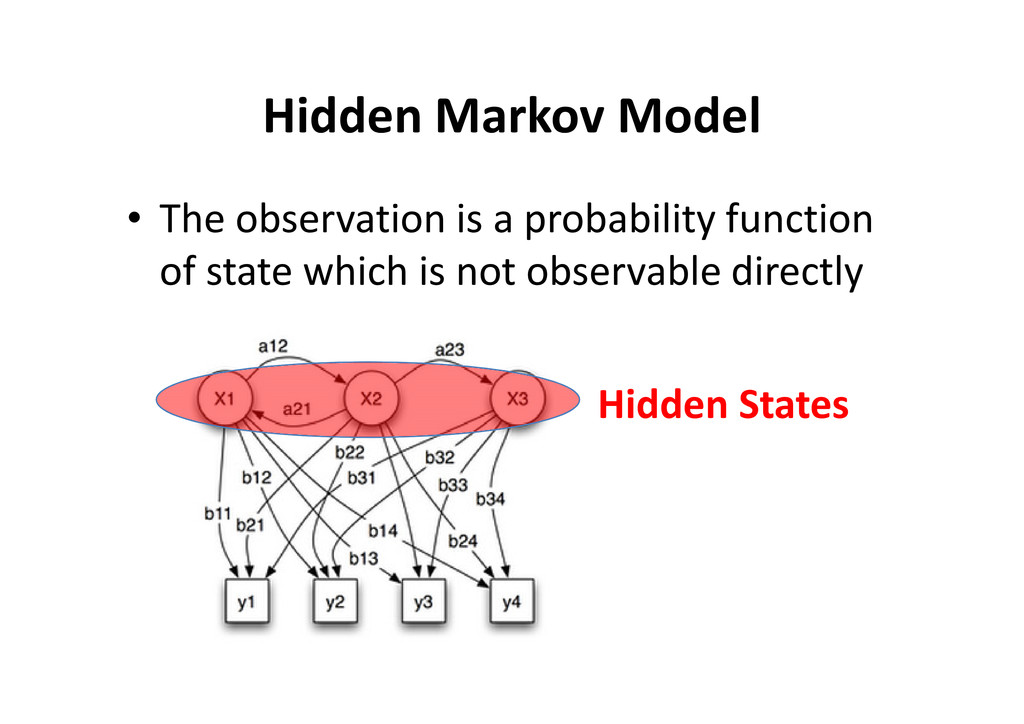
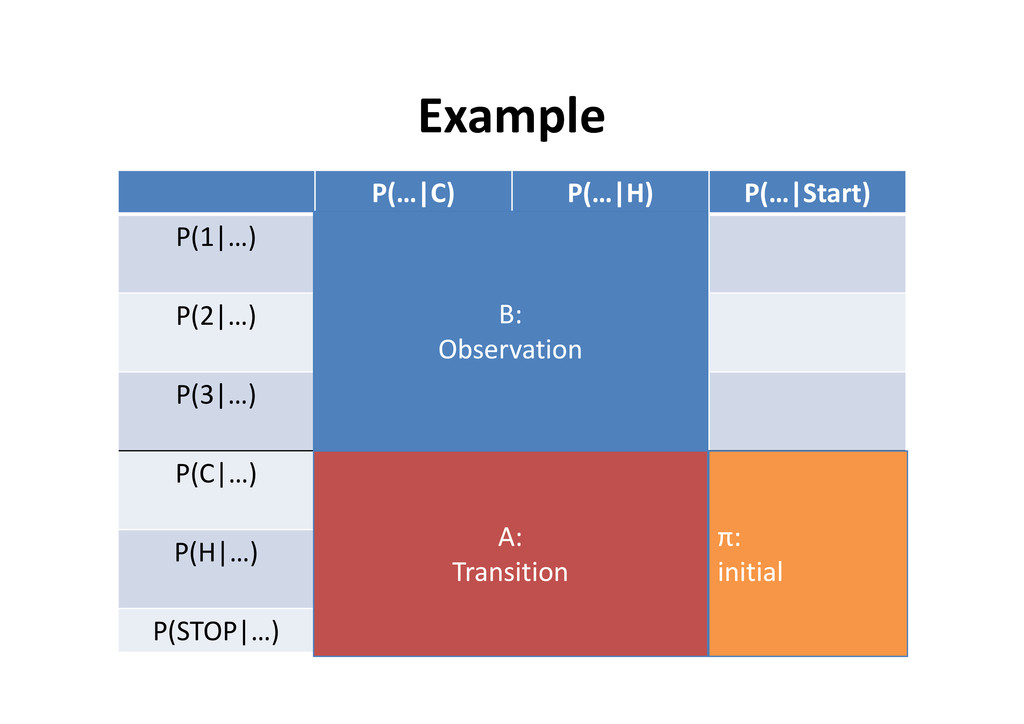
model • M, the number of distinct observation symbols • A, the state transition probability distribution • A, the state transition probability distribution • B, the observation symbol probability distribution in states • π, the initial state distribution λ: model
2T*NT ≈ (2T-1)NT muls + NT-1 adds (NT:狀態轉換 組合數) – For N=5 states, T=100 observations, there are – For N=5 states, T=100 observations, there are order 2*100*5100 ≈ 1072 computations!! • Forward Algorithm – Forward variable αt (i) (給定時間 t 時狀態為 Si 的 條件下,向前 向前 向前 向前局部觀察序列為O1 , O2 , O3 …, Ot 的 機率) 1 2 ( ) ( , ,..., , | ) t t t i a i P O O O q S λ = =
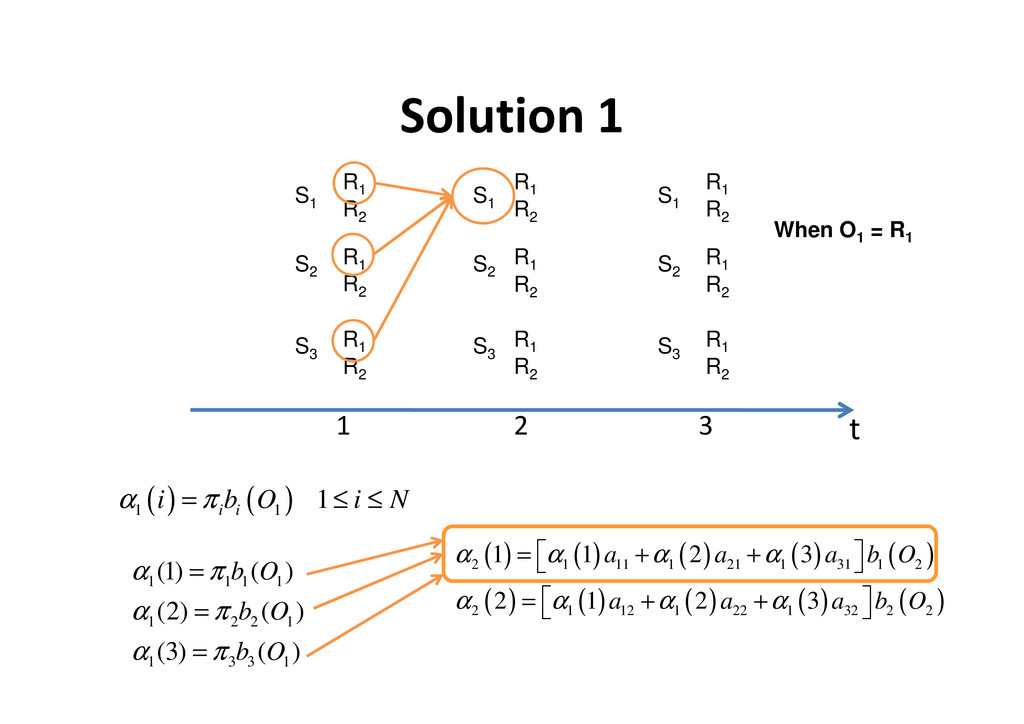
( ) 1 i i i b O i N α π = ≤ ≤ • Induction: • Termination: ( ) ( ) ( ) 1 1 1 N t t ij j t i j i a b O α α + + = = ∑ 1 1 1 t T j N ≤ ≤ − ≤ ≤ 1 ( | ) ( ) N T i P O i λ α = = ∑
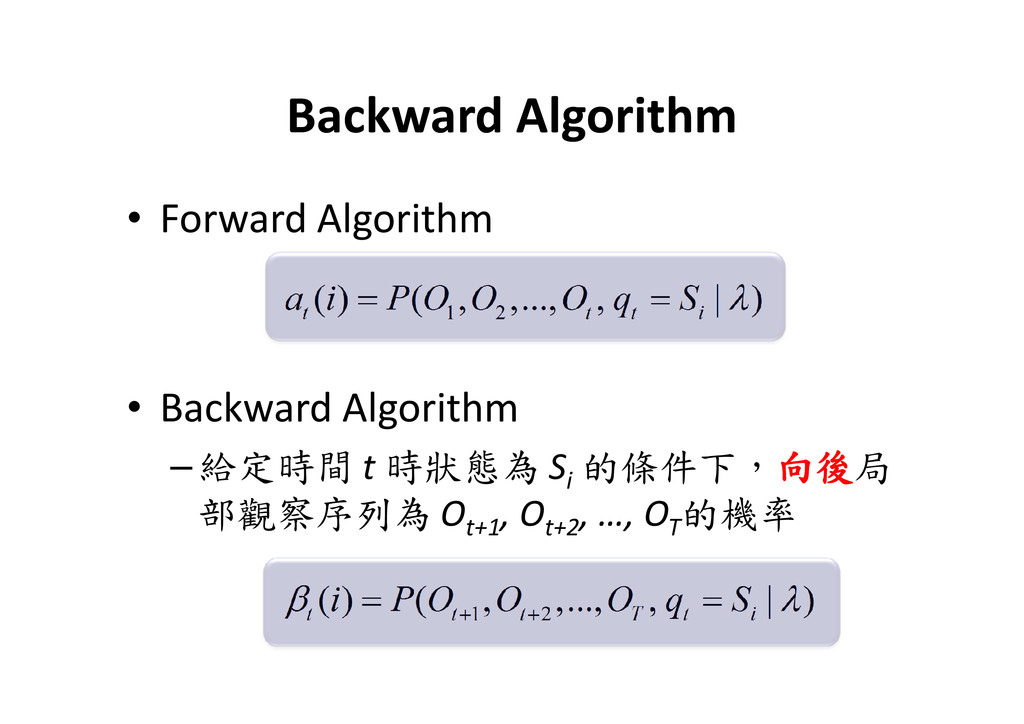
, ,..., , | ) t t t i a i P O O O q S λ = = • Backward Algorithm –給定時間 t 時狀態為 Si 的條件下,向後 向後 向後 向後局 部觀察序列為 Ot+1 , Ot+2 , …, OT 的機率 1 2 ( ) ( , ,..., , | ) t t t T t i i P O O O q S β λ + + = =
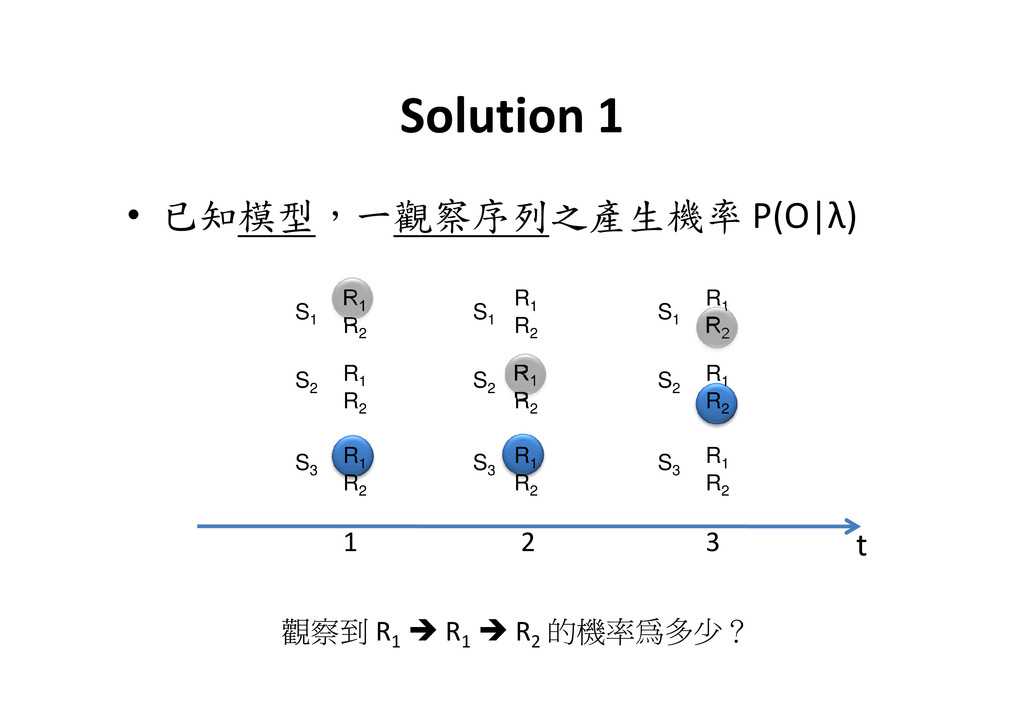
S1 S2 S3 R1 R2 R1 R R1 R2 R1 R2 R1 R R1 R2 R1 R2 R1 R When OT = R1 R2 R2 R2 ( ) ( ) ( ) ( ) ( ) ( ) 1 1 1 11 1 12 2 13 3 1 N T j j T T j T T T a b O j a b O a b O a b O β β − = = = + + ∑ t 1 2 3
individually most likely –γt (i) : the probability of being in state Si at time t, given the observation sequence O, time t, given the observation sequence O, and the model λ ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) 1 1 ( | , ) 1 t t t t t i t N t t i t t i N i i i i P O q S i P O P O i i q argmax i t T α β α β λ γ λ λ α β γ = ≤ ≤ = = = = = ≤ ≤ ∑
find the “single best state sequence” ( ) ( ) | , , | maxmize P Q O maxmize P Q O λ λ ≈ • A formal technique exists, based on dynamic programming methods, and is called the Viterbi algorithm ( ) ( ) | , , | maxmize P Q O maxmize P Q O λ λ ≈
Q = {q1 , q2 , …, qT }, for the given observation sequence O = {O1 , O2 , …, OT } • δt (i): the best score (highest prob.) along a single path, at time t, which accounts for the first t observations and end in state Si ( ) 1 2 1 1 2 1 2 , ,..., ... , ... t t t i t q q q i max P q q q S O O O δ λ − = =
1 the most probable path to a state does not sensibly exist –However we use the probability of being in that state given t = 1 and the observable state O1 ( ) ( ) ( ) 1 1 1 0 i i i b O i N i δ π ψ = ≤ ≤ =
– δt (i) : The most probable path to the state X at time t –This path to X will have to pass through one –This path to X will have to pass through one of the states A, B or C at time (t-1) Most probable path to A: 1 ( ) t A δ − AX a ( ) X t b O
( ) ( ) 1 1 t t ij j t i N j max i a b O j argmax i a δ δ ψ δ − ≤ ≤ = = 2 1 t T j N ≤ ≤ ≤ ≤ • Termination ( ) ( ) 1 1 t t ij i N j argmax i a ψ δ − ≤ ≤ = 1 j N ≤ ≤ ( ) ( ) * 1 * 1 T i N T T i N P max i q argmax i δ δ ≤ ≤ ≤ ≤ = =
* 1 1 * * ( ) 1, 2, ...,1 ( ) t t t q q t T T q q argmax i a ψ ψ δ + + = = − − = = ( ) * * * 1 1 1 * * 1 2 2 ( ) ... ... ( ) T T T T T iq i N q q argmax i a q q ψ δ ψ − − ≤ ≤ = = =
觀察到的現象 what 模型 maximize P(觀察到的現象| 模型) 模型) • There is no known analytic solution. We can choose λ = (A, B, π) such that P(O| λ) is locally maximized using an iterative procedure
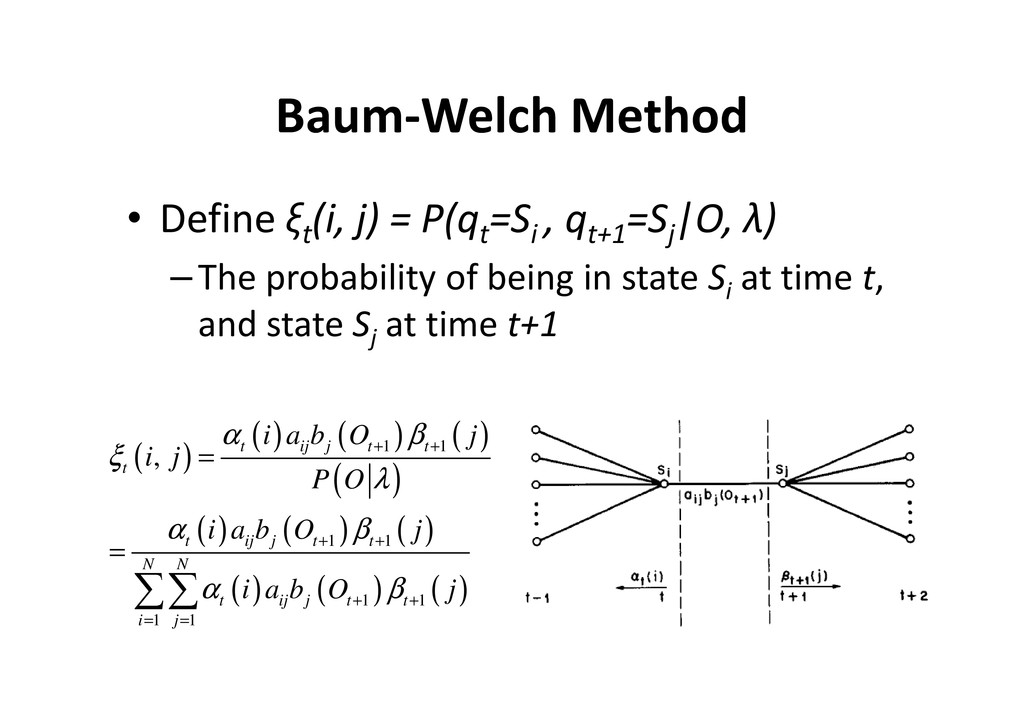
, qt+1 =Sj |O, λ) –The probability of being in state Si at time t, and state Sj at time t+1 ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) 1 1 1 1 1 1 1 1 , t ij j t t t t ij j t t N N t ij j t t i j i a b O j i j P O i a b O j i a b O j α β ξ λ α β α β + + + + + + = = = = ∑∑
in state Si at time t, given the observation sequence O, and the model λ ( ) ( ) ( ) ( ) ( ) ( ) t t t t i i i i i α β α β γ = = • Relate γt (i) to ξt (i, j) ( ) ( ) ( ) ( ) 1 t N t t i i P O i i γ λ α β = = = ∑ ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) 1 1 1 1 1 1 1 1 , t ij j t t t t ij j t t N N t ij j t t i j i a b O j i j P O i a b O j i a b O j α β ξ λ α β α β + + + + + + = = = = ∑∑ ( ) ( ) 1 , N t t j i i j γ ξ = = ∑
Si is visited ( ) 1 T t i γ − = ∑ Expected number of transitions from Si • Similarly, the expected number of transitions from state Si to state Sj ( ) 1 t t= ∑ ( ) 1 1 , T t t i j ξ − = = ∑ Expected number of transitions from Si to Sj
1 1 ( ) ( , ) i T i i j π γ ξ − = ∑ 1 1 1 1 . . 1 ( , ) ( ) ( ) ( ) ( ) t k t i j t ij T i t t T t t s t O v j T t t i j expected number of transitions fromstate S toS a expected number of transitions fromstate S i j expected number of timesinstate j and observing symb b k j ξ γ γ γ = − = = = = = = = = ∑ ∑ ∑ ∑ k ol v expected number of timesinstate j
in place of λ and repeat • Iteratively use λ in place of λ and repeat the re-estimation, we then can improve P(O| λ) until some limiting point is reached
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}