Wu1, Ruizhe Cheng2, Peizhao Zhang1, Peter Vajda1, Joseph E. Gonzalez2 1: Meta Reality Labs, 2: UC Berkeley 慶應義塾大学 杉浦孔明研究室 小槻誠太郎 ICLR2022 Poster B. Wu, R. Cheng, P. Zhang, T. Gao, J.E. Gonzalez, and P. Vajda, “Data efficient language-supervised zero-shot recognition with optimal transport distillation,” ICLR, 2022
{kind=link}
![概要 – OTTER 背景 CLIP[Radford+]は強力だが大量のデータが必要 画像とテキストのペアは弱く相関している 提案 画像とテキストのペアの弱い相関を考慮してInfoNCEを一般化 最適輸送を利用した画像-テキストペアの対照学習手法 OTTER](https://files.speakerdeck.com/presentations/d08b8b5d8c8741cf85317edb17cce5ad/slide_1.jpg){kind=link}
![背景 – CLIP[Radford+]は強力だが大量のデータが必要 画像とテキストのペアで対照学習 幅広い応用 一方で大量のデータが必要 ➔ 400Mペア 3](https://files.speakerdeck.com/presentations/d08b8b5d8c8741cf85317edb17cce5ad/slide_2.jpg){kind=link}
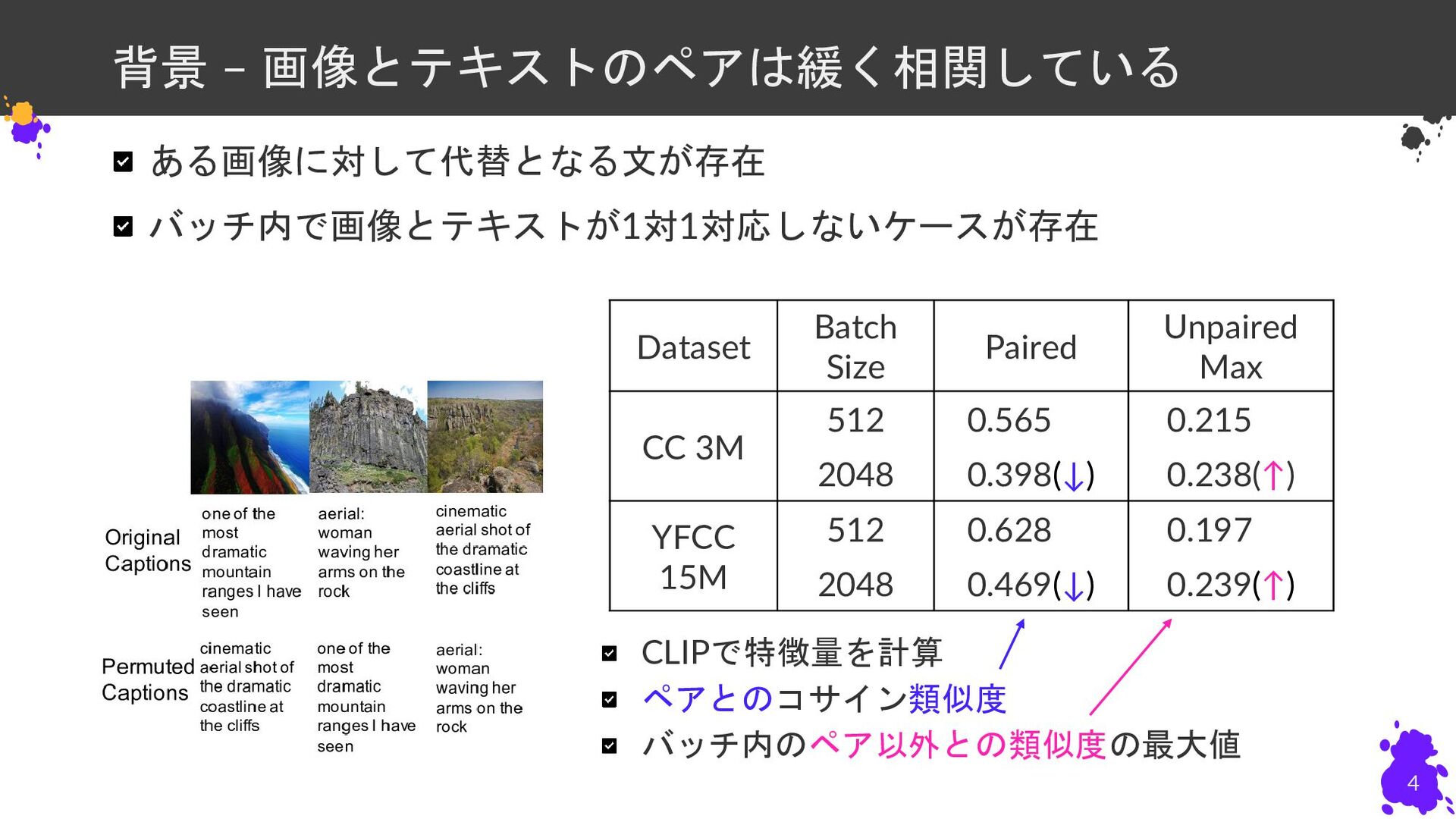{kind=link}
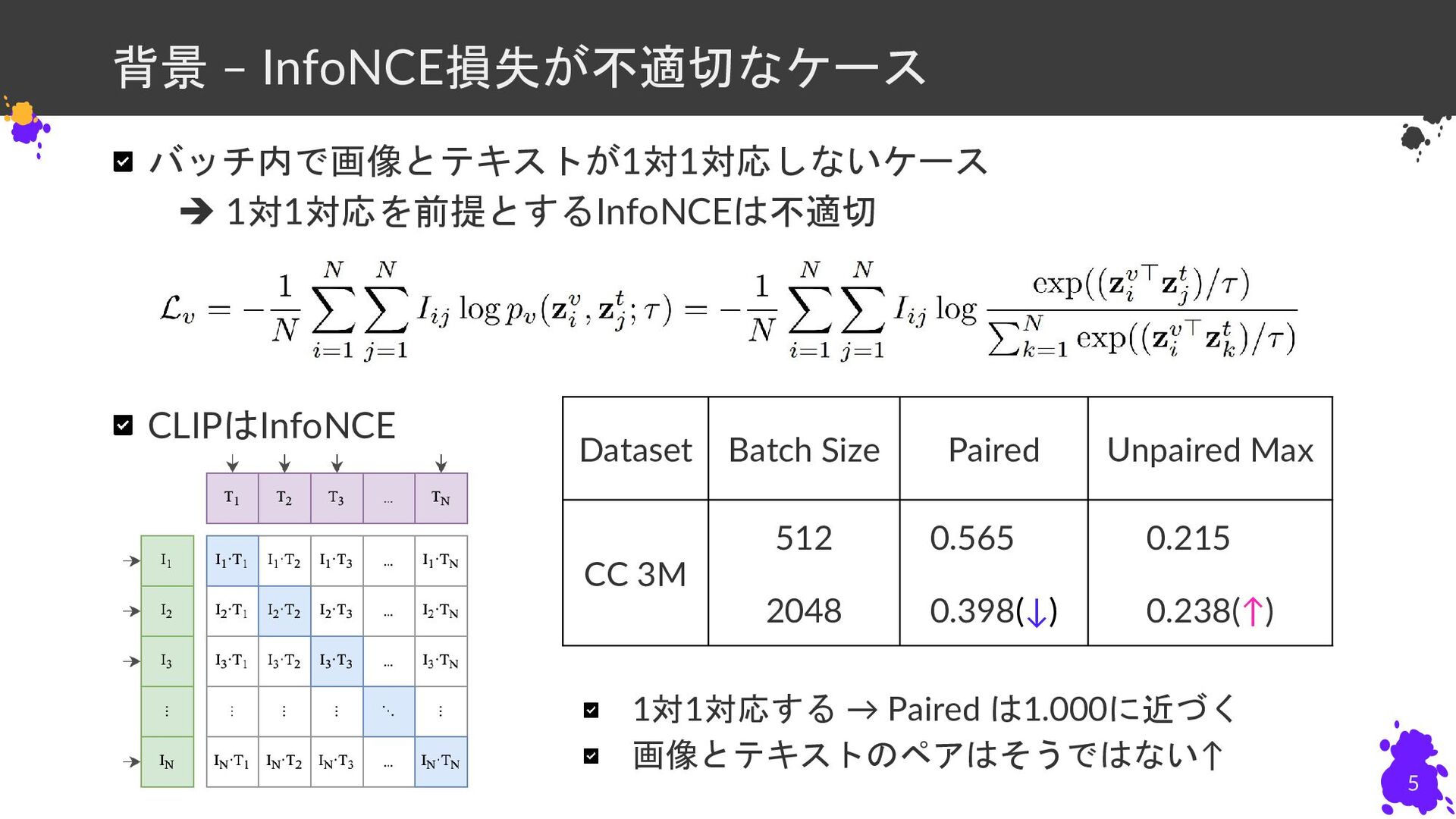{kind=link}
![関連・先行研究 – 画像-テキスト間の対照学習 6 手法 概要 CLIP [Radford+, ICML2021] (画像,](https://files.speakerdeck.com/presentations/d08b8b5d8c8741cf85317edb17cce5ad/slide_5.jpg){kind=link}
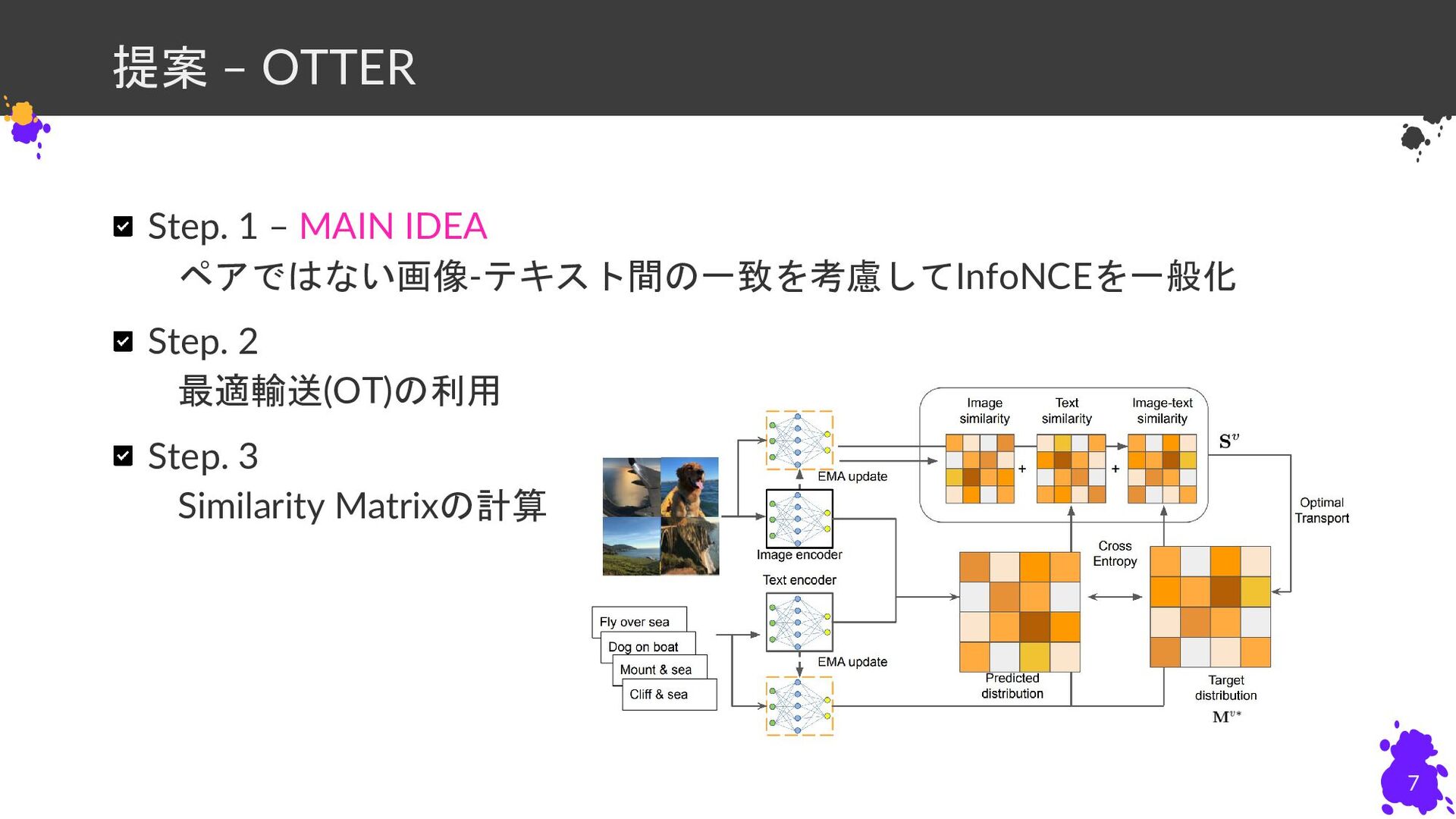{kind=link}
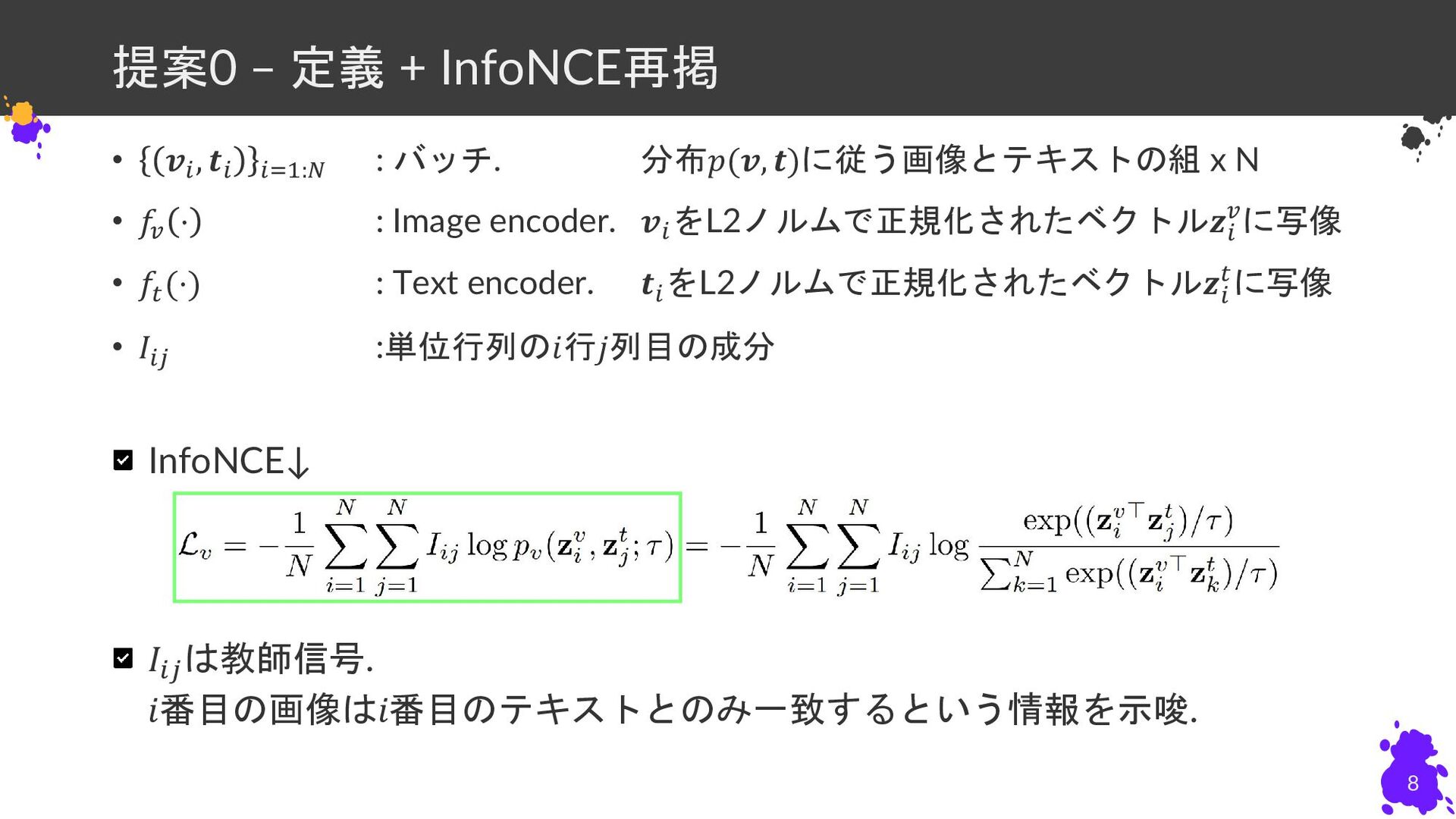{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![提案2 – 最適輸送(OT)の利用 M𝑣∗は以下の形になることが証明されている[Cuturi+, NeurIPS13] ここで𝒓, 𝒄はSinkhorn-Knoppアルゴリズムで求まる. 14](https://files.speakerdeck.com/presentations/d08b8b5d8c8741cf85317edb17cce5ad/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
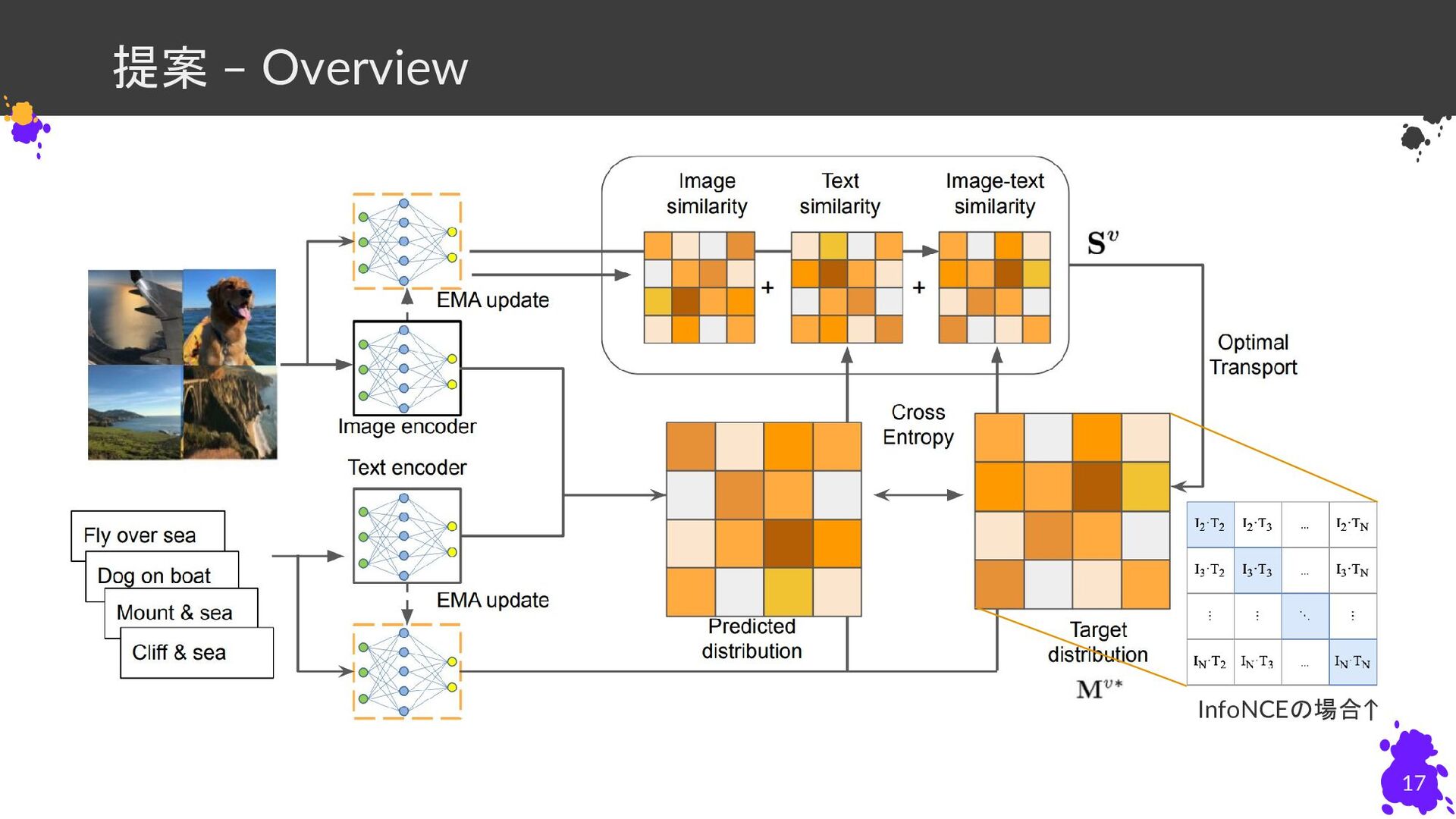{kind=link}
{kind=link}
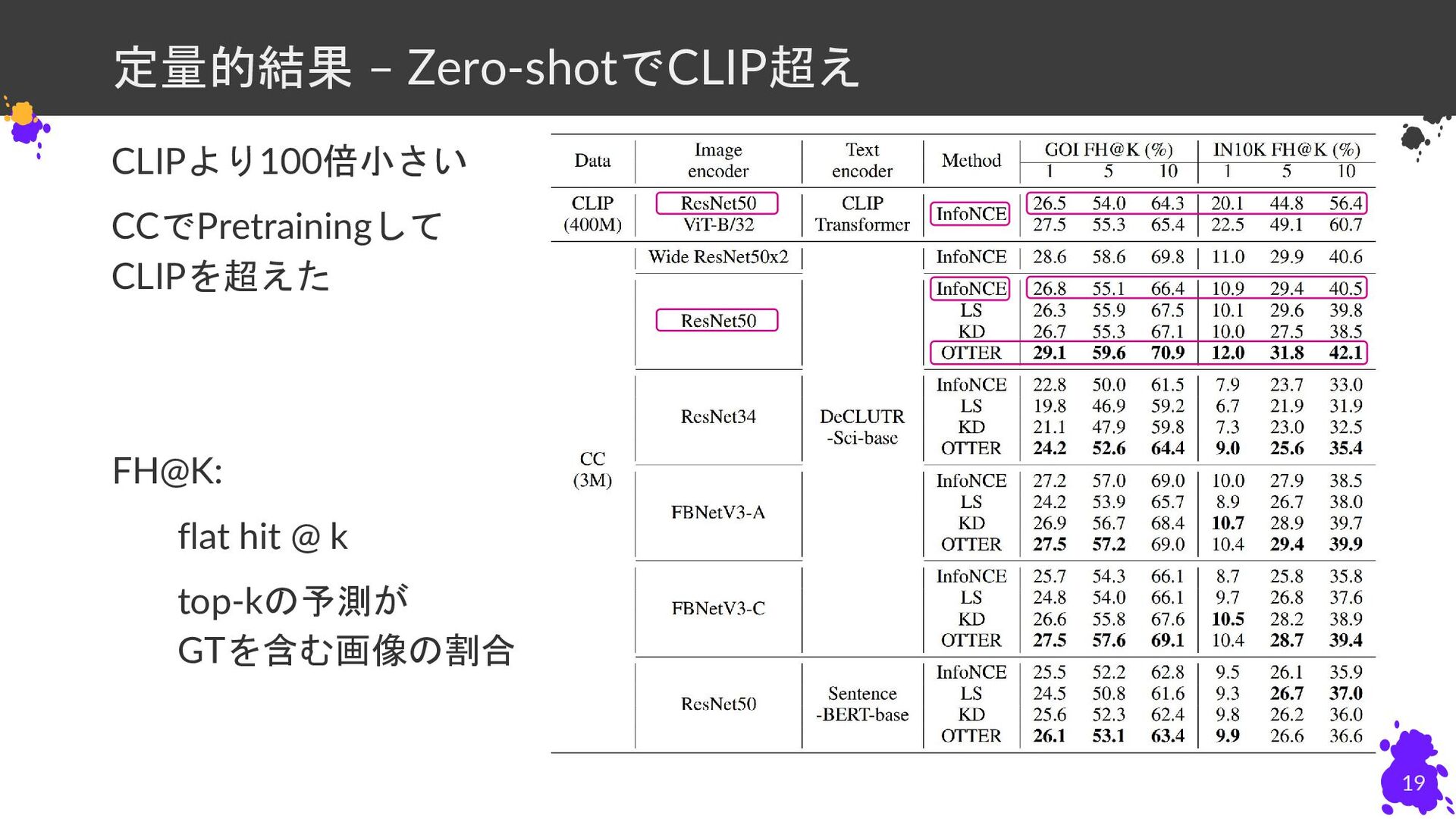{kind=link}
{kind=link}
![まとめ – OTTER 背景 CLIP[Radford+]は強力だが大量のデータが必要 画像とテキストのペアは弱く相関している 提案 画像とテキストのペアの弱い相関を考慮してInfoNCEを一般化 最適輸送を利用した画像-テキストペアの対照学習手法 OTTER](https://files.speakerdeck.com/presentations/d08b8b5d8c8741cf85317edb17cce5ad/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}