I use them in my application – You should not! • Why not – Not Stable – Ids are recycled over time, only guaranteed to be unique during a specific time span – Internal Neo implementation detail
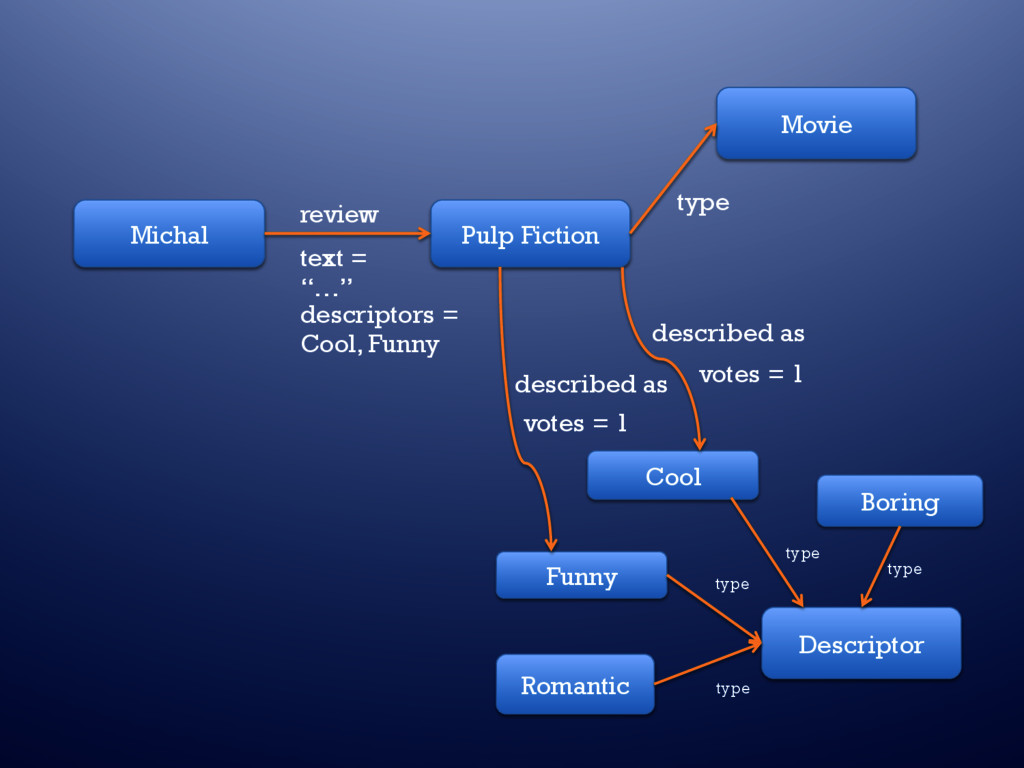
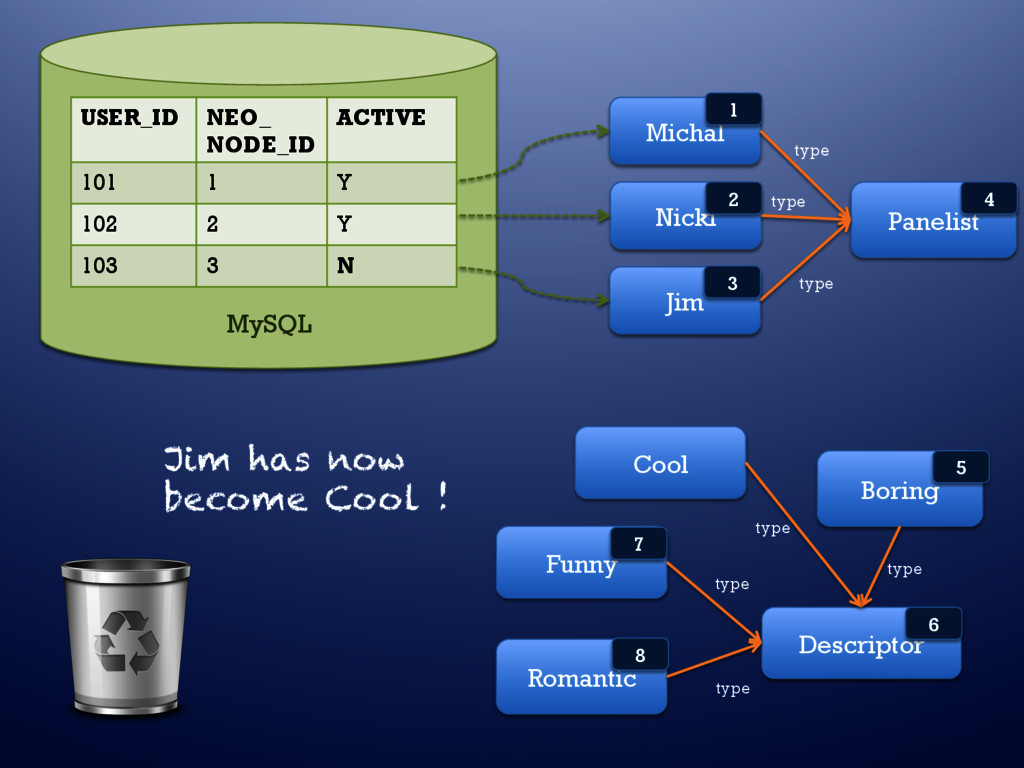
MySQL USER_ID NEO_ NODE_ID ACTIVE 101 1 Y 102 2 Y 103 3 Y Panelist type type type 1 2 4 5 6 7 8 USER_ID NEO_ NODE_ID ACTIVE 101 1 Y 102 2 Y 103 3 N Cool type 3 Jim has now become Cool !
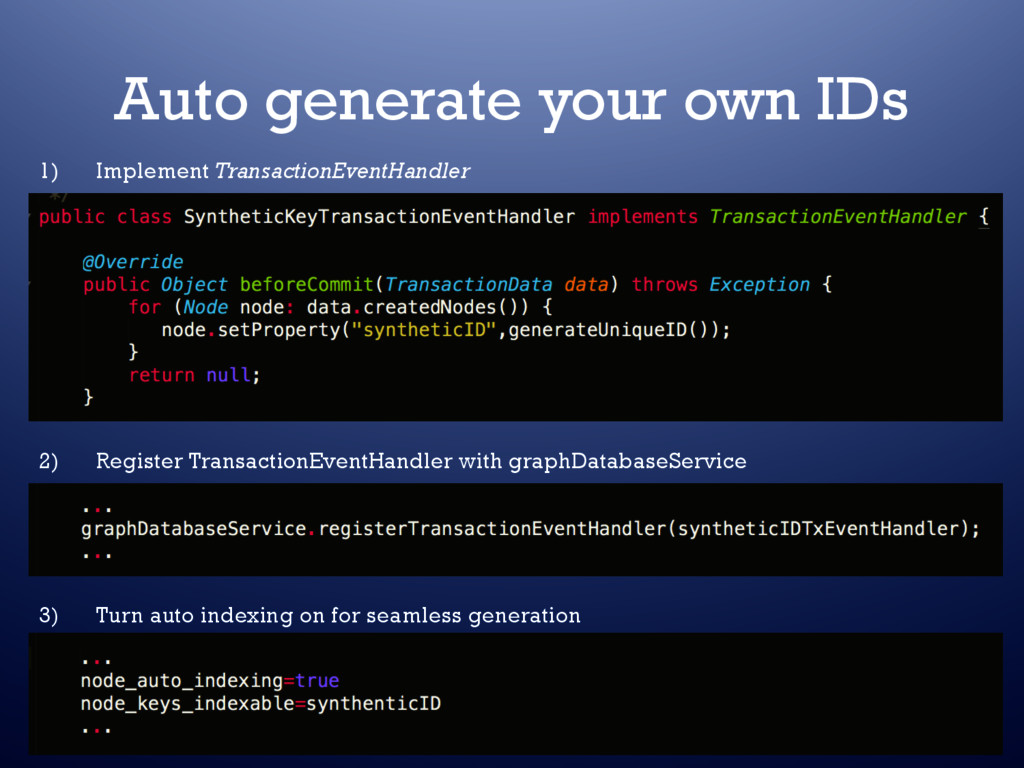
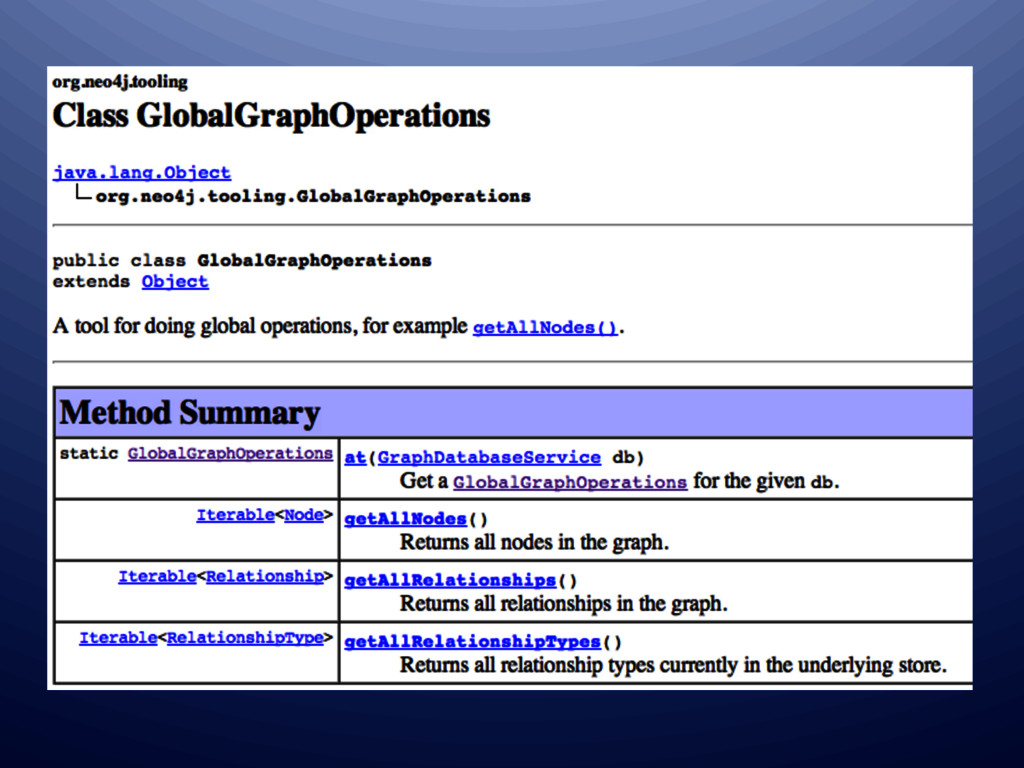
graph • Client provided IDs – Add as a standard property on the node – Add to index (or use auto indexer) • Natural vs. Synthetic IDs • Auto generate your own IDs – Hook into Neo4J Transaction Kernel – Use auto indexer
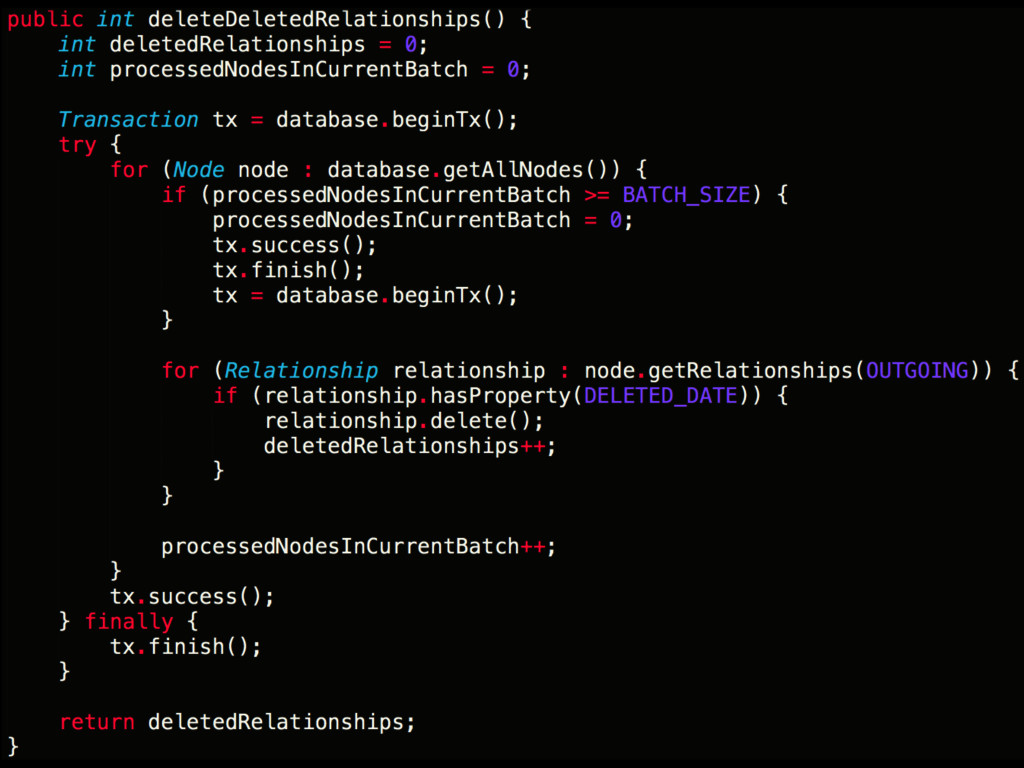
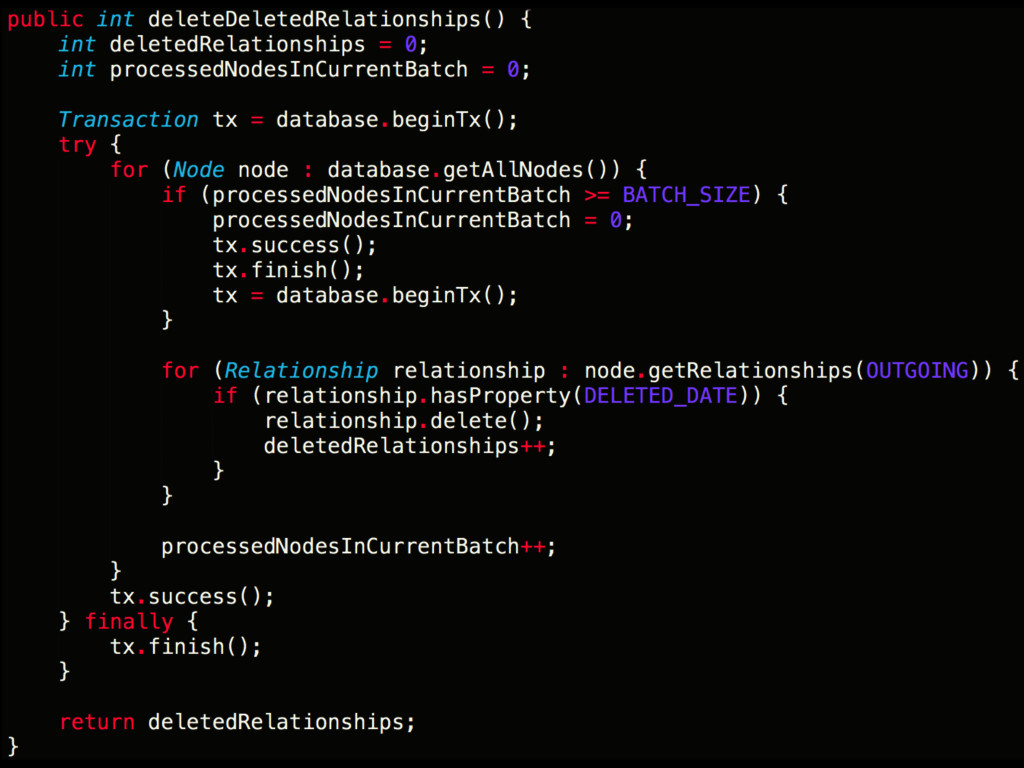
is your friend • Use an index to lookup specific nodes • If used inappropriately may result in inaccurate data & unexpected behaviour • Internal Neo implementation detail – subject to change
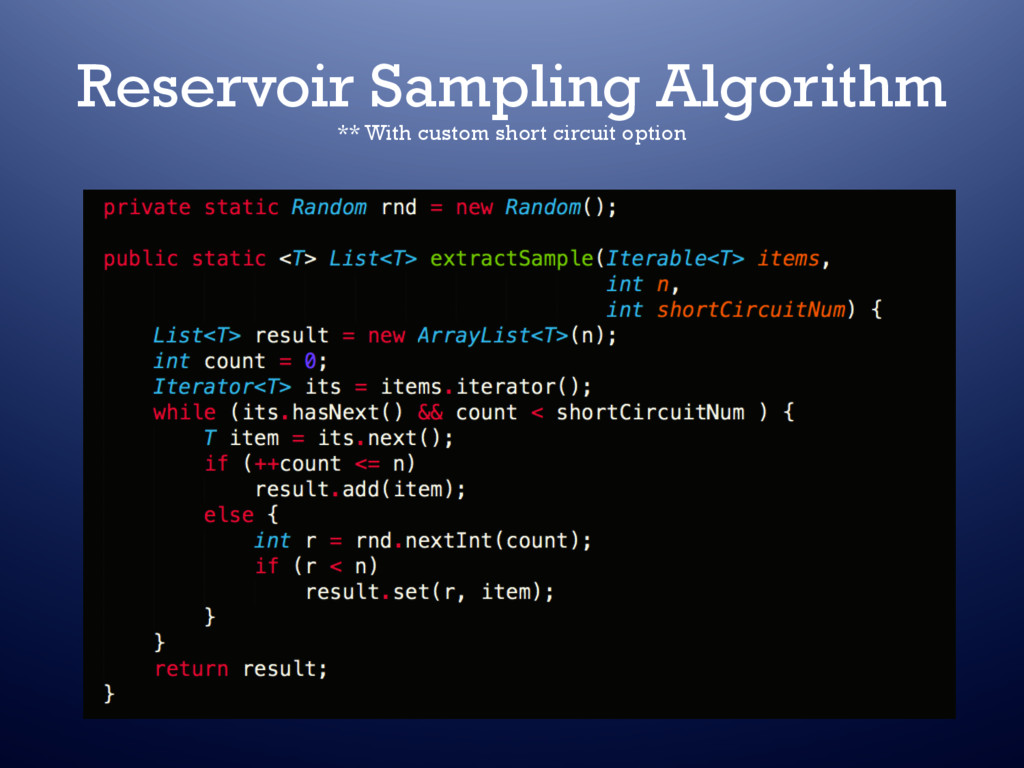
users – Use for statistical analysis aka “Random Sampling” • Problem – No built in Neo4J support – Not Neo4J’s sweet spot – May result in very bad performance
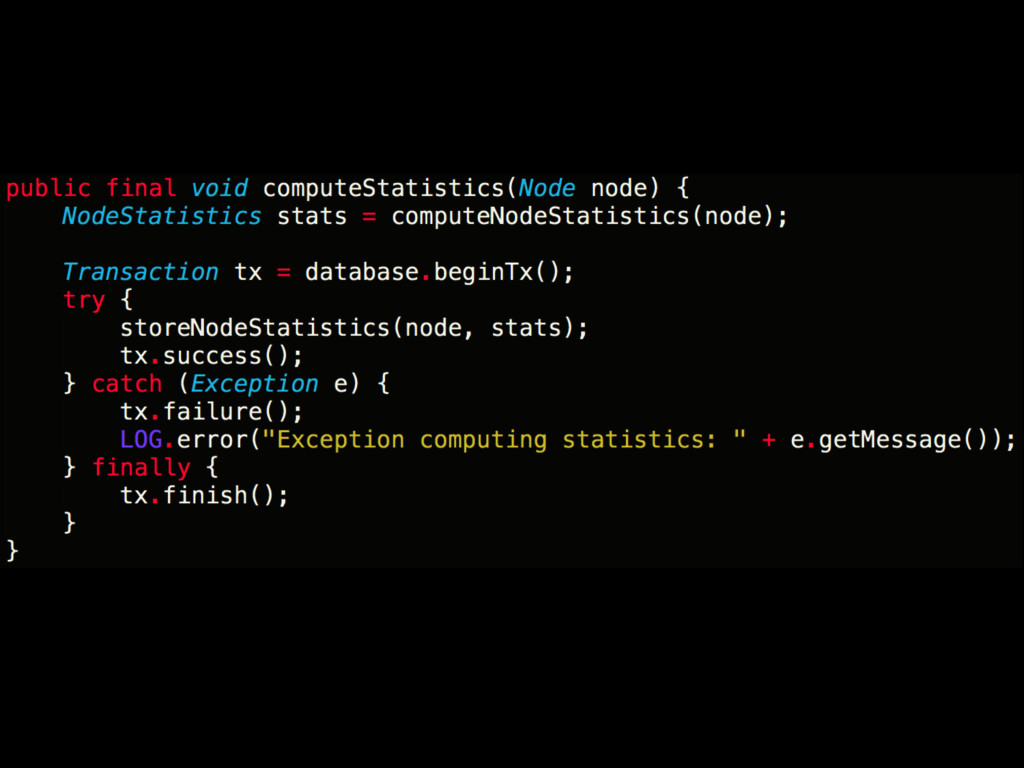
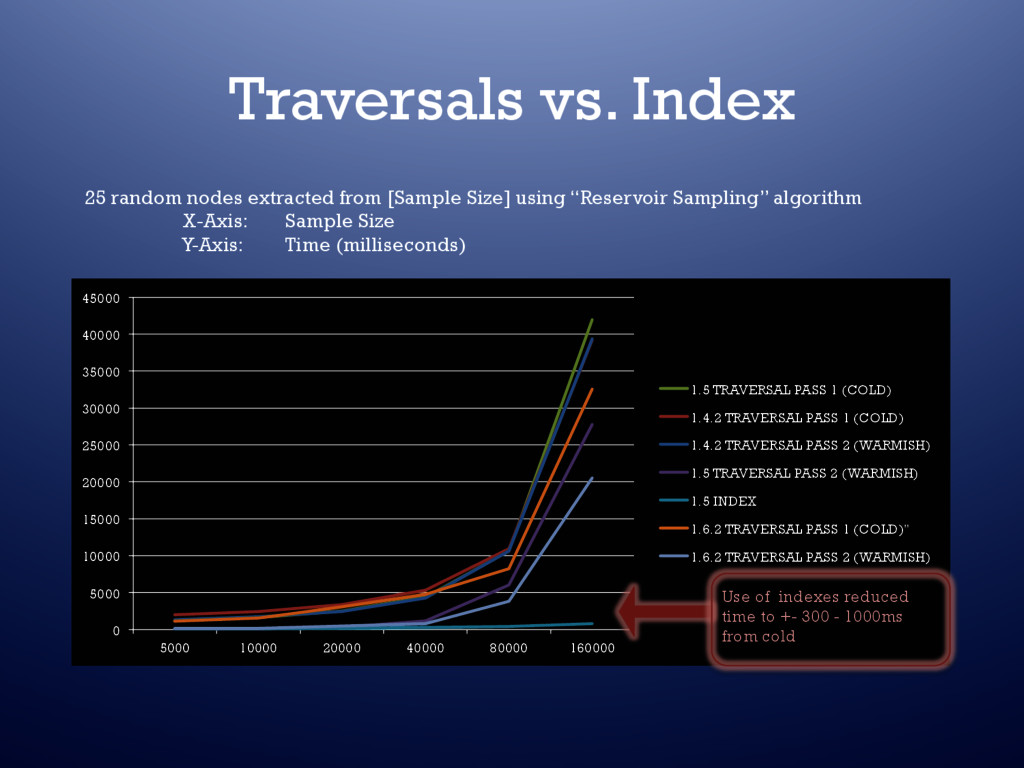
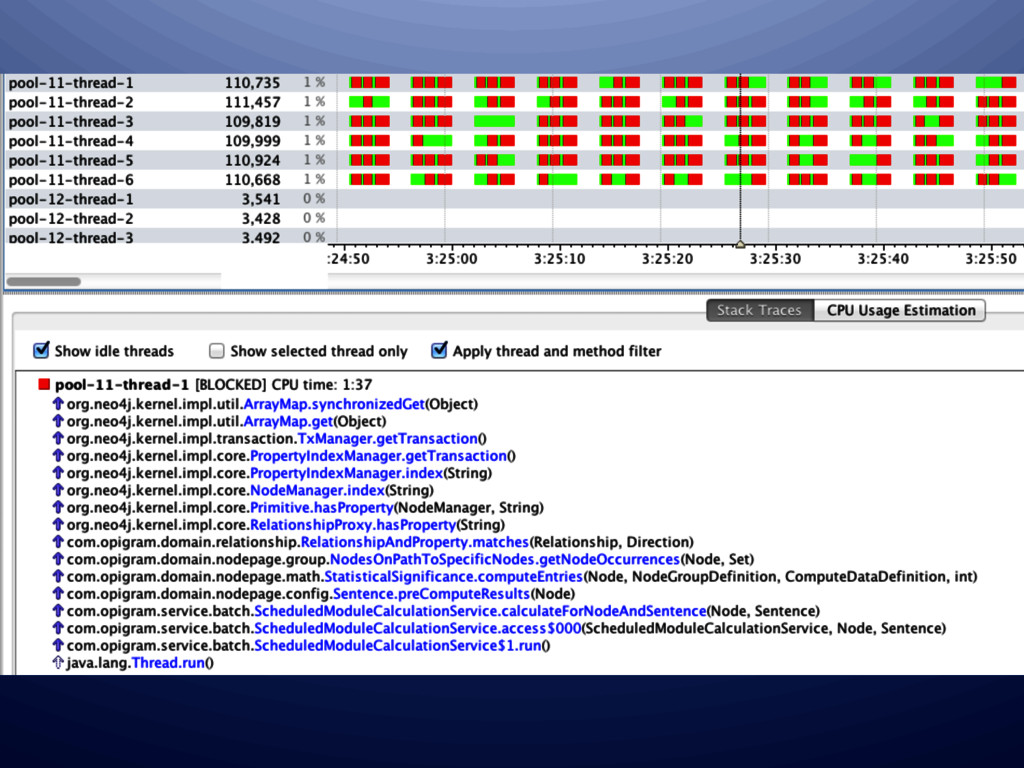
• Primarily has bad performance when hitting cold parts of graph ** This is generally true of any persistence technology which needs to perform random scattered disk access • Performance can be improved with – Indexes – Caching
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Beer Time! • @bachmanm • [email protected] • @techiewatt • [email protected]](https://files.speakerdeck.com/presentations/e1de34241a314deb9ae698b1eea0a8dd/slide_51.jpg){kind=link}