is only three years old 0.8 February 2009 First standalone release 1.0 August 2009 Simple, but used in production 1.2 December 2009 map/reduce, external sort index building 1.4 March 2010 Background indexing, geo 1.6 August 2010 Sharding, replica sets 1.8 March 2011 Journalling, sparse/covered indexes 2.0 September 2012 Compact, concurrency 2.2 July 2012 Concurrency, aggregation framework
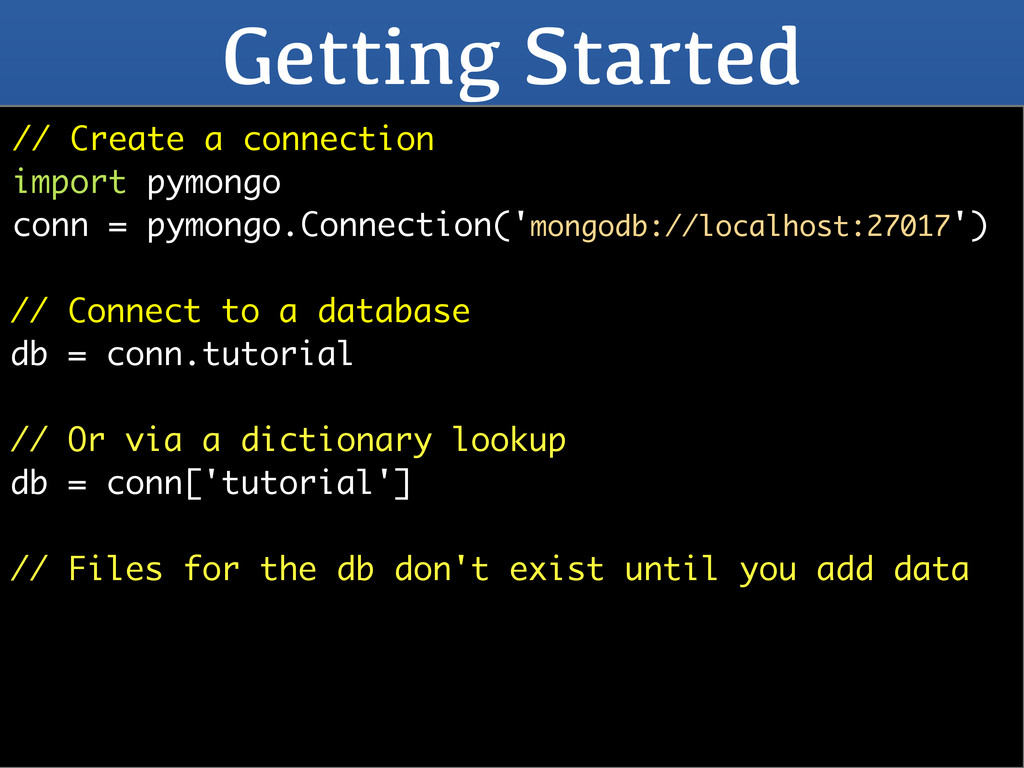
pymongo.Connection('mongodb://localhost:27017') // Connect to a database db = conn.tutorial // Or via a dictionary lookup db = conn['tutorial'] // Files for the db don't exist until you add data
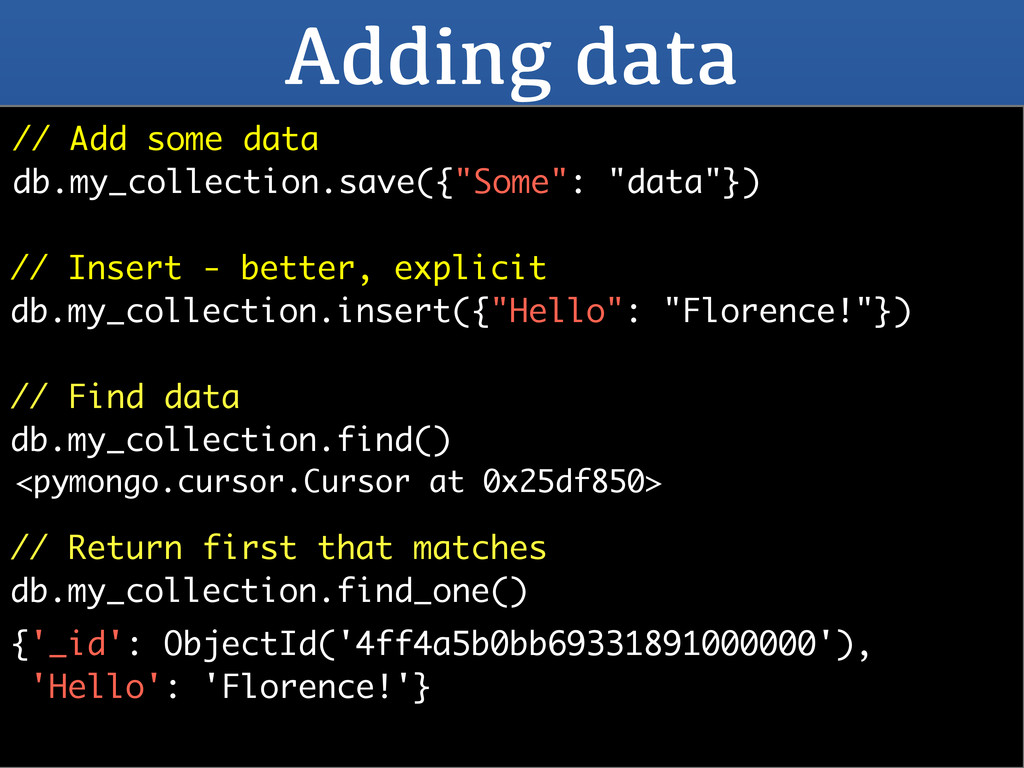
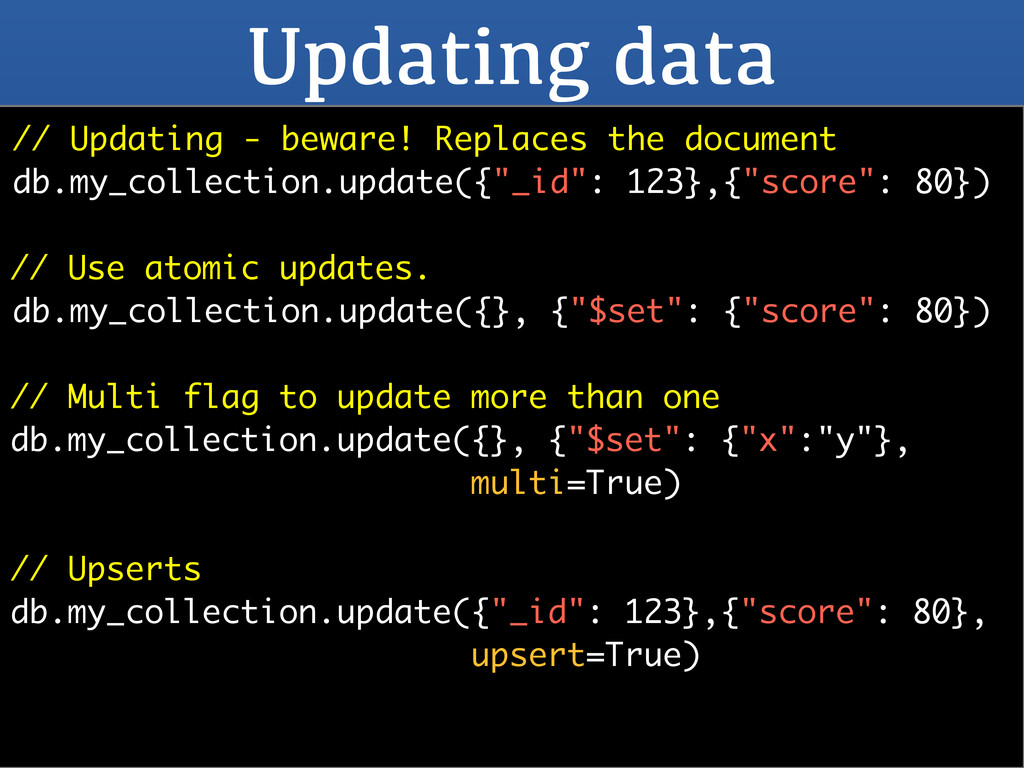
123},{"score": 80}) // Use atomic updates. db.my_collection.update({}, {"$set": {"score": 80}) // Multi flag to update more than one db.my_collection.update({}, {"$set": {"x":"y"}, multi=True) // Upserts db.my_collection.update({"_id": 123},{"score": 80}, upsert=True)
- ORM-like layer on top of PyMongo Ming - Developed by SourceForge MongoAlchemy - Inspired by SQLAlchemy MongoEngine - Inspired by the Django ORM Minimongo - lightweight, pythonic interface
database, collection and query level - Tag nodes and direct writes to specific nodes / data centres Prioritisation - Prefer specific nodes to be primary - Ensure certain nodes are never primary Scaling reads - Not applicable for all applications - Secondaries can be used for backups, analytics, data processing
![Ross Lawley - [email protected] twitter: @RossC0 Building your first app](https://files.speakerdeck.com/presentations/4ff593d2b8b35a001f009330/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
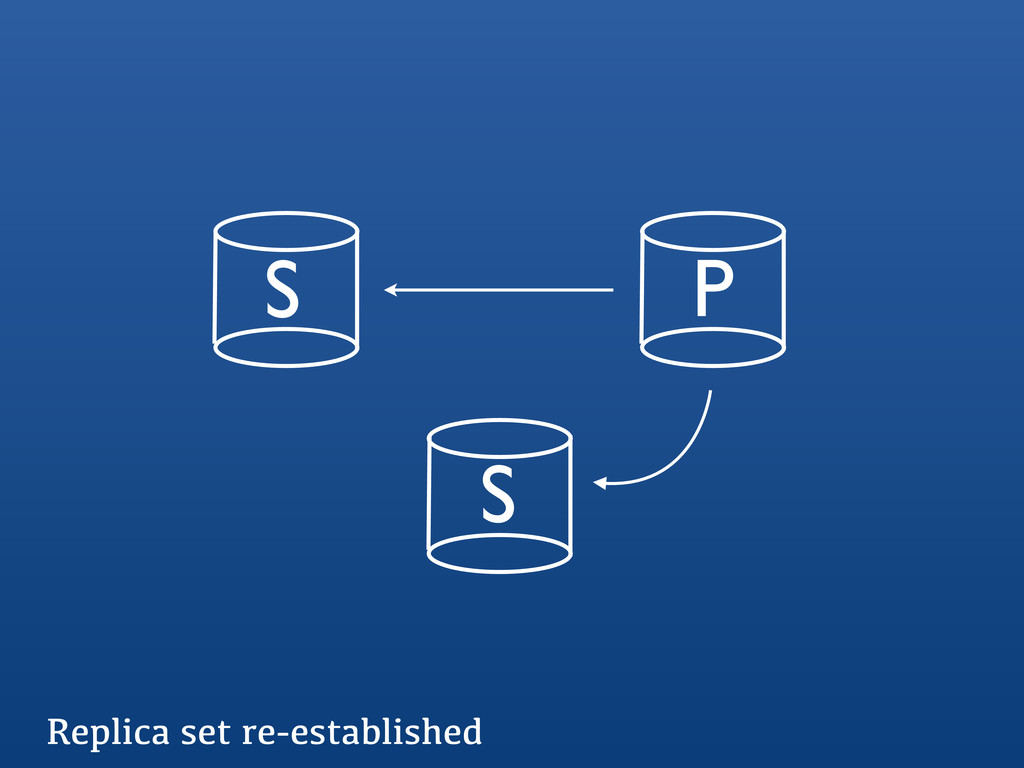{kind=link}
{kind=link}
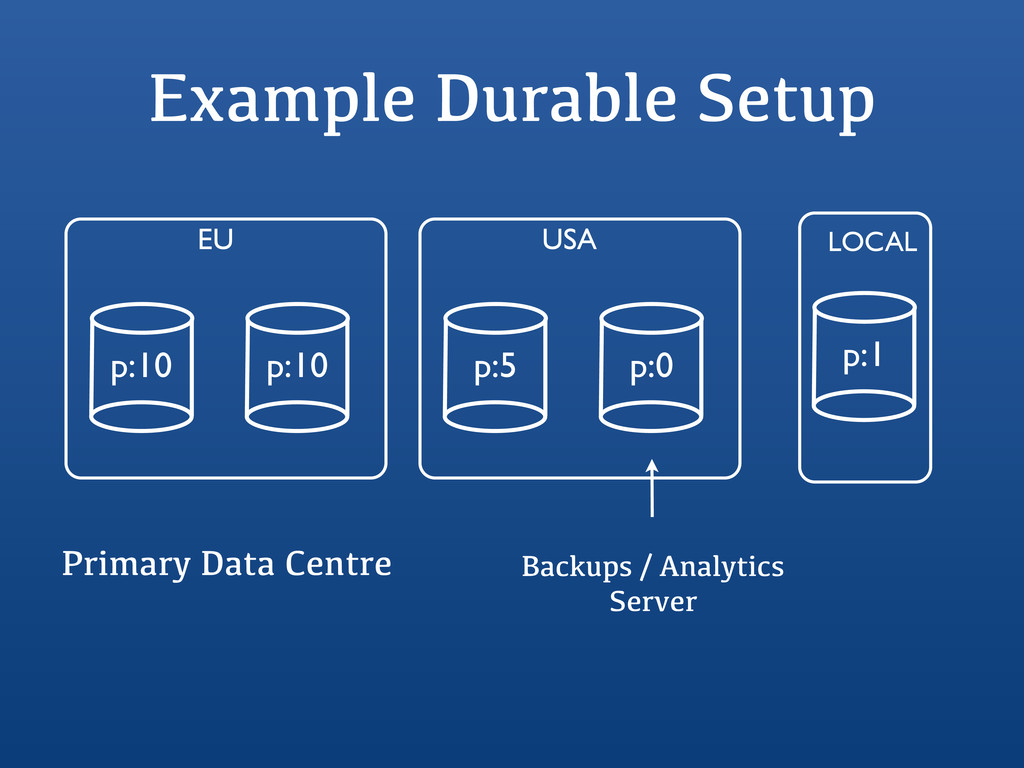{kind=link}
{kind=link}
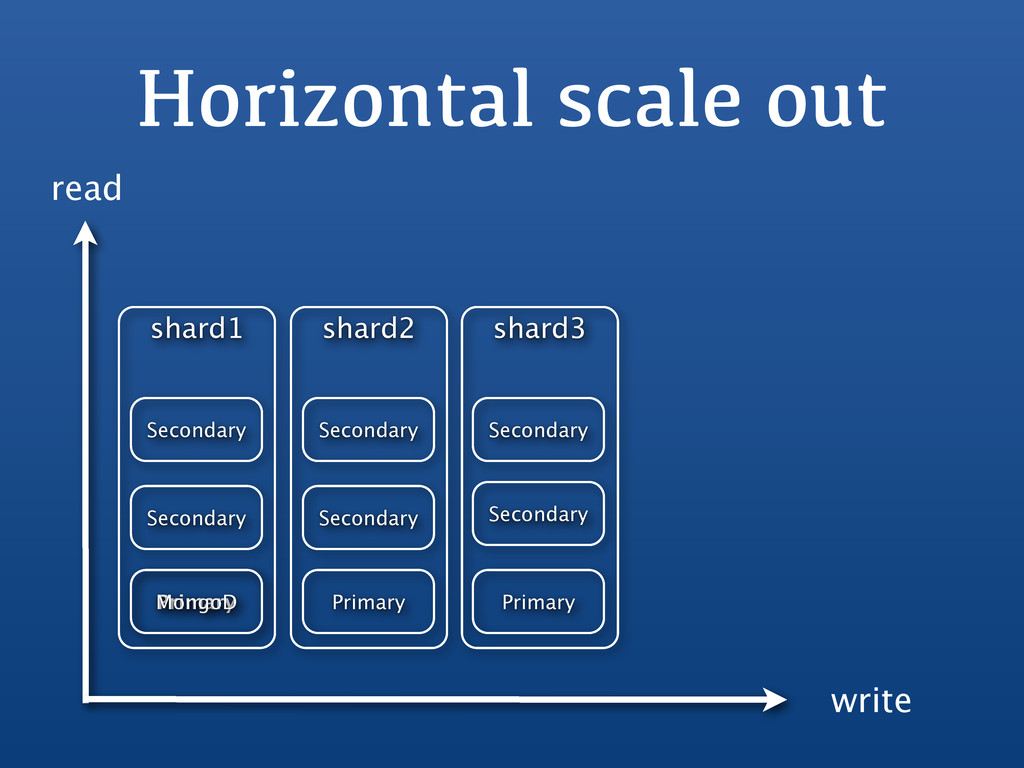{kind=link}
{kind=link}
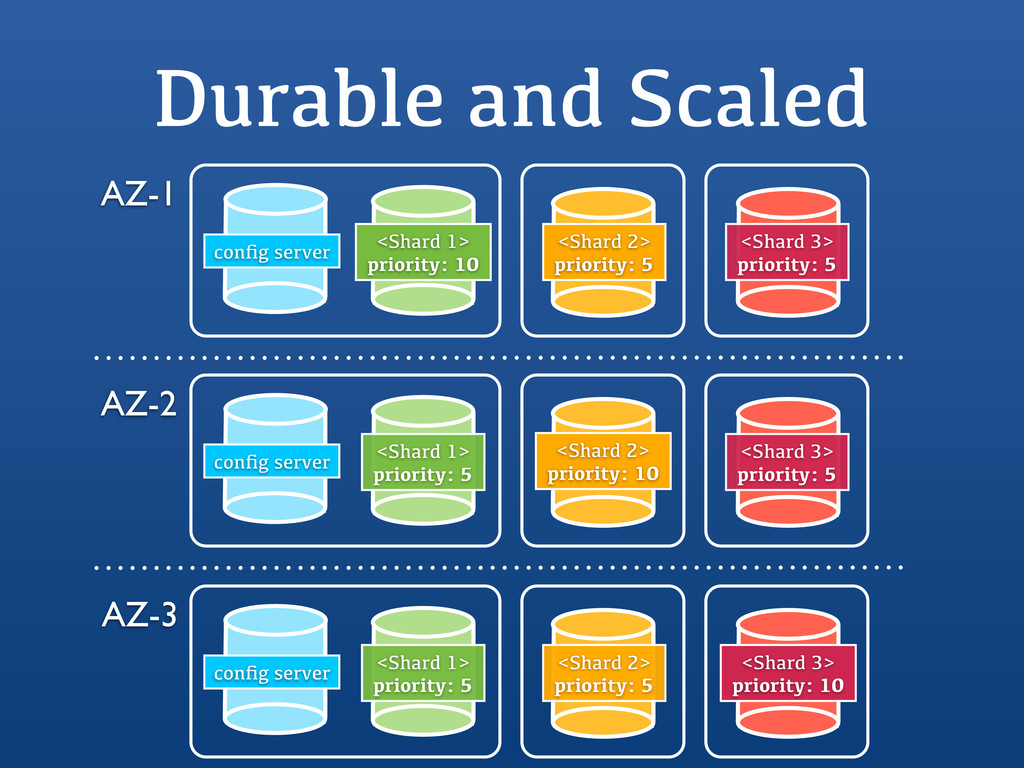{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
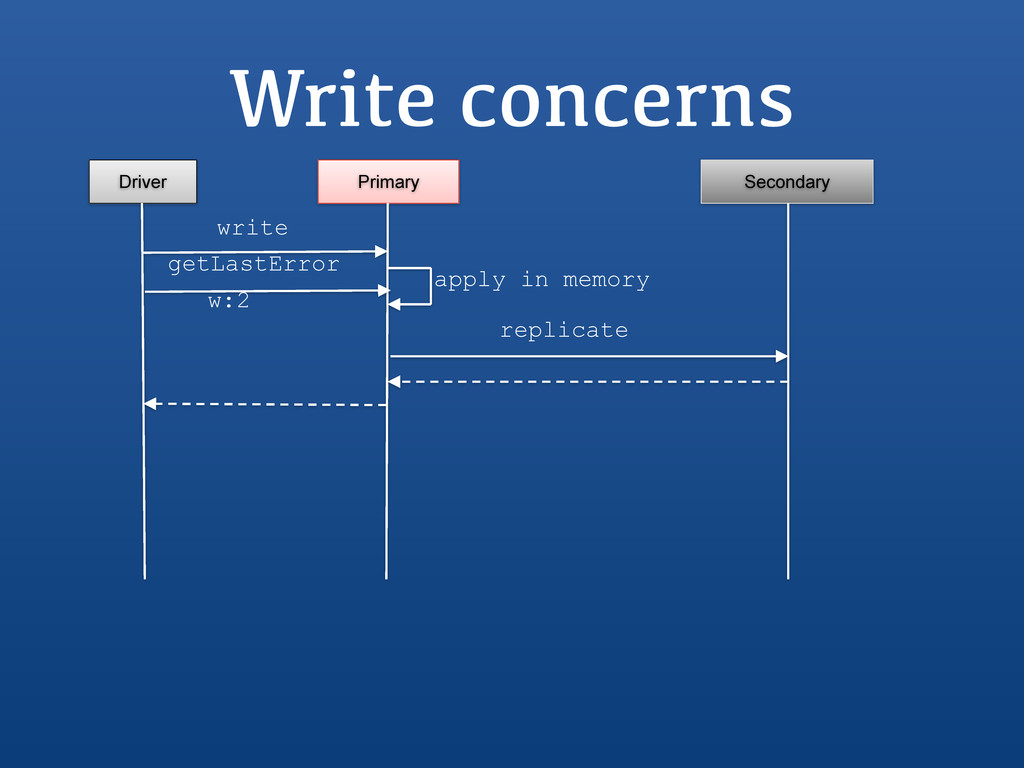{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}