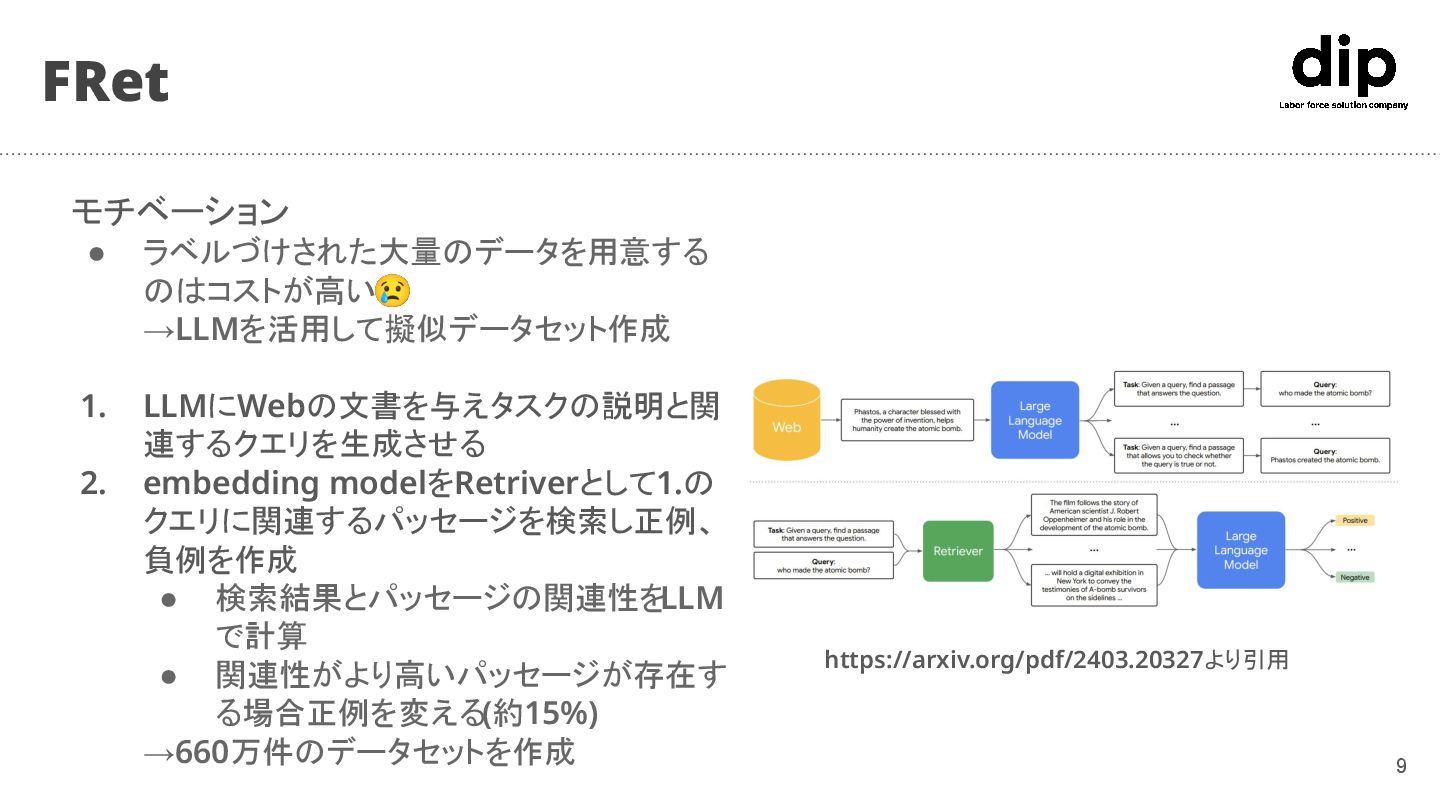
8 • LLMで合成データを作成(FRet)、Transfromer言語モデルを Pre-finetuningとfine-tuningで学習
◦ Pre-finetuning: 様々な形式の教師なしのテキストペアを Contrastive Learningで学習
▪ query側テキストの先頭には”question answering“や”search result”などの 識別子がデータセットに基づいて付与される
◦ fine-tuning:後述のFRetデータセットと学術的データセットを混ぜて教師あり 学習
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
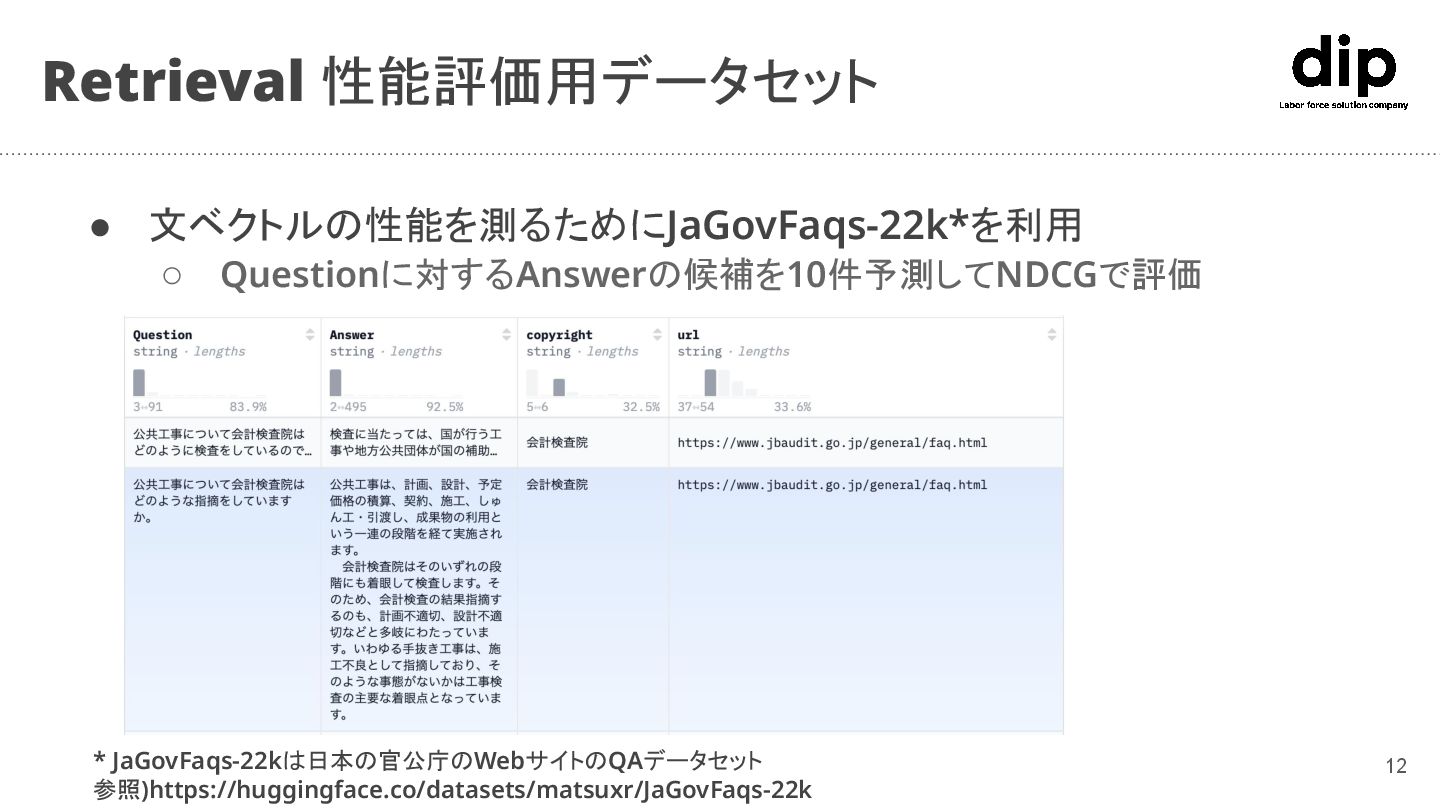{kind=link}
{kind=link}
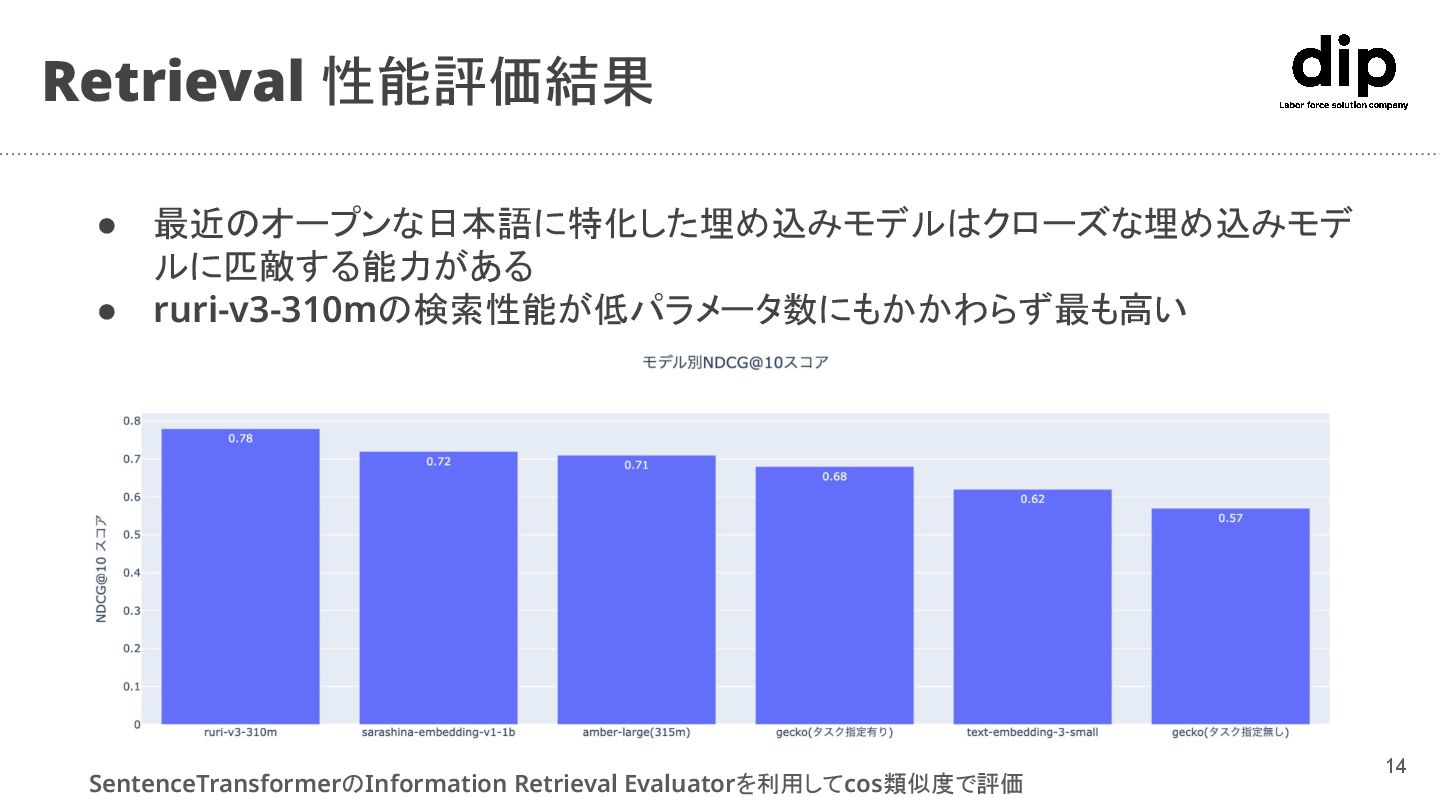{kind=link}