with a focus on the Python ecosystem. Talk given at Paris DataGeeks 2013. This is a preliminary version of the talk I will give at SciPy 2013. Feedback appreciated.
NLP, Computer Vision, Predictive Modeling & ML in general • Interested in Cloud Tech and Scaling Stuff • Starting an ML consultancy, writing a book http://ogrisel.com mardi 21 mai 13
of all users • Ad-Placement / bidding in Web Pages Given user browsing history / keywords • Fraud detection Given features derived from behavior mardi 21 mai 13
specific • + Feature Normalization / Transformation • Unmet Statistical Assumptions • Linear Separability of the target classes • Correlations between features • Natural metric to for the features mardi 21 mai 13
what they learned. Expert knowledge required to understand the model behavior and gain deeper insight on the data: this is model specific. mardi 21 mai 13
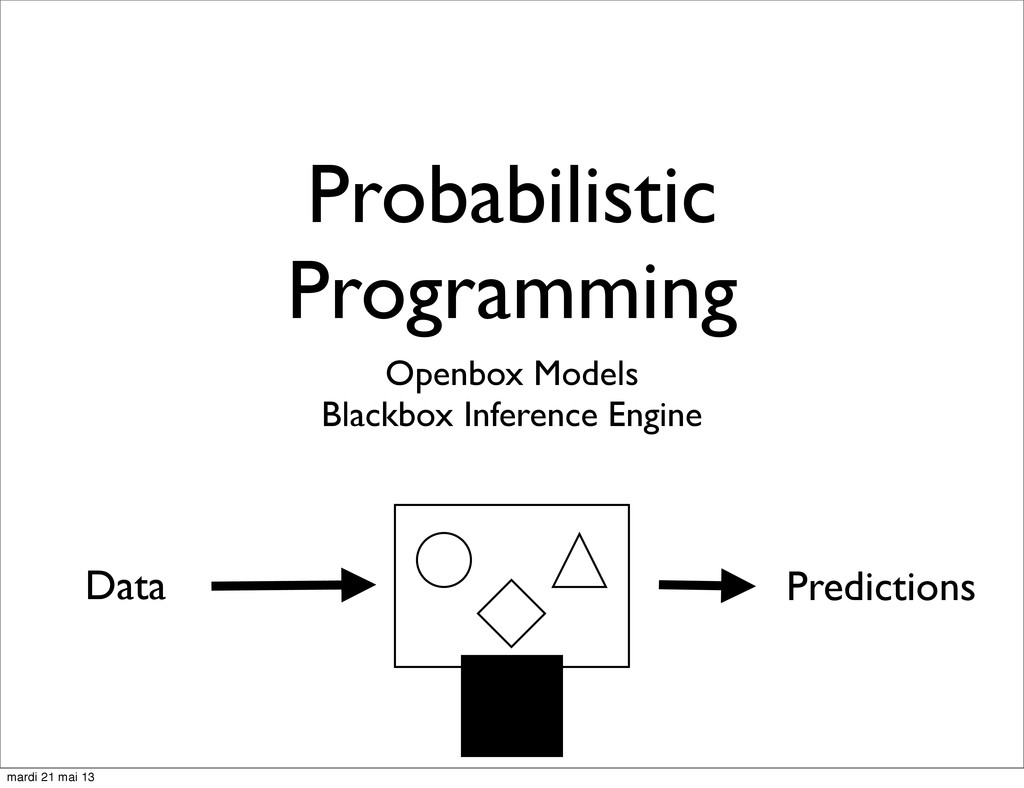
phenomenom with random variables • Write a programmatic story to derive observables from unknown variables • Plug data into observed variables • Use engine to invert the story and assign prob. distributions to unknown params. mardi 21 mai 13
Start from a Random Point • Move Parameters values Randomly • Reject with new sample randomly depending on a likelihood test • Accumulate non-rejected samples and call it the trace mardi 21 mai 13
Deterministic Approximations: ‣ Mean Field Approximation ‣ Variational Bayes and VMP Only is VMP seems as generic as MCMC for Prob. Programming mardi 21 mai 13
with R bindings • PyMC: in Python / NumPy / Theano • Prob. Programming with VMP • Infer.NET (C#, F#..., academic use only) • Infer.py (pythonnet bindings, very alpha) mardi 21 mai 13
tells a Generative Story • Story Telling is good for Human Understanding and Persuasion • Grounded in Quantitative Analysis and the sound theory of Bayesian Inference • Black Box inference Engine (e.g. MCMC): ‣ can be treated as Compiler Optimization mardi 21 mai 13
still... • Highly nonlinear dependencies lead to highy multi-modals posterior • Hard to mix between posterior modes: slow convergence • How to best build models? How to choose priors? mardi 21 mai 13
for scalability of MCMC for some model classes (in Stan and PyMC3) • VMP (orig. paper 2005, generalized in 2011) in Infer.NET • New DARPA Program (2013-2017) to fund research on Prob. Programming. mardi 21 mai 13
Hackers • Creative Commons Book on Github • Uses PyMC & IPython notebook • Doing Bayesian Data Analysis • Book with example in R and BUGS mardi 21 mai 13
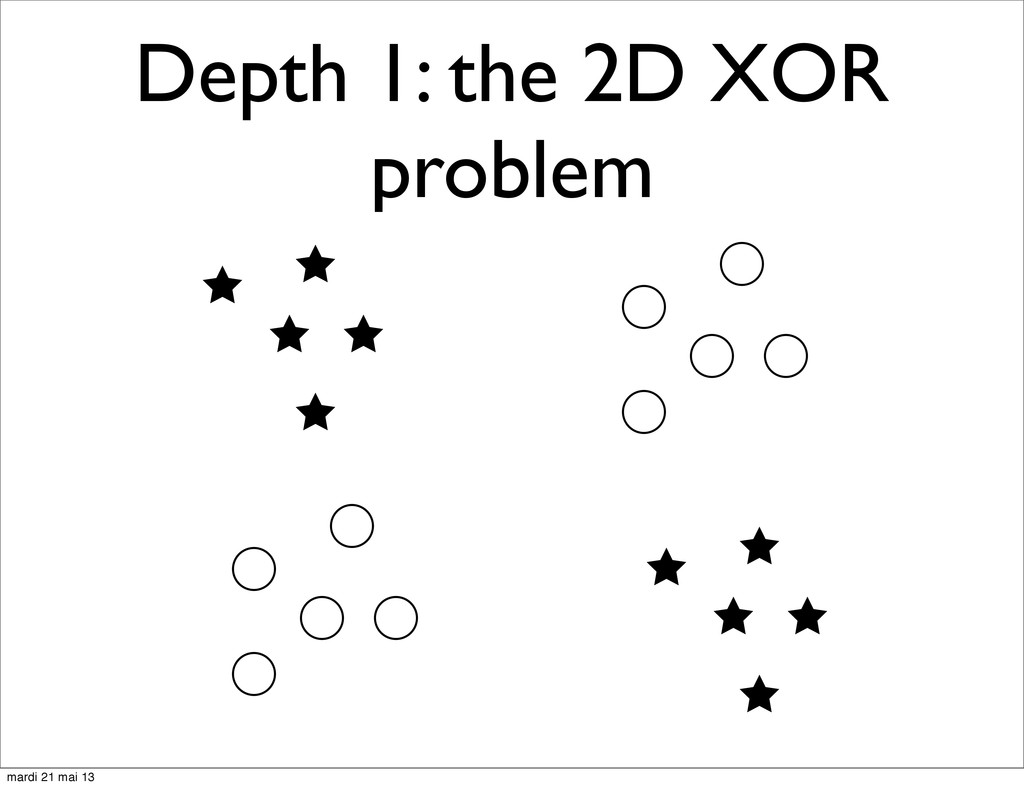
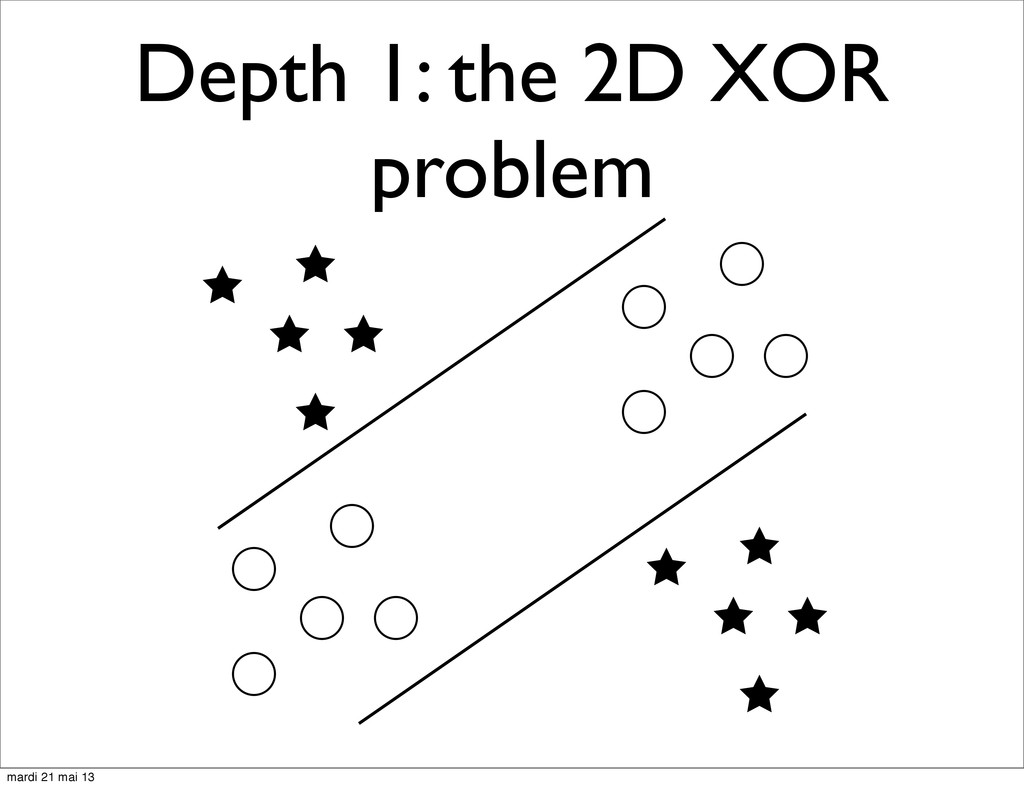
trees depth • Number of non-linearities between the unobserved “True”, “Real-World” factors of variations (causes) and the observed data (e.g. pixels in a robot’s camera) • But what is non-linearly separable data? mardi 21 mai 13
Logistic Regression, Multinomial Naive Bayes Depth 1: NN with 1 hidden Layer, RBF SVM, Decision Trees Depth 2: NN with 2 hidden Layers, Ensembles of Trees mardi 21 mai 13
Function: given N boolean variables, return 1 if number of positive values is even, 0 otherwise • Depth 1 models can learn the parity function but: • Need ~ 2^N hidden nodes / SVs • Require 1 example per local variation mardi 21 mai 13
can be learned by depth-2 NN with a number of hidden unit that grows linearly with the dimensionality of the problem • Similar results for the Checker Board learning task mardi 21 mai 13
80s with early successes (e.g. Neural Nets for OCR) • 2 Major Problems: • Backprop does not work with more than 1 or 2 hidden layers • Overfitting: forces early stopping mardi 21 mai 13
moved away from NN • SVM with kernel: less hyperparameters • Random Forests / Boosted Trees often beat all other models when enough labeled data and CPU time mardi 21 mai 13
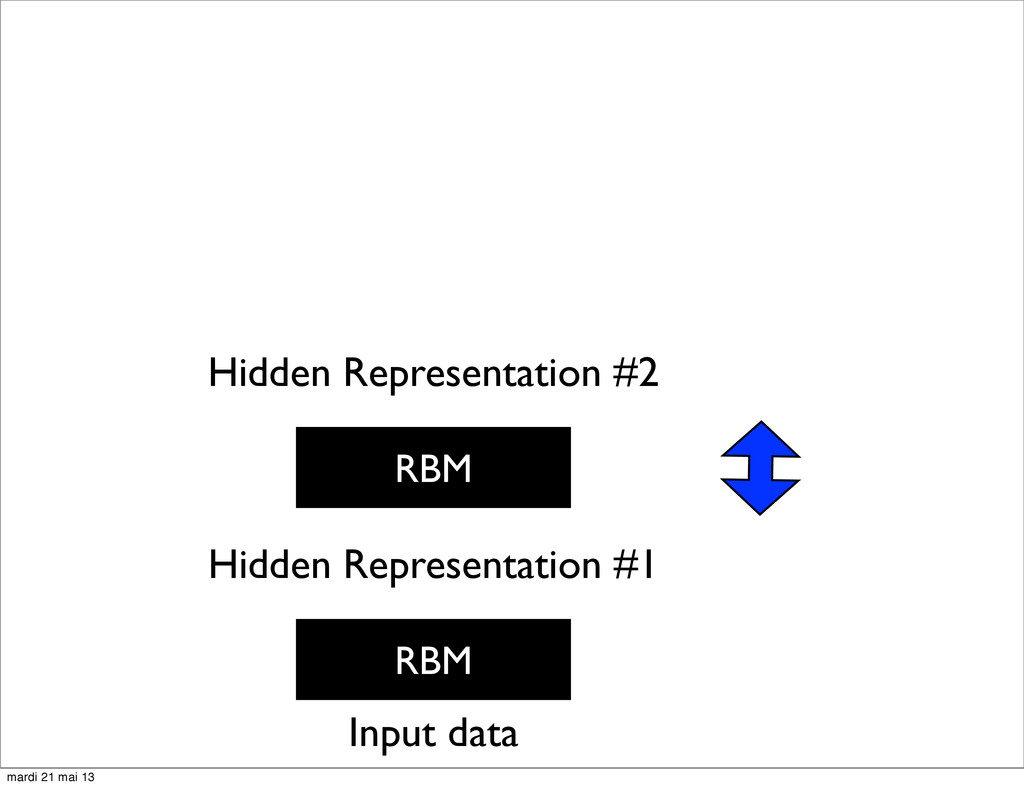
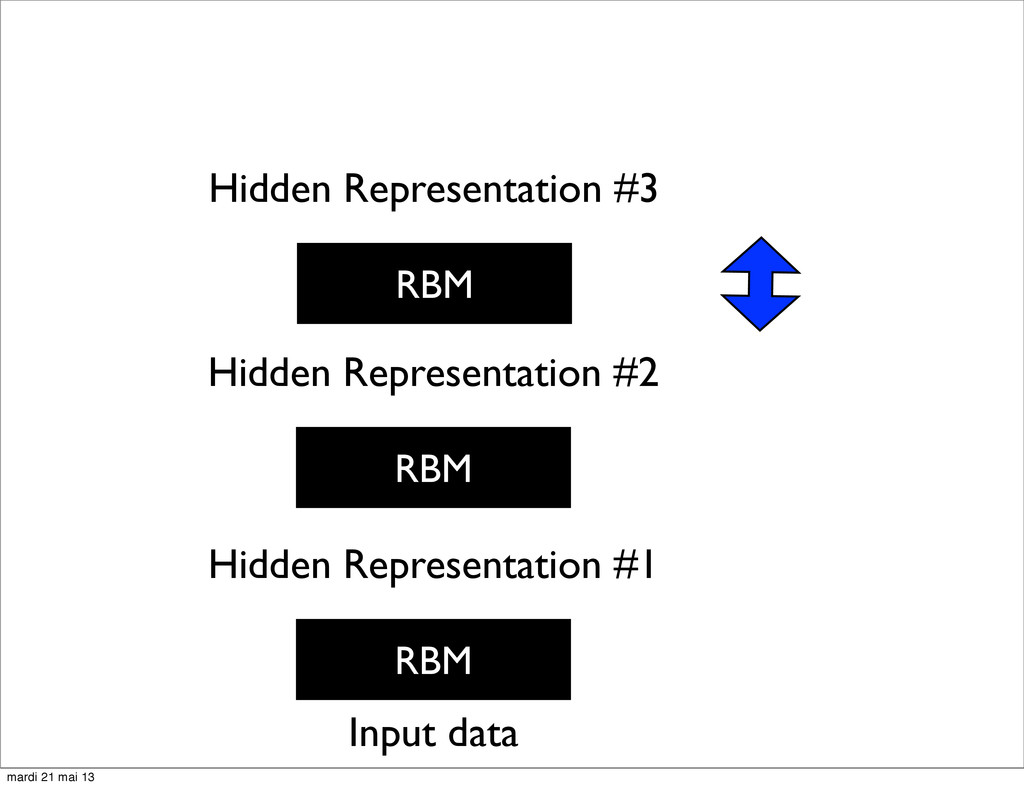
U. of Toronto • Unsupervised Pre-training of Deep Architectures (Deep Belief Networks) • Can be unfolded into a traditional NN for fine tuning mardi 21 mai 13
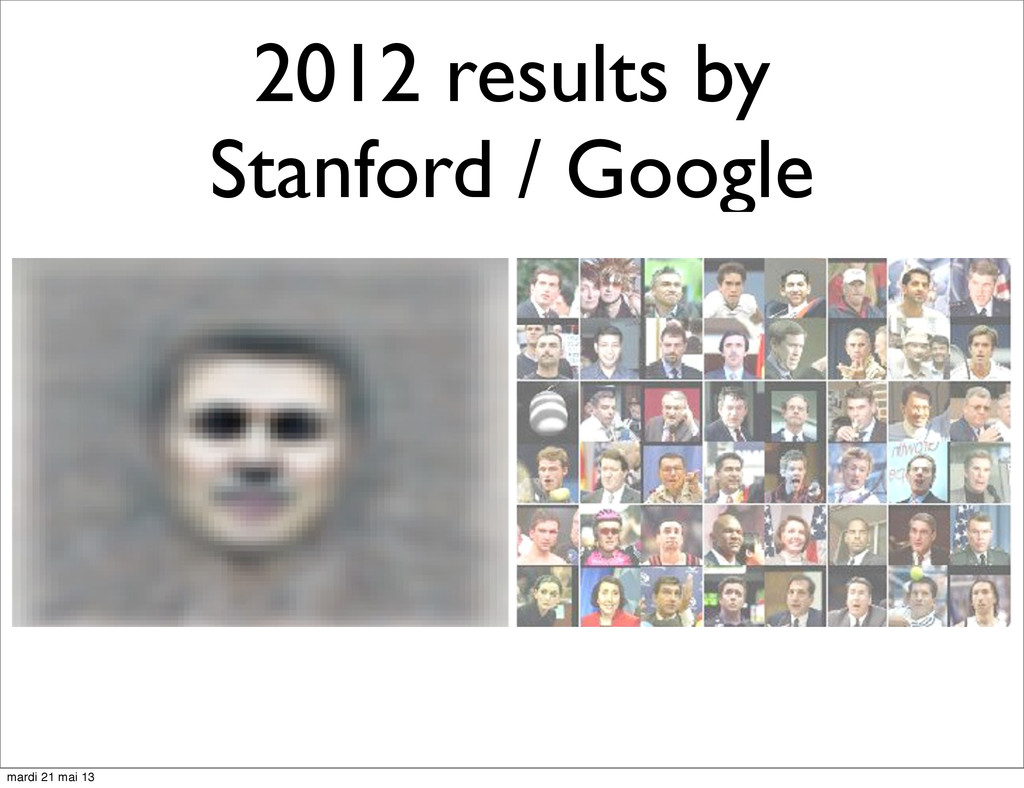
of Montreal • Ng et al. in Stanford • Replaced RBM with various other models such as Autoencoders in a denoising setting or with a sparsity penalty • Started to reach state of the art in speech recognition, image recognition... mardi 21 mai 13
Dropout networks • New way to train deep feed forward neural networks with much less overfitting and without unsupervised pretraining • Allows NN to beat state of the art approaches on ImageNet (object recognition in images) mardi 21 mai 13
high level, invariant, discriminative features from raw data (pixels, sound frequencies...) • Starting to reach or beat State of the Art in some Speech Understanding and Computer Vision tasks • Stacked Abstractions and Composability might be a path to build a real AI mardi 21 mai 13
lots of training data • Typically requires running a GPU for days to fit a model + many hyperparameters • Under-fitting issues for large models • Not yet that useful with high level abstract input (e.g. text data): shallow models can already do very well for text classification mardi 21 mai 13
Microsoft...) investing in DL for speech understanding and computer vision • Many top ML researchers are starting to look at DL & some on the theory side mardi 21 mai 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}