非構造化での Data Store にて実施 b. クエリファイル: クエリリスト、最低100個 c. コーパスファイル: スニペットリスト、クエリごとに最低1個 d. スコア: 0~10の評価値 e. トレーニングラベルファイルでスコアとともに紐づける https://docs.cloud.google.com/generative-ai-app-builder/docs/tune-search
での 評価値を見ることができる a. 本データでの評価は Evaluation の機能を利用する 3. 個人的見解 a. 数日かかることもザラにある b. コストがかかり、データを作るのも大変なため、同義語でできないかを考える https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/search/tuning/ vertexai-search-tuning.ipynb?hl=ja
ドキュメントに見えてはいけないものがあった場合に検知、防御する i. お客様情報(電話番号、住所)、token など b. タイミング i. なるべくコストを減らすため、パイプラインを走らせる前に検査 ii. 検査に引っかかった場合に秘匿するか、そのまま破棄するかを決定 https://docs.cloud.google.com/sensitive-data-protection/docs/concepts-actions?hl=ja
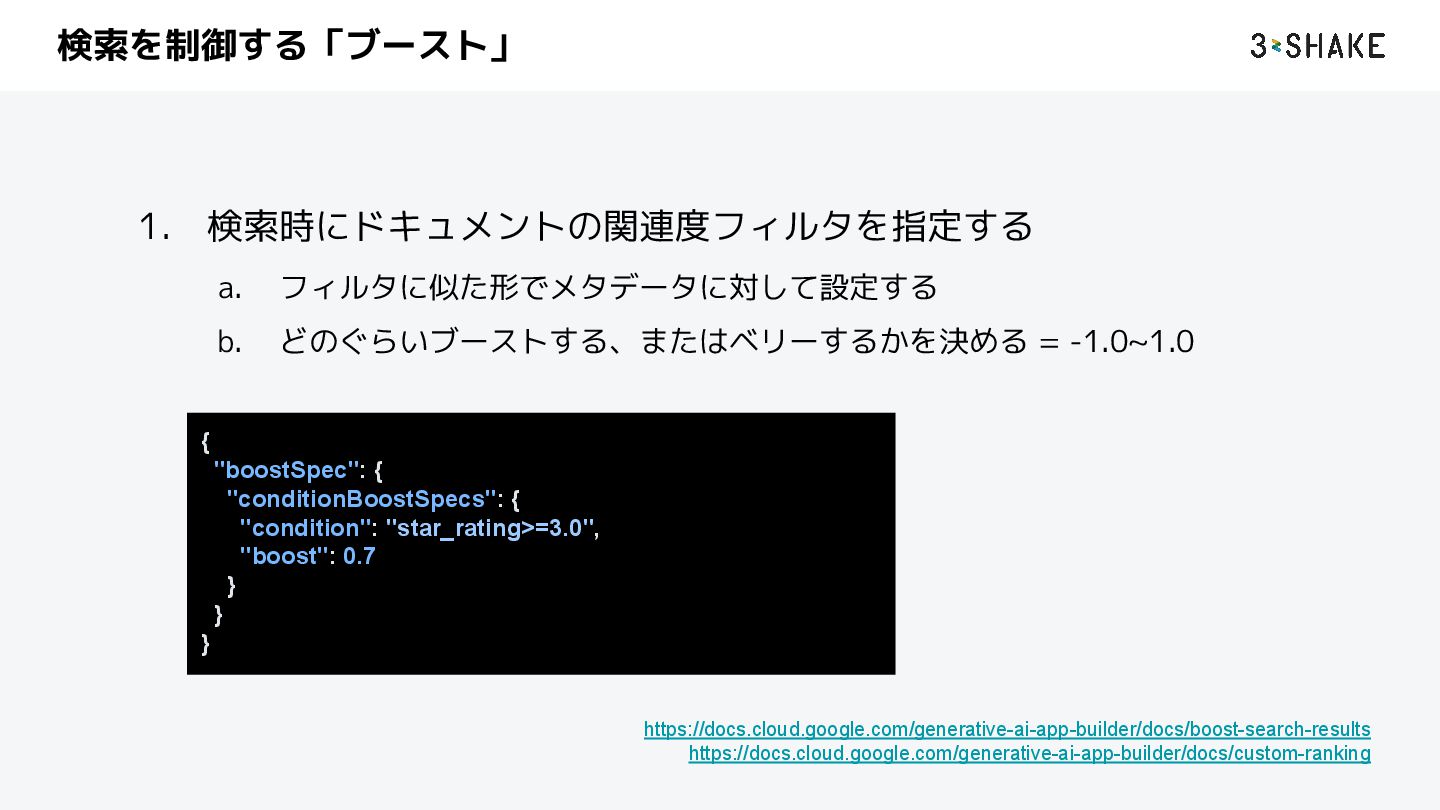
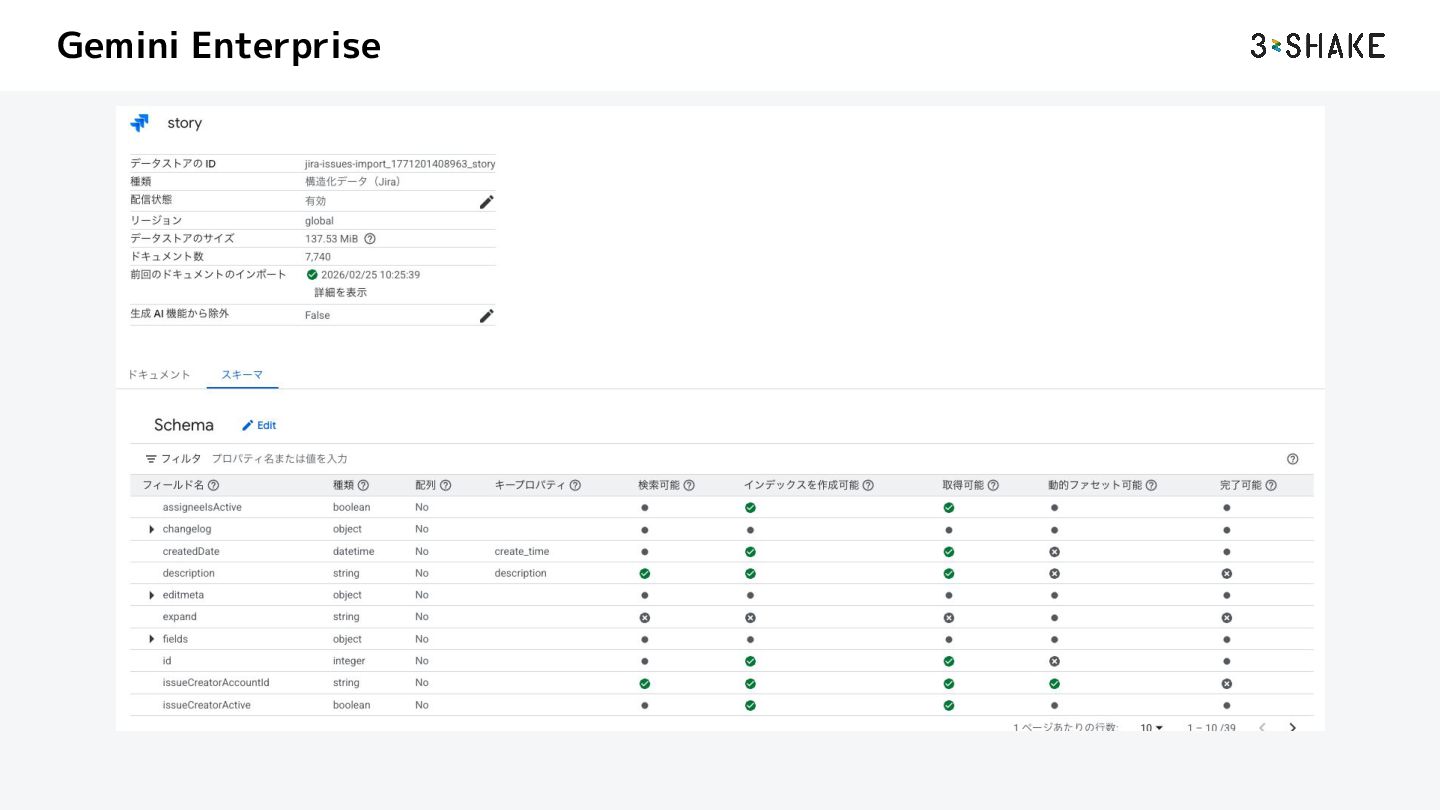
3rd Party などのコネクタのものは、パイプラインに ついてブラックボックスとなっているため、制御ができない b. 更に Federation Connector になれば API 通信なので余計に何もできない 2. できるのは以下の変更だけ a. ブーストやフィルタの値 b. スキーマの設定値
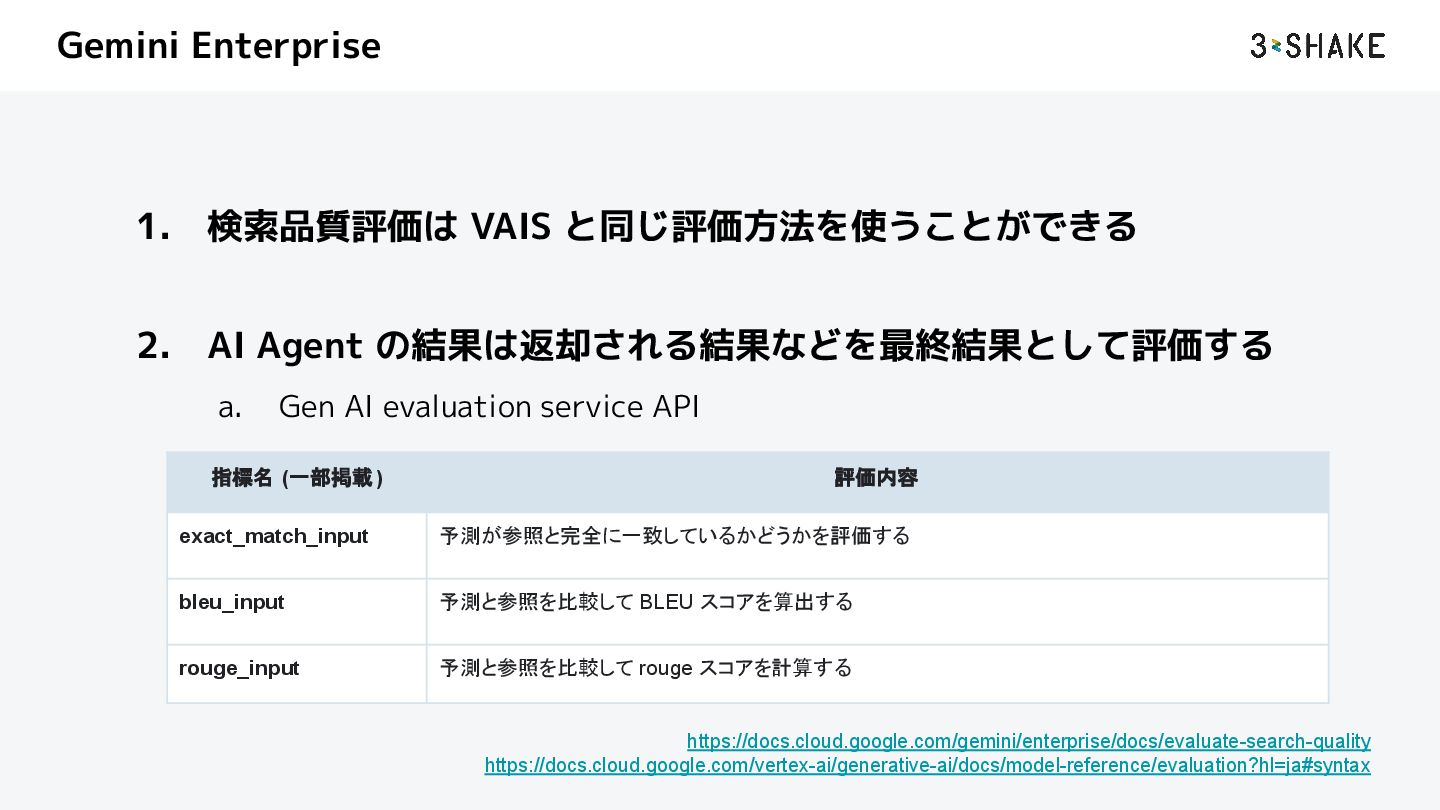
a. Gen AI evaluation service API https://docs.cloud.google.com/gemini/enterprise/docs/evaluate-search-quality https://docs.cloud.google.com/vertex-ai/generative-ai/docs/model-reference/evaluation?hl=ja#syntax 指標名 (一部掲載) 評価内容 exact_match_input 予測が参照と完全に一致しているかどうかを評価する bleu_input 予測と参照を比較して BLEU スコアを算出する rouge_input 予測と参照を比較して rouge スコアを計算する
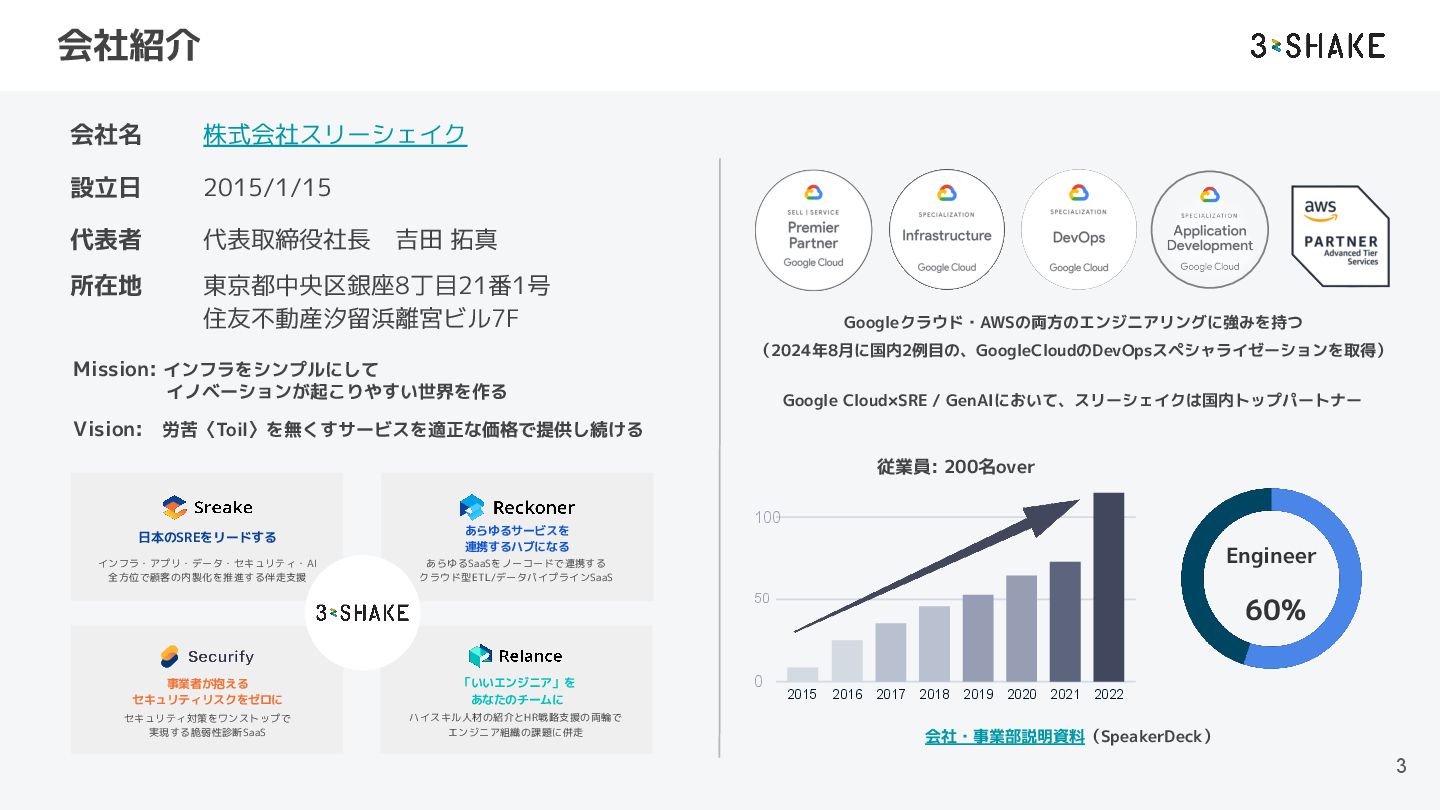
{kind=link}
{kind=link}
{kind=link}
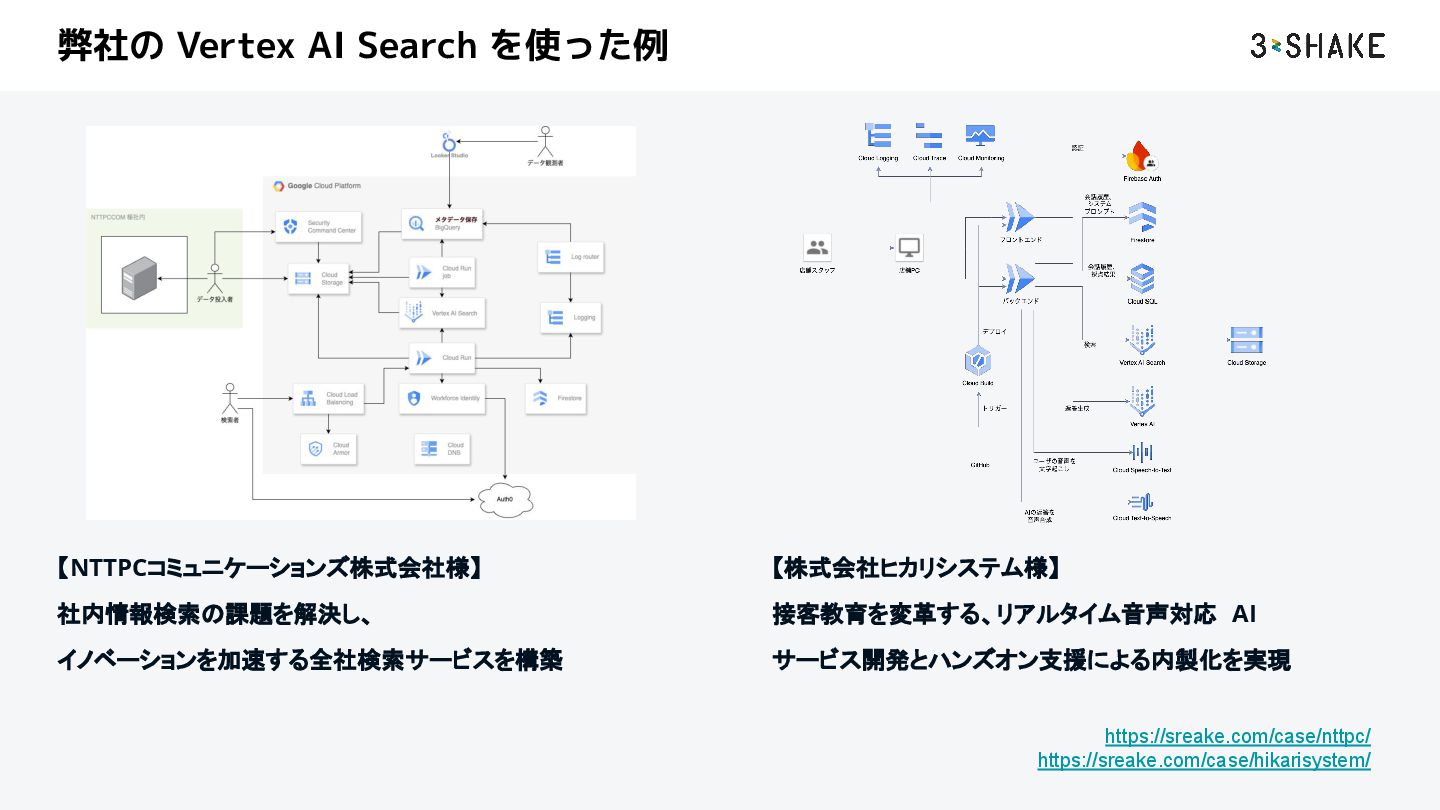{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
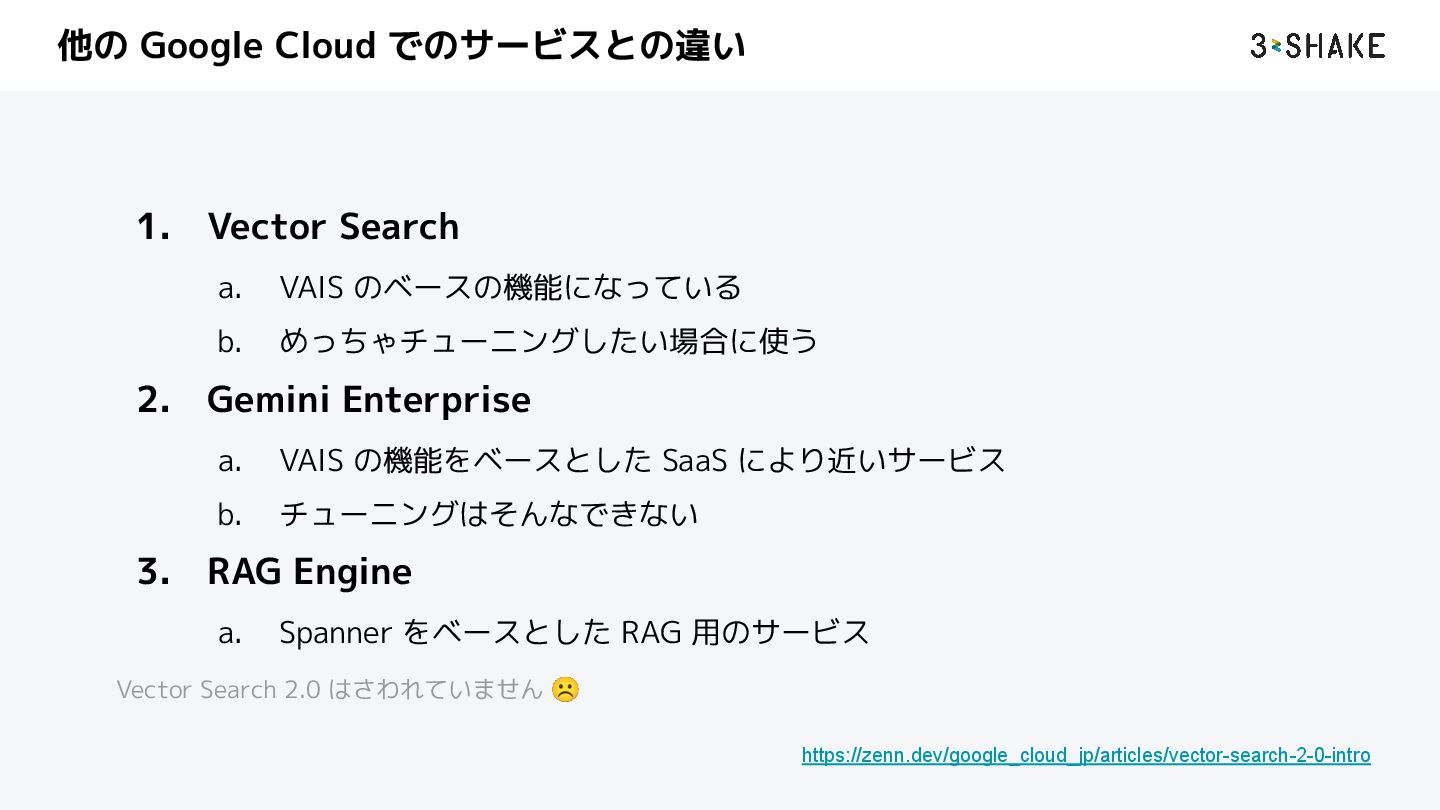{kind=link}
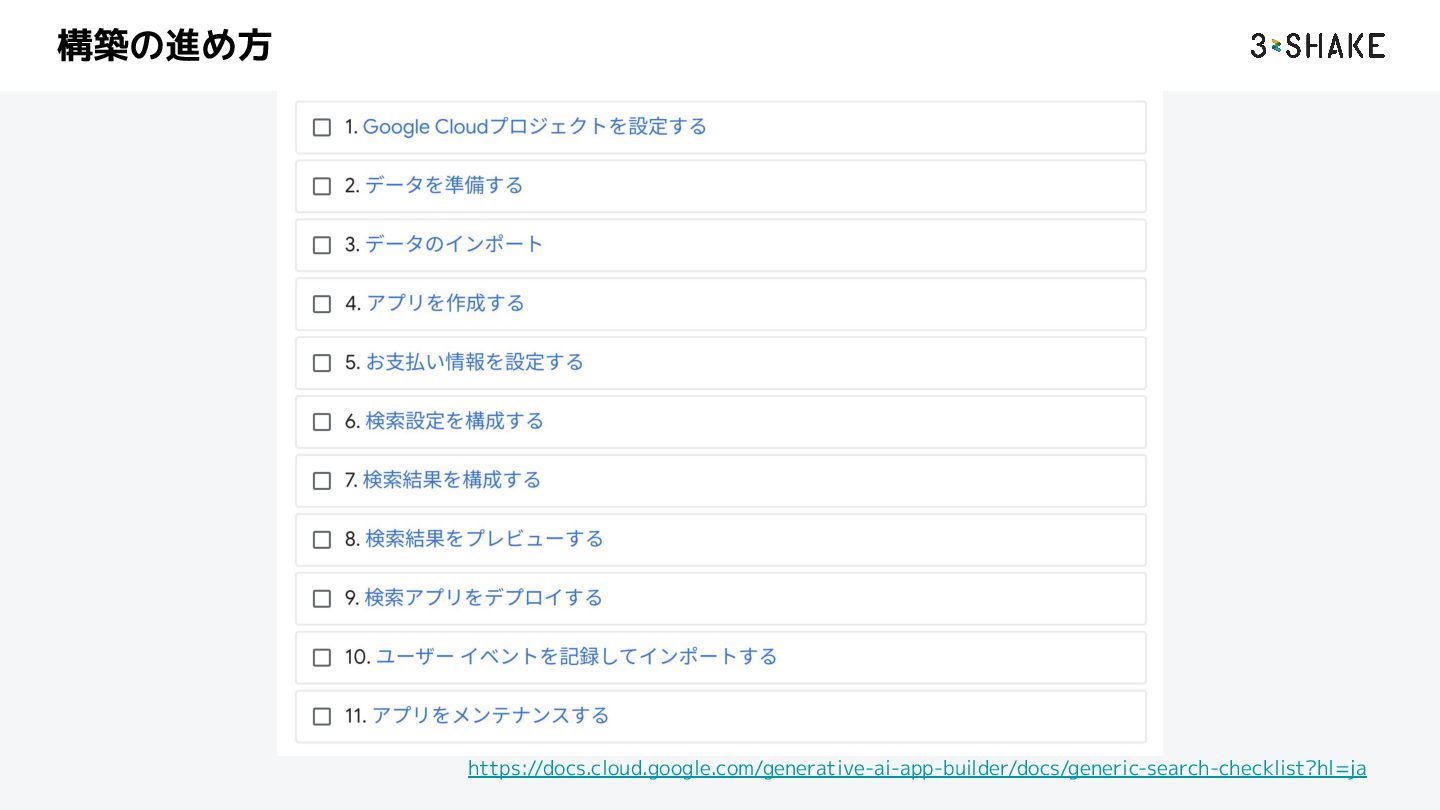{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
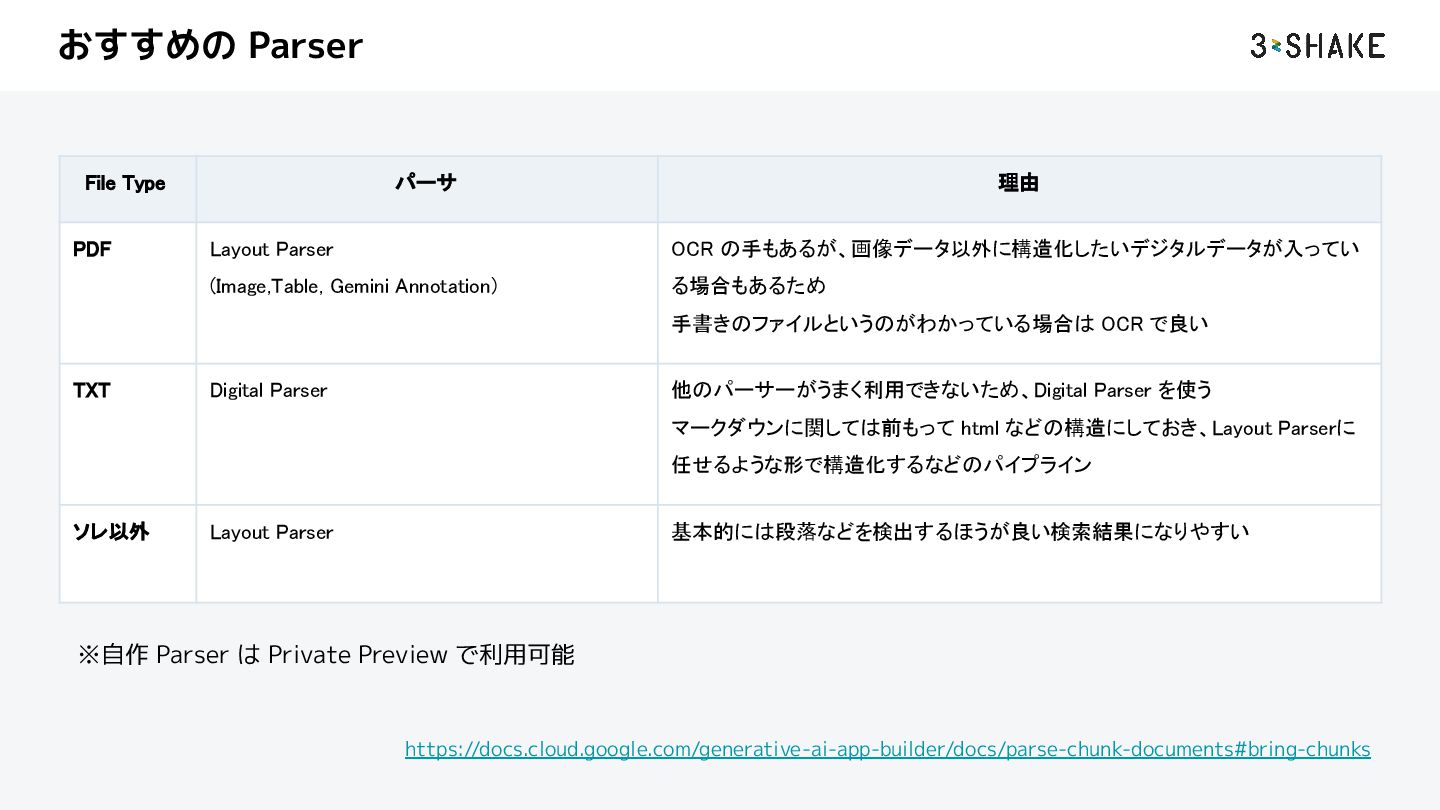{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}