Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019. [15] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, P. J. Liu, et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67, 2020. [16] A. Rajkomar, E. Oren, K. Chen, A. Dai, N. Hajaj, P. Liu, X. Liu, M. Sun, P. Sundberg, H. Yee, K. Zhang, G. Duggan, G. Flores, M. Hardt, J. Irvine, Q. Le, K. Litsch, J. Marcus, A. Mossin, and J. Dean. Scalable and accurate deep learning for electronic health records. npj Digital Medicine, 1, 01 2018.
{kind=link}
{kind=link}
{kind=link}
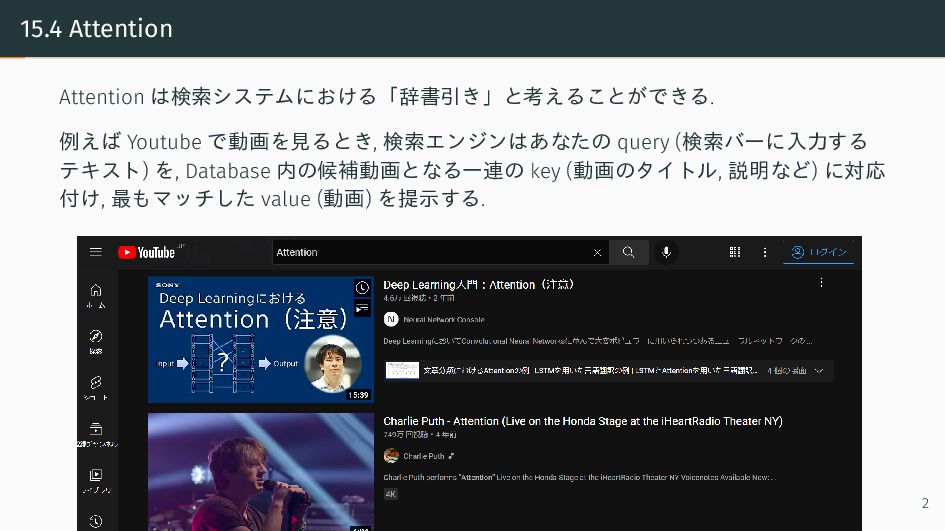{kind=link}
{kind=link}
{kind=link}
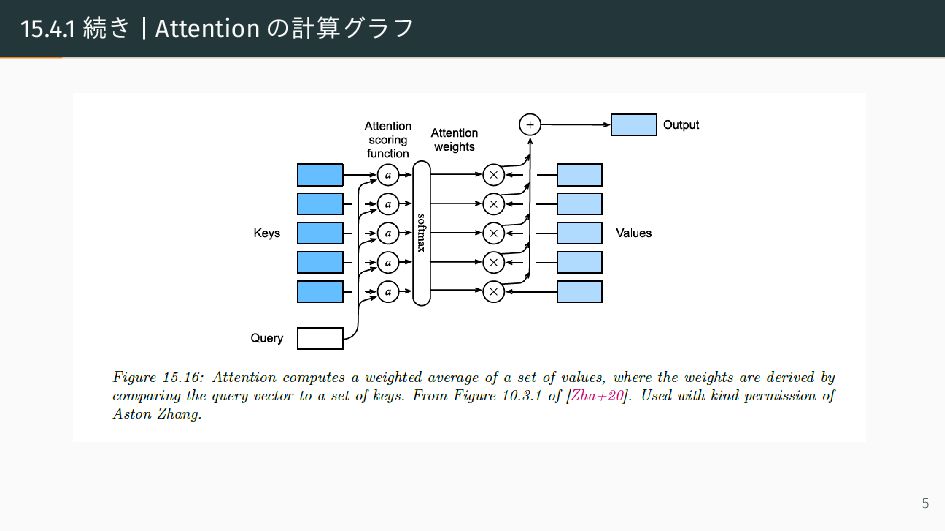{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
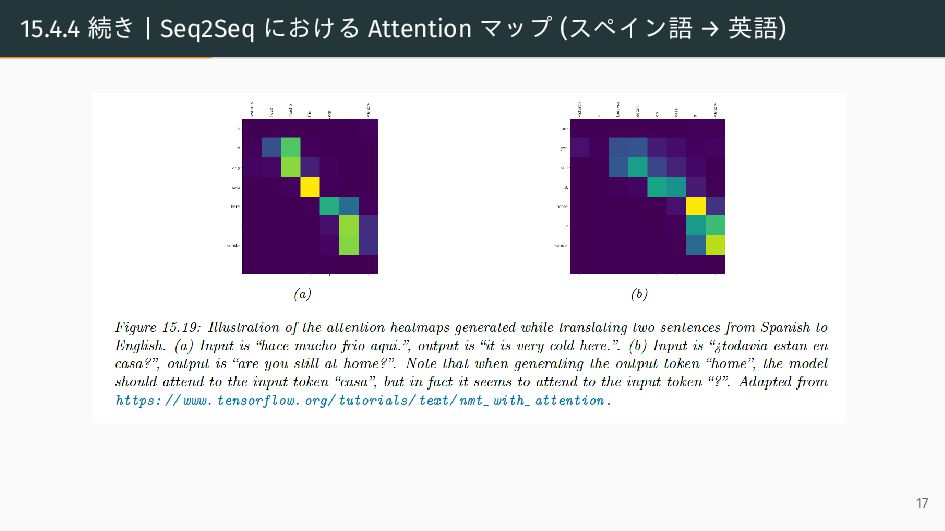{kind=link}
{kind=link}
{kind=link}
{kind=link}
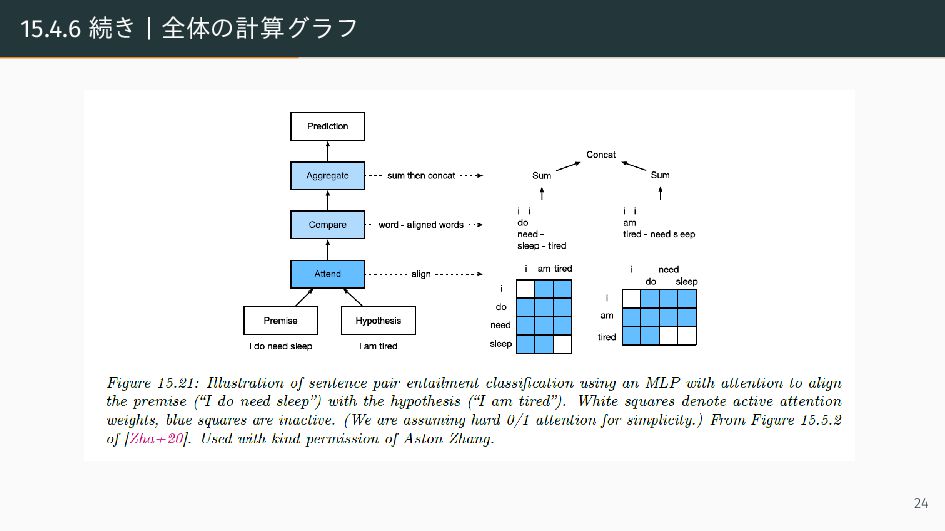
![15.4.6 続き | Attention によるアプローチ この分類問題に対するアプローチとして [12] の手法を紹介する. premise に対応する文章集合を](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
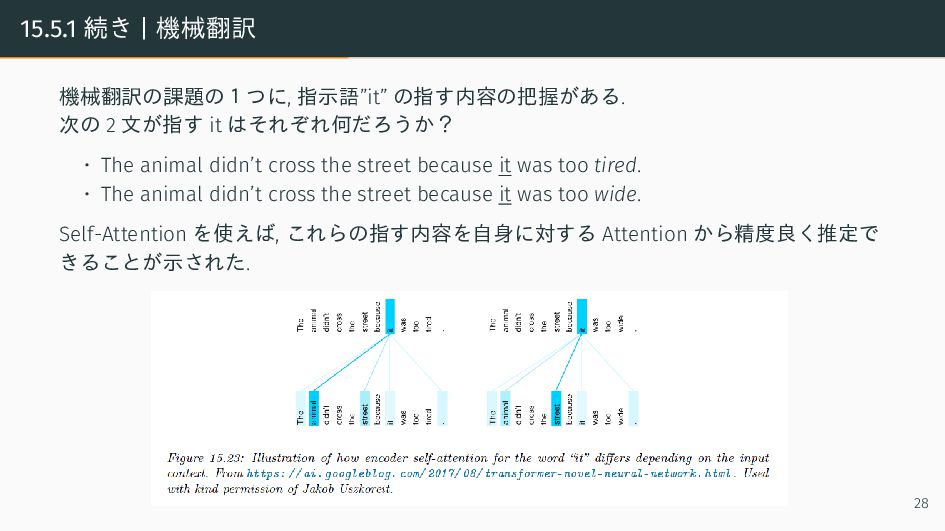
![15.5 Transoformers Transformer[19] は Seq2Seq モデルの 1 種である. しかし今まで議論してきた Seq2Seq](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
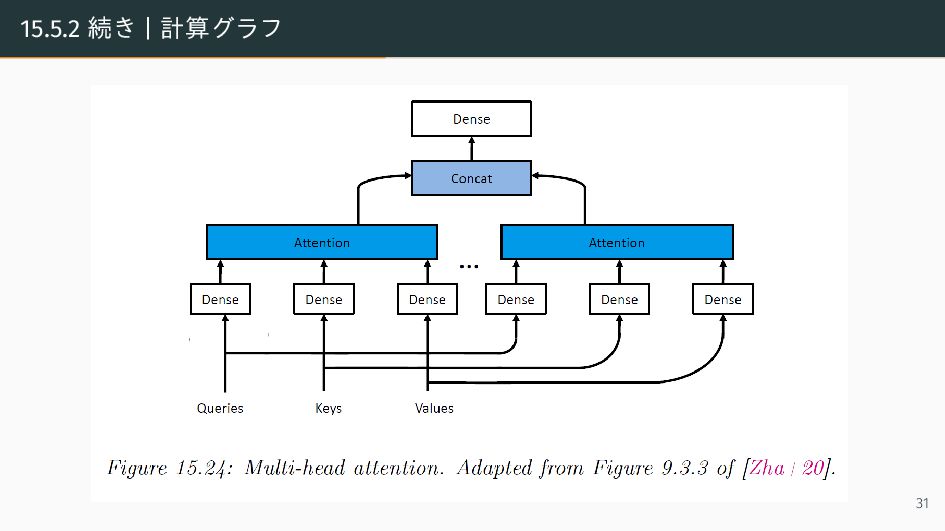
{kind=link}
{kind=link}
{kind=link}
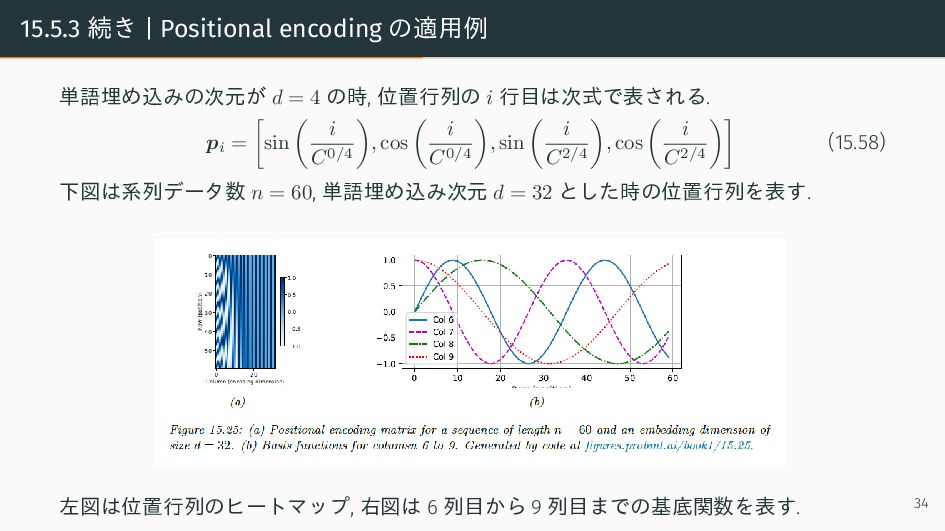
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
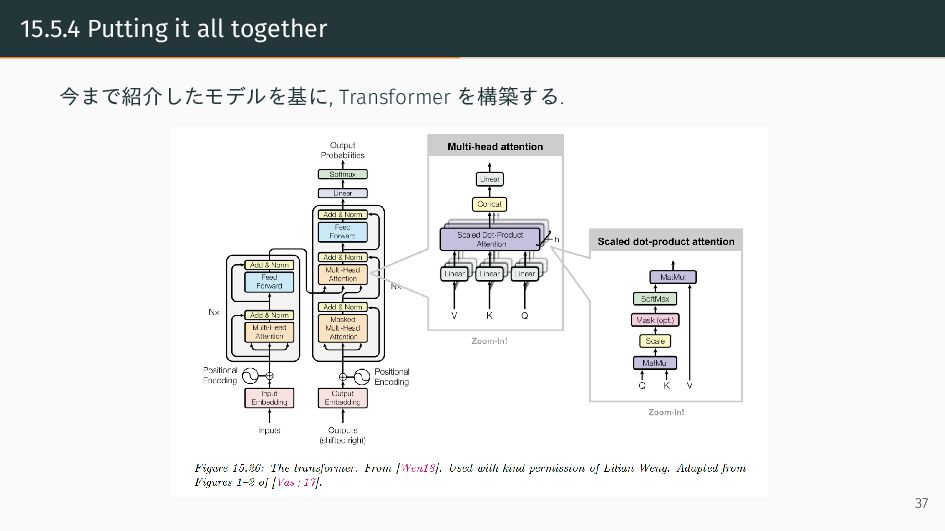{kind=link}
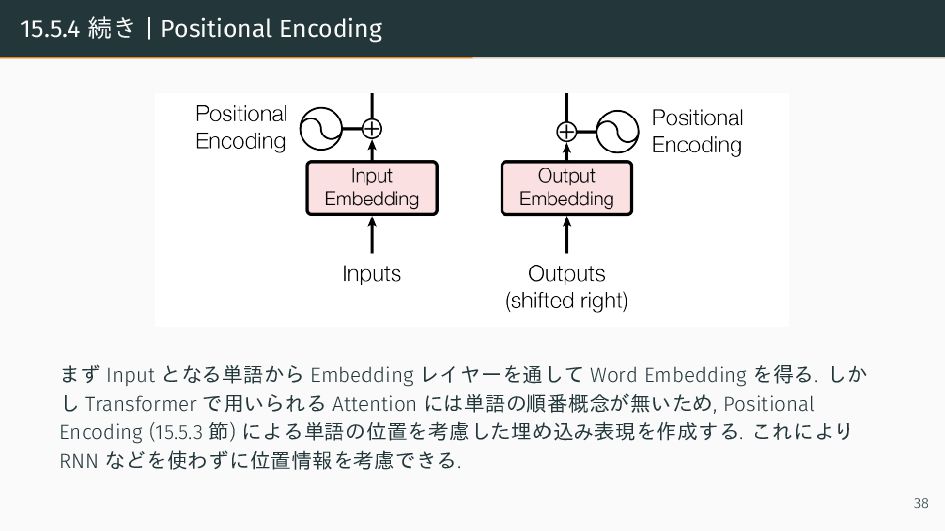{kind=link}
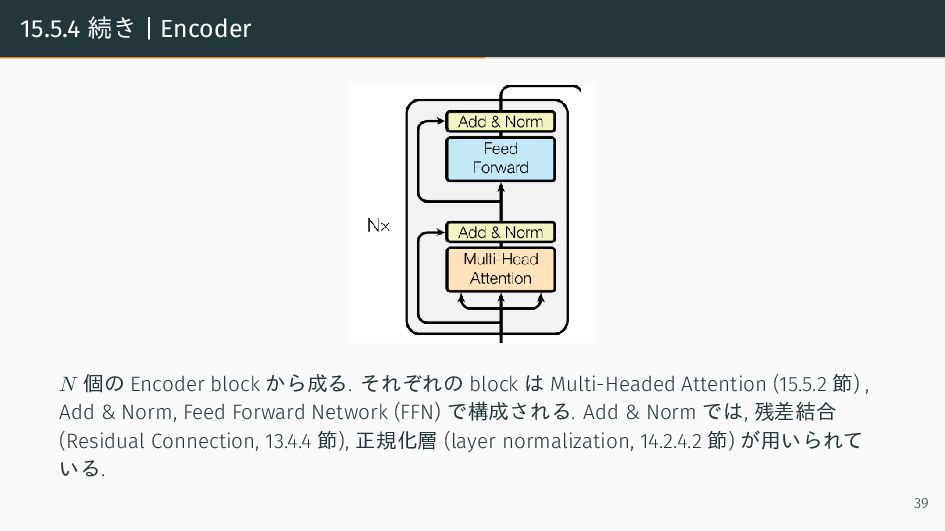{kind=link}
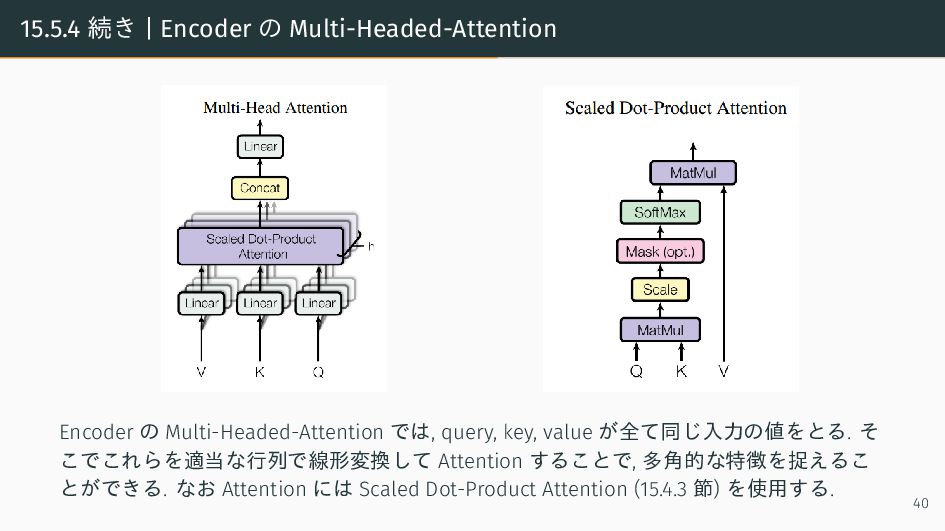{kind=link}
{kind=link}
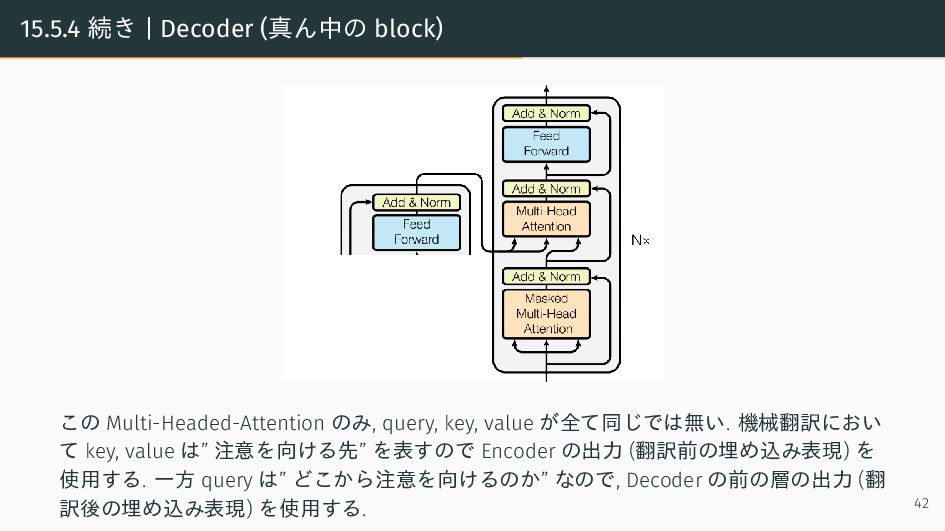{kind=link}
{kind=link}
{kind=link}
{kind=link}
![15.5.5 Transformers for images 十分な学習データ数があれば, Transformer は画像分類でも高い精度を示した [6]. Vision Transformer](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_48.jpg){kind=link}
![15.5.7 Other transformer variants • Gshard[9] は, FFN の一部を Mixture](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_49.jpg){kind=link}
{kind=link}
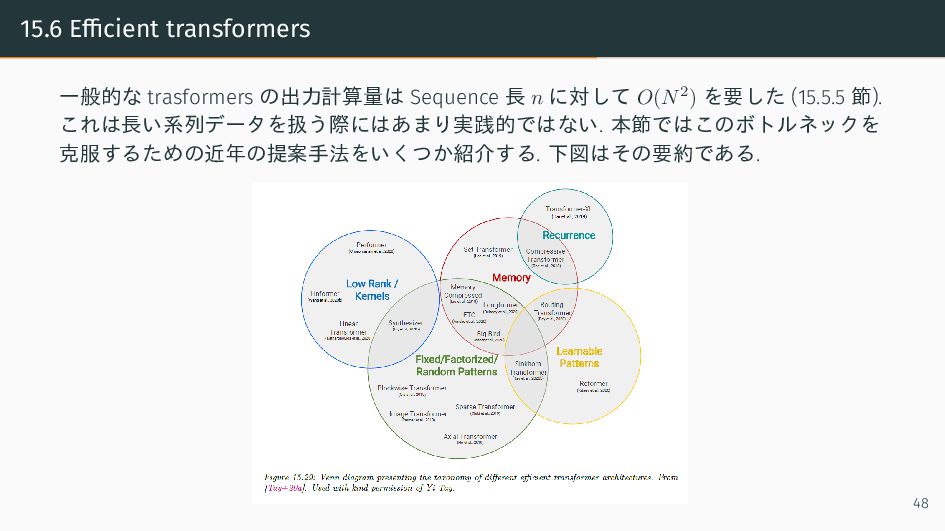{kind=link}
{kind=link}
{kind=link}
![15.6.3 Memory and recurrence methods • Momery ベースの手法 [20] は,](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_54.jpg){kind=link}
![15.6.4 Low-rank and kernel methods Performer[3] は, Attention 行列を kernel](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
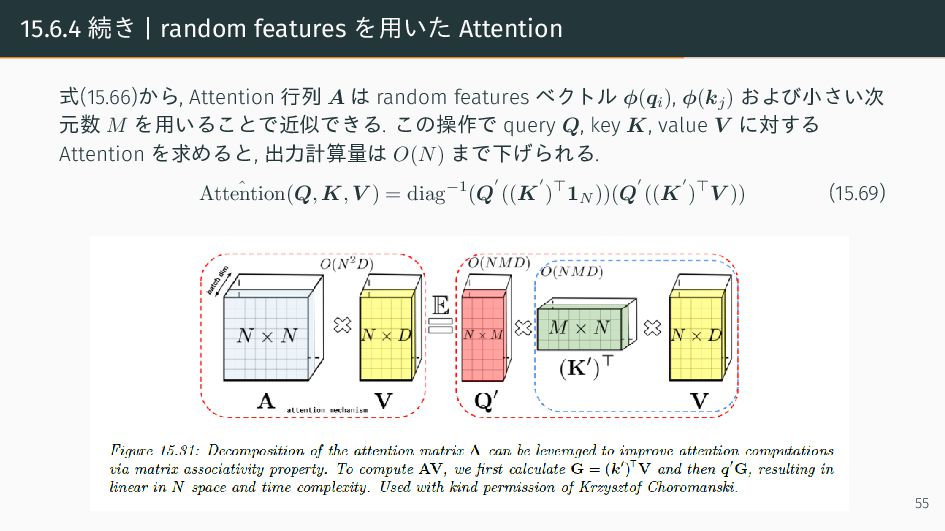{kind=link}
{kind=link}
{kind=link}
![15.7.1 ELMo Embeddings from Language Model (ELMo) [18] は, 順方向の](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_61.jpg){kind=link}
{kind=link}
{kind=link}
![15.7.2 BERT Bidirectional Encoder Representations from Transformers (BERT) [5] は,](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_64.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
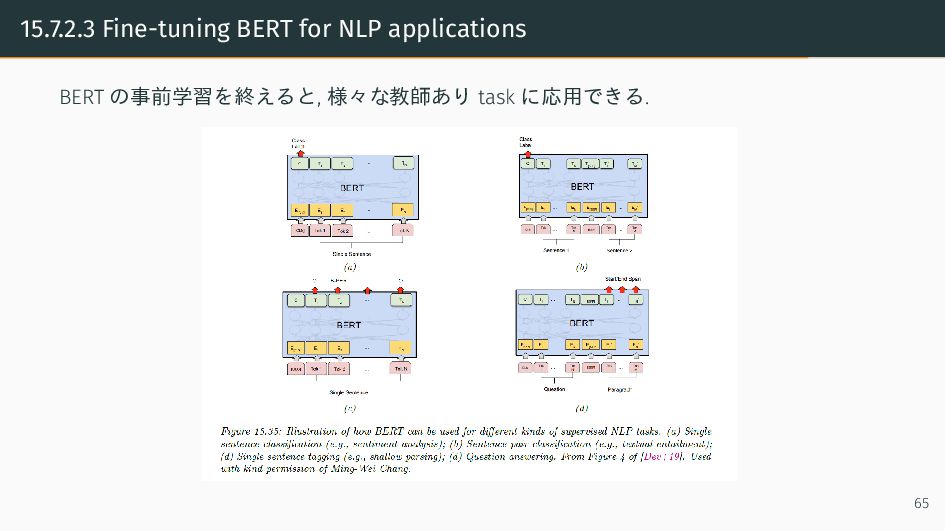{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
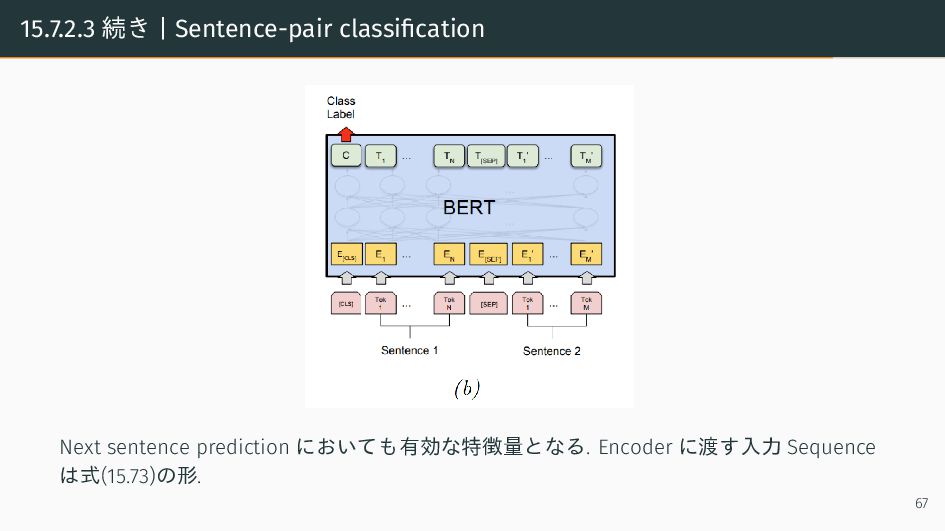
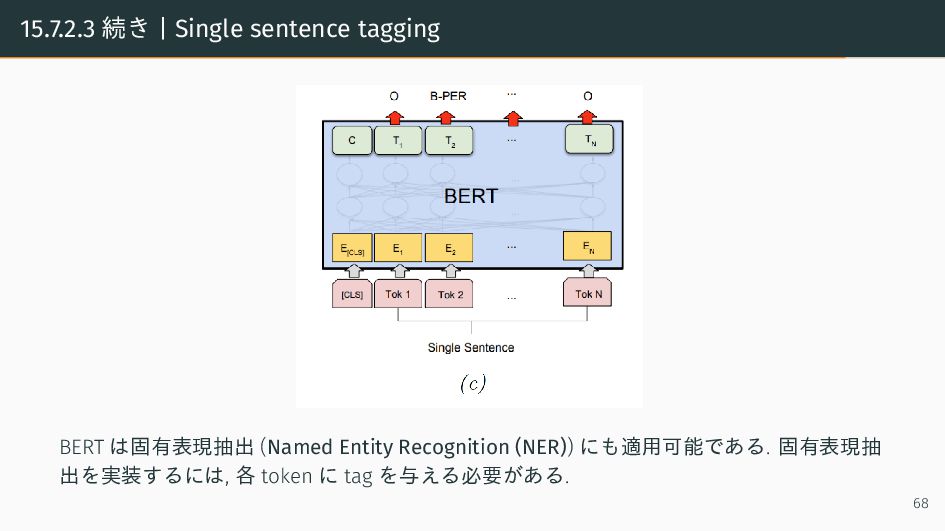
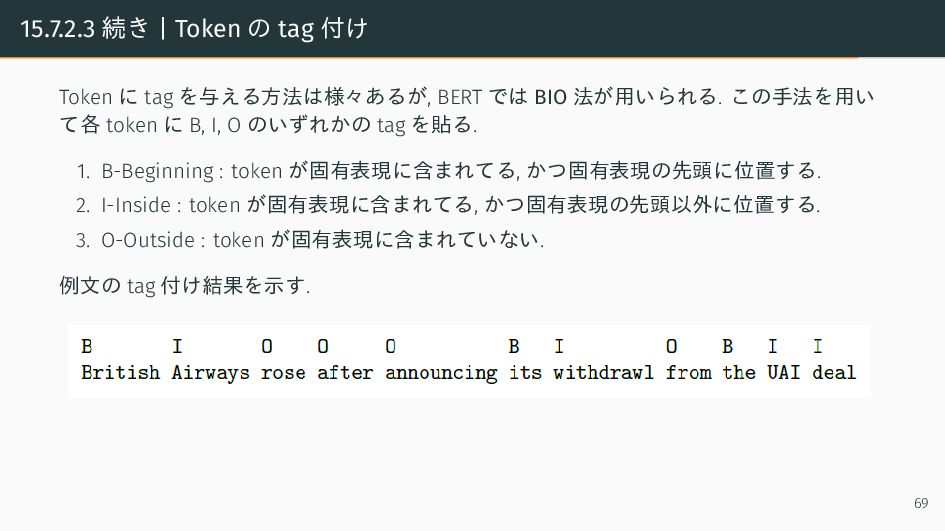
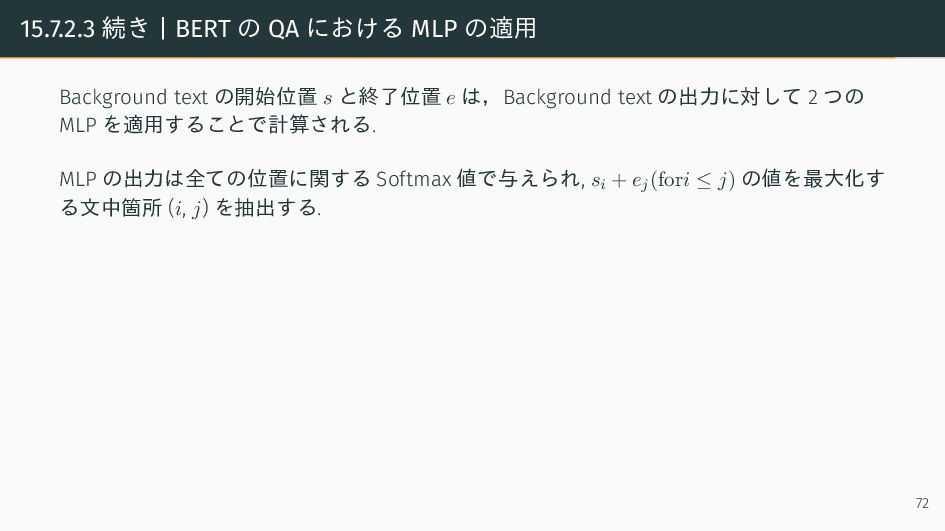
{kind=link}
{kind=link}
{kind=link}
![15.7.3 GPT • Generative Pre-training Transformer (GPT) [13] は, Decoder](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_77.jpg){kind=link}
{kind=link}
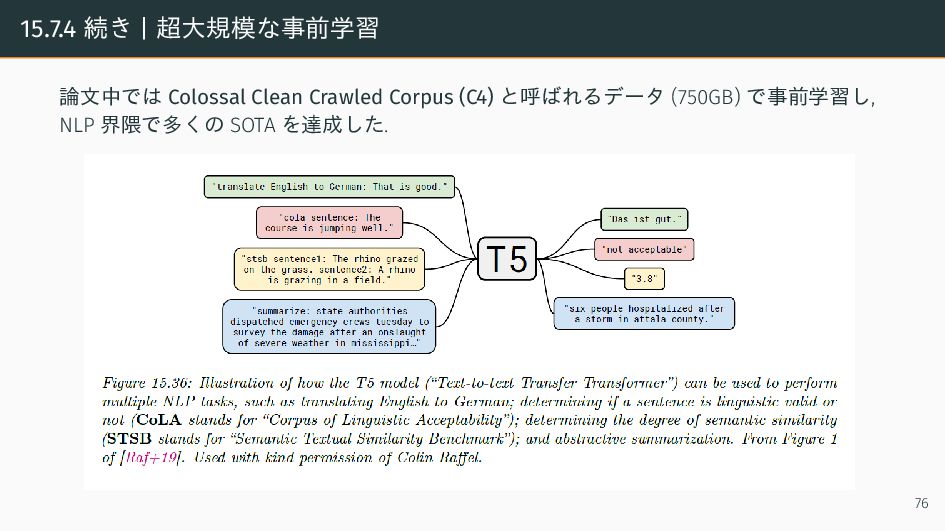
![15.7.4 T5 Text-to-text Transfer Transformer (T5) [15] は, Seq2Seq の一種で入出力ともにテキストが](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_79.jpg){kind=link}
{kind=link}
![References i [1] S. R. Bowman, G. Angeli, C. Potts,](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_81.jpg){kind=link}
![References ii [4] Z. Dai, Z. Yang, Y. Yang, J.](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_82.jpg){kind=link}
![References iii [7] A. Gulati, J. Qin, C.-C. Chiu, N.](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_83.jpg){kind=link}
![References iv [10] M.-T. Luong. Neural machine translation. 2016. [11]](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_84.jpg){kind=link}
![References v [14] A. Radford, J. Wu, R. Child, D.](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_85.jpg){kind=link}
![References vi [17] A. Roy, M. Saffar, A. Vaswani, and](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_86.jpg){kind=link}
![References vii [20] M. Zaheer, G. Guruganesh, K. A. Dubey,](https://files.speakerdeck.com/presentations/e9ee1d09759f40a086eecb0236698785/slide_87.jpg){kind=link}