etc) started as a bookstore • Today, they sell just about everything - bicycles, appliances, computers, TVs, etc. • In some cities in America, they even do home grocery delivery • No longer as much of a physical goods company - becoming fixated and surrounded by software • Pioneering the eBook revolution with Kindle • EC2 is running a huge percentage of the public internet Friday, November 16, 12
company to deliver DVDs to the home... • But as they’ve grown, business has shifted to an online streaming service • They are now rolling out rapidly in many countries including Ireland, the UK, Canada and the Nordics • No need for physical inventory or postal distribution ... just servers and digital copies Friday, November 16, 12
– be it text files, user form input, emails, etc • But what does software excrete? • More Data, of course... • This data gets bigger and bigger • The solutions become narrower for storing & processing this data • Data Fertilizes Software, in an endless cycle... Friday, November 16, 12
Big Data • Data Warehouse Software • Operational Databases • Old style systems being upgraded to scale storage + processing • NoSQL - Cassandra, MongoDB, etc • Platforms • Hadoop Friday, November 16, 12
distracted by all of these solutions • Keep it simple • Use tools you (and your team) can understand • Use tools and techniques that can scale • Try not to reinvent the wheel Friday, November 16, 12
• Break it into smaller pieces • You can’t fit a whole pig into your mouth... • ... slice it into small parts that you can consume. Friday, November 16, 12
gigabytes, terabytes, petabytes or exabytes • An ideal big data system scales up and down around various data sizes – while providing a uniform view • Major concerns • Can I read & write this data efficiently at different scale? • Can I run calculations on large portions of this data? Large Dataset Primary Key as “username” Friday, November 16, 12
System (which inspired Hadoop’s HDFS) and MongoDB’s Sharding handle the scale problem by chunking • Break up pieces of data into smaller chunks, spread across many data nodes • Each data node contains many chunks • If a chunk gets too large or a node overloaded, data can be rebalanced Large Dataset Primary Key as “username” ... Friday, November 16, 12
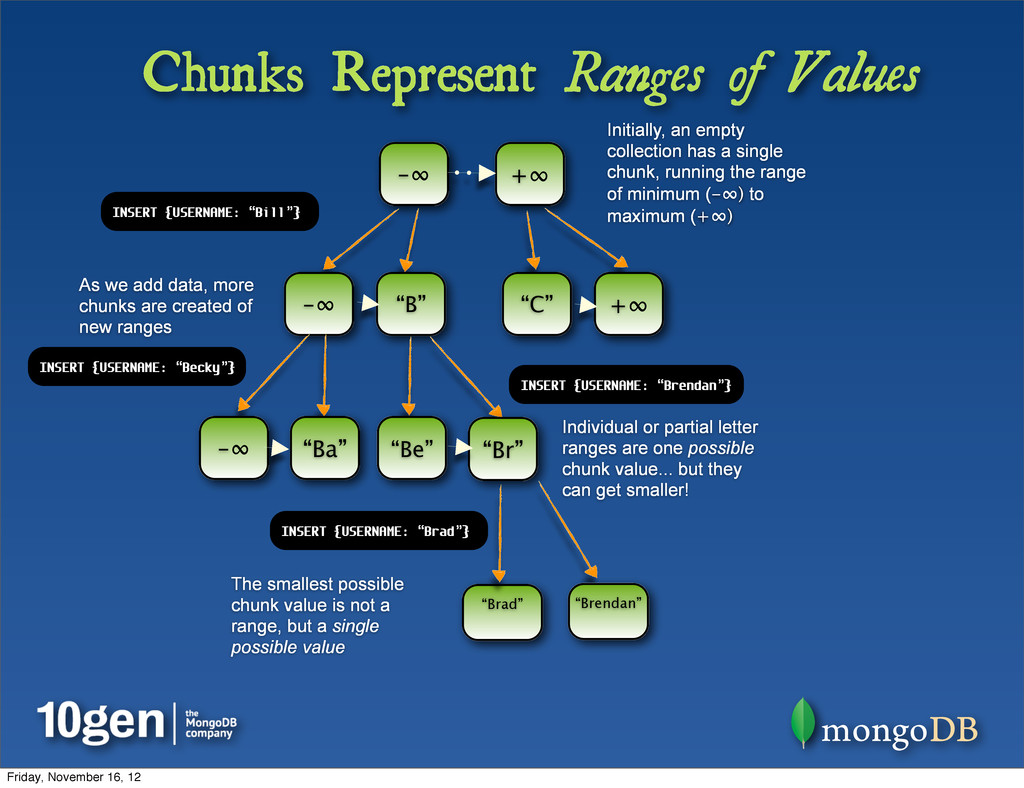
empty collection has a single chunk, running the range of minimum (-∞) to maximum (+∞) As we add data, more chunks are created of new ranges INSERT {USERNAME: “Bill”} -∞ “B” “C” +∞ Individual or partial letter ranges are one possible chunk value... but they can get smaller! “Ba” -∞ “Br” “Be” “Brendan” “Brad” The smallest possible chunk value is not a range, but a single possible value INSERT {USERNAME: “Becky”} INSERT {USERNAME: “Brendan”} INSERT {USERNAME: “Brad”} Friday, November 16, 12
look at our dataset split into chunks by letter • Each chunk is represented by a single letter marking its contents • You could think of “B” as really being “Ba” →”Bz” Large Dataset Primary Key as “username” a b c d e f g h s t u v w x y z ... Friday, November 16, 12
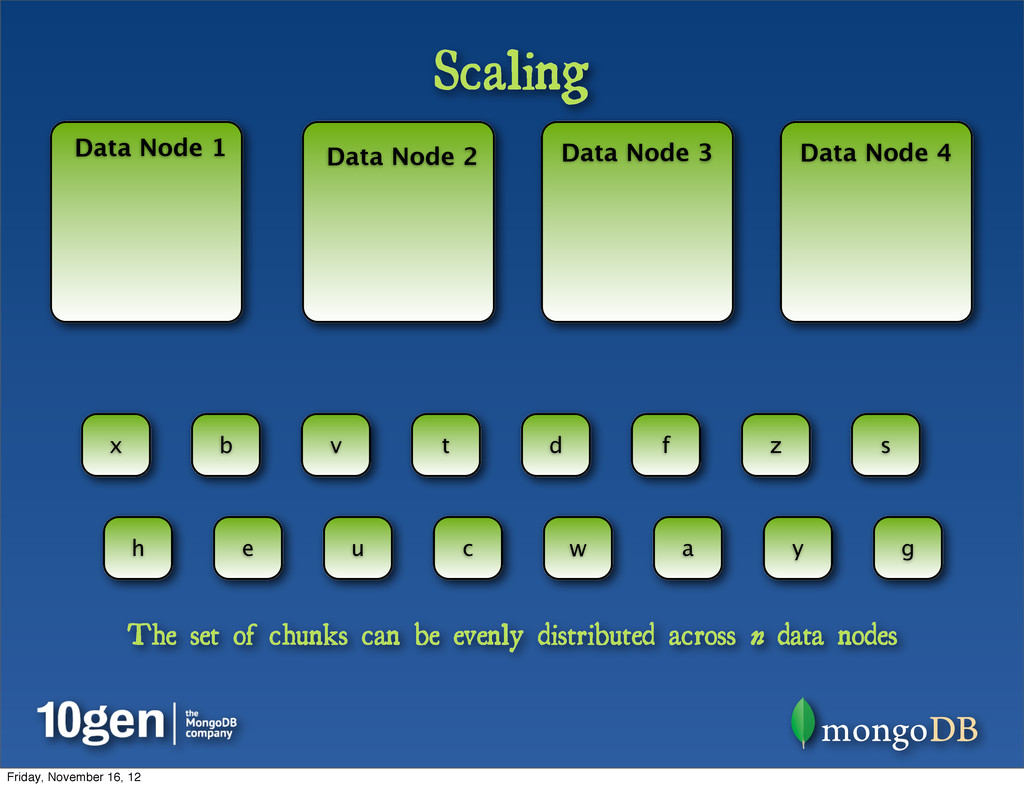
Glance Data Node 1 25% of chunks Data Node 2 25% of chunks Data Node 3 25% of chunks Data Node 4 25% of chunks a b c d e f g h s t u v w x y z Representing data as chunks allows many levels of scale across n data nodes Friday, November 16, 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z The goal is equilibrium - an equal distribution. As nodes are added (or even removed) chunks can be redistributed for balance. Friday, November 16, 12
answer to calculating big data is much the same as storing it • We need to break our data into bite sized pieces • Build functions which can be composed together repeatedly on partitions of our data • Process portions of the data across multiple calculation nodes • Aggregate the results into a final set of results Friday, November 16, 12
are not chunks – rather, the individual data points that make up each chunk • Chunks make up a useful data transfer units for processing as well • Transfer Chunks as “Input Splits” to calculation nodes, allowing for scalable parallel processing Friday, November 16, 12
techniques is MapReduce • Based on a Google Whitepaper, works with two primary functions – map and reduce – to calculate against large datasets Friday, November 16, 12
HDFS storage component, Hadoop is built around MapReduce for calculation • MongoDB can be integrated to MapReduce data on Hadoop • No HDFS storage needed - data moves directly between MongoDB and Hadoop’s MapReduce engine Friday, November 16, 12
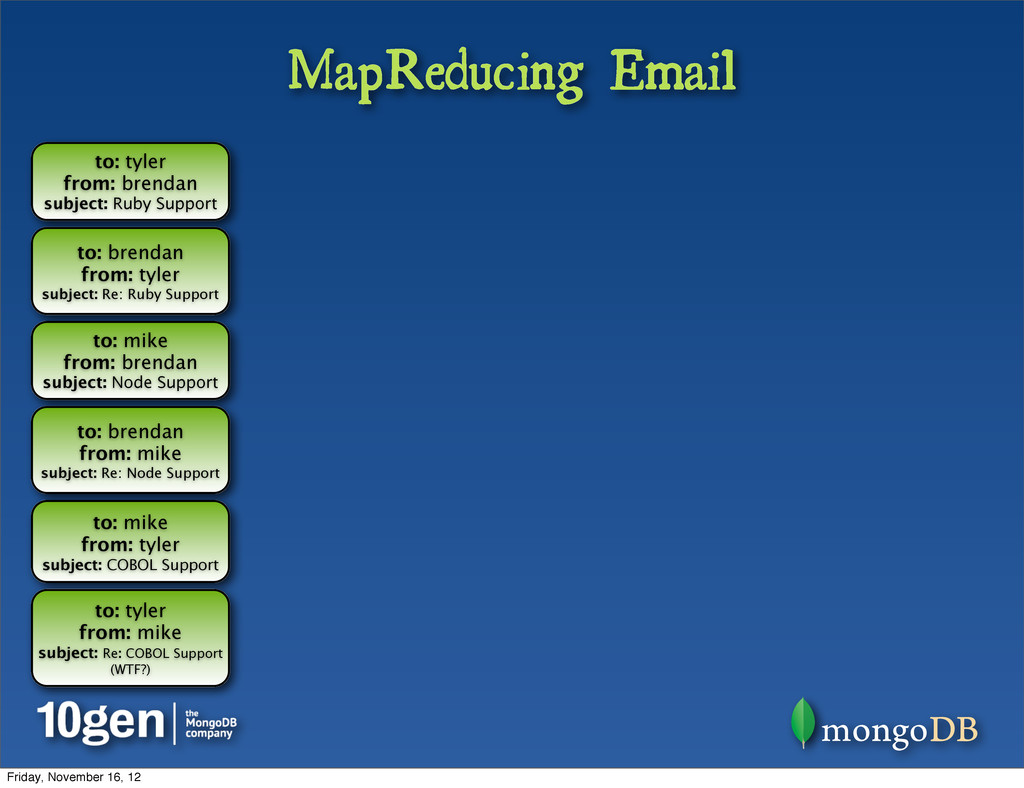
of phases, the primary of which are • Map • Shuffle • Reduce • Let’s look at a typical MapReduce job • Email records • Count # of times a particular user has received email Friday, November 16, 12
brendan from: tyler subject: Re: Ruby Support to: mike from: brendan subject: Node Support to: brendan from: mike subject: Re: Node Support to: mike from: tyler subject: COBOL Support to: tyler from: mike subject: Re: COBOL Support (WTF?) Friday, November 16, 12
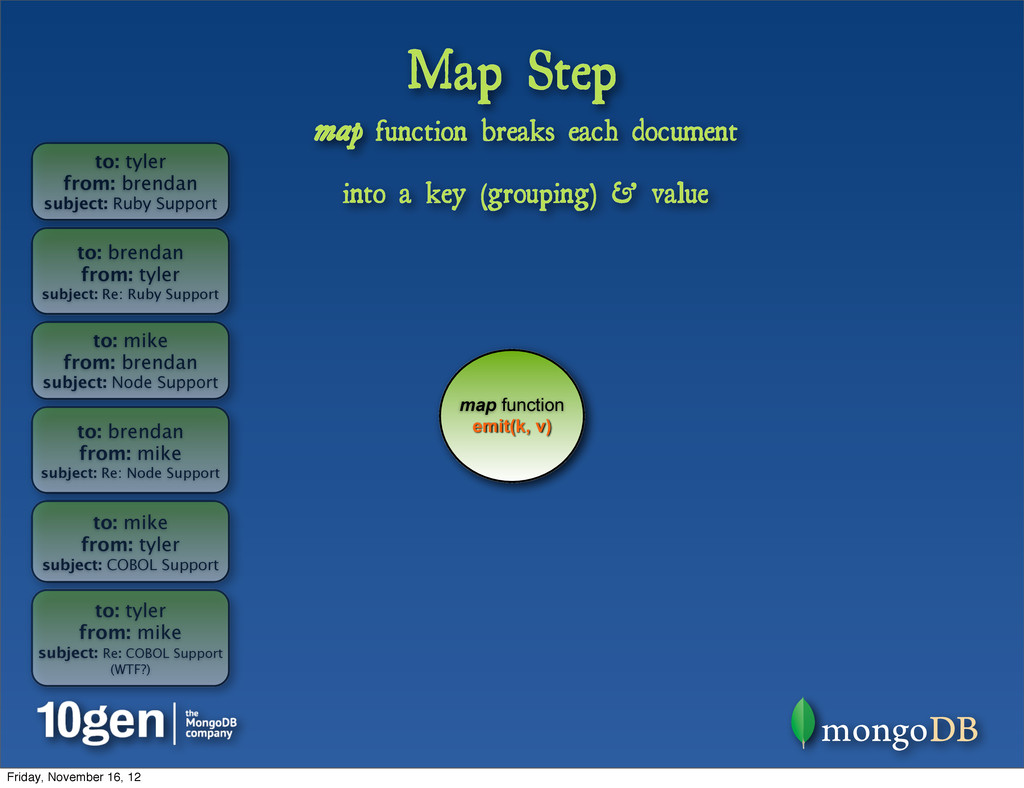
brendan from: tyler subject: Re: Ruby Support to: mike from: brendan subject: Node Support to: brendan from: mike subject: Re: Node Support to: mike from: tyler subject: COBOL Support to: tyler from: mike subject: Re: COBOL Support (WTF?) key: tyler value: {count: 1} key: brendan value: {count: 1} key: mike value: {count: 1} key: brendan value: {count: 1} key: mike value: {count: 1} key: tyler value: {count: 1} map function emit(k, v) map function breaks each document into a key (grouping) & value Friday, November 16, 12
{count: 1} key: mike value: {count: 1} key: brendan value: {count: 1} key: mike value: {count: 1} key: tyler value: {count: 1} Group like keys together, creating an array of their distinct values (Automatically done by M/R frameworks) Friday, November 16, 12
mike values: [{count: 1}, {count: 1}] key: tyler values: [{count: 1}, {count: 1}] Group like keys together, creating an array of their distinct values (Automatically done by M/R frameworks) Friday, November 16, 12
mike values: [{count: 1}, {count: 1}] key: tyler values: [{count: 1}, {count: 1}] For each key reduce function flattens the list of values to a single result reduce function aggregate values return (result) key: tyler value: {count: 2} key: mike value: {count: 2} key: brendan value: {count: 2} Friday, November 16, 12
for calculating and processing our large datasets (from gigabytes through exabytes and beyond) • MapReduce is supported in many places including MongoDB & Hadoop • We have effective answers for both of our concerns. • Can I read & write this data efficiently at different scale? • Can I run calculations on large portions of this data? • Can I run calculations on large portions of this data? Friday, November 16, 12
- fundamentally, MapReduce is a batch process • Batch systems like Hadoop give us a “Catch 22” • You can get answers to questions from Petabytes of Data • But you can’t guarantee you’ll get them quickly • In some ways, this is a step backwards in our industry • Business Stakeholders tend to want answers now • We must evolve Friday, November 16, 12
moving rapidly away from slow, batch based processing solutions • Google moved forward from Batch into more Realtime over last few years • Hadoop is replacing “MapReduce as Assembly Language” with more flexible resource management in YARN • Now MapReduce is just a feature implemented on top of YARN • Build anything we want • Newer systems like Spark & Storm provide platforms for realtime processes Friday, November 16, 12
• All that software is leaving behind an awful lot of data • We must be careful not to “step in it” • More Data Means More Software Means More Data Means... • Practical Solutions for Processing & Storing Data will save us • We as Data Scientists & Technologists must always evolve our strategies, thinking and tools Friday, November 16, 12
![Brendan McAdams 10gen, Inc. [email protected] @rit A Modest Proposal for](https://files.speakerdeck.com/presentations/31af7dc0124f0130f91e12313d142636/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Group/Shuffle Step key: brendan values: [{count: 1}, {count: 1}] key:](https://files.speakerdeck.com/presentations/31af7dc0124f0130f91e12313d142636/slide_33.jpg){kind=link}
![Reduce Step key: brendan values: [{count: 1}, {count: 1}] key:](https://files.speakerdeck.com/presentations/31af7dc0124f0130f91e12313d142636/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Download the Hadoop Connector] http://github.com/mongodb/mongo-hadoop [Docs] http://api.mongodb.org/hadoop/ ¿QUESTIONS? *Contact Me*](https://files.speakerdeck.com/presentations/31af7dc0124f0130f91e12313d142636/slide_39.jpg){kind=link}