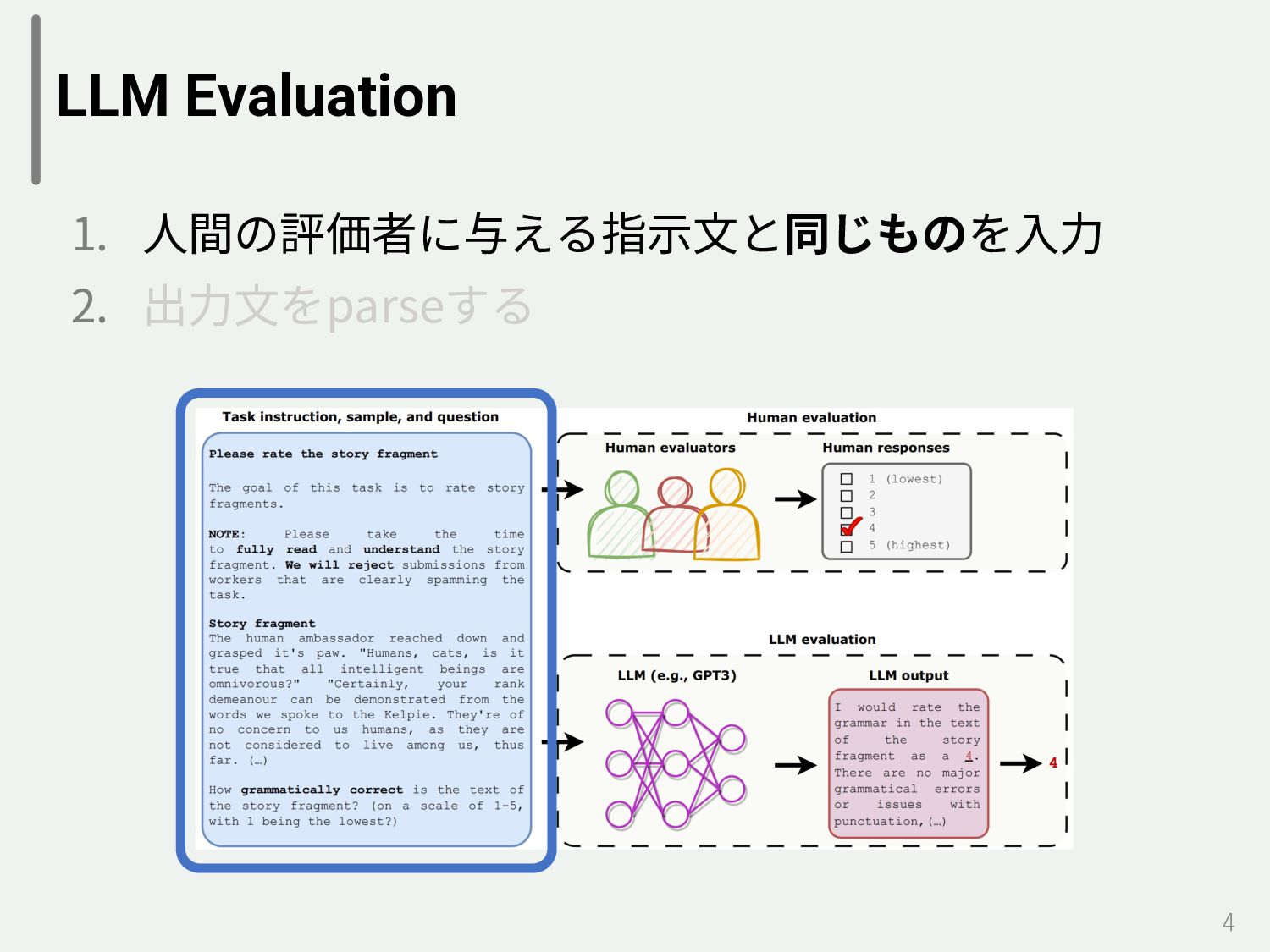
Cohesiveness 0.18 0.14 Likability 0.19 0.22 Relevance 0.38 0.43 ∗ 𝜏 の値と相関の強さ [Botsch+11] [0, 0.1): very weak correlation [0.1, 0.2): weak correlation [0.2, 0.3): moderate correlation [0.3, 1.0): strong correlation • text-davinci-003と⼈間の評価のインスタンスごとの 相関(Kendall’s 𝜏)を測る • 結果 • 弱〜強相関 • Grammaticalityが最も弱い相関 • 評価軸がはっきりしてない • Relevanceが最も強い相関
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![タスク1:物語⽣成 • プロンプトに基づいて物語を⽣成するタスク • プロンプト:物語の設定、内容などを記述 • WritingPrompts データセット[Fan+18]を使⽤ • プロンプトと⼈⼿で書かれた物語のペア集合](https://files.speakerdeck.com/presentations/b13fecc80e34454ba586c5e2be490ed0/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Limitation • LLMは不正確な知識を持つ [Cao+21] • LLMの応答にはバイアスがある • 安全性、無害性 • ポジティブ、楽観的](https://files.speakerdeck.com/presentations/b13fecc80e34454ba586c5e2be490ed0/slide_20.jpg){kind=link}