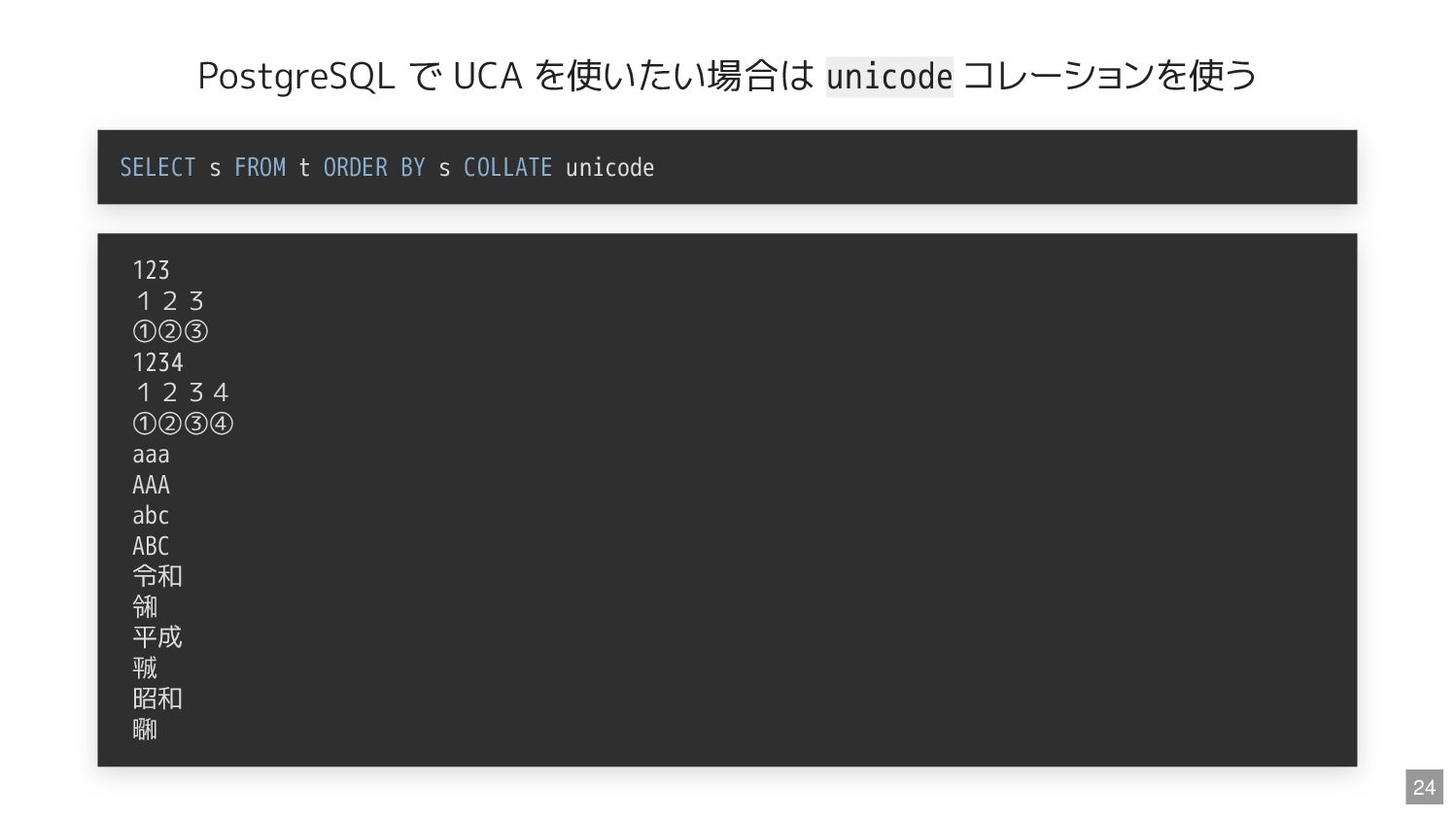
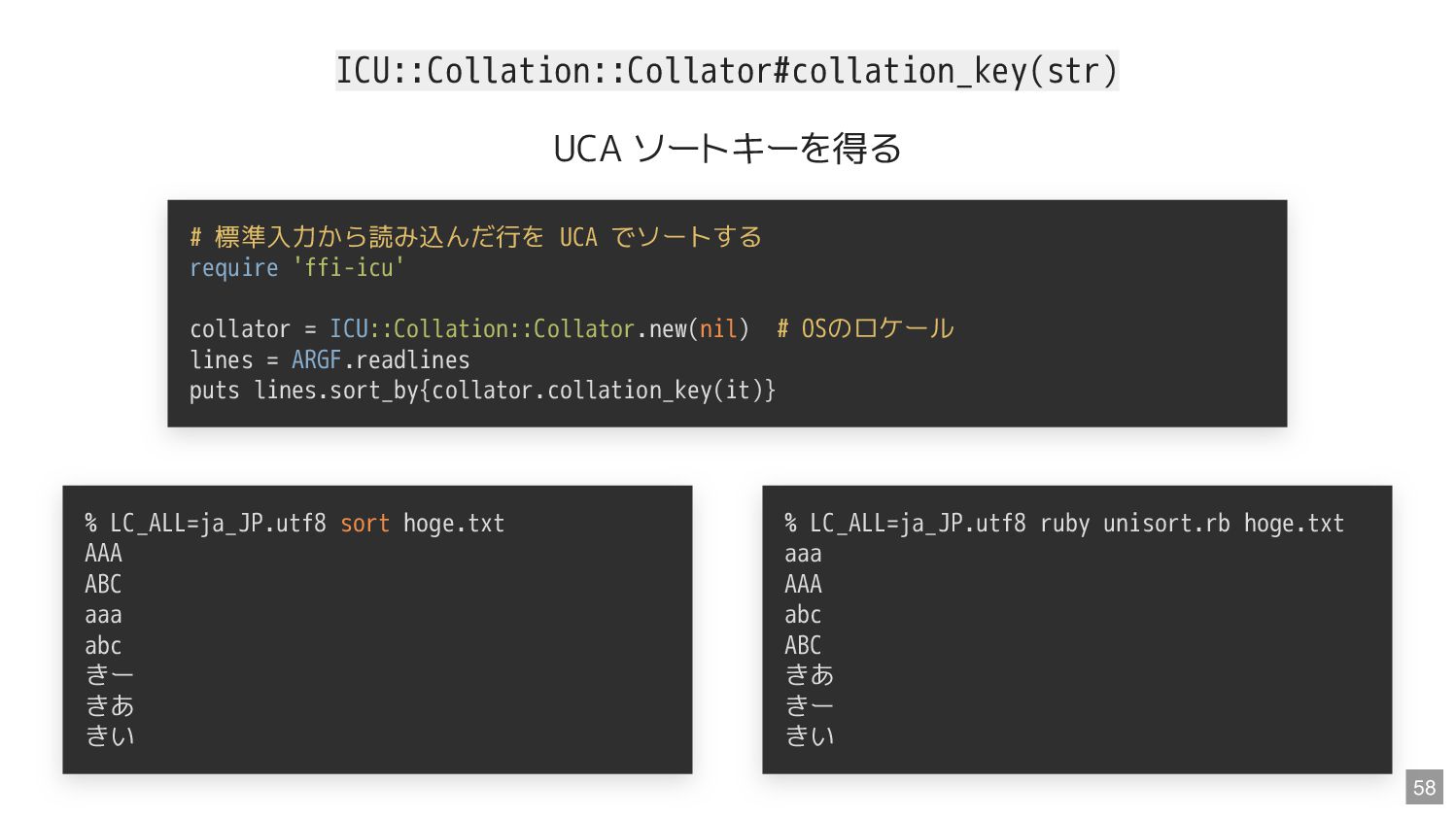
コレーション名 を指定する CREATE TABLE t (s VARCHAR COLLATE unicode) CREATE TABLE t (s VARCHAR(1000)) COLLATE utf8mb4_0900_as_cs SELECT * FROM t ORDER BY s COLLATE unicode 14
は3つの値からなる Default Unicode Collation Element Table (DUCET) • a : [.2380.0020.0002] • A : [.2380.0020.0008] • b : [.239A.0020.0002] • B : [.239A.0020.0008] • c : [.23B4.0020.0002] • C : [.23B4.0020.0008] https://www.unicode.org/Public/UCA/16.0.0/allkeys.txt 25
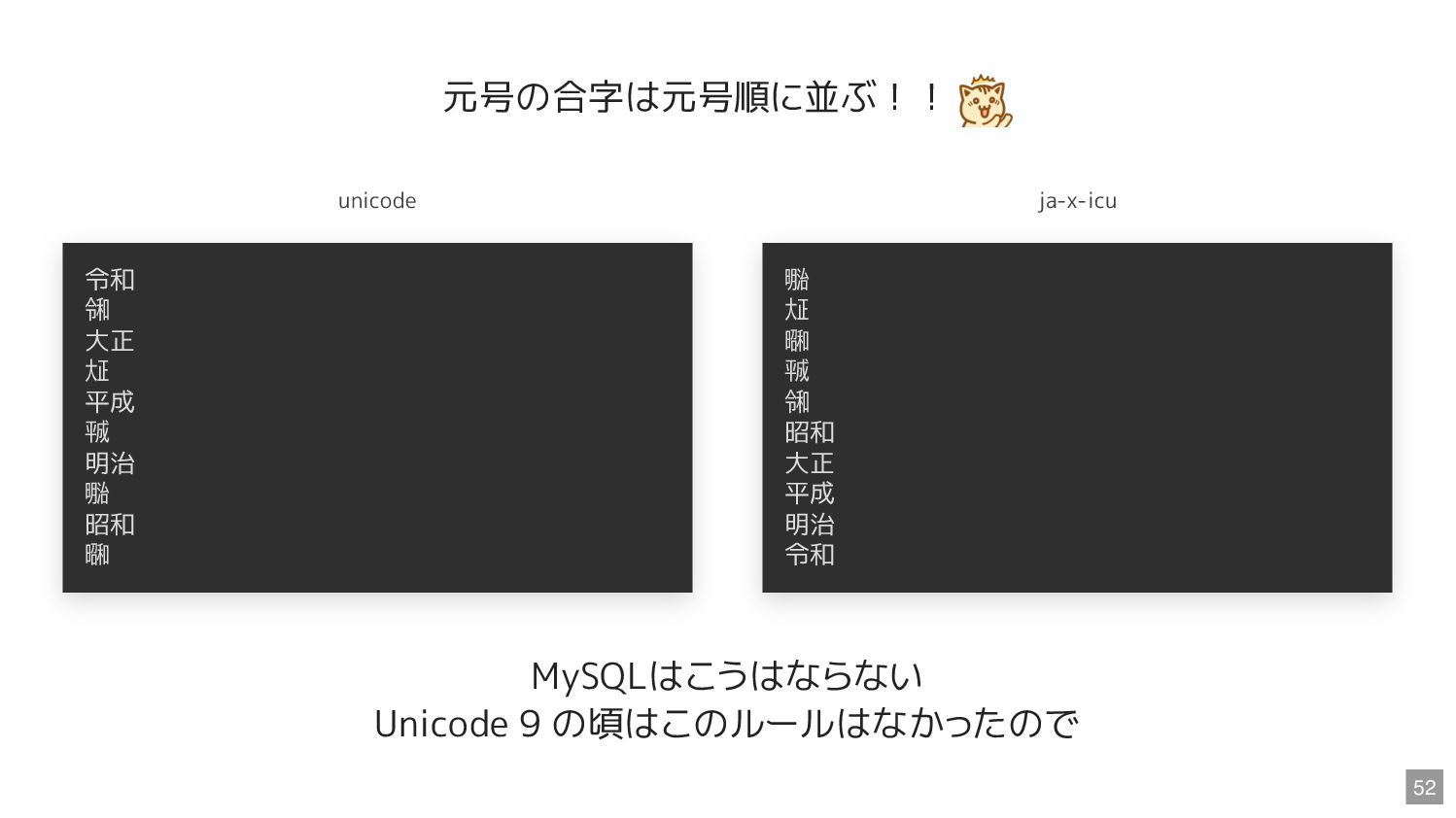
安 於 永 ORDER BY s COLLATE "ja-x-icu" 安 以 宇 永 於 ja ロケールでは漢字はJISコード順! JIS第1水準文字は音読みの順に並んでる https://github.com/unicode-org/cldr/blob/main/common/collation/ja.xml 51
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![文字ごとではなく文字列全体のソートキーを求める 文字列中の文字のweightの1番目の値、2番目の値、 3番目の値をまとめて 0000 で連結する abc : [.2380.0020.0002] [.239A.0020.0002] [.23B4.0020.0002]](https://files.speakerdeck.com/presentations/d60ebe2d00e9409289dc9a037e899f52/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
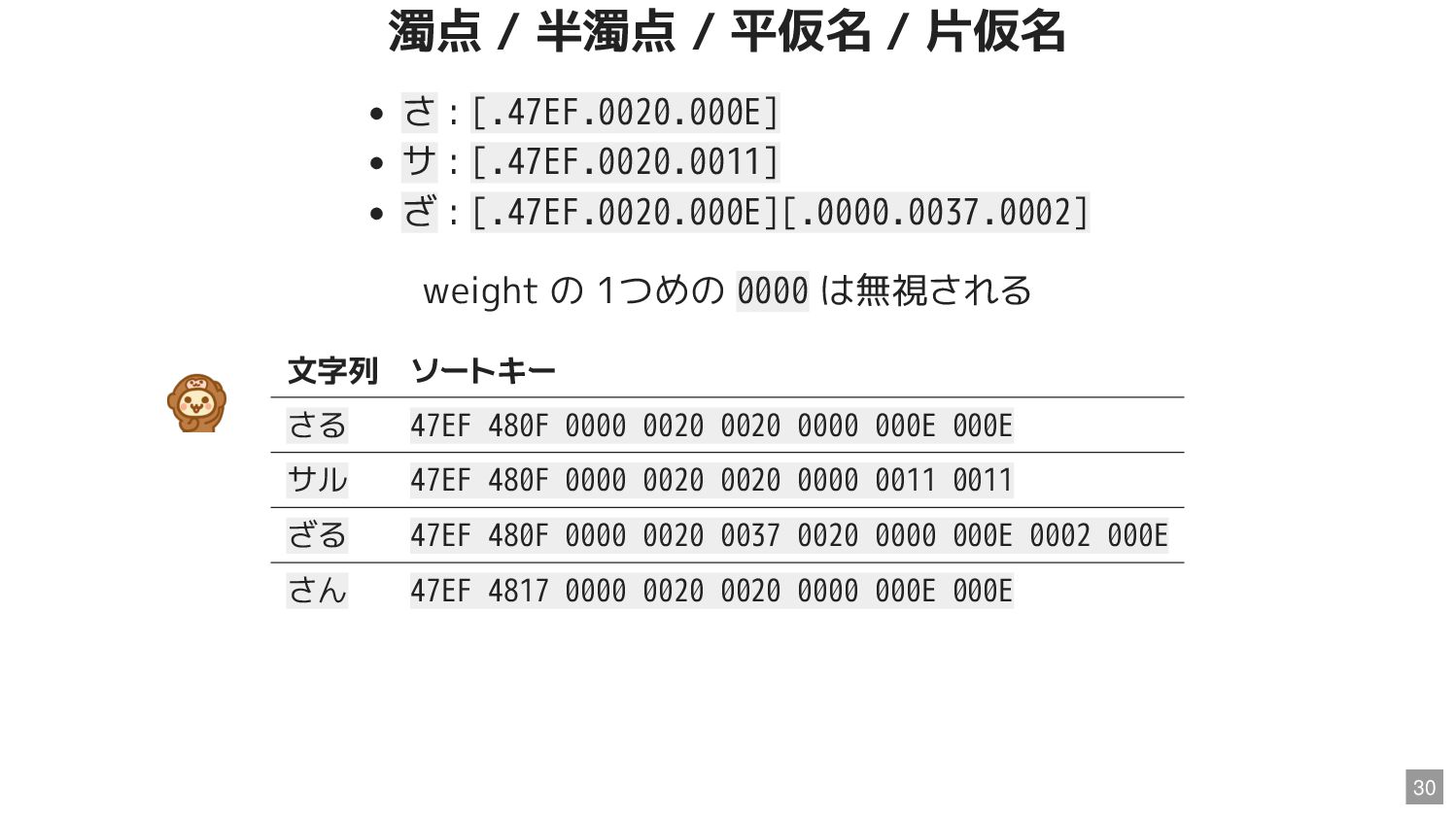
![Unicode 9 の DUCET より 「さ」「サ」「ざ」 3055 ; [.3D65.0020.000E] #](https://files.speakerdeck.com/presentations/d60ebe2d00e9409289dc9a037e899f52/slide_35.jpg){kind=link}
![ai_ci 3055 ; [.3D65 ] # HIRAGANA LETTER SA 30B5](https://files.speakerdeck.com/presentations/d60ebe2d00e9409289dc9a037e899f52/slide_36.jpg){kind=link}
![as_ci 3055 ; [.3D65.0020 ] # HIRAGANA LETTER SA 30B5](https://files.speakerdeck.com/presentations/d60ebe2d00e9409289dc9a037e899f52/slide_37.jpg){kind=link}
![as_cs 3055 ; [.3D65.0020.000E] # HIRAGANA LETTER SA 30B5 ;](https://files.speakerdeck.com/presentations/d60ebe2d00e9409289dc9a037e899f52/slide_38.jpg){kind=link}
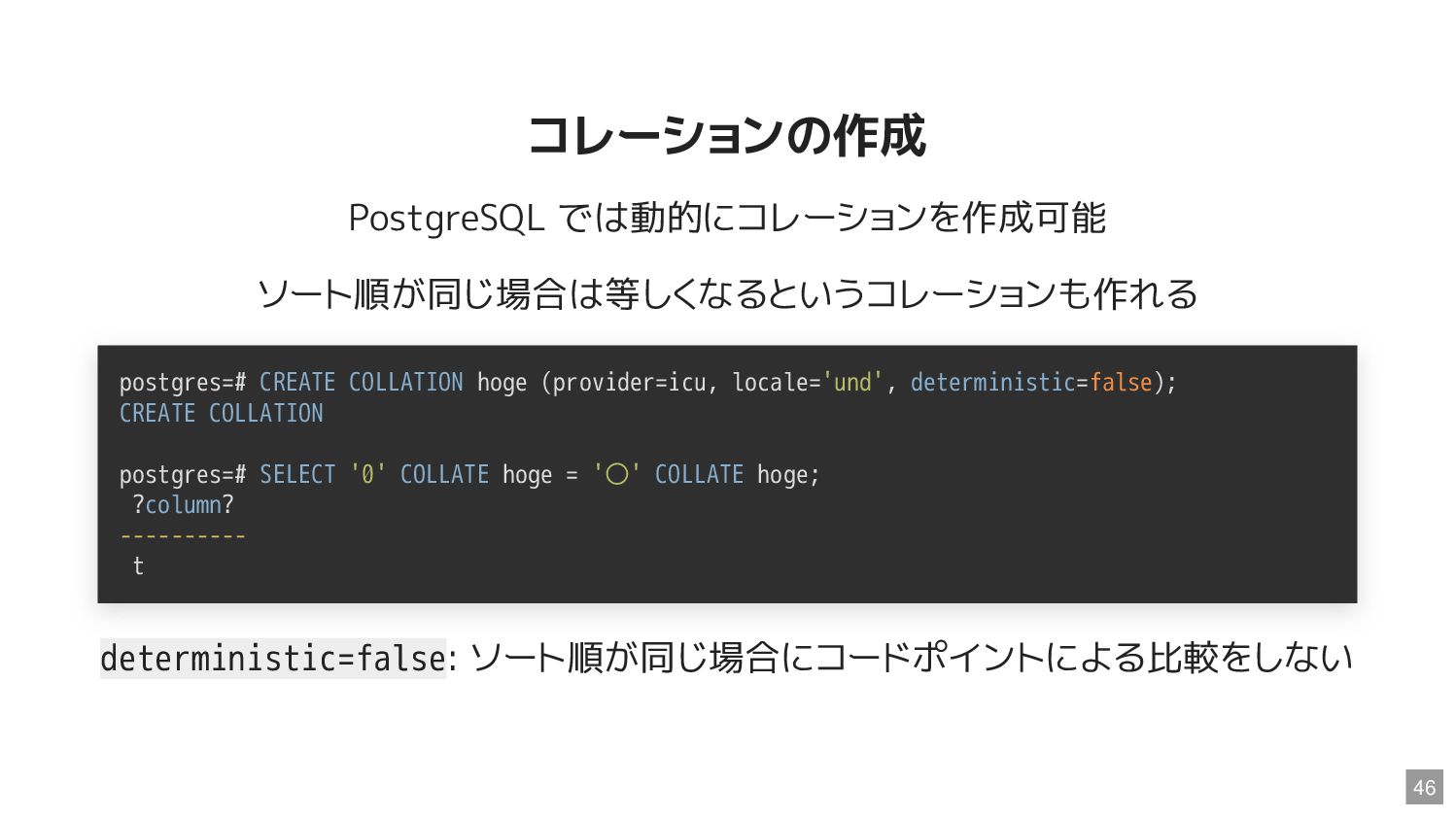
![異なる文字でも同じ weight 結構ある たとえば 0 と 〇 0030 ; [.217D.0020.0002]](https://files.speakerdeck.com/presentations/d60ebe2d00e9409289dc9a037e899f52/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}