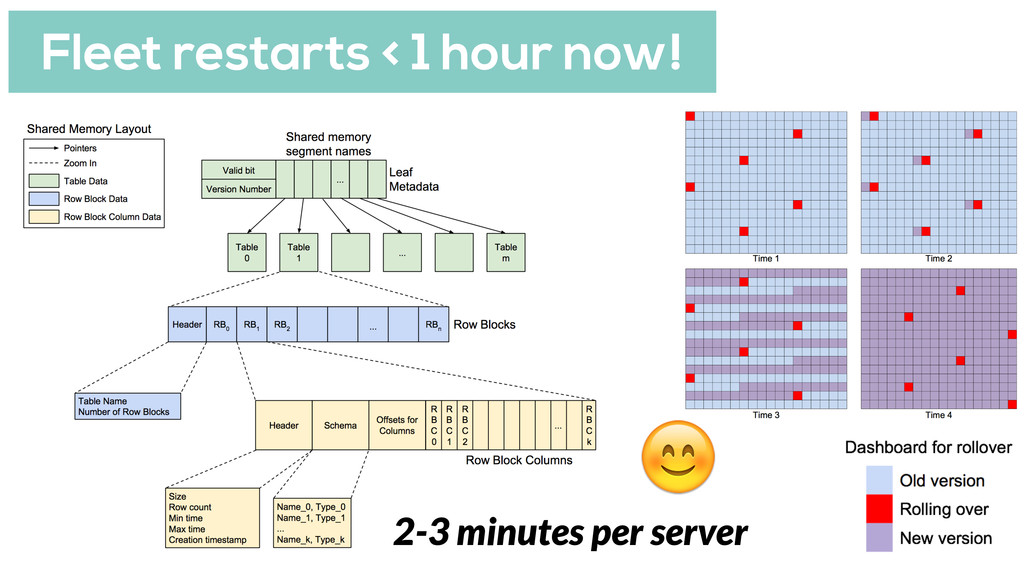
Reading 120GB of data from disk takes about 3 hours per server (8 per machine) Even with orchestrated restarts & partial queries total of ~12 hours to restart a fleet Operationally expensive & slow!
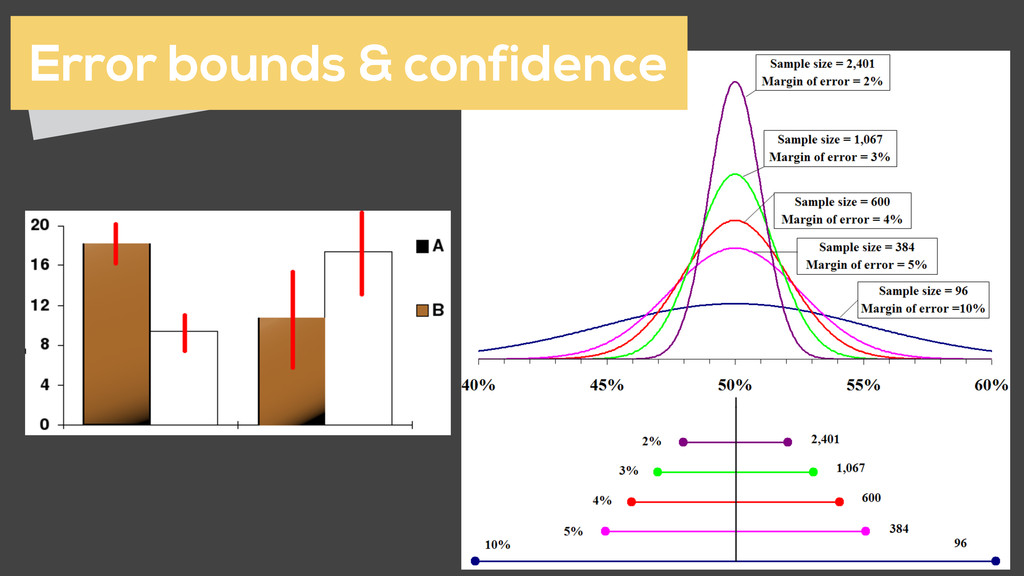
successfully) but more useful because it directly maps to user experience Failure during high & low traffic generates different yields. Uptime misses this Focus on yield rather than uptime
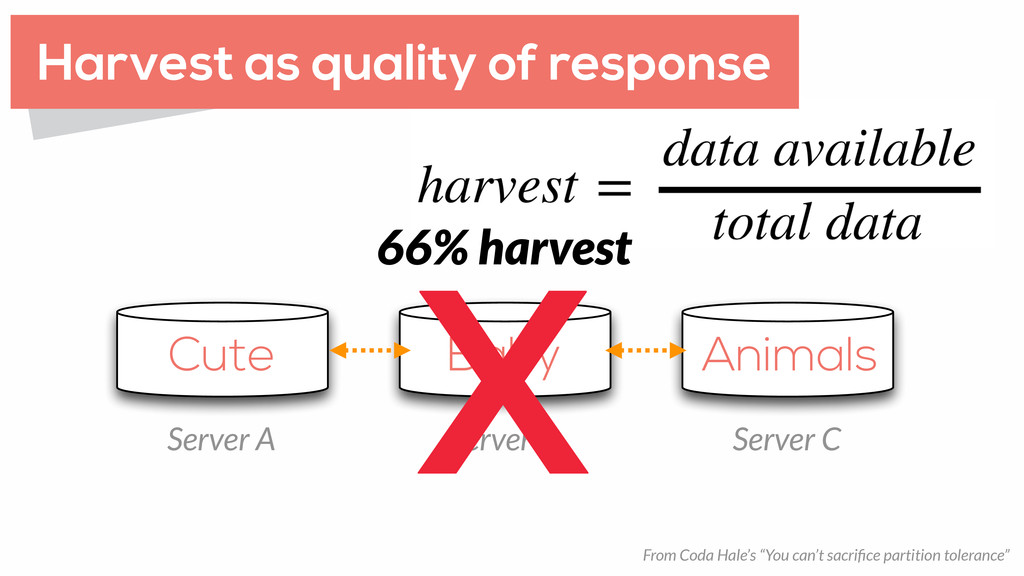
harvest degradation (fail by reducing yield). But app can continue if they fail Only provide strong consistency for the subsystems that need it Orthogonal mechanisms (state vs functionality)
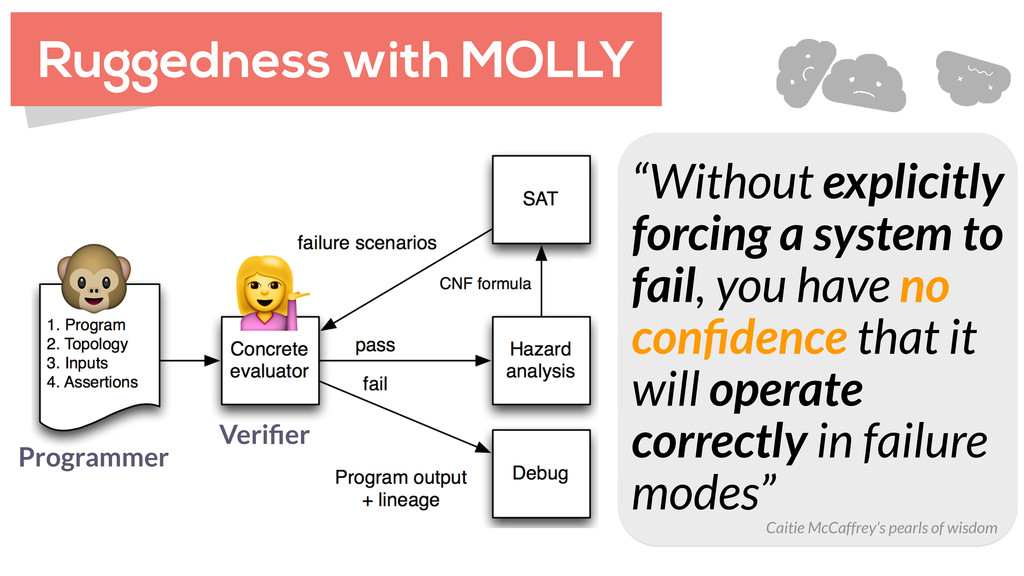
GENERATORS BOTTOM-UP LINEAGE DRIVEN FAULT INJECTORS WHITE / BLACK BOX WE KNOW (OR NOT) ABOUT THE SYSTEM HUMAN ASSISTED PROOFS SAFETY CRITICAL (TLA+, COQ, ISABELLE) MODEL CHECKING PROPERTIES + TRANSITIONS (SPIN, TLA+) LIGHTWEIGHT FM BEST OF BOTH WORLDS (ALLOY, SAT)
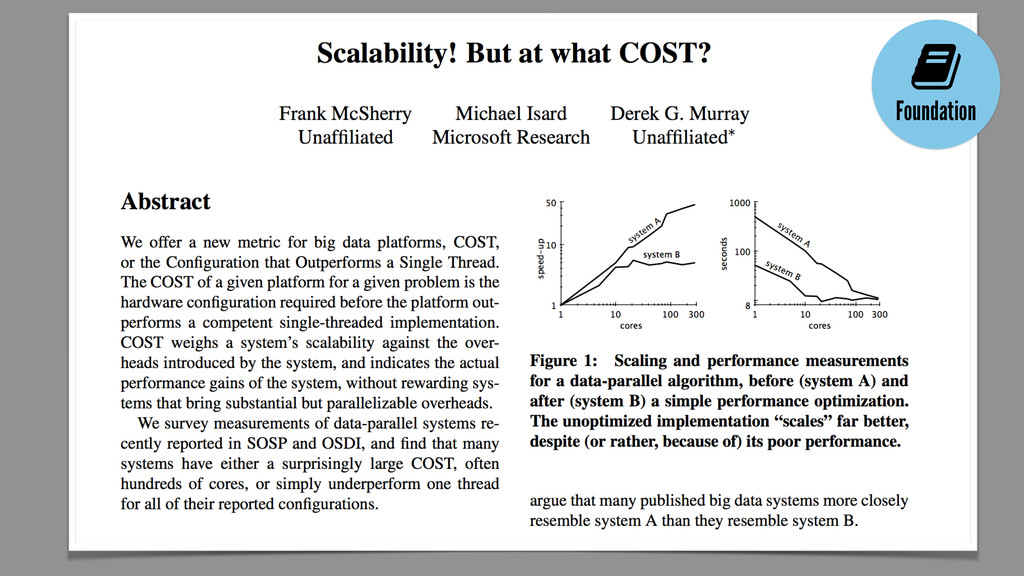
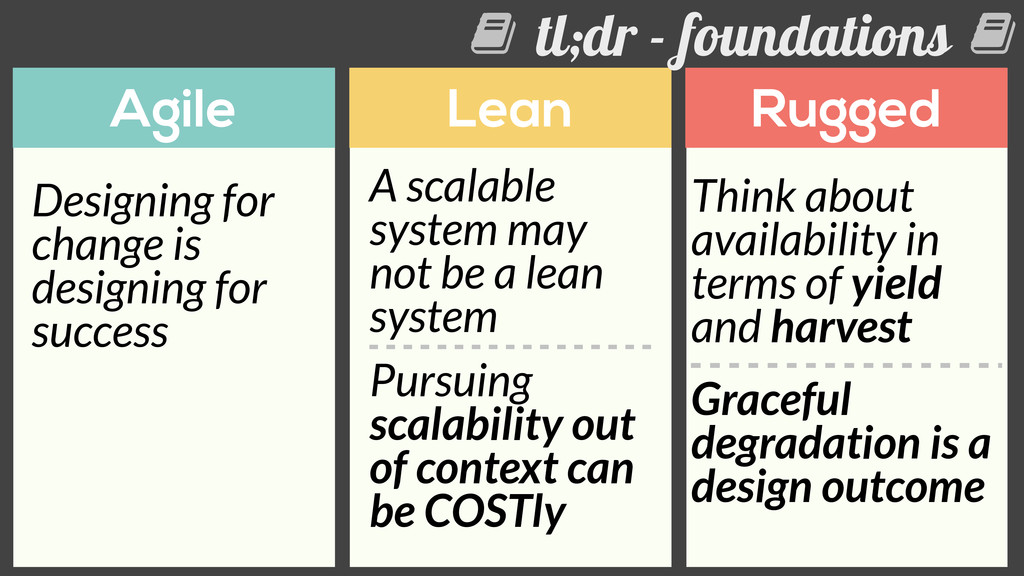
not be a lean system Pursuing scalability out of context can be COSTly Designing for change is designing for success Think about availability in terms of yield and harvest Graceful degradation is a design outcome ! !
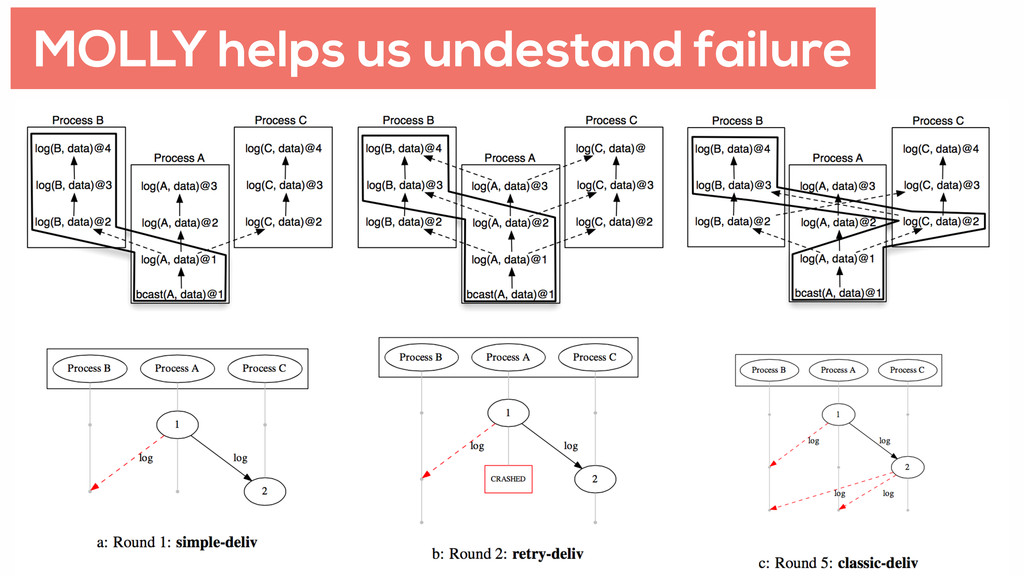
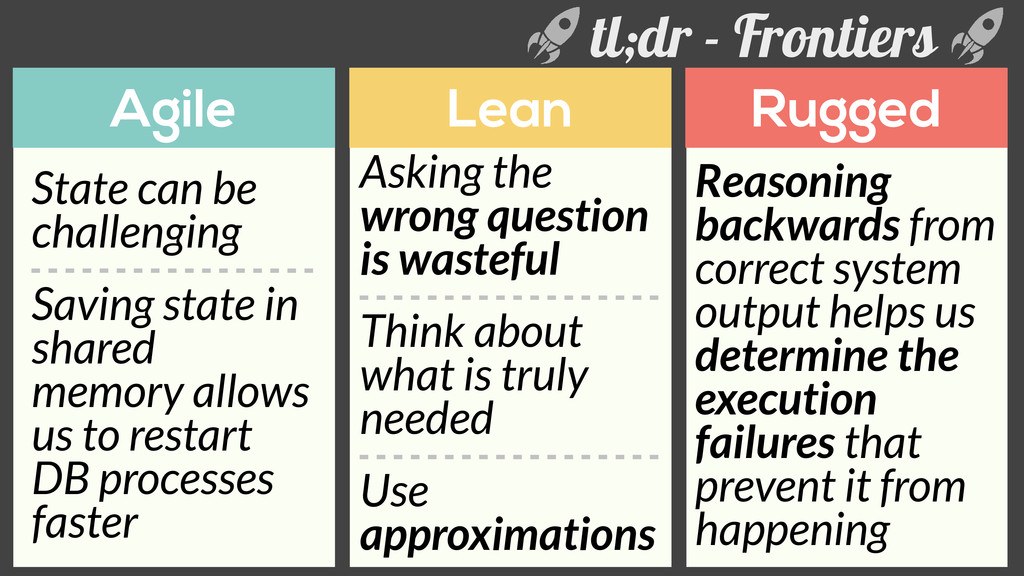
is wasteful Think about what is truly needed Use approximations State can be challenging Saving state in shared memory allows us to restart DB processes faster Reasoning backwards from correct system output helps us determine the execution failures that prevent it from happening
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}