and S. King, “Comparison of Speech Representations for Automatic Quality Estimation in Multi-Speaker Text-to-Speech Synthesis,” Speaker Odyssey, 2020. [2] K.-Z. Lee and E. Cooper, “A comparison of speaker-based and utterance-based data selection for text-to-speech synthesis,” Interspeech 2018, vol. 12873, 2018. [3] R. Dall, C. Veaux, J. Yamagishi, and S. King, “Analysis of speaker clustering strategies for hmm-based speech synthesis,” in Thirteenth Annual Conference of the International Speech Communication Association, 2012. [4] A. W. Black and T. Schultz, “Speaker clustering for multilingual synthesis,” in Multilingual Speech and Language Processing, 2006. [5] H. Zen, V. Dang, R. Clark, Y. Zhang, R. J. Weiss, Y. Jia, Z. Chen, and Y. Wu, “Libritts: A corpus derived from librispeech for textto-speech,” arXiv preprint arXiv:1904.02882, 2019. [6] D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X-vectors: Robust dnn embeddings for speaker recognition,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5329–5333. [7] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011. [8] H. Tachibana, K. Uenoyama, and S. Aihara, “Efficiently trainable text-to-speech system based on deep convolutional networks with guided attention,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4784–4788.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
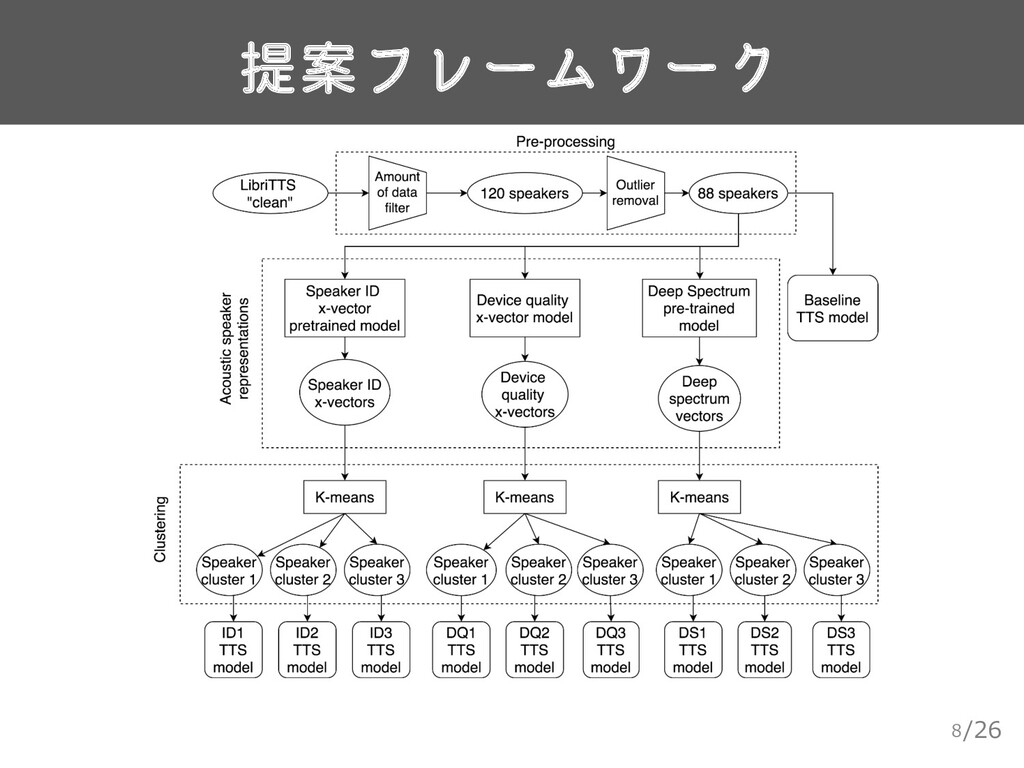
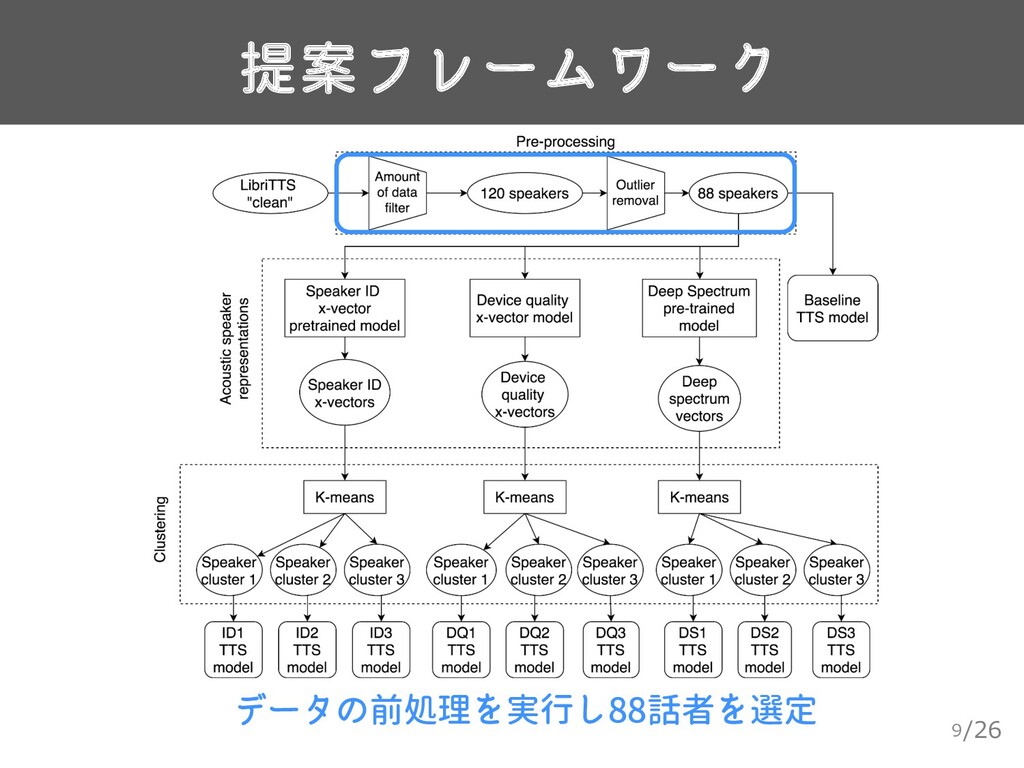
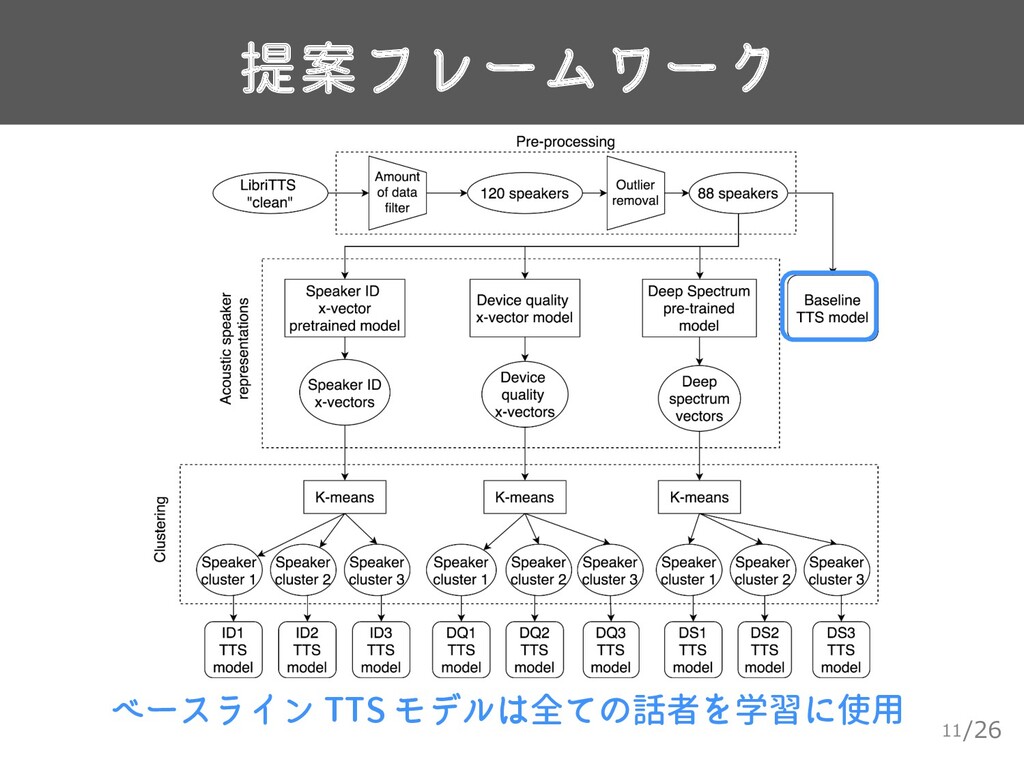
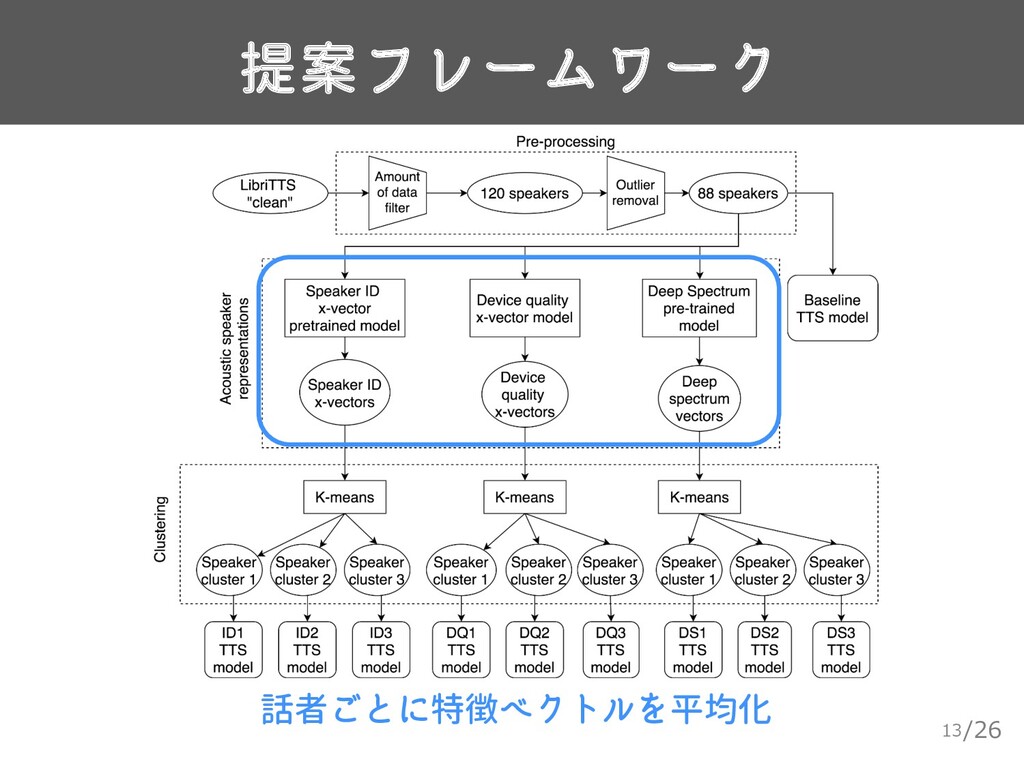
![/26 使用するデータ 10 ▸ LibriTTS[5] • 話者ごとのデータ量に偏り ▸ 発話時間が20分未満 or](https://files.speakerdeck.com/presentations/f33b53ce9ac24d308b0d21ed33b959f7/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
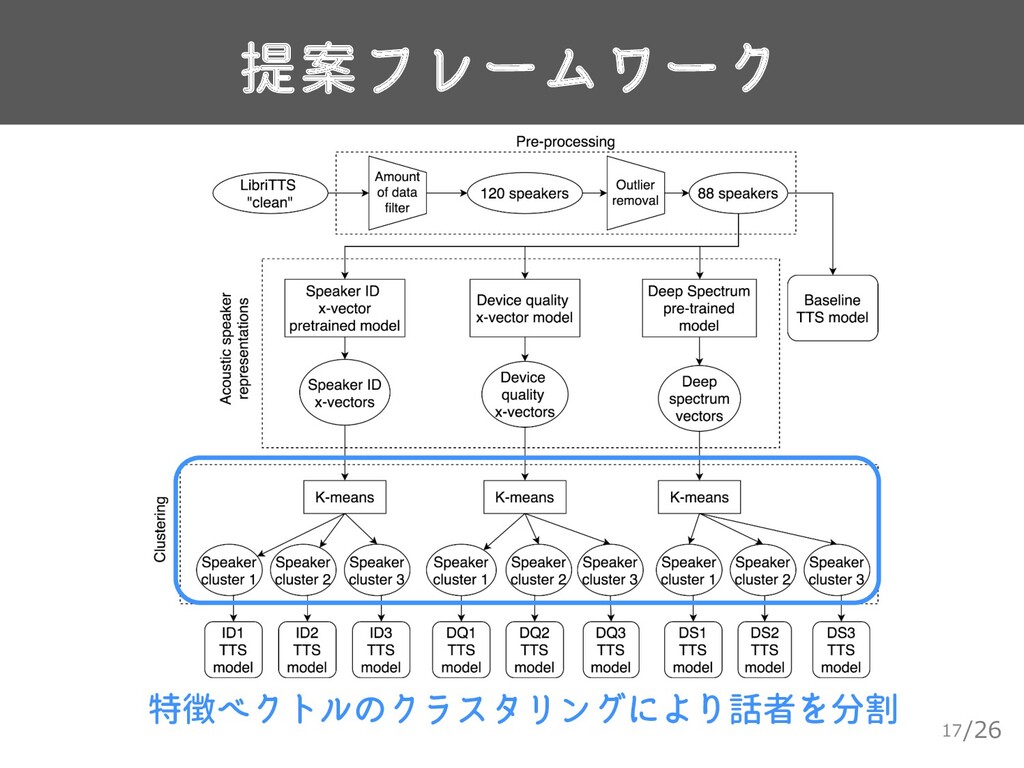{kind=link}
{kind=link}
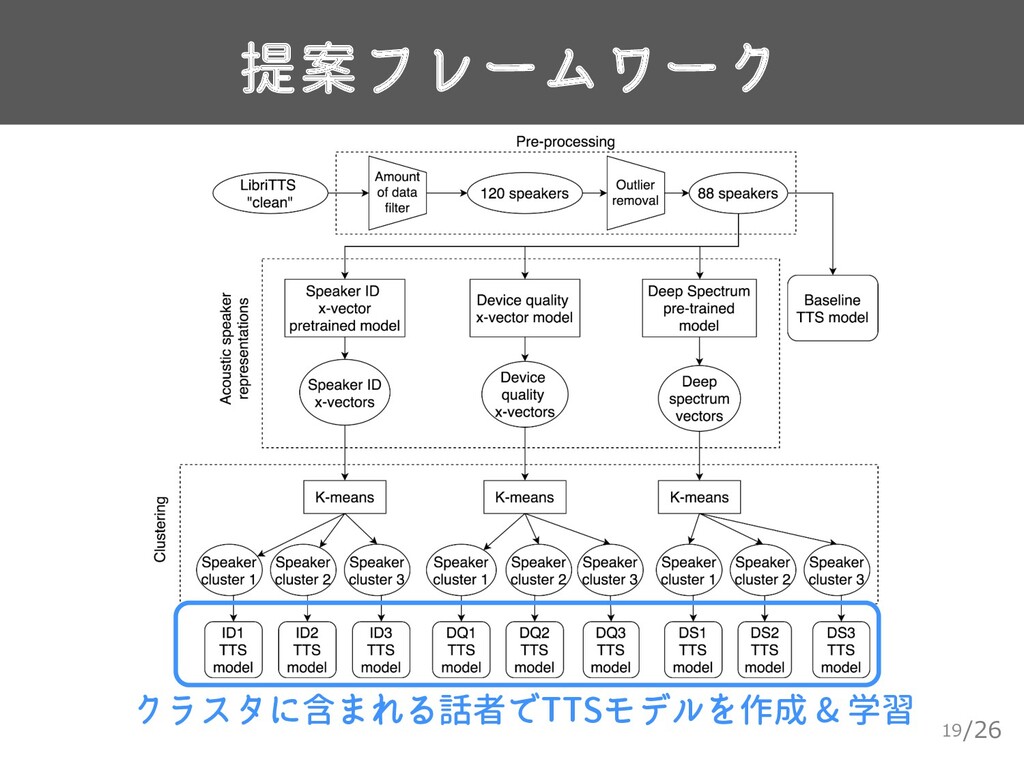{kind=link}
{kind=link}
{kind=link}
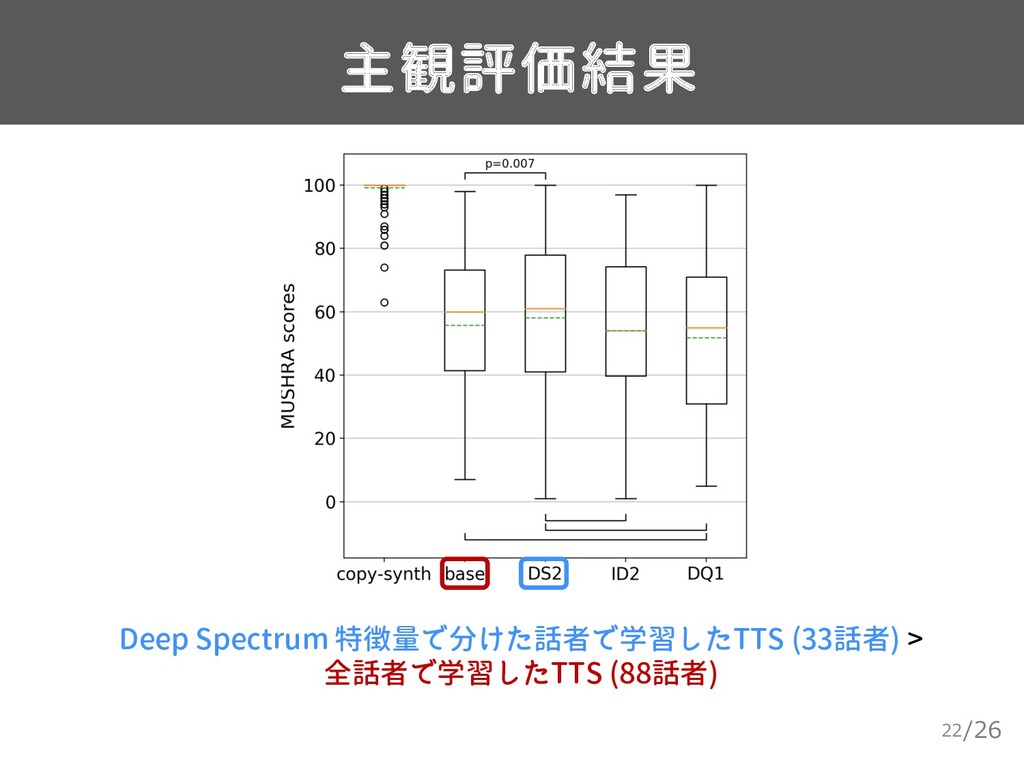{kind=link}
{kind=link}
![/26 合成音声 24 • [https://pilarog.github.io/] に生成された音声が掲載 • 波形生成は Griffin-Lim [10]アルゴリズムを使用](https://files.speakerdeck.com/presentations/f33b53ce9ac24d308b0d21ed33b959f7/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
![/26 参考文献 27 [1] J. Williams, J. Rownicka, P. Oplustil,](https://files.speakerdeck.com/presentations/f33b53ce9ac24d308b0d21ed33b959f7/slide_26.jpg){kind=link}
![/26 参考文献 28 [9] J. Shen, R. Pang, R. J.](https://files.speakerdeck.com/presentations/f33b53ce9ac24d308b0d21ed33b959f7/slide_27.jpg){kind=link}
{kind=link}