サービス信頼性向上の為のボトルネックは、サービスのアーキテクチャ自体の見直しなくしては解消できないことがあります。
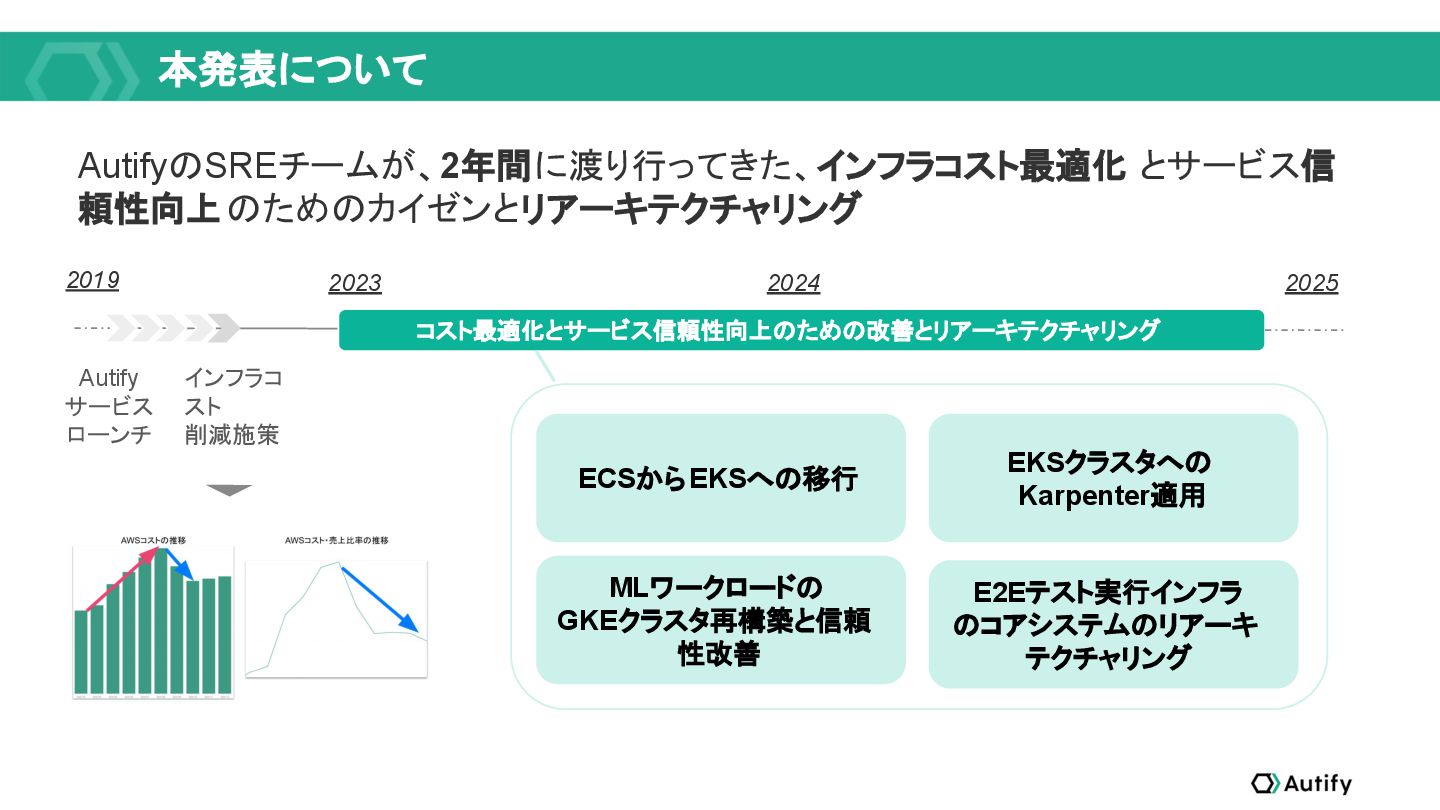
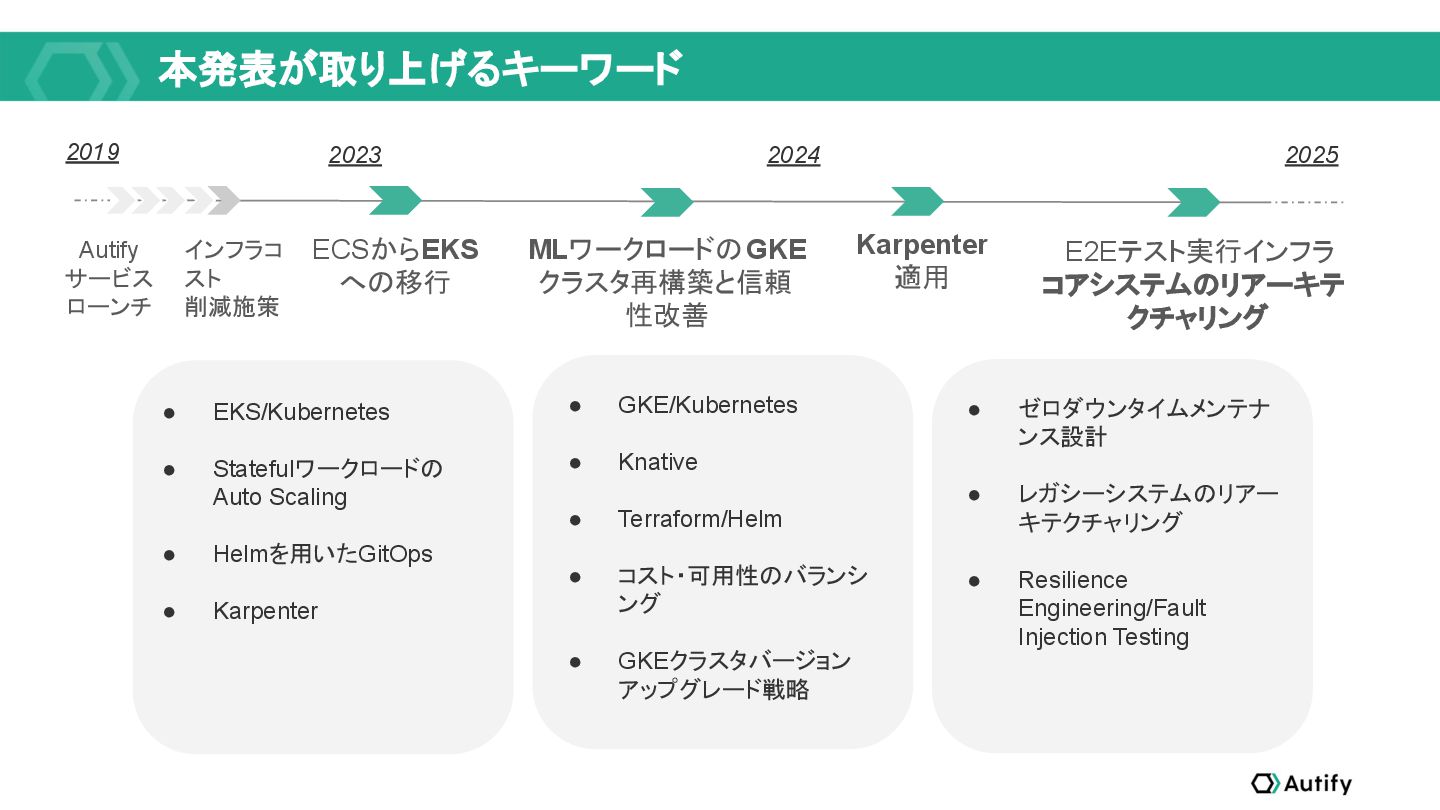
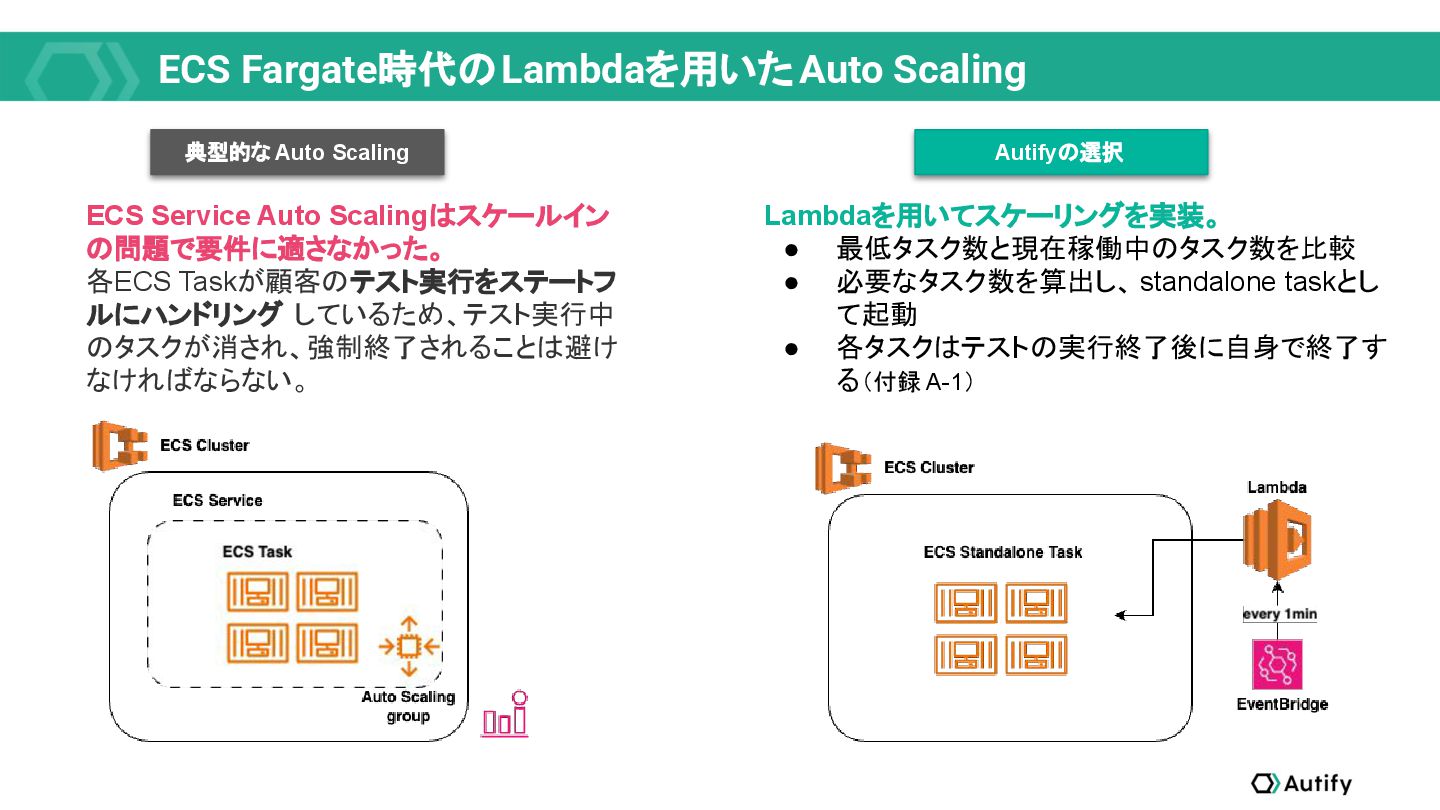
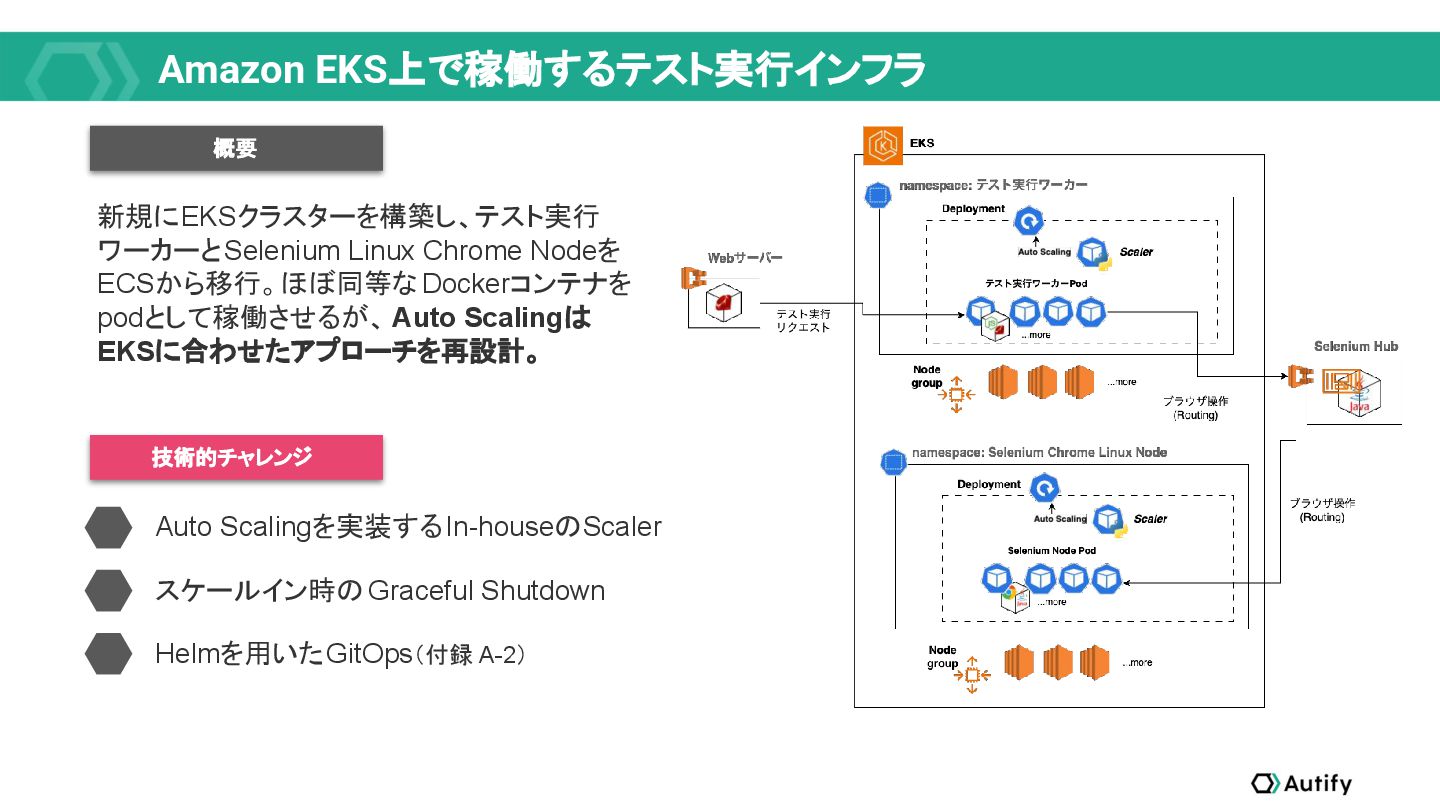
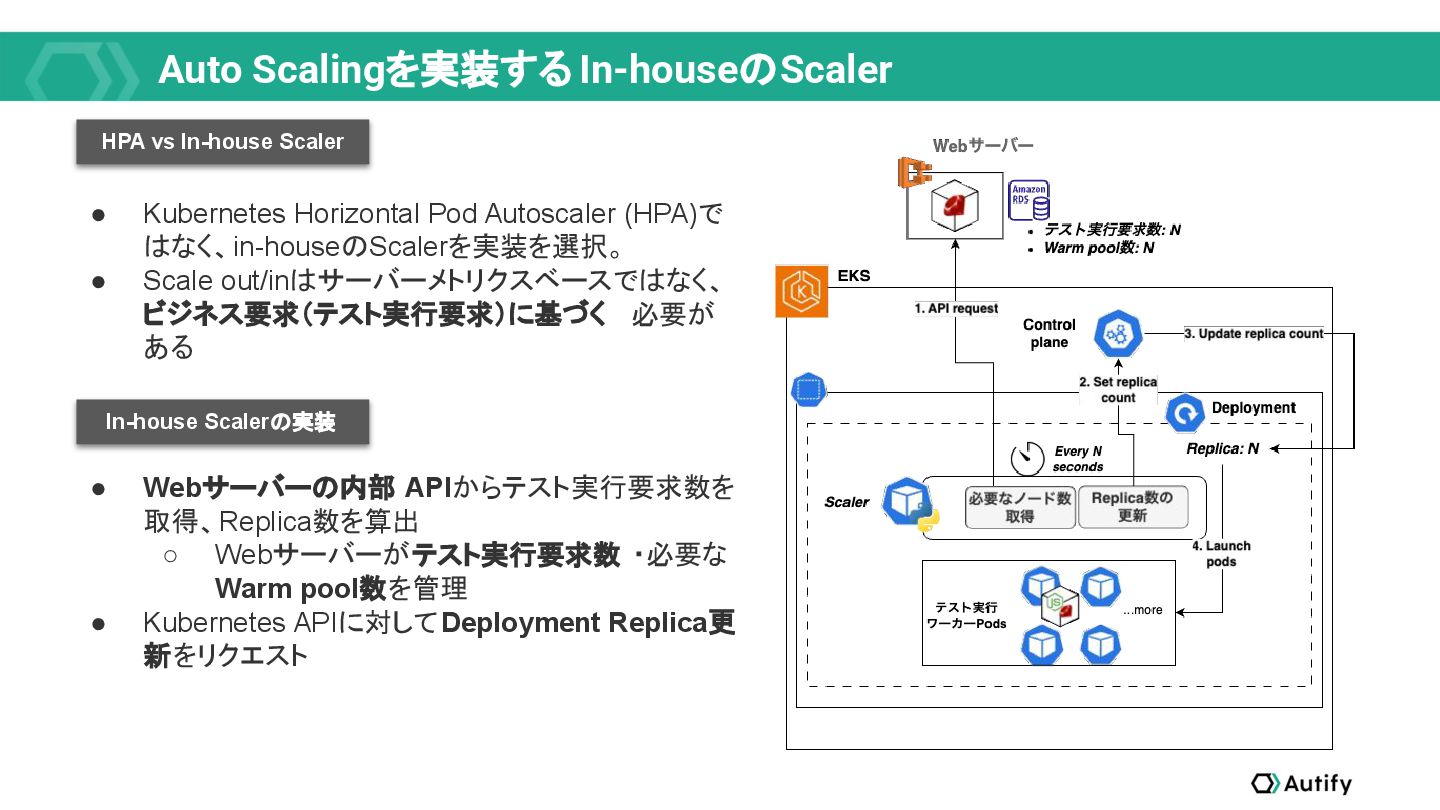
品質保証エンジニアリングプラットフォームAutifyのSREチームは、プロダクトのコアに手を入れなくても最適化できるコスト効率化を終えた後、コスト効率化・潜在的なセキュリティ課題解消のため、Kubernetesへの移行、Karpenterの導入、MLワークロードが稼働するGKEクラスターの運用改善、そして、SPOFを解消するリアーキテクチャリングに取り組みました。
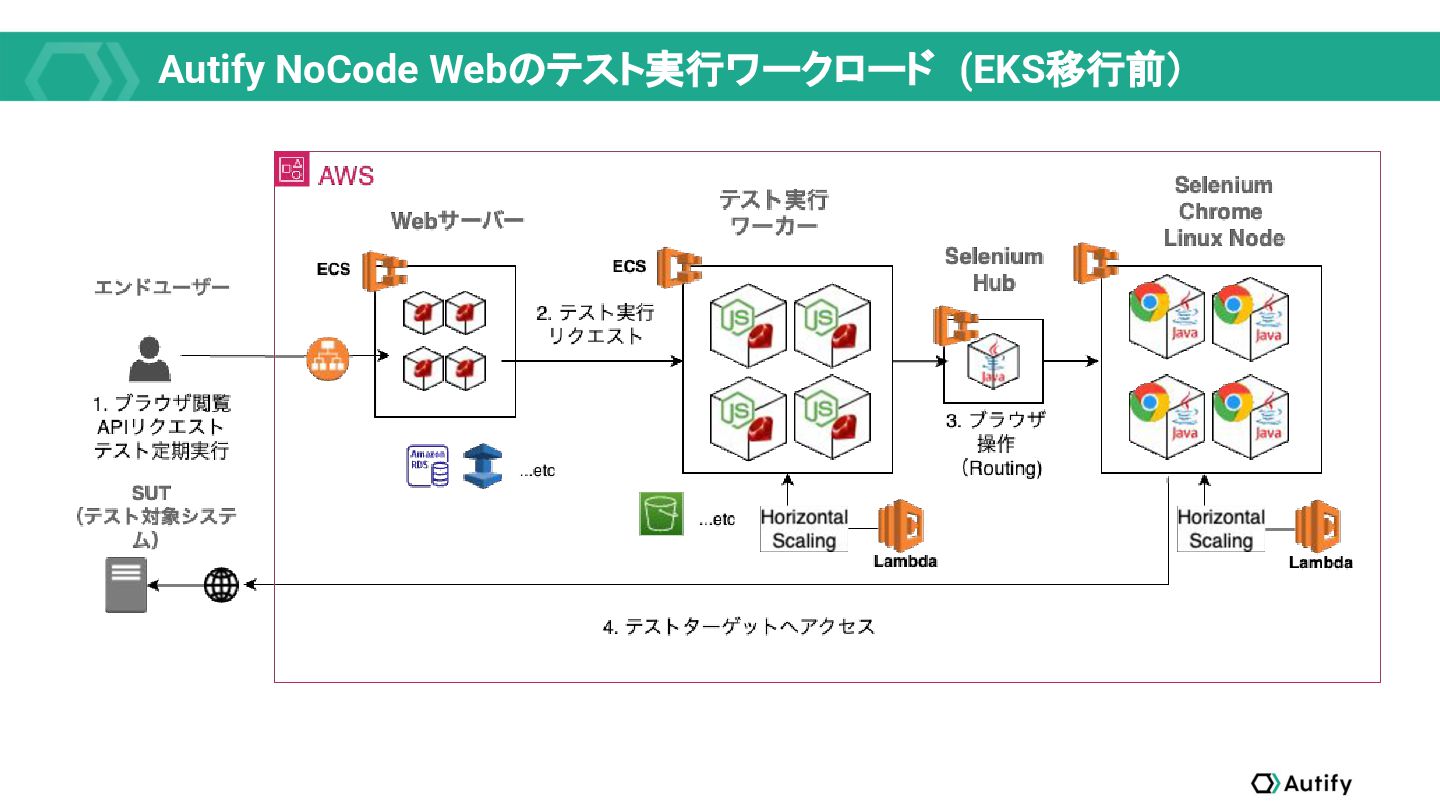
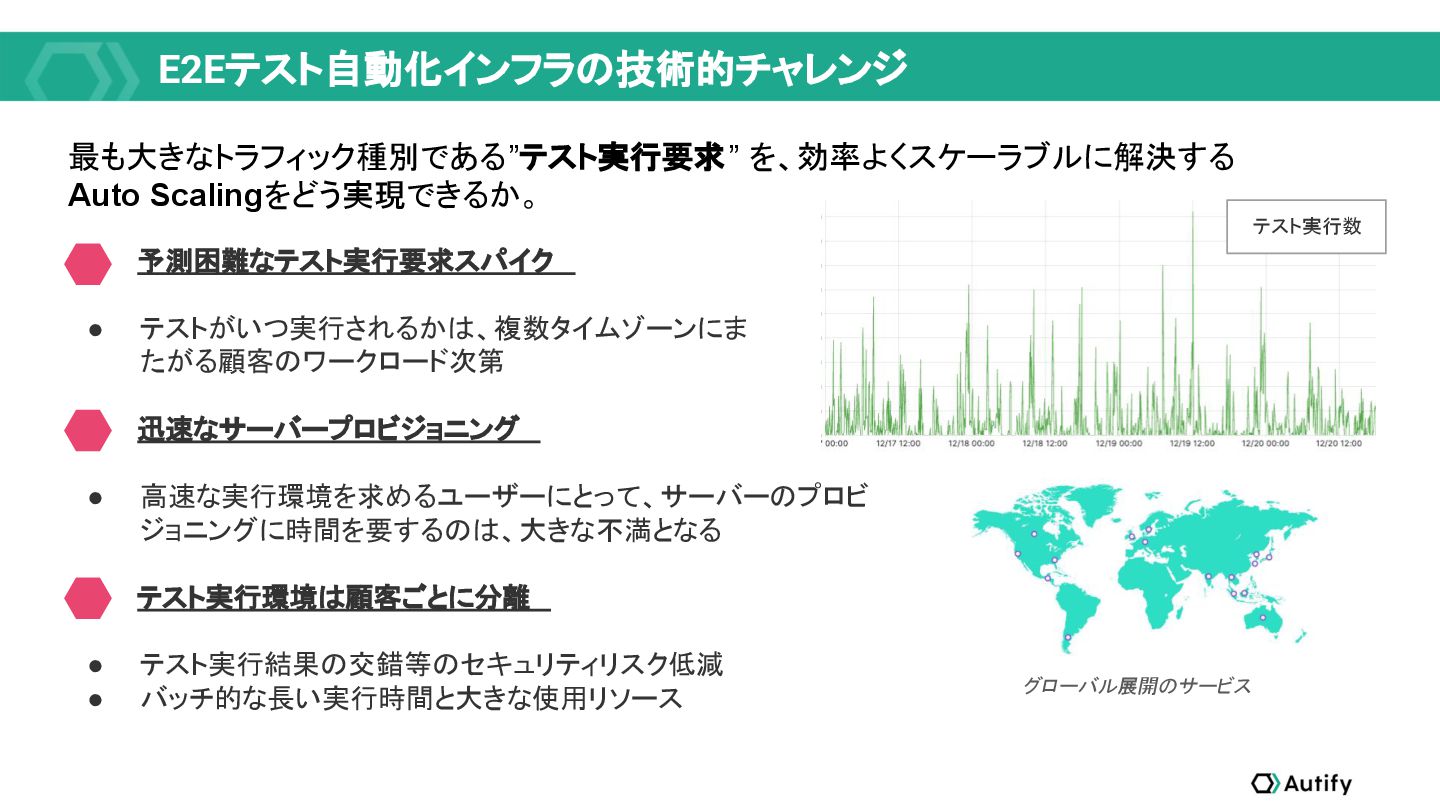
テスト自動化ツールのインフラストラクチャは典型的なWEBサービスとはトラフィックやスケーリング要件が異なるため、教科書通りのクラウドネイティブ技術の適用では収まらない面白みがあります。本セッションで紹介される事例は、独自性のある事例であるともに、様々なサービス開発現場で再利用可能なナレッジとなるでしょう。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![EKS移行による効果 テスト実行ワーカー Selenium Chrome Linux Node [w/EKS] 1~3 GB, ~0.2v](https://files.speakerdeck.com/presentations/bef2525af3334243b845d602fd21b22d/slide_20_1742168351.jpg){kind=link}
{kind=link}
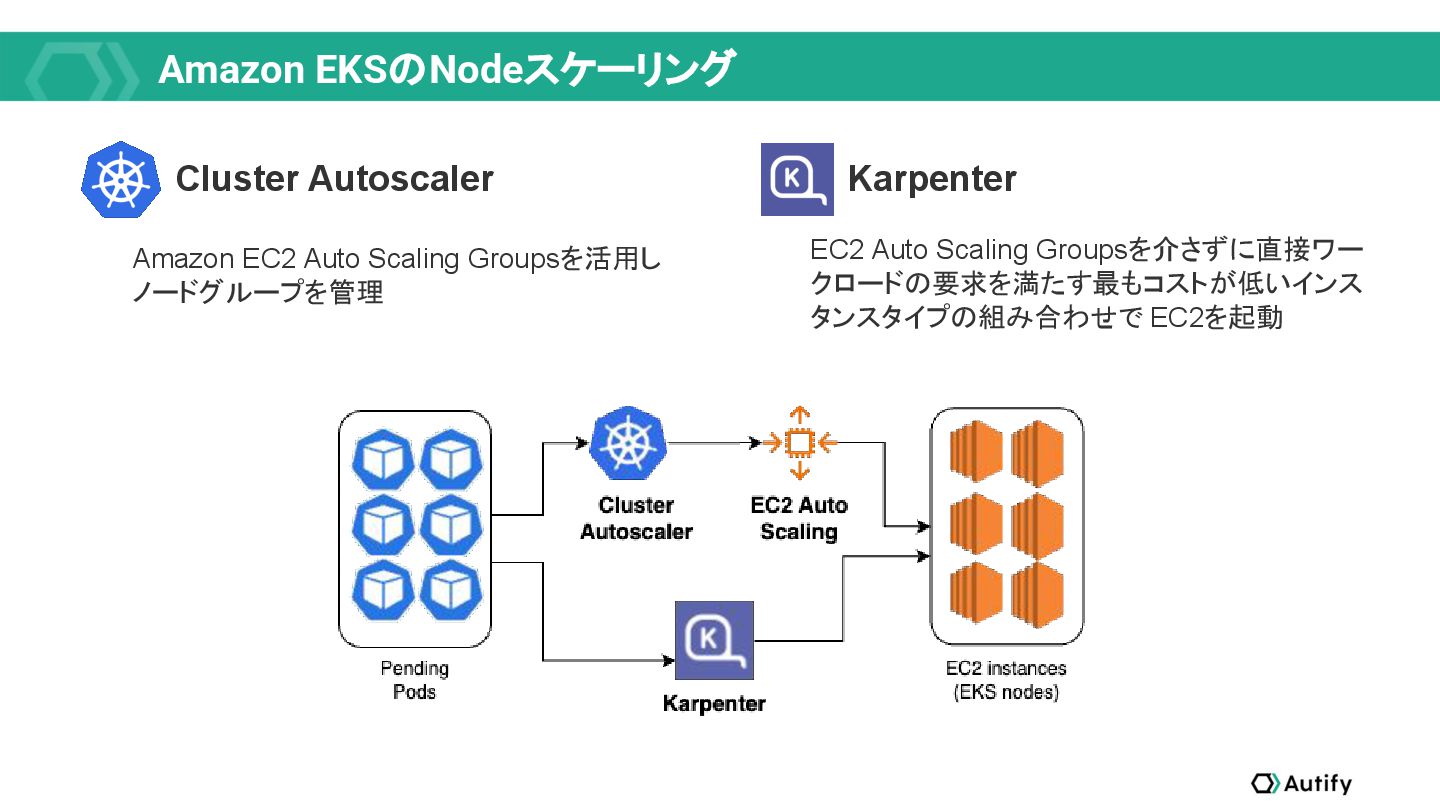{kind=link}
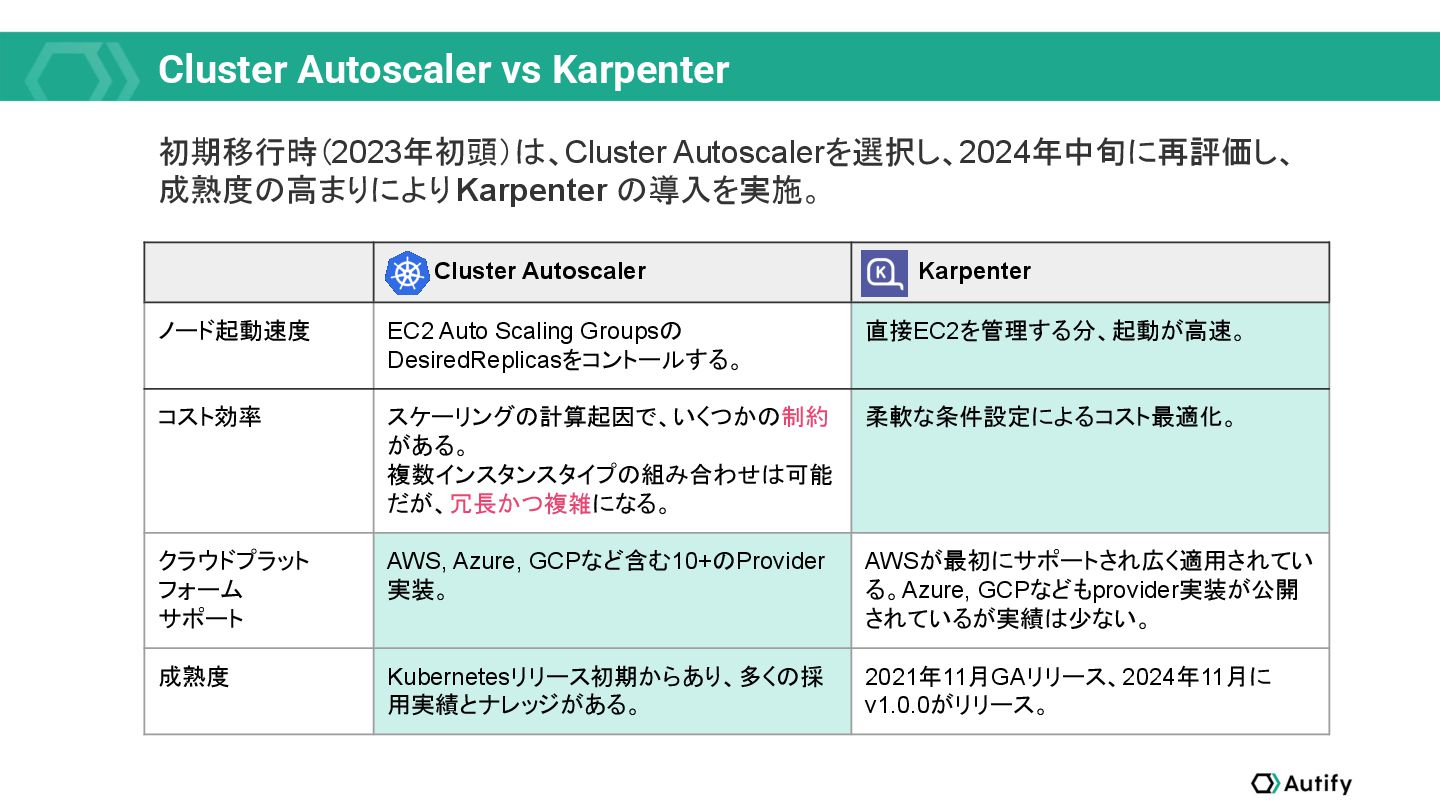{kind=link}
{kind=link}
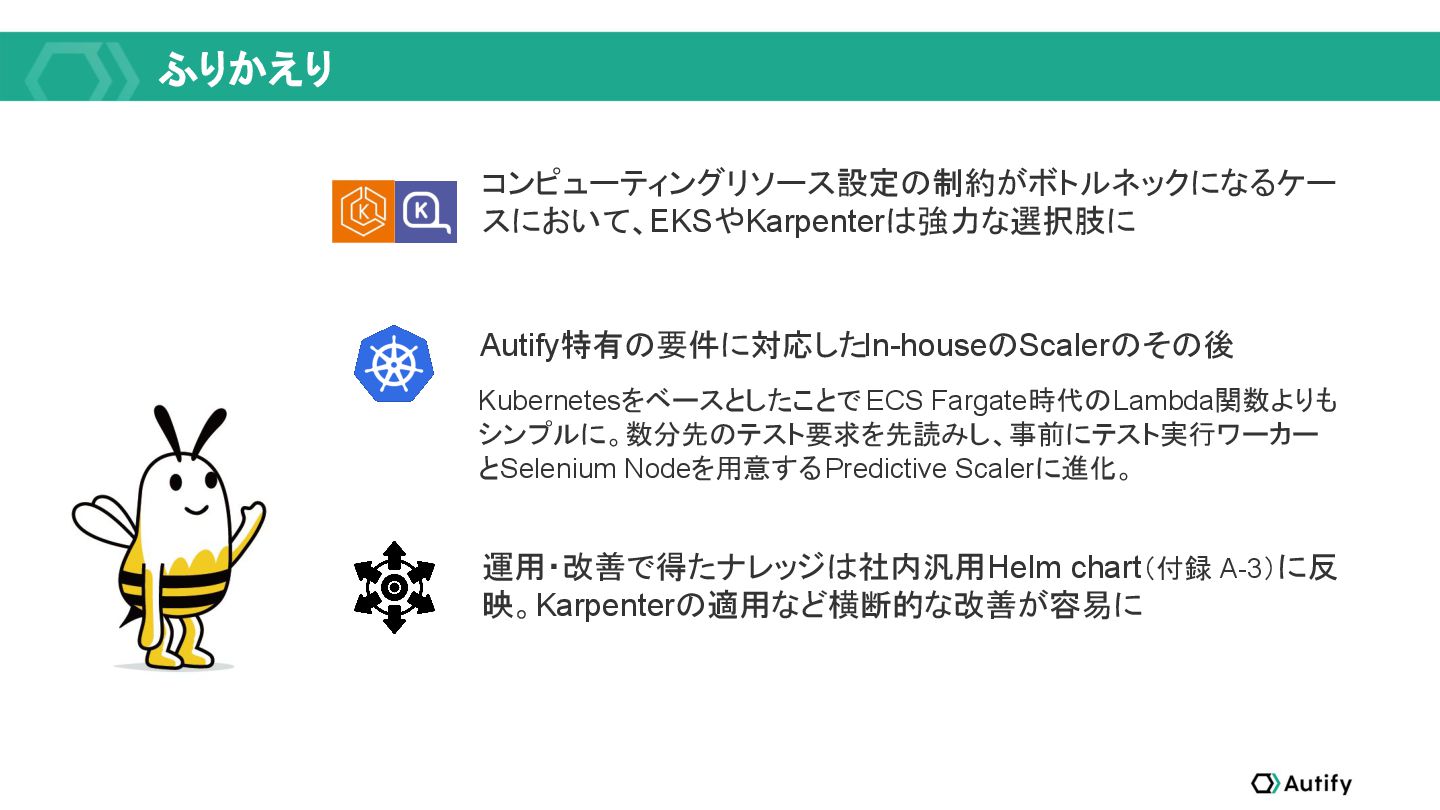{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
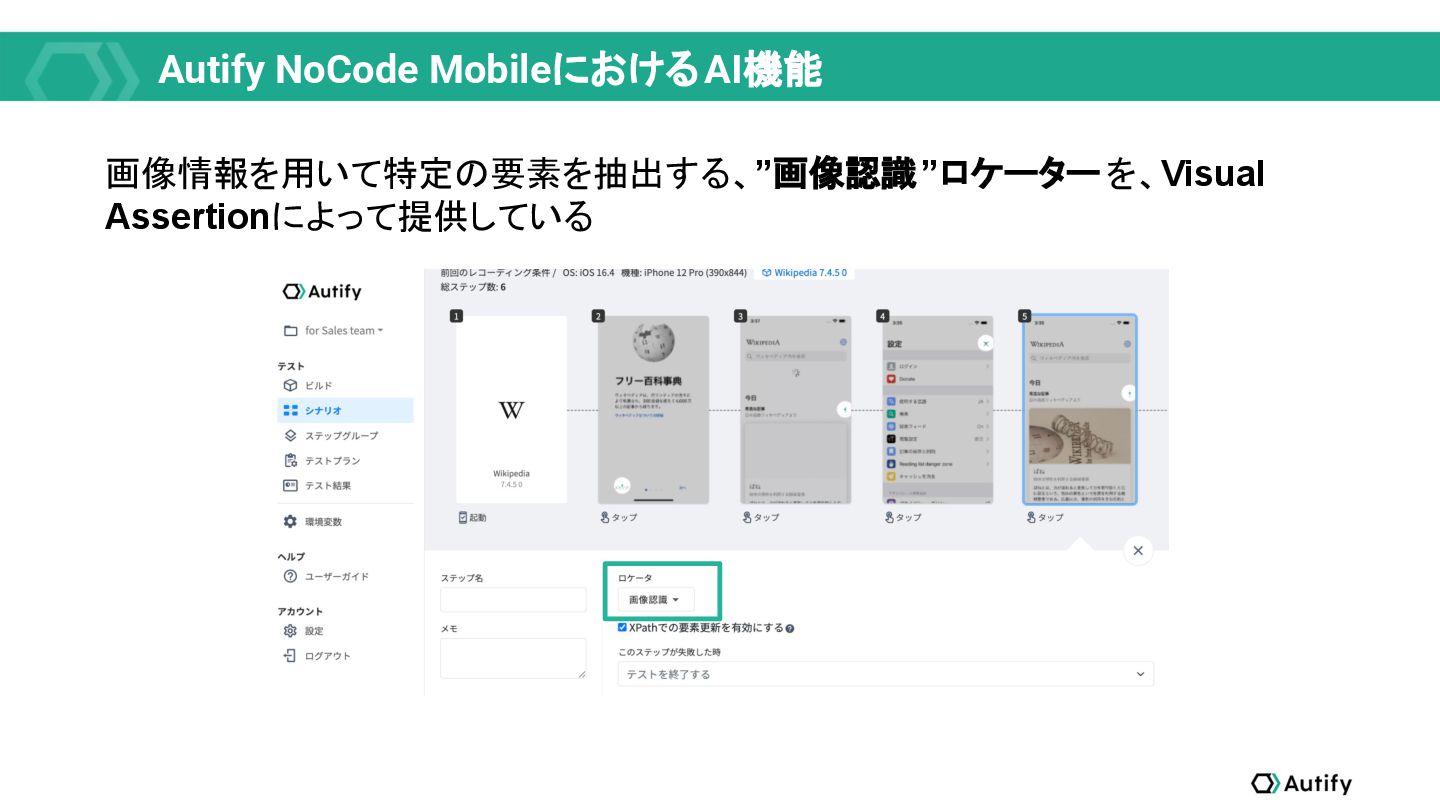{kind=link}
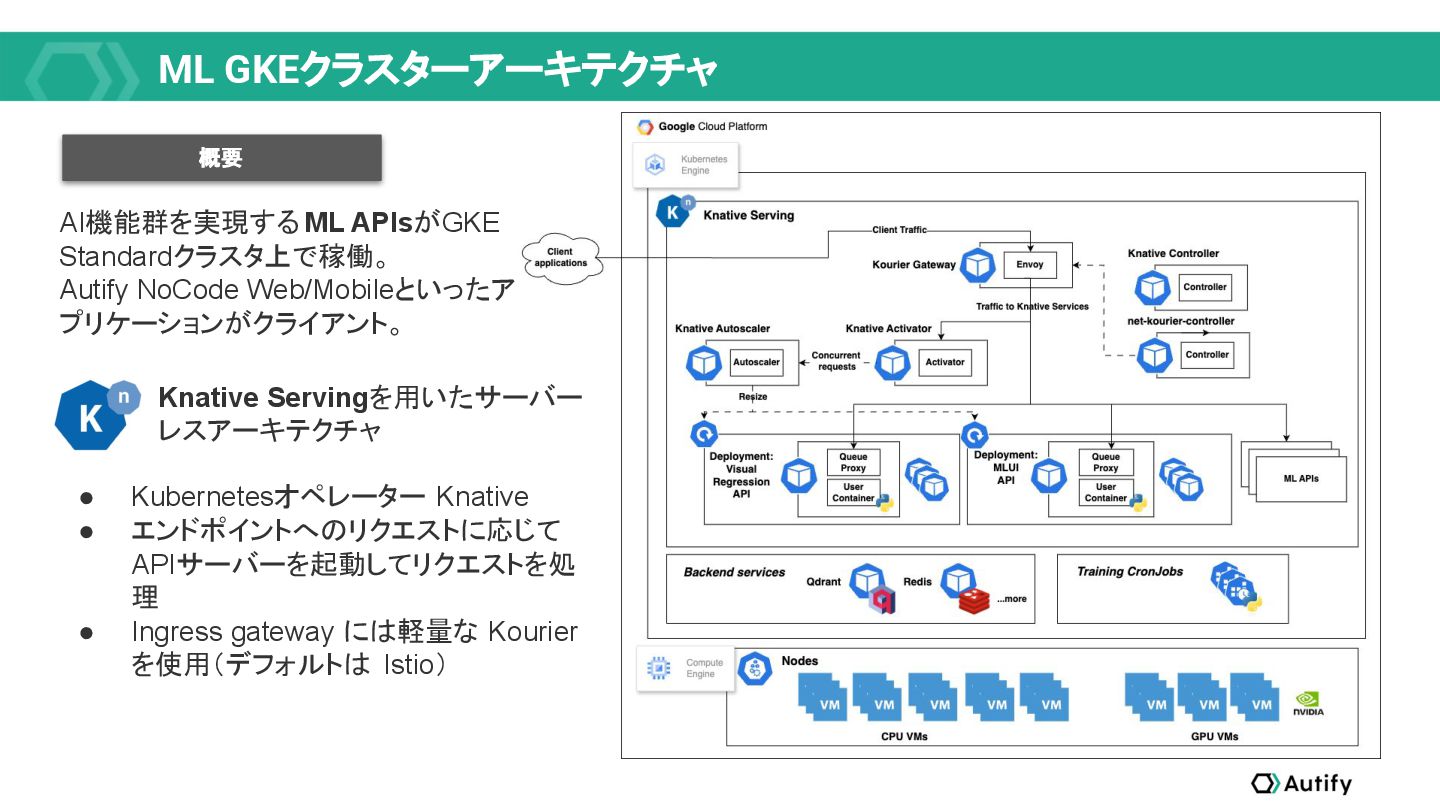{kind=link}
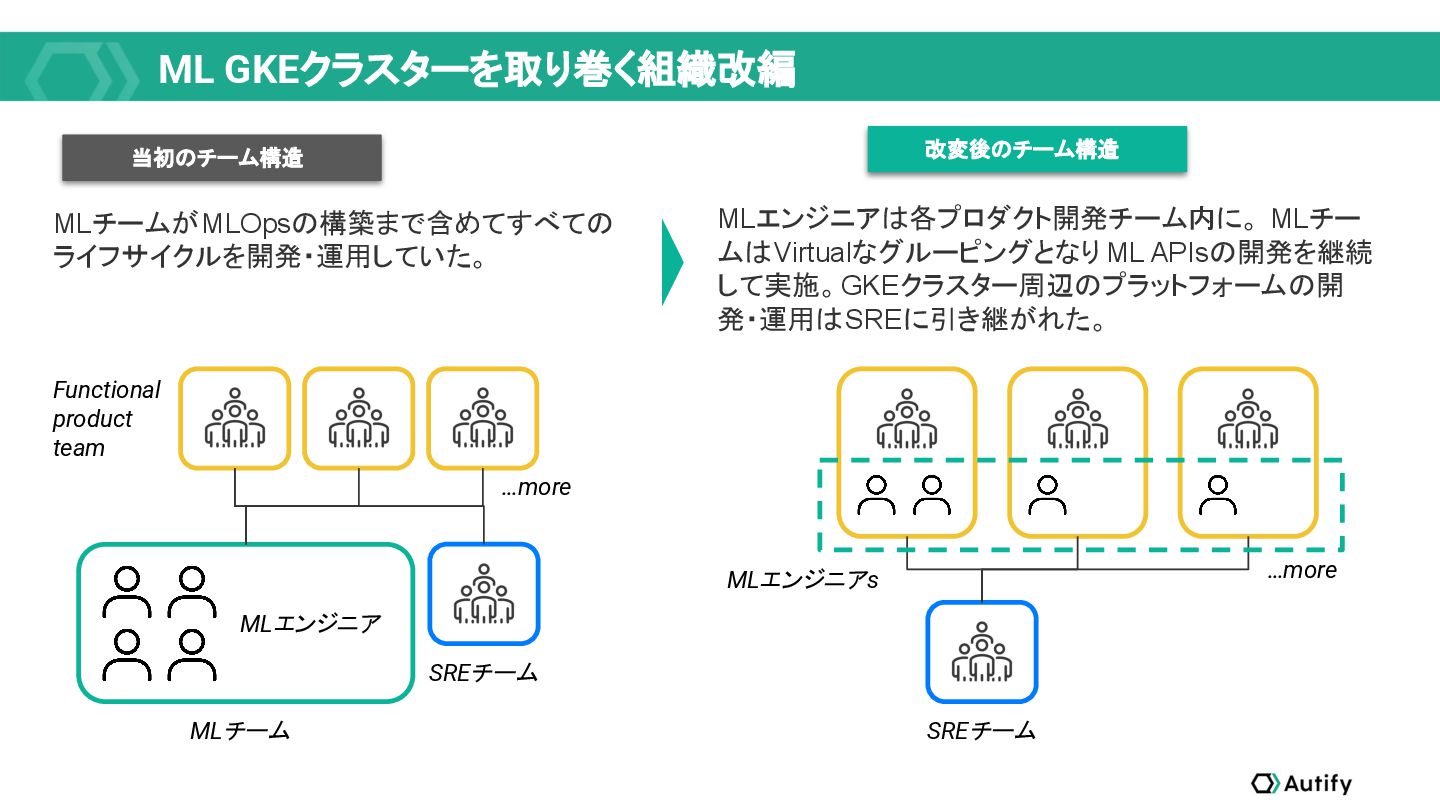{kind=link}
{kind=link}
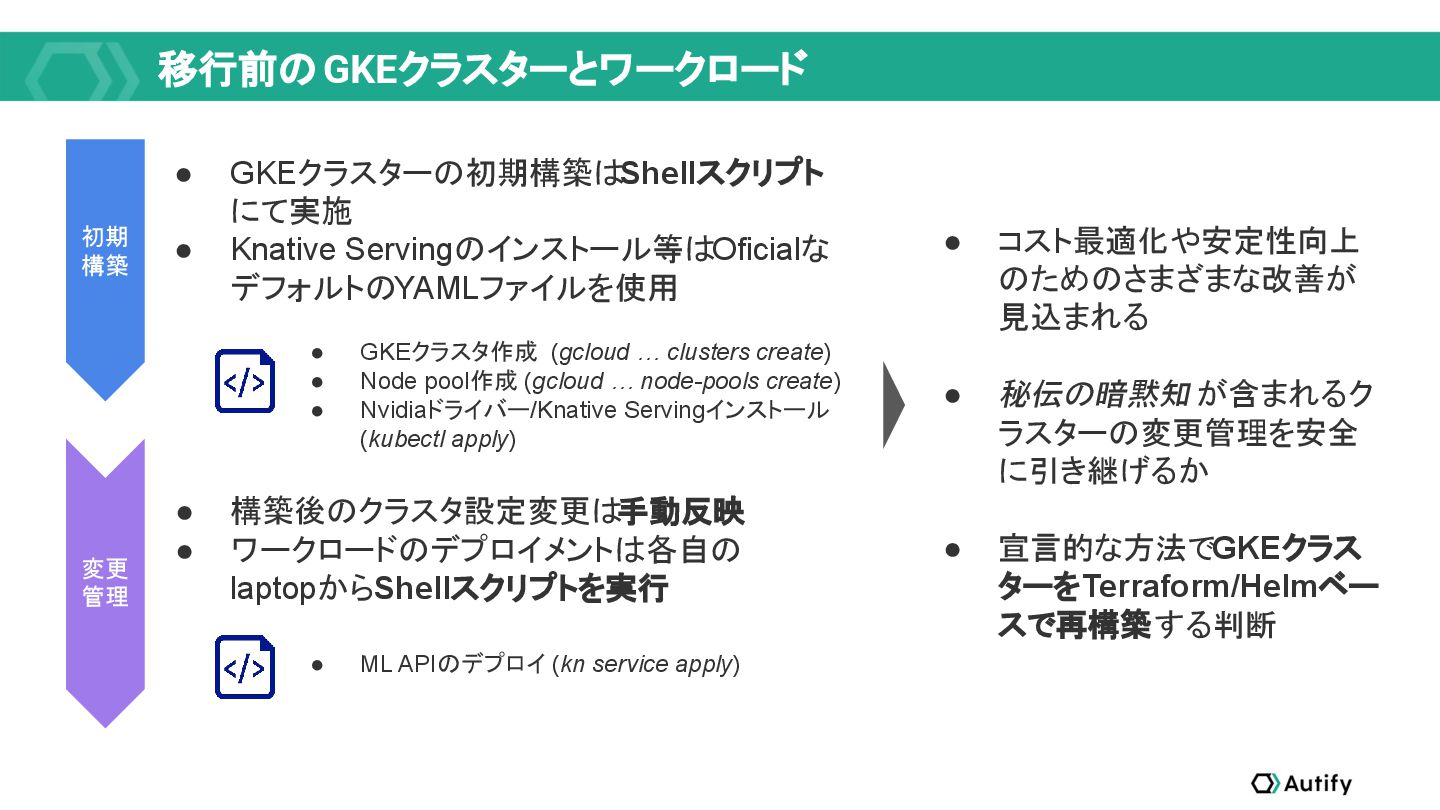{kind=link}
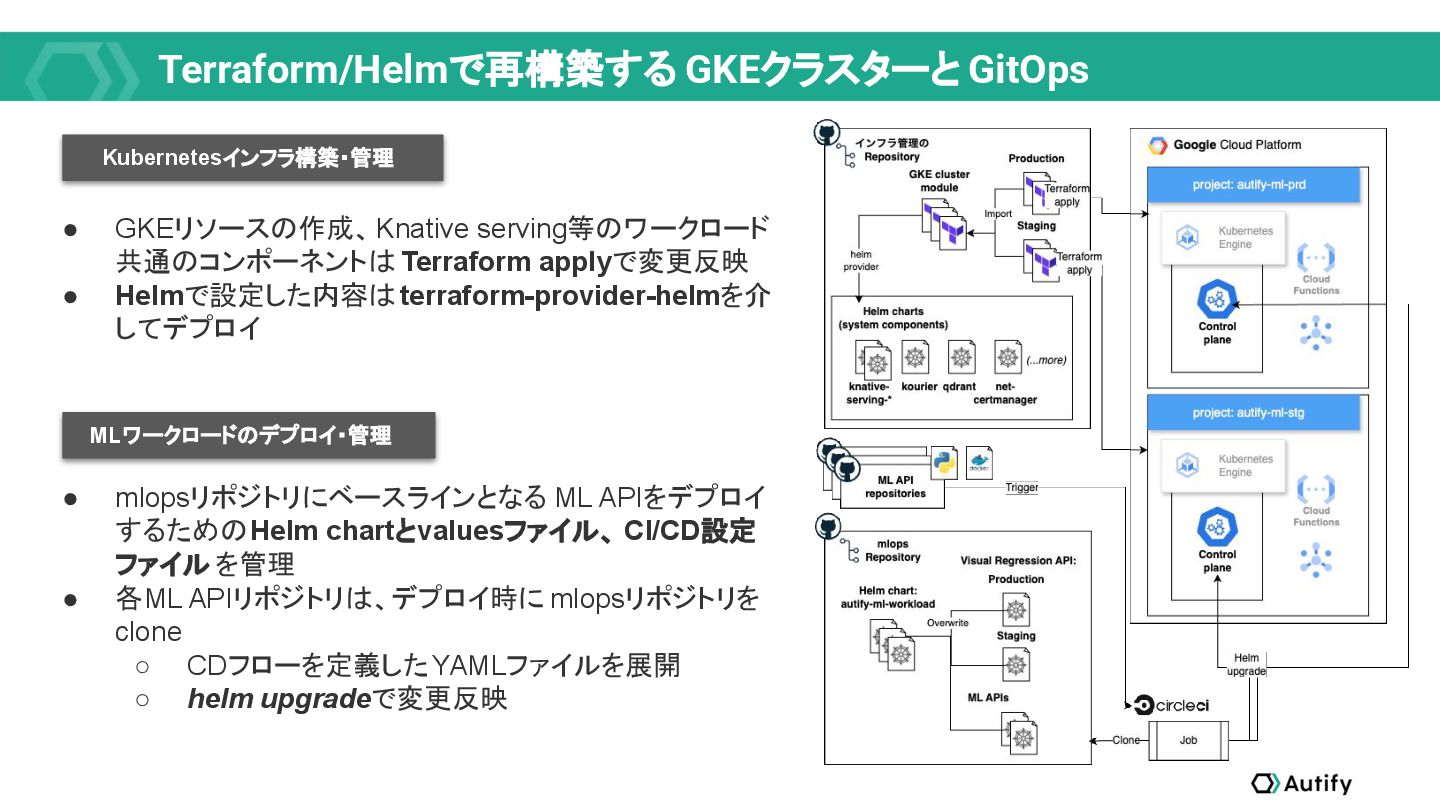{kind=link}
{kind=link}
{kind=link}
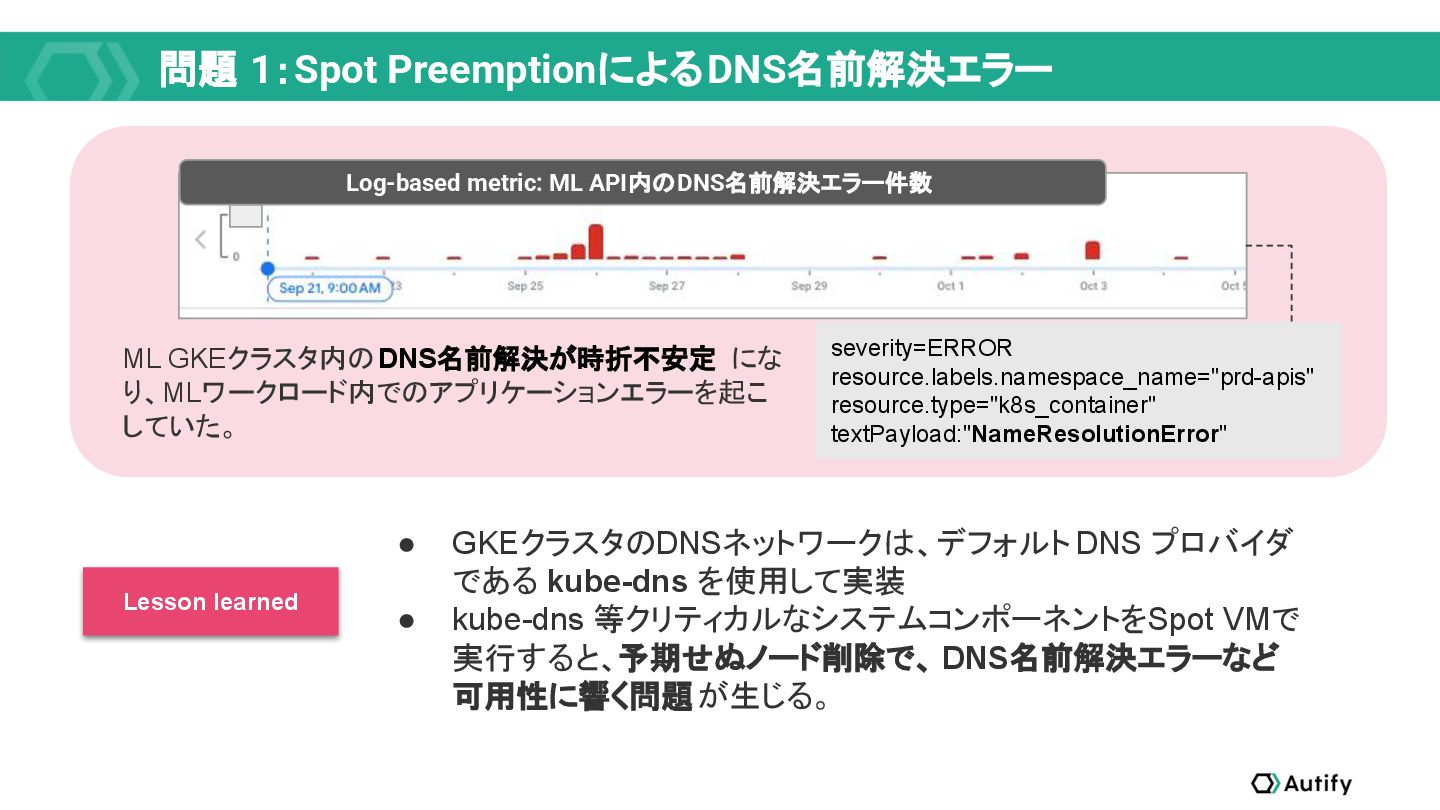{kind=link}
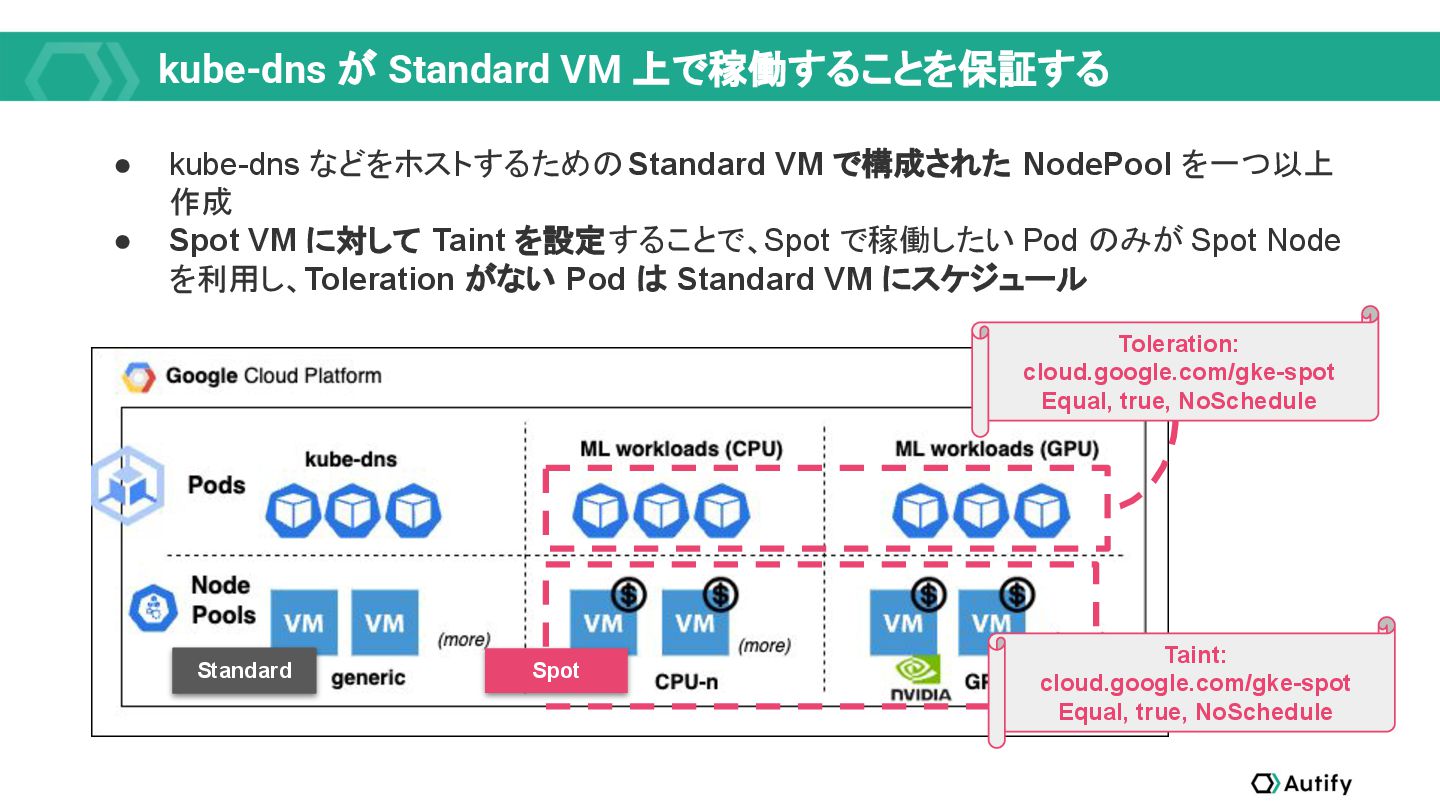{kind=link}
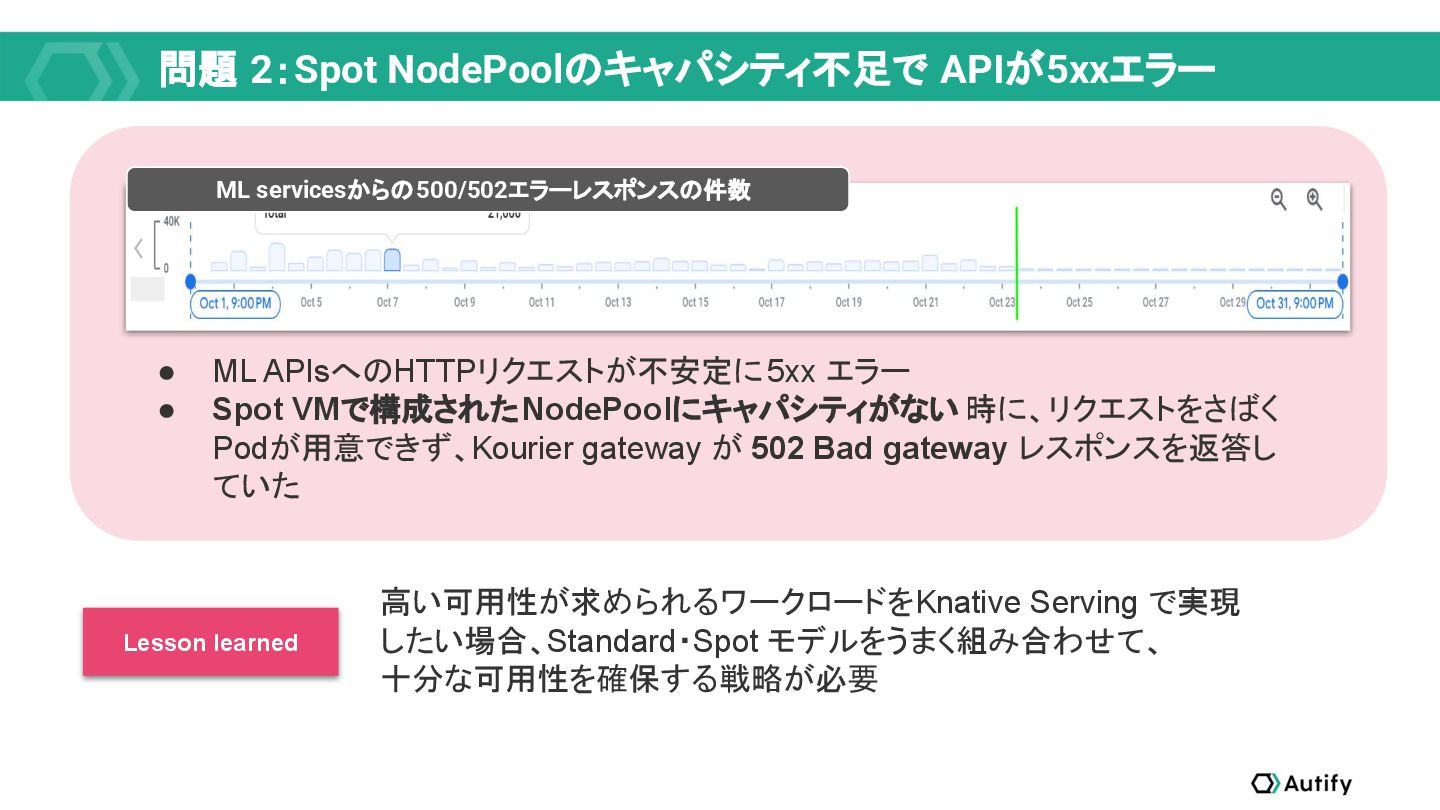{kind=link}
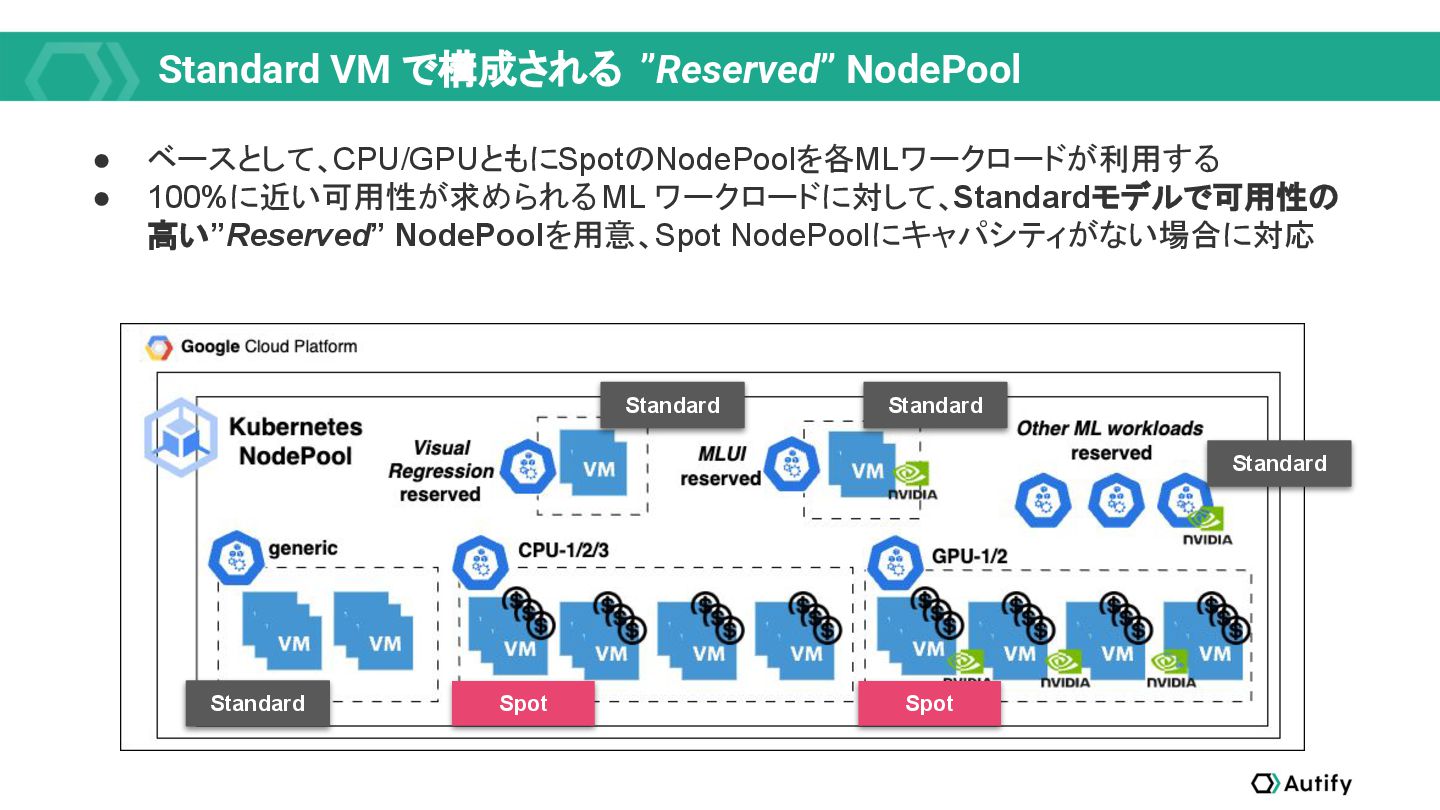{kind=link}
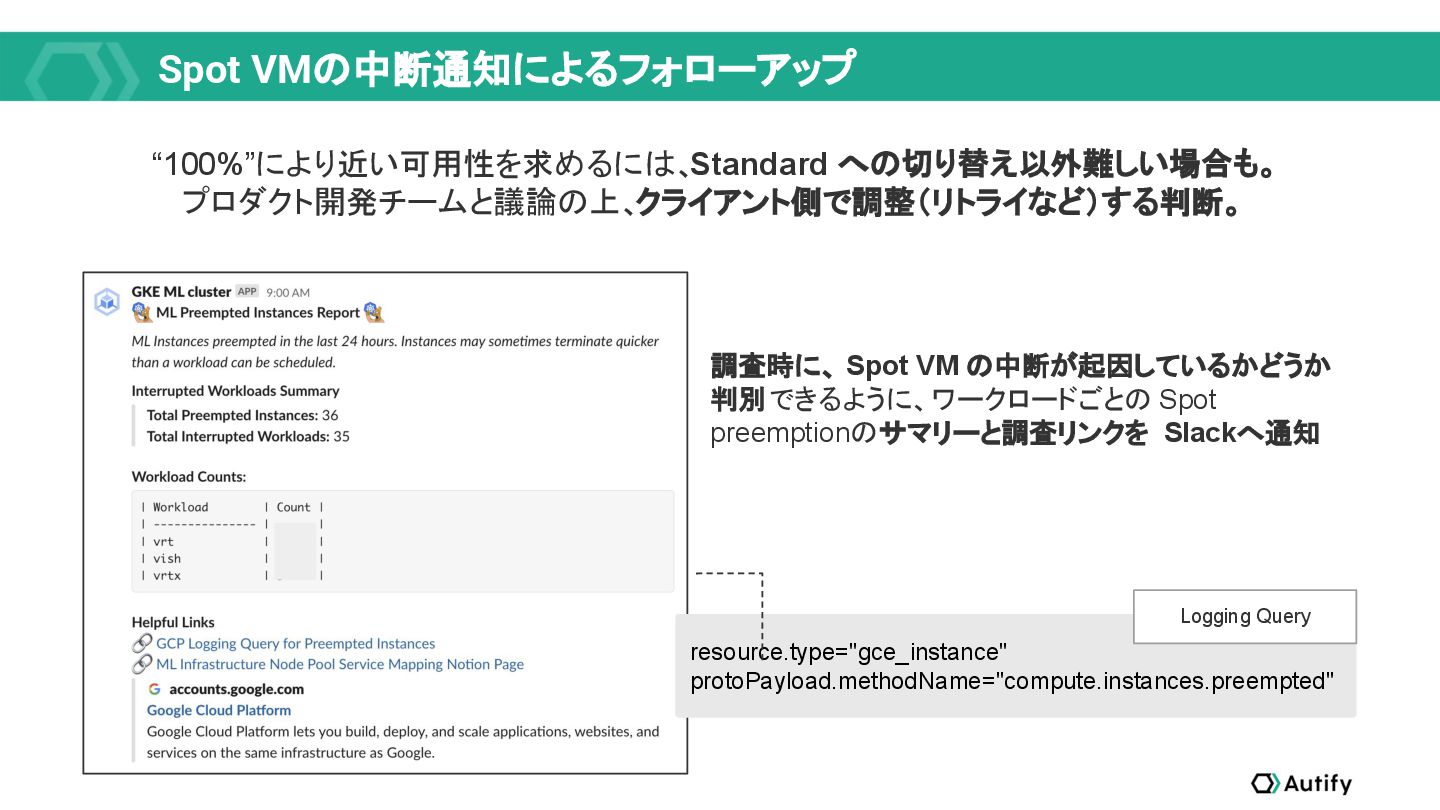{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
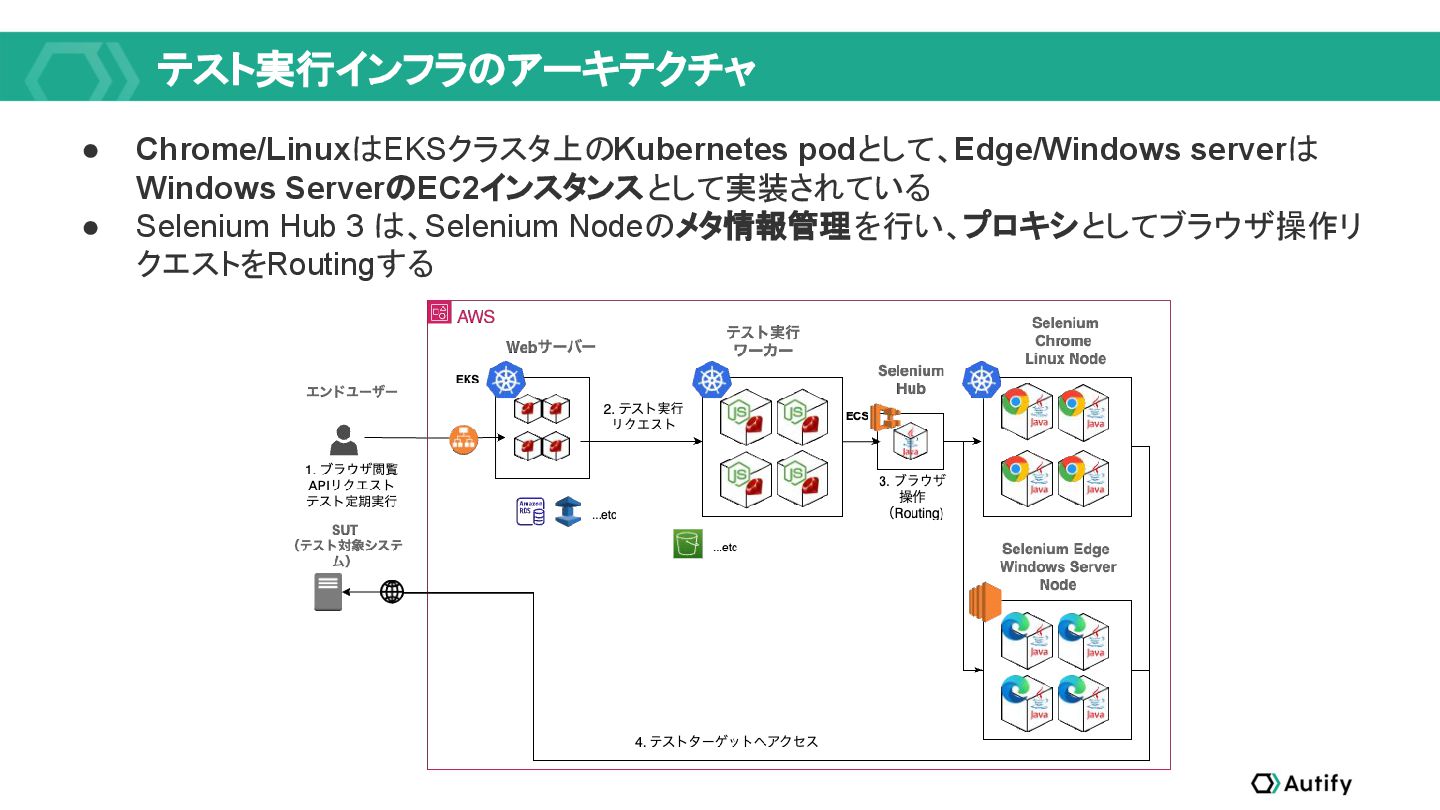{kind=link}
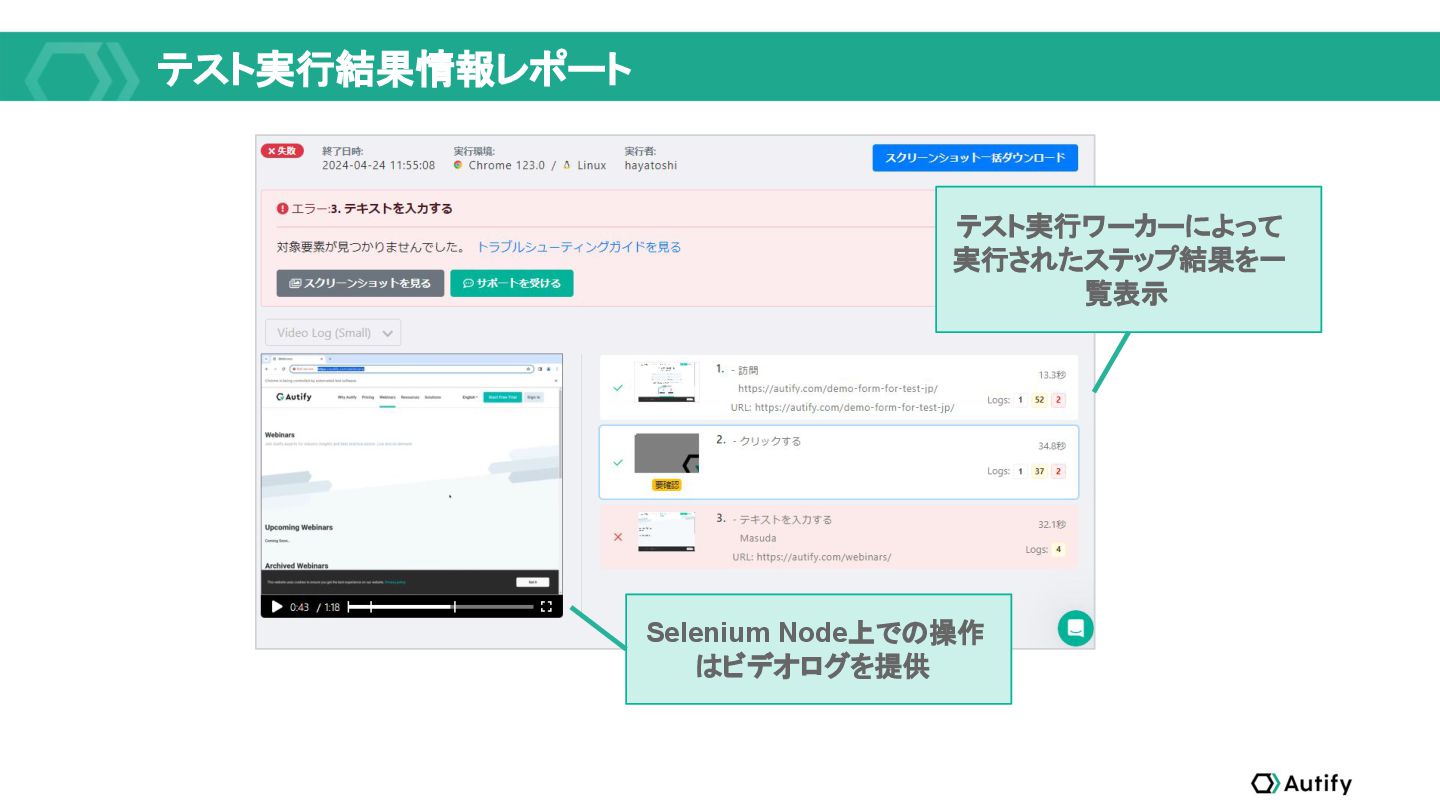{kind=link}
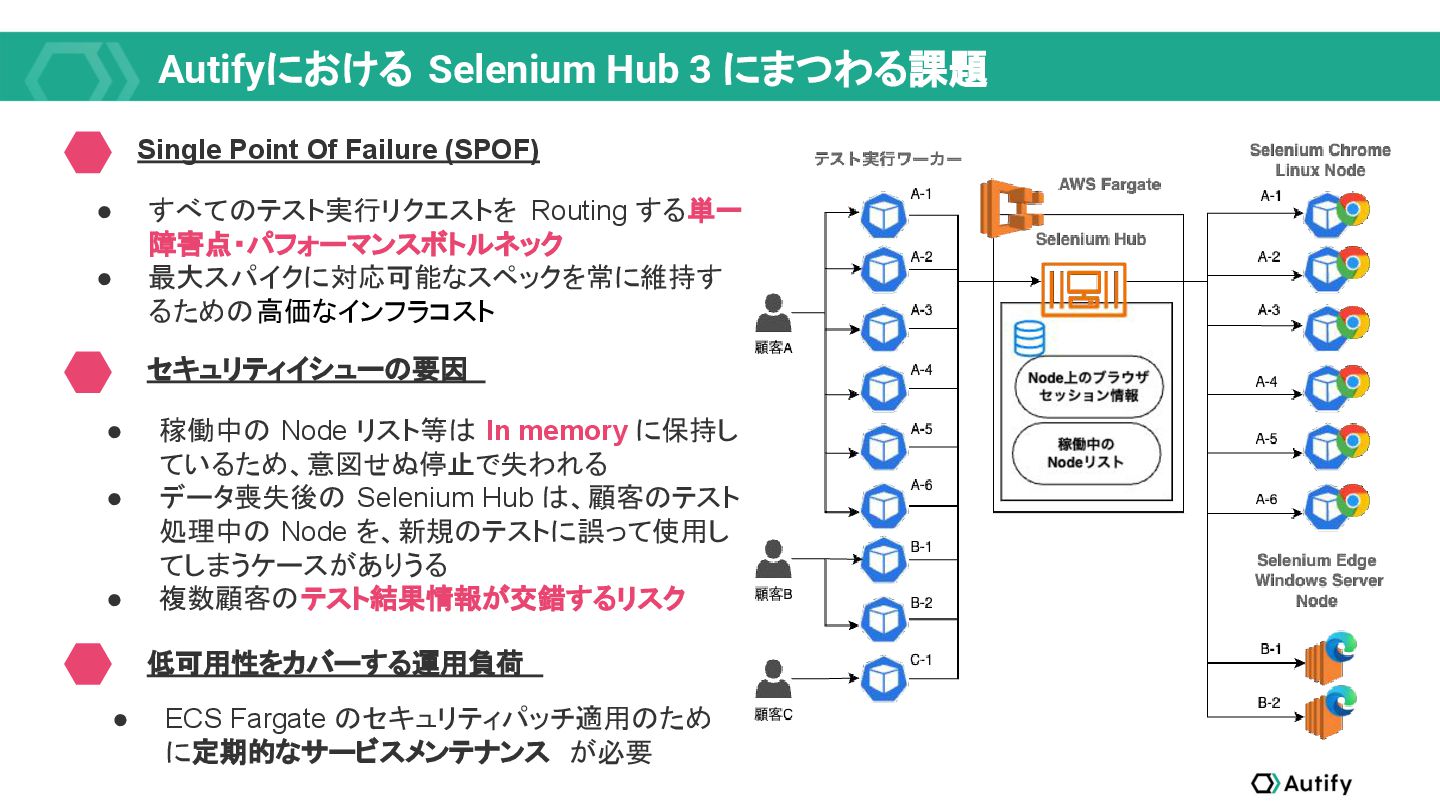{kind=link}
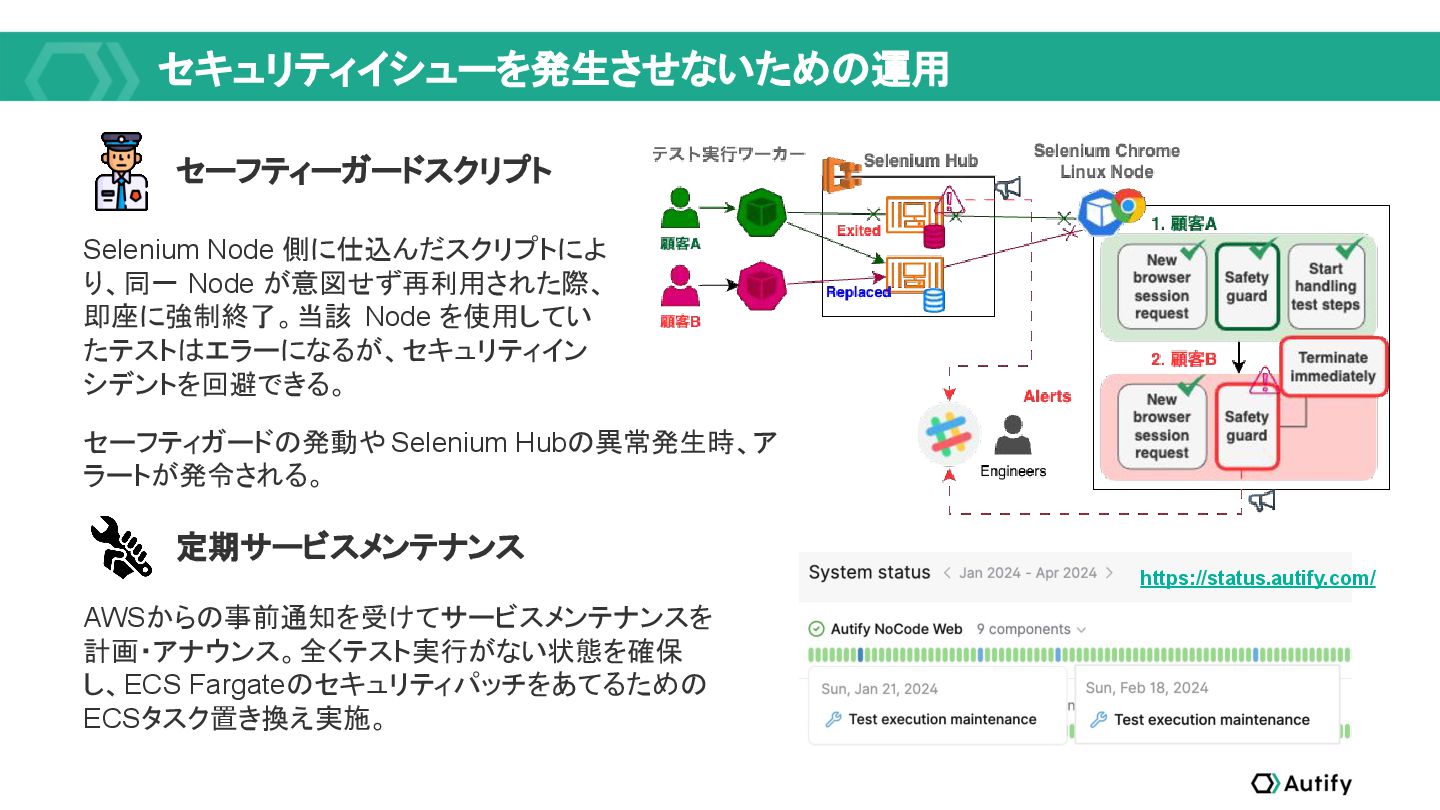{kind=link}
{kind=link}
{kind=link}
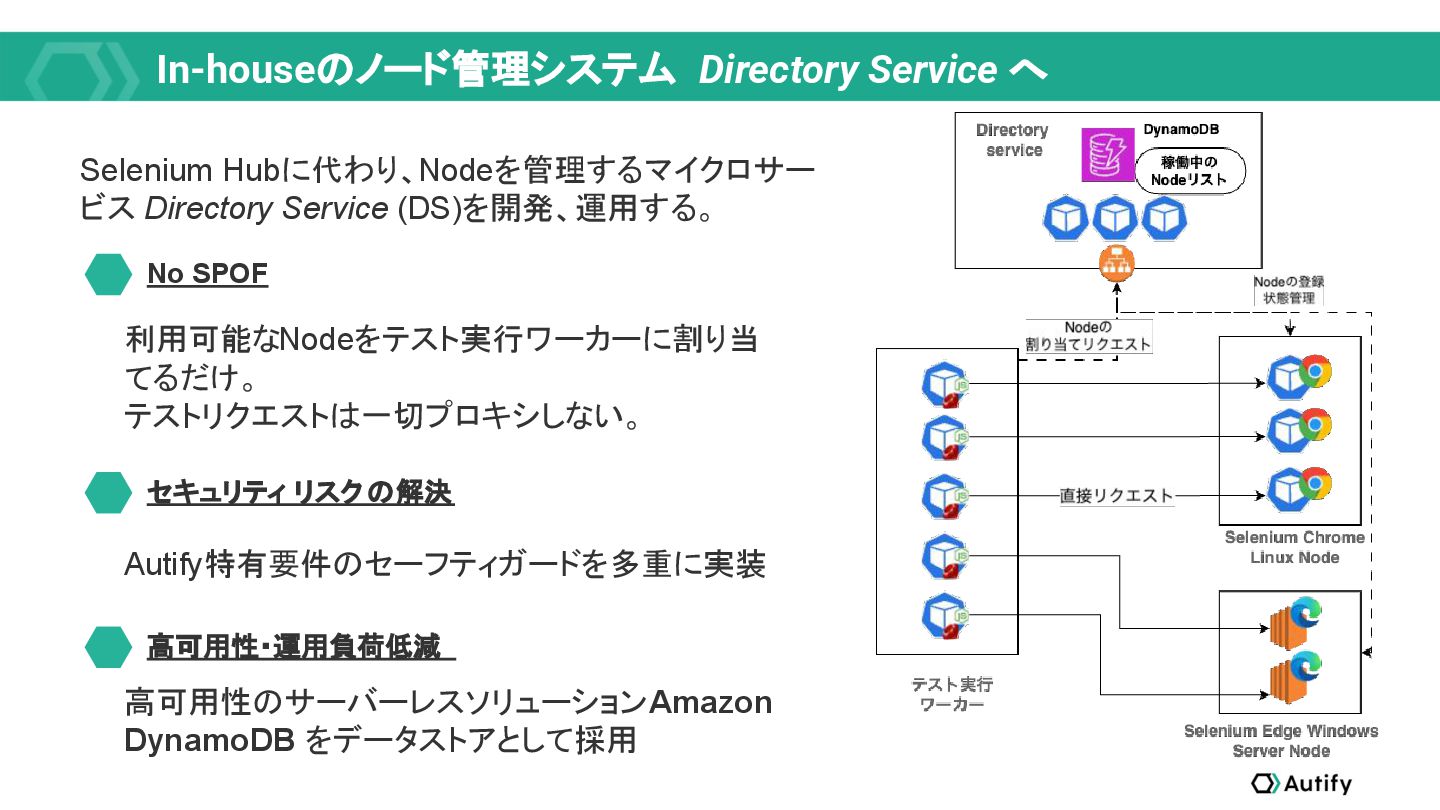{kind=link}
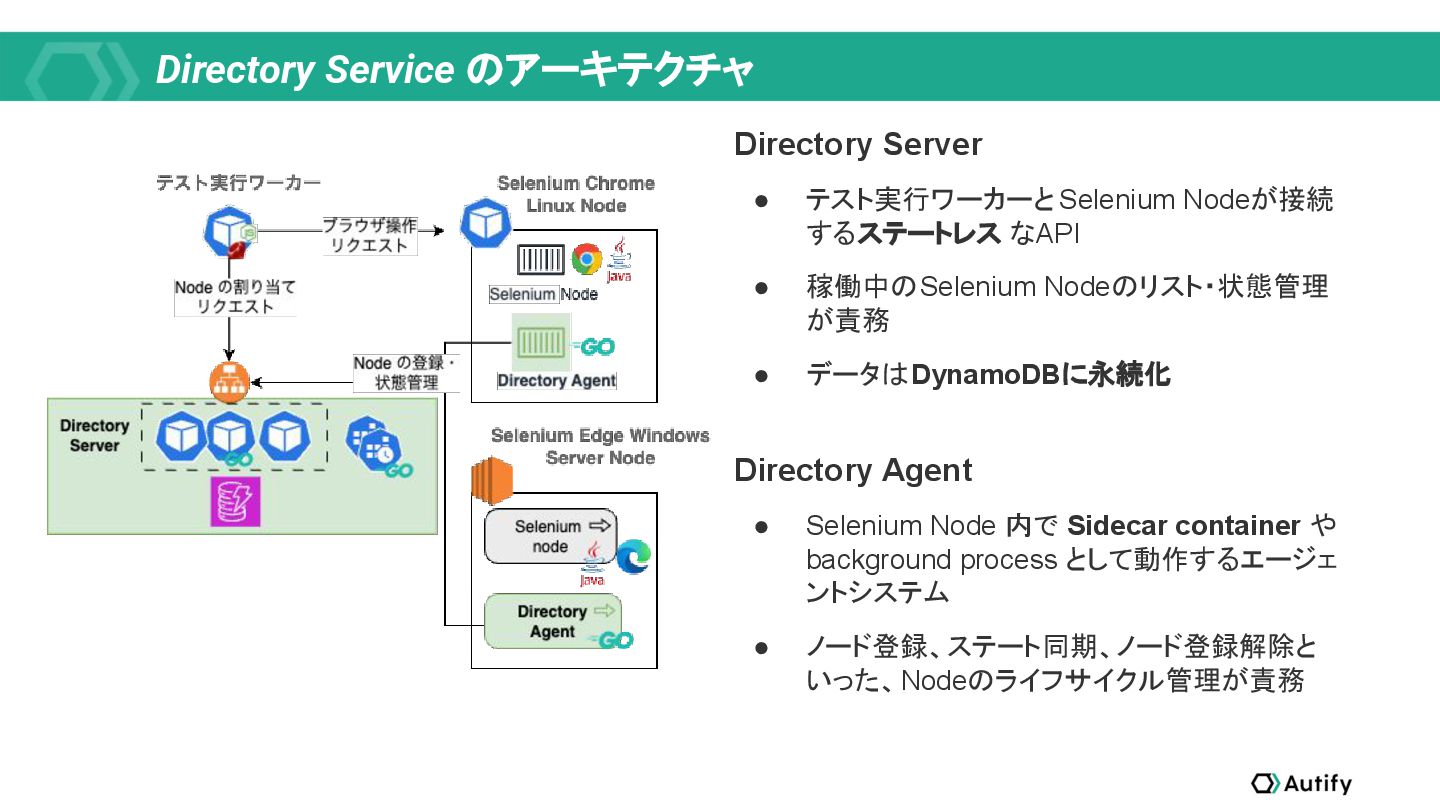{kind=link}
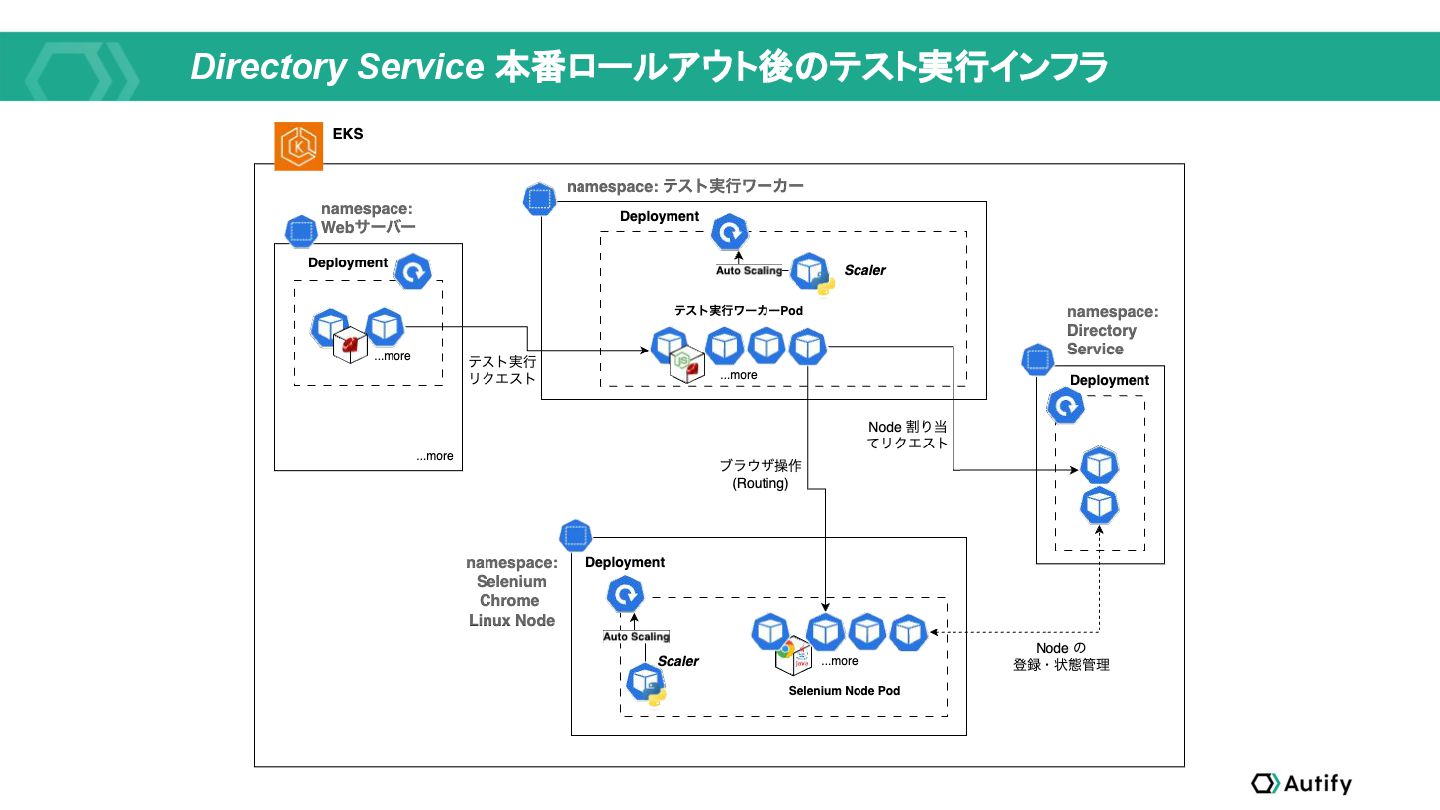{kind=link}
{kind=link}
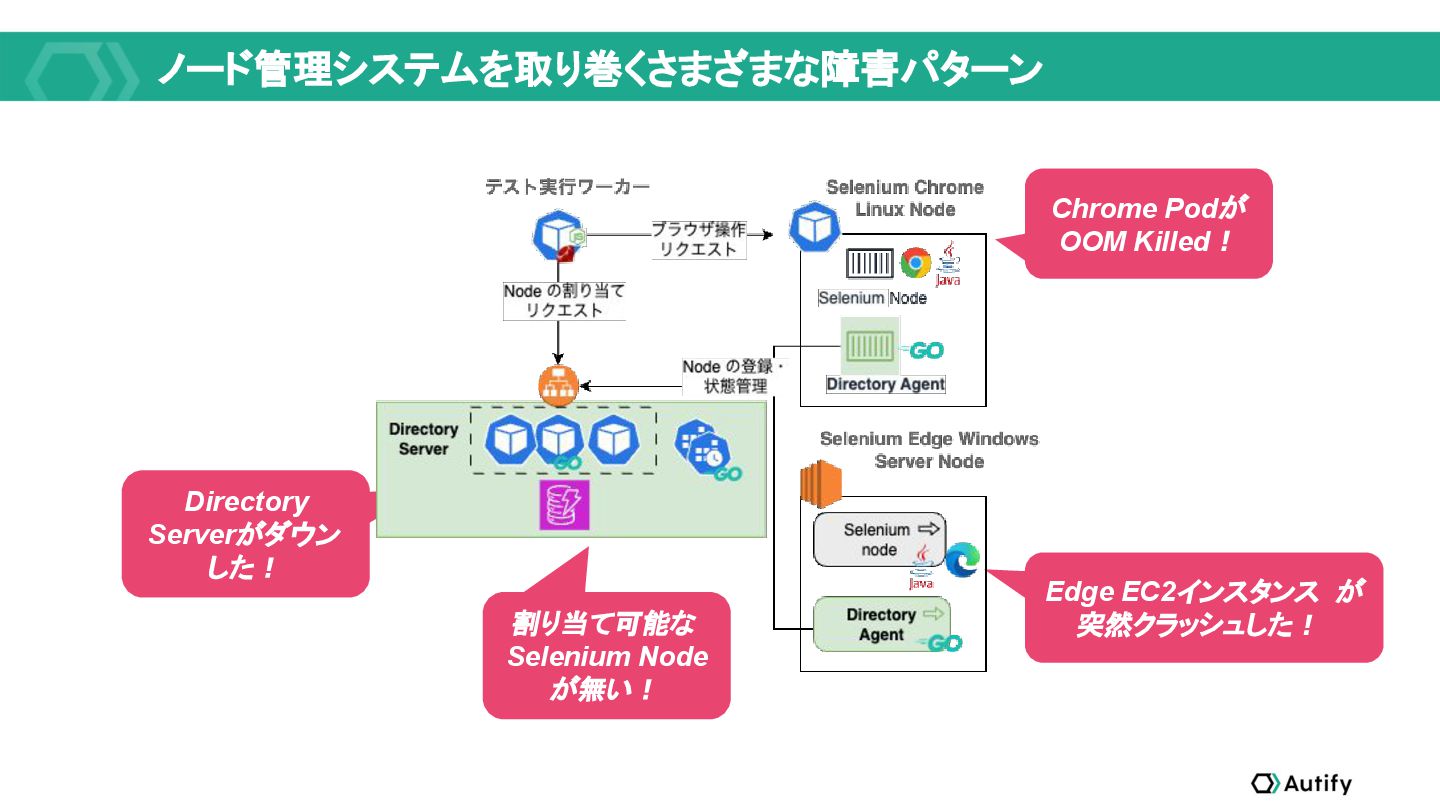{kind=link}
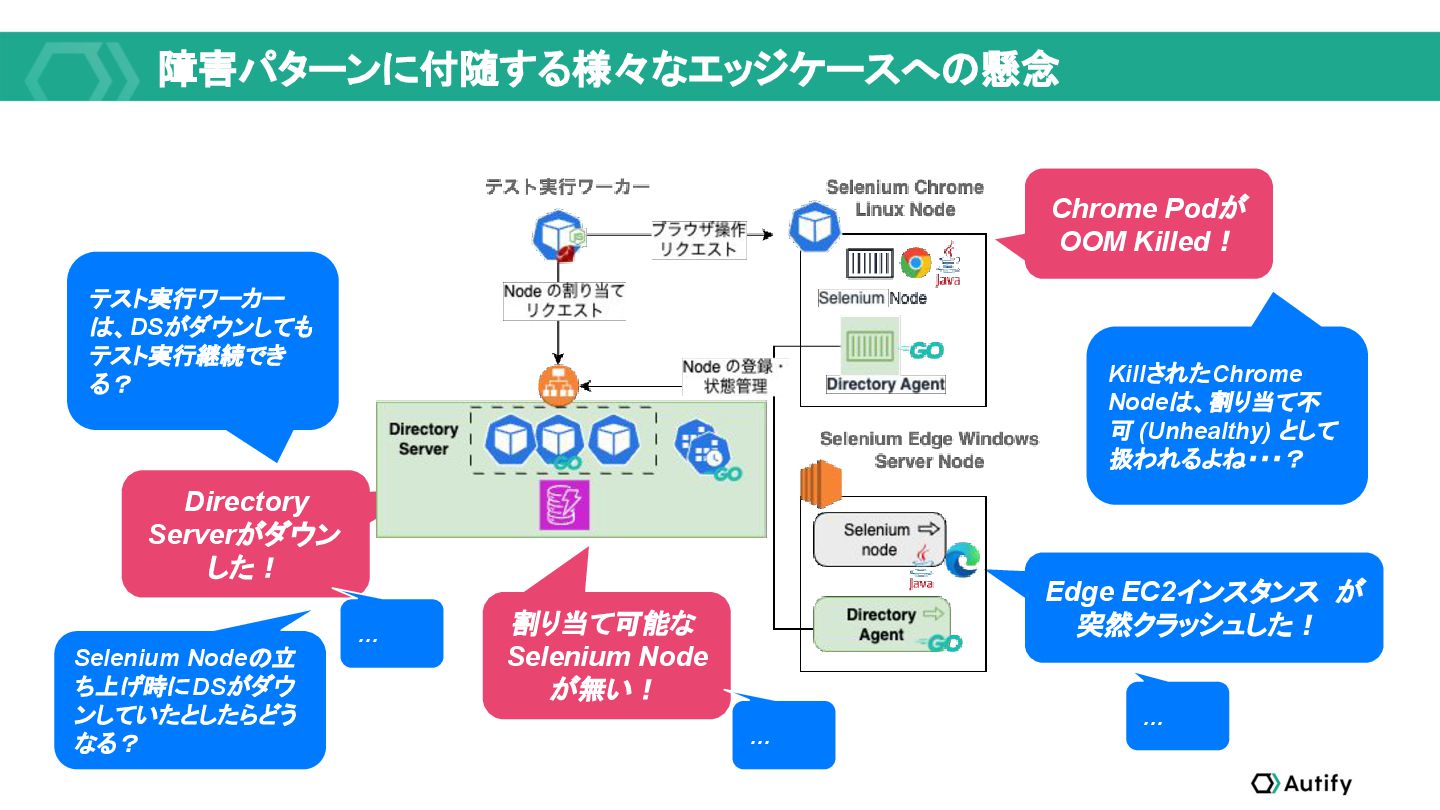{kind=link}
{kind=link}
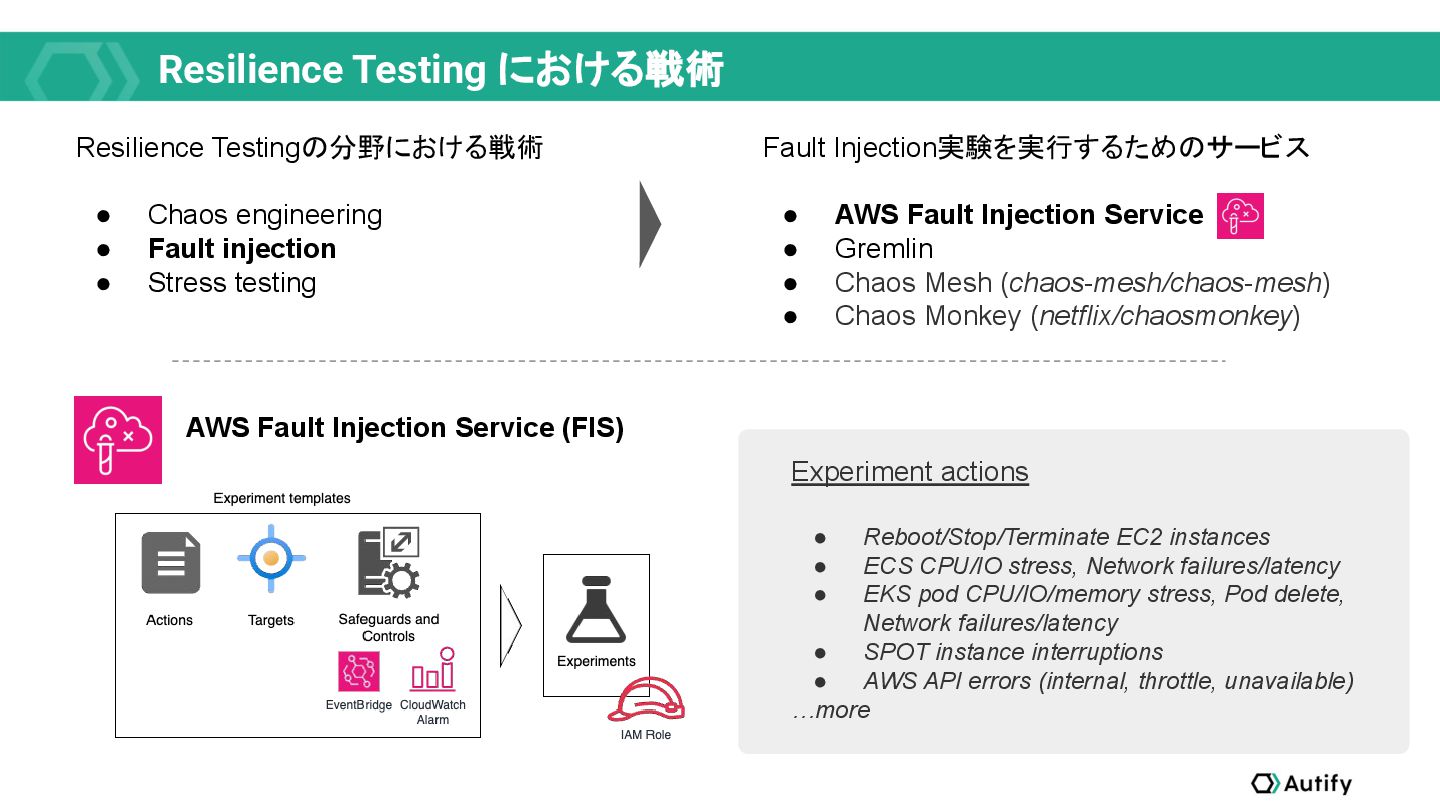{kind=link}
{kind=link}
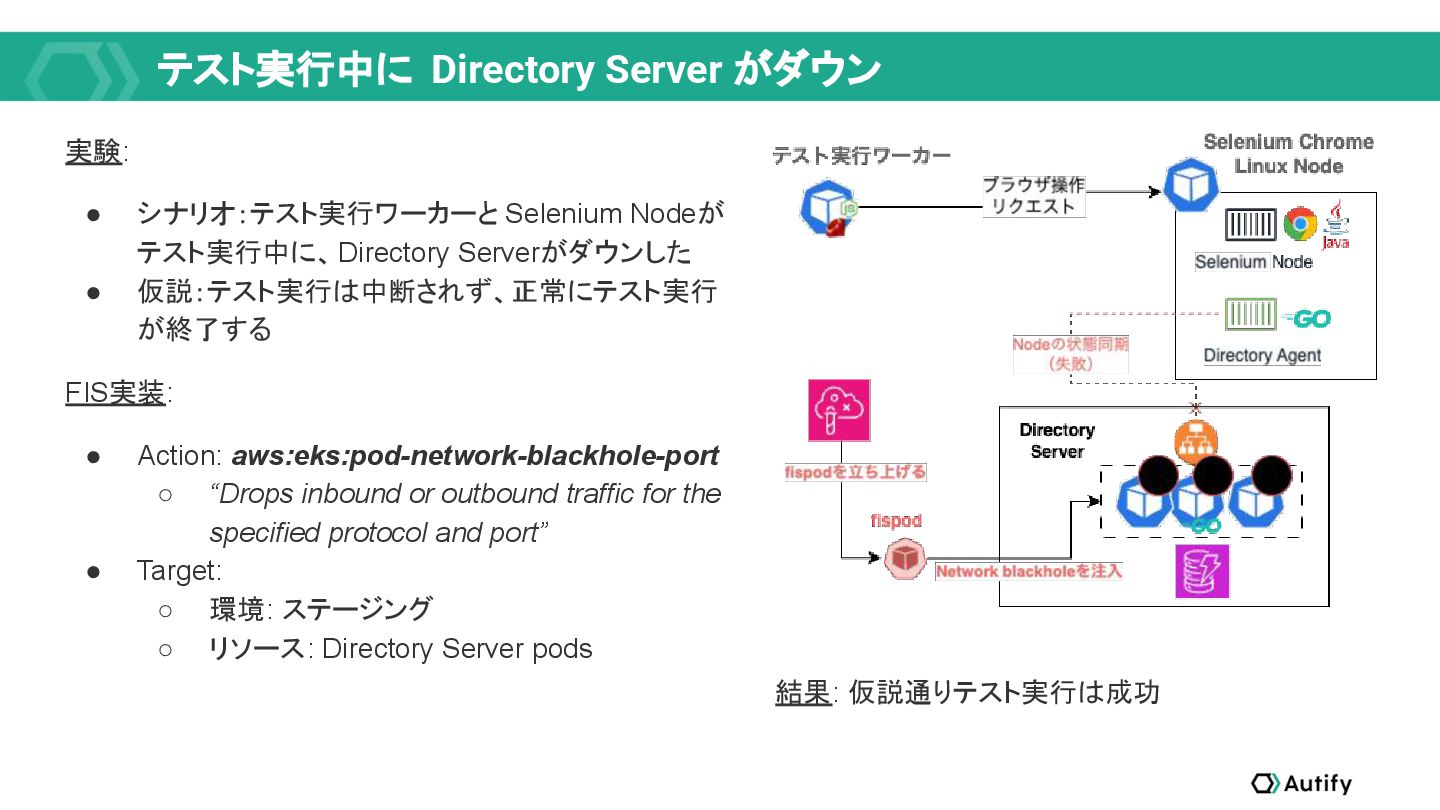{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
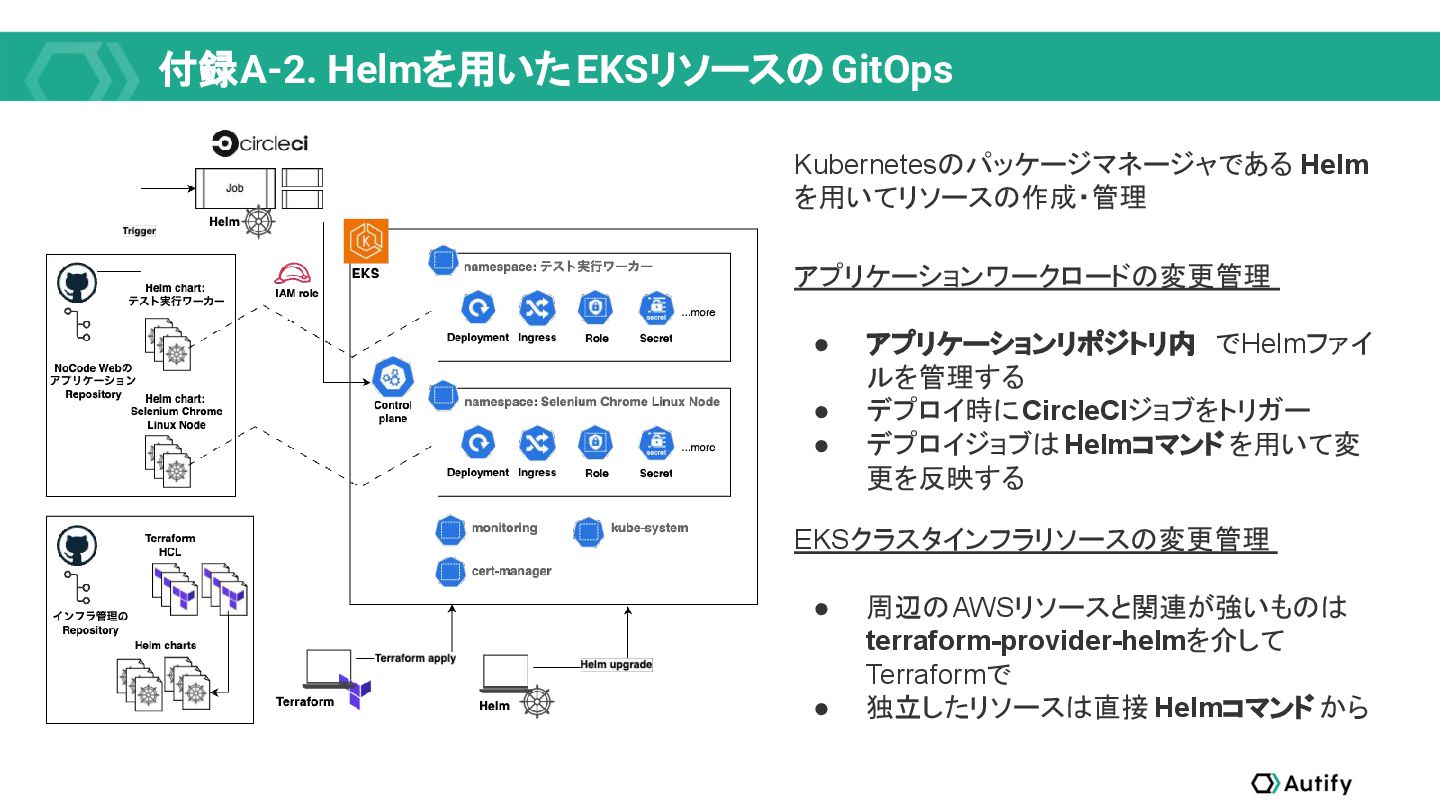{kind=link}
{kind=link}
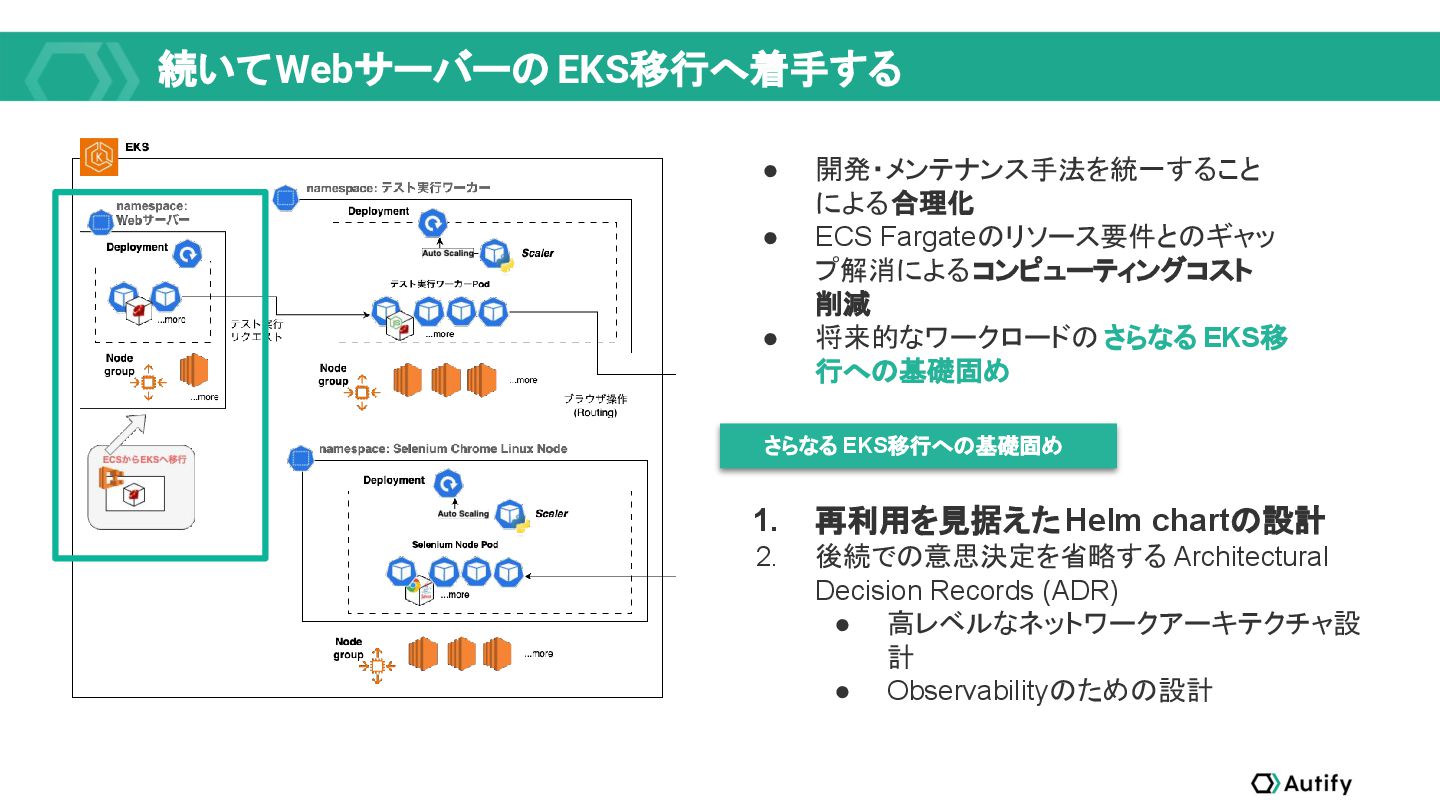{kind=link}
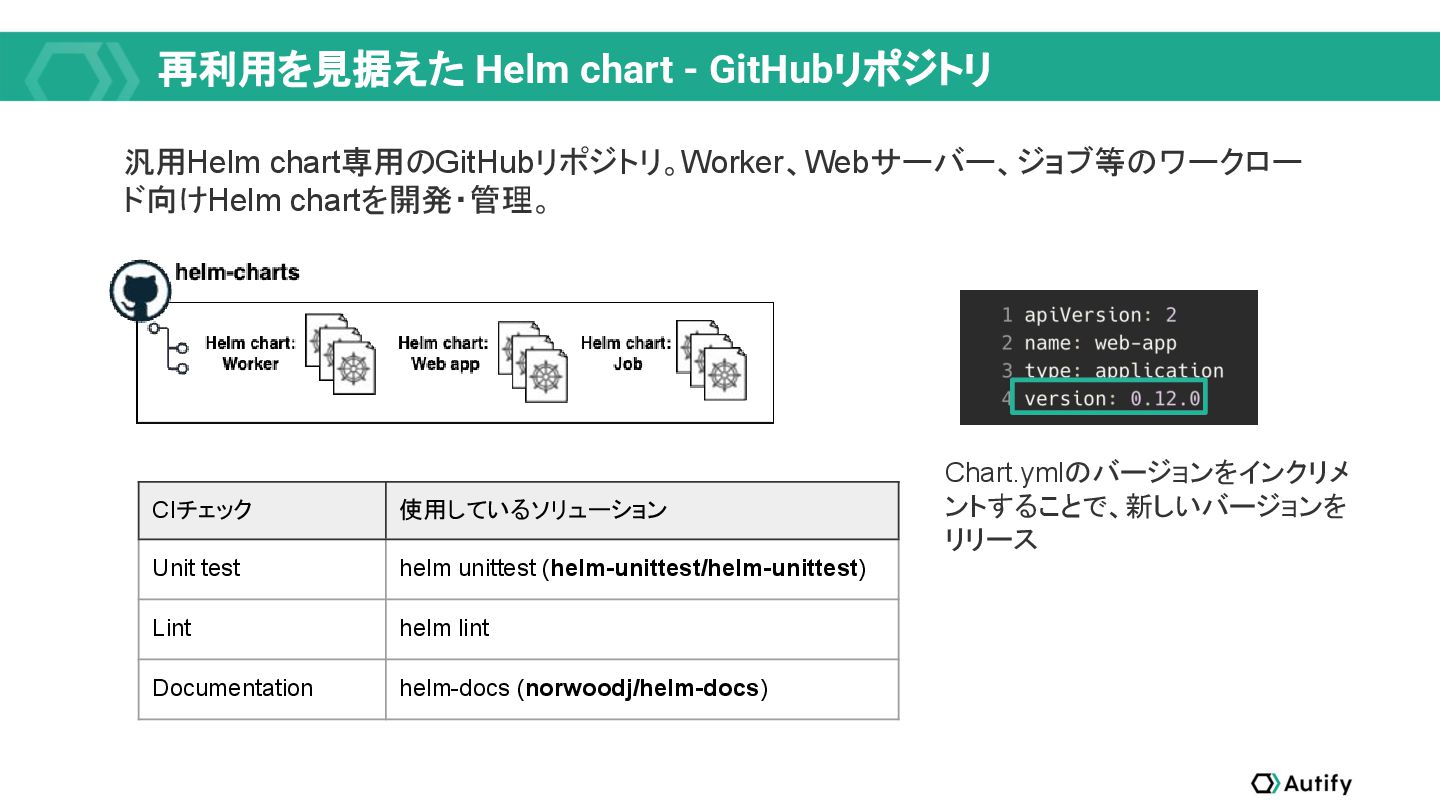{kind=link}
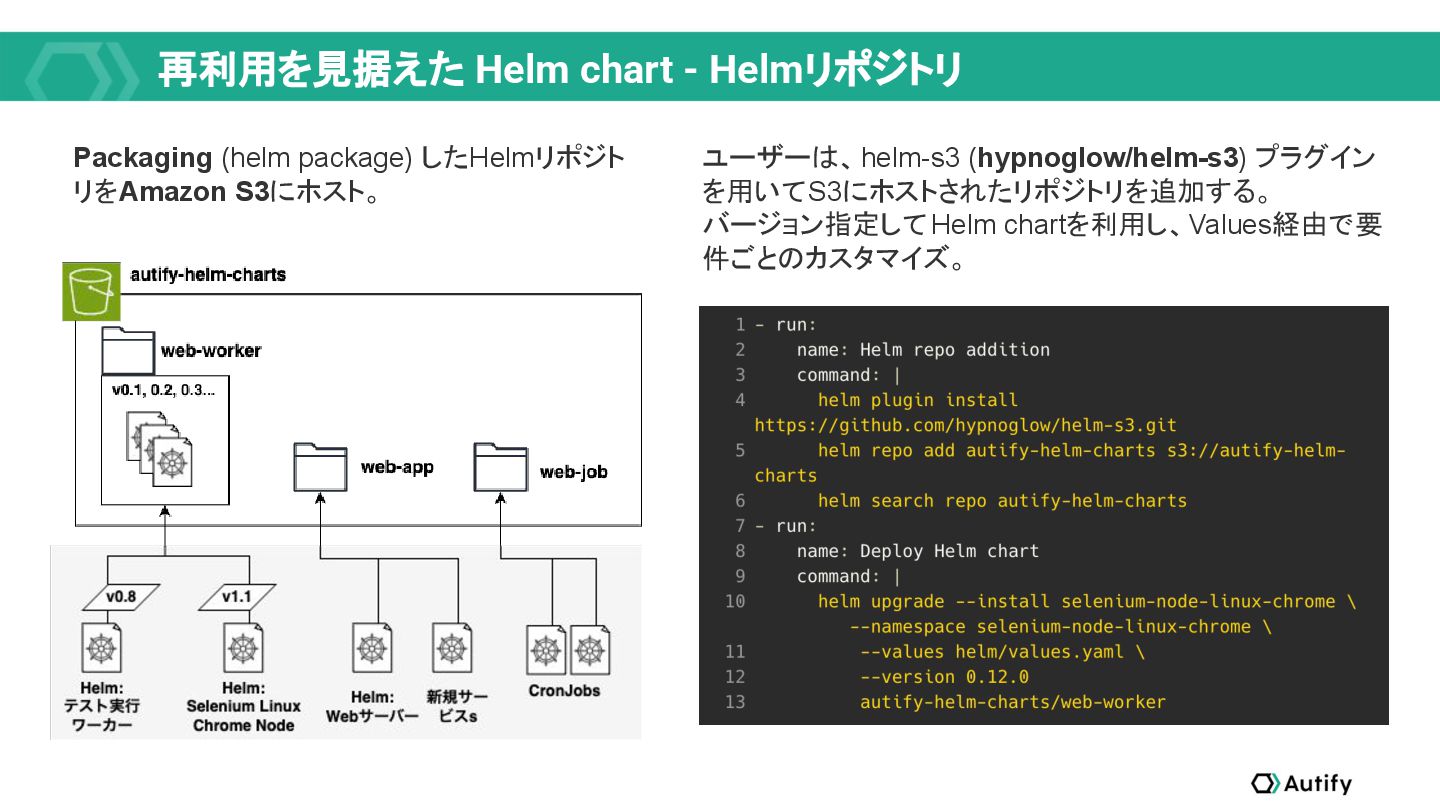{kind=link}
{kind=link}
{kind=link}
{kind=link}
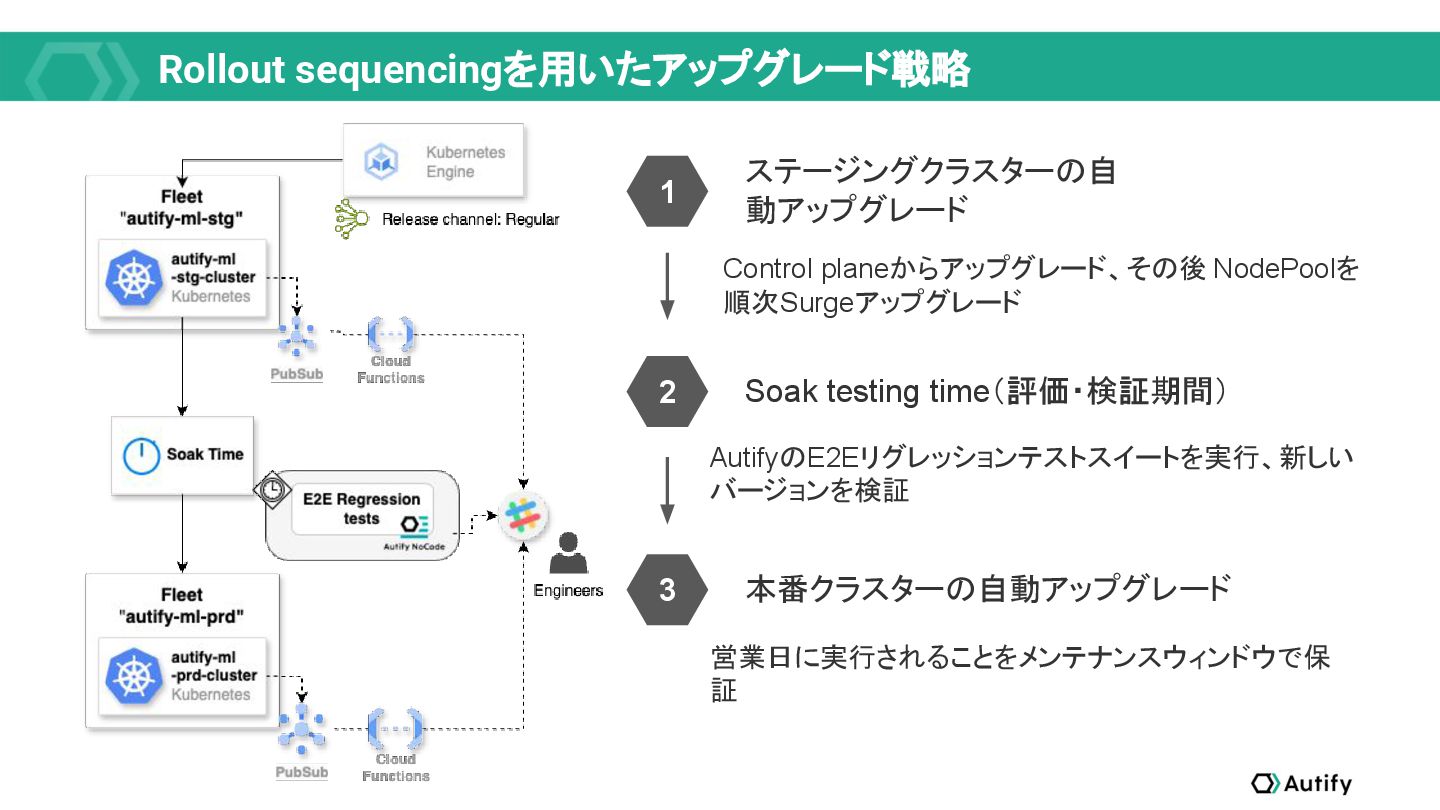{kind=link}
{kind=link}
{kind=link}
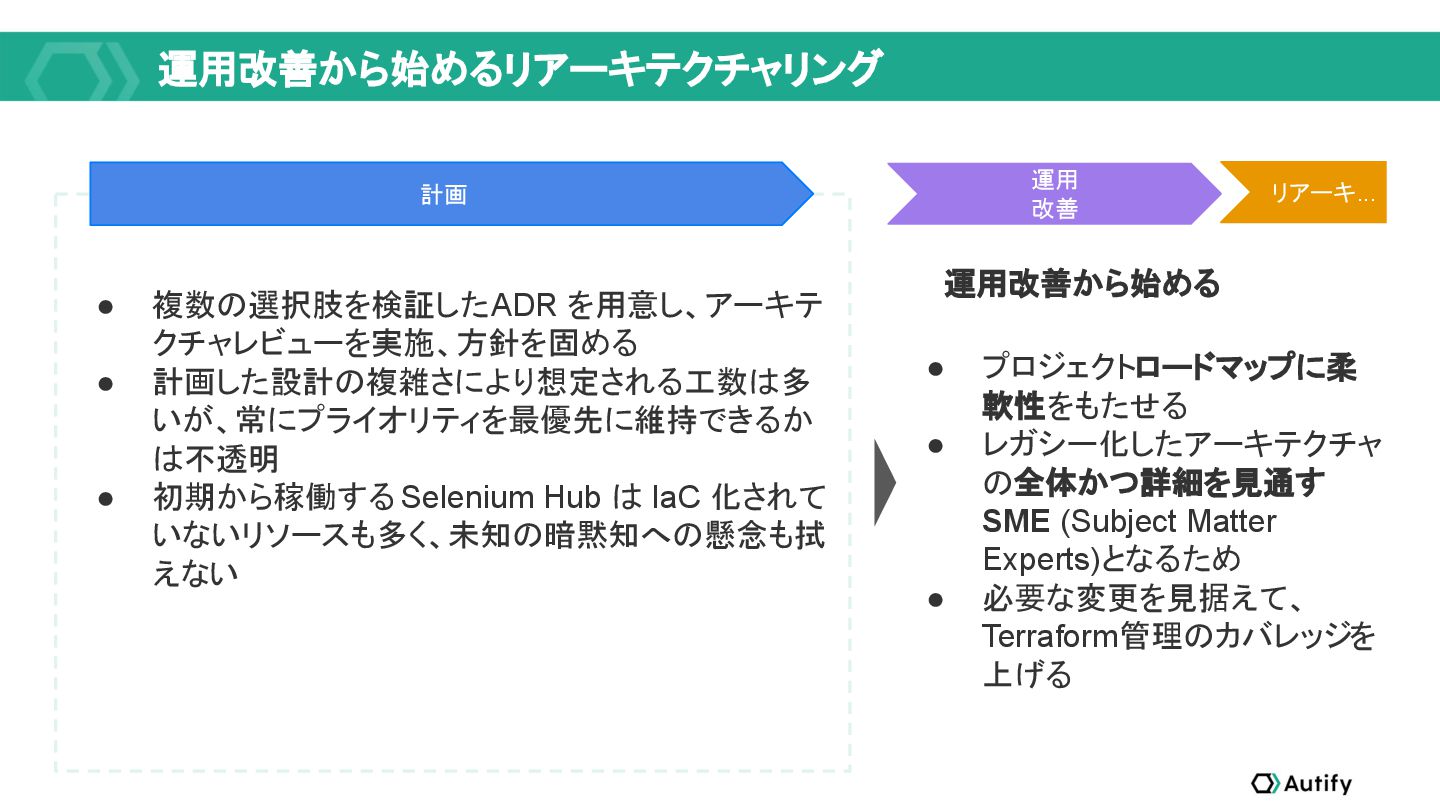{kind=link}
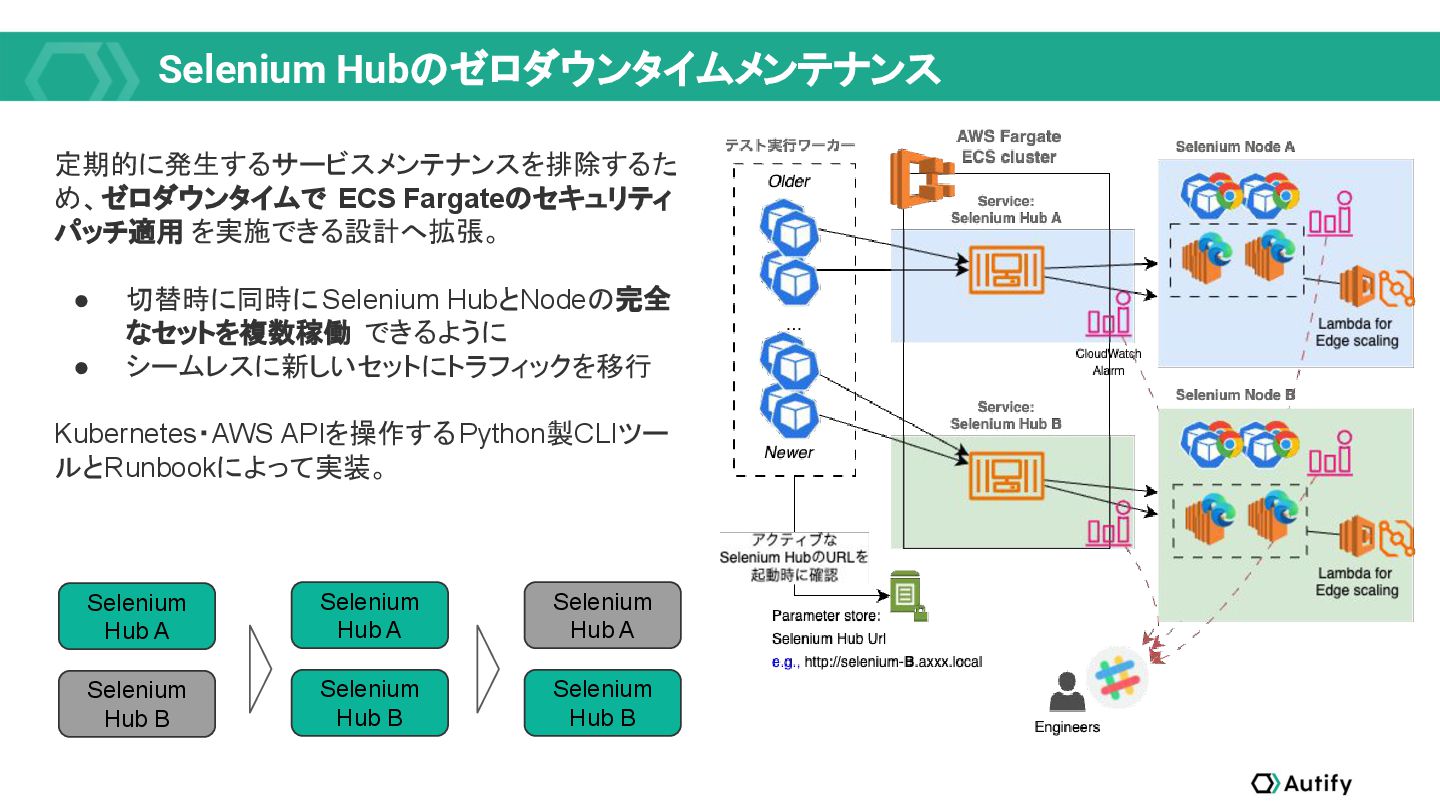{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}