Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
一休.com がどのように SendGrid と仲良く付き合っているか
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Tatsuro Shibamura
June 06, 2018
Technology
5.6k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
一休.com がどのように SendGrid と仲良く付き合っているか
Tatsuro Shibamura
June 06, 2018
More Decks by Tatsuro Shibamura
See All by Tatsuro Shibamura
# Azure Cosmos DB パフォーマンス最適化入門 - 設計・開発・運用の実践テクニック
shibayan
0
550
Hack Azure! #5 - Geek of Azure Serverless
shibayan
0
130
.NET Conf 2020 Online - .NET 5 リリース記念パーティートーク
shibayan
0
9.9k
Terraform Provider for Azure に貢献してみた話
shibayan
0
660
Azure Functions と SendGrid の良い関係
shibayan
0
1.3k
Azure Serverless を活用したリアルタイム Web のすべて
shibayan
1
3k
祝 東日本リージョン一般提供! Azure Application Insights 基礎と実践
shibayan
1
42k
なかなか楽にならないSSL/TLS証明書の話
shibayan
2
1.9k
.NET Conf 2018 Tokyo
shibayan
1
4.1k
Other Decks in Technology
See All in Technology
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
3
1.1k
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
0
110
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
120
企業でAWS Organizationsを動かすための組織設計の考え方
nrinetcom
PRO
1
110
Network Firewallやっていき!
news_it_enj
0
170
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
1
490
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
410
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
0
220
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
670
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
1
120
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
470
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.4k
Featured
See All Featured
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
The World Runs on Bad Software
bkeepers
PRO
72
12k
A Tale of Four Properties
chriscoyier
163
24k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
460
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Designing for Timeless Needs
cassininazir
1
370
Prompt Engineering for Job Search
mfonobong
0
380
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
How STYLIGHT went responsive
nonsquared
100
6.2k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Transcript
一休.com がどのように SendGrid と付き合っているか 2018.5.29 Send With Confidence Tour 仲良く
自己紹介 Tatsuro Shibamura (@shibayan) 一休.com エンジニア Microsoft MVP
一休.com について • 厳選ホテル・レストラン専門の予約サイト
一休.com における SendGrid の利用 • 基本的にトランザクションメール • 新規会員登録など • ホテルやレストランのユーザー向け予約完了
• 施設・店舗向け予約追加 • 今後はマーケティングメールも
メールは非常に重要 • 送信に失敗すると何が起こるか • 予約完了のメールが届かないため、予約が取れていないと考える _人人人人人人人人人_ > 重複予約が発生 <  ̄Y^Y^Y^Y^Y^Y^Y^Y ̄
SendGrid の利用前後 • オンプレの SMTP サーバーを自前で管理 • とても高かったらしい • 一休.com
の AWS 移行のタイミングで SendGrid に全て移行 • メール配信だけオンプレに残すとかありえない • SMTP から REST API へ移行 • 憎き .NET と ISO-2022-JP の組み合わせ問題も解消
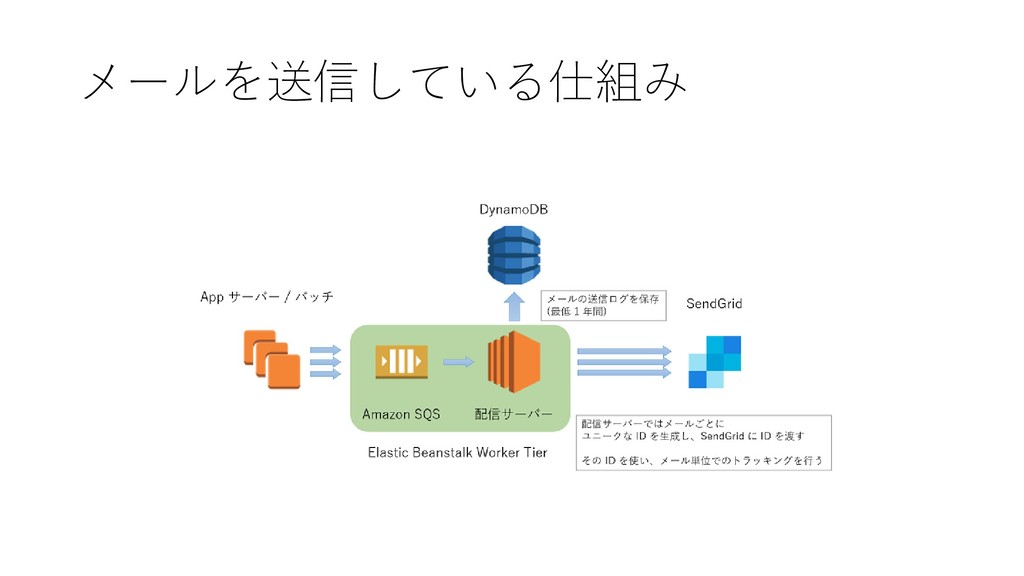
メールを送信している仕組み
Event Webhook で状態をトラッキング
設計時に考慮した点 • SendGrid の API がエラーを返した場合のリトライ • Elastic Beanstalk +
SQS を使うことで自動的に実行させるように • メール配信結果の保存 • DynamoDB と Event Webhook を使い 1 通単位でトラッキング • スケーラビリティと信頼性 • 基本的には Elastic Beanstalk と SQS の信頼性に乗っかる形
学びの多い 2017 年の SendGrid 障害 • メール送信 API のエラーレートが上がる •
送信完了までに遅延が発生する(まだマシな例) • デッドレターキュー入りする(完全に届かない) • 運用を行い半年、ノートラブルで稼働していたので油断 • 原因の特定にかなりの時間を要してしまった • 大規模障害時のリカバリーは手動で行うしかなかった • 送信ログは全て DynamoDB に保存されているのが救いだった
教訓 : 失敗を前提に設計する • Elastic Beanstalk or SendGrid の問題切り分けが行えなかった •
→ SendGrid API エラー時のレスポンスを詳細にログへ • デッドレターキューからのリカバリ方法が手動 • → 管理画面から一括で未送信メールのリカバリを行えるように改善 • SendGrid 障害時のみに発生するバグもあった • → ワーカーの修正後、リカバリを行えるように管理画面も改善
教訓 : モニタリングを強化する • 障害時にメールの遅延具合や影響範囲を確認出来なかった • → Datadog で Beanstalk
Worker のモニタリング強化 • → Datadog に SQS のメトリクスを流し込んでアラート設定
障害を受けて改善 • 10 分以上の配信遅延が発生した場合は Slack にアラート • 遅延が発生した時点で、何かしらの問題が発生していることが分かる • 各事業部・CS
チームと連携して対応 • 管理画面から送信できなかったメールを確認できるように • DynamoDB にクエリを投げるだけ、GSI も専用に用意 • 未送信メールは簡単にリカバリ可能に
最近の状況 • 障害が発生しても、検知とリカバリの仕組みを用意済み • 運用ドキュメントを作成して共有 • 運用の分散 • 各事業部から担当者を一人任命、属人化を避ける •
SendGrid の障害が発生していないため極めて平和 • 感謝しかない
参考 • 新メール配信基盤への移行 • https://speakerdeck.com/minato128/ikyu-mail-platform • メール配信基盤のモニタリングと障害リカバリーについて • http://user-first.ikyu.co.jp/entry/2017/12/05/000000
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}