its goal is to make replicated data appear as though there were only a single copy, and to make all operations act on it atomically. Although linearizability is appealing because it is easy to understand—it makes a database behave like a variable in a single-threaded program—it has the downside of being slow, especially in environments with large network delays.」 「We also explored causality, which imposes an ordering on events in a system (what happened before what, based on cause and effect). Unlike linearizability, which puts all operations in a single, totally ordered timeline, causality provides us with a weaker consistency model: some things can be concurrent (2PL, SSI), so the version history is like a timeline with branching and merging. Causal consistency does not have the coordination overhead of linearizability and is much less sensitive to network problems.」 「However, even if we capture the causal ordering (for example using Lamport timestamps), we saw that some things cannot be implemented this way: in “Timestamp ordering is not sufficient” we considered the example of ensuring that a username is unique and rejecting concurrent registrations for the same username. If one node is going to accept a registration, it needs to somehow know that another node isn’t concurrently in the process of registering the same name. This problem led us toward consensus.」 Why we are looking for Consensus For DDIA
nothing (no half-updated state) • Total Order Broadcast • Leader Election Avoid bad failover (split brain, inconsistency, data loss) • Linearizable compare-and-set registers • Locks and Leases • Membership/Coordination Service • … Example Consensus Problems 「situations in which it is important for nodes to agree」
fl ict • Some of the commit requests might be lost in the network • Some node may crash before commit record is fully written • … Atomic Transaction Commit Examples of Distributed Half-Updated State
de fi nitely be able to commit later and waits for the coordinator inde fi nitely, even if it crashes after voting. • When the coordinator has received response to all prepare requests, it makes a de fi nitive decision to commit or abort and then keeps instructing all participants inde fi nitely until all of them acknowledge the decision, even if anyone crashes. What makes 2PC provide atomicity? Two crucial “points of no return”
• Coordinator transaction state participants state decision • Restart network communication based on recovered state. What should be recovered after crash? What storage it needs?
& storage engine (https://www.burnison.ca/notes/fun-mysql-fact-of-the-day-everything-is-two-phase) MySQL NDB/InnoDB Cluster MongoDB Cluster • Heterogeneous distributed transactions XA supported by PostgreSQL, MySQL, ActiveMQ… Exactly(Effectively) Once Message Processing Distributed Transaction in Practice
machine. It is a single point of failure. • If coordinators are embedded into stateless servers, they are stateless anymore. The coordinator storage cannot be discard. • XA doesn’t include deadlocks detection and Serializable Snapshot Isolation. • Amplifying failures. No progress if someone fails Limitations of 2PC
or more nodes may propose values, and the consensus algorithm decides on one of those values. • In this formalism, a consensus algorithm must satisfy the following properties: • Uniform agreement No two nodes decide differently. No split brain. • Integrity No node decides twice, no change mind. • Validity If a node decides value v, then v was proposed by some node. • Termination Majority of nodes that do not crash eventually decides some value. It can’t have no decision forever. Fault-Tolerant Consensus Informally, consensus means getting several nodes to agree on something
once, in the same order, to all nodes. • It is equivalent to repeated rounds of consensus: • Due to the agreement property of consensus, all nodes decide to deliver the same messages in the same order. • Due to the integrity property, messages are not duplicated. • Due to the validity property, messages are not corrupted and not fabricated out of thin air. • Due to the termination property, messages are not lost. How to dive into Consensus? Total Order Broadcast
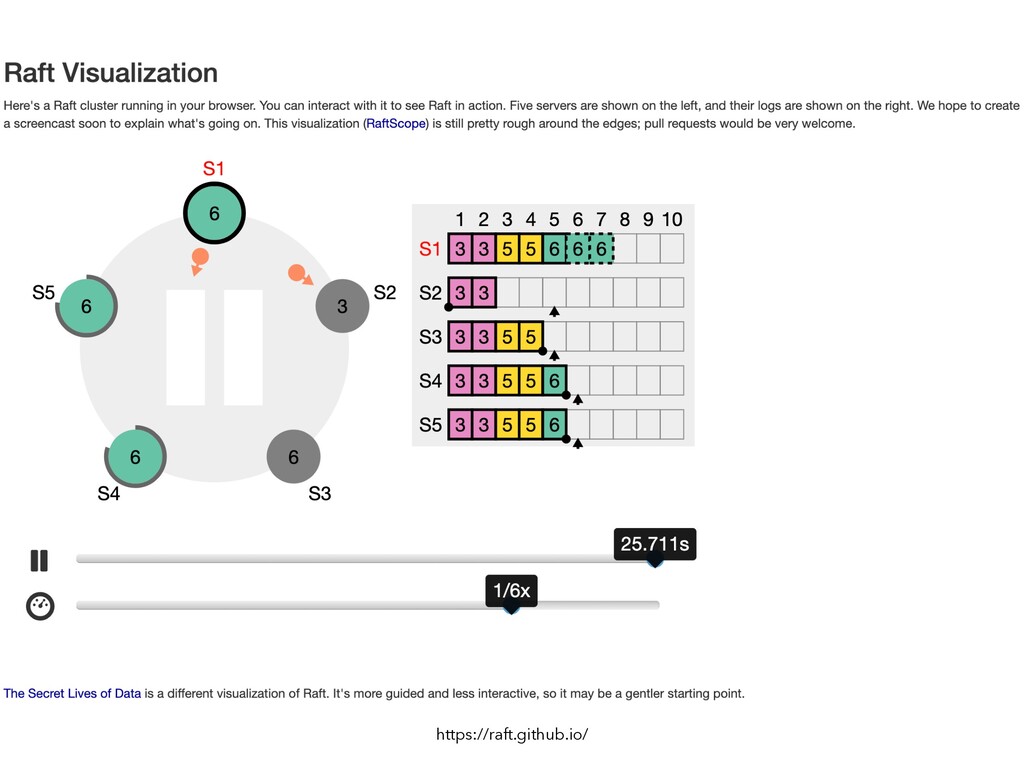
Followers”), which takes all the writes to the leader and applies them to the followers in the same order, thus keeping replicas up to date. Isn’t this essentially total order broadcast? How come we didn’t have to worry about consensus in Chapter 5? The answer comes down to how the leader is chosen.」 「Some databases perform automatic leader election and failover, promoting a follower to be the new leader if the old leader fails (see “Handling Node Outages”). This brings us closer to fault-tolerant total order broadcast, and thus to solving consensus.」 「However, there is a problem. All nodes need to agree who the leader is— otherwise split brain. Thus, we need consensus in order to elect a leader. But if the consensus algorithms described here are actually total order broadcast algorithms, and total order broadcast is like single-leader replication, and single-leader replication requires a leader, then… It seems that in order to elect a leader, we first need a leader. In order to solve consensus, we must first solve consensus. How do we break out of this conundrum?」 How to dive into Consensus?
Zab • They are hard to implement, follow these notes when implementing. • http://blog.willportnoy.com/2012/06/lessons-learned-from-paxos.html • http://www.read.seas.harvard.edu/~kohler/class/08w-dsi/chandra07paxos.pdf • https://www.cockroachlabs.com/blog/consensus-made-thrive/ Consensus Implementations
use a leader in some form or another, but they don’t guarantee that the leader is unique. Instead, they can make a weaker guarantee: the protocols de fi ne an epoch number and guarantee that within each epoch, the leader is unique. • Every time the current leader is thought to be dead, a vote is started among the nodes to elect a new leader. This election is given an incremented epoch number, and thus epoch numbers are totally ordered and monotonically increasing. If there is a con fl ict between two different leaders in two different epochs, then the leader with the higher epoch number prevails. • Before a leader is allowed to decide anything, it must fi rst check that there isn’t some other leader with a higher epoch number which might take a con fl icting decision by collecting votes from a quorum of nodes. A node votes in favor of a proposal only if it is not aware of any other leader with a higher epoch Consensus Epoch and Quorums
to choose a leader, and a second time to vote on a leader’s proposal. • The key insight is that the quorums for those two votes must overlap: if a vote on a proposal succeeds, at least one of the nodes that voted for it must have also participated in the most recent leader election [Flexible Paxos]. • Thus, if the vote on a proposal does not reveal any higher- numbered epoch, the current leader can conclude that no leader election with a higher epoch number has happened, and therefore be sure that it still holds the leadership. It can then safely decide the proposed value. Consensus Epoch and Quorums
two-phase commit. The biggest differences are that in 2PC the coordinator is not elected, and that fault-tolerant consensus algorithms only require votes from a majority of nodes, whereas 2PC requires a “yes” vote from every participant. • Moreover, consensus algorithms de fi ne a recovery process by which nodes can get into a consistent state after a new leader is elected, ensuring that the safety properties are always met. These differences are key to the correctness and fault tolerance of a consensus algorithm. Consensus Epoch and Quorums
con fi rmed). • Minimum of 3 nodes to tolerate 1 failure. Minimum of 5 nodes to tolerate 2 failure. • Network sensitive, unnecessary leader elections result in terrible performance because the system can end up spending more time choosing a leader than doing any useful work. Designing algorithms that are more robust to unreliable networks is still an open research problem. • 「Raft has been shown to have unpleasant edge cases [106]: if the entire network is working correctly except for one particular network link that is consistently unreliable, Raft can get into situations where leadership continually bounces between two nodes, or the current leader is continually forced to resign, so the system effectively never makes progress. 」 Limitations of Consensus Costs What? https://zhuanlan.zhihu.com/p/55658164
98], implementing not only total order broadcast (and hence consensus), but also an interesting set of other features that turn out to be particularly useful when building distributed systems • Linearizable atomic compare-and-set operations (provide lock interface) • Total ordering of operations (monotonically increased fencing token to prevent client pause or any con fl ict) • Failure detection (declare dead sessions and release their locks) • Change noti fi cations • Strong Consistent Client Cache (Chubby Only) • Use cases: • Allocating work to nodes (ex. Leader Election) • Service discovery (readonly replica cache, may be stale) • Membership services (determines nodes are active or dead) Membership and Coordination Services Outsourcing Consensus to ZooKeeper
single threaded and slow. • We then try capturing causality which allow some concurrency, but it still have some cases for all nodes to agree with. (Ex. Distributed Lock, Uniqueness Constraint) • 2PC is kind of consensus, coordinator must keep retrying until succeed, but not fault tolerant. (coordinator is the single point of failure, also no participants can die) • Most Consensus algorithms use two rounds of voting: once to choose a leader, and a second time to vote on a leader’s proposal. Those two votes must overlap • For DDIA, use outsourced consensus service and a proven algorithm that correctly handles adverse network conditions [https://aphyr.com/posts/ 323-jepsen-elasticsearch-1-5-0] [https://www.elastic.co/blog/a-new-era-for- cluster-coordination-in-elasticsearch] Summary
with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions Spanner • Features • Externally consistent (linearizability) read and write transaction distributed at global scale • Global consistent reads across the database at a timestamp • Auto balanced data distribution across machine and datacenter • Application can specify constraints which datacenter contain which data • Supported Client Operation:
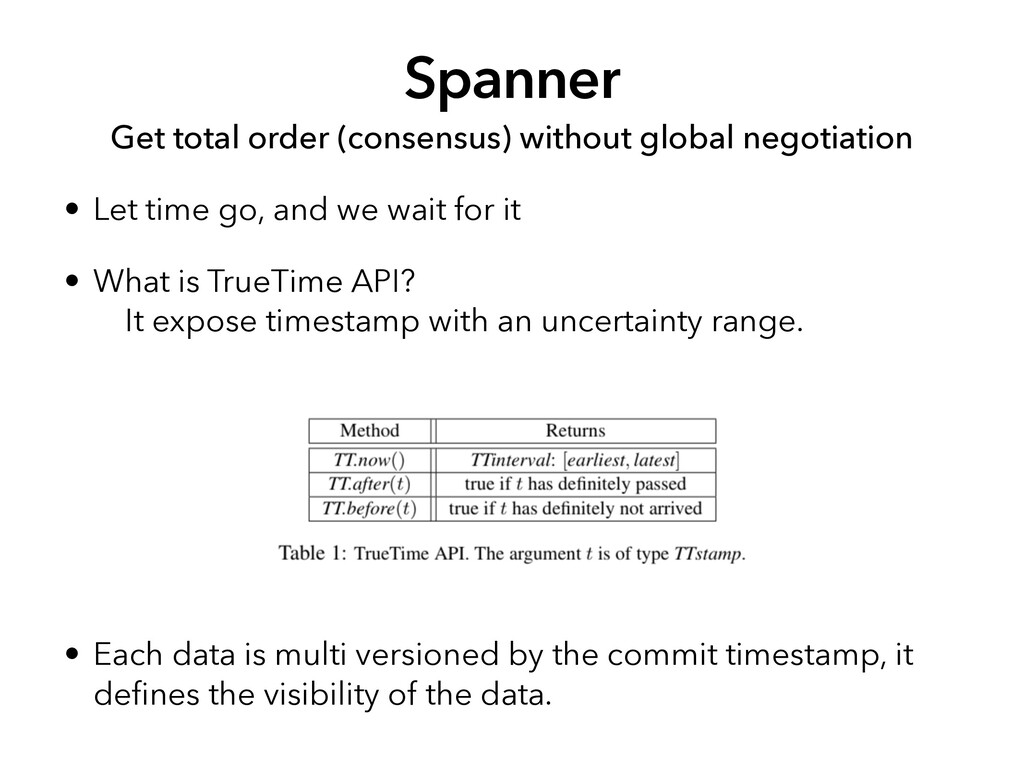
time go, and we wait for it • What is TrueTime API? It expose timestamp with an uncertainty range. • Each data is multi versioned by the commit timestamp, it de fi nes the visibility of the data.
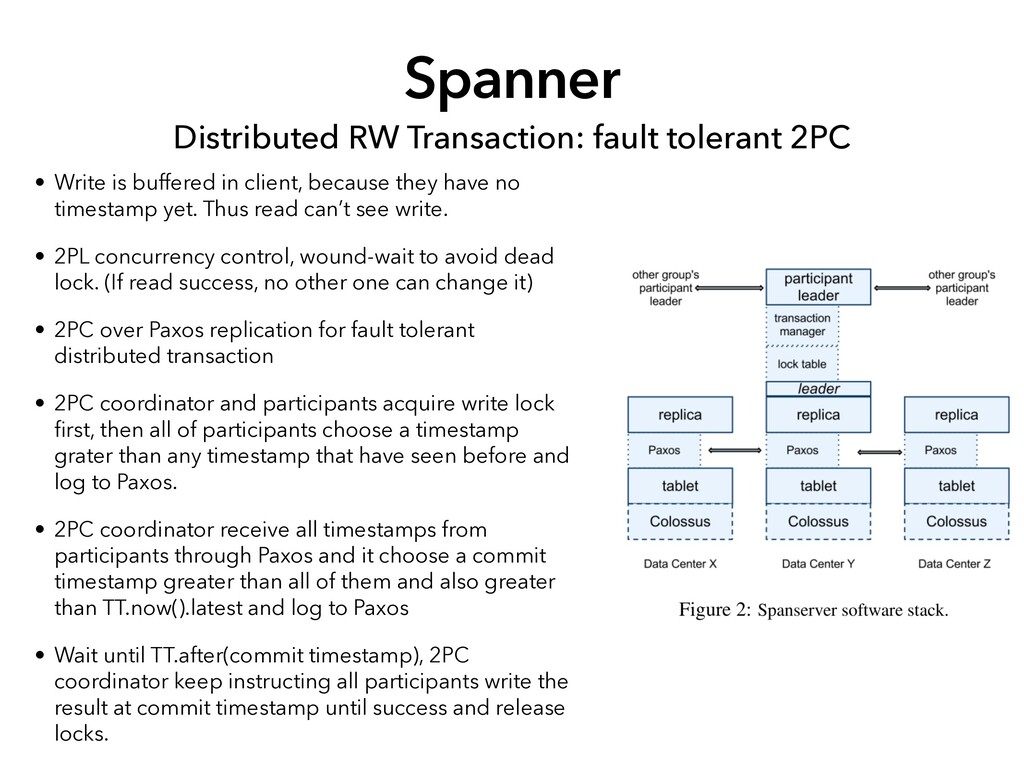
buffered in client, because they have no timestamp yet. Thus read can’t see write. • 2PL concurrency control, wound-wait to avoid dead lock. (If read success, no other one can change it) • 2PC over Paxos replication for fault tolerant distributed transaction • 2PC coordinator and participants acquire write lock fi rst, then all of participants choose a timestamp grater than any timestamp that have seen before and log to Paxos. • 2PC coordinator receive all timestamps from participants through Paxos and it choose a commit timestamp greater than all of them and also greater than TT.now().latest and log to Paxos • Wait until TT.after(commit timestamp), 2PC coordinator keep instructing all participants write the result at commit timestamp until success and release locks.
timestamp for read only transaction for consistency across multi versions. • If the transaction is single statement, Spanner automatically fi nd out the related Paxos groups. • Otherwise user needs to specify the “scope expression” to let spanner fi nd out the related Paxos groups before transaction starts. • If only one Paxos group involved, Spanner choose LastTS() of the group as read timestamp. • If multiple Paxos group involved, Spanner choose TT.now().latest without negotiation, and wait for required replicas catching up.
Cockroach DB • Clocks are allowed to drift away from each other up to a con fi gured "maximum clock offset" (by default 500ms) • Provides more than serializable isolation (no stale read), but not linearizability. • If transaction observe data timestamp within uncertainty range, it shrinks its uncertainty range up from the timestamp, and may restart or abort transaction, while spanner always wait s after writes. • https://www.cockroachlabs.com/blog/living-without-atomic- clocks/ • https://www.cockroachlabs.com/blog/consistency-model/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}