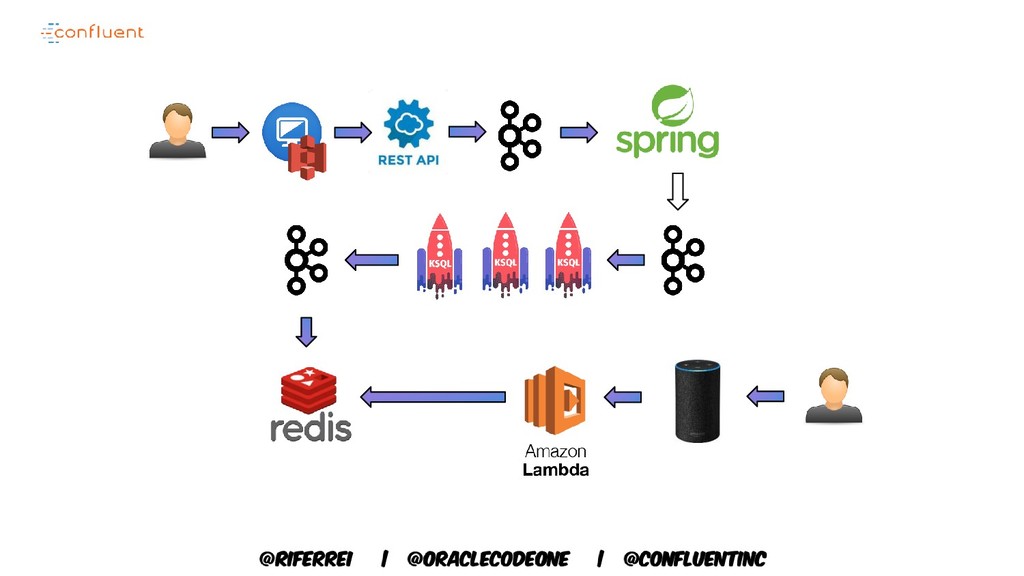
❑ Ex-Oracle, Red Hat, IONA Tech ❑ [email protected] ❑ https://riferrei.net • Alexa (amazon echo) ❑ The voice behind Amazon ❑ Ex-Raspberry Pi, Arduino ❑ She is a female in character! @riferrei @alexa99
The bag itself • The sensors which detects when there is a collision probability based on speed • The inflation system, which does combine the chemical compounds (sodium azide and potassium nitrate) to make gas to inflate the bag What if the airbag deploys 30 seconds after the collision?
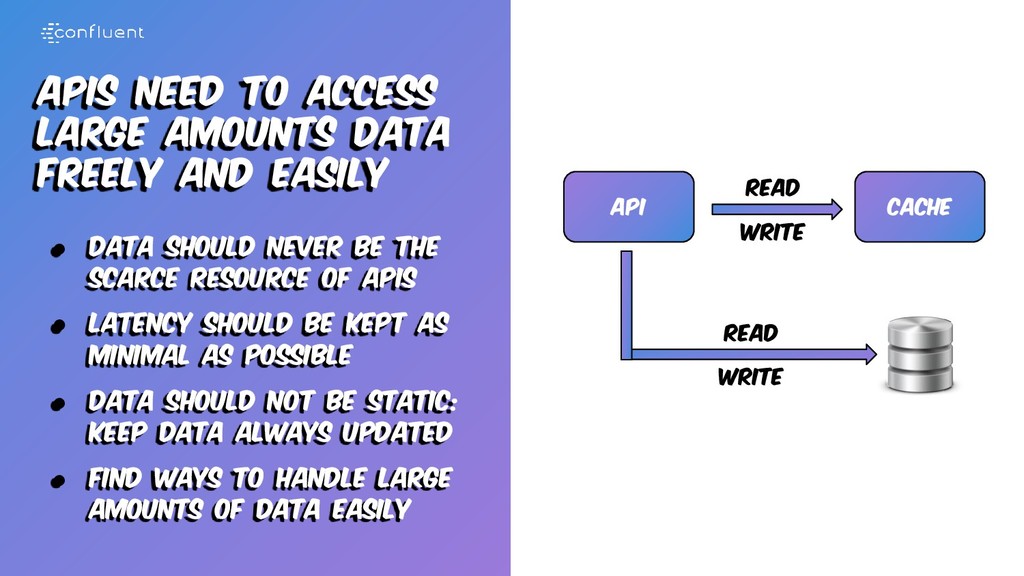
• Data should never be the scarce resource of apis • Latency should be kept as minimal as possible • Data should not be static: keep data always updated • Find ways to handle large amounts of data easily Cache API Read Write Read Write
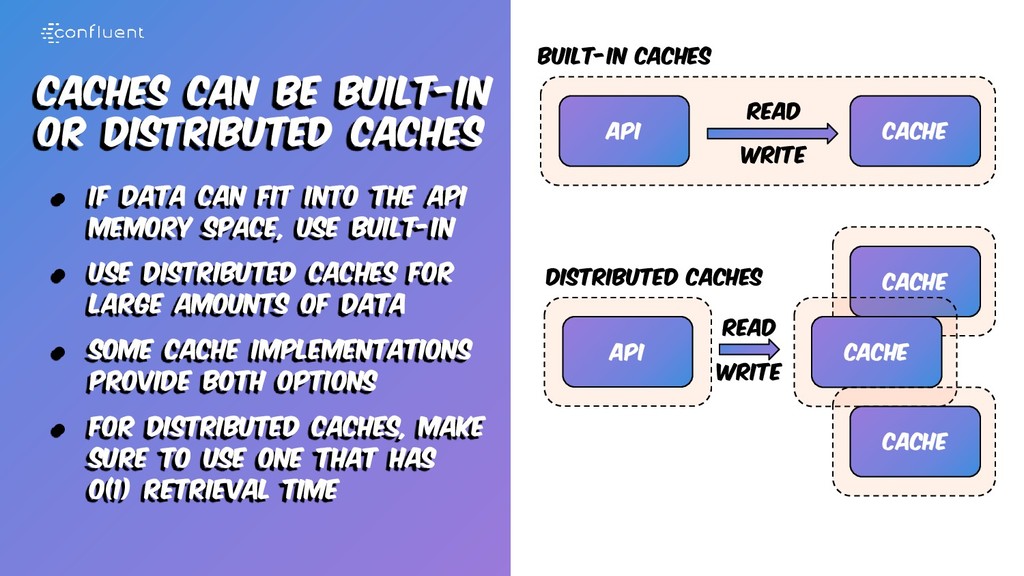
Caches Cache API Distributed Caches Cache Cache Read Write Read Write • If data can fit into the api memory space, use built-in • Use distributed caches for large amounts of data • Some cache implementations provide both options • For distributed caches, make sure to use one that has o(1) retrieval time
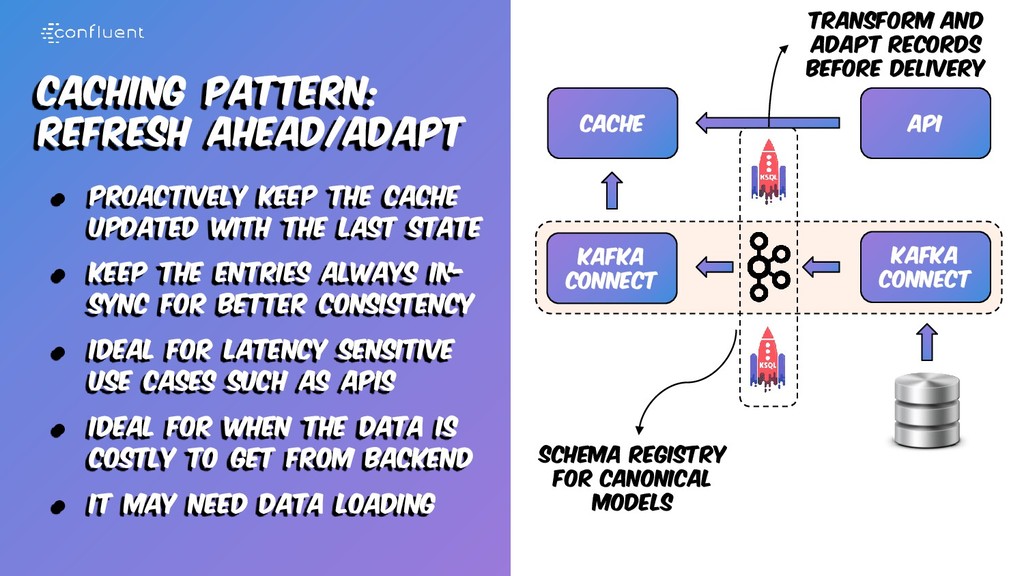
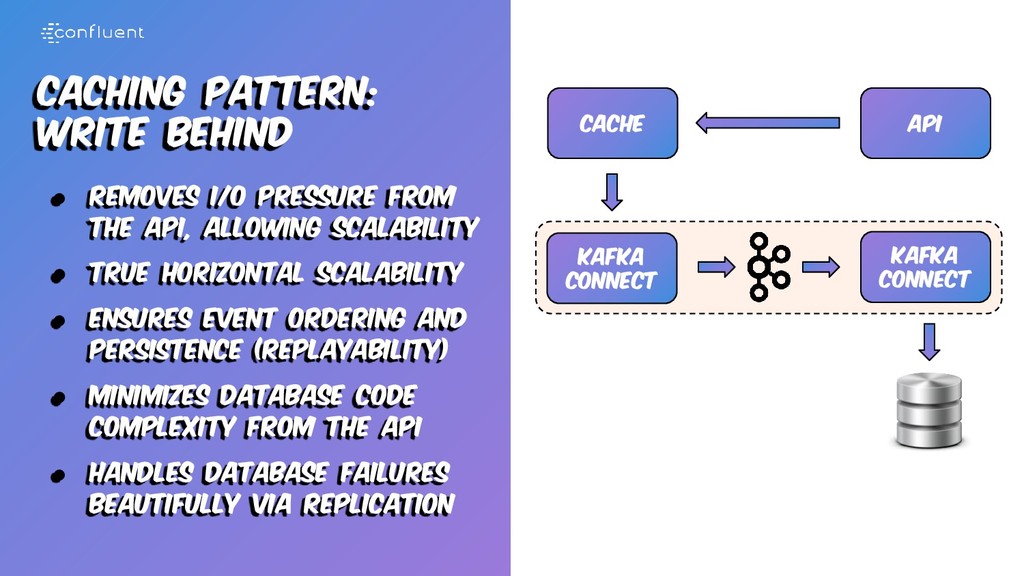
with the last state • Keep the entries always in- sync for better consistency • Ideal for latency sensitive use cases such as apis • Ideal for when the data is costly to get from backend • It may need data loading Kafka Connect Cache Kafka Connect API
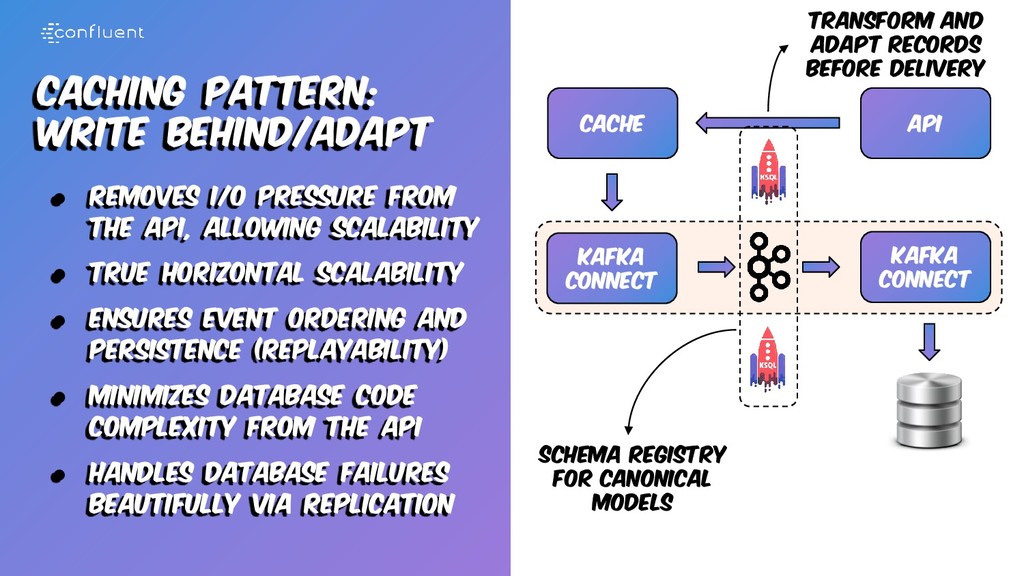
with the last state • Keep the entries always in- sync for better consistency • Ideal for latency sensitive use cases such as apis • Ideal for when the data is costly to get from backend • It may need data loading Kafka Connect Cache Kafka Connect Transform and adapt records before delivery Schema Registry for canonical models API
api, allowing scalability • True horizontal scalability • Ensures event ordering and persistence (replayability) • Minimizes database code complexity from the api • Handles database failures beautifully via replication Kafka Connect Cache Kafka Connect Transform and adapt records before delivery API Schema Registry for canonical models
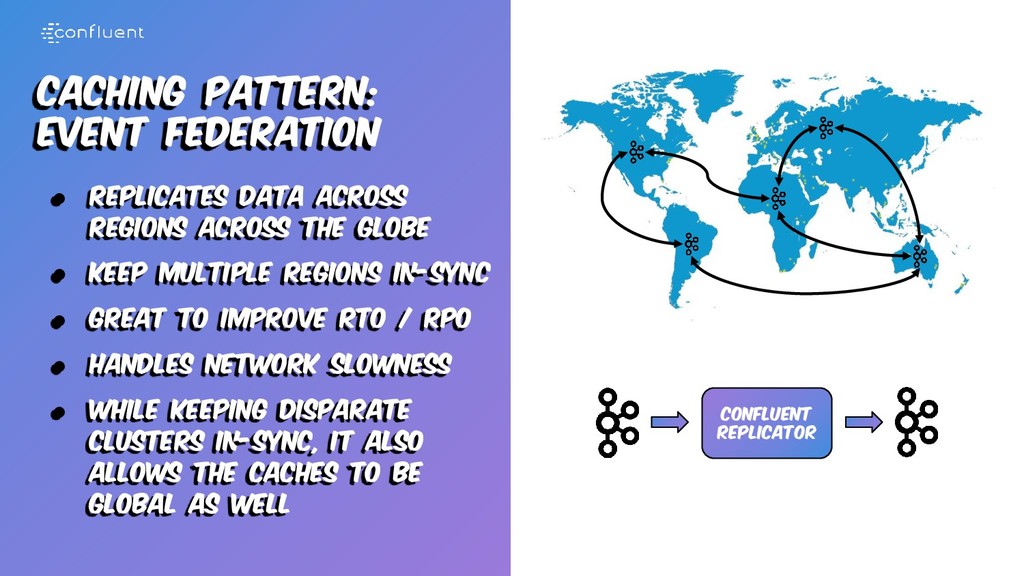
the globe • Keep multiple regions in-sync • Great to improve rto / rpo • Handles network slowness • While keeping disparate clusters in-sync, it also allows the caches to be global as well Confluent Replicator
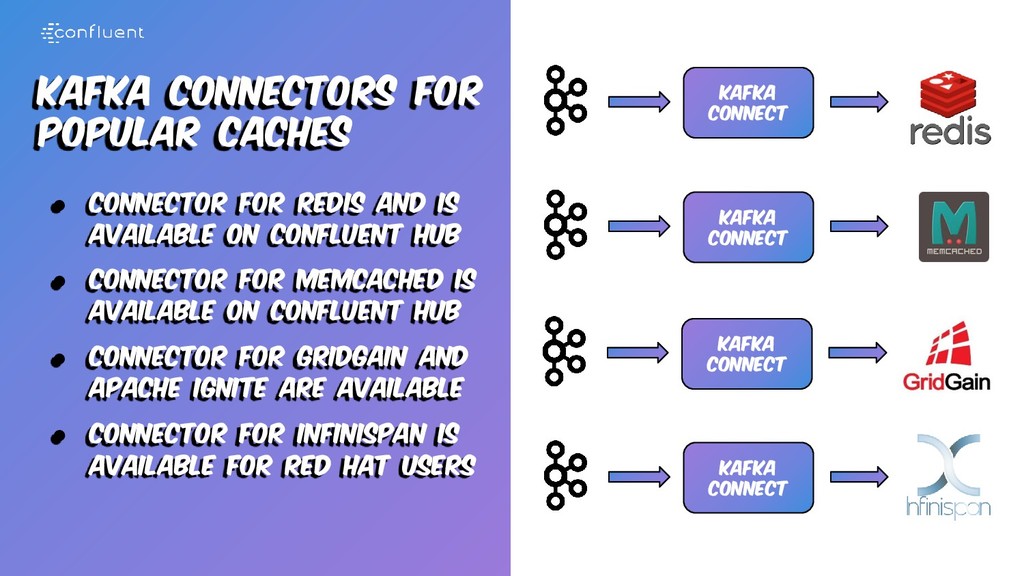
is available on confluent hub • Connector for Memcached is available on confluent hub • Connector for gridgain and apache ignite are available • Connector for infinispan is available for red hat users Kafka Connect Kafka Connect Kafka Connect Kafka Connect
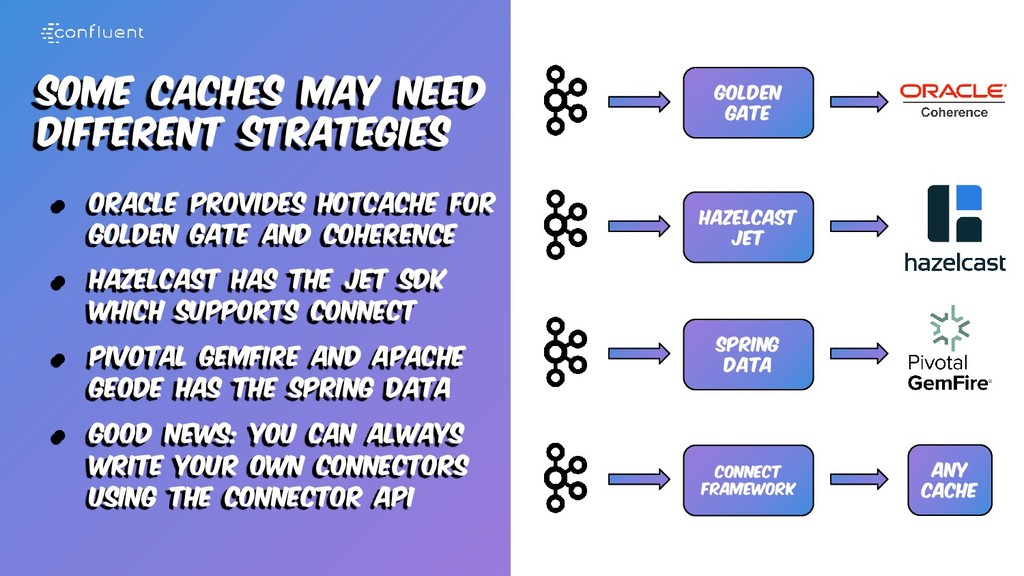
for golden gate and coherence • Hazelcast has the jet sdk which supports connect • Pivotal gemfire and apache geode has the spring data • Good news: you can always write your own connectors using the connector api Golden gate Hazelcast Jet Spring data Connect Framework Any Cache
a plataform to perform database cdc • Works in a log level, which means true cdc behavior for your projects • Open-source and maintained by red hat. Has a broad set of connectors available • It is built on kafka connect
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}