それより次元の低い密な行列を用いて Z = UV⊤ ≈ Y と分解する. 記号の定義 • U : ユーザに関する行列で, サイズは M × K. • V : item に関する行列で, サイズは N × K. • M, N, K : それぞれユーザ数, item 数, 潜在空間の次元を表す. Z の各要素 ˆ yui について考えると, 以下と同様である. ˆ yui = u⊤ u vi (22.3) 11
• ある item は全体的に低い評価値を付けられる傾向にある, など... 行列補完では, これらのバイアスの影響もパラメータとして考慮する. ˆ yui = µ + bu + ci + u⊤ u vi (22.4) µ は全体で共通のパラメータ, bu はユーザ u 固有の パラメータ, vi は item i 固有のパラメータをそれぞれ表す. 12
ユーザ u と item i のペア x = [one − hot(u), one − hot(i)] が与えられた時, その評価値を予測する. f(x) = µ + D ∑ i=1 wi xi + D ∑ i=1 D ∑ j=i+1 (v⊤ i vj )xi xj (22.17) 記号の定義 • x ∈ RD: 入力データ • D = M + N: 入力データの次元 (ユーザ数 +item 数) • V ∈ RD×K: 潜在変数を要素とする重み行列 • w ∈ RD: 重みベクトル • µ: 共通のバイアス (v⊤ i vj )xi xj の項が入力データ間の相互作用を表す. 24
O(KD) まで下げられる. D ∑ i=1 D ∑ j=i+1 (v⊤ i vj )xi xj = 1 2 D ∑ i=1 D ∑ j=1 (v⊤ i vj )xi xj − 1 2 D ∑ i=1 (v⊤ i vi )xi xi (22.18) = 1 2 D ∑ i=1 D ∑ j=1 K ∑ k=1 vik vjk xi xj − D ∑ i=1 K ∑ k=1 vik vik xi xi (22.19) = 1 2 K ∑ k=1 ( D ∑ i=1 vik xi )2 − D ∑ i=1 v2 ik x2 i (22.20) x は one-hot encoding の形式であるため, 式(22.20)の計算量は実質 O(K) である. このモデルは目的に応じた損失関数で fit させることができる. 例えば Implicit feedback であれば ranking loss, Explicit feedback であれば MSE など. 25
introduction. MIT Press, 2022. [2] Yehuda Koren. The bellkor solution to the netflix grand prize. Netflix prize documentation, Vol. 81, No. 2009, pp. 1–10, 2009. [3] F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context. Acm transactions on interactive intelligent systems (tiis), Vol. 5, No. 4, pp. 1–19, 2015. [4] Ken Goldberg, Theresa Roeder, Dhruv Gupta, and Chris Perkins. Eigentaste: A constant time collaborative filtering algorithm. information retrieval, Vol. 4, No. 2, pp. 133–151, 2001.
Konstan, and Georg Lausen. Improving recommendation lists through topic diversification. In Proceedings of the 14th international conference on World Wide Web, pp. 22–32, 2005. [6] David Goldberg, David Nichols, Brian M Oki, and Douglas Terry. Using collaborative filtering to weave an information tapestry. Communications of the ACM, Vol. 35, No. 12, pp. 61–70, 1992. [7] Yehuda Koren, Robert Bell, and Chris Volinsky. Matrix factorization techniques for recommender systems. Computer, Vol. 42, No. 8, pp. 30–37, 2009. [8] Andriy Mnih and Russ R Salakhutdinov. Probabilistic matrix factorization. Advances in neural information processing systems, Vol. 20, , 2007.
and Lexing Xie. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th international conference on World Wide Web, pp. 111–112, 2015. [10] Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618, 2012. [11] Steffen Rendle. Factorization machines with libfm. ACM Transactions on Intelligent Systems and Technology (TIST), Vol. 3, No. 3, pp. 1–22, 2012.
Li, and Xiuqiang He. Deepfm: a factorization-machine based neural network for ctr prediction. arXiv preprint arXiv:1703.04247, 2017. [13] Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. Neural collaborative filtering. In Proceedings of the 26th international conference on world wide web, pp. 173–182, 2017. [14] Jiaxi Tang and Ke Wang. Personalized top-n sequential recommendation via convolutional sequence embedding. In Proceedings of the eleventh ACM international conference on web search and data mining, pp. 565–573, 2018.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![22.1.1 Datasets モデルの説明に入る前に, この分野の有名なデータセットをいくつか紹介する. • Netflix の映画評価 [2] : 現在は扱うことができない.](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_8.jpg){kind=link}
{kind=link}
![22.1.2 Collaborative filtering 協調フィルタリング (Collaborative filtering) [6] あるユーザの評価値を他のユーザと共有することで, 共同で item](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![22.1.3.1 Probabilistic matrix factorization (PMF) MF を次式のように確率モデルとして扱うこともできる [8]. p(yui =](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_15.jpg){kind=link}
{kind=link}
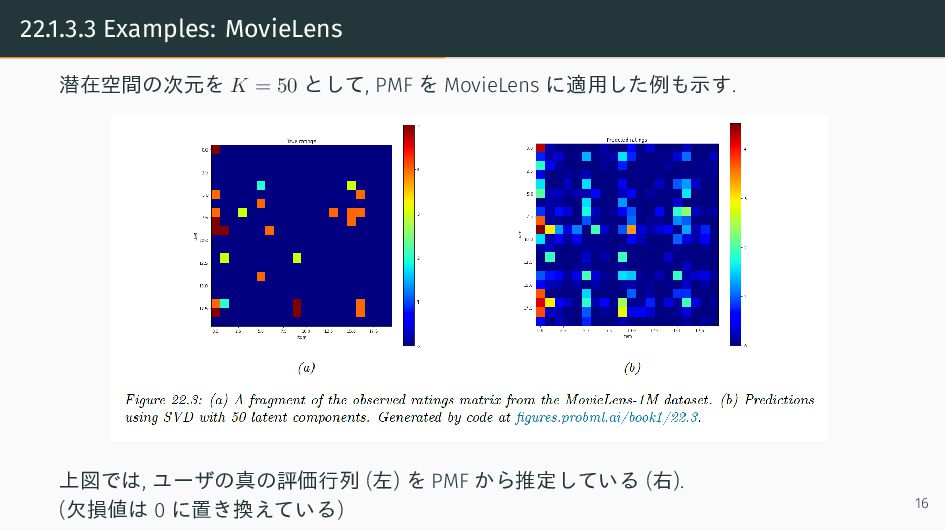{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
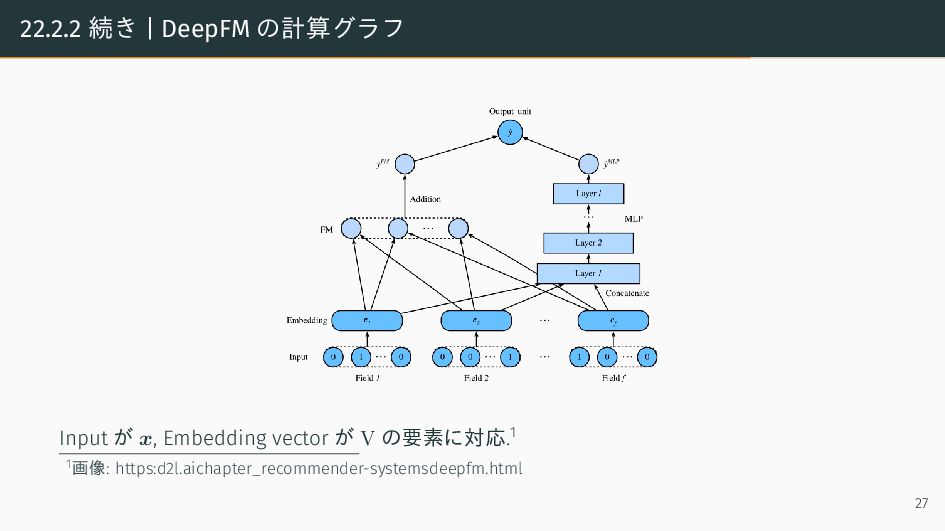
![22.2.2 Factorization machines Factorization machines [11] は, ユーザと item の相互作用を考慮したモデルである.](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![22.2.3 Neural matrix factorization Neural matrix factorization (NeuMF) [13] は](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
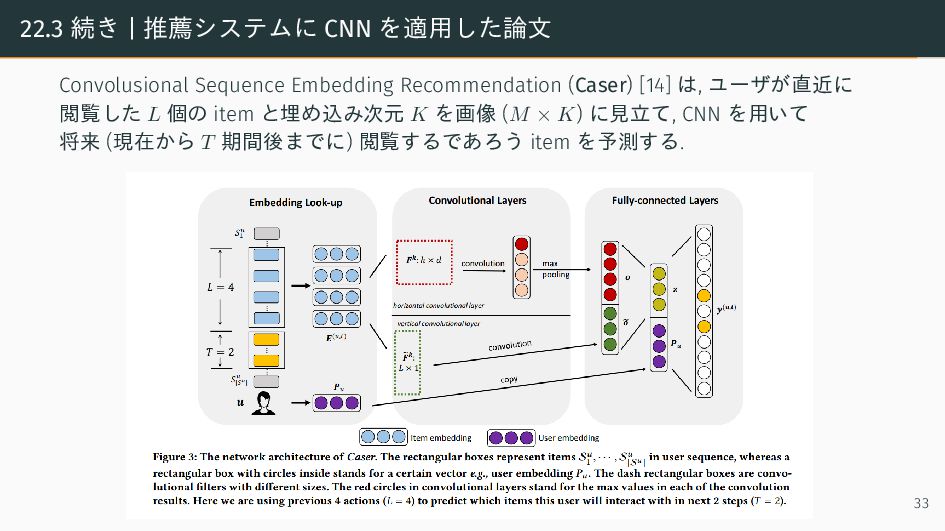{kind=link}
{kind=link}
{kind=link}
![References i [1] Kevin P. Murphy. Probabilistic Machine Learning: An](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_39.jpg){kind=link}
![References ii [5] Cai-Nicolas Ziegler, Sean M McNee, Joseph A](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_40.jpg){kind=link}
![References iii [9] Suvash Sedhain, Aditya Krishna Menon, Scott Sanner,](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_41.jpg){kind=link}
![References iv [12] Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_42.jpg){kind=link}
![References v [15] Paul Covington, Jay Adams, and Emre Sargin.](https://files.speakerdeck.com/presentations/13028c6b9b4d4e37ad81a46aa190753a/slide_43.jpg){kind=link}