Answering Systems A Quantitative Evaluation of Natural Language Question Interpretation for Questions Answering Systems Takuto Asakura, Jin-Dong Kim, Yasunori Yamamoto, Yuka Tateisi and Toshihisa Takagi JIST2018 2018-11-27 1 / 16
Answering Systems The World of LD In Linked Data (LD), all relations are expressed as RDF graphs Recently, the number of RDF Knowledge Bases (RKBs) is rapidly increasing Example res:Japan res:Tokyo onto:capital Linking Open Data cloud diagram 2017, by Andrejs Abele, John P. McCrae, Paul Buitelaar, Anja Jentzsch and Richard Cyganiak. http://lod-cloud.net/ 2 / 16
Answering Systems SPARQL and QA Systems SPARQL The most standard way to treat RKBs However, authoring SPARQL is not so easy QA systems General Question Answering (QA) systems Inputs: Natural Language Questions (NLQs) Outputs: The answers to the NLQs Converting NLQs to SPARQL queries → Allowing non-experts of SPARQL to use LD! Example What is the capital of Japan? SELECT ?v1 WHERE { res:Japan onto:capital ?v1 . } 3 / 16
Answering Systems Why New Evaluation Method Is Needed? Existing methods Current evaluation methods are not enough: They evaluate only on the final answers They treat a QA system like a blackbox They are only suitable for end-to-end systems → but, many QA systems are pipeline systems We wanted to provide Component-wise evaluation would be much helpful: To find the reason of failure To get KB-independent evaluation 4 / 16
Answering Systems Test Bet: OKBQA Framework We applied our method to OKBQA framework [Kim+, 2016] A pipeline framework for QA A community-driven open source project OKBQA Framework TGM Generating templates DM Identify resources QGM Generating queries AGM Querying KBs 5 / 16
Answering Systems Our Goal: Proposing a New Evaluation Method OKBQA Framework TGM Generating templates DM Identify resources QGM Generating queries AGM Querying KBs The sQA Evaluator Library Subdivided: modularized & detailed criteria Semantic: based on the meanings of questions and SPARQL queries Systematic: evaluating automatically 6 / 16
Answering Systems The Target: Template Generation Module TGM Input: an NLQ q q What is the capital of Japan? Output: SPARQL templates T (q) = {(τ, S )} τ 0 SELECT ?v1 WHERE { ?v6 ?v8 ?v1 . } S0 [ v8 verbalization −−−−−−−−−→ capital, v6 verbalization −−−−−−−−−→ Japan, ... ] Example Rocknrole: a rule-based TGM implementation [Unger+, 2012] LODQA: based on a syntactic parser [Kim+, 2013] 7 / 16
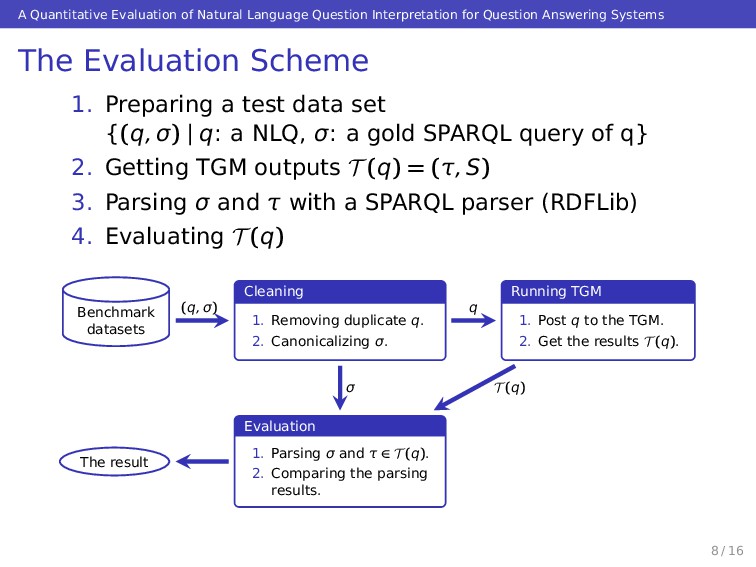
Answering Systems The Evaluation Scheme 1. Preparing a test data set {(q, σ) | q: a NLQ, σ: a gold SPARQL query of q} 2. Getting TGM outputs T (q) = (τ, S) 3. Parsing σ and τ with a SPARQL parser (RDFLib) 4. Evaluating T (q) Cleaning 1. Removing duplicate q. 2. Canonicalizing σ. Running TGM 1. Post q to the TGM. 2. Get the results T (q). Evaluation 1. Parsing σ and τ ∈ T (q). 2. Comparing the parsing results. Benchmark datasets The result (q, σ) q T (q) σ 8 / 16
Answering Systems Overview of The Evaluation Criteria Categories of the evaluation criteria Three aspects; each has two criteria. Robustness Query types and ranges Graph patterns Severeity levels The criteria are categorized into two severity levels. Lv. critical make the chance to find an anwer zero Lv. notice lower chance to find an anwer 9 / 16
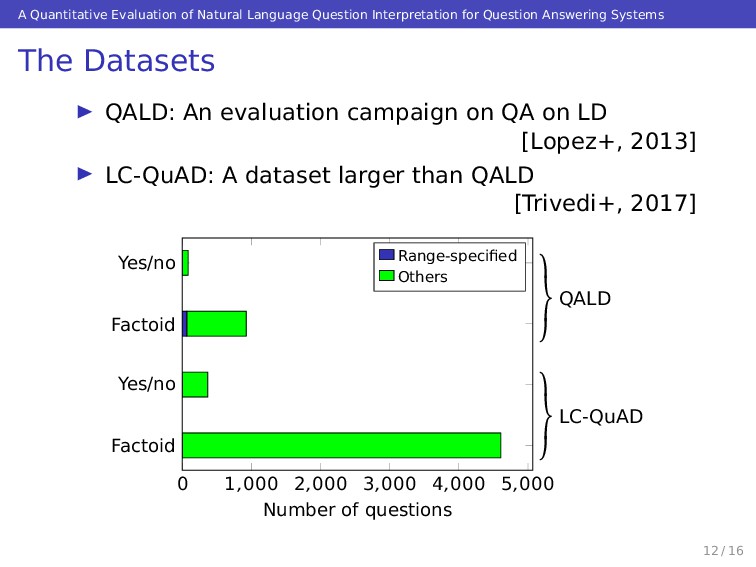
Answering Systems Robustness, Query Types and Ranges Evaluation on robustness TGM failure Did it work without errors? Lv. critical Syntax Did it return valid SPARQL templates? Lv. critical Evaluation on query types and ranges Question type Did it detect the question type correctly? Lv. critical Wrong range Did it recognize the right range? Lv. notice Question types Yes/no questions can be answered as “yes” or “no” Factoid questions require entities as their answers some of them are range-specified factoid questions Eg. What is the second highest mountain on Earth? 10 / 16
Answering Systems Tendencies of the TGMs Rocknrole Covering both of the question types Able to add range specification However, often failing to generate good SPARQL templates misjudging 4.7% of factoid (as yes/no) adding wrong range specifications (45.2%) Too many DC triples LODQA Problems on robustness cf. TGM failure: 1, Syntax: 18 Not able to distinguish factoid and yes/no Not able to produce range specifications 14 / 16
Answering Systems Future Work Applying our evaluation to other: datasets which have question–SPARQL pairs larger datasets are desirable languages other than English QA systems which produce SPARQL queries it can easily be applied to other TGMs possibly be applied to other QA systems Proposing evaluation methods for other modules URI annotations types and classes of targets more evaluation on S ∈ T (q) with URIs Improving the QA systems by using the evaluation results 15 / 16
Answering Systems Conclusions Improving QA systems is important for expanding the use of LD Existing evaluation methods are not enough Our method is subdivided, semantic, and systematic We successfully applied the method to OKBQA framework The method can be applied to other datasets & QA systems large-scale and multi-language datasets any QA systems which produce SPARQL queries Future work evaluation methods for other modules improving QA systems 16 / 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}