1 Friday, April 12, 13 Earlier Mike said that speakers spend 6-8 weeks working on their presentations. Unfortunately most speakers only knew their talk was accepted 3 weeks ago, so they wrote it on the plane to the conference, which is why they're nervous. The timing for this talk in the schedule is fortunate, as I'm sure everyone really just wants to hear Jesse talk about ChatOps at GitHub. I do.
• System Administrator • Father, Gamer, CrossFitter totally legit mustache! 2 Friday, April 12, 13 Who am I, and how am I qualified to talk about this to you? I work for Opscode, a company that makes some automation software for operations teams and developers you might have heard of. In my role, I am a technical community manager. Basically, I write cookbooks and help others do so. I'm also a system administrator. While I'm not on call at Opscode, I have been on call for the majority of my career. And in a way, I kind of am on call for everyone's infrastructure that uses Chef and Opscode cookbooks, since I participate in front line community support via mailing lists, IRC, and twitter. You just don't get my phone number. Though, it's on my business card. I'm also a man of many interests - I like video and table top games, brewing my own beer, and I'm a husband and father. My career as a system administrator has caused many interruptions in these areas, of course.
• Business people? (Consultants?) • On call (for production)? http://www.flickr.com/photos/timyates/2854357446/ 3 Friday, April 12, 13 One thing I like to do is get an idea of whom I'm talking to
Operations people get into road block mode when all they get is code that brings the site down, and gets them paged at 2am. Whether that is reality, or survivor bias, doesn't matter. This doesn't work either.
14 Friday, April 12, 13 What we need is collaboration, and sharing. Not sharing "on call" but sharing the responsibility for the applications "you" write and "we" run.
system administration services to other large enterprise corporations in our little slice of hosting. This is for "separation of duties" or for change management/control/itil/cobit or some business reasons supposedly, but what it meant was silozation, a practice unheard of in startups and other small companies, right?
had an on call "hotpager" rotation. Each person had their own primary accounts they worked on, but one person per week was the first contact. We were all system administrators responsible only for the OS. Filesystems, network services, host-based firewall rules, security policy, user management, that kind of thing. Everyone had one of these pagers, because a) it was the early 2000's so cell phones weren't as widespread yet, and cell phones didn't get reception in the data centers (or, weren't allowed, but that's another story).
• Help desk pages "on call" • On call looks at system • On call determines alert is a full filesystem for customer data • On call pages primary sysadmin • Primary sysadmin looks at system • Primary sysadmin doesn't know what of the giant log files is safe to delete (oldest, right? Maybe!) • Primary sysadmin pages application support (sometimes the customer) 19 Friday, April 12, 13 This is probably the most common example.
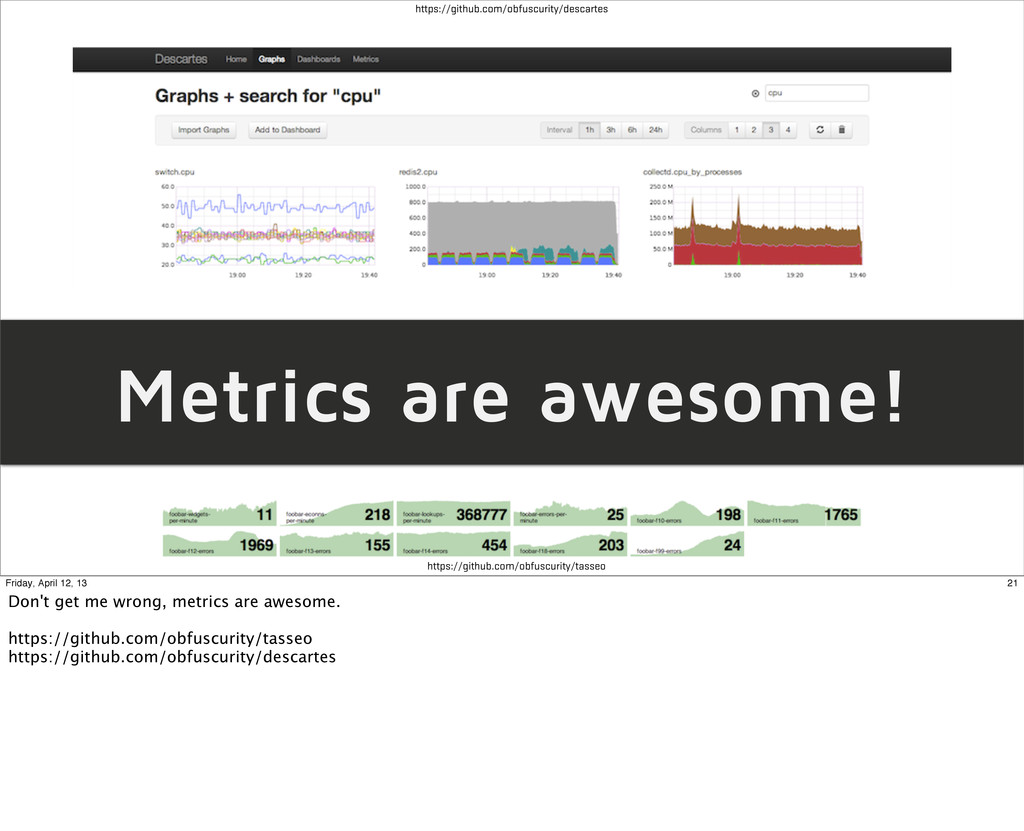
• But most of the time, this alerting is non-actionable • It isn't necessarily indicative of the problem • If it is, it's not clear why, or necessarily where to look from the outside. 22 Friday, April 12, 13 Everyone loves metrics and graphs. #monitoringlove is here to stay. But they're not super helpful without context. Sometimes, developers know the context best, when it wouldn't be obvious to anyone else. "Oh, yeah, sometimes the CPU usage goes up. There's a IO deadlock due to a janson rod misalignment."
13 What if the problem is that the application isn't starting up? Or if it's starting, it's not connecting to the database? I wasn't the DBA, I didn't know we had a schema update, or how to recover a bad partition tablespace tuple.
trends, but I don't necessarily know what is "normal" for an app, or what nuances to look for. Developers do. This is exacerbated by the high turnover rate seen in operations positions. That is, I know a lot of sysadmins who don't stay at a company more than a year or so. That means retraining on new applications all the time.
• CustomInk http://www.flickr.com/photos/g_kat26/4060301657/ "You build it, you run it." - Werner Vogels, Amazon 26 Friday, April 12, 13 I talked to operations managers or team leads some companies that have "Developers on-call" policies. Or did at the time :-). Except Amazon. That is a quote from Werner Vogels, Amazon CTO, but it's confirmed from former Amazon employees that work at, or worked at Opscode, like our own CTO Chris Brown, or founding CEO Jesse Robbins.
application domain knowledge • People like accountability, responsibility! • People don't like stress "We found that when we woke up developers at 2am, defects got fixed faster than ever" - Patrick Lightbody, ceo browsermob 27 Friday, April 12, 13 I think it is safe to say that in most companies doing web operations, there are more developers than sysadmins. In most companies I've worked in, or with, there are more developers than sysadmins across the board. These developers bring valuable application domain knowledge to the table, since generally speaking, they *wrote* the application. Also, as it turns out, at least in the companies I spoke to, people actually like the accountability and responsibility. It's empowering. What I mean by people don't like stress is twofold. First, with more developers, more people share the load of on-call rotations. This helps the operations people not be stressed out, which will improve team morale, and improve the culture.
teams are escalation • Greater collaboration • Team building, learning/knowledge transfer 28 Friday, April 12, 13 Unsurprisingly, Nagios is the most popular tool for alerting. Knowing how it works is useful, and it's a great help to operating the application if those who write it also write the checks for it. Pagerduty is likewise popular for actually managing the alerts and escalation. In all the companies I talked to, the operations team gets escalated to for resolving issues/outages that are beyond the application (network issues, firewall configuration, third party services). Collaboration between team members increased because developers worked closer with operations both for making the application easier to manage, but also in the events of an outage. This naturally leads to team building and learning/knowledge transfer.
Write application code that runs in production? • Write application code for clients? (consultants) • Are the first to get paged/called if there's a problem? 31 Friday, April 12, 13
Other talks? • Coda Hale's metrics library? https://github.com/codahale/metrics https://github.com/johnewart/ruby-metrics 33 Friday, April 12, 13 I don't have specific advice on instrumentation. There's a lot of material about this, including talks at other RubyConferences. Coda Hale's metrics library for java has inspired a lot of people to build similar libraries for other languages.
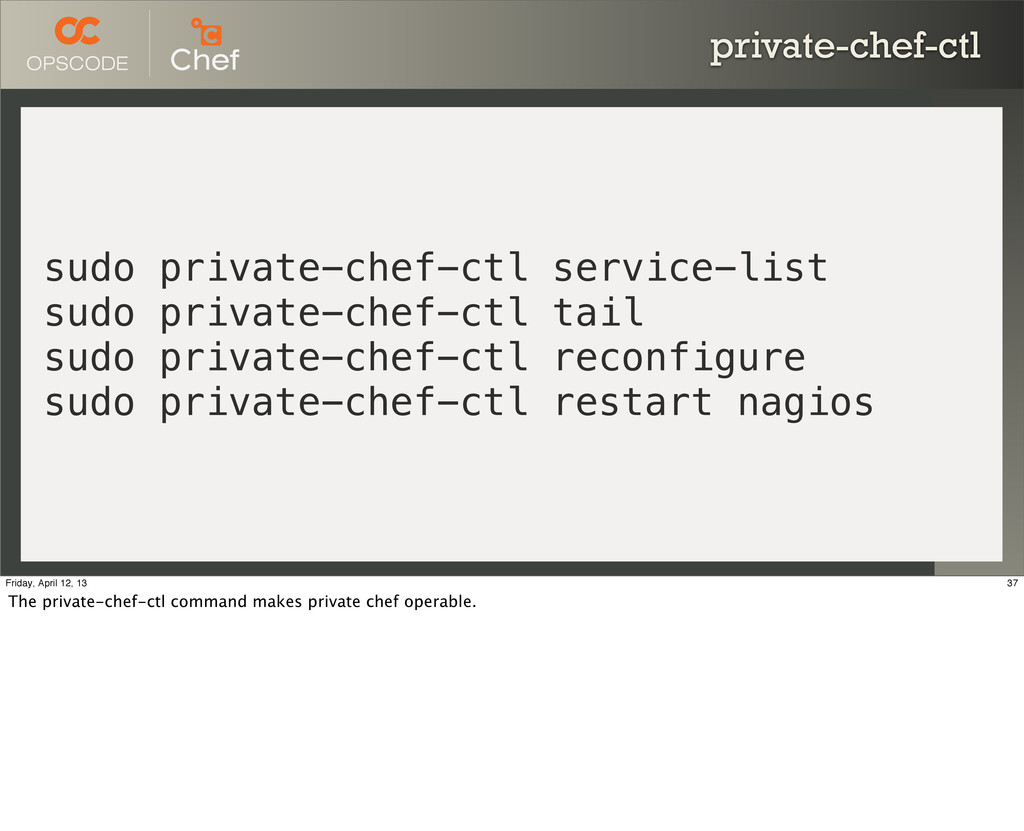
Private Chef is built on Hosted Chef, basically • There's a lot of moving parts • Enter `private-chef-ctl` 36 Friday, April 12, 13 We have Chef, and we leverage that for managing the Chef Servers.
operations team to manage. • Private Chef is easier for Opscode's customers and our support team to manage • Adapted tools for Open Source were released w/ Chef 11's Erlang port, too 38 Friday, April 12, 13 We've adapted the '-ctl' command to other products, too.
for operations • It's for you. • Future you. •3AM you. http://www.flickr.com/photos/robotson/236366629/ 39 Friday, April 12, 13 Future you will thank you.
it easier for your clients to operate the applications you've delivered to them. • This is a HUGE value add. If you have a shareable toolbox you can re-deliver, all the better. • Everyone knows this, right, but how many do it in practice? 40 Friday, April 12, 13 If you're a consultant, you may not be on call. But you can deliver more value for your customers by making it easier for them to manage, operate the app that you've written for them. Partnering with an operations focused consultant/firm can be mutually beneficial, too.
your applications operable is write the automation code for managing/deploying them. Whether that is Chef or another tool matters less than working with the operations team to automate consistently.
Friday, April 12, 13 DevOps is a professional and cultural movement. It's practices focus on the business benefits of collaboration, culture, sharing. Follow the lead from other companies and have developers be on call for production applications. This will increase their responsibility, and vested interest in building more robust, resilient applications. By having developers participate more actively in the operation of the site through response to outages, they will naturally help build better tools to operate the application.
![You Should Be On Call, too Joshua Timberman @jtimberman [email protected]](https://files.speakerdeck.com/presentations/d2c57ee085c0013088e11231381d84ba/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Joshua Timberman @jtimberman [email protected] Jez Humble on "DevOps](https://files.speakerdeck.com/presentations/d2c57ee085c0013088e11231381d84ba/slide_42.jpg){kind=link}