Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Deep Learning
Search
Abhinav Tushar
September 10, 2015
Research
300
6
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Deep Learning
Introductory talk on deep learning
Abhinav Tushar
September 10, 2015
More Decks by Abhinav Tushar
See All by Abhinav Tushar
the garden of eden
lepisma
0
110
Technology
lepisma
0
100
Bio-Inspired Computing
lepisma
0
110
Maestro
lepisma
0
140
War and Economics
lepisma
0
160
Other Decks in Research
See All in Research
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
350
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
160
COMETAを用いたデータ民主化運動の歴史
sazimai
0
130
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
590
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
610
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.5k
Using our influence and power for patient safety
helenbevan
0
370
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
290
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
290
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
140
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
570
Featured
See All Featured
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
For a Future-Friendly Web
brad_frost
183
10k
It's Worth the Effort
3n
188
29k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
BBQ
matthewcrist
89
10k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
320
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
440
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
My Coaching Mixtape
mlcsv
0
180
Leo the Paperboy
mayatellez
8
1.9k
Transcript
D E E P L E A R N I
N G
models AE / SAE RBM / DBN CNN RNN /
LSTM Memnet / NTM agenda questions What ? Why ? How ? Next ?
what why how next What ? AI technique for learning
multiple levels of abstractions directly from raw information
what why how next Primitive rule based AI Tailored systems
Hand Crafted Program Output Input
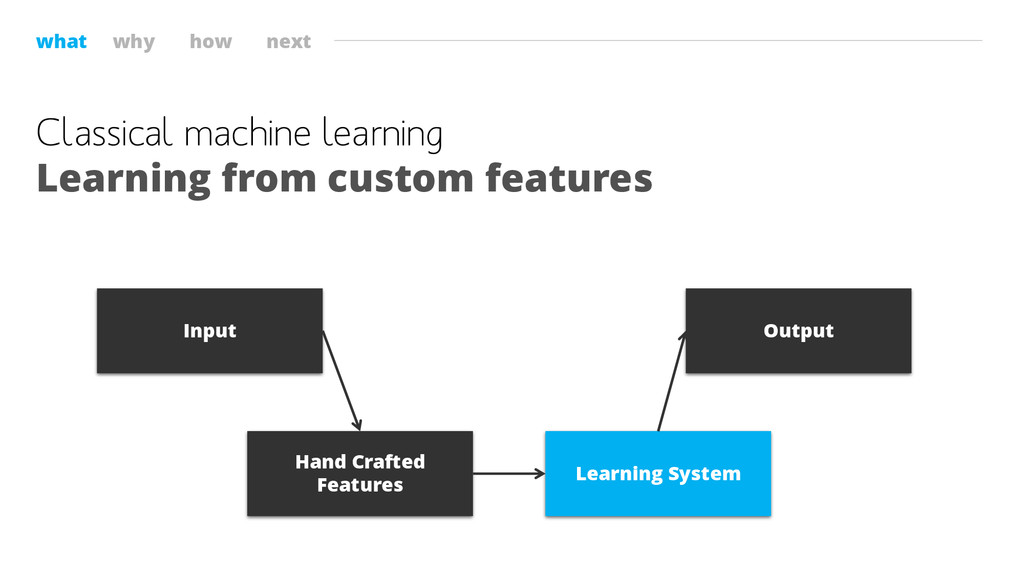
what why how next Classical machine learning Learning from custom
features Hand Crafted Features Learning System Output Input
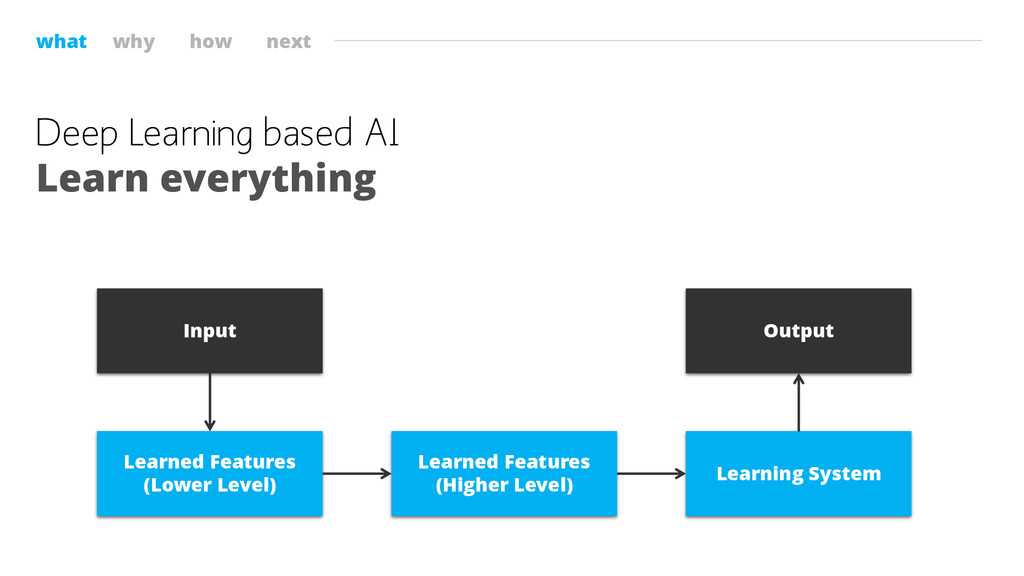
what why how next Deep Learning based AI Learn everything
Learned Features (Lower Level) Learned Features (Higher Level) Learning System Output Input
None
https://www.youtube.com/watch?v=Q70ulPJW3Gk PPTX PDF (link to video below)
With the capacity to represent the world in signs and
symbols, comes the capacity to change it Elizabeth Kolbert (The Sixth Extinction) “
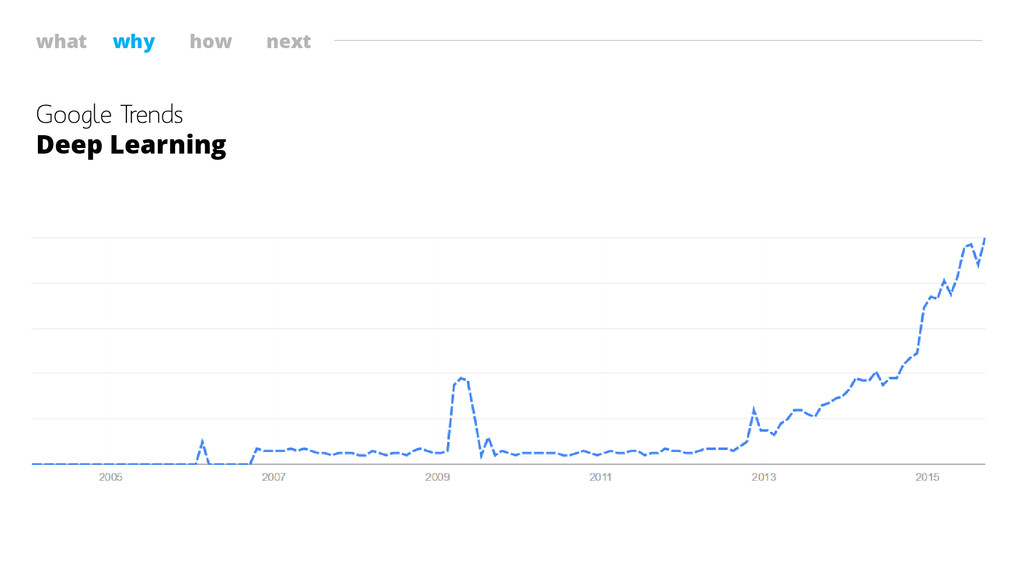
Why The buzz ?
what why how next Google Trends Deep Learning
what why how next
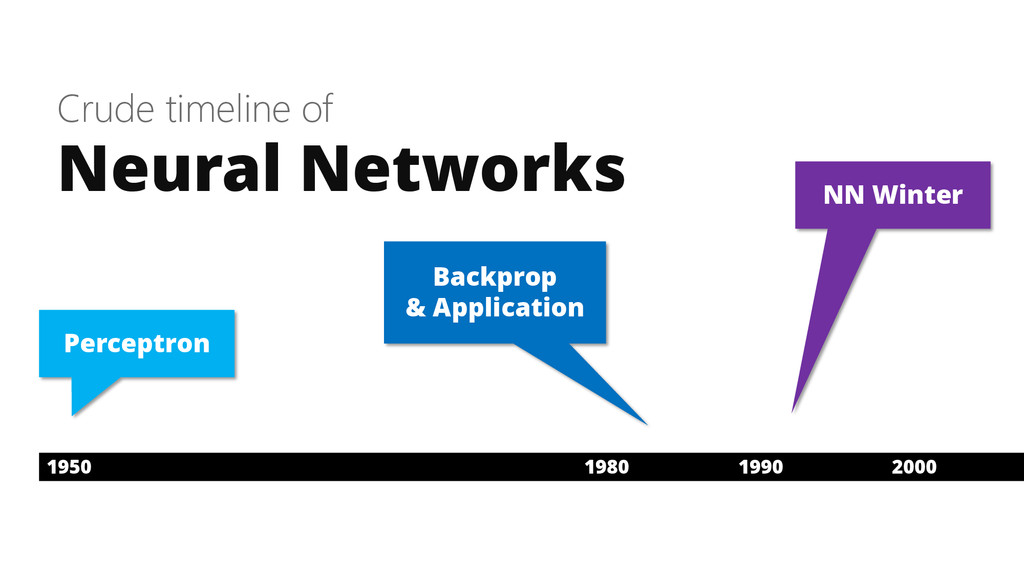
Crude timeline of Neural Networks 1950 1980 1990 2000 Perceptron
Backprop & Application NN Winter
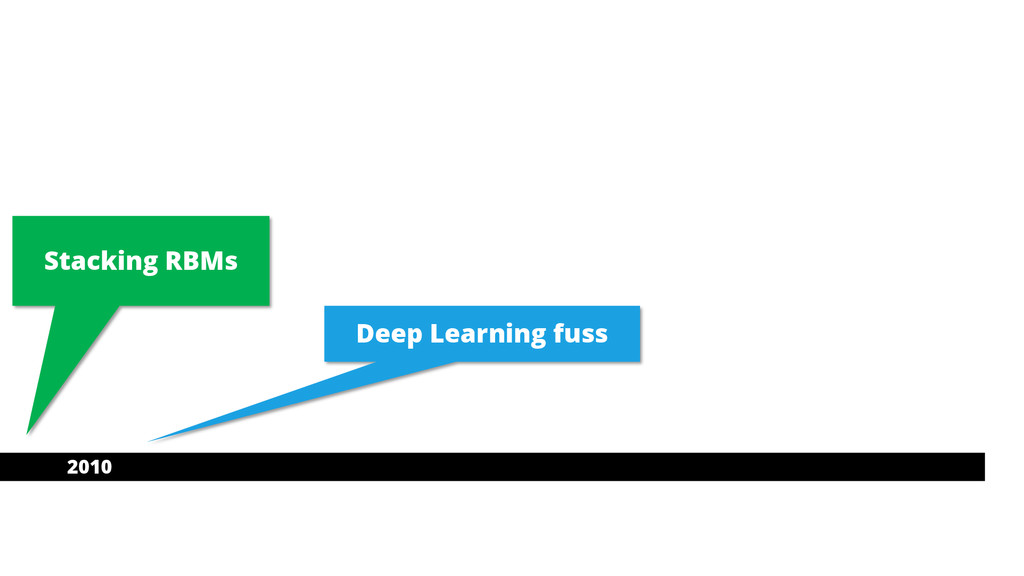
2010 Stacking RBMs Deep Learning fuss
HUGE DATA Large Synoptic Survey Telescope (2022) 30 TB/night
HUGE CAPABILITIES GPGPU ~20x speedup Powerful Clusters
HUGE SUCCESS Speech, text understanding Robotics / Computer Vision Business
/ Big Data Artificial General Intelligence (AGI)
How its done ?
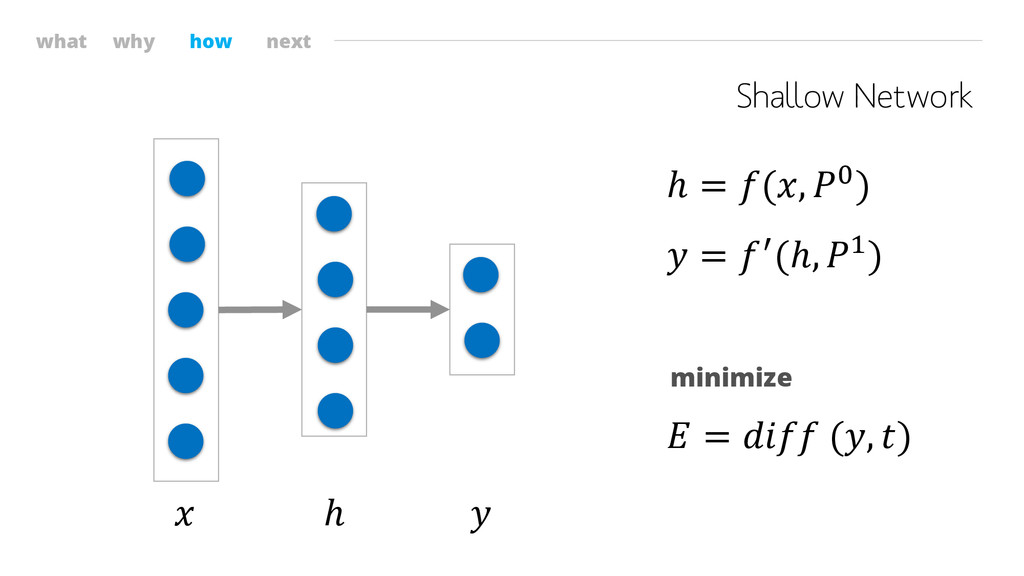
what why how next Shallow Network ℎ ℎ = (,
0) = ′(ℎ, 1) = (, ) minimize
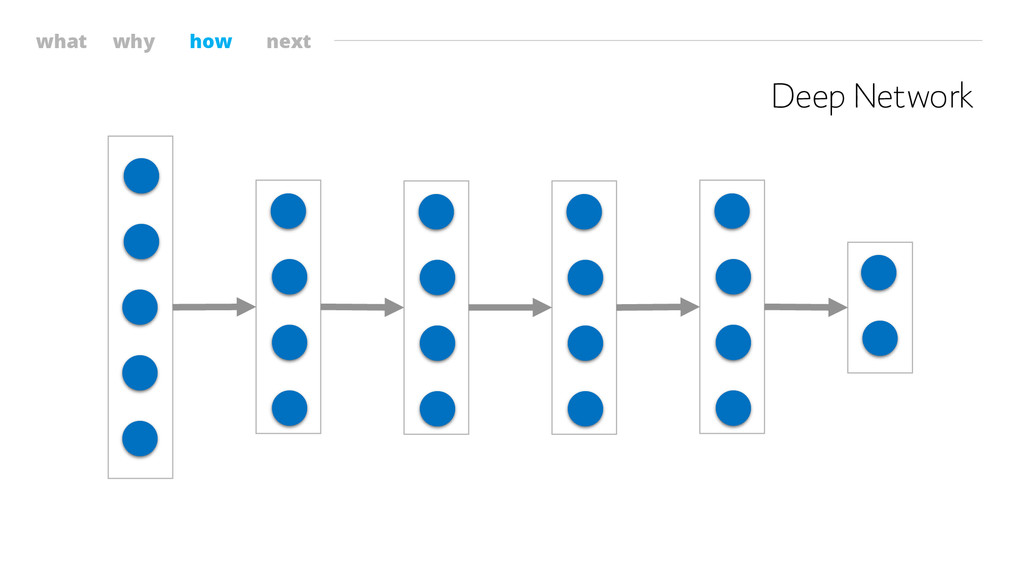
what why how next Deep Network
what why how next Deep Network More abstract features Stellar
performance Vanishing Gradient Overfitting
what why how next Autoencoder ℎ Unsupervised Feature Learning
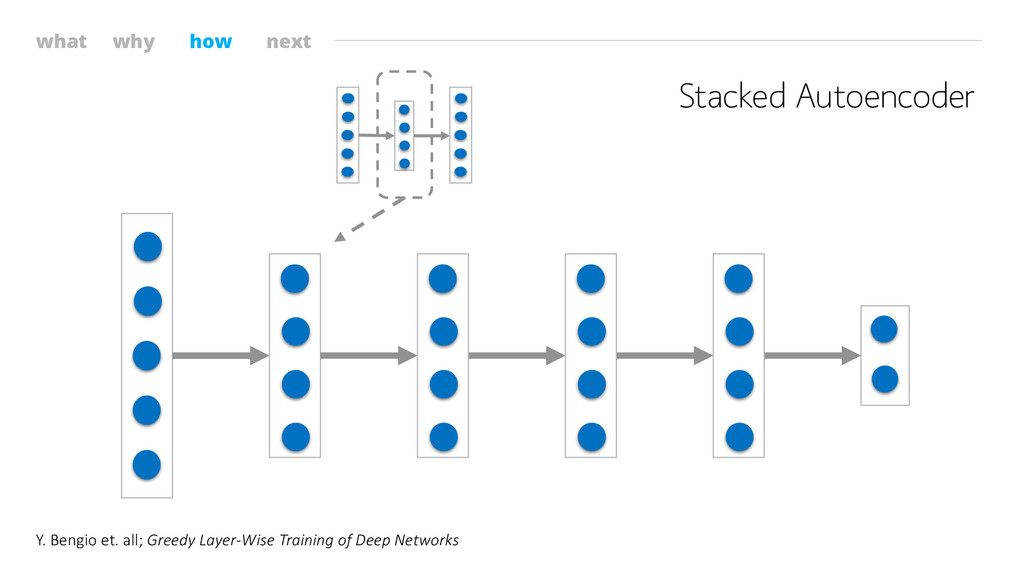
what why how next Stacked Autoencoder Y. Bengio et. all;
Greedy Layer-Wise Training of Deep Networks
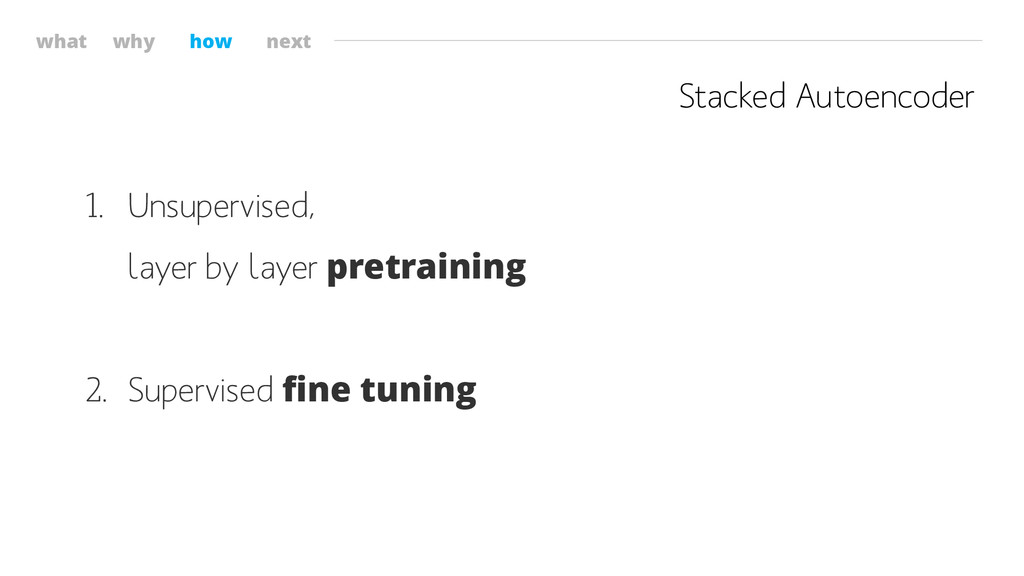
what why how next Stacked Autoencoder 1. Unsupervised, layer by
layer pretraining 2. Supervised fine tuning
what why how next Deep Belief Network 2006 breakthrough Stacking
Restricted Boltzmann Machines (RBMs) Hinton, G. E., Osindero, S. and Teh, Y.; A fast learning algorithm for deep belief nets
Rethinking Computer Vision
what why how next Traditional Image Classification pipeline Feature Extraction
(SIFT, SURF etc.) Classifier (SVM, NN etc.)
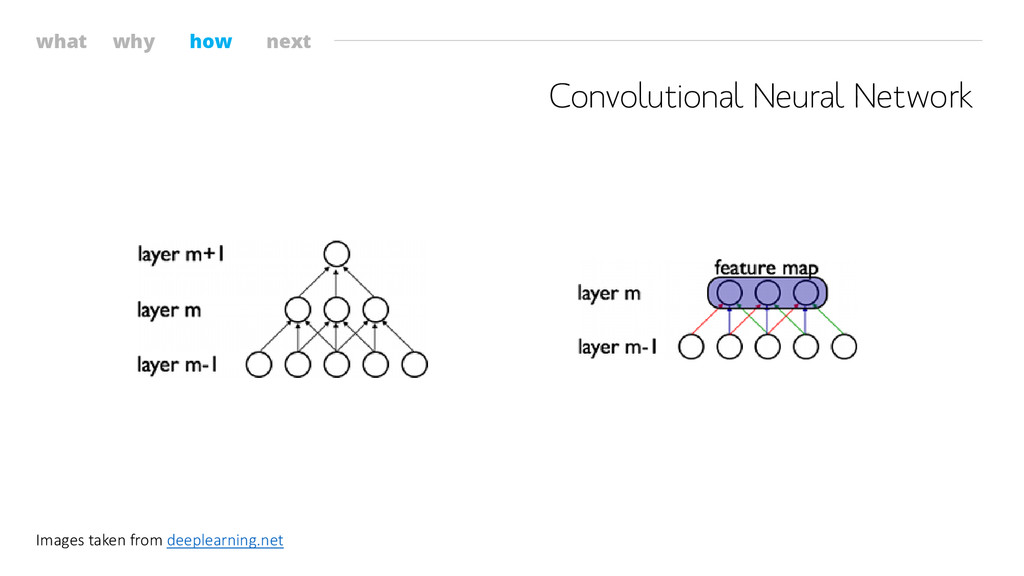
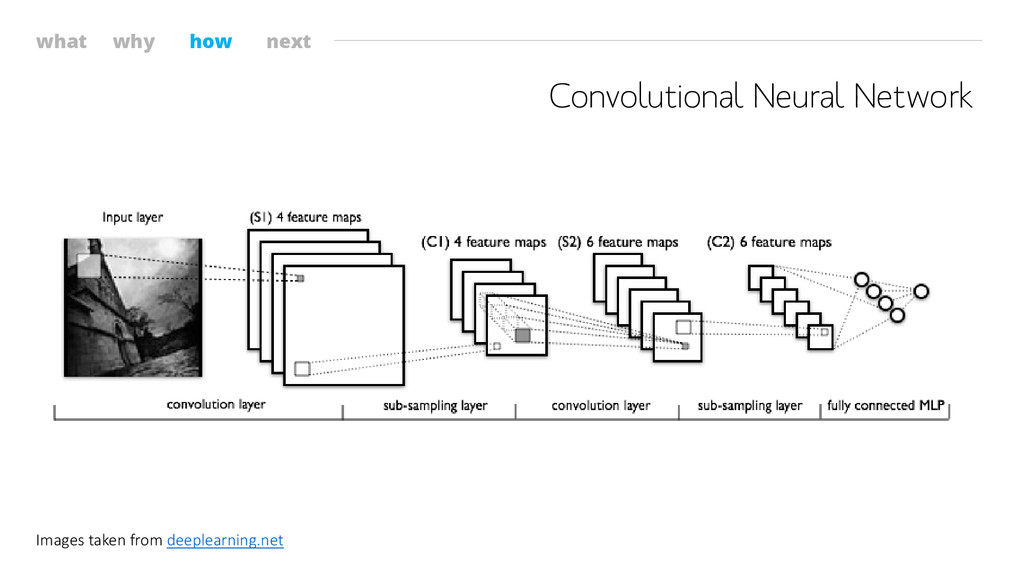
what why how next Convolutional Neural Network Images taken from
deeplearning.net
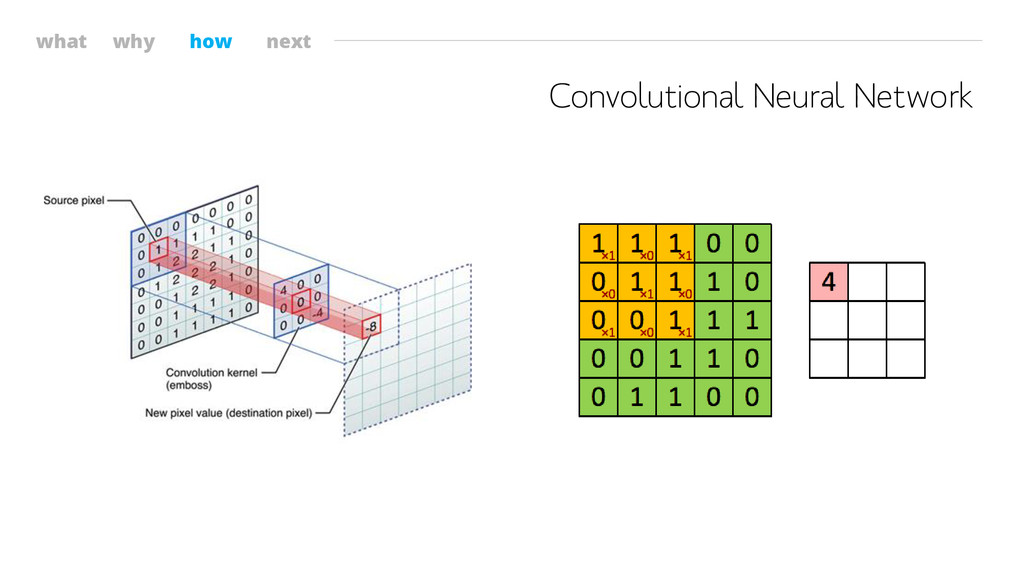
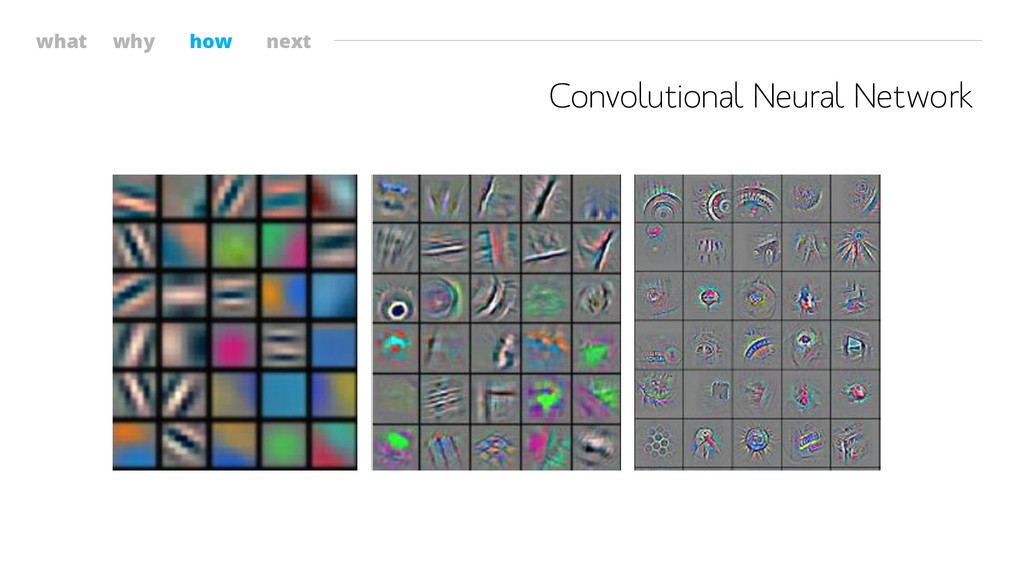
what why how next Convolutional Neural Network
what why how next Convolutional Neural Network Images taken from
deeplearning.net
what why how next Convolutional Neural Network
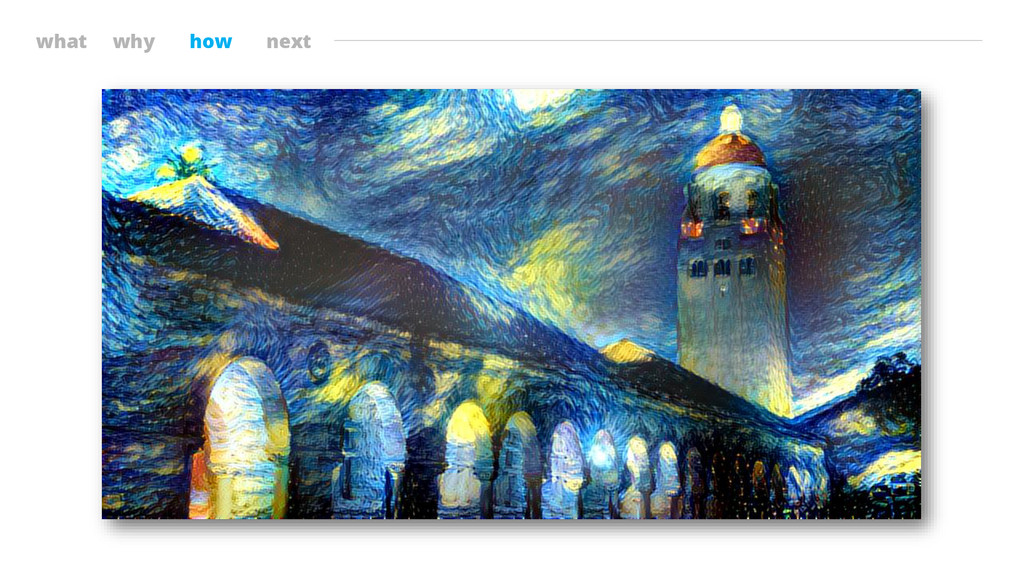
what why how next The Starry Night Vincent van Gogh
Leon A. Gatys, Alexander S. Ecker and Matthias Bethge; A Neural Algorithm of Artistic Style
what why how next
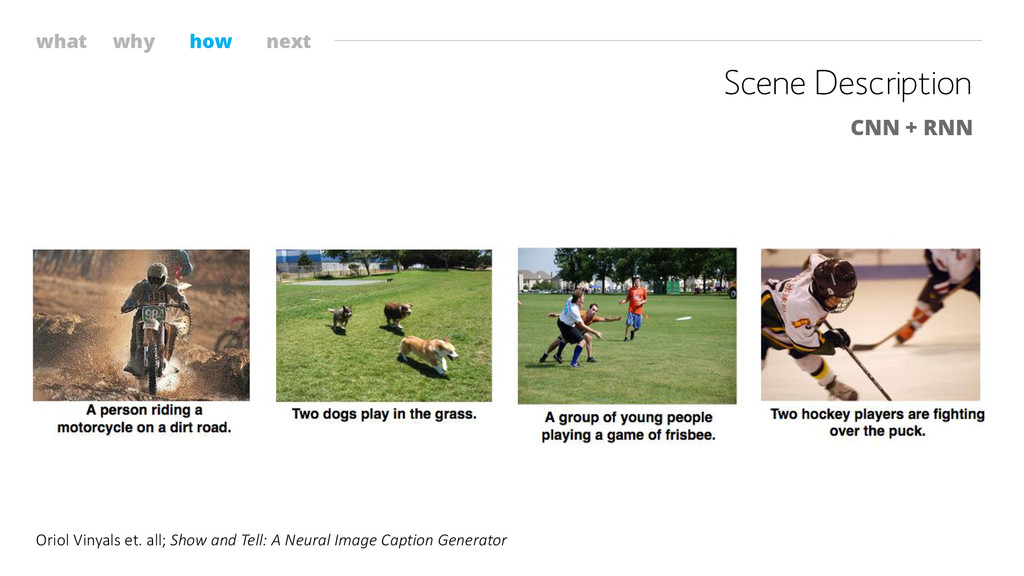
what why how next Scene Description CNN + RNN Oriol
Vinyals et. all; Show and Tell: A Neural Image Caption Generator
Learning Sequences
what why how next Recurrent Neural Network Simple Elman Version
ℎ ℎ = ( , ℎ−1 , 0, 1) = ′(ℎ , 2)
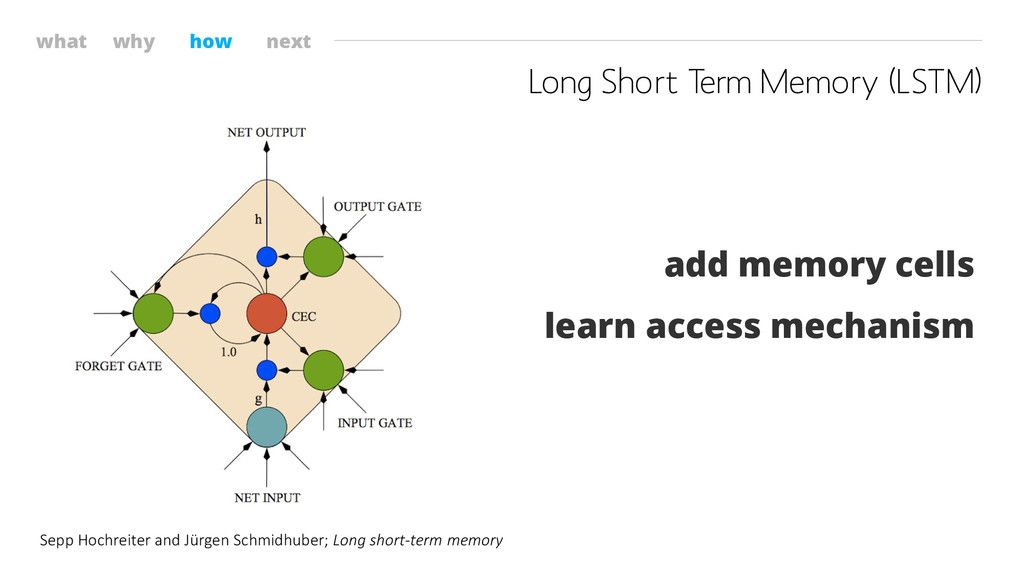
what why how next Long Short Term Memory (LSTM) add
memory cells learn access mechanism Sepp Hochreiter and Jürgen Schmidhuber; Long short-term memory
None
what why how next
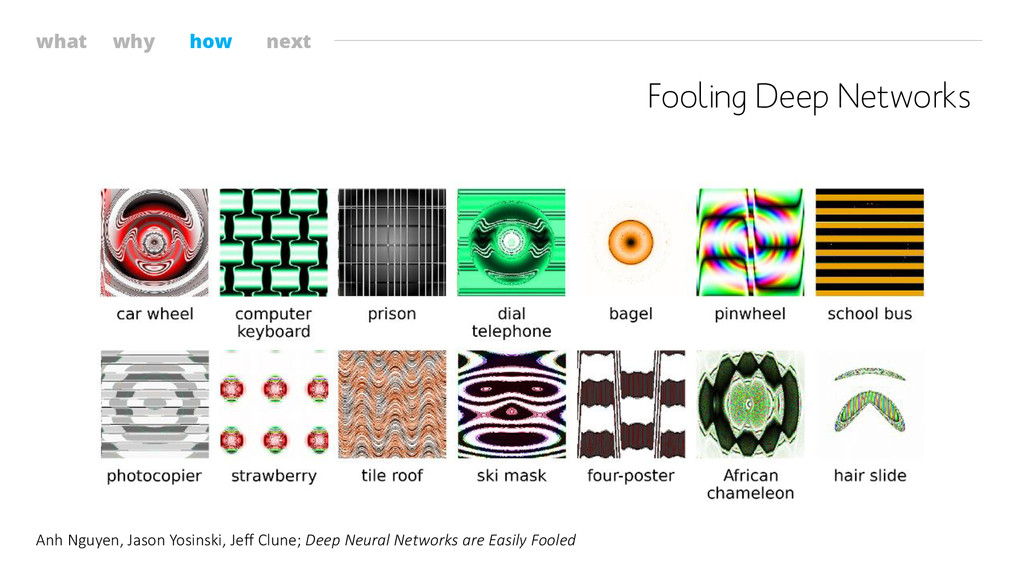
what why how next Fooling Deep Networks Anh Nguyen, Jason
Yosinski, Jeff Clune; Deep Neural Networks are Easily Fooled
Next Cool things to try
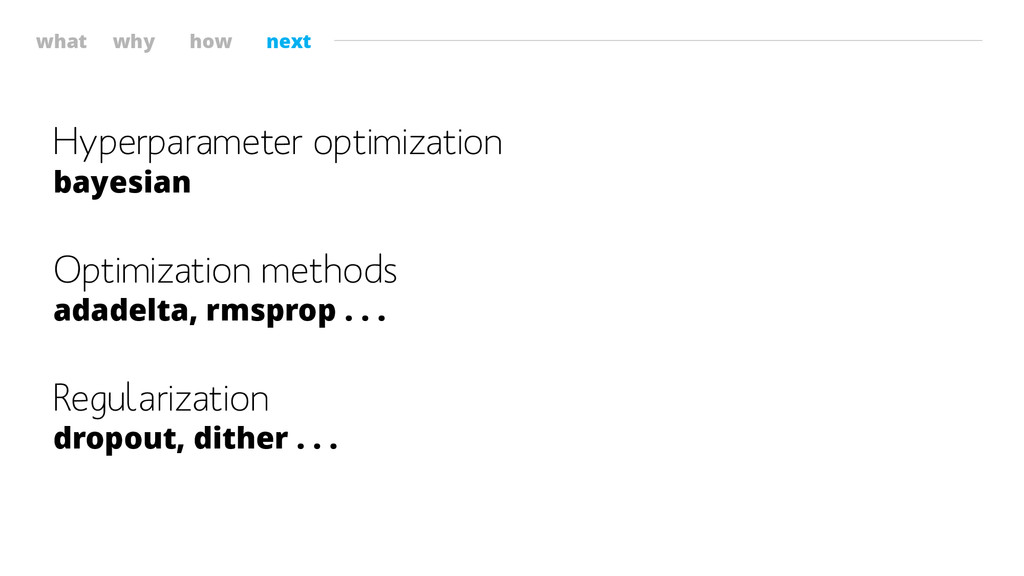
what why how next Hyperparameter optimization bayesian Optimization methods adadelta,
rmsprop . . . Regularization dropout, dither . . .
what why how next Attention & Memory NTMs, Memory Networks,
Stack RNNs . . . NLP Translation, description
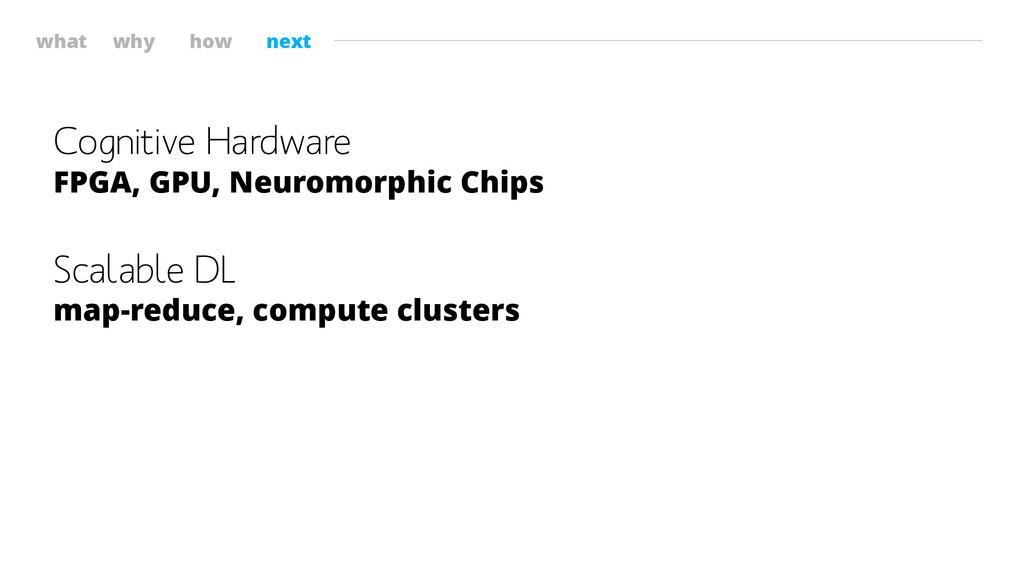
what why how next Cognitive Hardware FPGA, GPU, Neuromorphic Chips
Scalable DL map-reduce, compute clusters
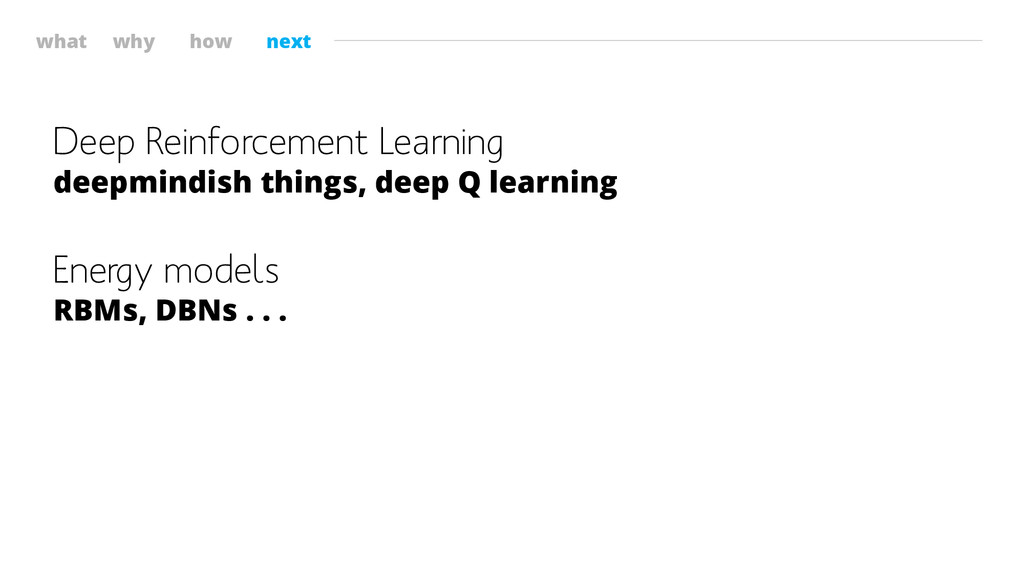
what why how next Deep Reinforcement Learning deepmindish things, deep
Q learning Energy models RBMs, DBNs . . .
https://www.reddit.com/r/MachineLearning/wiki
Theano (Python) | Torch (lua) | Caffe (C++) Github is
a friend
@AbhinavTushar ?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}