本資料は、2026/1/14開催のオンライン勉強会(AIMTG)にて発表した内容をまとめたものです。
LiDAR 点群にオルソ画像の情報を融合することで視認性や分類性能を紹介しています。
主な内容:
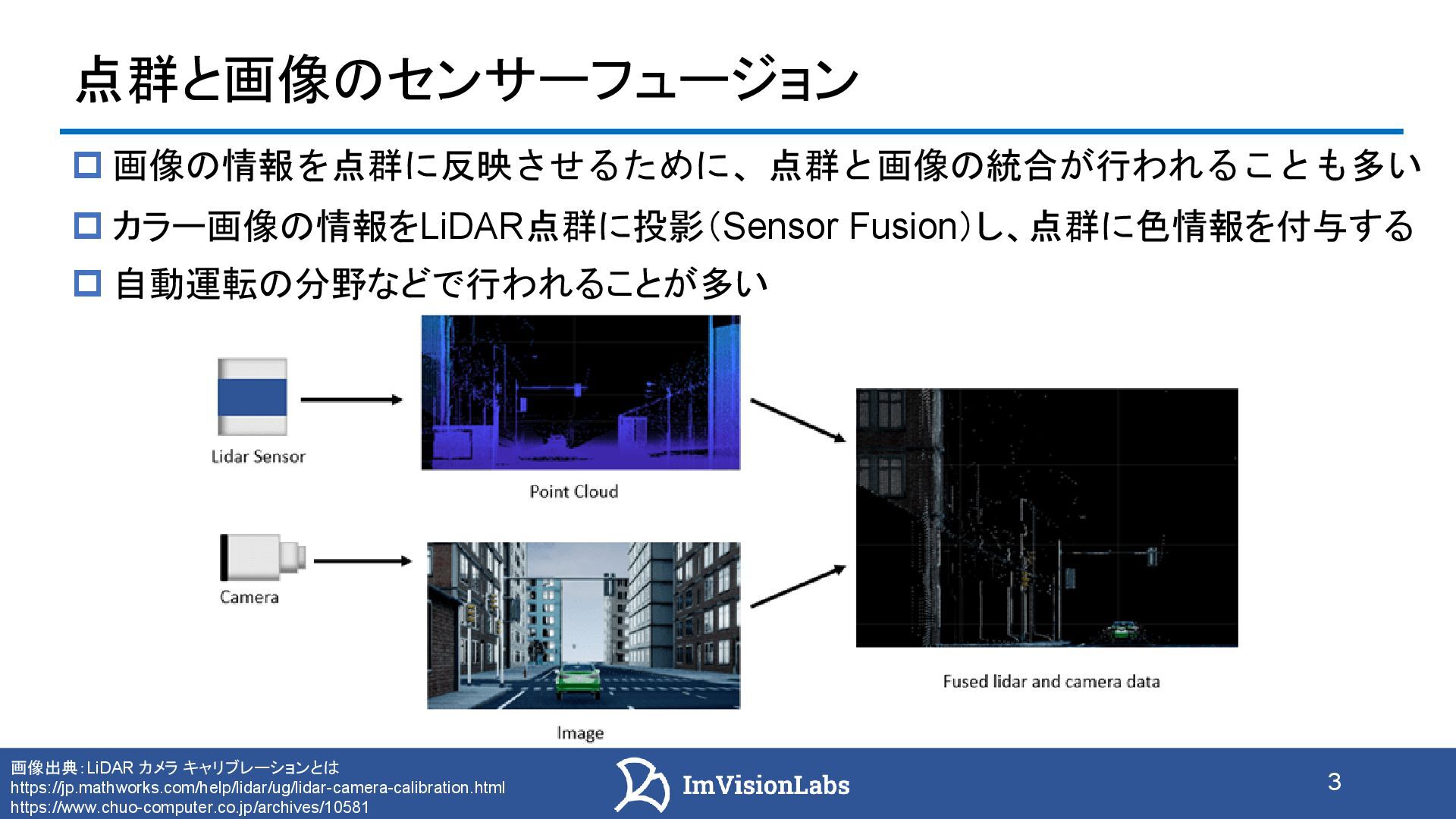
LiDAR 点群の色情報付与の意義と活用例
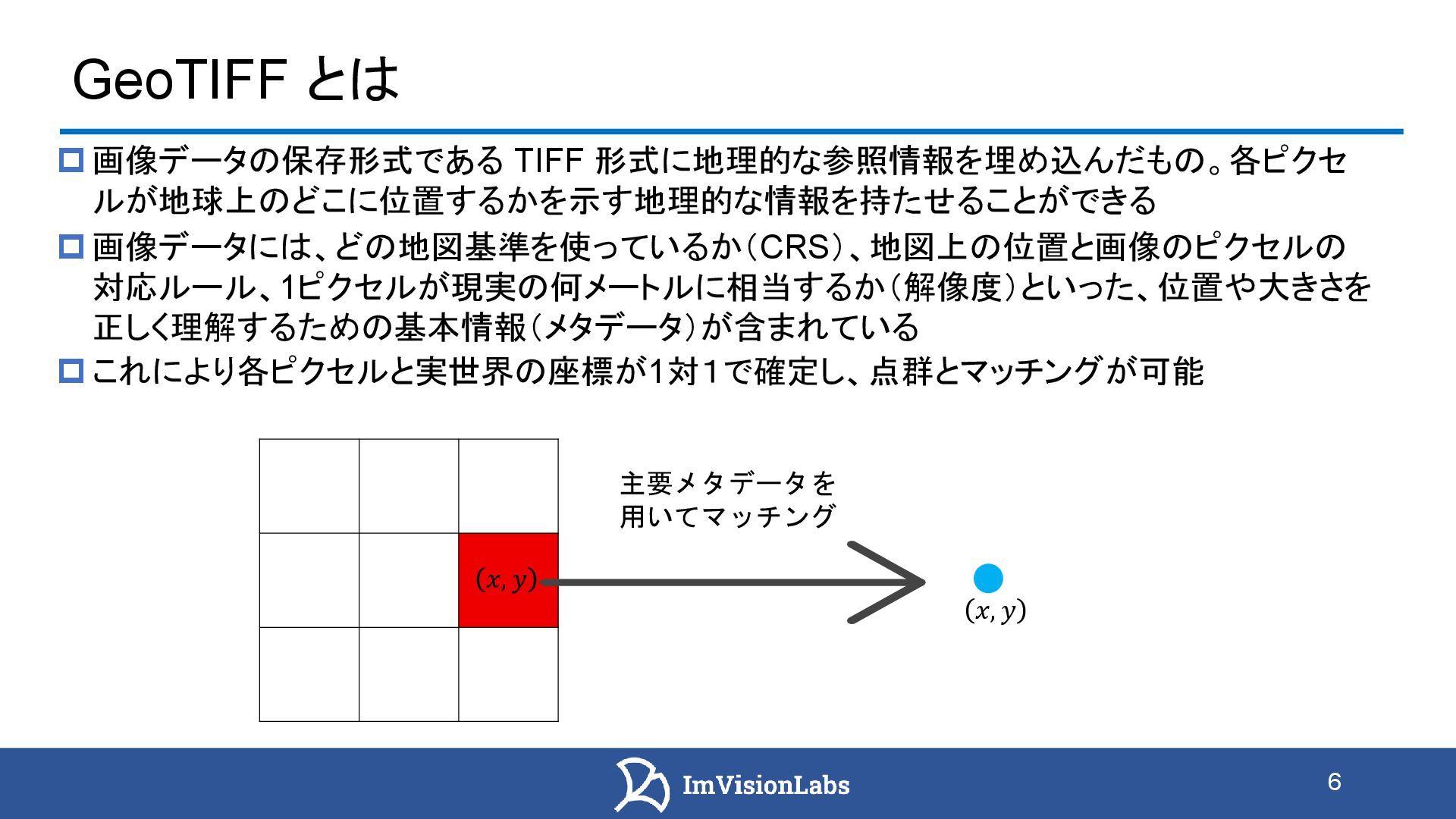
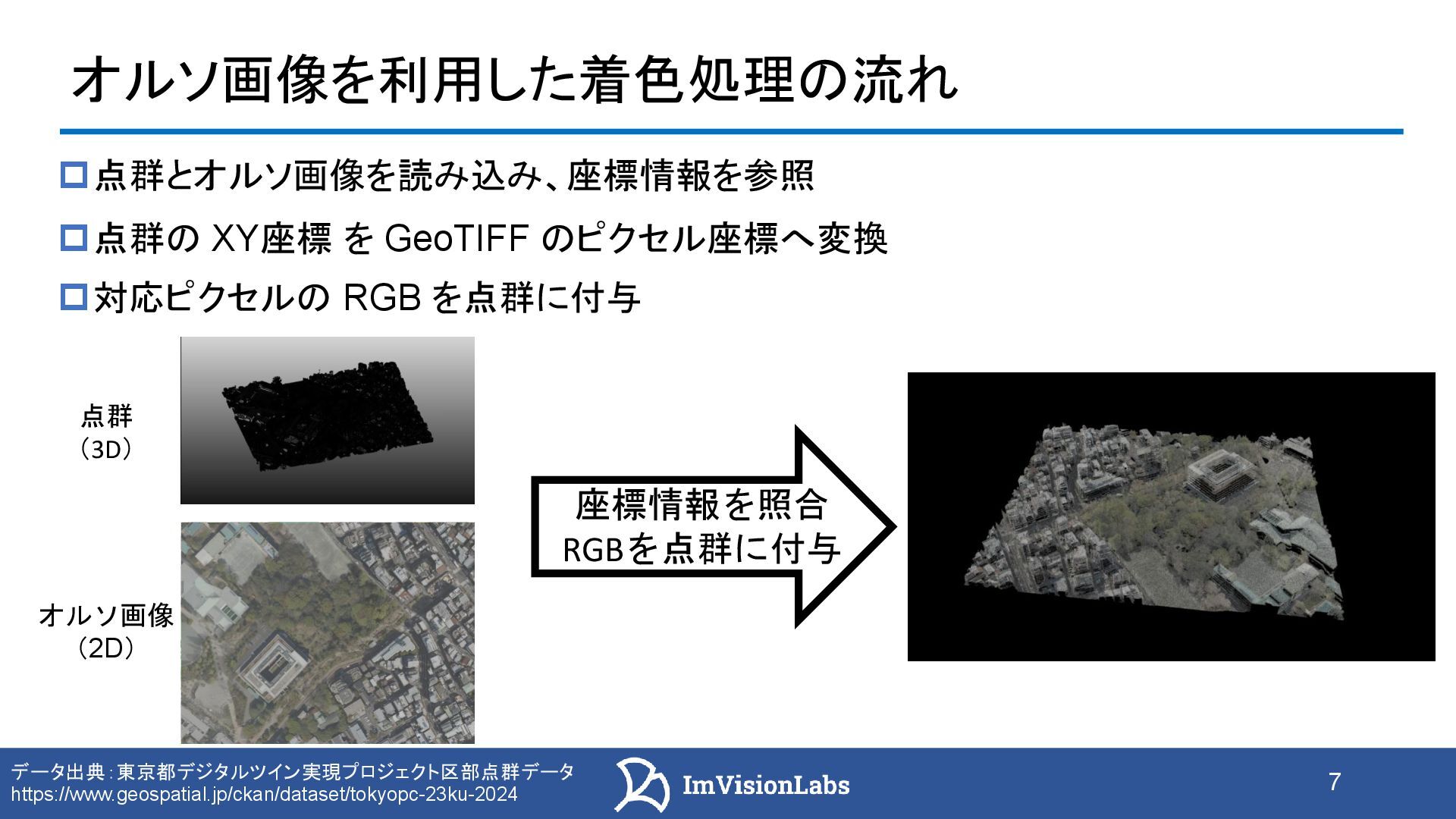
オルソ画像情報を点群に反映する手法
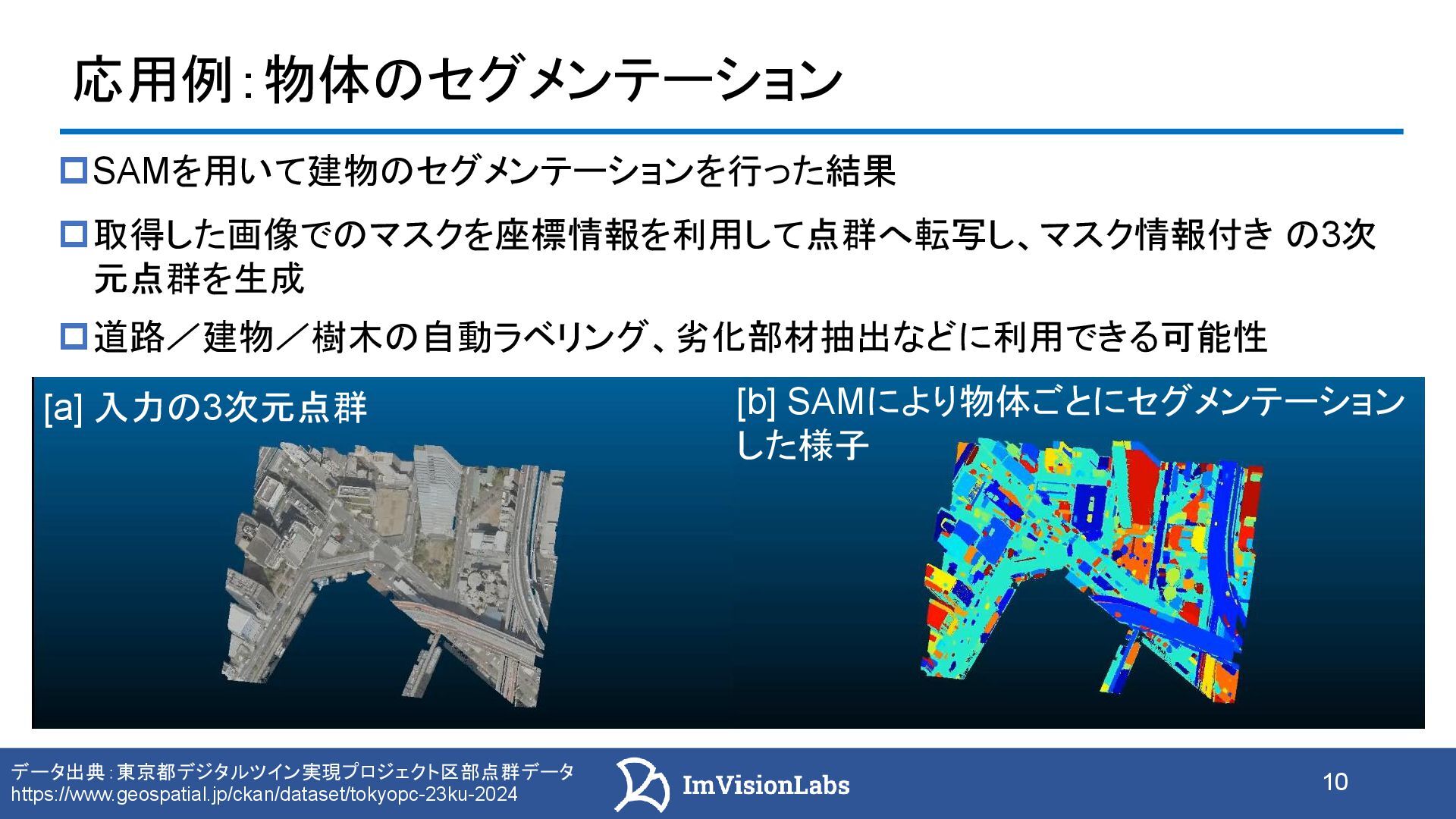
セグメンテーション(SAM)を用いた物体抽出と点群への反映
イベントページ:
https://osaka-driven-dev.connpass.com/event/378594/
Youtube動画:
https://www.youtube.com/live/A_zzsfpgrss?si=wVqU4VVUPUadZnAQ&t=2783
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![オルソ画像による点群のカラー化の結果 • 左:[a] 色情報を持たない3次元点群(着色前) • 右:[b] オルソ画像のRGB情報を付与した3次元点群(着色後) オルソ画像によるカラー化により,建物・植生・道路などの構造が視覚的に判別しやすくなった [a]](https://files.speakerdeck.com/presentations/c8c4dbd8f836417fa108e74bfbe9c0e5/slide_8.jpg){kind=link}
{kind=link}
![11 応用例:物体のセグメンテーション SAMを用いて建物のセグメンテーションを行った結果 取得した画像でのマスクを座標情報を利用して点群へ転写し、マスク情報付き の3次 元点群を生成 道路/建物/樹木の自動ラベリング、劣化部材抽出などに利用できる可能性 データ出典:東京都デジタルツイン実現プロジェクト区部点群データ https://www.geospatial.jp/ckan/dataset/tokyopc-23ku-2024 [a]](https://files.speakerdeck.com/presentations/c8c4dbd8f836417fa108e74bfbe9c0e5/slide_10.jpg){kind=link}