Samuel Hess and Gregory Ditzler The International Joint Conference on Neural Networks (IJCNN) 2021 Department of Electrical & Computer Engineering University of Arizona Tucson, AZ 85721 [email protected][email protected]
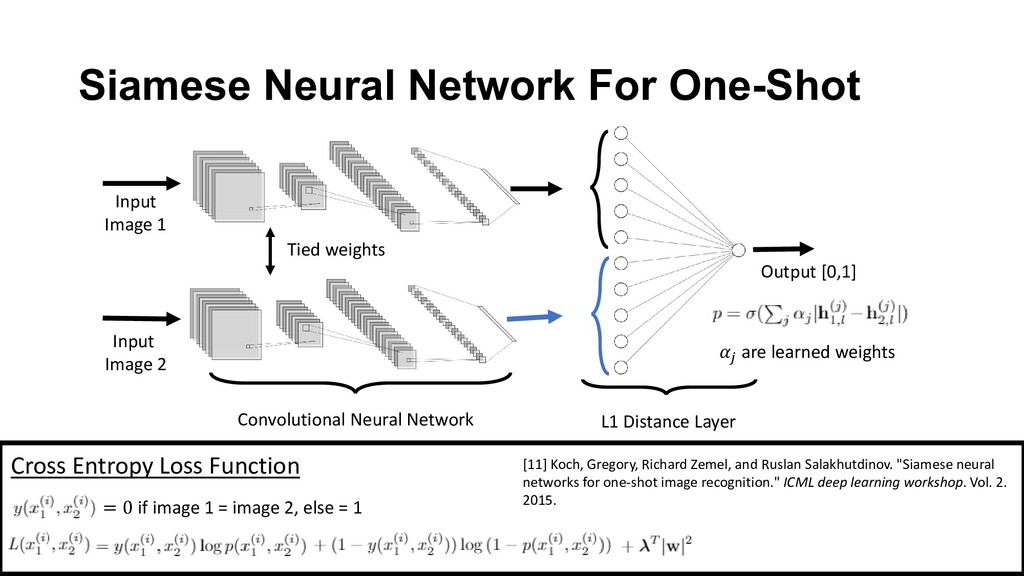
well when trained over an extensive set of data but struggle with learning from a small sets of data • Few-shot neural networks is an active area of research around a small number of samples per class • Few-shot benchmark datasets are trained 24,000 – 48,000 samples. • They are not truly low sample training they are low sample per class training and low sample testing • OrderNet is designed to help bridge the gap and be truly low sample training • Catch: Have to be able to naturally order your training dataset
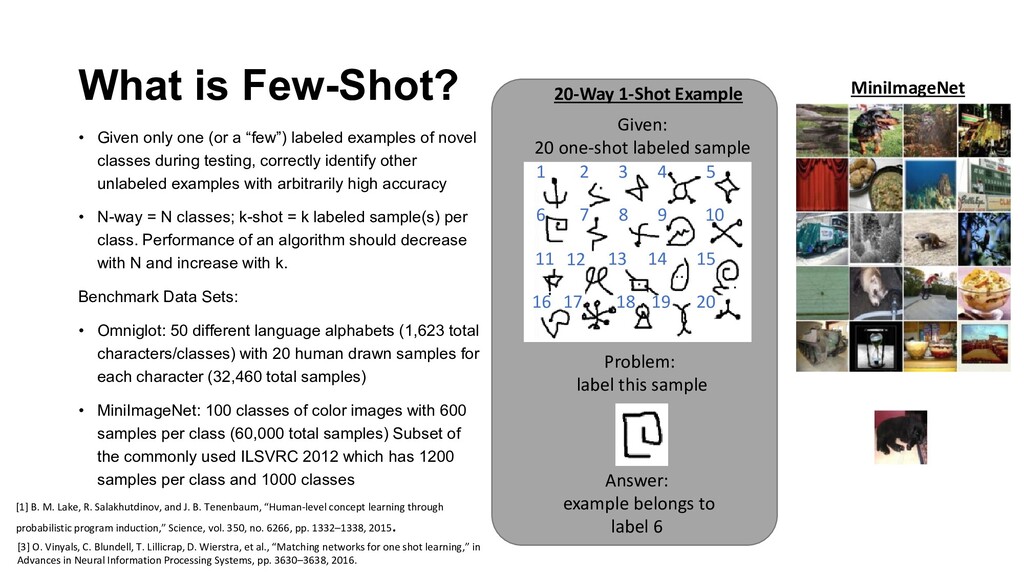
labeled examples of novel classes during testing, correctly identify other unlabeled examples with arbitrarily high accuracy • N-way = N classes; k-shot = k labeled sample(s) per class. Performance of an algorithm should decrease with N and increase with k. Benchmark Data Sets: • Omniglot: 50 different language alphabets (1,623 total characters/classes) with 20 human drawn samples for each character (32,460 total samples) • MiniImageNet: 100 classes of color images with 600 samples per class (60,000 total samples) Subset of the commonly used ILSVRC 2012 which has 1200 samples per class and 1000 classes Given: 20 one-shot labeled sample Problem: label this sample 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Answer: example belongs to label 6 20-Way 1-Shot Example MiniImageNet [1] B. M. Lake, R. Salakhutdinov, and J. B. Tenenbaum, “Human-level concept learning through probabilistic program induction,” Science, vol. 350, no. 6266, pp. 1332–1338, 2015. [3] O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra, et al., “Matching networks for one shot learning,” in Advances in Neural Information Processing Systems, pp. 3630–3638, 2016.
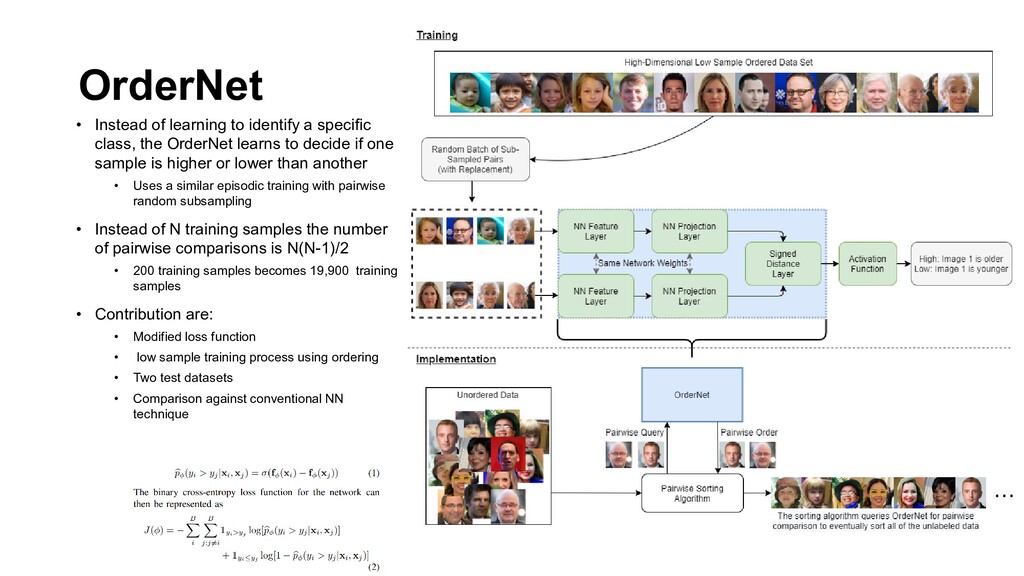
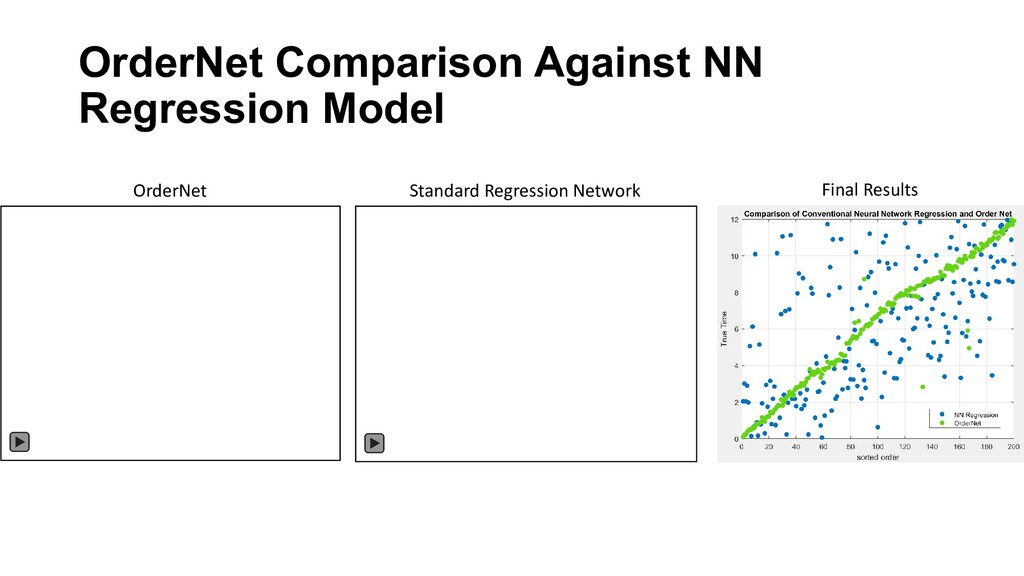
the OrderNet learns to decide if one sample is higher or lower than another • Uses a similar episodic training with pairwise random subsampling • Instead of N training samples the number of pairwise comparisons is N(N-1)/2 • 200 training samples becomes 19,900 training samples • Contribution are: • Modified loss function • low sample training process using ordering • Two test datasets • Comparison against conventional NN technique
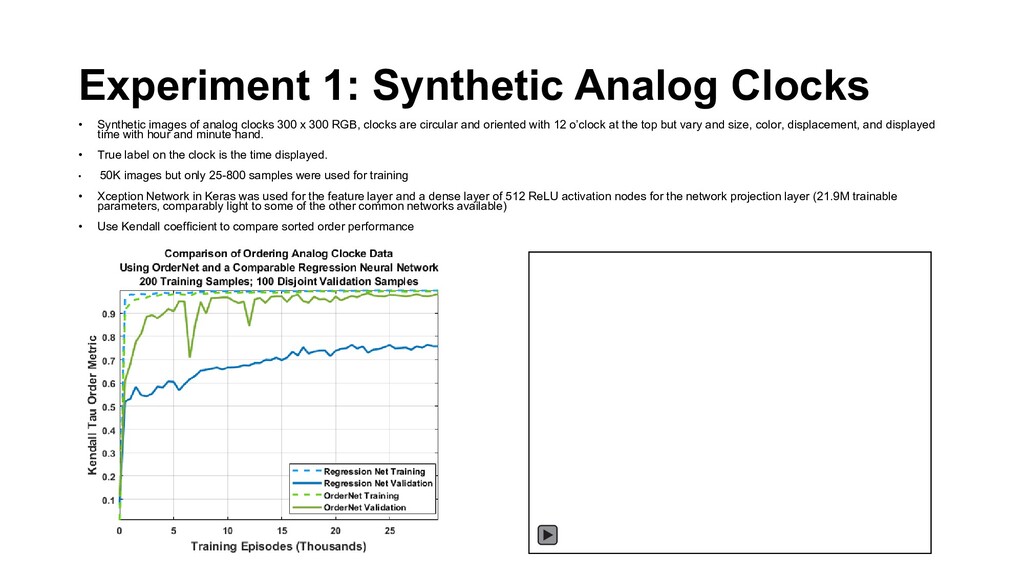
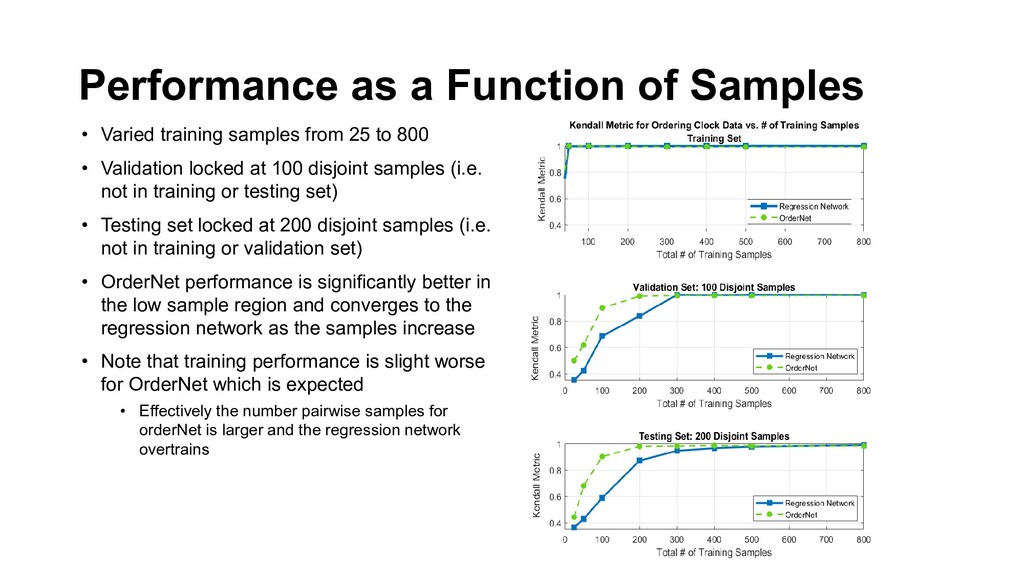
clocks 300 x 300 RGB, clocks are circular and oriented with 12 o’clock at the top but vary and size, color, displacement, and displayed time with hour and minute hand. • True label on the clock is the time displayed. • 50K images but only 25-800 samples were used for training • Xception Network in Keras was used for the feature layer and a dense layer of 512 ReLU activation nodes for the network projection layer (21.9M trainable parameters, comparably light to some of the other common networks available) • Use Kendall coefficient to compare sorted order performance
from 25 to 800 • Validation locked at 100 disjoint samples (i.e. not in training or testing set) • Testing set locked at 200 disjoint samples (i.e. not in training or validation set) • OrderNet performance is significantly better in the low sample region and converges to the regression network as the samples increase • Note that training performance is slight worse for OrderNet which is expected • Effectively the number pairwise samples for orderNet is larger and the regression network overtrains
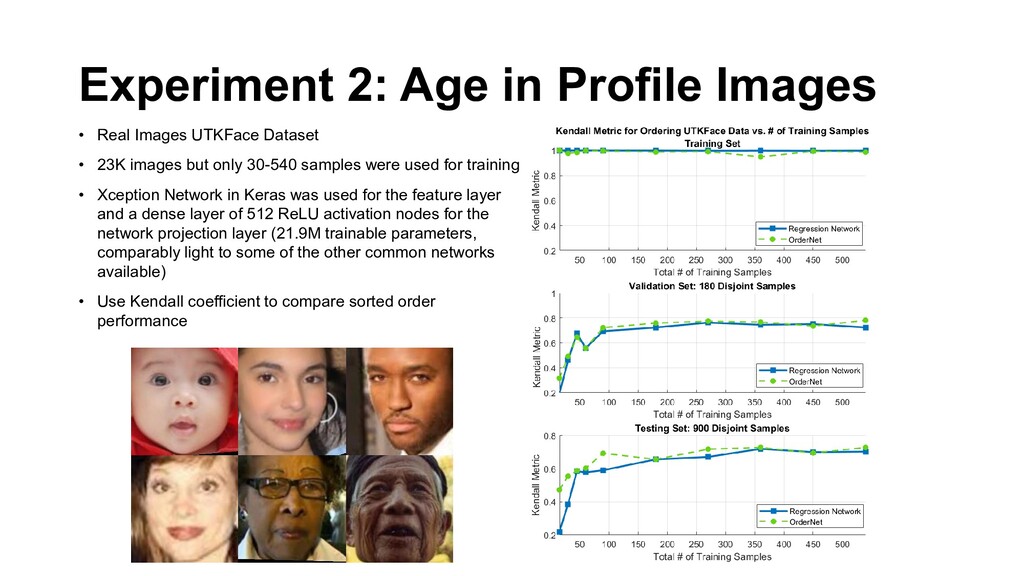
Dataset • 23K images but only 30-540 samples were used for training • Xception Network in Keras was used for the feature layer and a dense layer of 512 ReLU activation nodes for the network projection layer (21.9M trainable parameters, comparably light to some of the other common networks available) • Use Kendall coefficient to compare sorted order performance
training if the training data can be organized into some natural order 2. In the synthetic dataset of analog clocks orderNet performance at 100 samples is similar to regression network at 300 samples 3. If the training dataset is naturally ordered, OrderNet can work on unlabeled data 4. The performance on the age in profile images is better with OrderNet but only marginally so. There are more challenges to work out with this dataset • Dataset is significantly more complicated: age is a tough feature • Dataset is discretized to 90 samples, way lower than the 720 samples in the analog clock case • this causes a reduction in pairwise sampling • Performance of both networks seem to converge quickly around 0.64, there might be fundamental issues with classification accuracy on age in the first place
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}