Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DTD_生成AIアシスタントのコスト最適化
Search
BrainPad
November 27, 2025
Technology
250
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DTD_生成AIアシスタントのコスト最適化
BrainPad
November 27, 2025
More Decks by BrainPad
See All by BrainPad
白金鉱業Meetup_Vol.24_「AIエージェントは分けるほど良い」は本当か? / Is it true that “the more you divide AI agents, the better”?
brainpadpr
1
530
「ビジネス現場でのデータ分析者」 東京大学 GCI 2026 Summer
brainpadpr
2
2.3k
BrainPad_DE_202604
brainpadpr
1
14k
BrainPad AAA_AIエージェントの社会実装する上での壁 / Barriers to the Social Implementation of AI Agents
brainpadpr
1
280
白金鉱業Meetup_Vol.22_Orbital Senseを支える衛星画像のマルチモーダルエンベディングと地理空間のあいまい検索技術
brainpadpr
3
440
DTD_AIエージェント開発プロジェクトのメソッドを体系化してみる
brainpadpr
1
380
DTD_Databricksことはじめ
brainpadpr
0
310
【採用候補者向け】BrainPad AAAご紹介資料
brainpadpr
0
2.3k
DTD_はじめての因子分析_理論とビジネス活用.pdf
brainpadpr
2
2.6k
Other Decks in Technology
See All in Technology
公式ドキュメントの歩き方etc
coco_se
0
100
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.6k
AI Driven AI Governance
pict3
0
330
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
230
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
120
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
180
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
1
230
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
2.8k
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
220
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
1
700
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.3k
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
620
Featured
See All Featured
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Making the Leap to Tech Lead
cromwellryan
135
10k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
820
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
260
Paper Plane (Part 1)
katiecoart
PRO
0
9.6k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
290
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Transcript
【第7回 DEU TECH DRIVE 《BrainPad》】 生成AIアシスタントのコスト最適化 〜PoC死の回避に向けて〜 2025年11月27日
©BrainPad Inc. Strictly Confidential 2 自己紹介 データエンジニア 服部 晃平 (はっとり
こうへい) データエンジニアリングユニット ビジネス開発 所属 ⮚ 経歴 ⮚ 2018年 早稲田大学 助手 ⮚ 2021年~ 株式会社ブレインパッド(新卒五年目) ⮚ プロジェクト経験 データエンジニアとしてスタートし、最近は生成AI活用の案 件を中心に担当しています ⮚ データ基盤構築、運用保守、BIツール導入 ⮚ 生成AIアプリ開発 ⮚ 趣味 ⮚ 弓道、イラスト制作
©BrainPad Inc. Strictly Confidential 3 本日話すこと 社内情報などに基づいて回答する生成AIチャットアプリをPoC案件にて開発しました その際に直面したコスト面の課題や、大規模展開に向けた改善アプローチについて話します
©BrainPad Inc. Strictly Confidential 4 1. 生成AIチャットアプリにおけるRAG 1. 検索拡張生成 (RAG)
2. RAG実装のアプローチ 3. 検索対象の多様化 2. 事例:大手製造業向け生成AIチャットアプリ開発PoC 1. 概要 2. 回答生成ロジック 3. 一般ユーザー展開の検討時に直面した課題 3. 大規模展開に向けて 1. 対策例:低コストであるFAQでの回答に可能な限り集約する 2. 対策例: FAQや過去質問をキャッシュ化しRAG検索のリクエスト自体を抑える 3. 対策例:より安価な検索APIを使う 4. 対策例:ユーザ課金型のサービスを使う(社内用途) 4. まとめ 目次
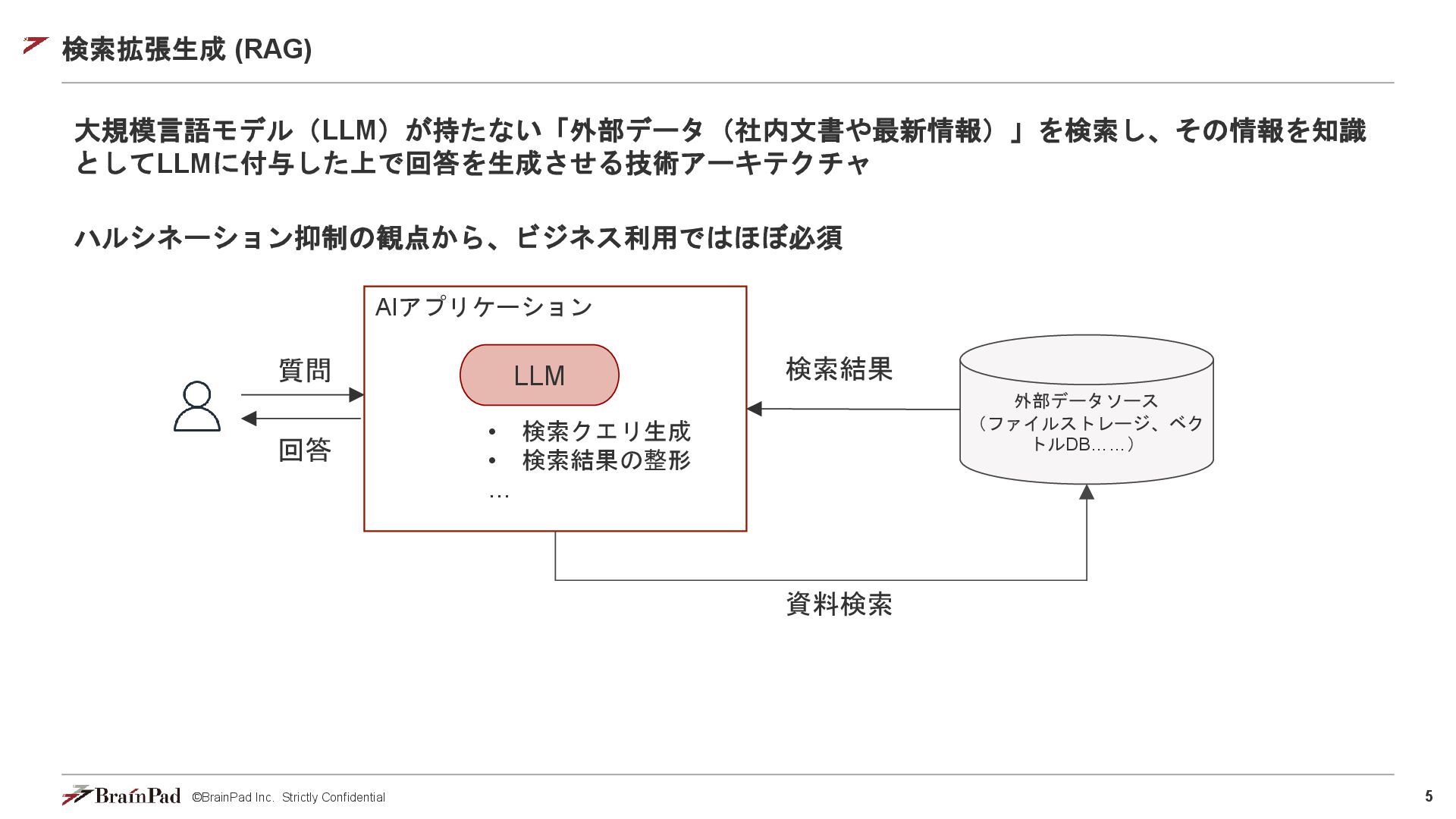
©BrainPad Inc. Strictly Confidential 5 検索拡張生成 (RAG) 大規模言語モデル(LLM)が持たない「外部データ(社内文書や最新情報)」を検索し、その情報を知識 としてLLMに付与した上で回答を生成させる技術アーキテクチャ ハルシネーション抑制の観点から、ビジネス利用ではほぼ必須
AIアプリケーション LLM 外部データソース (ファイルストレージ、ベク トルDB……) 質問 • 検索クエリ生成 • 検索結果の整形 … 回答 検索結果 資料検索
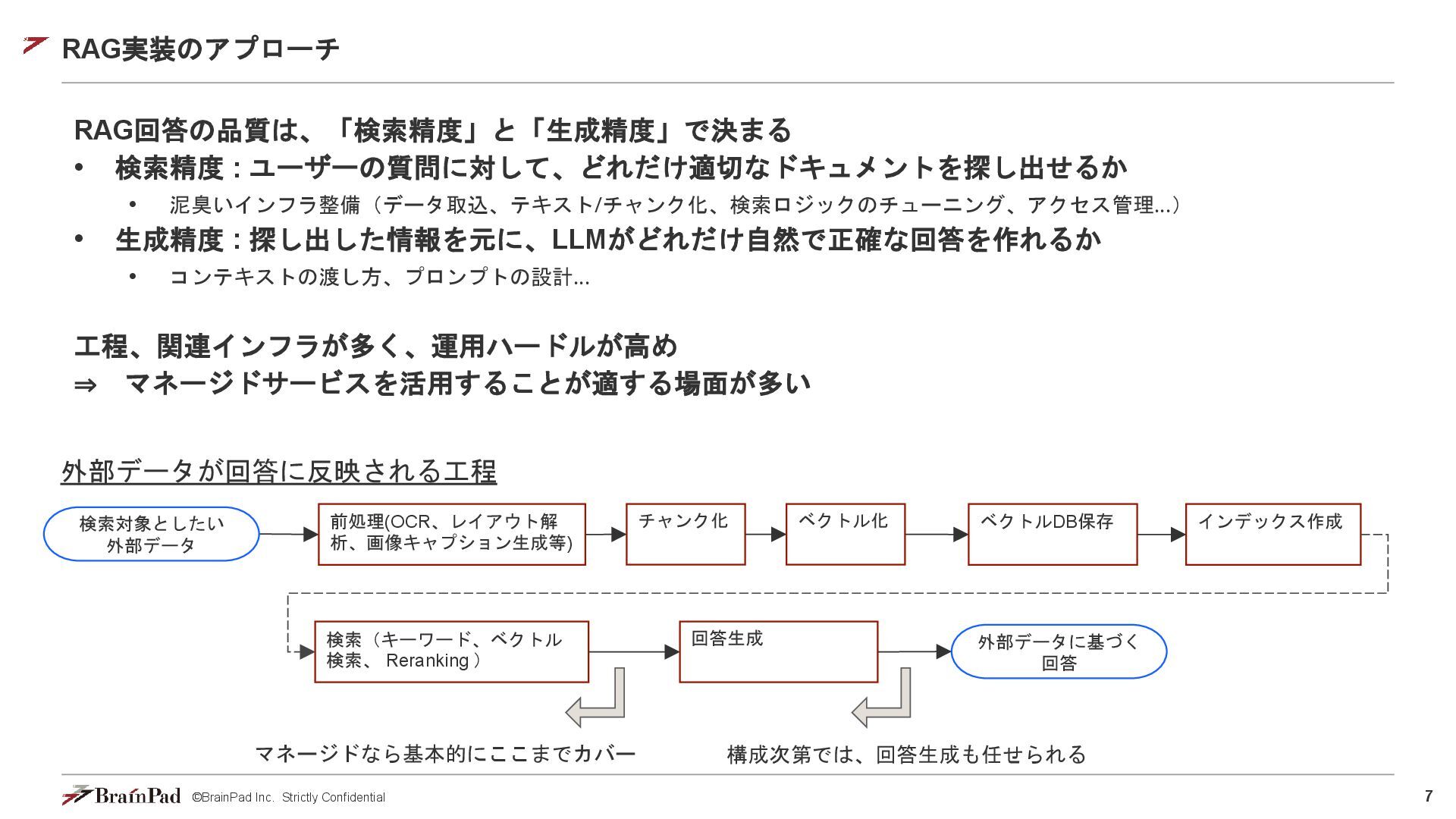
©BrainPad Inc. Strictly Confidential 6 RAG実装のアプローチ RAG回答の品質は、「検索精度」と「生成精度」で決まる • 検索精度 :
ユーザーの質問に対して、どれだけ適切なドキュメントを探し出せるか • 泥臭いインフラ整備(データ取込、テキスト/チャンク化、検索ロジックのチューニング、アクセス管理…) • 生成精度 : 探し出した情報を元に、LLMがどれだけ自然で正確な回答を作れるか • コンテキストの渡し方、プロンプトの設計… 工程、関連インフラが多く、運用ハードルが高め ⇒ マネージドサービスを活用することが適する場面が多い ベクトルDB保存 検索対象としたい 外部データ 前処理(OCR、レイアウト解 析、画像キャプション生成等) インデックス作成 外部データに基づく 回答 検索(キーワード、ベクトル 検索、 Reranking ) 回答生成 外部データが回答に反映される工程 チャンク化 ベクトル化
©BrainPad Inc. Strictly Confidential 7 RAG実装のアプローチ RAG回答の品質は、「検索精度」と「生成精度」で決まる • 検索精度 :
ユーザーの質問に対して、どれだけ適切なドキュメントを探し出せるか • 泥臭いインフラ整備(データ取込、テキスト/チャンク化、検索ロジックのチューニング、アクセス管理…) • 生成精度 : 探し出した情報を元に、LLMがどれだけ自然で正確な回答を作れるか • コンテキストの渡し方、プロンプトの設計… 工程、関連インフラが多く、運用ハードルが高め ⇒ マネージドサービスを活用することが適する場面が多い ベクトルDB保存 検索対象としたい 外部データ 前処理(OCR、レイアウト解 析、画像キャプション生成等) インデックス作成 外部データに基づく 回答 検索(キーワード、ベクトル 検索、 Reranking ) 回答生成 外部データが回答に反映される工程 チャンク化 ベクトル化 マネージドなら基本的にここまでカバー 構成次第では、回答生成も任せられる
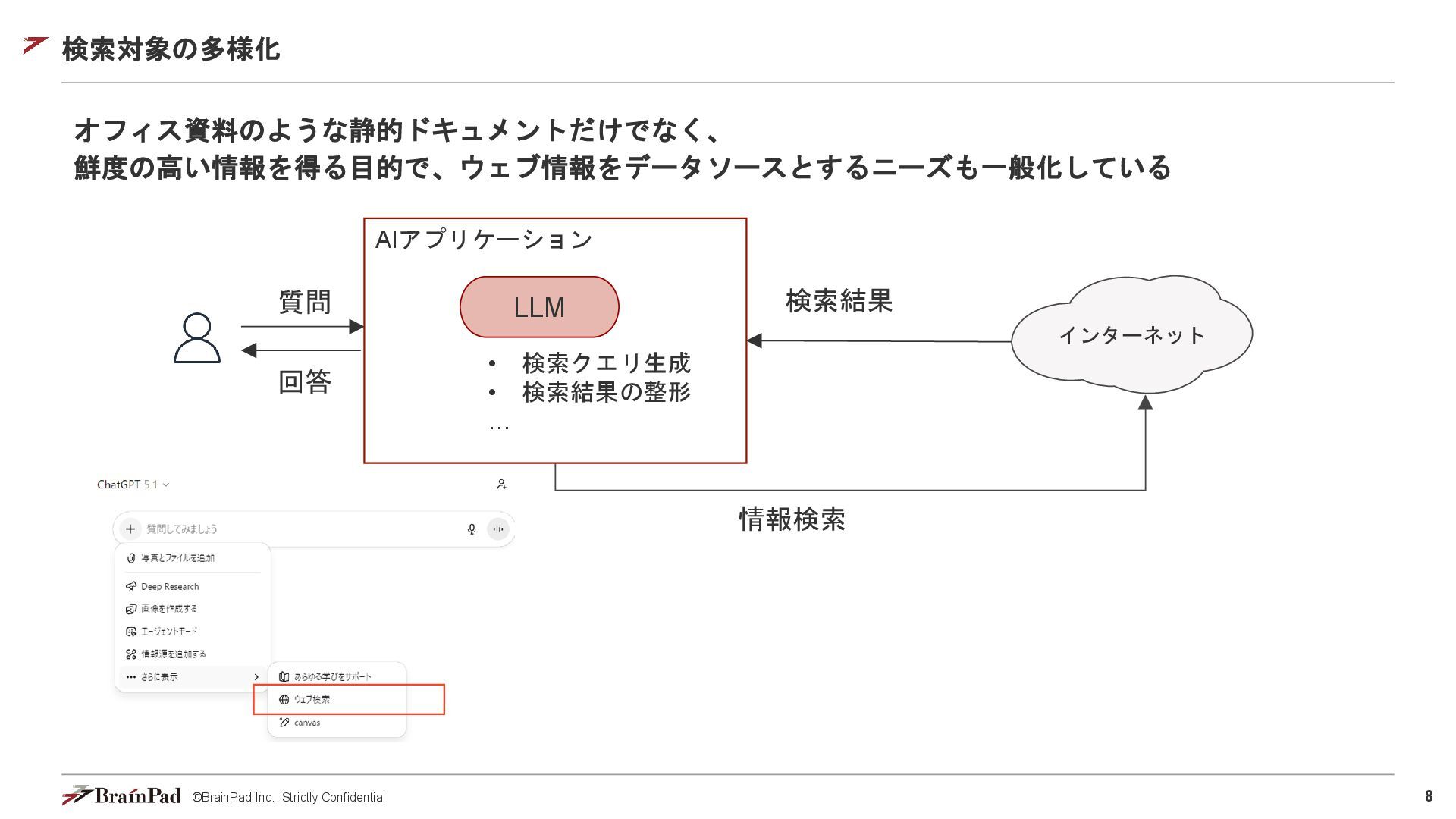
©BrainPad Inc. Strictly Confidential 8 検索対象の多様化 オフィス資料のような静的ドキュメントだけでなく、 鮮度の高い情報を得る目的で、ウェブ情報をデータソースとするニーズも一般化している AIアプリケーション LLM
質問 • 検索クエリ生成 • 検索結果の整形 … 回答 検索結果 情報検索 インターネット
©BrainPad Inc. Strictly Confidential 9 1. 生成AIチャットアプリにおけるRAG 1. 検索拡張生成 (RAG)
2. RAG実装のアプローチ 3. 検索対象の多様化 2. 事例:大手製造業向け生成AIチャットアプリ開発PoC 1. 概要 2. 回答生成ロジック 3. 一般ユーザー展開の検討時に直面した課題 3. 大規模展開に向けて 1. 対策例:低コストであるFAQでの回答に可能な限り集約する 2. 対策例: FAQや過去質問をキャッシュ化しRAG検索のリクエスト自体を抑える 3. 対策例:より安価な検索APIを使う 4. 対策例:ユーザ課金型のサービスを使う(社内用途) 4. まとめ 目次
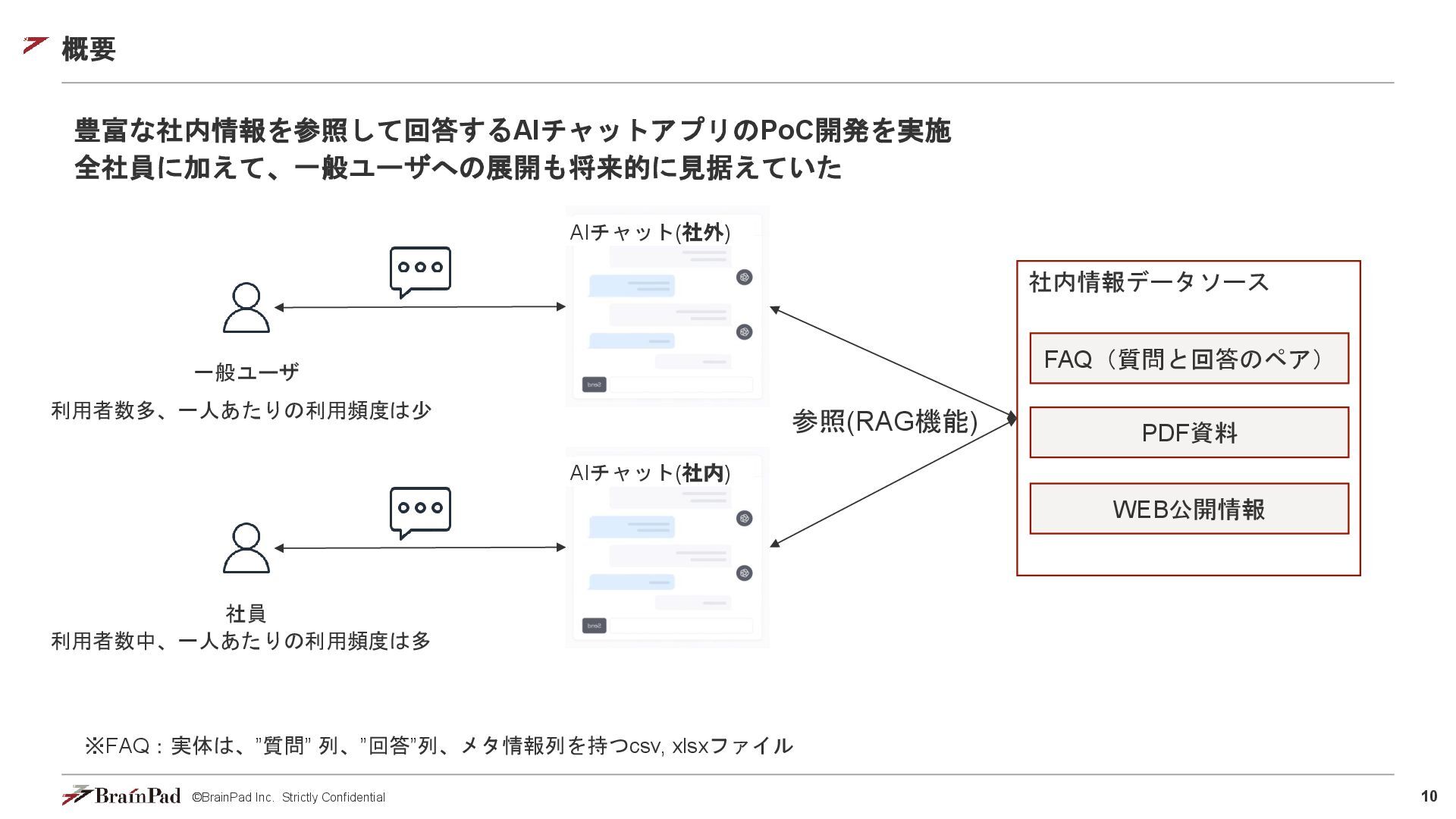
©BrainPad Inc. Strictly Confidential 10 概要 豊富な社内情報を参照して回答するAIチャットアプリのPoC開発を実施 全社員に加えて、一般ユーザへの展開も将来的に見据えていた FAQ(質問と回答のペア) WEB公開情報
一般ユーザ AIチャット(社外) 社員 AIチャット(社内) 社内情報データソース 参照(RAG機能) PDF資料 利用者数多、一人あたりの利用頻度は少 利用者数中、一人あたりの利用頻度は多 ※FAQ:実体は、”質問” 列、”回答”列、メタ情報列を持つcsv, xlsxファイル
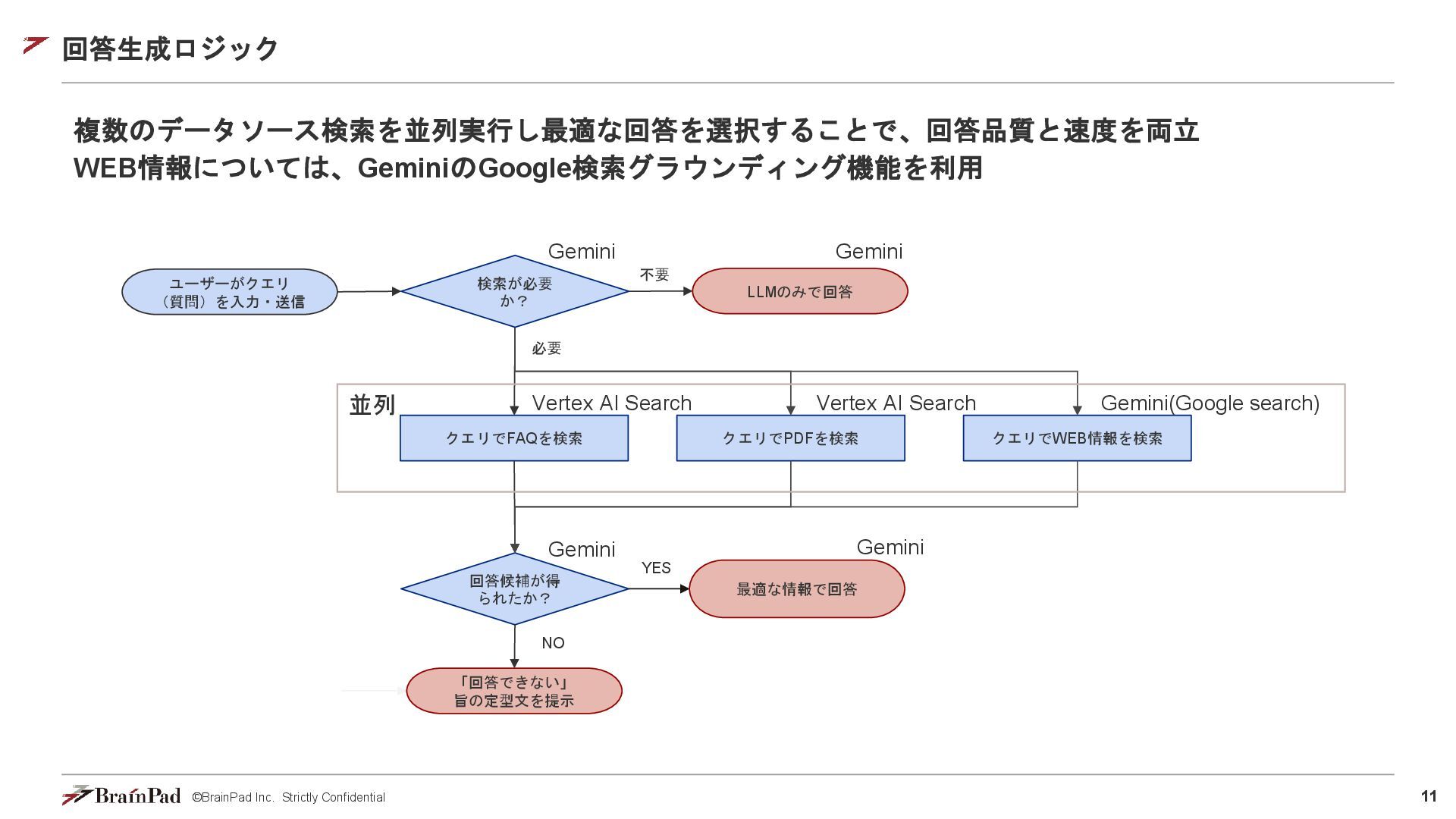
©BrainPad Inc. Strictly Confidential 11 回答生成ロジック 複数のデータソース検索を並列実行し最適な回答を選択することで、回答品質と速度を両立 WEB情報については、GeminiのGoogle検索グラウンディング機能を利用 クエリでFAQを検索 回答候補が得
られたか? 「回答できない」 旨の定型文を提示 最適な情報で回答 ユーザーがクエリ (質問)を入力・送信 YES NO 必要 LLMのみで回答 クエリでPDFを検索 クエリでWEB情報を検索 並列 Vertex AI Search Vertex AI Search Gemini(Google search) 不要 検索が必要 か? Gemini Gemini Gemini Gemini
©BrainPad Inc. Strictly Confidential 12 一般ユーザー展開の検討時に直面した課題 PoC時の実地検証での反応は上々! ! ! ……でしたが、システム化の検討段階で運用コストに関する課題に直面しました
課題:高度な検索機能を有効にすると検索コストが倍増する • 通常検索 • $4.00/1000クエリ • AIモード(検索結果の要約など) • $8.00/1000クエリ • ※ 2025/11時点、要約が通常検索に含まれるとの記載が公式ドキュメントにあり。仕様改善された可能性あり。 課題:クラウドプロバイダーの生成AI向けWeb検索オプションは、意外と高い • Gemini API の Grounding with Google Search • Azure Grounding with Bing • 共に$35/1,000クエリ https://ai.google.dev/gemini-api/docs/pricing?utm_source=chatgpt.com&hl=ja https://www.microsoft.com/en-us/bing/apis/grounding-pricing https://cloud.google.com/generative-ai-app- builder/pricing?utm_source=chatgpt.com&hl=ja
©BrainPad Inc. Strictly Confidential 13 一般ユーザー展開の検討時に直面した課題 運用費の試算イメージ(サーバー代は除く) • 前提 •
月間質問数 1,000,000件 • 月間利用者数:10,000人、一人あたりの日次質問数:5件、利用日数/月:20日 • RAGエンジン:Vertex AI Search(高度なLLM機能有効化) • 生成AIモデル:Gemini 2.5 Flash • 検索グラウンディング有効化(毎質問に必ず) • 質問あたりの平均トークン数(入力+出力合算):1,000トークン • 運用費 • Vertex AI Search クエリ費用 1,200,000円 • Gemini 2.5 Flash モデル料金 420,000円 • Google検索グラウンディング料金 5,092,500円 合計 : 6,712,500円/月 LLM本体よりも周辺機能のコストが支配的 特に、Web検索オプションの使いどころは慎重に判断すべき
©BrainPad Inc. Strictly Confidential 14 一般ユーザー展開の検討時に直面した課題 運用費の試算イメージ(サーバー代は除く) • 前提 •
月間質問数 1,000,000件 • 月間利用者数:10,000人、一人あたりの日次質問数:5件、利用日数/月:20日 • RAGエンジン:Vertex AI Search(高度なLLM機能有効化) • 生成AIモデル:Gemini 2.5 Flash • 検索グラウンディング有効化(毎質問に必ず) • 質問あたりの平均トークン数(入力+出力合算):1,000トークン • 運用費 • Vertex AI Search クエリ費用 1,200,000円 • Gemini 2.5 Flash モデル料金 420,000円 • Google検索グラウンディング料金 5,092,500円 合計 : 6,712,500円/月 LLM本体よりも周辺機能のコストが支配的 特に、Web検索オプションの使いどころは慎重に判断すべき ChatGPT、 Gemini などの対話型生成AIサービスは無料で利用できるため、 類似の機能を自社運用するだけで高額なコスト発生しうることは、投資対 効果(ROI)の観点から社内の理解を得にくい可能性があります。
©BrainPad Inc. Strictly Confidential 15 1. 生成AIチャットアプリにおけるRAG 1. 検索拡張生成 (RAG)
2. RAG実装のアプローチ 3. 検索対象の多様化 2. 事例:大手製造業向け生成AIチャットアプリ開発PoC 1. 概要 2. 回答生成ロジック 3. 一般ユーザー展開の検討時に直面した課題 3. 大規模展開に向けて 1. 対策例:低コストであるFAQでの回答に可能な限り集約する 2. 対策例: FAQや過去質問をキャッシュ化しRAG検索のリクエスト自体を抑える 3. 対策例:より安価な検索APIを使う 4. 対策例:ユーザ課金型のサービスを使う(社内用途) 4. まとめ 目次
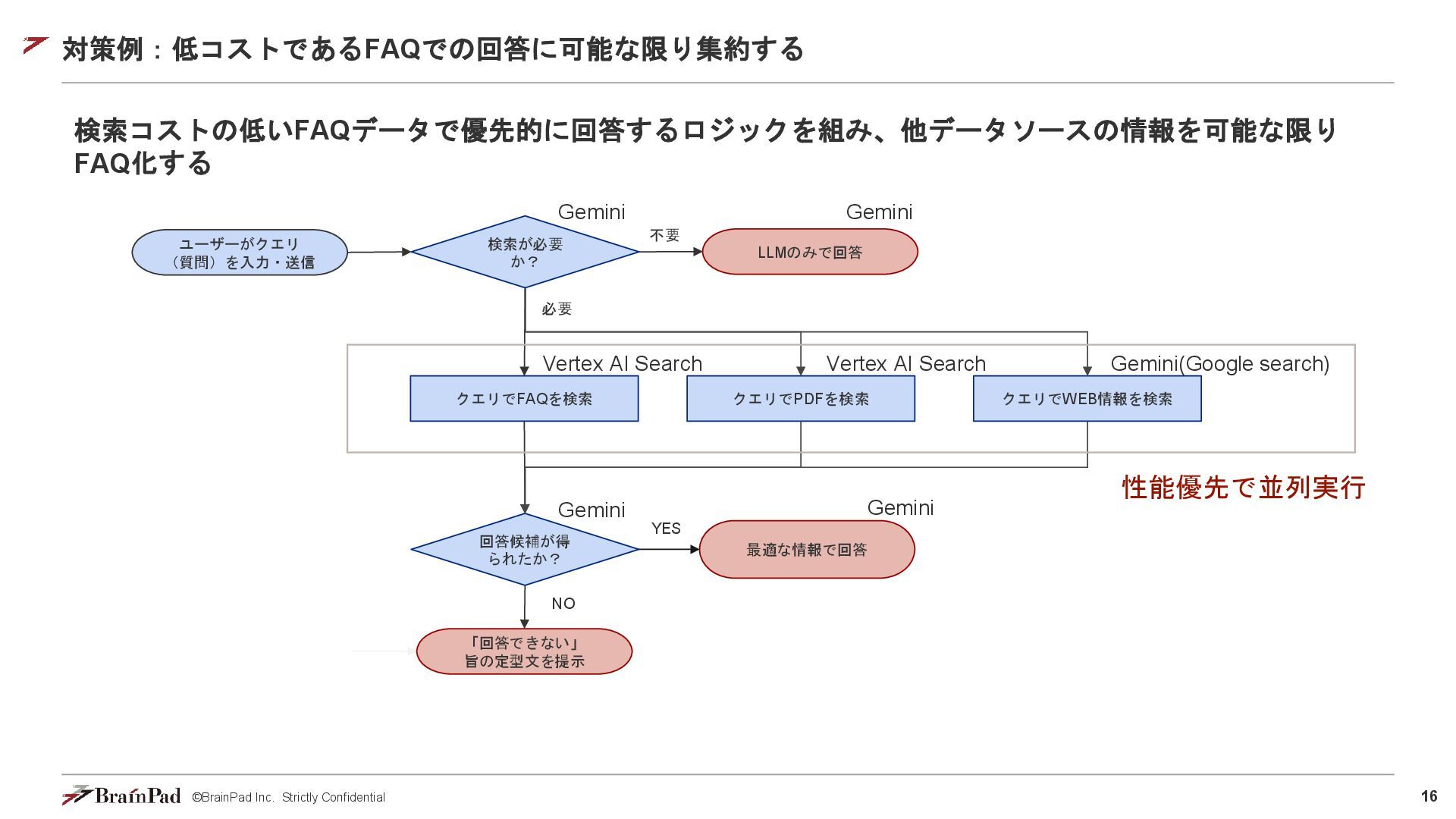
©BrainPad Inc. Strictly Confidential 16 対策例:低コストであるFAQでの回答に可能な限り集約する 検索コストの低いFAQデータで優先的に回答するロジックを組み、他データソースの情報を可能な限り FAQ化する クエリでFAQを検索 回答候補が得
られたか? 「回答できない」 旨の定型文を提示 最適な情報で回答 ユーザーがクエリ (質問)を入力・送信 YES NO 必要 LLMのみで回答 クエリでPDFを検索 クエリでWEB情報を検索 Vertex AI Search Vertex AI Search Gemini(Google search) 不要 検索が必要 か? Gemini Gemini Gemini Gemini 性能優先で並列実行
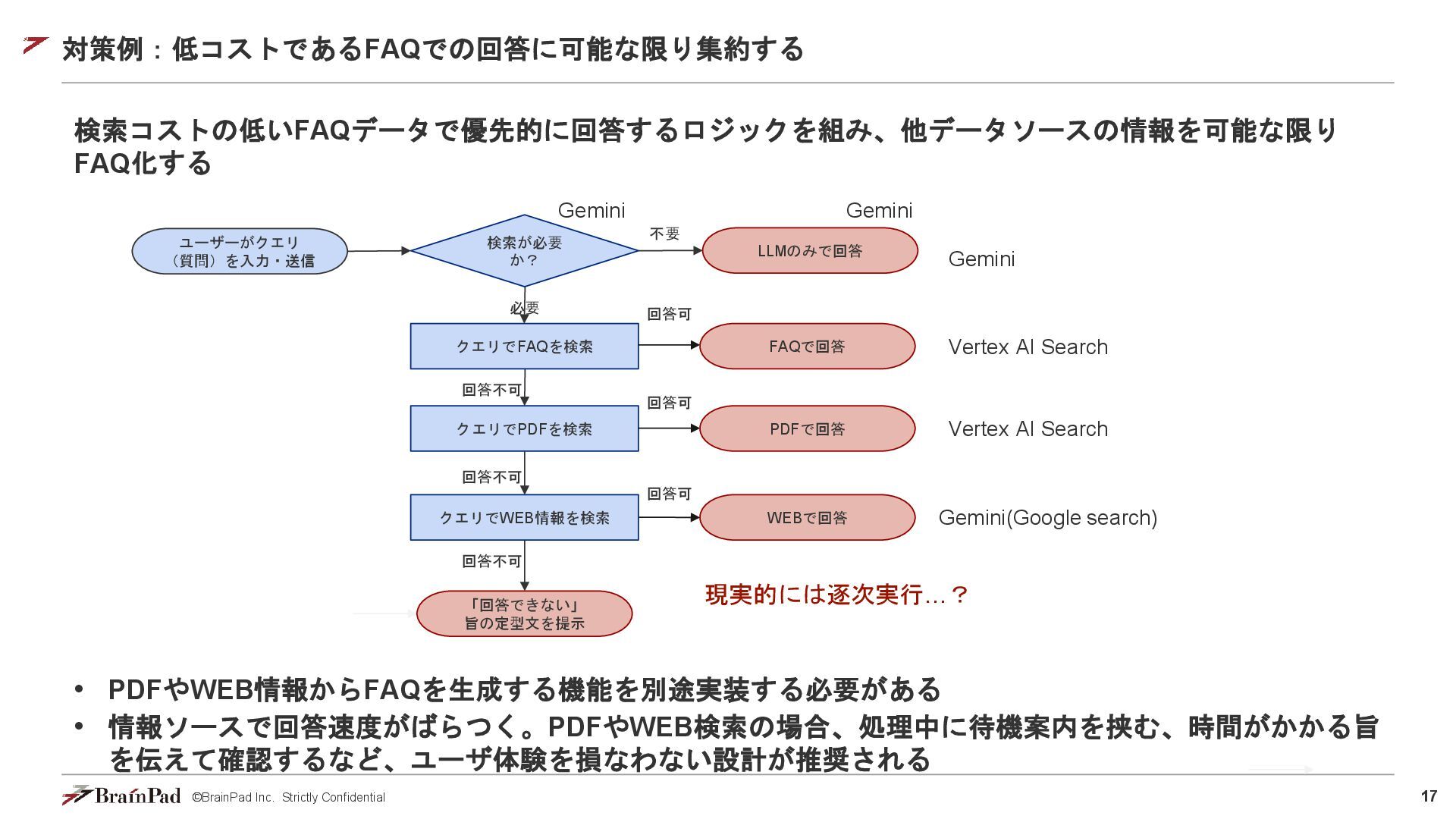
©BrainPad Inc. Strictly Confidential 17 対策例:低コストであるFAQでの回答に可能な限り集約する 検索コストの低いFAQデータで優先的に回答するロジックを組み、他データソースの情報を可能な限り FAQ化する クエリでFAQを検索 「回答できない」
旨の定型文を提示 ユーザーがクエリ (質問)を入力・送信 回答可 必要 LLMのみで回答 クエリでPDFを検索 クエリでWEB情報を検索 Vertex AI Search Gemini(Google search) 不要 検索が必要 か? Gemini Gemini Gemini • PDFやWEB情報からFAQを生成する機能を別途実装する必要がある • 情報ソースで回答速度がばらつく。PDFやWEB検索の場合、処理中に待機案内を挟む、時間がかかる旨 を伝えて確認するなど、ユーザ体験を損なわない設計が推奨される WEBで回答 PDFで回答 FAQで回答 Vertex AI Search 回答可 回答可 回答不可 回答不可 回答不可 現実的には逐次実行…?
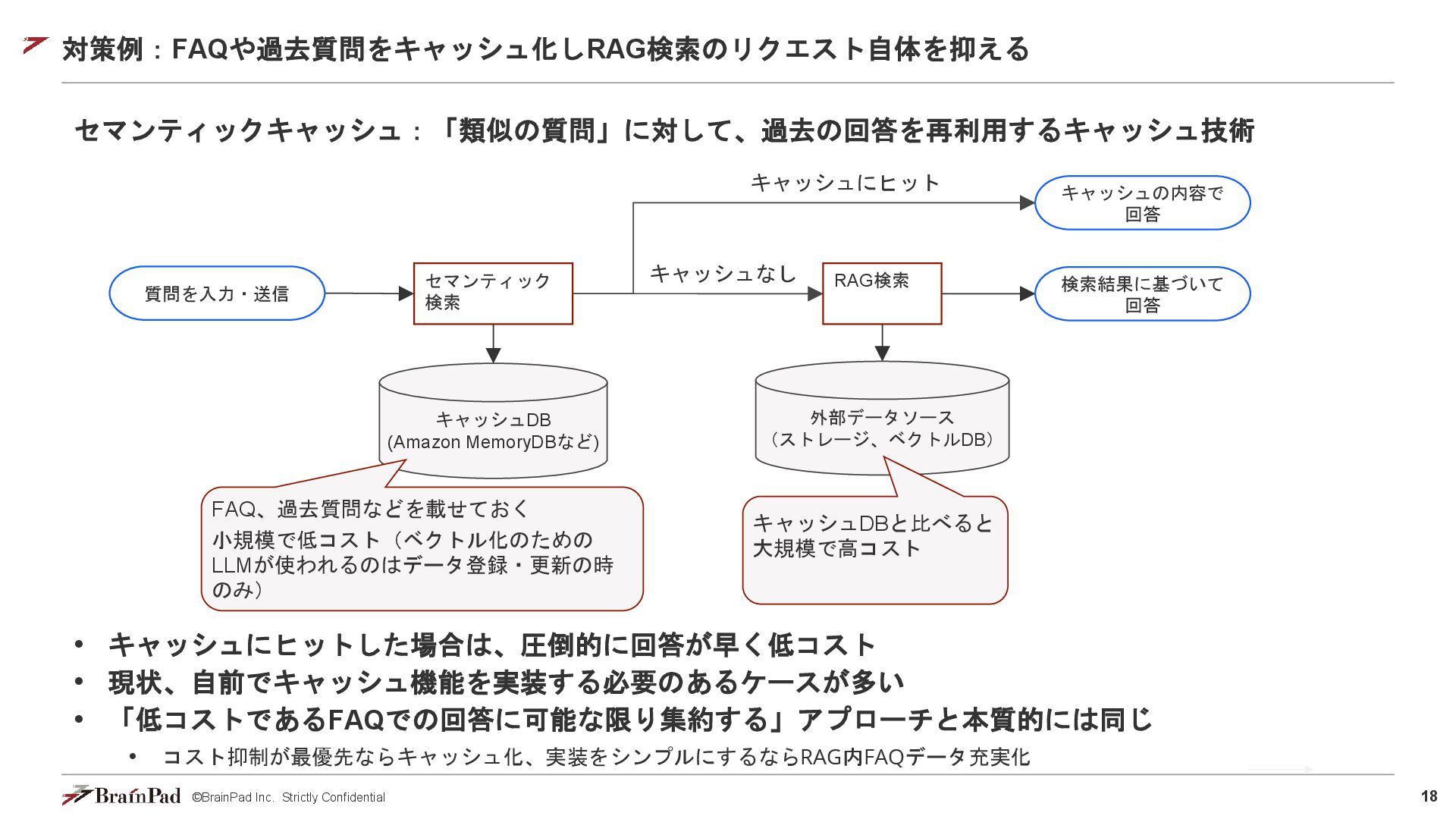
©BrainPad Inc. Strictly Confidential 18 対策例:FAQや過去質問をキャッシュ化しRAG検索のリクエスト自体を抑える セマンティックキャッシュ:「類似の質問」に対して、過去の回答を再利用するキャッシュ技術 • キャッシュにヒットした場合は、圧倒的に回答が早く低コスト •
現状、自前でキャッシュ機能を実装する必要のあるケースが多い • 「低コストであるFAQでの回答に可能な限り集約する」アプローチと本質的には同じ • コスト抑制が最優先ならキャッシュ化、実装をシンプルにするならRAG内FAQデータ充実化 質問を入力・送信 セマンティック 検索 RAG検索 キャッシュDB (Amazon MemoryDBなど) キャッシュにヒット キャッシュの内容で 回答 外部データソース (ストレージ、ベクトルDB) 検索結果に基づいて 回答 キャッシュなし FAQ、過去質問などを載せておく 小規模で低コスト(ベクトル化のための LLMが使われるのはデータ登録・更新の時 のみ) キャッシュDBと比べると 大規模で高コスト
©BrainPad Inc. Strictly Confidential 19 対策例:より安価な検索APIを使う Tavilyなどの独自の検索APIを使うことで、WEB検索コストを抑えられる それでもなお、大量リクエスト時には高額となりうるため、リクエスト数の制御も変わらず重要 料金/目安 利点
欠点 Tavily(検索API) $8~16/1,000クエリ ※$0.008/1クレジット 検索設定により1リクエストあたり 1~2クレジット消費 LLMアプリ用途に最適化されており、検索結果の 構造化・抽出・要約・citation付与までを全て依頼 できる 独自のインデックスに対する検索となり、細かな検索設定 はサポートされていない Bright Data(ス クレイピング) $1.5/1,000クエリ 単純比較で圧倒的に安価 SLA 99.9% スクレイピングを代行するサービスで、LLMアプリ向けに 最適化されていない 検索結果は生のHTMLデータのため、検索結果から回答を 整形する工程は自前で用意する必要がある Grounding with Google Search (GCP) $35/1,000クエリ クラウドサービス組込のため、自前での作りこみ 不要 外部サービスに比べると高価 Bing Search API (Azure) $35/1,000クエリ クラウドサービス組込のため、自前での作りこみ 不要 外部サービスに比べると高価 ※AWSのAIサービス(Amazon Bedrock)はWeb検索オプションを直接提供しておらず、Tavilyの利用を推奨している https://aws.amazon.com/jp/blogs/machine-learning/build-dynamic-web-research-agents-with-the-strands-agents-sdk-and-tavily/?utm_source=chatgpt.com
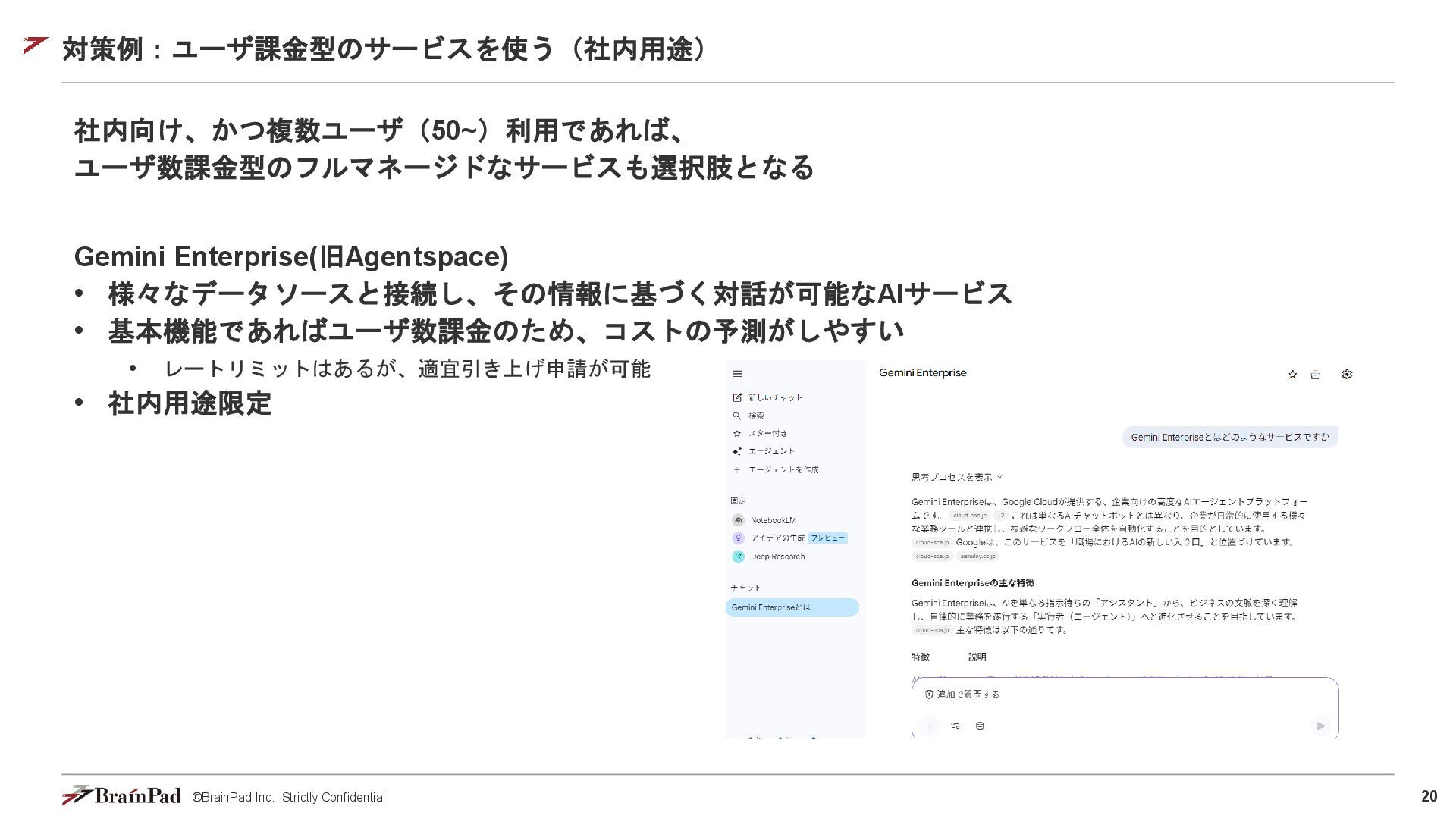
©BrainPad Inc. Strictly Confidential 20 対策例:ユーザ課金型のサービスを使う(社内用途) 社内向け、かつ複数ユーザ(50~)利用であれば、 ユーザ数課金型のフルマネージドなサービスも選択肢となる Gemini Enterprise(旧Agentspace)
• 様々なデータソースと接続し、その情報に基づく対話が可能なAIサービス • 基本機能であればユーザ数課金のため、コストの予測がしやすい • レートリミットはあるが、適宜引き上げ申請が可能 • 社内用途限定
©BrainPad Inc. Strictly Confidential 21 まとめ 1. 関連情報検索によって回答精度を高めるRAGは、ビジネス向けの生成AIアプリで重宝される 技術 2.
一方、RAGに関連するサービスは安くない。データストアに保持した情報に対する検索と WEB情報に対する検索のどちらも、想定以上のコストとなる可能性がある 3. 大規模に展開する場合は、検索リクエストを抑えられるような構成を組むことが重要
株式会社ブレインパッド 106-0032 東京都港区六本木三丁目1番1号 六本木ティーキューブ TEL:03-6721-7002 FAX:03-6721-7010 www.brainpad.co.jp
[email protected]
本資料は、未刊行文書として日本及び各国の著作権法に基づき保護されております。本資料には、株式会社ブレインパッド所有の特定情報が含まれており、これら情報に基づく本資料の内容は、貴社以外の第三者に開示されること、また、本資料を評価する以外の目的で、その 一部または全文を複製、使用、公開することは、禁止されています。また、株式会社ブレインパッドによる書面での許可なく、それら情報の一部または全文を使用または公開することは、いかなる場合も禁じられております。
©BrainPad Inc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![株式会社ブレインパッド 106-0032 東京都港区六本木三丁目1番1号 六本木ティーキューブ TEL:03-6721-7002 FAX:03-6721-7010 www.brainpad.co.jp [email protected] 本資料は、未刊行文書として日本及び各国の著作権法に基づき保護されております。本資料には、株式会社ブレインパッド所有の特定情報が含まれており、これら情報に基づく本資料の内容は、貴社以外の第三者に開示されること、また、本資料を評価する以外の目的で、その 一部または全文を複製、使用、公開することは、禁止されています。また、株式会社ブレインパッドによる書面での許可なく、それら情報の一部または全文を使用または公開することは、いかなる場合も禁じられております。](https://files.speakerdeck.com/presentations/21af944f2ff542f0a6966fa486a5bf1c/slide_21.jpg){kind=link}