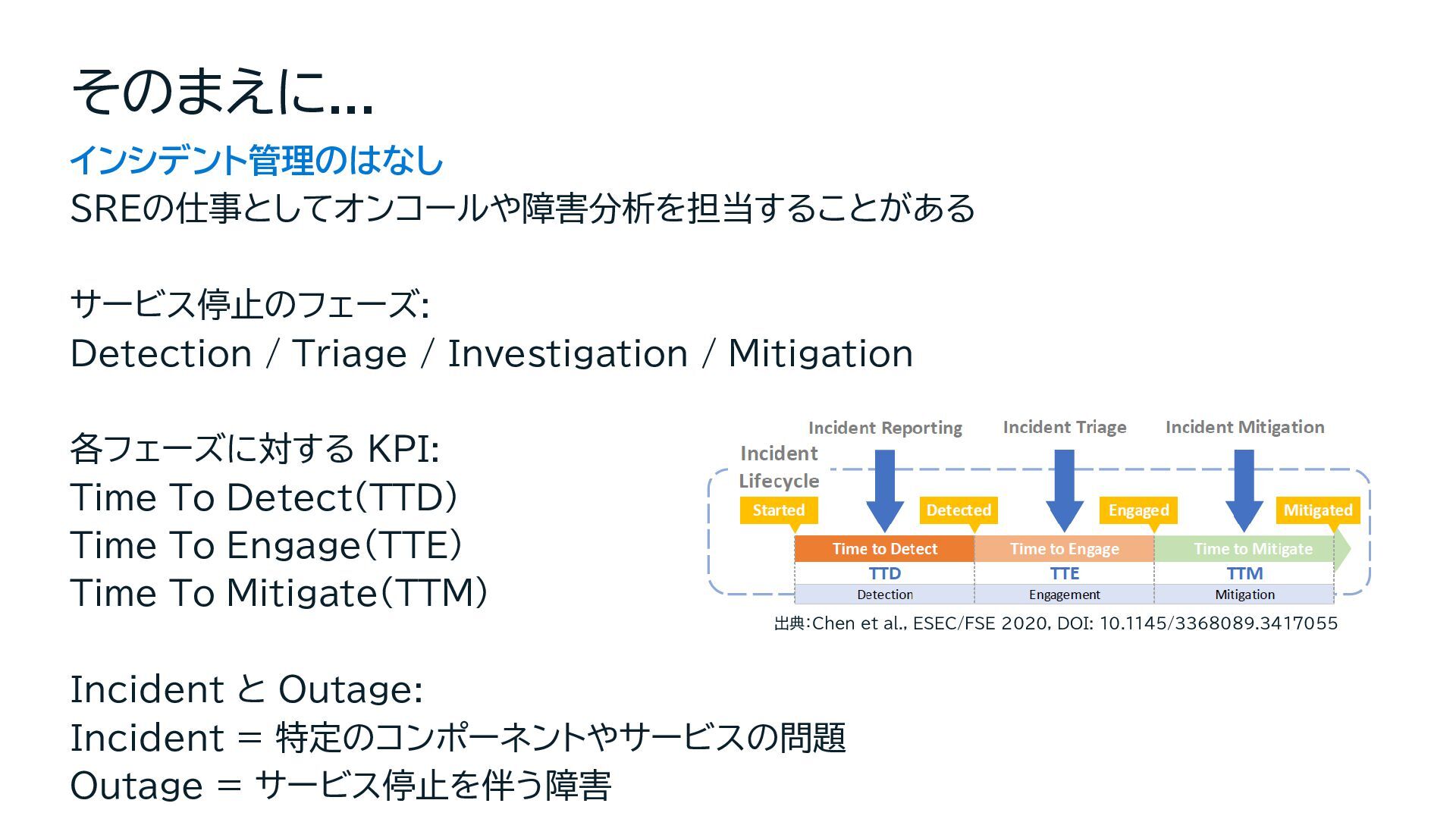
Zhang, H., Xu, H., Zhou, Y., Yang, L., Sun, J., Xu, Z., Dang, Y., Gao, F., Zhao, P., Qiao, B., Lin, Q., Zhang, D., & Lyu, M. R. (2020). Towards intelligent incident management: why we need it and how we make it. Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2020), 1487-1497. https://doi.org/10.1145/3368089.3417055 [2] Yu, Z., Ma, M., Feng, X., Ding, R., Zhang, C., Li, Z., Chintalapati, M., Zhang, X., Wang, R., Bansal, C., Rajmohan, S., & Lin, Q. (2025). Triangle: Empowering Incident Triage with Multi-LLM-Agents. Unpublished manuscript, Microsoft Research. https://www.microsoft.com/en-us/research/publication/triangle- empowering-incident-triage-with-multi-llm-agents/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![インシデントの検出・トリアージ・相関関係の生成 BRAIN[1] Microsoft の AIOps の取り組みのひとつ 機械学習ベース サービスや IcM に組み込まれている](https://files.speakerdeck.com/presentations/22a7cc05017442e1bd2b05ecfcd61e5f/slide_25.jpg){kind=link}
![トリアージの精度向上 Triangle[2] LLM+エージェントを活用したトリアージの 精度向上 意味的蒸留メカニズム 3種類のキーフレーズ (障害の場所、症状、必要な能力)を抽出 マルチロールエージェントフレームワーク 3つの専門化されたエージェント(Analyser、Triage Decider、Team](https://files.speakerdeck.com/presentations/22a7cc05017442e1bd2b05ecfcd61e5f/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考資料 [1] Chen, Z., Kang, Y., Li, L., Zhang, X.,](https://files.speakerdeck.com/presentations/22a7cc05017442e1bd2b05ecfcd61e5f/slide_32.jpg){kind=link}
{kind=link}
{kind=link}