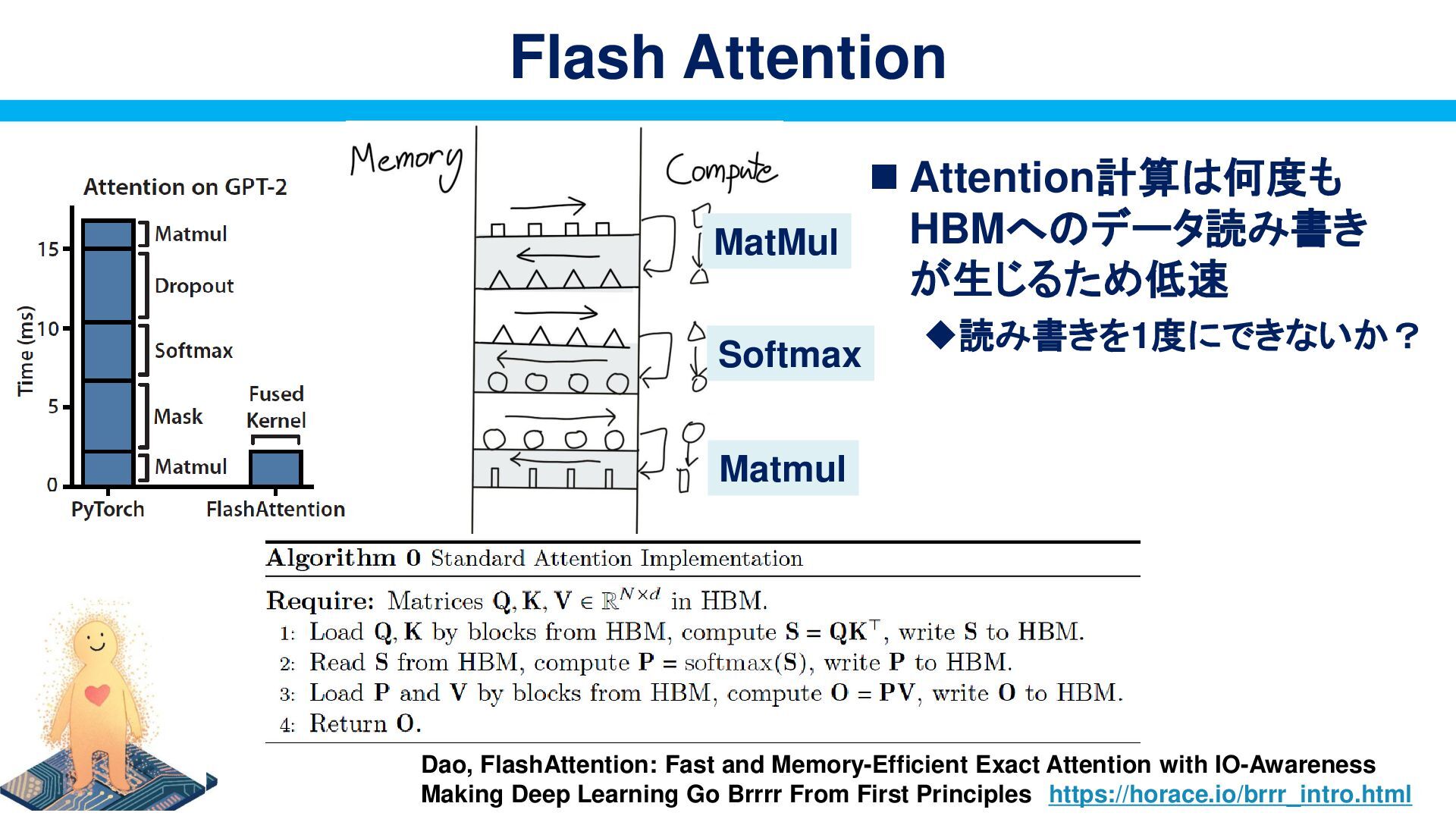
and Memory-Efficient Exact Attention with IO-Awareness Making Deep Learning Go Brrrr From First Principles https://horace.io/brrr_intro.html MatMul Softmax Matmul
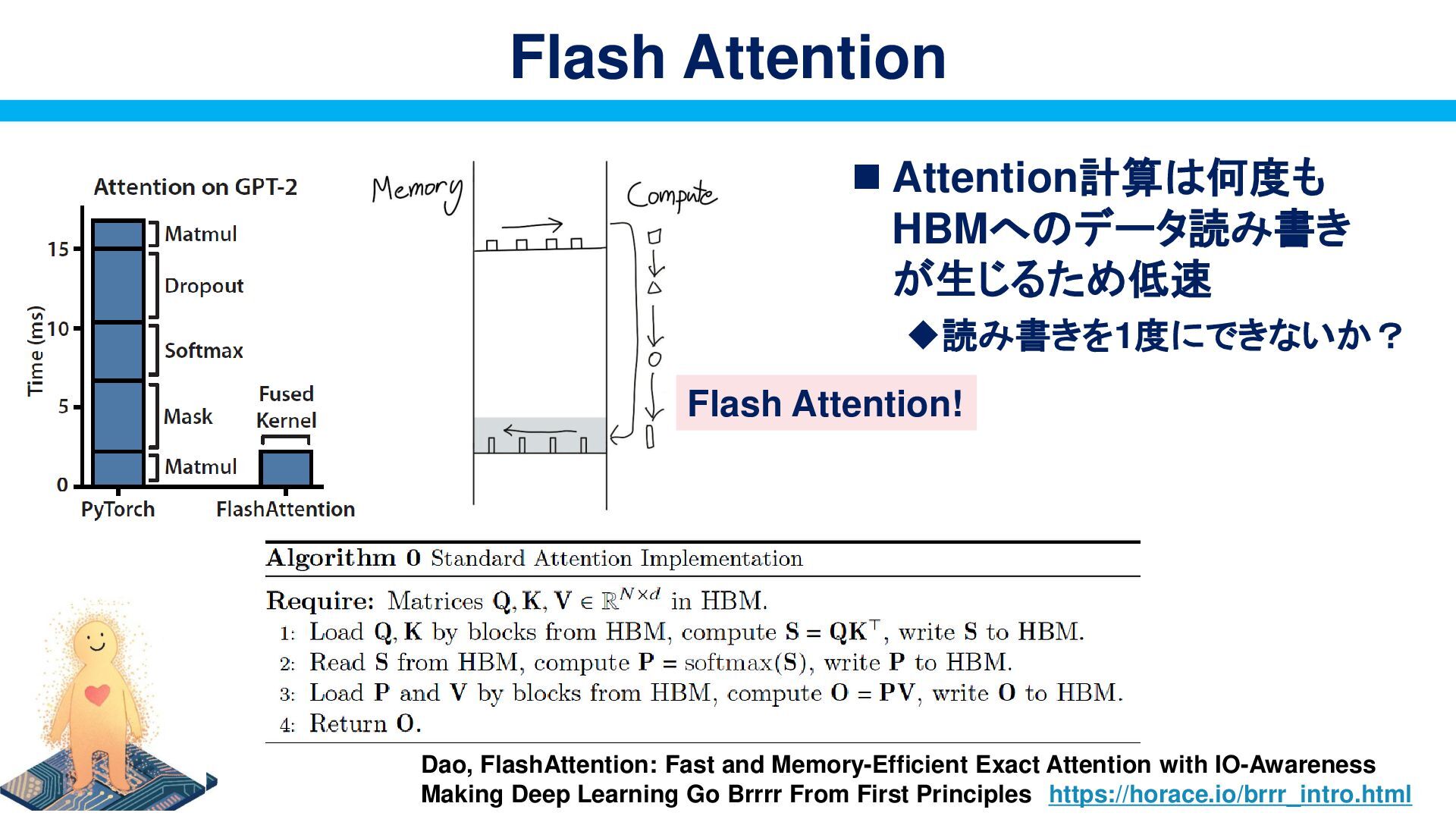
and Memory-Efficient Exact Attention with IO-Awareness Making Deep Learning Go Brrrr From First Principles https://horace.io/brrr_intro.html Flash Attention!
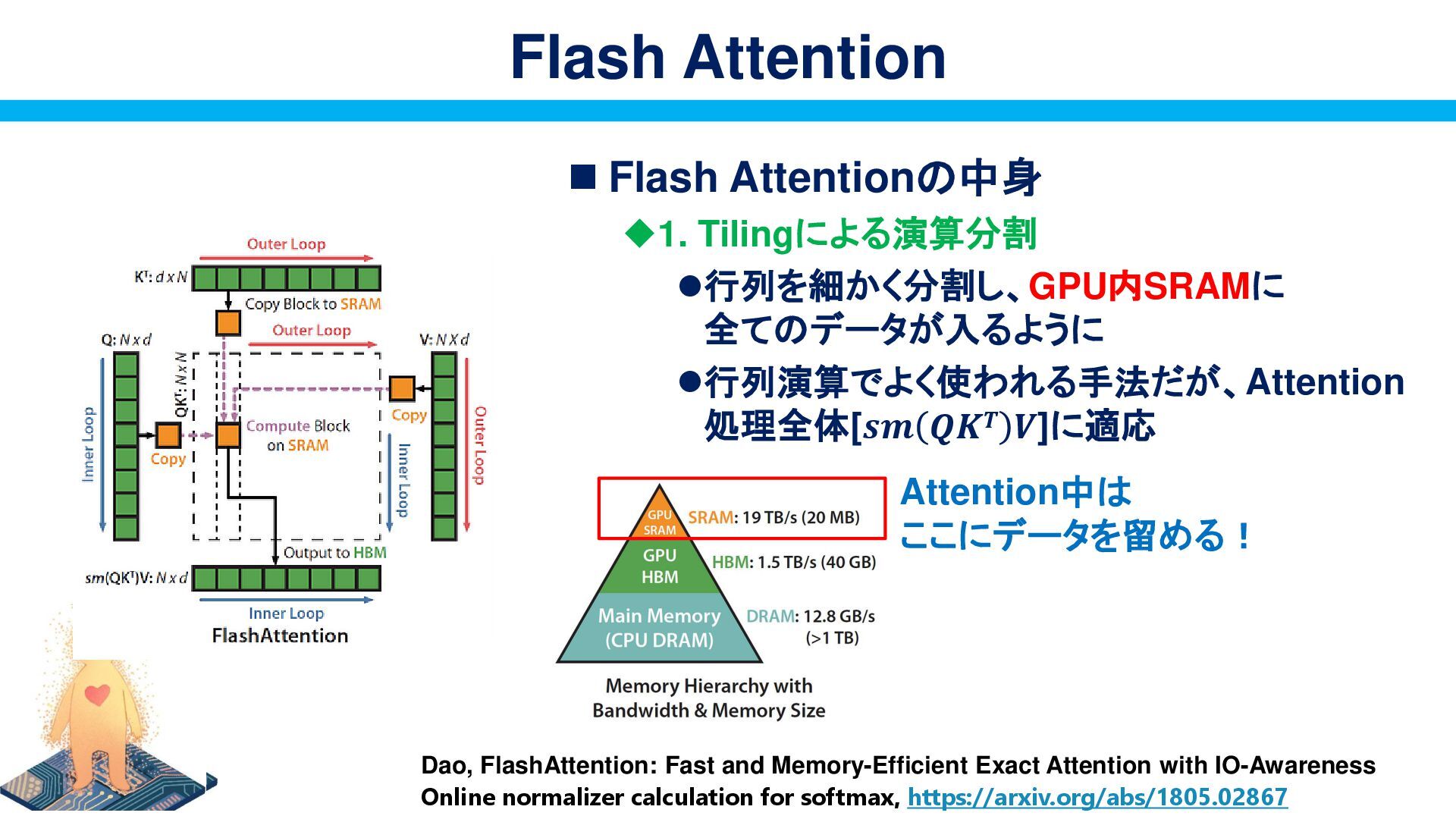
𝑽]に適応 Flash Attention Dao, FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness Online normalizer calculation for softmax, https://arxiv.org/abs/1805.02867 Attention中は ここにデータを留める!
AttentionはBackwardも対応。 Flash Attention Dao, FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness [ref] Online normalizer calculation for softmax, https://arxiv.org/abs/1805.02867 Softmax式
![エッジLLMハードウェアの問題 ~そして私たちに何ができるか~ 吉岡 健太郎 [email protected] 慶應義塾大学理工学部電気情報工学科准教授](https://files.speakerdeck.com/presentations/f4ead78f61fa46069ee7e5fdb13fb47f/slide_0.jpg){kind=link}
{kind=link}
![自己紹介 [ISSCC’24] (回路トップ学会) [ASP-DAC’24] ダイ写真(Single array) I/O Register CIM SAR](https://files.speakerdeck.com/presentations/f4ead78f61fa46069ee7e5fdb13fb47f/slide_2.jpg){kind=link}
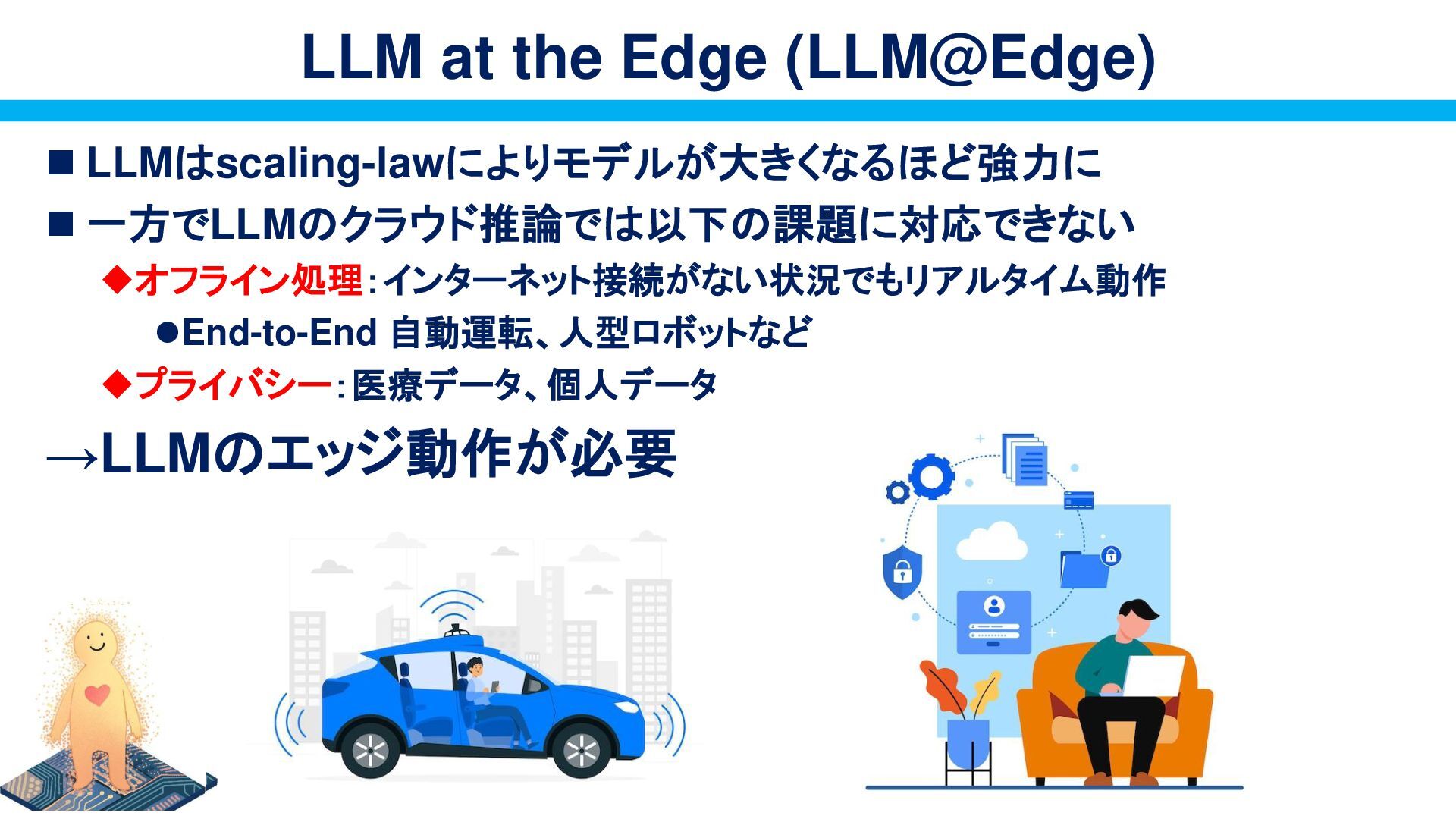{kind=link}
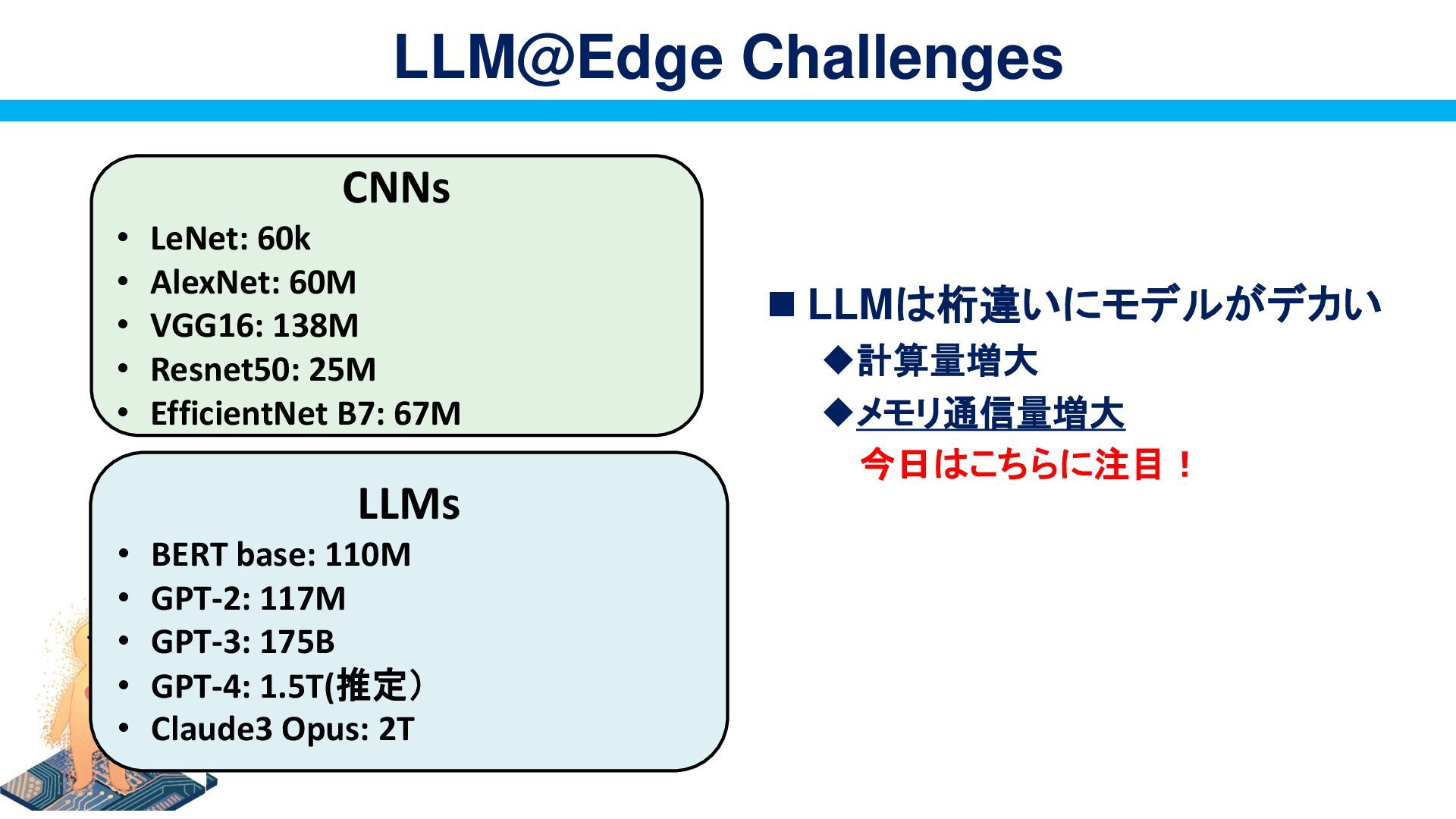{kind=link}
{kind=link}
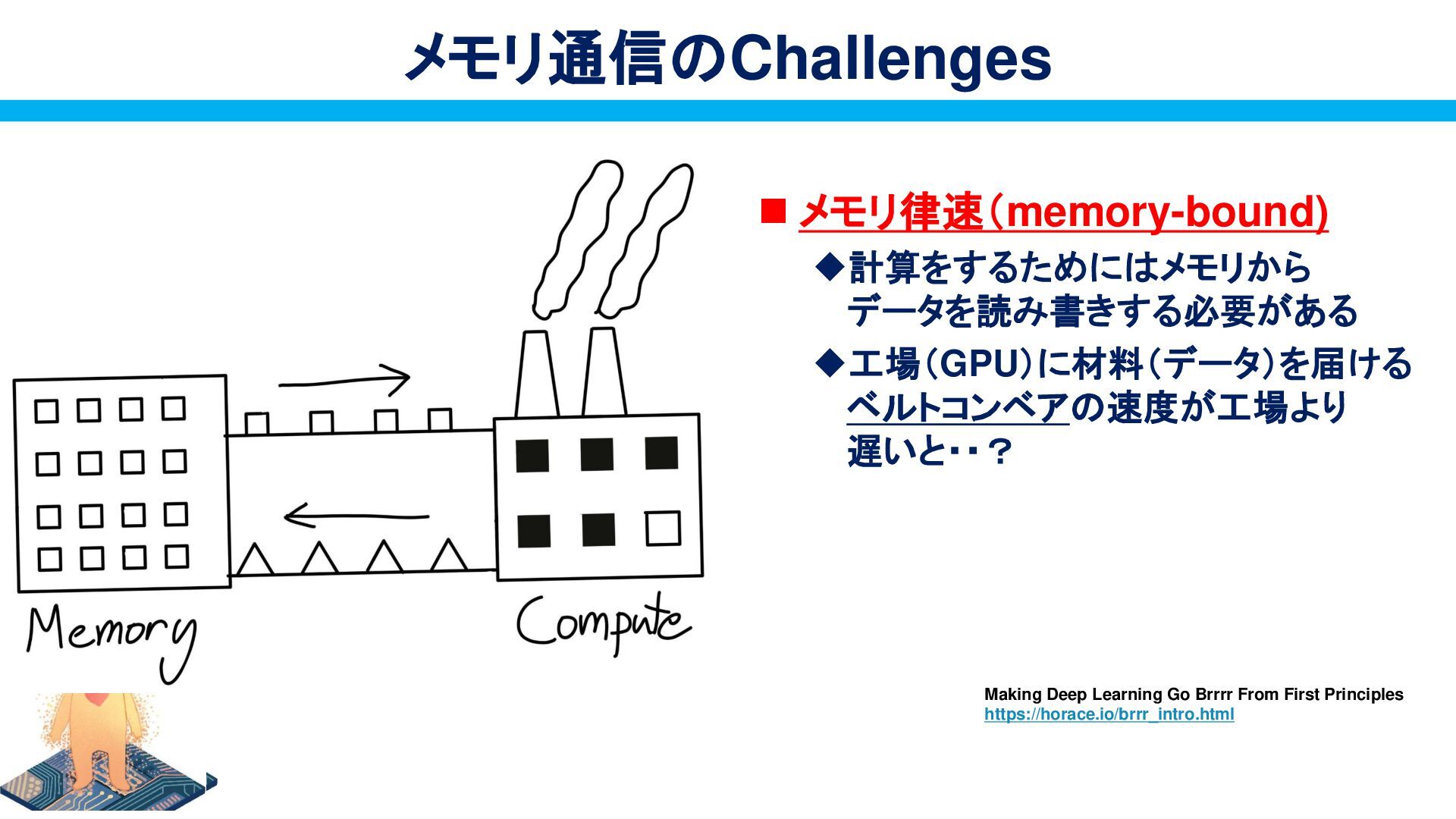{kind=link}
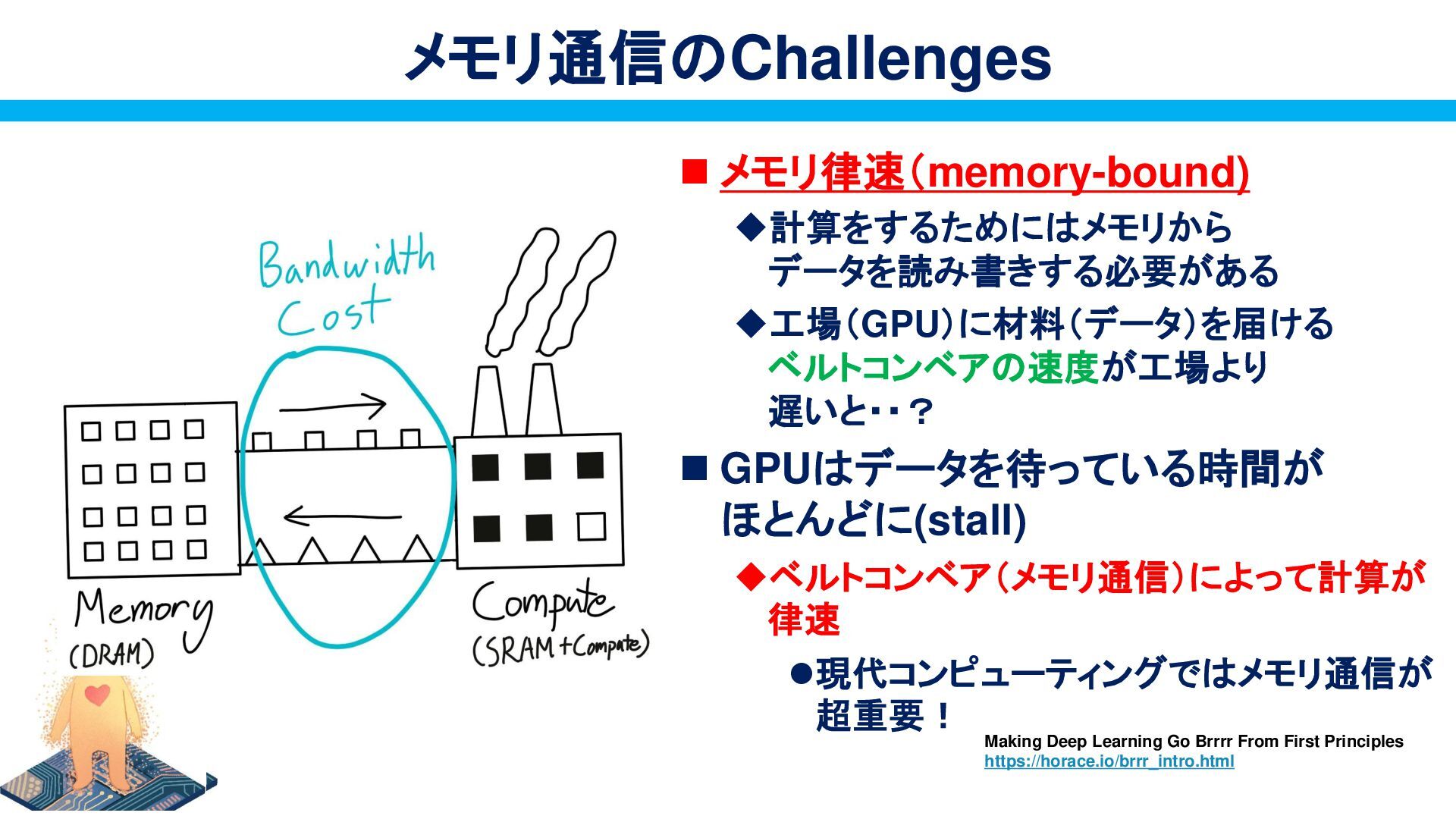{kind=link}
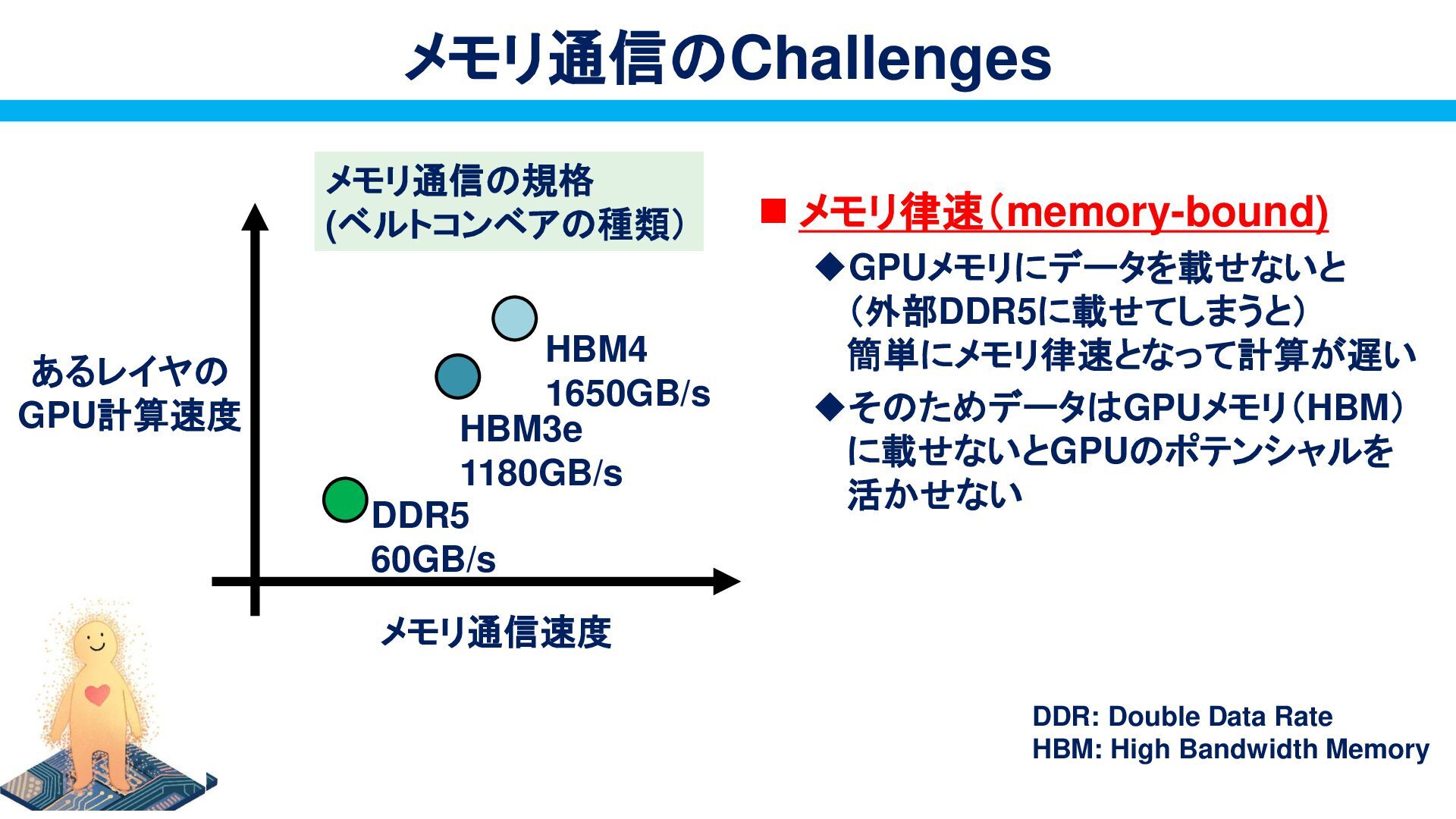{kind=link}
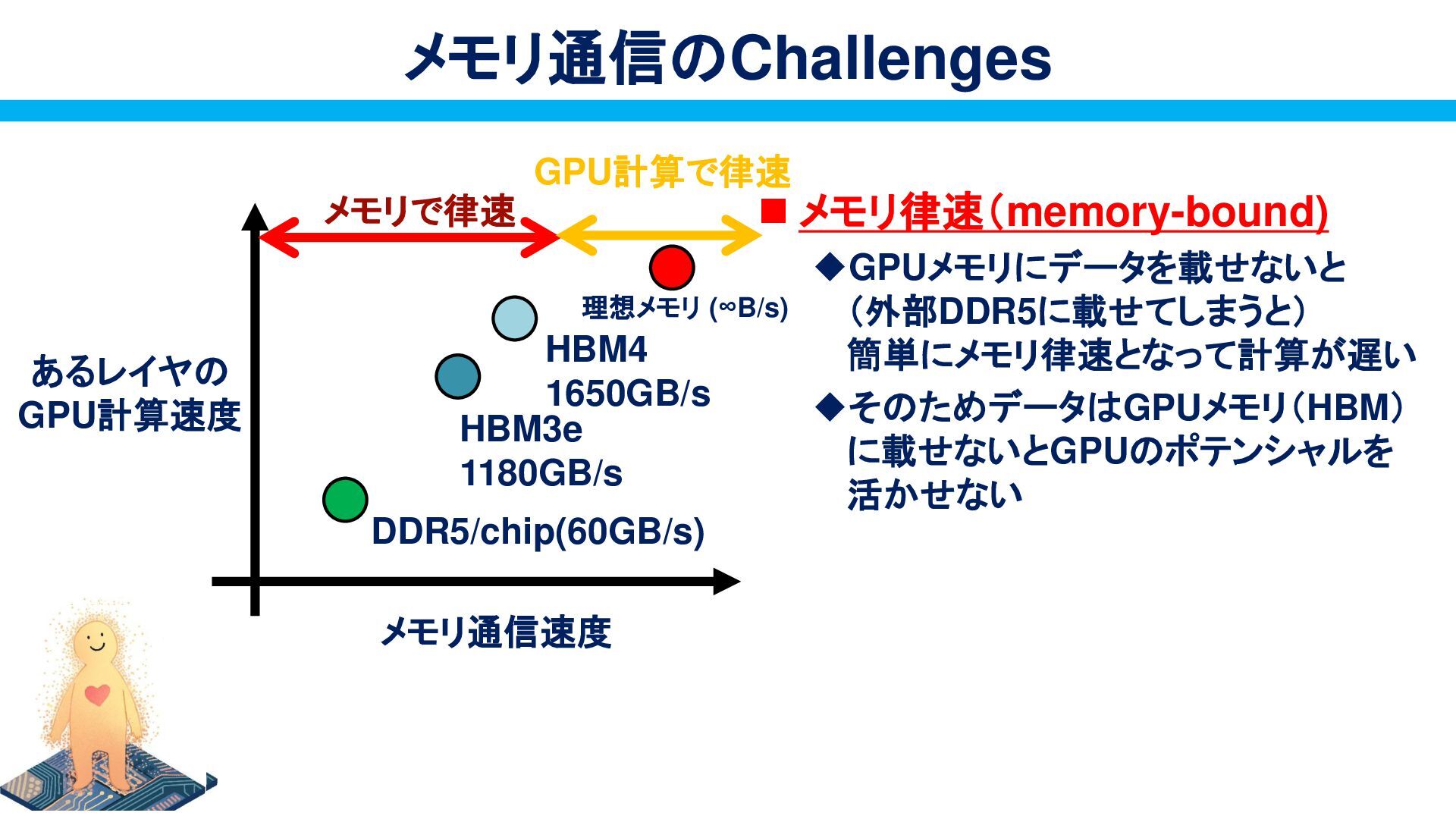{kind=link}
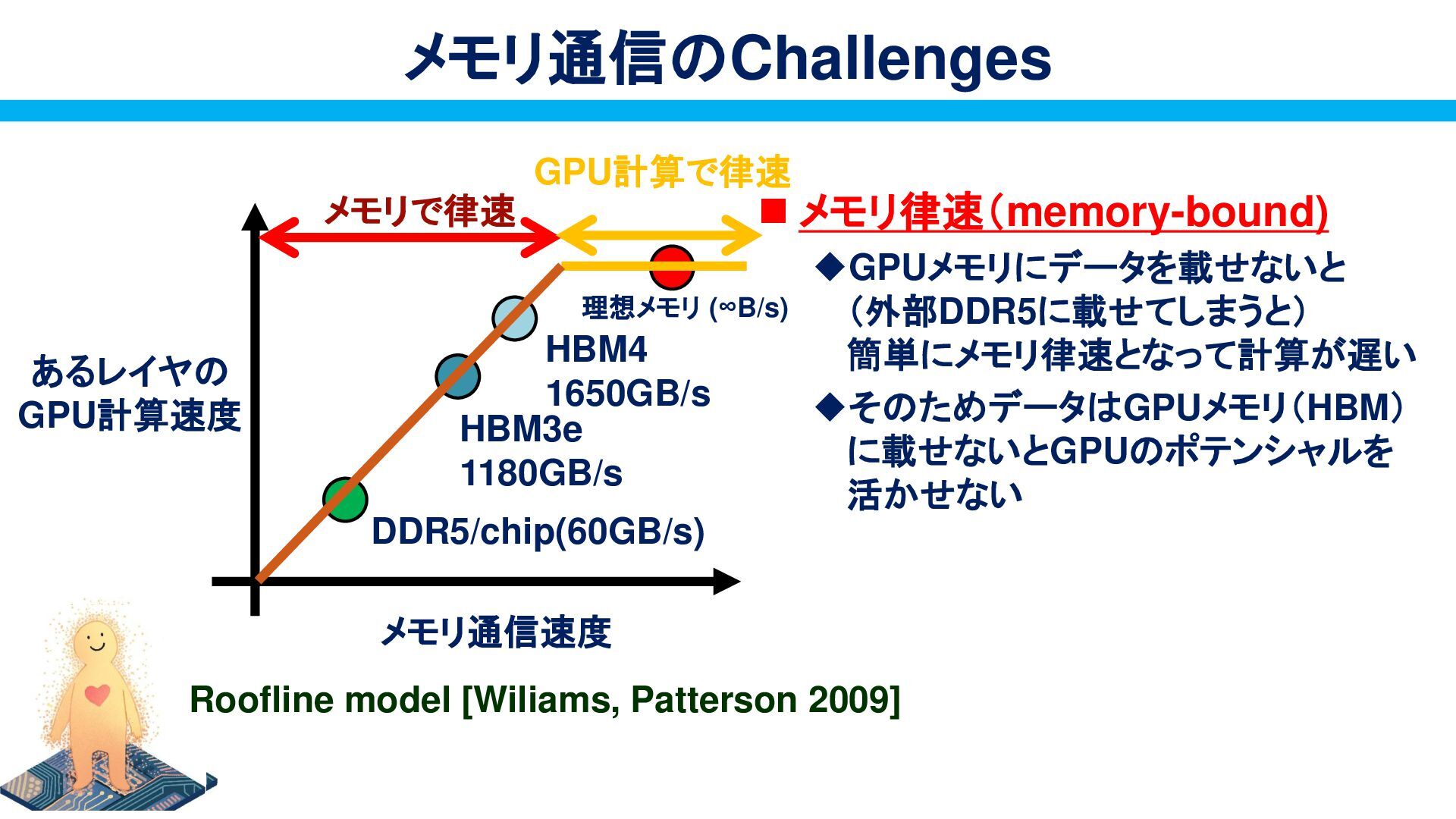{kind=link}
{kind=link}
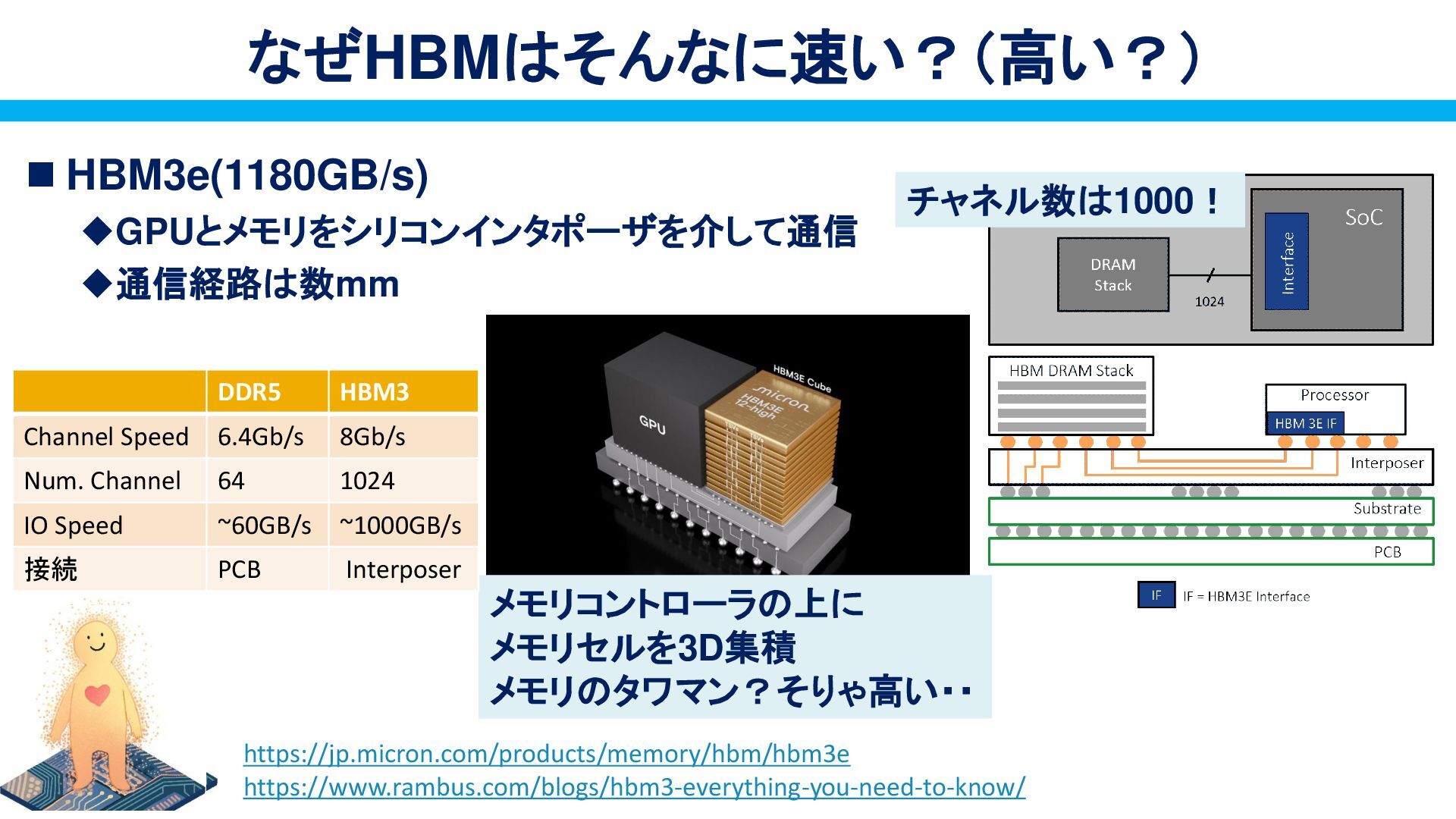{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![◼ Flash Attentionの中身 ◆2. Online Softmax[ref]により 分割データからsoftmaxを計算可能に ⚫通常kernel fusionはForwardのみ最適化する が、Flash](https://files.speakerdeck.com/presentations/f4ead78f61fa46069ee7e5fdb13fb47f/slide_18.jpg){kind=link}
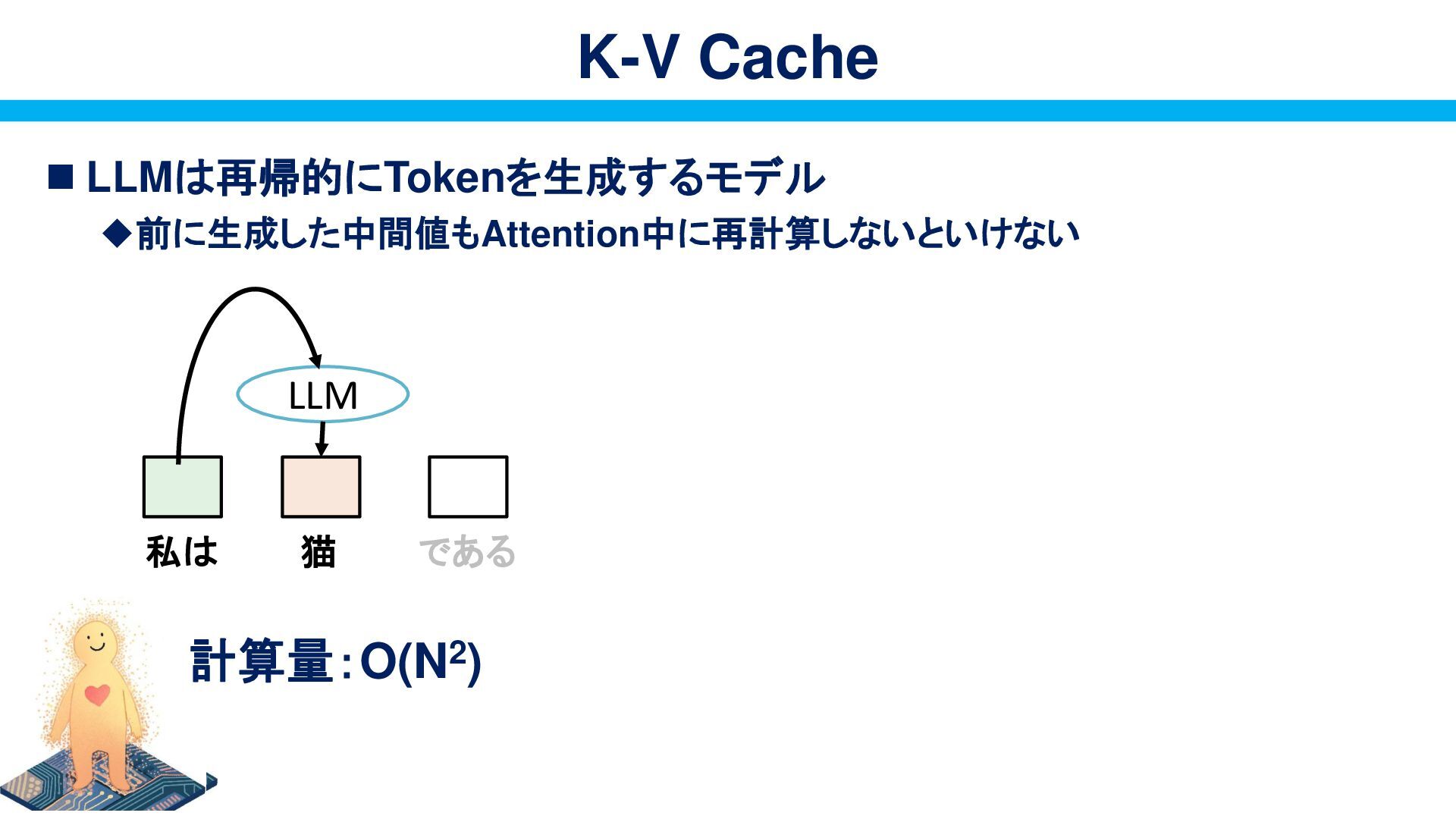{kind=link}
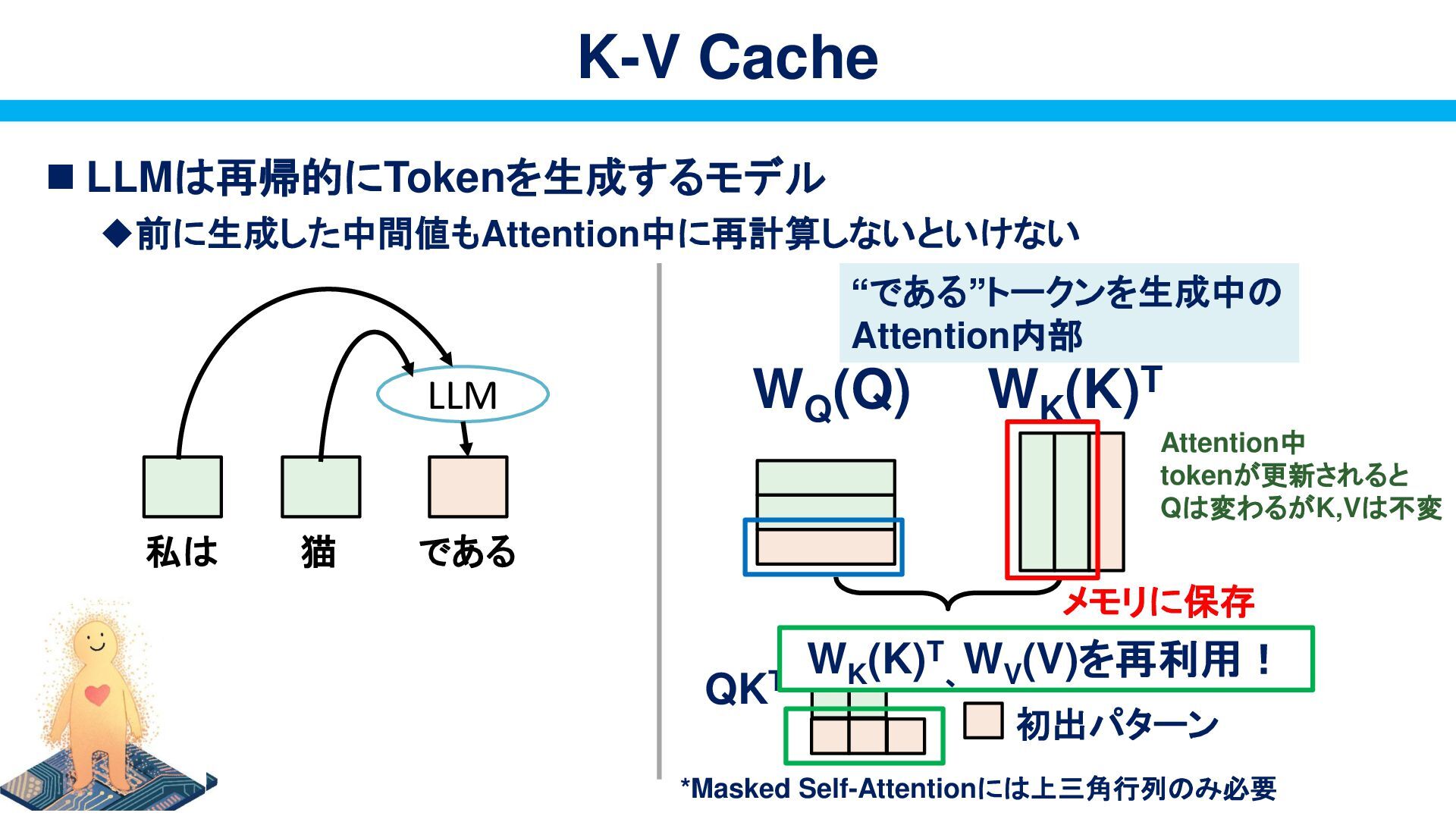{kind=link}
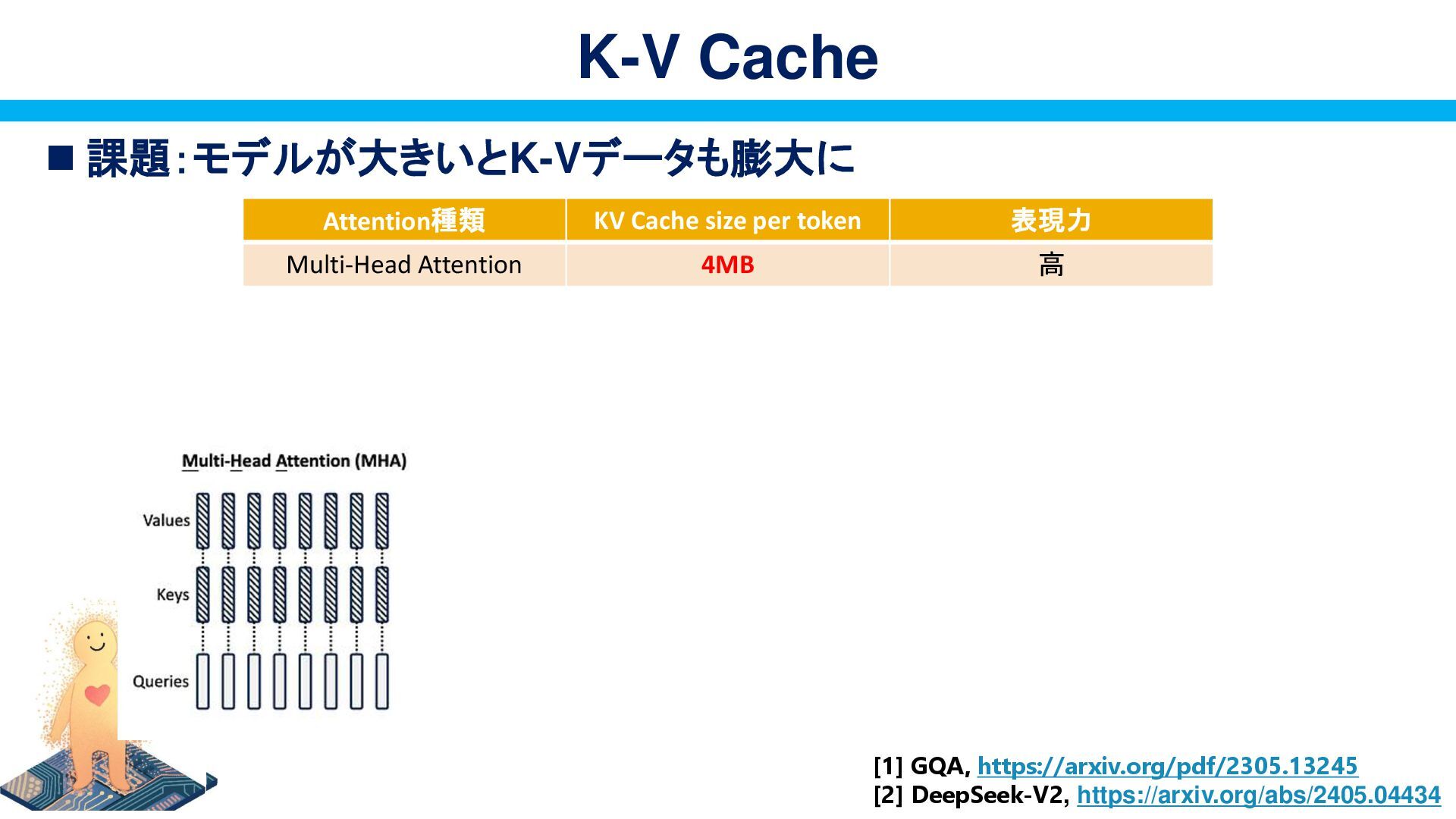{kind=link}
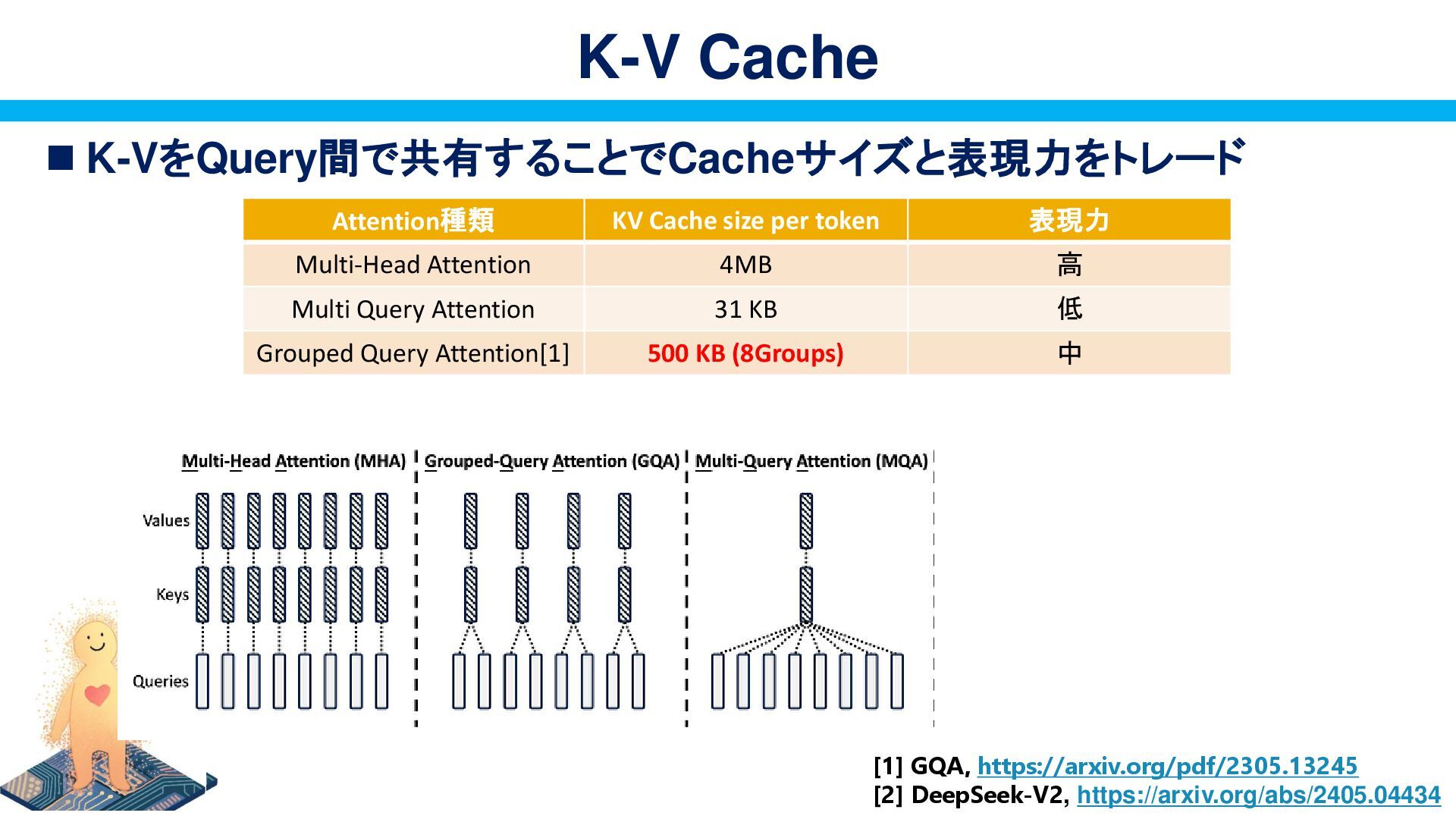{kind=link}
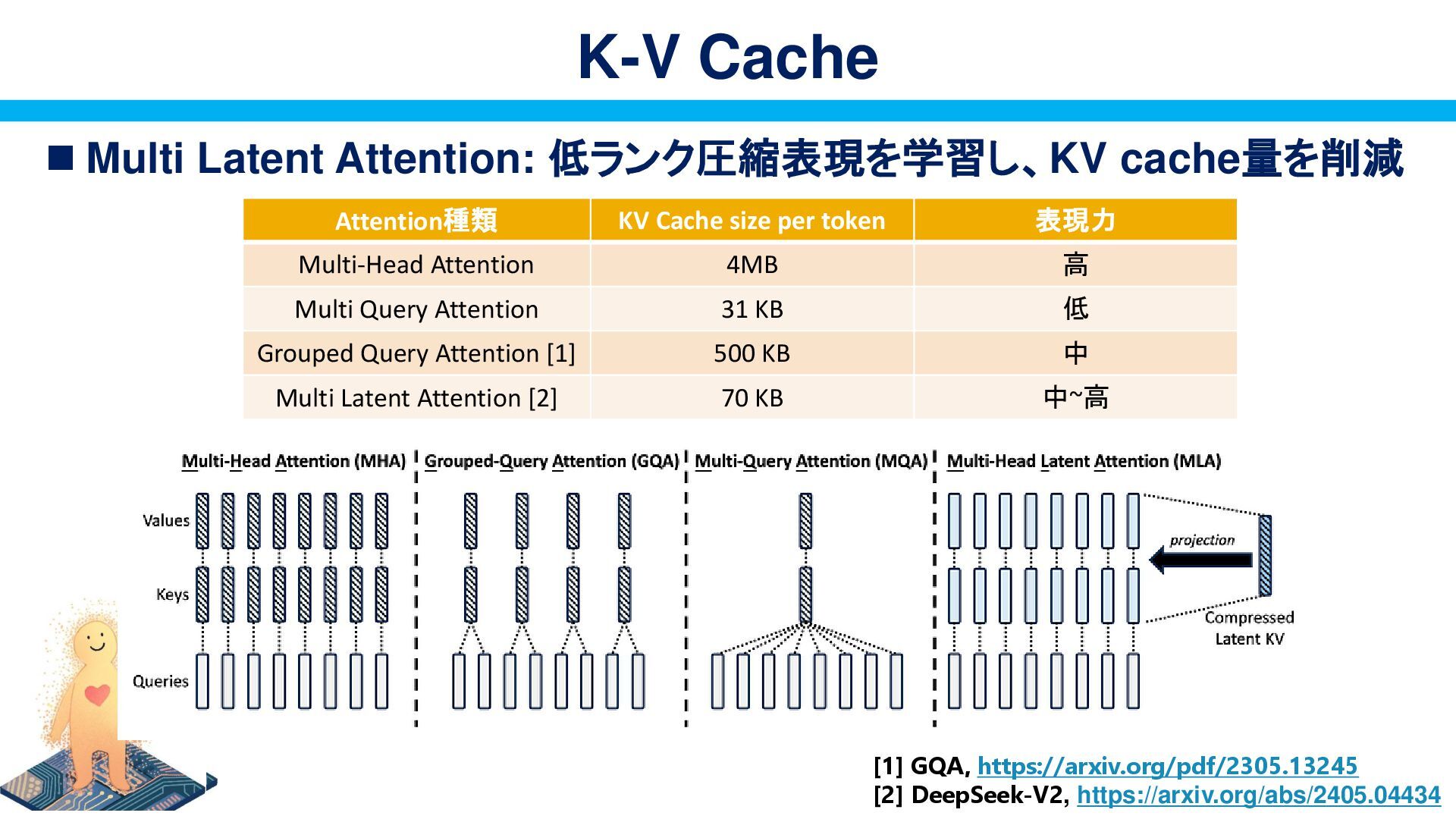{kind=link}
{kind=link}