(Univ. Paris Saclay, CNRS, CentraleSupélec, L2S)
Title — Statistical and Computational Complexity of the Feature Matching Map Detection Problem
Abstract — The problem of finding the best matching between two point clouds has been extensively studied, both theoretically and experimentally. The matching problem arises in various applications, for instance in computer vision, bioinformatics and natural language processing. In computer vision, finding the correspondence between two sets of local descriptors extracted from two images of the same scene is a well-known example of a matching problem. When datasets do not contain outliers, meaning that both matching sets have the same size and all points have their corresponding match in the other dataset, the optimality of the matching procedures was previously studied from a minimax statistical viewpoint. Clearly, in aforementioned applications, not all the points have their matching point and one can hardly know in advance how many points have their corresponding matching points. This work focuses on various extended settings of the problem (i.e. containing outliers) and gaining a theoretical understanding of the statistical limitations of the matching problem.
{kind=link}
{kind=link}
{kind=link}
![Mathematical formulation of the problem • Notation: [n] = {1,](https://files.speakerdeck.com/presentations/c6bc1405b96e493abe4779f59f6260ae/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Upper bound for LSL πLSL n,m ≜ arg min π:[n]→[m]](https://files.speakerdeck.com/presentations/c6bc1405b96e493abe4779f59f6260ae/slide_11.jpg){kind=link}
{kind=link}
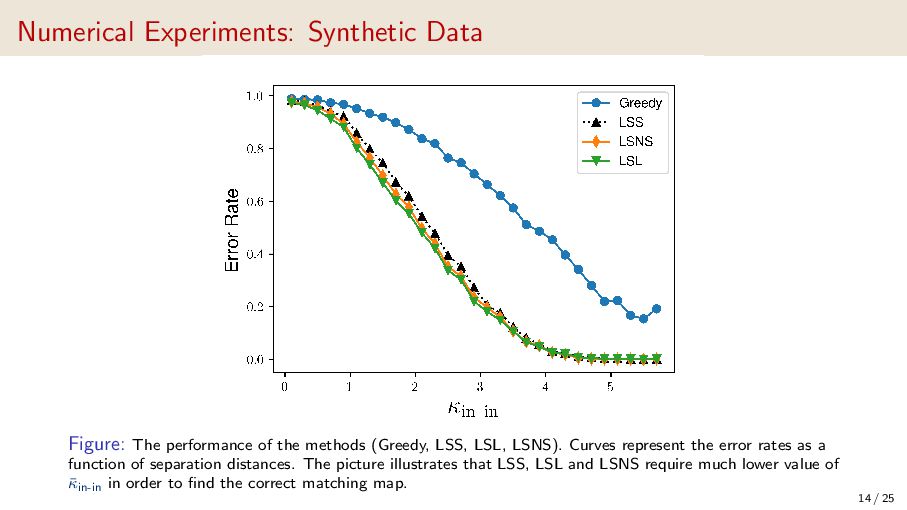{kind=link}
{kind=link}
{kind=link}
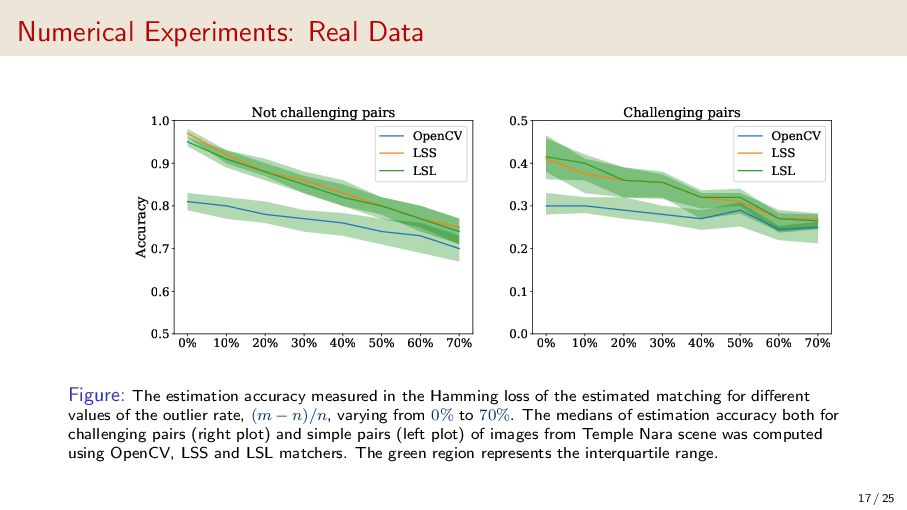{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
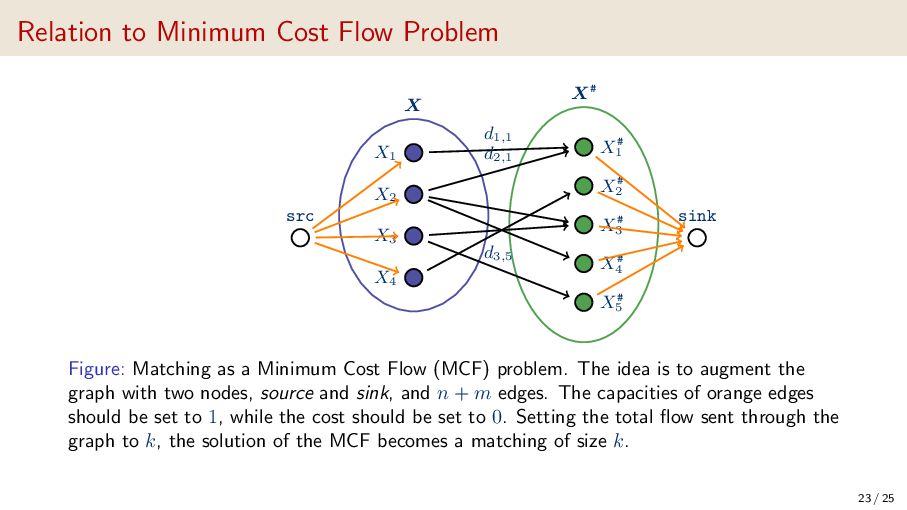{kind=link}
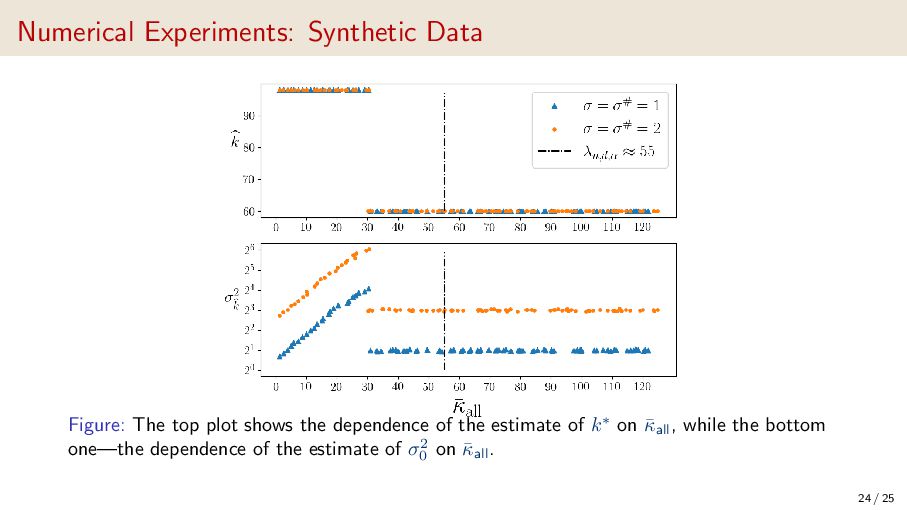{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
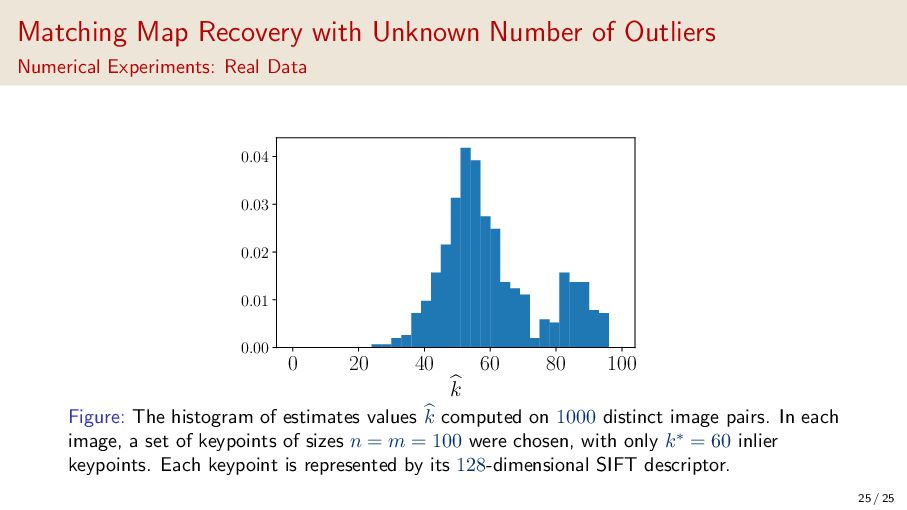{kind=link}