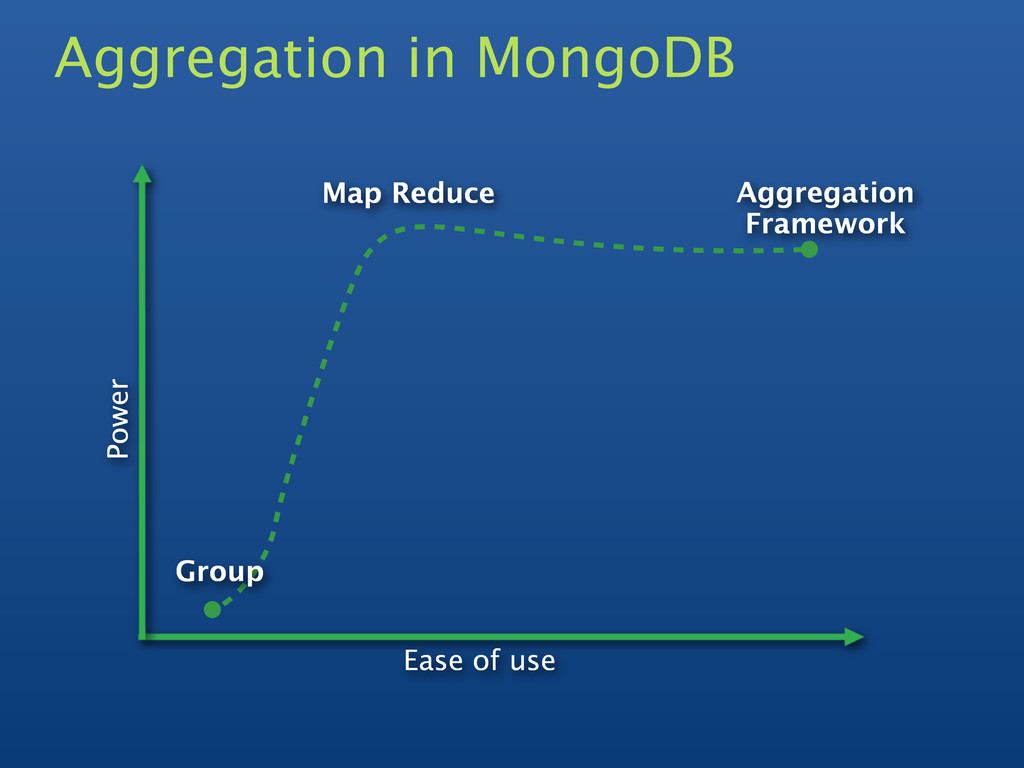
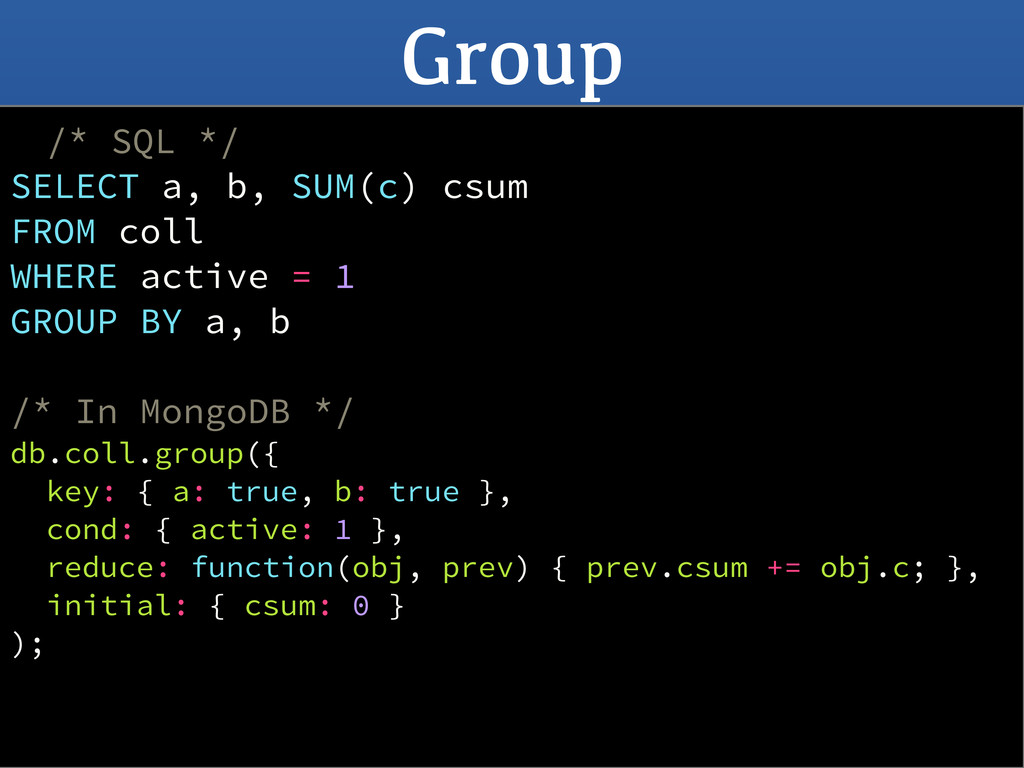
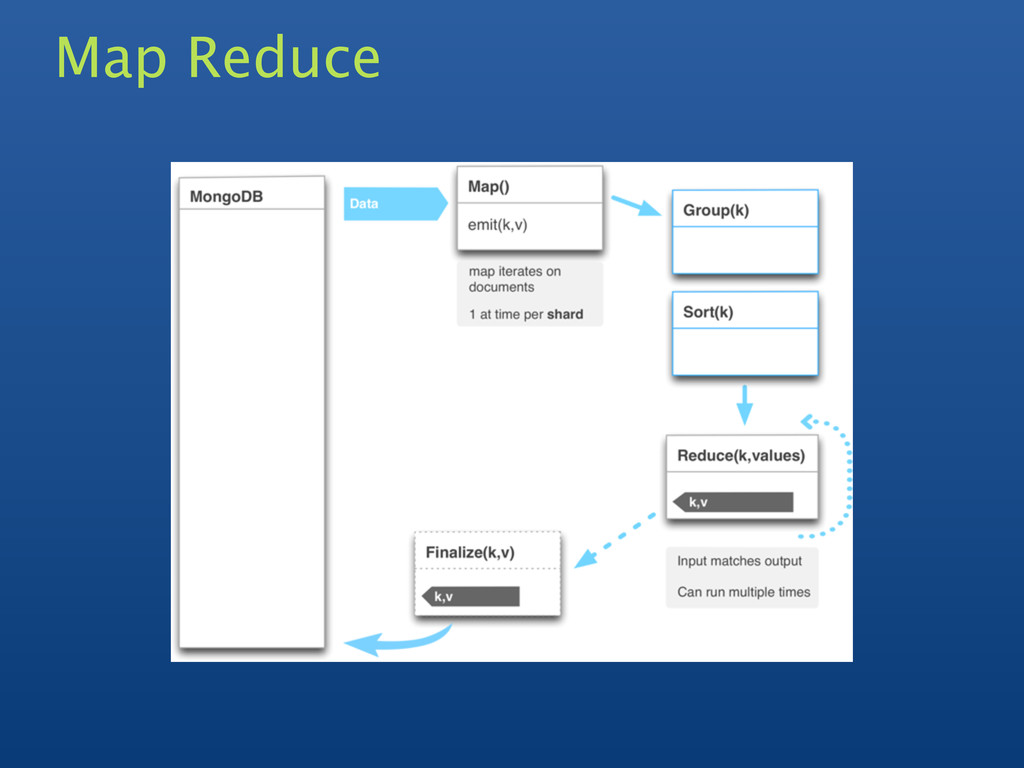
Currently being used for totalling, averaging, etc • Map/Reduce is a big hammer • Simpler tasks should be easier • Shouldn't need to write JavaScript • Avoid the overhead of JavaScript engine
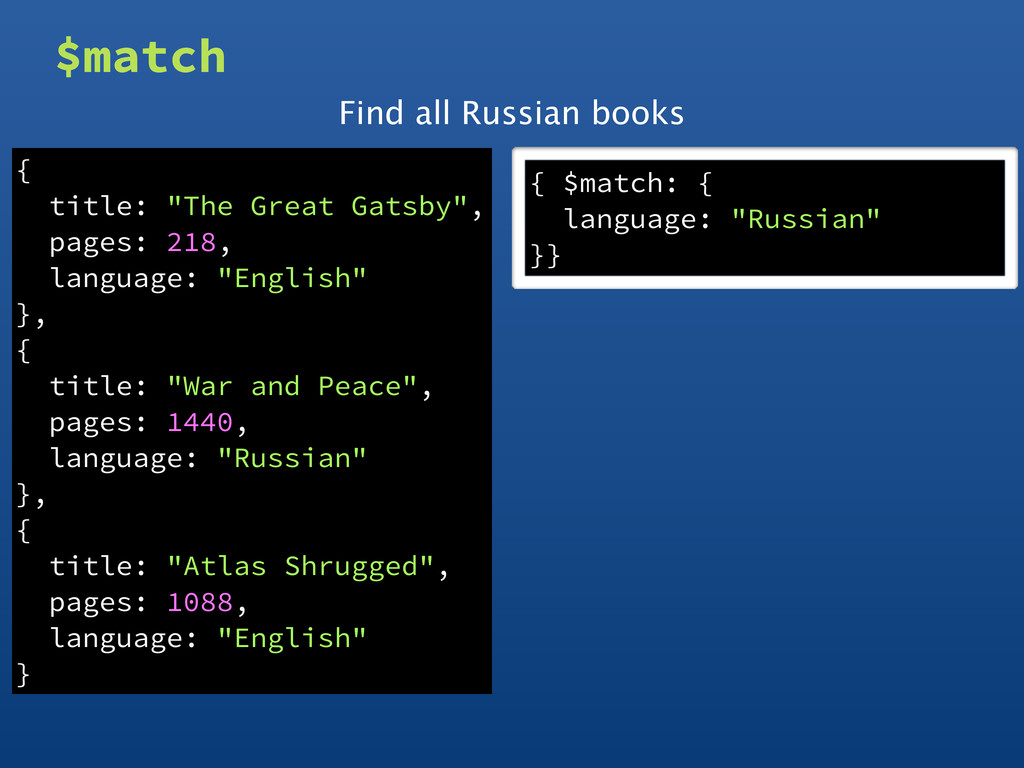
• Original input is a collection • Final output is a result document • Series of operators • Filter or transform data • Input/output chain ps ax | grep mongod | head -n 1
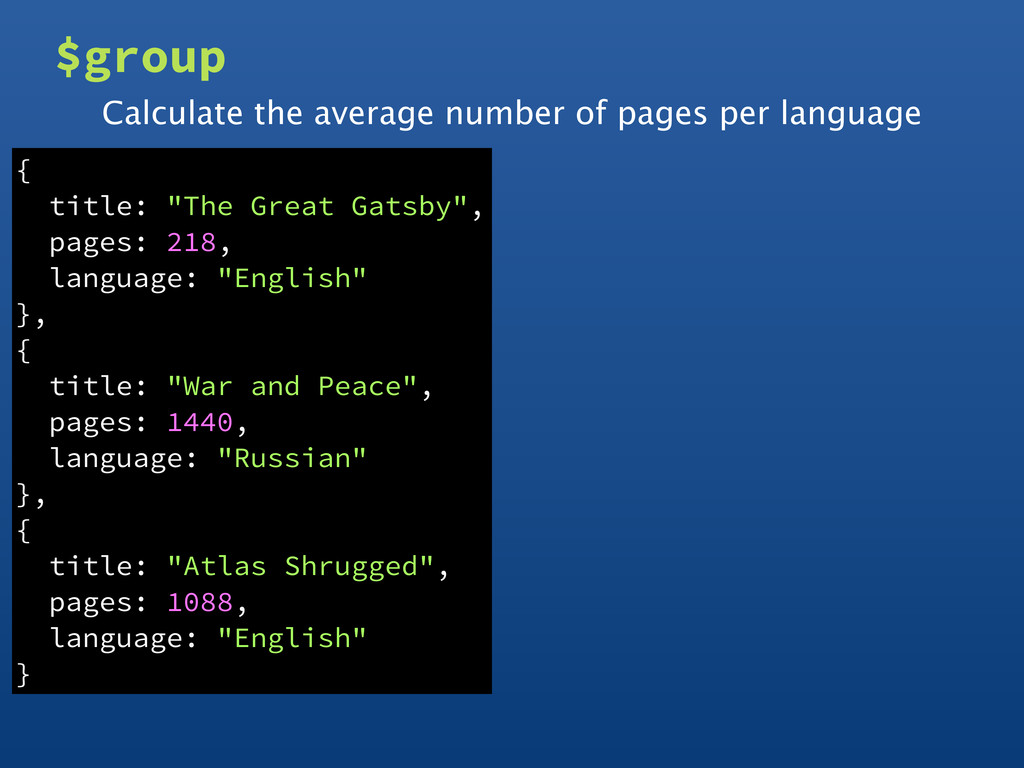
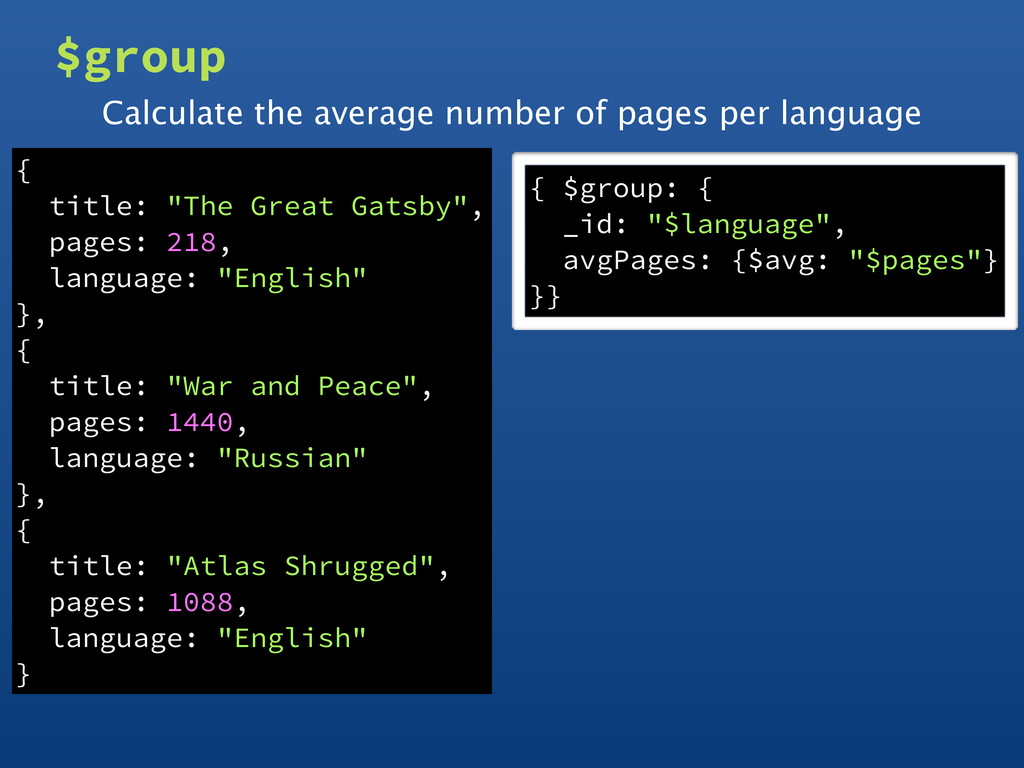
reference • Object with multiple references • Constant value • Other output fields are computed $max, $min, $avg, $sum, $addToSet, $push, $first, $last • Processes all data in memory
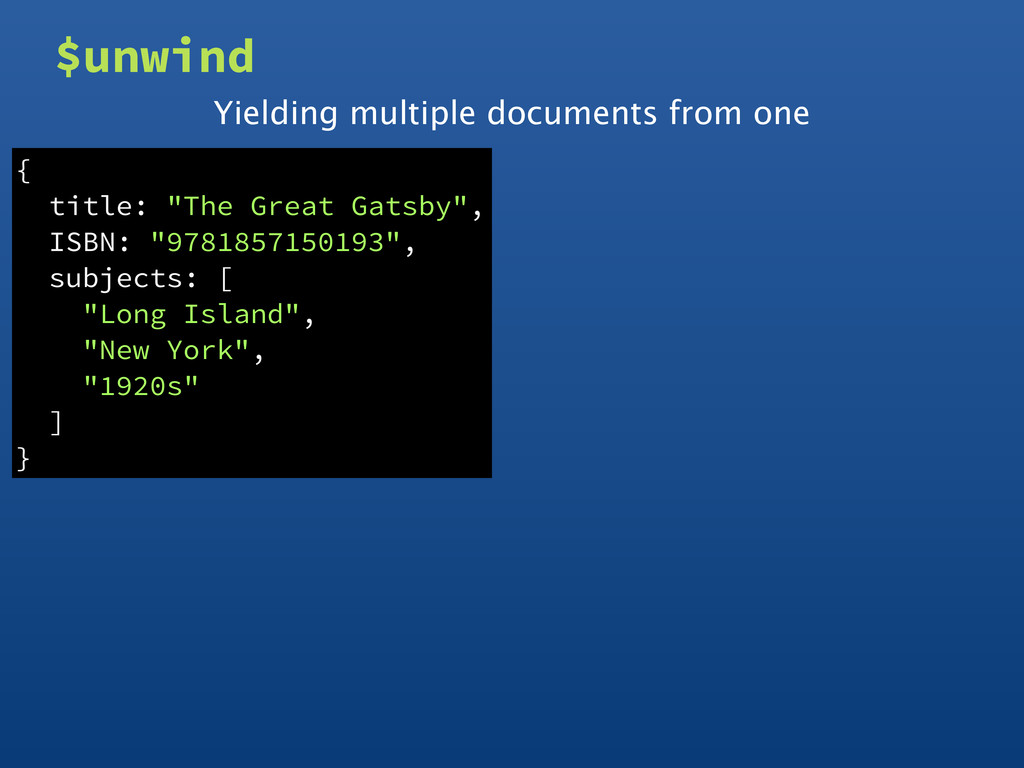
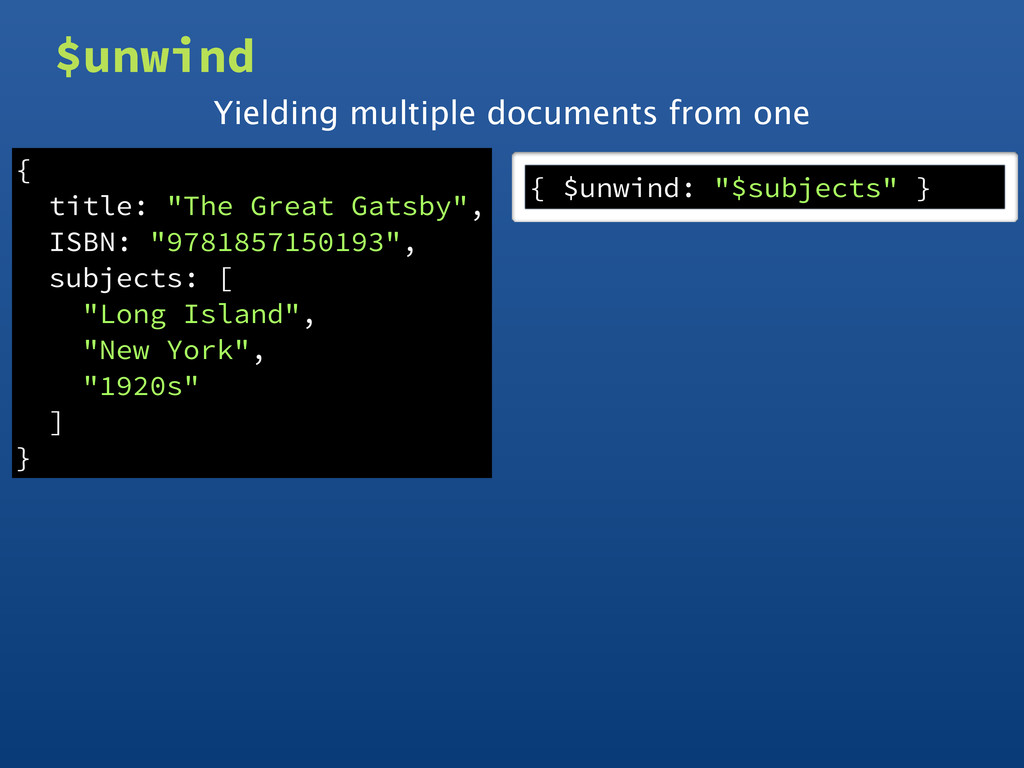
Island", "New York", "1920s" ] } { title: "The Great Gatsby", ISBN: "9781857150193", subjects: [ "Long Island", "New York", "1920s" ] } $unwind Yielding multiple documents from one
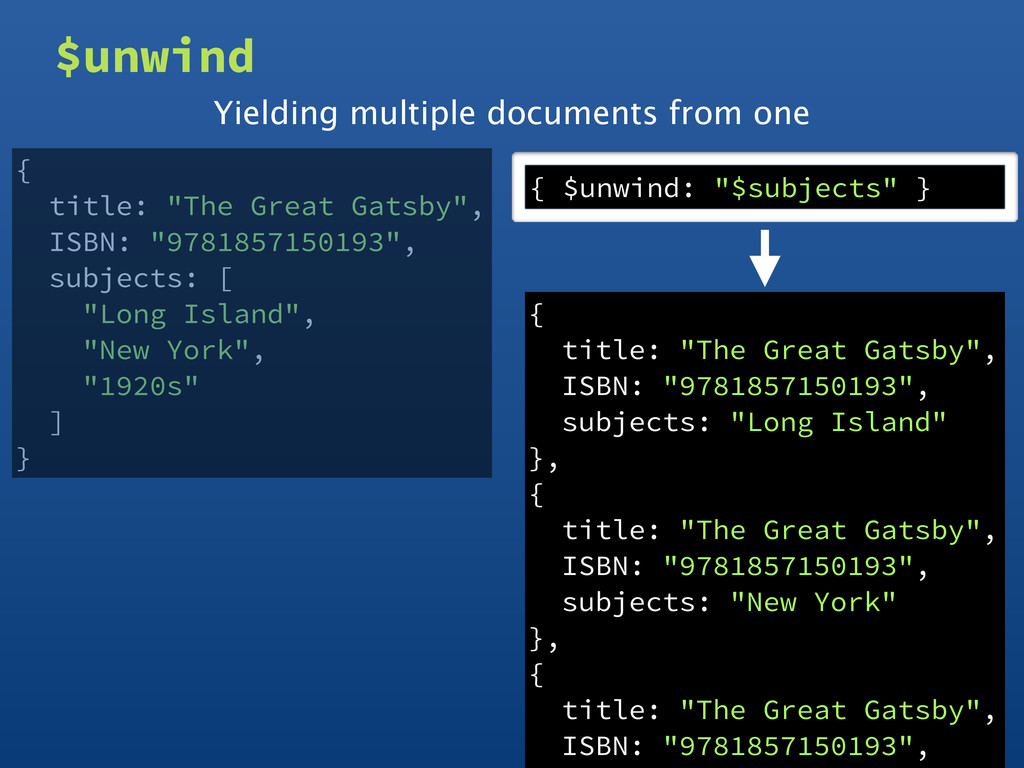
Island", "New York", "1920s" ] } $unwind { $unwind: "$subjects" } { title: "The Great Gatsby", ISBN: "9781857150193", subjects: "Long Island" }, { title: "The Great Gatsby", ISBN: "9781857150193", subjects: "New York" }, { title: "The Great Gatsby", ISBN: "9781857150193", Yielding multiple documents from one
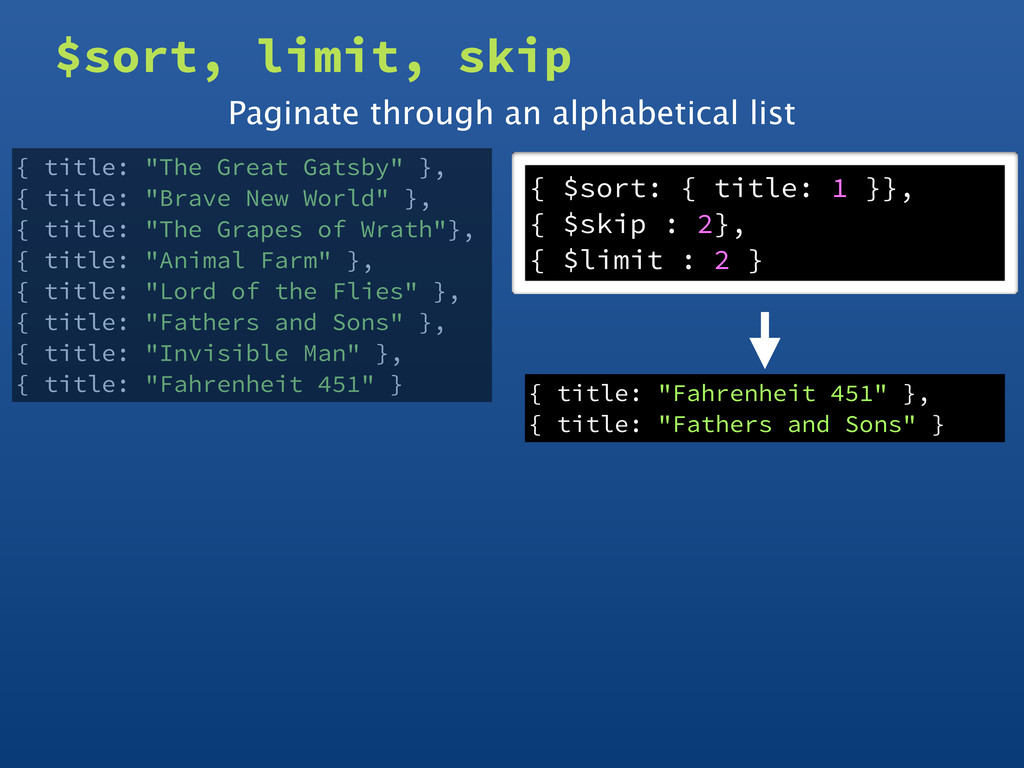
fields • Uses familiar cursor format • Waits for earlier pipeline operator to return • In-memory unless early and indexed $skip • Skip over documents in the pipeline $limit • Skip over documents in the pipeline
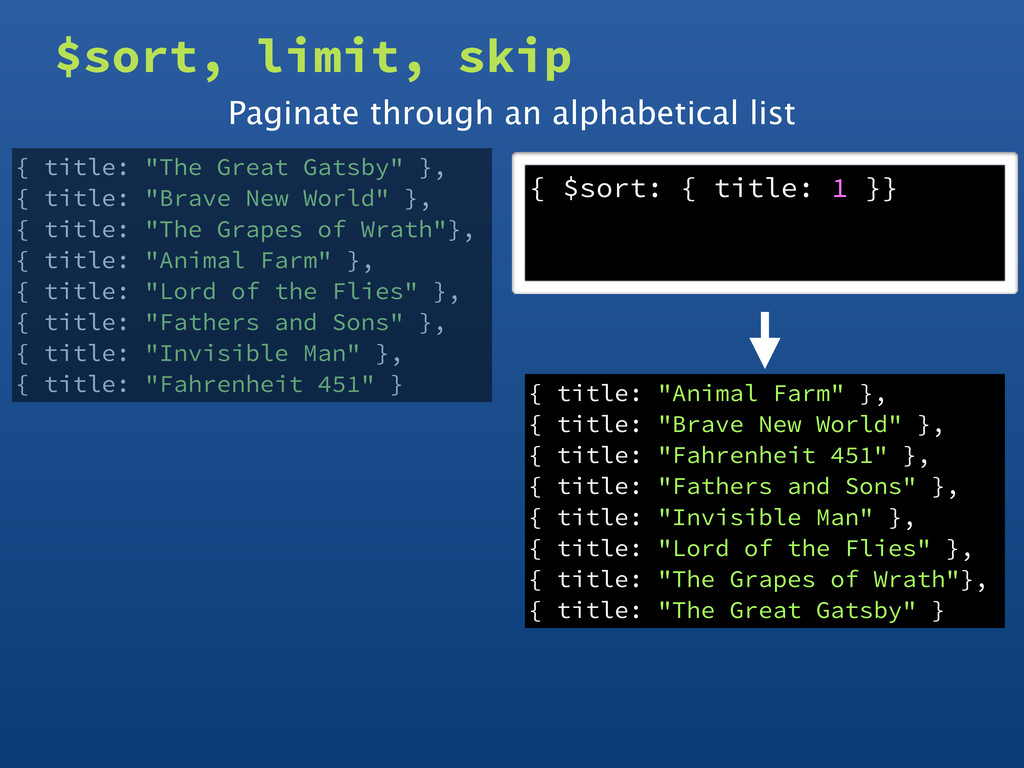
as possible • The query optimizer can then choose to scan an index and avoid scanning the entire collection • Use $sort in a pipeline as early as possible • The query optimizer can then be used to choose an index to scan instead of sorting the result
Saves the document stream to a collection • Similar to M/R $out, but with sharded output • Functions like a tee, so that intermediate results can be saved
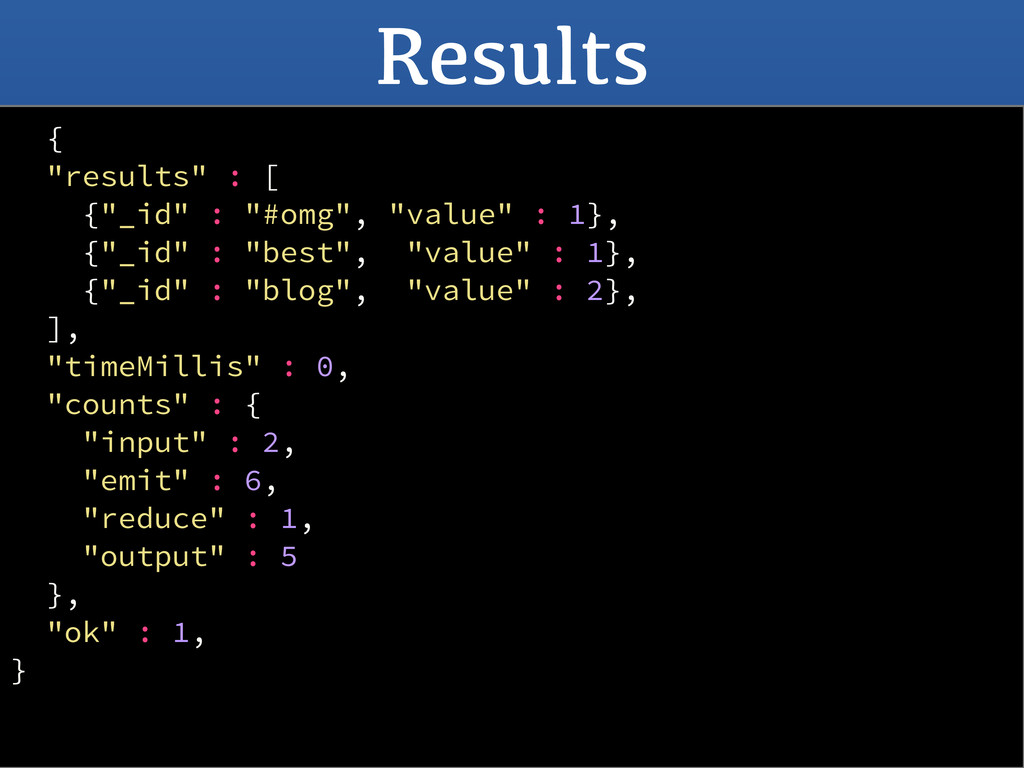
function() { new_date = new Date(this.ts); // Turn the ts into a minute bucket minute = new Date(new_date.setSeconds(0)) emit(minute, this); } r = function(key, values) { var bid = { low: Number.MAX_VALUE, high: Number.MIN_VALUE, count: 0, total: 0, open: 0, open_ts: 0, close: 0, close_ts: 0, } values.forEach(function(v) { var b = v['bid']; var a = v['ask']; var ts = v['ts']; // first - find opening bid in the range if (bid.open_ts == 0) { bid.open_ts = ts; bid.open = b; } else if ( ts < bid.open_ts ) { bid.open_ts = ts; bid.open = b; } // last - final closing bid in the range if (bid.close_ts == 0) { bid.close_ts = ts; bid.close = b; } else if ( ts > bid.close_ts ) { bid.close_ts = ts; bid.close = b; } // max - find max bid for the range if (b > bid.high) { bid.high = b; } // min - find min bid for the range if (b < bid.low) { bid.low = b; } // count - count the number of entries for the range bid.count += 1; // sum - sum the bid for the range bid.total += b; }); return { minute: key, bid: bid}; } f = function(key, obj) { // average - calc the average for if (obj.bid.count > 0){ obj.bid.avg = obj.bid.total / } delete obj.bid.count; delete obj.bid.open_ts; delete obj.bid.close_ts; delete obj.bid.total; delete obj.minute; return obj; } // Run the Map/Reduce db.money.mapReduce(m, r, {out : {in
![Ross Lawley - [email protected] twitter: @RossC0 Aggregation](https://files.speakerdeck.com/presentations/50793317cd5250000205d6e0/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Usage db.col.aggregate() db.runCommand({ aggregate : <col>, pipeline : [] });](https://files.speakerdeck.com/presentations/50793317cd5250000205d6e0/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}