Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
「実践DataOps」書籍紹介
Search
wakama1994
May 25, 2025
Programming
84
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
「実践DataOps」書籍紹介
個人で参加してる「DS協会コンペ部」の月次共有会にて発表した資料
wakama1994
May 25, 2025
More Decks by wakama1994
See All by wakama1994
Rで始めるML・LLM活用入門
wakamatsu_takumu
0
280
ド文系だった私が、 KaggleのNCAAコンペでソロ金取れるまで
wakamatsu_takumu
3
2.9k
Kaggleの歩き方-関西Kaggler会に参加してみて-
wakamatsu_takumu
2
710
BQで天気基盤をつくって、役立つ情報を可視化してみた!
wakamatsu_takumu
4
1.3k
「データモデリング実践入門」は20年経っても色あせない
wakamatsu_takumu
4
1.5k
いろんな可視化ツールあるけどggplotて何がいいの?- 複数ツールで比較してみた!-
wakamatsu_takumu
1
1.6k
文系出身でも「アルゴリズム×数学」はスッキリ理解できた!話
wakamatsu_takumu
0
660
ChatGPTにどんなときRを使えばいいか聞いてみた!
wakamatsu_takumu
0
760
A/Bテスト実践ガイド ~真のデータドリブンへ至る信用できる実験とは~
wakamatsu_takumu
1
1.9k
Other Decks in Programming
See All in Programming
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
150
AI時代、エンジニアはどう育つのか -未経験エンジニアの成長を間近で見て考えたこと-
thasu0123
0
110
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
5.7k
1年で人数1.5倍、PR数5.5倍増。 品質とアウトカムはどうなったか、 何が効いたか
ike002jp
0
120
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
160
Semantic Version 単位で戦略を柔軟に変えて、パッケージアップデートを自動化する
daitasu
1
350
例外の正しい扱い方 そのエラー try-catchして大丈夫?
jinwatanabe
0
360
ランチタイムLT会3周年!ランチタイムLT会を3年間続けられたお話
y0hgi
1
140
Developing with AI Agents — Codex, Claude Code & Cowork Practical Guide
x5gtrn
PRO
0
1.4k
霧の中の代数的エフェクト
funnyycat
1
340
初めてのKubernetes 本番運用でハマった話
oku053
0
120
どこまでゆるくて許されるのか
tk3fftk
0
470
Featured
See All Featured
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.6k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
220
Automating Front-end Workflow
addyosmani
1370
210k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
Being A Developer After 40
akosma
91
590k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
The Limits of Empathy - UXLibs8
cassininazir
1
450
Navigating Team Friction
lara
192
16k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
Transcript
『実践DataOps』 書籍紹介 データサイエンティスト協会 (DS協会) コンペ部 2025年3月, 5月 月次共有会
AGENDA 2 Part1 DataOps序論 Chapter1 データサイエンスの問題点 Chapter2 データ戦略 Part2 DataOpsの実践に向けて
Chapter3 リーンシンキング Chapter4 アジャイルなコラボレーション Chapter5 効果測定とフィードバックの仕組み作り
AGENDA 3 Part3 更なるステップアップ Chapter6 信頼の構築 Chapter7 DataOpsのDevOpsの適応 Chapter8 DataOps実現のための組織作り
Part4 セルフサービス型組織 Chapter9 DataOpsで用いるテクノロジー Chapter10 DataOpsの導入手順
4 お断り: • 著作権の都合上、定例会で共有した図についてのスクショは Speacker Deckでは省略 • それに伴い、一部の図に関しては文章のみに変更を加えている
5 Chapter1 データサイエンスの問題点
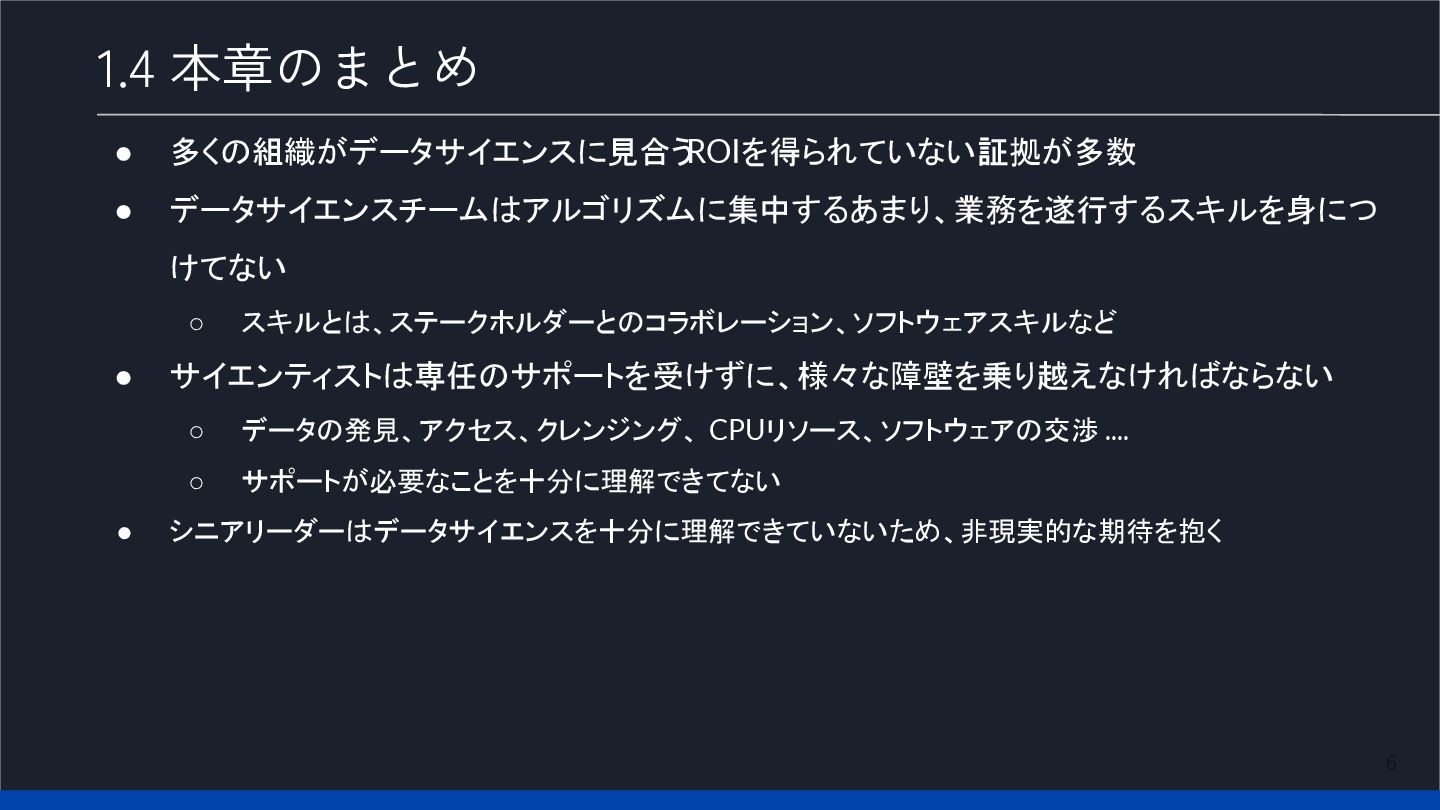
6 1.4 本章のまとめ • 多くの組織がデータサイエンスに見合う ROIを得られていない証拠が多数 • データサイエンスチームはアルゴリズムに集中するあまり、業務を遂行するスキルを身につ けてない ◦
スキルとは、ステークホルダーとのコラボレーション、ソフトウェアスキルなど • サイエンティストは専任のサポートを受けずに、様々な障壁を乗り越えなければならない ◦ データの発見、アクセス、クレンジング、 CPUリソース、ソフトウェアの交渉 .... ◦ サポートが必要なことを十分に理解できてない • シニアリーダーはデータサイエンスを十分に理解できていないため、非現実的な期待を抱く
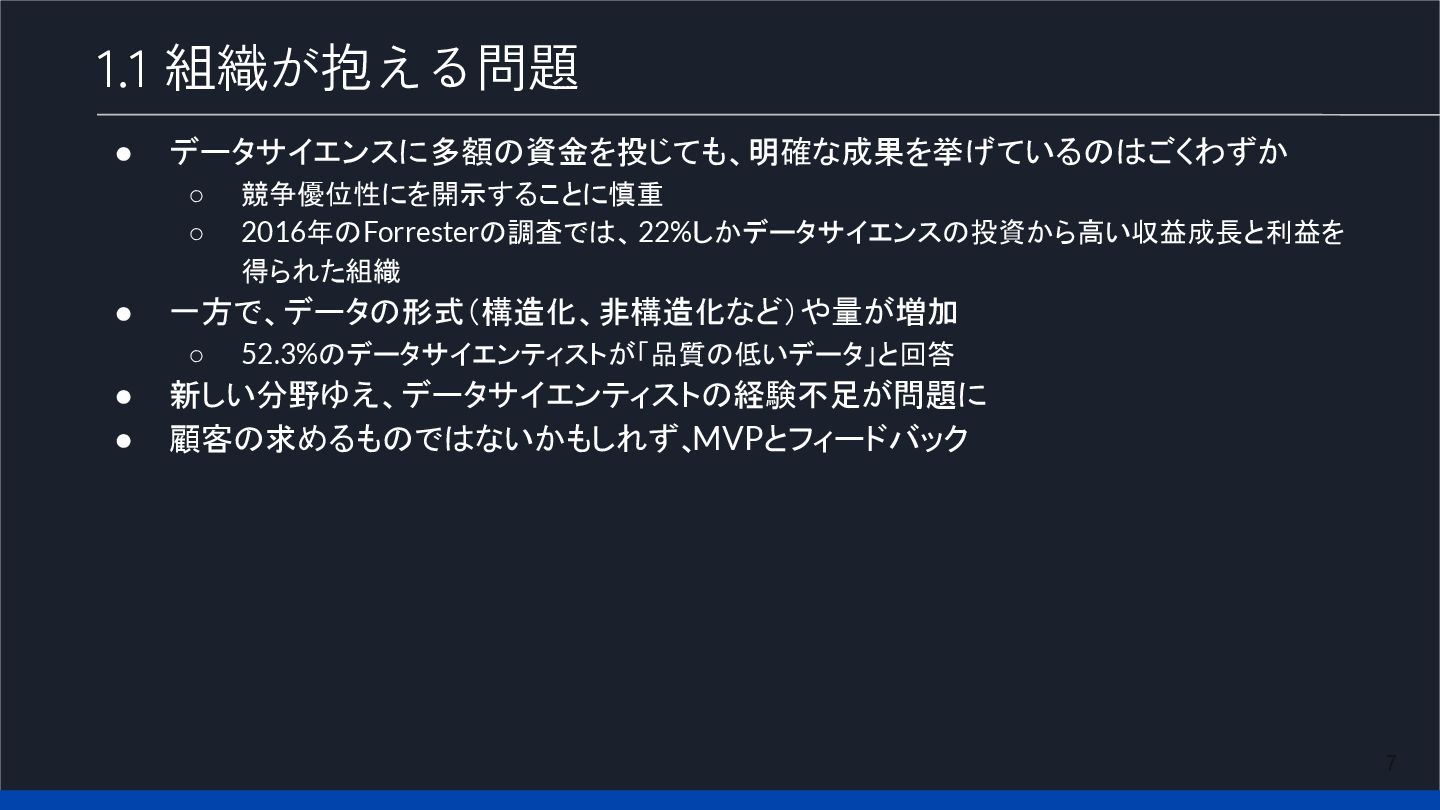
7 1.1 組織が抱える問題 • データサイエンスに多額の資金を投じても、明確な成果を挙げているのはごくわずか ◦ 競争優位性にを開示することに慎重 ◦ 2016年のForresterの調査では、22%しかデータサイエンスの投資から高い収益成長と利益を 得られた組織
• 一方で、データの形式(構造化、非構造化など)や量が増加 ◦ 52.3%のデータサイエンティストが「品質の低いデータ」と回答 • 新しい分野ゆえ、データサイエンティストの経験不足が問題に • 顧客の求めるものではないかもしれず、 MVPとフィードバック
8 1.2 知識のギャップ • データサイエンティストの知識ギャップ ◦ 目指すべきはMVPの本番化でモデルの作成技術とは異なる • IT知識のギャップ ◦
機械学習と通常のプログラミングの間の決定的違い • テクノロジー知識のギャップ • 経営層の知識ギャップ ◦ CEOやCFOのほとんどは、数字に強い or ITリテラシーが高いがデータサイエンスを十分理解し てない ◦ 短期的な成果や非現実的な期待を抱きがち • データリテラシーのギャップ ◦ 高度な分析技術スキルをもつ人材は極めて少ない
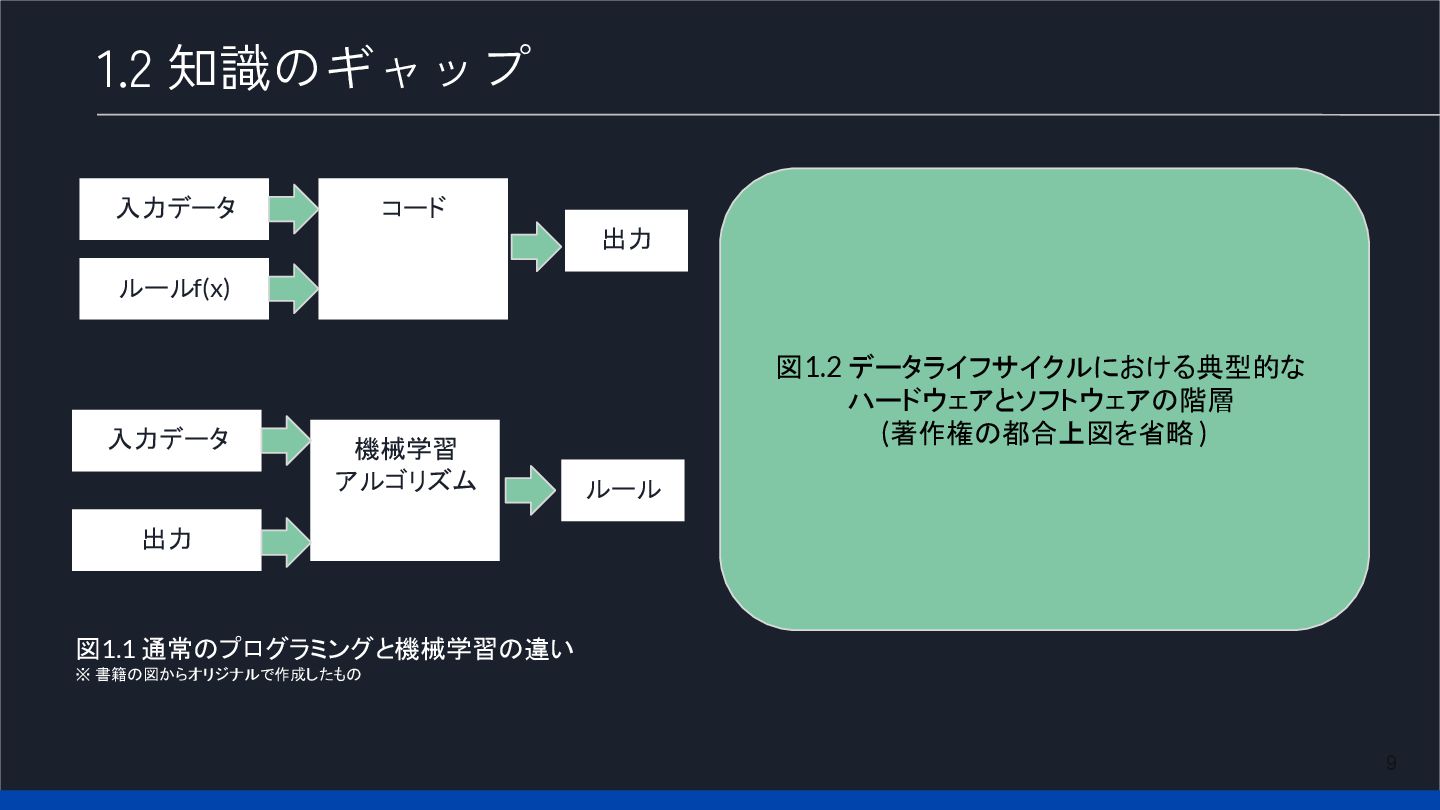
9 1.2 知識のギャップ 入力データ ルールf(x) コード 出力 図1.1 通常のプログラミングと機械学習の違い ※
書籍の図からオリジナルで作成したもの 入力データ 出力 機械学習 アルゴリズム ルール 図1.2 データライフサイクルにおける典型的な ハードウェアとソフトウェアの階層 (著作権の都合上図を省略 )
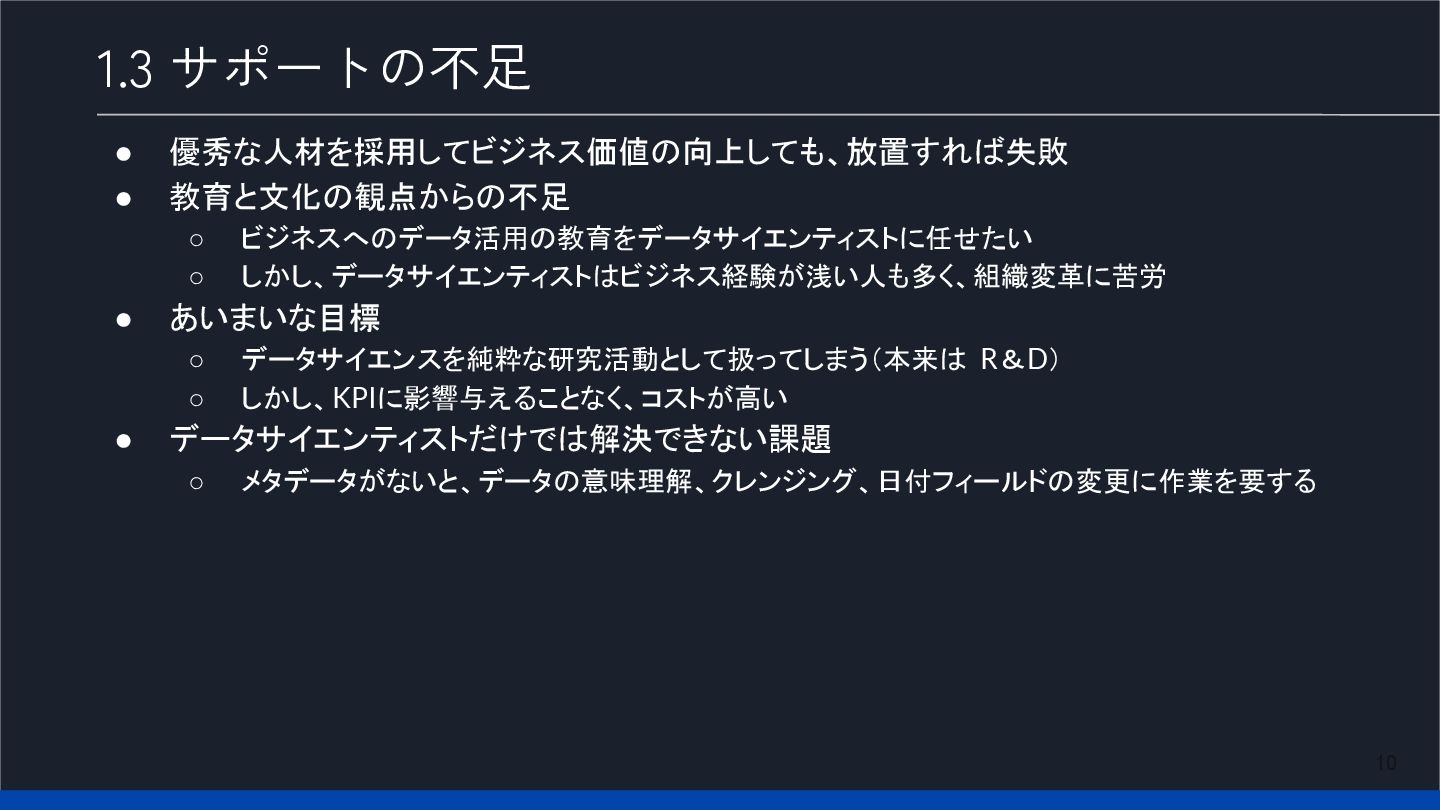
10 1.3 サポートの不足 • 優秀な人材を採用してビジネス価値の向上しても、放置すれば失敗 • 教育と文化の観点からの不足 ◦ ビジネスへのデータ活用の教育をデータサイエンティストに任せたい ◦
しかし、データサイエンティストはビジネス経験が浅い人も多く、組織変革に苦労 • あいまいな目標 ◦ データサイエンスを純粋な研究活動として扱ってしまう(本来は R&D) ◦ しかし、KPIに影響与えることなく、コストが高い • データサイエンティストだけでは解決できない課題 ◦ メタデータがないと、データの意味理解、クレンジング、日付フィールドの変更に作業を要する
11 Chapter2 データ戦略
12 2.6 本章のまとめ • 現代のデータアナリティクスは、従来のようなデータの業務利用やデータマネジメントの手法 では対応が困難 • データ戦略の策定はデータライフサイクルを中心に行い、経営層からの合意が必要 ◦ ミッション、ビジョン、目標、強み、弱み、外部環境を把握
• 戦略達成の目標には、人材、テクノロジー、プロセスの改善が必要 ◦ アジャイル型で進めるべき、ウォーターフォールは NG
13 2.1 なぜ新しいデータ戦略が必要なのか • 施策によってはリソースの配置をミスって、投資を無駄にする可能性 • データはもはやITではない ◦ かつては、コンピュータサイエンスの一部(第 1期-第4期)
◦ 今やITアプリケーションの副産物ではなく、価値ある原材料 ◦ データサイエンスとアナリティクスは競争力の前提 • データ戦略のスコープ ◦ 取得>保管>処理>共有>利用>廃棄の一連の流れ(図 2.1) • 時間軸 ◦ 2年より短い場合は、対処療法になってしまい人材育成がうまく行かない ◦ 5年を超えると、テクノロジー、アナリティクス、ビジネス環境の変化の予測が難しい • スポンサー ◦ 経営陣がサポート
14 2.2 状況把握から始める • 組織をしる ◦ 戦略のスコープ、製品の強み・弱み、競合他社、目標と実績のギャップやその原因、顧客は誰 で理想とのギャップ、愛着はあるか、社会的経済的脅威の有無 • 人材をしる
◦ リーダーは誰か、有力なステークホルダーはデータチームをどう見てるか、意思決定を行う可能 性が高いのは誰か、データを使う理由と用途 ◦ 組織内の作業量と人材がマッチするか、事業目標やステークホルダーと一致するか、人材が フィットしているか(離職率)、顧客ニーズと一致するか • テクノロジーを知る ◦ データアーキテクチャ、 VM・PaaS・コンテナ管理ソリューション (Kubernaetesなど)言語アプリ ケーション... • プロセス成熟度をしる ◦ アナリティクスの能力、 ETLの効率的プロセス、開発ライフサイクル、顧客とデータプロダクトの 接点 • データ資産 ◦ データオーナー・データスチュワードの存在、データプロベナンス(履歴)リネージ、マスターデー タ管理や参照データ、データ品質保証と品質管理
15 2.3 分析のユースケースを特定する • 「私たちのAI戦略は何か」「私たちのビッグデータ戦略は何か」に収支しがち • ミッション、ビジョン、KPI ◦ OKR(Object and
Key Results)目標達成の主要な結果を測定 • アイデアを練る、自分たちにできることは何かを把握 ◦ 分析の選択肢を幅広く検討し、アナリティクスタイプを理解(図 2.2) ◦ 分析目標(イニシアチブ)は短くて簡素に
16 2.4 データライフサイクルの評価尺度 • ギャップ分析 ◦ 小売の例:「組織の収益目標を達成するために、顧客情報、取引履歴、製品情報を使って機械 学習モデル構築し、商品販促のためレコメンド機能を提供 1人頭の収益250$>275$」 ▪
共有ステージ: 複数システムから1つのシステムにデータ集約(データサイエンティストは 好む形式) ▪ 処理ステージ: できるだけ短時間で RAWデータを分析に適した形に変換 ▪ 保管ステージ: タイムスタンプ、イベント名、イベントタイプなどのイベント形式データ ▪ 取得ステージ:追加データの取得や生成(地理データ、外部データ取得) • データ戦略の目標を定める : 上記の各ステージごとに実施 (図2.3)
17 2.5 データ戦略の実現 • データ戦略のイニシアチブを設定 ◦ 例) 小売企業の例 ▪ 保管ステージ:
「変換まえの生データを集約してストレージに入れる」 ▪ 処理ステージ: 「品質向上させ、データリネージや出所を追跡」 • CDC(変更データキャプチャ )を導入する ▪ 共有ステージ:メタデータ管理ソリューション導入、 MDMソリューション導入う、データカタ ログの構、DWHの構築.. ▪ 人材、戦略、テクノロジーを一致 • 人材: データスチュワードとデータオーナーが必要 • テクノロジー: クラウド知識習得 • 戦略: 最高データ責任者(CDO)の配下に置く
18 2.5 データ戦略の実現 • 実行と測定計画 図2.4データ戦略のイニシアチブと、その実行、 測定のステップ (著作権の都合上図を省略 )c 図2.5データ戦略の策定ステップと組織目標との
整合性 (著作権の都合上図を省略 )
19 Chapter3 リーンシンキング
20 3.3 本章のまとめ • リーンシンキングはデータアナリティクスにも適応できる ◦ ですが、ほとんどの企業はアナリティクス =生産システムや製品開発と認識してない • これらを有効に活用するには、顧客が何を重視しているかを理解し、顧客が望まないものを
作る時間と労力の無駄を避ける ◦ MVPを作って、検証による学びと FBによってプロダクトを反復的に改善 ◦ バリューストリームマップは、本番環境におけるデータフローやデータプロダクト開発プロセスに 内在する無駄を特定するのに最適 ◦ 待ち行列理論では、作業を小さな均一バッチに分割し、目指すべきは作業開始からデータプロ ダクトの提供までをできる限り早く行う • フロー改善できれば、プル型スケジュールに移行できる ◦ ワークフローが平準化され、オーバーコミットが抑制され、次に取り組むタスクを選んで実施でき る
21 3.1 リーンシンキングの紹介 • トヨタ生産方式が起源 • リーンソフトウェア開発 ◦ 無駄をなくす ◦
品質を作り込む ◦ 知識を作り出す ◦ 決定を遅らせる ◦ 早く提供する ◦ 人を尊重する ◦ 全体を最適化する • リーン製品開発() ◦ 検証による学び、構築〜計測〜学習サイクル、 MVP(実用最小限の製品)、スプリットテスト、計 測に基づくアクション
22 3.2 リーンシンキングとデータアナリティクス 図3.1データアナリティクスにおける生産システム と製品開発システム (著作権の都合上図を省略 )
23 3.2 リーンシンキングとデータアナリティクス • Poppendieck夫妻が指摘した7つの無駄 ◦ 未完成の無駄 : 本番環境に繋がらない作業・ 余分な機能
: データ利用者の意思決定に繋がらな いもの・余分なプロセス : 構成管理の不足による再現性のないプロセス・ マルチタスク :アナリ ティクスやデータエンジニアリングは、問題解決のために深い集中が必要とする高度な学問・ 待 ち時間や頻繁なタスク移管 ・欠陥・(8つめの無駄として才能の活用不足 ) • バリューストリームマップ: 次頁図解 • 迅速に提供する ◦ 統計的工程管理(問題発見に役立つ)、リリースとイテレーションの導入 • プル型システム ◦ Apache Kafkaの例:Kafkaトピックスにレコードのストリームを送信 • 全体をみる • 現状問題ツリーを用いた根本原因分析 : 次頁図解
24 バリューストリームマップと現状問題構造の図 図3.2解約予測モデルのバリューストリームマッ プ (著作権の都合上図を省略 ) 図3.3簡略した現状問題構造ツリー (著作権の都合上図を省略 )
25 Chapter4 アジャイルなコラボレーショ ン
26 4.6 本章のまとめ • データサイエンスでは、多くのデータソース、特徴量、モデルのアルゴリズム、アーキテクチ が存在するため、受け入れられる解決策を見つけるまでに反復的に予測困難になる可能性 ◦ 場当たり的な開発は言い訳に過ぎない ◦ データサイエンスの非公式なプロジェクト管理のアプローチは組織のステークホルダーや他
チームとの連携をかく • アジャイルプラクティスはDataopsの価値基準と原則の支えとなり、規律をもたらす ◦ 正しいプラクティスは、現場のコンテキストや組織特有のものとして、データ分析チームがより適 応性と協調性を高め、フィードバックループを強化して、いち早く結果を出す ◦ データサイエンスに適したアジャイルプラクティスの組み合わせは1つもない
27 4.1 なぜアジャイルか? • ウォーターフォール型プロジェクト管理の欠点 ◦ 納品遅れのバグ多発、顧客ニーズの読み違い • アジャイル価値基準 ◦
プロセスツールよりも個人と対話 ◦ ドキュメントよりも動くもの ◦ 顧客との協調 ◦ 計画に従うよりも変化への対応
28 4.2 アジャイルフレームワーク • スクラム、XP、カンバン方式、スクラムバン 図4.1スクラムのライフサイクル (著作権の都合上図を省略 ) 図4.2XPのアジャイルライフサイクル (著作権の都合上図を省略
)
29 4.3 アジャイルのスケーリング 図4.4エッセンシャルSAFeのライフサイクル(簡易 版) (著作権の都合上図を省略 ) 図4.3プロダクトのライフサイクルにおけるスクラ ム・オブ・スクラム、DAD、SAFeの適用範囲 (著作権の都合上図を省略
)
30 4.4 DataOpsにおけるアジャイル手法 • 18の原則 ◦ 継続的にお客様を満足、実用的な分析に重きをおく、変化を受け入れる、チームスポーツ、 日々の関わり、自己組織化、ヒーロイズムを減らす、自己反映、分析はコード、オーケストレー ション、再現可能にする、自由に使用できる環境、単純さ、分析は製造、品質が最も重要、品質 とパフォーマンスを監視、再利用、サイクル時間を短縮
• データサイエンスのライフサイクル(図 4.5)
31 4.5 アジャイルなDataOpsプラクティス(図3つ) • アイデア化、方向づけ、研究開発、移行 /本番化 図4.6エピデミックカンバンボード (著作権の都合上図を省略 ) 図4.7エピックの仮説ステートメントの例
(著作権の都合上図を省略 ) 図4.8エピック優先順位付マトリックスの例 (著作権の都合上図を省略 )
32 Chapter5 効果測定とフィードバックの 仕組みづくり
33 5.6 本章のまとめ • 既存の枠組みから抜け出すのはできるが、やるべきことは2つある • 日常の仕事を遂行すると同時に、常に自分の仕事を改善し続けること ◦ Dataopリーダーは、生産性と顧客価値を継続的に改善する文化を醸成するために、常に新し い方法を探し続けましょう
◦ システム思考を身につけ、チーム利用者からフィードバックを収集し、科学的アプローチを取り 入れる必要がある ◦ 労力がいるが、より速く、質の高い成果がでる • もう一つは、測定に基づいて改善を行うために、信頼性のあるデータを用意する
34 5.1 システム思考(図5.1,5.2) • 世界はシステムの一例 • 継続的な改善とフィードバックループ
35 5.2 チームの健康状態 • レトロスペクティブ • ヘルスチェック(5.3) • プレモーテム: プロジェクト開始時に実施し、問題の原因特定する
36 5.3 サービスデリバリー/5.4 プロダクトの健全性 • サービスデリバリーレビュー、デリバリーの改善 • データプロダクトをモニタリングするための KPI ◦
データ取り込みとデータパイプラインの正確性 ◦ データの適時性、エンドツーエンドのレイテンシー ◦ レイテンシーや可用性 • コンセプトドリブン ◦ 顧客の購買行動、スパムメールの検出で予測精度が落ちる現象 ◦ データの再トレーニングを行うことで解決する ◦ 負のフィードバックループに陥る場合も ▪ 解決方法として、「バイアスのないデータセット生成」「モデル更新のタイミング設定」「予測 を一時的に停止し、バイアスのないデータを再トレーニング」 • 「モデル更新のタイミング設定」のアルゴリズム : ドリフト検出法、早期ドリフト検出 法、指数移動平均チャート法、幾何移動平均検出法
37 5.5 プロダクトがもたらす効果 • コスト削減、収益増加、顧客体験の改善などの KPIのモニタリングの実施(図5.6) • A/Bテストを実施し、プロダクトのFBを行う ◦ ABテストを行う際はバイアスが入るため、完全なランダム性は難しい
◦ DID(差分の差分法)などで代替 • 効果測定のKPIを自動化するために、ユーザーインターフェースを備えたダッシュボードの 活用 ◦ KPIに加えて、p値、信頼区間、有意性などの統計手法の活用
38 Chapter6 信頼の構築
39 6.3 本章のまとめ • データガバナンスは新しい概念ではないが、組織が取り込む膨大な量と多様なデータ、高速 な処理に加え、GDPRなどの新たな規制から、従来と異なるアプローチが求められる ◦ 昔ながらのやり方: リスクを軽減するために、データマートやウェアハウスを慎重に管理し、手作 業でアクセスコントロール
▪ しかしこういった従来のやり方は、新しいデータプロダクトの妨げ ◦ データの識別・分類・セキュリティ・提供・品質評価の自動化、データ利用者とそのものの信頼性 担保 ◦ 利用者データやシステムに安全にアクセスできるように信頼関係を築くことが、データサイエン スのプロセスにおける無駄を最大限省ける
40 6.1 データ利用者に対する信頼 • データアクセスとプロビジョニング ◦ 全ての人にアクセス権付与 VS IAMを使用してロールベースアクセス制御すること •
データセキュリティとプライバシー ◦ EU一般データ保護規制( GDPR)、欧州経済領域(EAA)などのデータ保護、セキュリティに関す る規制 ◦ 規制で目指すべき: センシティブ、コンフィデンシャル、パブリック ▪ マスキング、セキュアハッシュ化、バケット化、フォーマット保持暗号化 • インフラはマルチテナントであり、ユーザー間で公平に分け合う必要あり (図6.1)
41 6.2 データ自体に対する信頼(図) • データ自体を説明するメタデータ ◦ 記述メタデータ、構造メタデータ、管理用メタデータ(米国の NISO定義) • データの一貫性をタグ付け
◦ ビジネス用語、タクソノミー、オントロジーとの整合 • データ取得における信頼性 ◦ 整合性、重複、ファイルサイズ、ファイル周期性チェック • データ品質の評価 ◦ 統計情報を用いたプロファイリング、品質を高めるための完全性、有効性、一貫性の徹底 • データのクレンジング • データリネージ ◦ ETLツールで自動でデータの出所や移動経路がわかる • データディスカバリ
42 6.2 データ自体に対する信頼 ※ 上記図の流れはデータガバナンスの一環に過ぎない 図6.2データへの信頼性を確保するための ワークフロー (著作権の都合上図を省略 )
43 Chapter7 DataOpsへのDevOpsの 適用
44 7.6 本章のまとめ • DevOpsの実践がなければ、リソース作業の山が際限なく積み上がる ◦ DevOpsを実践することで、1日に何度も改修ができる • データプロダクトやデータパイプラインの高速な開発ができない組織は、意思決定が遅れ、 競合他社に負ける
◦ DevOpsのマインドセットはとプラクティスはデータアナリティクスにイノベーションを起こす • CALMS(Culture, Automation, Lean,Measurement and sharing)モデルはDevOpsの準備 導入を多角的な視点で評価 ◦ 組織のコラボレーション文化、自動化レベル、ワークフローの継続的な改善と高速化、パフォー マンス計測、責任コミュニケーションの共有などで成熟度を評価
45 7.1 開発と運用 • 開発チームと運用チームの確執 ◦ 負のスパイラルを3つに分けて解説 ▪ 第一段階では、ドキュメントが不十分で技術負債を抱えた複雑なアプリケーションやインフ ラを運用チームが運用する
▪ 第二段階では、以前の失敗の問題を補うために開発チームが別の緊急プロジェクトを担 当 ▪ 最終段階では、PJが複雑化し、タスク間の依存関係が増える ◦ 負のスパイラルに陥ると、本番コードのデプロイに時間がかかる • 負のスパイラル解消に向けて ◦ バージョン管理ツール、アーティファクトリポジトリ、構成データベース( CMDB)
46 7.2 継続的なデリバリーによる高速なフロー • 再現性ある環境 ◦ 構成オーケストレーション : Terraform AWS
Cloud Formation ◦ オペレーションシステムの設定 : Debian pressedやRedHat Kickstater ◦ 仮想マシン(VM) ◦ コンテナプラットフォーム : DockerやCoreOS, rkt ◦ 構成管理: Puppet,Chef,Ansible ◦ バージョン管理: Anaconda Distribution • デプロイパイプライン(図 7.1) • 継続的インテグレーション ◦ 開発ブランチを作成し、各システムの構成要素を並行で開発 • 自動化テスト ◦ テスト駆動型開発、機能テストと非機能テスト
47 7.3 デプロイとリリースのプロセス • セルフサービスによるデプロイ ◦ スクリプトはコードやファイルを再利用可能なアーティファクトとしてパッケージ化し、テスト実行し て、仮想マシンやコンテナを更新 • リリース方式:
ブルーグリーンデプロインメント ◦ 一方は開発環境で、もう一方は本番環境で顧客に提供 • DevOpsにおける効果測定 ◦ デプロイの頻度、変更のリードタイム、本番デプロイの失敗率、平均復旧タイム (MTTR) • レビュープロセス ◦ GitHubを使う
48 7.4 データアナリティクスのためのDevOps • マイクロサービスアーキテクチャで、協働しながら動作(図 7.2) • データパイプライン環境 ◦ 分散システムにはペタバイト級のデータが入っている
◦ pythonスクリプトやシェルスクリプト、 Yamlを使って管理 • オーケストレーション ◦ Airflowのワークフロー図:DAG,オペレーター,センサー • データパイプラインの継続的インテグレーション ◦ 入力に対して出力結果のみを検証するブラックボックステストから始めるのが理想的 • シンプルな構造と再利用(図7.4)
49 7.5 MLOpsとAIOps • MLOpsとAIOpsはDataOpsと密接に関係し、補完 ◦ ログ、アラート、ネットワークの監視などが両者に関係性ある • 機械学習モデルの開発 ◦
学習と推論の2つの要素で構成 • 機械学習モデルの構築 ◦ パラメータやハイパーパラメータの調整
50 Chapter8 DataOps実現のための組 織作り
51 8.5 本章のまとめ • DataOpsでは、新しいデータプロダクトの開発スピードを最適化すること、リスクを抑えること を優先する • DataOpsでは、スキル、ツール、垂直方向の報告ラインに基づく組織化ではなく、データ中 心の目標に基づいて組織化 •
DataOpsでは、ドメイン別、自己組織化、マルティスキル、小規模、機能横断といった特性を 持つチームづくり、そうしたチームが同じロケーションで長期的に活動する
52 8.1 チーム構造 1. 機能指向のチーム a. 従来型の分業方法で、高度な技術を必要とする職種(データサイエンティスト、 BIアナリスト、 データエンジニアなど)を専門性によって分ける b.
機能別チームや外部の専門家を雇用するコンタルタントモデルは、データ分析チームが小規模 であれば機能する c. 責任が分散されているため、最終的に生み出される価値はごくわずか 2. ドメイン指向のチーム a. 異なる専門性をもったメンバーで、構成された機能横断的チーム b. 常に全てのスキルをフル活用できるとは限らないが、アイデアを練る時間が生み出され、優先 事項を迅速につけられる c. ドメイン別チームでは、キャリア開発、ナレッジ共有、一貫した採用といった点で課題
53 8.1 チーム指向とドメイン指向の図解 図8.1機能別チームを通じた業務の流れと複雑 な連携 (著作権の都合上図を省略 ) 図8.2ドメイン別チームのためのハブ・アンド・ス ポークモデル (著作権の都合上図を省略
)
54 8.2 新しいスキルマトリックス • ペルソナ:職務の役割やスキルを表現する最も簡単な方法 ◦ コアペルソナ: データプラットフォーム管理者、データアナリスト、データサイエンティスト、データ エンジニア、DataOpsエンジニア、チームリーダー、ソリューションエキスパート、組織のステーク ホルダー
◦ 補助ペルソナ: データプロダクトオーナー、ドメインエキスパート、アナリティクススペシャリスト、 テクニカルスペシャリスト( MLエンジニアやセキュリティエキスパートも含む)など • T型人材の重要性
55 8.3 最適化されたチーム • コミュニケーションラインとチームサイズ (コミュニケーションリスク) • プロジェクトではなくプロダクト ◦ プロジェクト型チームに特有の、形成期、混乱期、統一期といった苦痛と時間を要する段階がな
い ◦ チームメンバーをお互いに信頼するようになる、仕事のやり方やプロセスの改善に注力 • 作業場所 ◦ Google:チームメンバーを数メートル以内に配置する
56 8.4 報告ライン • データプラットフォームの管理 ◦ データ最高責任者(CDO)やデータ分析責任者( CAO)の配下におき、CEOに報告が上がるよう にする •
機能横断的な役割は集約型、分散型、ハイブリット型のいずれか ◦ 集約型:CEOやCDO等に直接報告ができる、小規模チームに役立つ ▪ 組織ドメイン知識を獲得して、機能別チームと関係性構築が難しい ◦ 分散型:マーケティング部門や機能別チームなど、機能の方向性に合わられる ▪ メンバー同士が孤立すること /データプラットフォームの管理業務が機能別チームとは別 で報告される ◦ ハイブリット型:
57 Chapter9 DataOps実現のための組 織作り
58 9.5 本章のまとめ • データプロダクトやデータパイプラインのアジャイルな開発はアプリ開発と違う ◦ アプリケーション用のプロセスやテクノロジーはデータに適応すると阻害 • DataOpsエコシステムのテクノロジーは、データやツールへのセルフ型サービスのアクセス を可能にし、摩擦を最小限
◦ 需要に応じて、複雑なプロセスのオーケストレーションを拡充 ◦ 再現性、再利用性、テスト、監視性、自動化を通じて、開発スピードを上げる
59 9.1 DataOpsの価値基準と原則に基づいてツールを選択 • 背骨を整合させる(図9.1) ◦ DataOpsの20の基本原則に合わせる • プラクティスとツールへの影響 ◦
それぞれの基本原則に影響がある
60 9.2 DataOpsテクノロジーのエコシステム ① • 組み立てライン(図9.2): 有名だからではなく、組織にあったアーキテクチャが重要 • データ統合: アクセス解析やCRMプラットフォームなど様々な場所から
◦ 最近ではSaaSのETLツールも登場し、容易に : オンライントランザクション処理 (OLTP) • データプレパレーション: 収集、クレンジング、結合、変換 • ストリーム処理: イベントソーシング(Apache kafka) • データマネジメント: データカタログの利用 ...
61 9.2 DataOpsテクノロジーのエコシステム ② • 再現性、デブロイ、オーケストレーション、監視 • コンピューターインフラストラクチャとクエリ実行エンジン ◦ Hadoop
Distributed File System(HDFS)やGoogle Kurbenates Engine(GKE)など • データストレージ ◦ RAWデータ処理済データ永続化、データパイプライン処理の中間結果、ログ保管。データパイ プラインやアナリティクスの開発と運用時に必要 ▪ かつては、HDFSが主流だった ◦ データウェアハウス(スキーマオンライド) ↔ データレイク(スキーマオンリード) • DataOpsツール: Apache kafka.. • データ分析ツール: BI製品、Amazon Sagemaker.. • 課題 ◦ モノリシスなアーキテクチャに比べ、複雑で労力がかかる
62 9.3 構築するか、購入するか • 拡張する:メリットが少ない • 自社構築する: 複雑な作業を完了までに要する正確な時間を見積もるのが難しい(ホフス タッターの法則) •
製品やサービスを購入する()内は製品例 ◦ IaaS(EC2) 基盤インフラにアクセスできるが、プロビジョニングやアクセスはユーザー ◦ PaaS(Google App Engine)OSや開発ツール、データベースを意識せずに開発可能 ◦ FaaS(AWS Lambda)マイクロサービスの構築やイベント駆動型のコード ◦ SaaS (slack) WEB上で利用できるもの ◦ サーバレスプラットフォーム( Databricks, BQ)インフラ管理やソフトウェア設定不要 • オープンソース利用: Hadoopエコシステム、Cloudera • クラウドネイティブアーキテクチャー : ◦ 統合と効率性からマネージドサービスを利用するが、ベンダーロックインの可能性も
63 9.4 テクノロジースタックを進化させる • ウォドリーマップ • テクノロジーリーダー
64 Chapter10 DataOpsの導入手順
65 10.5 本章のまとめ • データ中心の考え方が定着しておらず、時代遅れで目的にあっていない組織はデータサイエンスやア ナリティクス完全に要件を満たすのは難しい ◦ DWHや従来のBIのために設計された従来の仕事の進め方は、むしろ負債となる ◦ 前進する際の制約となるだけでなく、ガバナンスが聞かないシャドー
ITになる • DataOpsは障壁を取り除き導入は、コラボレーションを促進し、成功率を上げる
66 10.1 最初のステップ • データ戦略から始める ◦ 2017年の調査では、明確にあると答えた企業はない企業よりも 2.5倍成功率が上がる ◦ データ戦略とは、組織の内部・外部を分析し、データアナリティクスの現状と目指す将
来像とを埋めるロードマップを策定する • リーダーシップ ◦ データアナリティクスのリーダーや、複数のリーダーからなるグループ ◦ 最高データ責任者(CDO)かDS,DA,DEを担当する最上位の人物がリーダーシップを 発揮する
67 10.2 実用最小限のDataOps • 最初のイニシアティブ • 測定 • 最初のDataOps(図10.1) ◦
専任のドメインチームを作成 ◦ 最初のゴールは、テスト、拡張性、再現性、再利用性、デプロイ、監視 ◦ 信頼を高めるところから始める ◦ ウォーターマークを入れて、品質、完全性、正確性、整合性、精度、均一性
68 10.3 複数チームへの展開 • クリティカルマスを達成する • チーム間の調整 • データガバナンス
69 10.4 拡張 • 成功のための組織化 • プラットフォームの集約化 • あらゆることの自動化 •
セルフサービスの実現
書籍を紹介した人 • 1994年6月生まれ 北海道出身 • 職種: データアナリスト • 主な保有資格:Kaggle Competitions
Expert | GoogleCloud Professinal DataEngineer Takumu Wakamatsu 若松 拓夢
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}