Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
理解してほしいVision Transformer / plz-understand-ViT
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
shun74
June 23, 2022
Programming
810
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
理解してほしいVision Transformer / plz-understand-ViT
Easy to understand explanation form NN to ViT.
shun74
June 23, 2022
More Decks by shun74
See All by shun74
深度推定モデルの自己教師あり学習/self-supervised-depth
shun74
0
530
GPUでステレオマッチング / Stereo-matching with GPU
shun74
0
1.2k
卒業研究の進め方 / How to preceed with the research
shun74
1
600
Barcode Recognition / pharmacode-decoder
shun74
0
1.1k
Vision Transformer講座 / Vision Transformer Presentation
shun74
1
770
ニューラルネットの1bit化 / 1bit-neural-network
shun74
0
1k
Defocus Map Estimation From a Single Image Based on Two-Parameter Defocus Model / two-parameter-defocus-model
shun74
0
410
Other Decks in Programming
See All in Programming
GDG Korea Android: 2026 I/O Extended ~ What's new in Android development tools
pluu
0
200
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
920
今さら聞けない .NET CLI
htkym
0
170
わからない話を追いかけたら、プログラミング言語を作る側にいた
ydah
2
160
全PRの83%がAIレビューだけでマージできるようになった開発組織はその後どうなったか
athug
0
920
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
790
ルールを書いて終わらせないハーネスエンジニアリング
yug1224
4
1.8k
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
3.3k
これって Effect でできたのでは? / TSKaigi Mashup Kansai #2
susisu
0
130
継続モナドとリアクティブプログラミング
yukikurage
3
670
改善しないと、タスクが回らない。 “てんこ盛りポジション” を引き継いだ情シスの、入社3ヶ月の業務改善録
krm963
0
230
<title><a id="</title>君はこのHTMLをパースできるか"></a></title> #雑LT_study
pizzacat83
0
130
Featured
See All Featured
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Ruling the World: When Life Gets Gamed
codingconduct
0
290
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
Skip the Path - Find Your Career Trail
mkilby
1
170
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
500
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Amusing Abliteration
ianozsvald
1
240
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Transcript
理解してほしい VisionTransformer B4 佐藤 駿
はじめに • 機械学習を全く知らない人でも理解できるように解説します 目次 • 機械学習 • ニューラルネット • 畳み込みニューラルネット
(CNN) • Vision Transformer (ViT) • Attention • CNN vs ViT • ViTとCNNのいいとこどり例
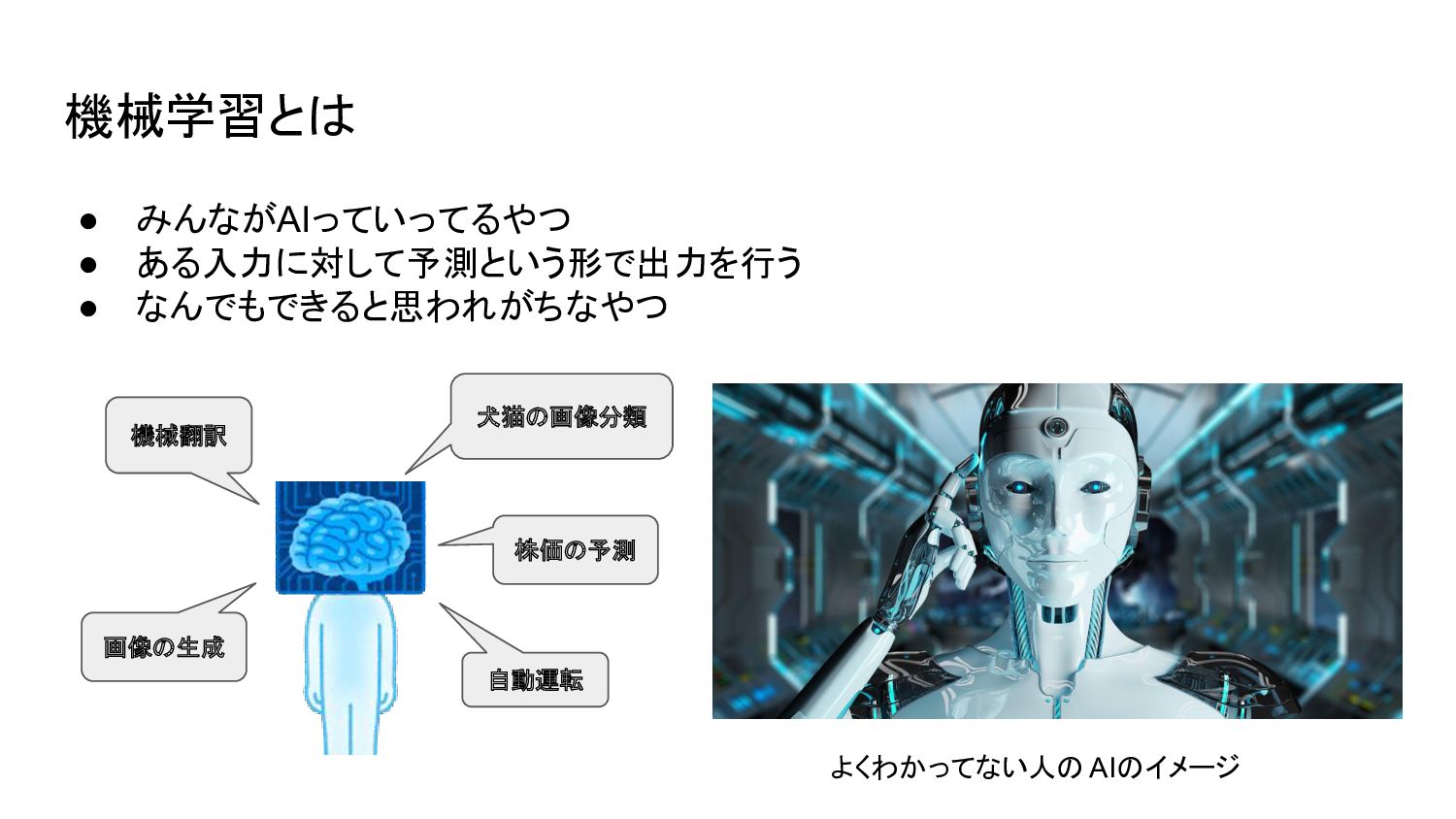
機械学習とは • みんながAIっていってるやつ • ある入力に対して予測という形で出力を行う • なんでもできると思われがちなやつ 犬猫の画像分類 株価の予測 機械翻訳
画像の生成 自動運転 よくわかってない人の AIのイメージ
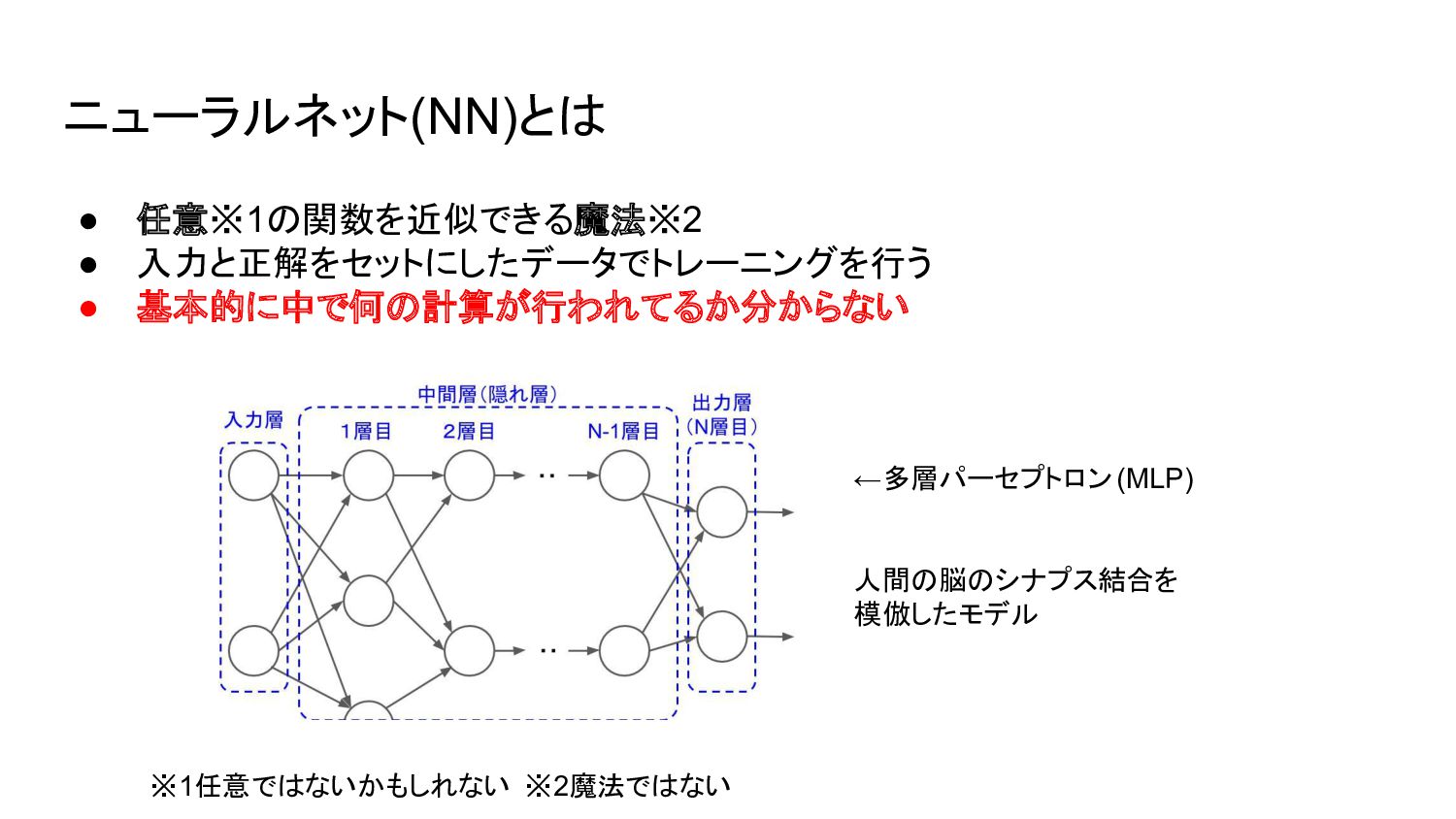
ニューラルネット(NN)とは • 任意※1の関数を近似できる魔法※2 • 入力と正解をセットにしたデータでトレーニングを行う • 基本的に中で何の計算が行われてるか分からない ※1任意ではないかもしれない ※2魔法ではない ←多層パーセプトロン(MLP)
人間の脳のシナプス結合を 模倣したモデル
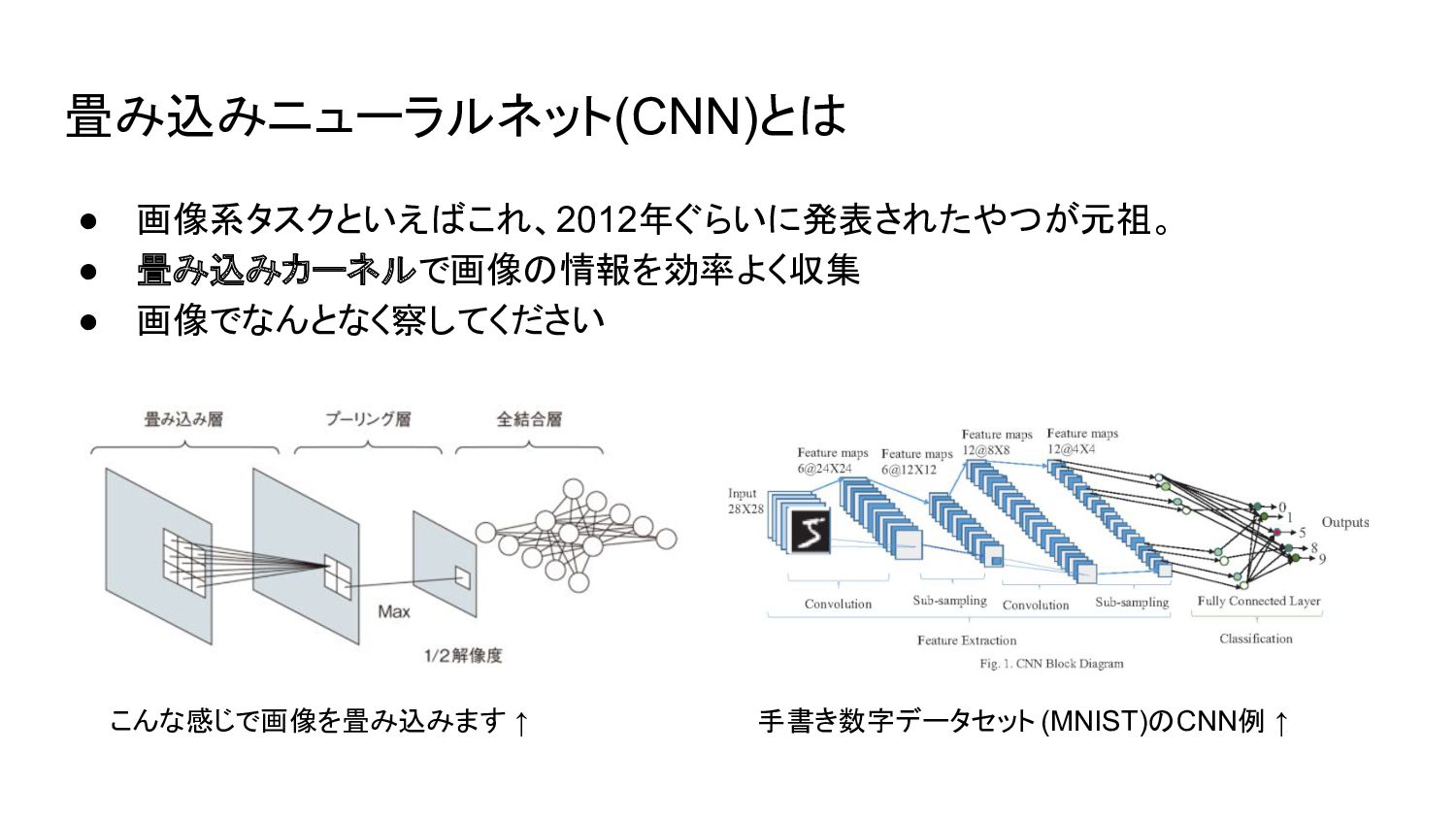
畳み込みニューラルネット(CNN)とは • 画像系タスクといえばこれ、2012年ぐらいに発表されたやつが元祖。 • 畳み込みカーネルで画像の情報を効率よく収集 • 画像でなんとなく察してください 手書き数字データセット (MNIST)のCNN例 ↑
こんな感じで画像を畳み込みます ↑
CNNの応用タスク 画像分類 画像生成 物体認識 距離画像生成
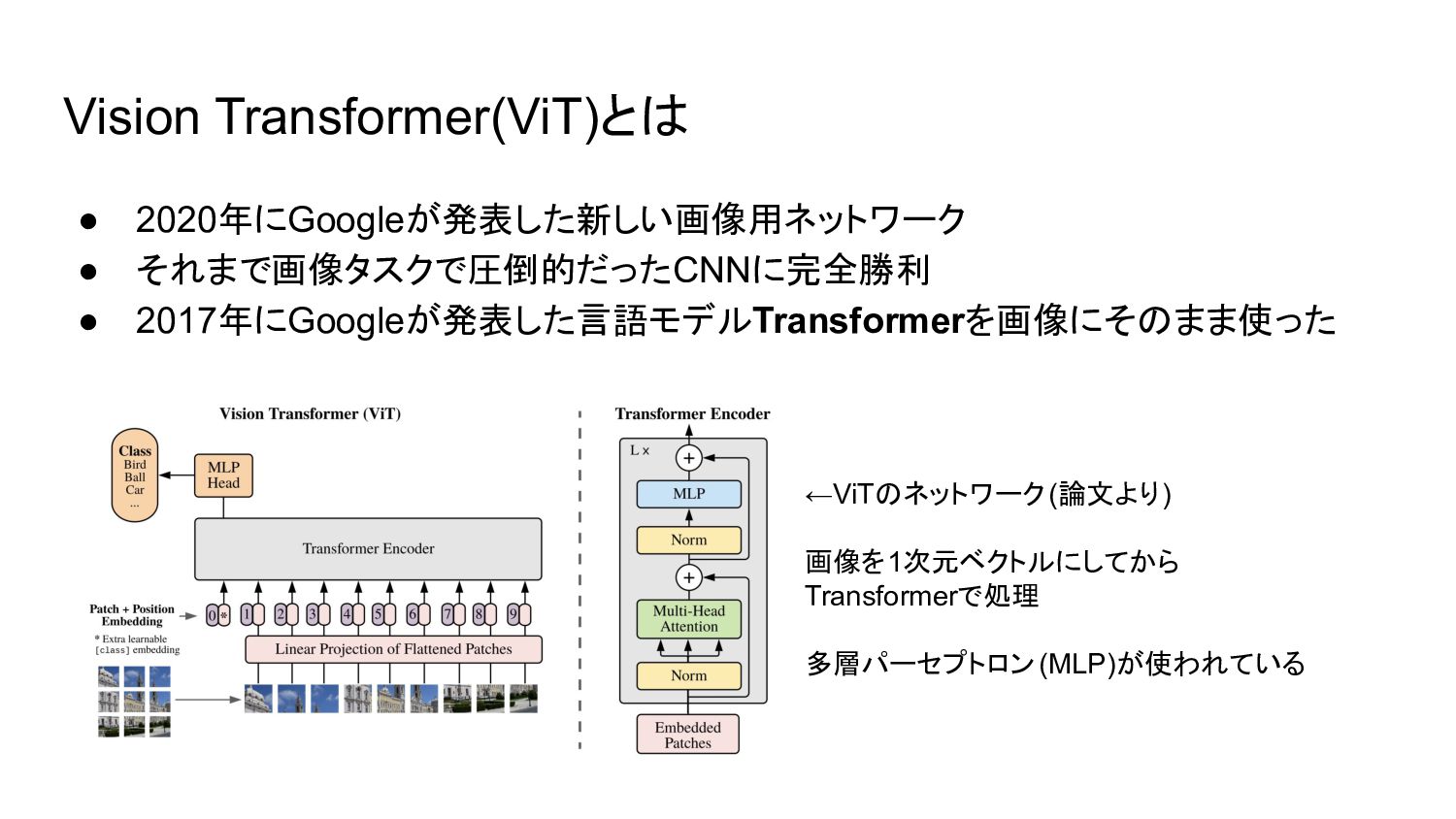
Vision Transformer(ViT)とは • 2020年にGoogleが発表した新しい画像用ネットワーク • それまで画像タスクで圧倒的だったCNNに完全勝利 • 2017年にGoogleが発表した言語モデルTransformerを画像にそのまま使った ←ViTのネットワーク(論文より) 画像を1次元ベクトルにしてから
Transformerで処理 多層パーセプトロン(MLP)が使われている
Attentionとは • 最初はCNNで導入されたモジュール • ニューラルネットがどこに注目するのかを決める Attentionの例 Attentionが犬以外の背景 をあまり重要視しない ように学習されている
Scaled Dot-Product Attentionの解説 Query, Key, Valueを用意して計算 1. Query, Keyの行列積を計算 2.
SoftMaxを使ってAttentionMapを生成 3. ValueにMaskを適用して完成 • ViTで使われているのはMulti-Head Attention • Scaled Dot-Product Attentionを複数使う • より多くのパターンを作ることで情報量UP
Vision Transformerのアーキテクチャ1 入力 画像をパッチに分割して1次元ベクトル化 (xy座標情報は捨てる) パッチごとにPosition Embeddingも追加 ViTでは16*16単位で画像をパッチ化 パッチ化した画像を平坦化して入力!
Vision Transformerのアーキテクチャ2 1. Norm: データの正規化を行うNormalization 2. MHA: 情報の注目を決めるAttention 3. MLP:
情報の処理を行う多層パーセプトロン (横道に逸れている矢印はSkip-Connection) Norm->MHA->Norm->MLPのブロックをLレイヤー繰り返す ここでMHAの入力QKVは全て同じ入力(?!)
CNN vs ViT Q. なぜViTがCNNに圧勝したのか A. タスクがちょうど良かったから ViT : Attentionで全体(Global)の特徴量をまとめる
CNN: 畳み込みで局所(Local)の特徴量を捉える • 比較が画像分類タスクだったためViTが圧勝した • 画像分類は画像の中に何が映っているか何となく分かればいい ViTとResNet(CNN)の 内部表現の類似性の比較 ViTの方が安定した表現を 獲得している (?)
CNNとViTのいいとこどり例 Depth Former (2022/3) : 深度推定タスク • ViTはCNNより良い性能が出せたがあと一歩性能が足りなかった • CNNの情報を足すことで細かいところまで考慮できるようになった
• 深度(距離)画像なのでカーペットのテクスチャが反映されているのはおかしい • CNNとViTの組み合わせでLocalとGlobalの情報を考慮できるネットワークになった 入力画像 ViTモデル1 ViTモデル2 DepthFormer 正解画像
さいごに • 現在多くの画像タスクでBackboneとしてViTが使われている • ViT自体も様々なモデルの開発競争が行われている • ViT以外にもCNNだけのモデルやMLPのモデルも研究されている • みんなもViTを実装して最新のAIモデルを作ろう! •
画像系AIの相談があれば@shun74まで
参考 1. ニューラルネット: https://ledge.ai/neural-network/ 2. CNN: https://leadinge.co.jp/rd/2021/06/07/863/ 3. ViT: https://qiita.com/omiita/items/0049ade809c4817670d7
(最強資料) 4. ViT vs CNN: https://ai-scholar.tech/articles/transformer/transformer-vs-cnn 5. DepthFormer: https://arxiv.org/abs/2203.14211
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}