Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Apache Kafkaでの大量データ処理がKubenetesで簡単にできて嬉しかった話
Search
システム開発部広報委員会
PRO
November 21, 2023
Programming
19
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Apache Kafkaでの大量データ処理がKubenetesで簡単にできて嬉しかった話
システム開発部広報委員会
PRO
November 21, 2023
More Decks by システム開発部広報委員会
See All by システム開発部広報委員会
Rancherで実現した、クラウドに頼らない低コストな次世 代データレイク
microaddevelopers
PRO
0
20
オンプレ環境でIcebergを運用して分かったテーブルメンテナンスの重要性
microaddevelopers
PRO
0
27
徹底比較!LonghornとCephのアーキテクチャ&パフォーマンス
microaddevelopers
PRO
0
260
マイクロアドでの Hive → Iceberg 移行事例紹介
microaddevelopers
PRO
1
130
Rancher × Hashicorp Vault で 実現する秘密情報管理
microaddevelopers
PRO
1
65
大規模システムを支える実践的インフラ基盤の開発と運用
microaddevelopers
PRO
0
93
マイクロアドのData LakehouseとIcebergテーブルの最適化について
microaddevelopers
PRO
1
44
広告配信システムにおけるデータ基盤移行の事例紹介
microaddevelopers
PRO
0
17
3rd Party Cookie 規制後の広告配信技術
microaddevelopers
PRO
0
16
Other Decks in Programming
See All in Programming
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
210
Augmenting AI with the Power of Jakarta EE
ivargrimstad
0
290
仕様書を書く前にハーネスを作る - Agent Native開発は「探索を速く、判定を固く」
gotalab555
2
1.3k
yield再入門 #phpcon
o0h
PRO
0
820
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
160
数百円から始めるRuby電子工作
tarosay
0
120
霧の中の代数的エフェクト
funnyycat
1
440
AIが無かった頃の素敵な出会いの話
codmoninc
1
280
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
780
地域 SRE コミュニティ最前線 - ホンマでっかSRE勉強会
tk3fftk
0
280
継続モナドとリアクティブプログラミング
yukikurage
3
660
Claude Team Plan導入・ガイド
tk3fftk
0
240
Featured
See All Featured
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
Ethics towards AI in product and experience design
skipperchong
2
330
Prompt Engineering for Job Search
mfonobong
0
390
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
How to make the Groovebox
asonas
2
2.3k
A designer walks into a library…
pauljervisheath
211
24k
Product Roadmaps are Hard
iamctodd
55
12k
From π to Pie charts
rasagy
0
240
Designing for Timeless Needs
cassininazir
1
410
Google's AI Overviews - The New Search
badams
0
1.1k
Deep Space Network (abreviated)
tonyrice
0
240
A Tale of Four Properties
chriscoyier
163
24k
Transcript
Apache Kafkaでの大量データ 処理がKubenetesで簡単にでき て嬉しかった話 Fluentd,Spark Streaming 株式会社マイクロアド 大澤 昂太
大澤 昂太 サーバサイドエンジニアをしています。 分散システム関連の開発が多いです。 K8sは何回か勉強したのですがあまり理 解できなかったです。 Dockerはよく使います 自己紹介など 株式会社マイクロアド インターネット広告の会社です。
設計に起因する苦しい時代を経験して いるので設計へのこだわりが強いで す。 関数型言語のScalaやサーバサイド KotlinなどJVMの活用が多いです。
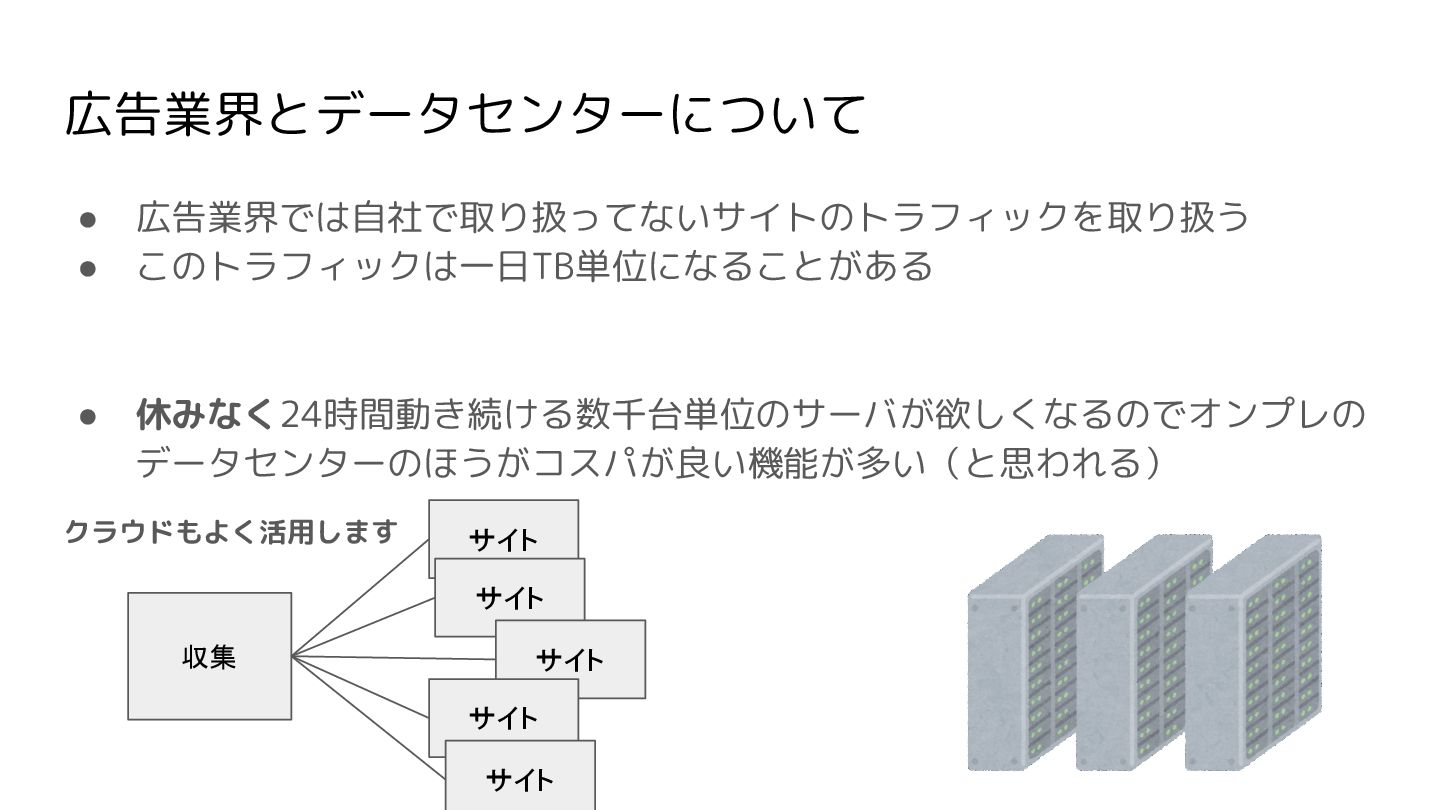
広告業界とデータセンターについて • 広告業界では自社で取り扱ってないサイトのトラフィックを取り扱う • このトラフィックは一日TB単位になることがある • 休みなく24時間動き続ける数千台単位のサーバが欲しくなるのでオンプレの データセンターのほうがコスパが良い機能が多い(と思われる) クラウドもよく活用します 収集
サイト サイト サイト サイト サイト
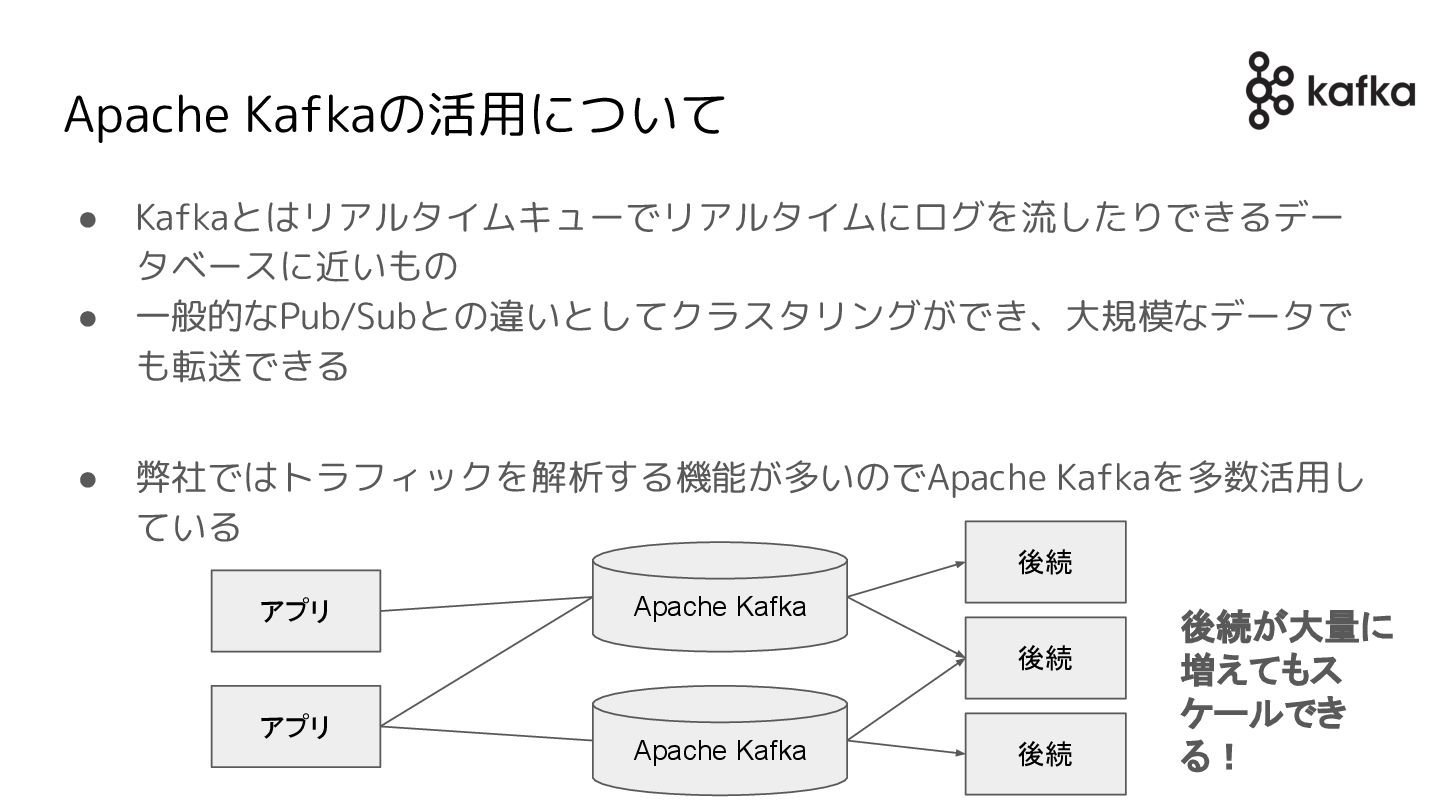
Apache Kafkaの活用について • Kafkaとはリアルタイムキューでリアルタイムにログを流したりできるデー タベースに近いもの • 一般的なPub/Subとの違いとしてクラスタリングができ、大規模なデータで も転送できる • 弊社ではトラフィックを解析する機能が多いのでApache
Kafkaを多数活用し ている Apache Kafka Apache Kafka アプリ アプリ 後続 後続 後続 後続が大量に 増えてもス ケールでき る!
Spark Streamingの活用と問題について • 弊社ではApache Kafkaのデータ処理をする際には主にSparkストリーミング を活用している • 問題点として軽い機能でもそれなりの規模の開発が必要 • (弊社Hadoopの問題で)オーバーコミットが安定せずCPUコアの消費量が多
い • Hadoopクラスタが老朽化していてどうにかしたい Apache Kafka Spark Streaming Apache Kafka Spark Streaming
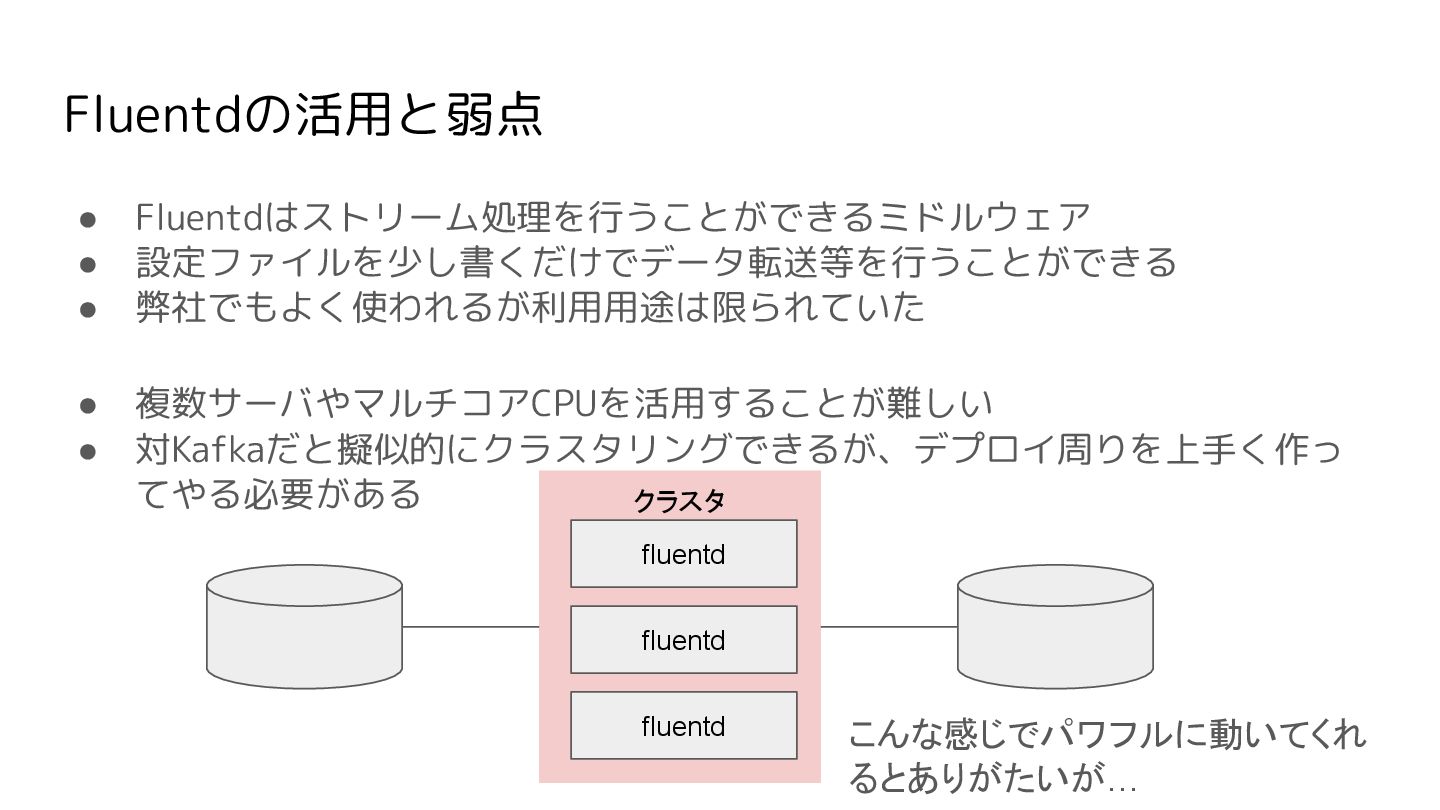
クラスタ Fluentdの活用と弱点 • Fluentdはストリーム処理を行うことができるミドルウェア • 設定ファイルを少し書くだけでデータ転送等を行うことができる • 弊社でもよく使われるが利用用途は限られていた • 複数サーバやマルチコアCPUを活用することが難しい
• 対Kafkaだと擬似的にクラスタリングできるが、デプロイ周りを上手く作っ てやる必要がある fluentd fluentd fluentd こんな感じでパワフルに動いてくれ るとありがたいが…
会社でのKubernetesの導入 • マイクロアドでは数年くらいK8sの準備をインフラチームの方で進めている • それ以外のサーバはDockerデーモンを直で使っていることが多い • ある時、リアルタイム処理の開発が必要になったが大した処理ではないので FluentdとK8sを組み合わせて使ってみることにした
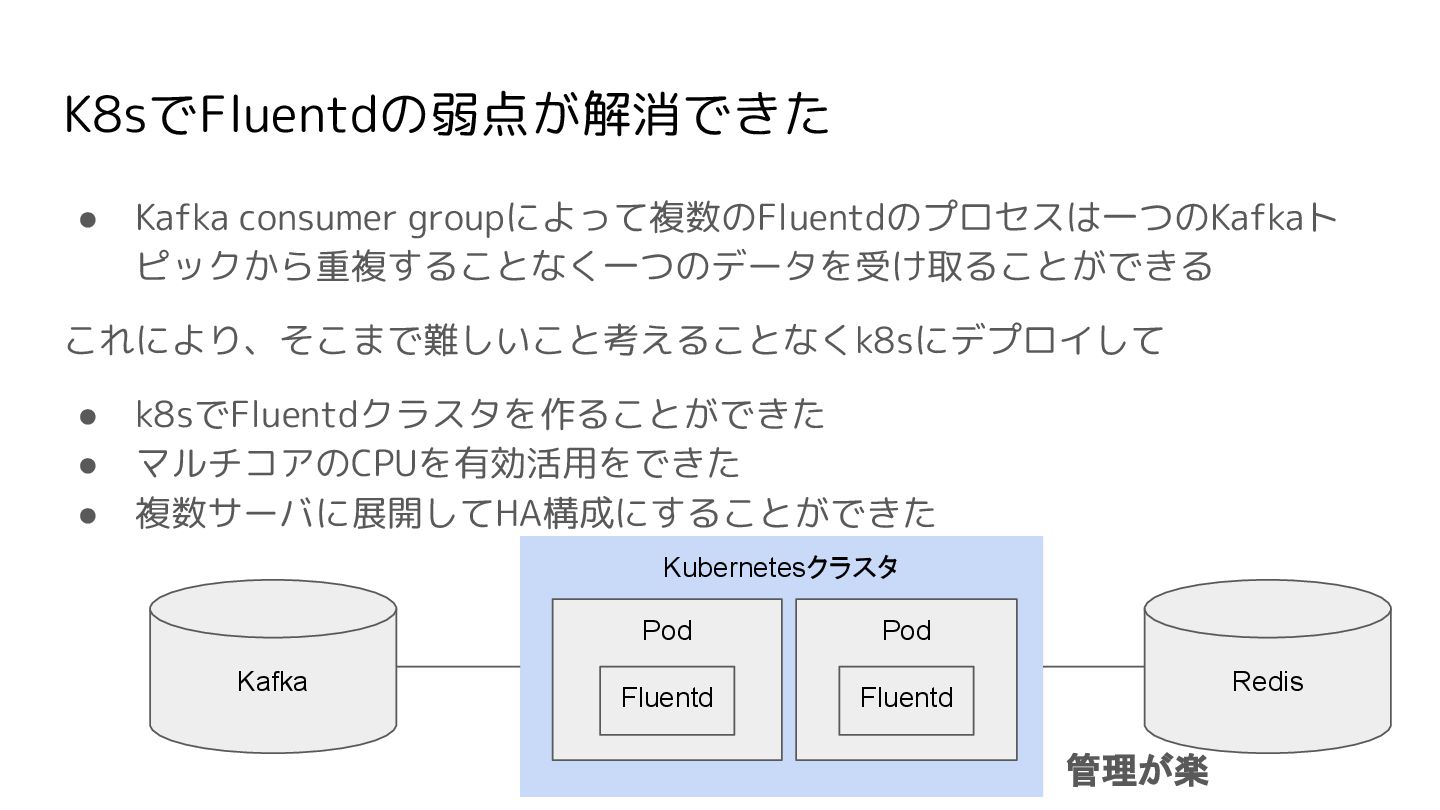
K8sでFluentdの弱点が解消できた • Kafka consumer groupによって複数のFluentdのプロセスは一つのKafkaト ピックから重複することなく一つのデータを受け取ることができる これにより、そこまで難しいこと考えることなくk8sにデプロイして • k8sでFluentdクラスタを作ることができた •
マルチコアのCPUを有効活用をできた • 複数サーバに展開してHA構成にすることができた Kafka Kubernetesクラスタ Pod Pod Fluentd Fluentd Redis 管理が楽
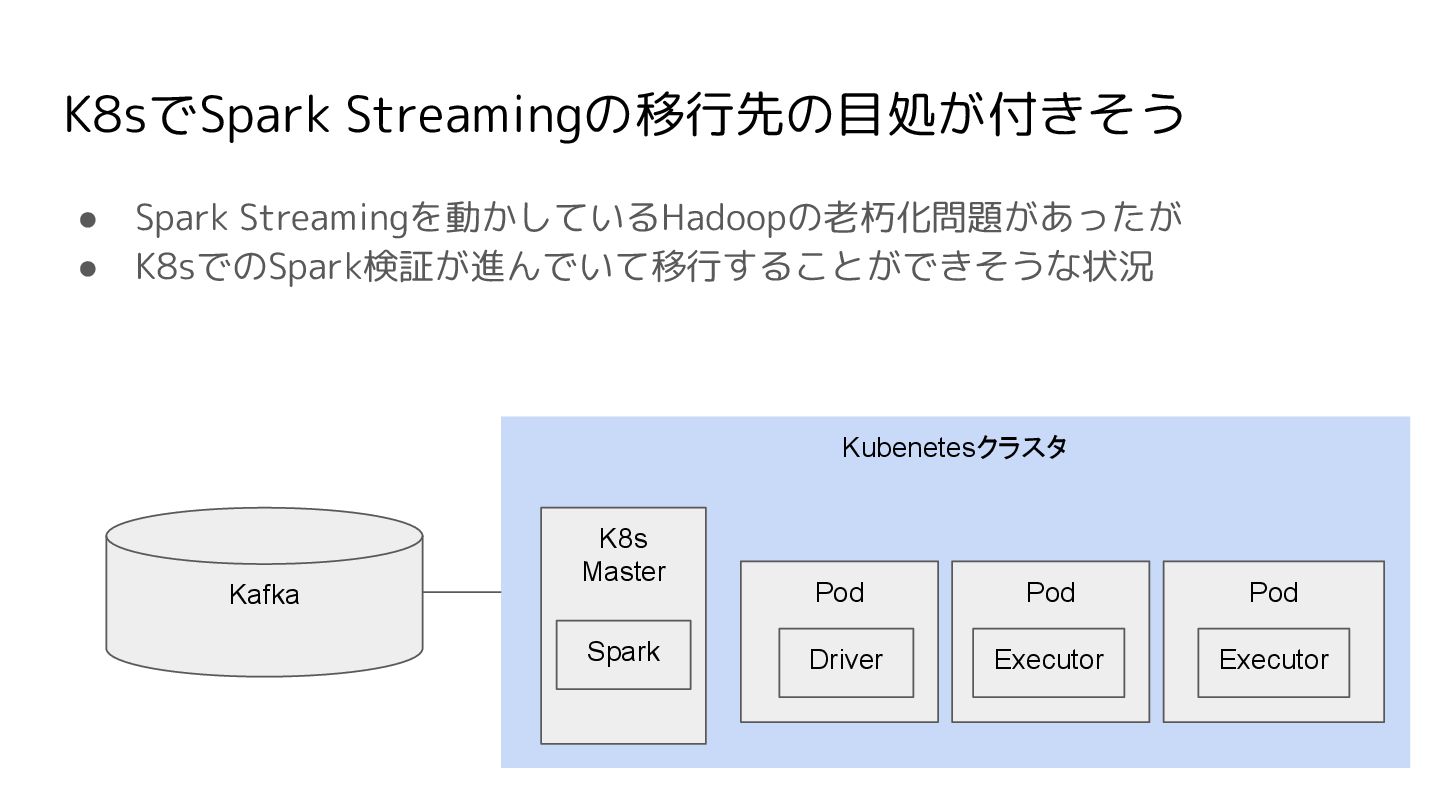
K8sでSpark Streamingの移行先の目処が付きそう • Spark Streamingを動かしているHadoopの老朽化問題があったが • K8sでのSpark検証が進んでいて移行することができそうな状況 Kubenetesクラスタ Pod Pod
Driver Executor K8s Master Spark Kafka Pod Executor
まとめ • KubernetesでFluentdの弱点を大きく改善することができた • ノード管理やHA化なども難しいこと考えることなく実現できた • KubernetesでSpark Streamingを活用することができた • 弊社のリアルタイム処理周りはK8sでほとんどカバーすることができそう
• k8sの威力を思い知り勉強を再開しようと思った
ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}