mechanisms, especially ones that are lighter weight or easier to test first? What user training is necessary to ensure adoption? Success Measure How will you know if it’s working as expected, or otherwise get feedback? What’s your “monitoring” plan, even if it’s manual and subjective? Risk Mitigation How could this model be mis-used by end users? Any constraints on modeling approach (e.g., interpretability requirements)?
overwhelmed into paralysis by complex process • Look for low-hanging fruit to buy political capital for more headcount and risky projects • Find senior sponsor • Most important takeaway: engage the business as partners early and often A note for early teams
CHALLENGES • X% of projects have little / no impact • Y number of weeks lost by employees identifying what projects have been done before and understanding that work 1 Inconsistent Project Prioritization and Kickoff • Duplication of work wastes time and slows down progress • Inability to leverage past work and customize across locations • Scope creep and loss of stakeholder enthusiasm 2 No Access to Technology On- Demand • <Subsidiary> approval for required infrastructure takes weeks per project • Insufficient infrastructure prevents differentiated innovation • 4-6 weeks delays for resource requests spread between approvals and implementation • X time wasted replacing Data Scientists 3 No Ability to Easily Deploy Results to Business • Data Scientists waste time on mundane tasks to expose models • Business stakeholders complain about lengthy delays to business value • Z time lost by employees setting up dashboard servers BUSINESS IMPACT Bottlenecks and pitfalls have quantified negative impact 4 Failure to preserve knowledge upon completion • Lack of documentation and reproducibility of code hurts iteration • Projects just fade away, so null results aren’t known for future collaborators • Model iteration velocity slowed by average of 1m
commonly cited as obstacle to being model-driven • Typical tenure <2 years with 3+ month ramp • Overwhelmed by resumes, underwhelmed by output Why focus on people?
How to lure the best talent • Assess – Hire systematically • Train – Focus on mindset, not just skills • Retain – Build community and mentorship • Organize - Define optimal roles and structure Framework for People
• Have a differentiated offering and strategy • Advertise projects, not just the company • Offer modern tools and commitment to open source • Common Pitfalls • Write unrealistic job descriptions • Seek PhDs when need hackers (or vice versa) Attracting the best and brightest
• Be systematic: identify required attributes, design assessments for each • Be analytical: track interviewer and interview type efficacy • Include EQ and non-technical assessments • Sell while assessing: simulate real work • Common Pitfalls • Over-rely on tech screens Picture of women’s sport’s team bench Assessment
• Reinforce mindsets, not just skills • Develop culture of reuse, compounding • Reward community- enhancing behavior • Provide “soft” skills training • Common Pitfalls • “Not built here” mentality Training
• Emphasize listening to stakeholders • Compensate team on new and existing work, not just current projects • Common Pitfalls • Employee churn from flawed expectations Source: Max Shron, Warby Parker Set expectations on time allocation upfront
• Share accountability with the business’s KPIs • Focus on iteration velocity • Systematically capture stakeholder feedback and engagement • Common Pitfalls • Measure everyone but yourself • Over-index on any one project vs. factory performance Metrics of managing data science
of data science PRIORITIES ROLE Generating and communicating insights, understanding the strengths and risks Data Scientist Creating engaging visual and narrative journeys for analytical solutions Data Storyteller Building scalable pipelines and infrastructure that make it possible to do the higher levels of needs. Data Infrastructure Engineer Articulating the business problem, translating to day-to-day work, ensuring ongoing engagement. Data Product Manager Vetting the prioritization and ROI, providing ongoing feedback Business Stakeholder
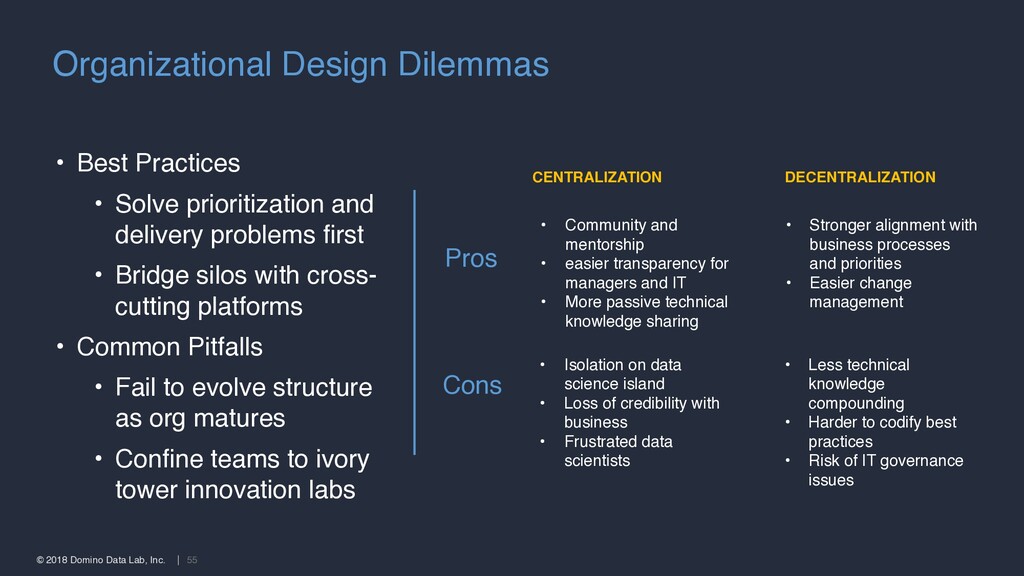
• Solve prioritization and delivery problems first • Bridge silos with cross- cutting platforms • Common Pitfalls • Fail to evolve structure as org matures • Confine teams to ivory tower innovation labs • Stronger alignment with business processes and priorities • Easier change management • Less technical knowledge compounding • Harder to codify best practices • Risk of IT governance issues DECENTRALIZATION CENTRALIZATION • Community and mentorship • easier transparency for managers and IT • More passive technical knowledge sharing • Isolation on data science island • Loss of credibility with business • Frustrated data scientists Pros Cons Organizational Design Dilemmas
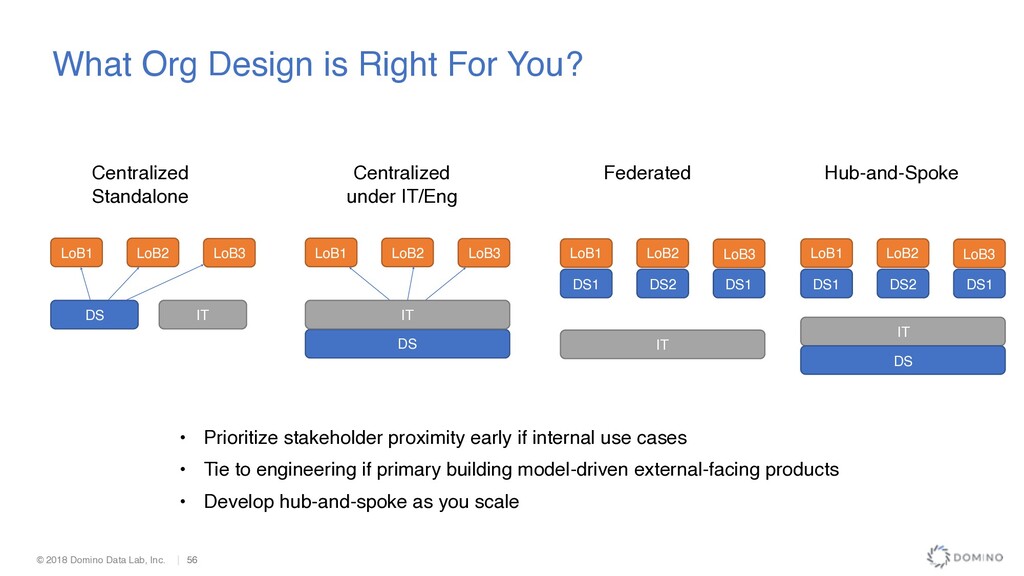
is Right For You? DS IT LoB1 LoB2 LoB3 Centralized Standalone Centralized under IT/Eng DS IT LoB1 LoB2 LoB3 Federated DS1 IT LoB1 LoB2 LoB3 DS2 DS1 Hub-and-Spoke DS1 IT LoB1 LoB2 LoB3 DS2 DS1 DS • Prioritize stakeholder proximity early if internal use cases • Tie to engineering if primary building model-driven external-facing products • Develop hub-and-spoke as you scale
Plan Template: Questions to Ask Attracting Talent • What’s your differentiated value proposition for candidate data scientists? List three things that make the opportunity unique, that you think will resonate with your target candidate pool. • What are 1-3 risks that might make the opportunity less appealing that competitive opportunities? How can you mitigate or get ahead of them? Hiring Process • What are the three most important attributes for your candidates? What is your assessment plan for each? Onboarding • What outcomes need to have been achieved in the first 30, 60, and 90 days? • What are the most important pieces of “tribal knowledge” your new hire needs to know, and how will she learn them? Examples include data sources, project methodologies, stakeholder dynamics, notable wins / losses, etc. Retention and Management • What skills do you hope this candidate develops over the first year? • What metrics will determine success of this candidate after a year? Examples include certain business metrics, community contributions, number of insights produced, or project iteration velocity.
practices “bottom up” Test Ideas Faster Deploy and Share Work Easily DATA SCIENTISTS: “I’M MORE PRODUCTIVE!” Powerful Collaboration Features Version Control & Reproducibility LEADERS: “CENTRALIZED WORK!”
business impact: - Deploy models as APIs - Deploy apps (e.g., Shiny) & reports to non-technical stakeholders - Scheduled jobs for ETL, reporting, model retraining Entice data scientists with: - Vertical and horizontally scalable infrastructure - DevOps automation - Computational lab notebook to track results Centralizing work makes it possible to: - Find, reuse, reproduce, and discuss work. How we approached this
at later maturity • Track and guardrail model usage • Document risks and trade-offs made in flight, not post hoc • Pre-emptively establish validation, monitoring, and compliance controls Model liability
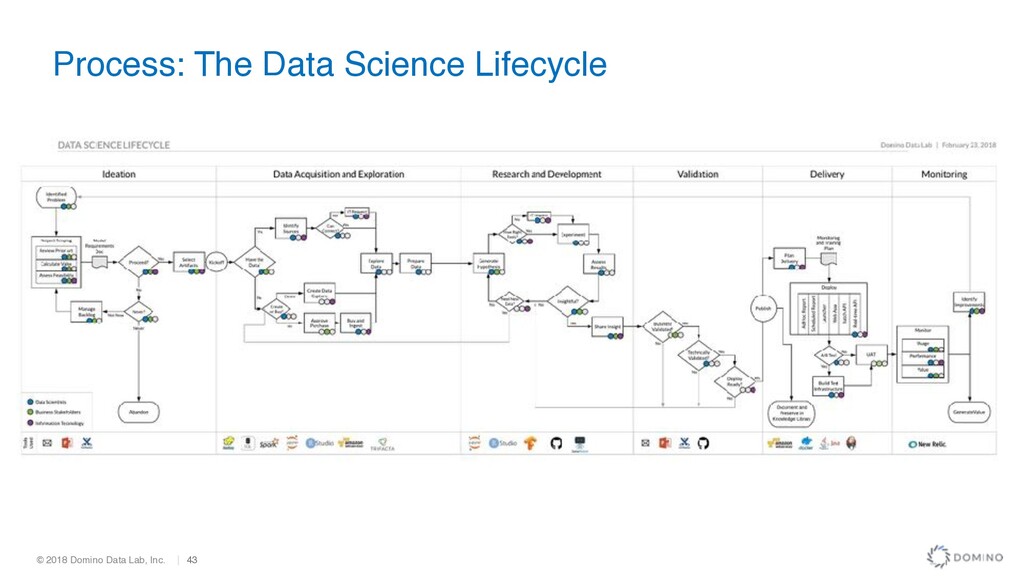
success is not adding up individual successes, it’s an organizational capability • Alignment and partnership with the business is critical • Process – Enforce a pre-flight checklist • People – Develop hiring and onboarding plans • Technology - Leverage technology to increase productivity and best practice processes • X-Factors – Navigate politics and risk Summary
about Domino’s Data Science Lifecycle and Value Assessment offerings • Tailored analysis of existing processes, gaps, and tangible best practices • Leverage our ROI analysis templates across your portfolio Struggling with your own lifecycle?
this content for more information • The Practical Guide to Managing Data Science at Scale • Data Science Management Survey Report • Stop by our booth #1403 Want to learn more? Questions?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}