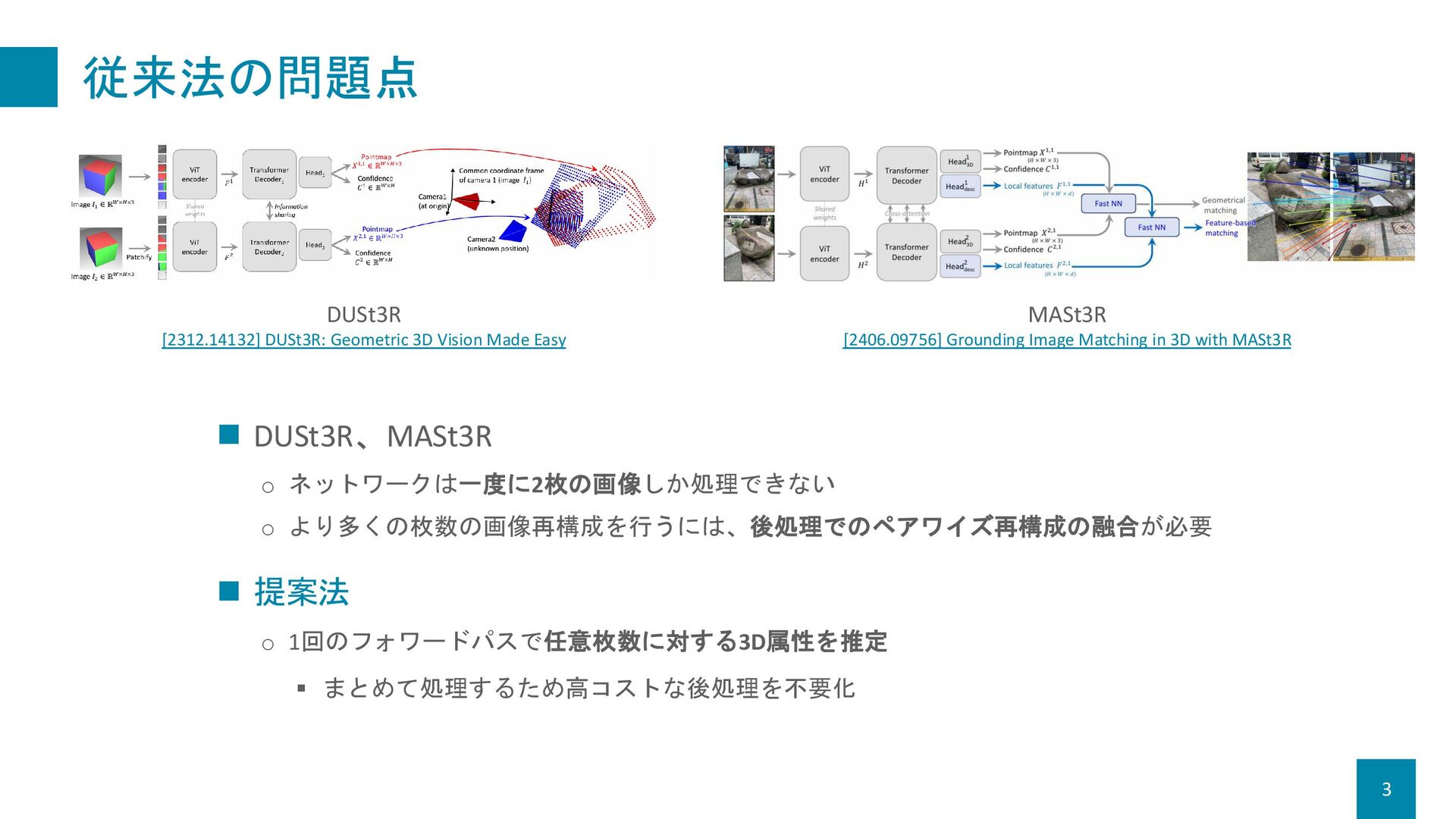
o 1回のフォワードパスで任意枚数に対する3D属性を推定 ▪ まとめて処理するため高コストな後処理を不要化 DUSt3R [2312.14132] DUSt3R: Geometric 3D Vision Made Easy MASt3R [2406.09756] Grounding Image Matching in 3D with MASt3R
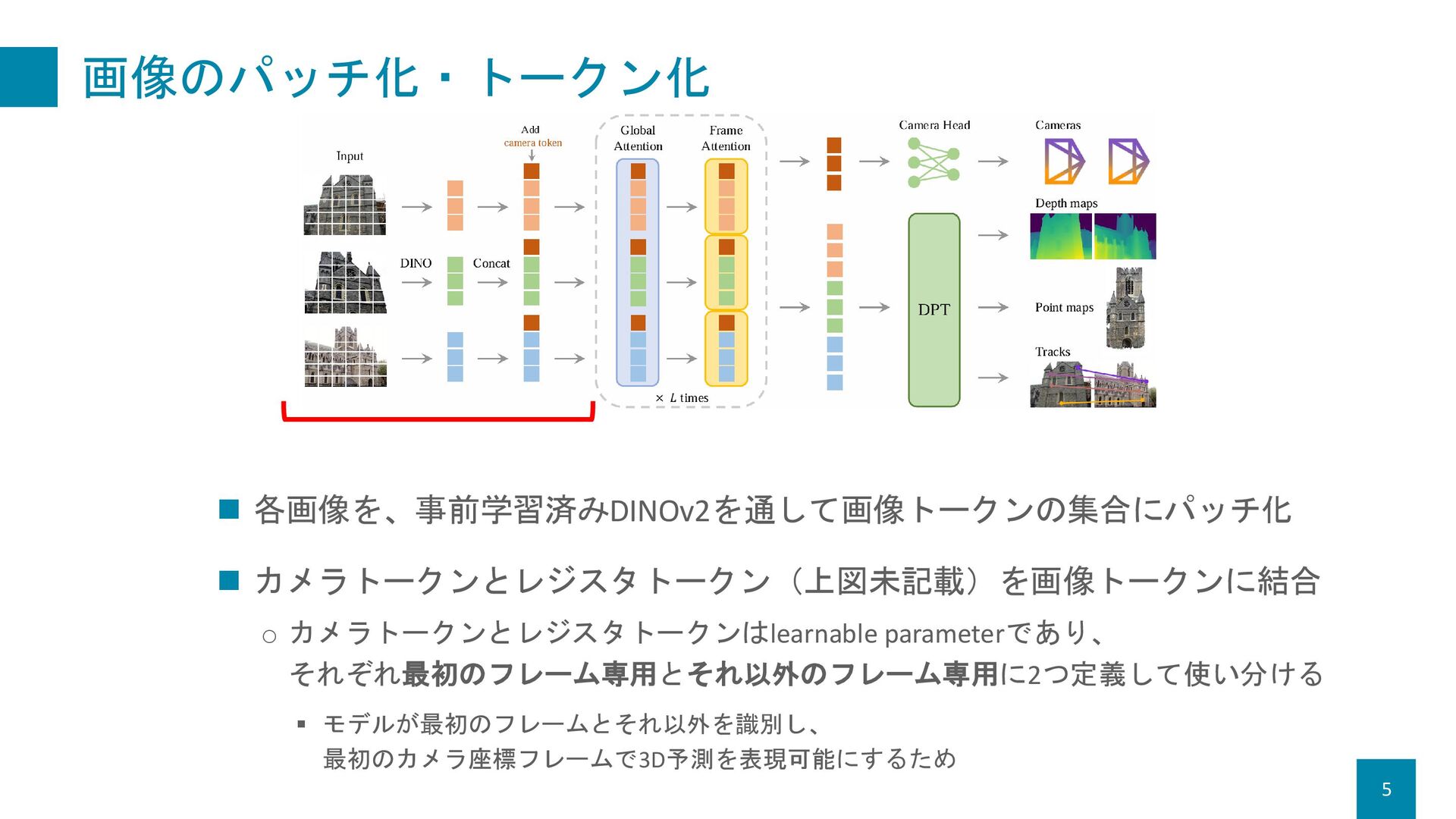
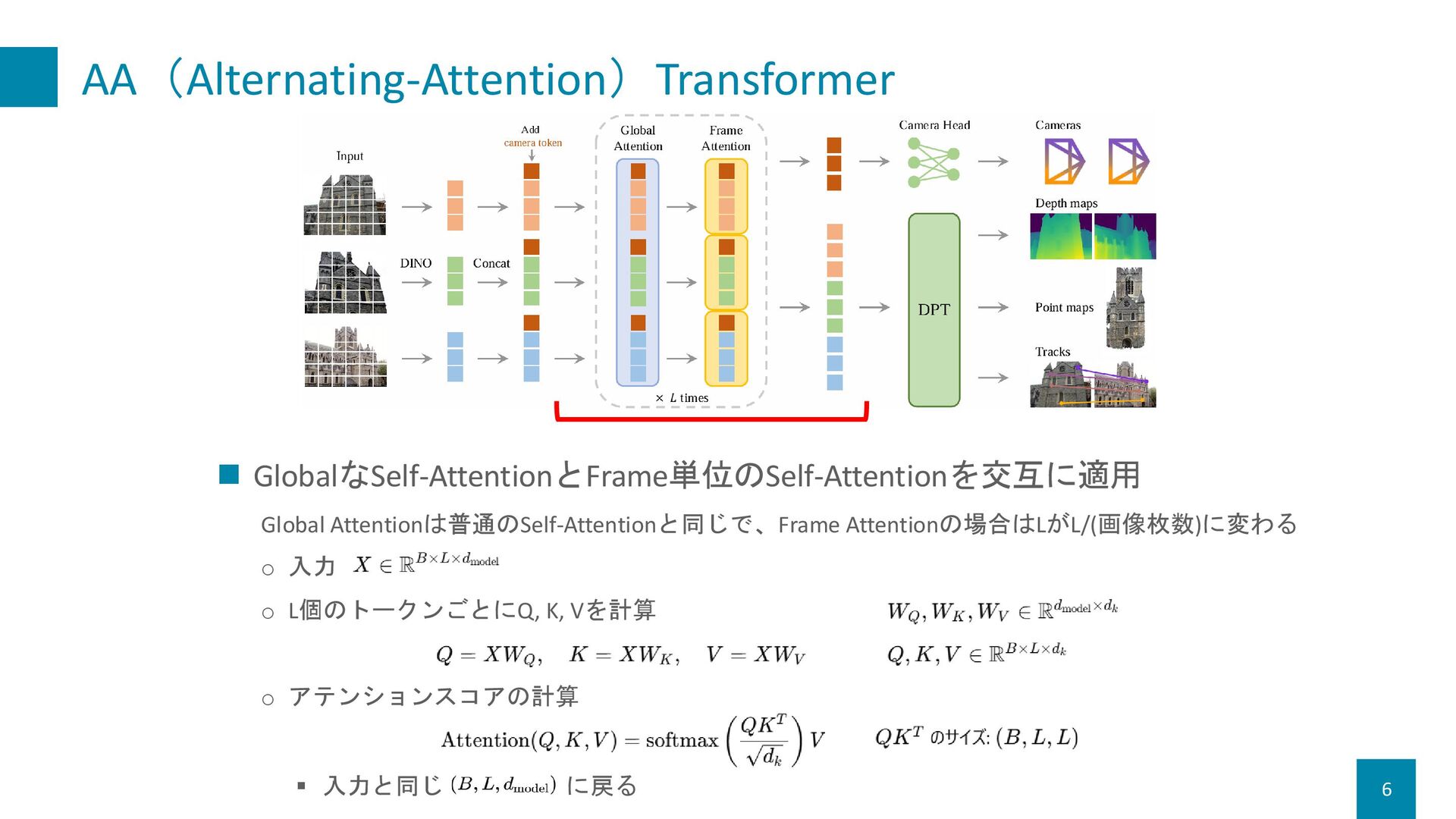
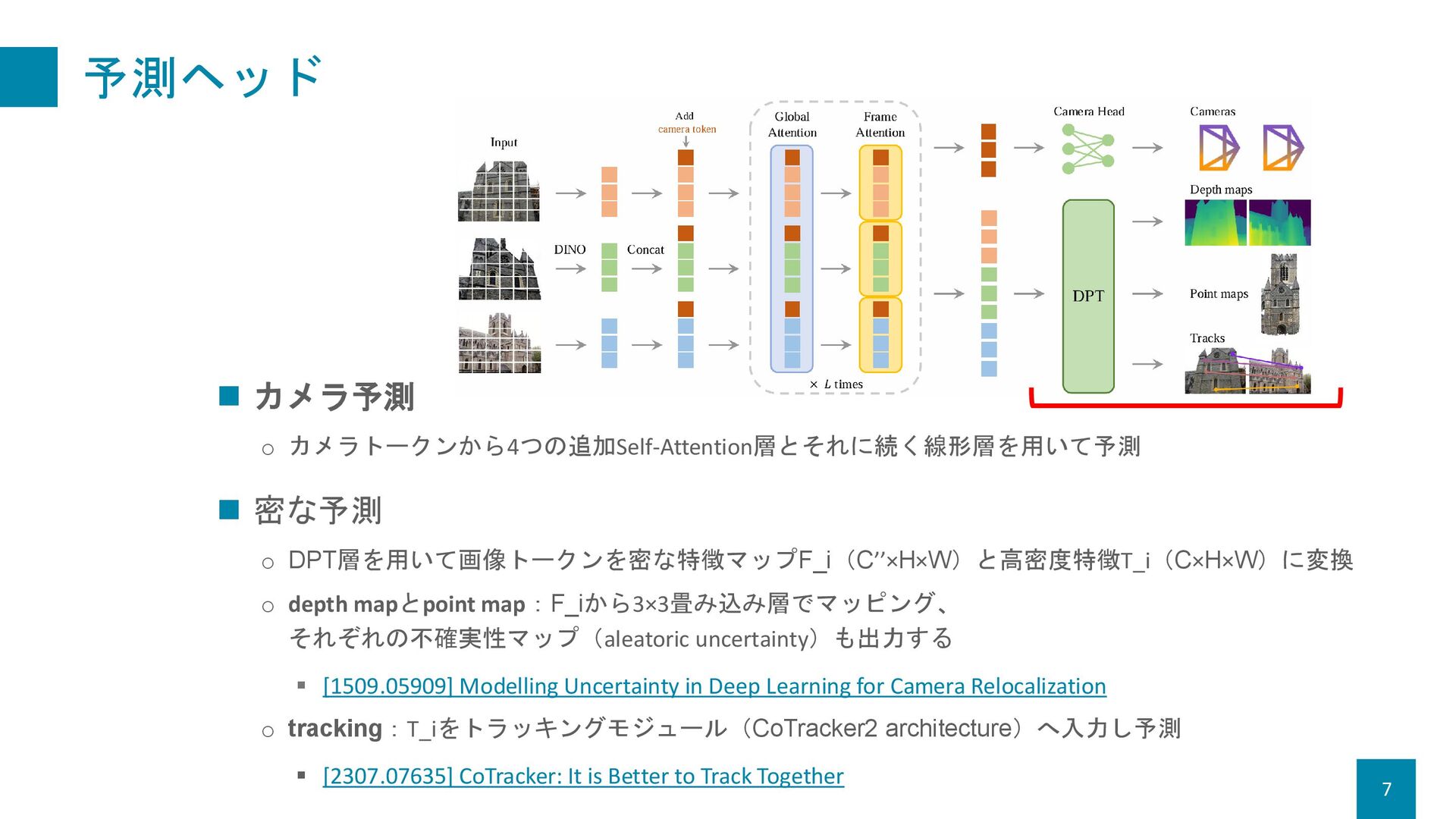
Improved DeNoising Anchor Boxes for End-to-End Object Detection 2. AA(Alternating-Attention)Transformer o Global Attention & Frame Attention 3. 予測ヘッド o カメラ:Self-Attention層+線形層 o Depth map, point map, track:DPT(Dense Prediction Transformer) [2103.13413] Vision Transformers for Dense Prediction
o depth mapとpoint map:F_iから3×3畳み込み層でマッピング、 それぞれの不確実性マップ(aleatoric uncertainty)も出力する ▪ [1509.05909] Modelling Uncertainty in Deep Learning for Camera Relocalization o tracking:T_iをトラッキングモジュール(CoTracker2 architecture)へ入力し予測 ▪ [2307.07635] CoTracker: It is Better to Track Together
Environments、Aria Digital Twin、 アーティストが作成したObjaverseに似た3D assetsデータセット o 3Dアノテーションは、センサーキャプチャ、合成エンジン、SfMなど複数のソースから取得 o データセットの組み合わせは、サイズと多様性においてMASt3Rとほぼ同等
{kind=link}
{kind=link}
{kind=link}
![提案法:アーキテクチャ 4 1. 画像のパッチ化・トークン化 o DINOv2の事前学習済みモデル [2203.03605] DINO: DETR with](https://files.speakerdeck.com/presentations/92c572e9eb6a44d0bb26f36e05e650dd/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
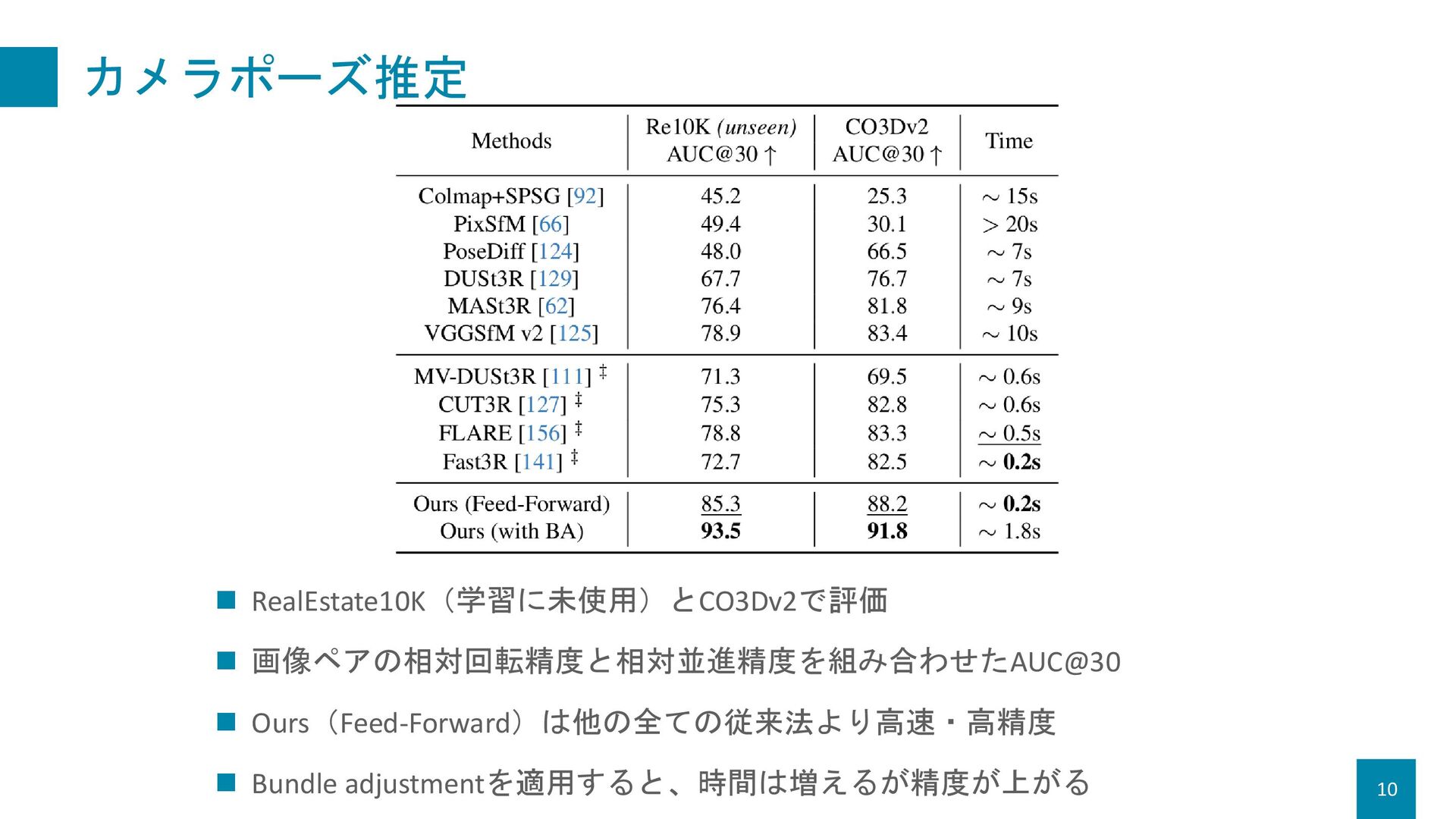{kind=link}
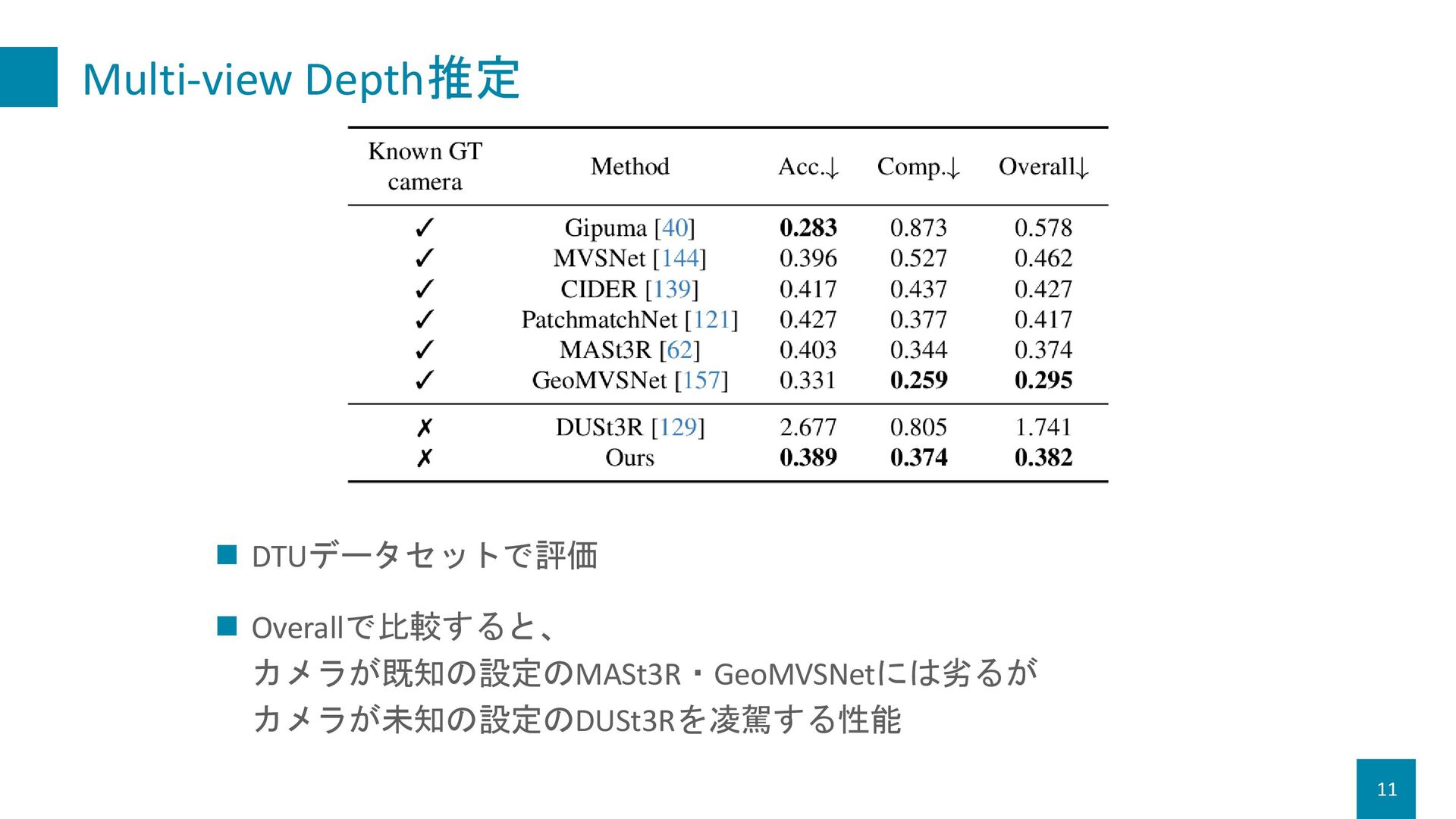{kind=link}
{kind=link}
![Two-view Image Matching 13 ◼ ScanNet-1500で評価 ◼ ALIKEDを用いてクエリとなるキーポイントを検出 o [2304.03608]](https://files.speakerdeck.com/presentations/92c572e9eb6a44d0bb26f36e05e650dd/slide_12.jpg){kind=link}
{kind=link}
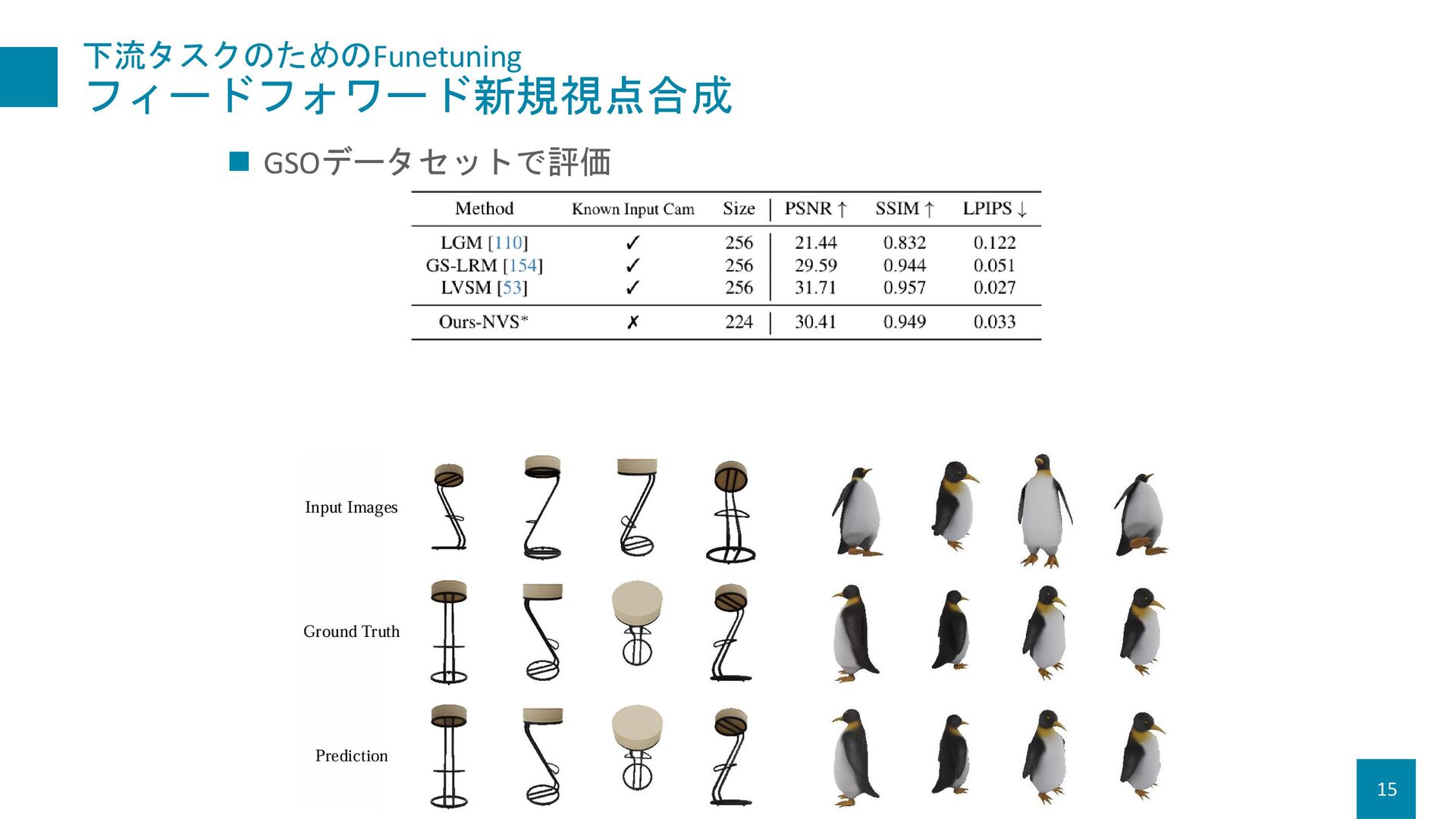{kind=link}
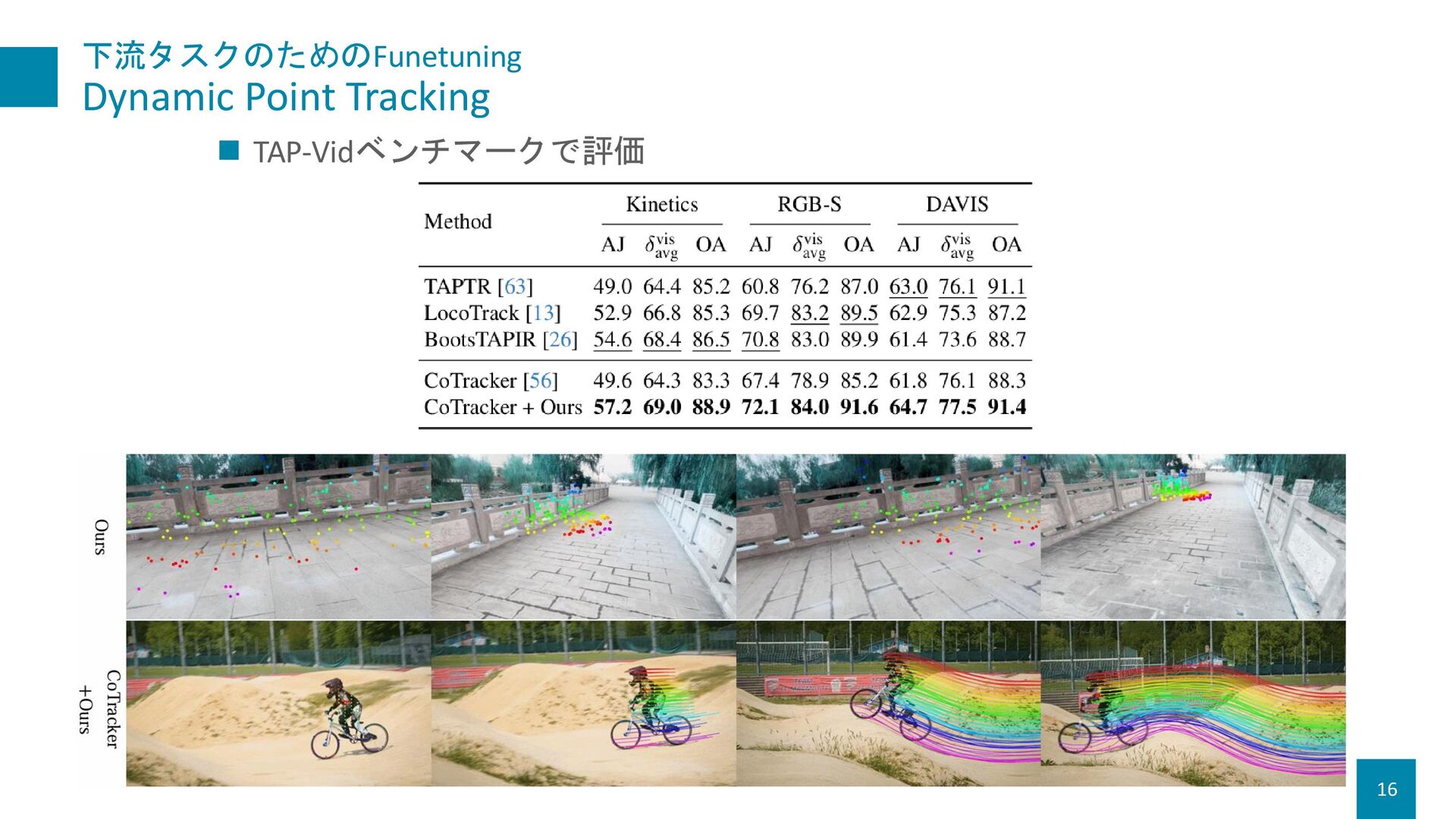{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}