Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
R言語で統計分類基本
Search
Pawel Rusin
June 22, 2013
Technology
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
R言語で統計分類基本
この発表はR言語を使って判別分析を実装するほうほうを紹介する
Pawel Rusin
June 22, 2013
More Decks by Pawel Rusin
See All by Pawel Rusin
Workflow and development in globally distributed mobile teams
rusinpaw
0
58
Background execution in iOS
rusinpaw
1
170
R言語で可視化について
rusinpaw
0
110
Other Decks in Technology
See All in Technology
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
290
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
1
640
生成AIワークショップ / Custom-AI-Agents-workshop
databricksjapan
0
100
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
0
240
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
1.1k
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
290
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
0
210
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
470
Making sense of Google’s agentic dev tools
glaforge
1
290
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
2
900
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
320
Featured
See All Featured
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Facilitating Awesome Meetings
lara
57
7k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
890
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
400
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
260
A Tale of Four Properties
chriscoyier
163
24k
Mind Mapping
helmedeiros
PRO
1
290
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
Transcript
関東第4回ゼロからはじめる R言語勉強会 R言語で統計分類基本 パヴェウ・ルシン 株式会社ブリリアントサービス
自己紹介 •Paweł Rusin (パヴェウ・ルシン) •
[email protected]
Facebook: Paweł Rusin (
[email protected]
)
•会社: • 株式会社ブリリアントサービス •業務: データマイニング
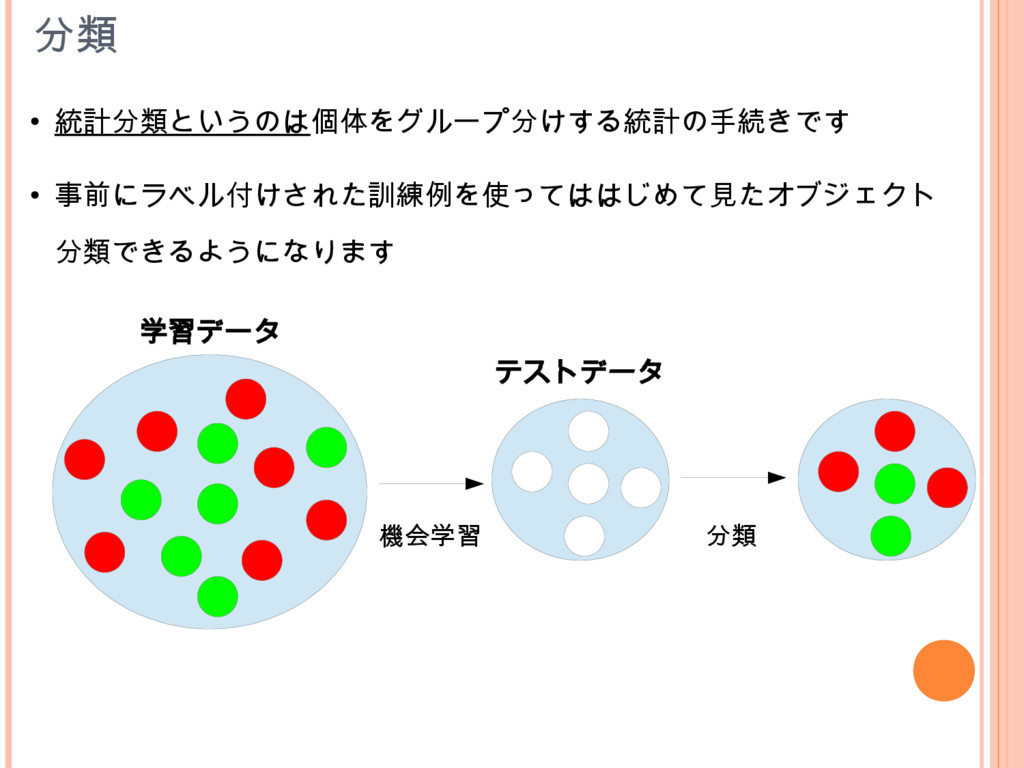
分類 • 統計分類というのは個体をグループ分けする統計の手続きです • 事前にラベル付けされた訓練例を使ってははじめて見たオブジェクト 分類できるようになります 学習データ テストデータ 機会学習 分類
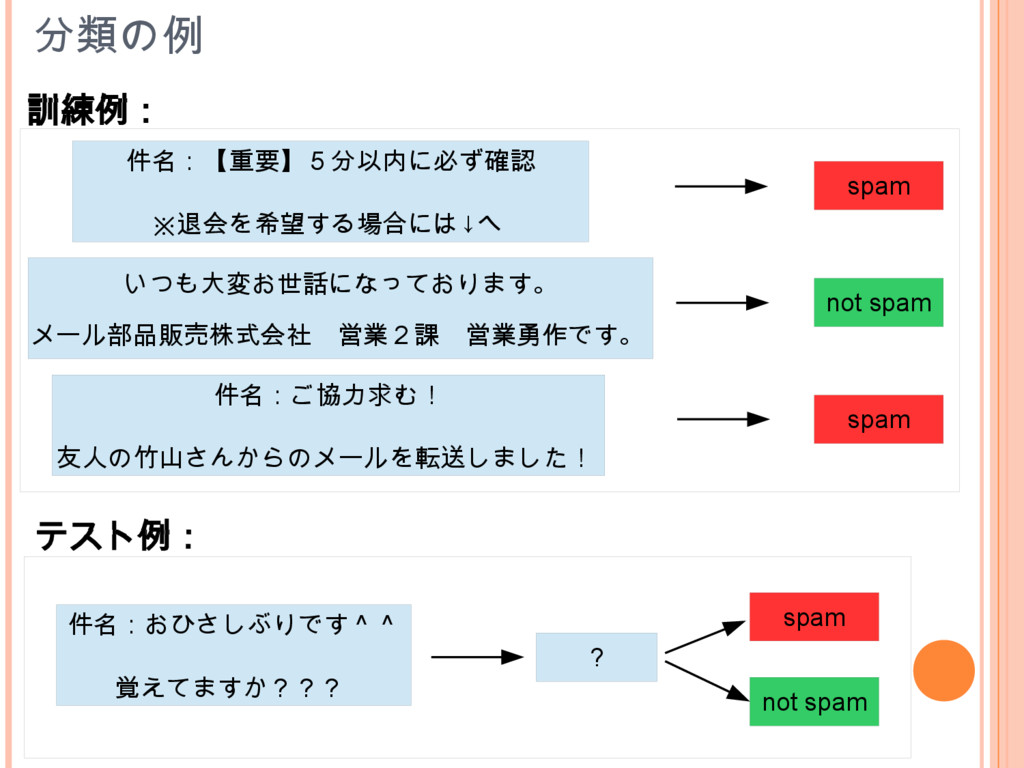
分類の例 spam not spam spam not spam 件名:【重要】5分以内に必ず確認 ※退会を希望する場合には↓へ 件名:ご協力求む!
友人の竹山さんからのメールを転送しました! いつも大変お世話になっております。 メール部品販売株式会社 営業2課 営業勇作です。 spam 件名:おひさしぶりです^^ 覚えてますか??? ? 訓練例: テスト例:
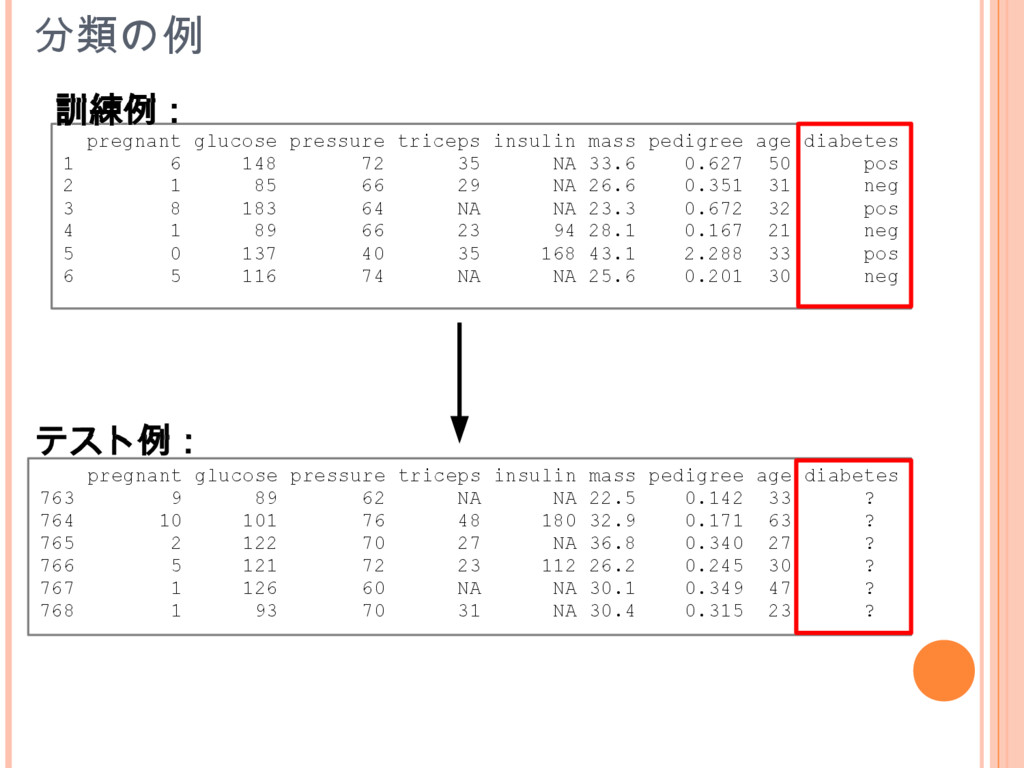
分類の例 pregnant glucose pressure triceps insulin mass pedigree age diabetes
1 6 148 72 35 NA 33.6 0.627 50 pos 2 1 85 66 29 NA 26.6 0.351 31 neg 3 8 183 64 NA NA 23.3 0.672 32 pos 4 1 89 66 23 94 28.1 0.167 21 neg 5 0 137 40 35 168 43.1 2.288 33 pos 6 5 116 74 NA NA 25.6 0.201 30 neg pregnant glucose pressure triceps insulin mass pedigree age diabetes 763 9 89 62 NA NA 22.5 0.142 33 ? 764 10 101 76 48 180 32.9 0.171 63 ? 765 2 122 70 27 NA 36.8 0.340 27 ? 766 5 121 72 23 112 26.2 0.245 30 ? 767 1 126 60 NA NA 30.1 0.349 47 ? 768 1 93 70 31 NA 30.4 0.315 23 ? 訓練例: テスト例:
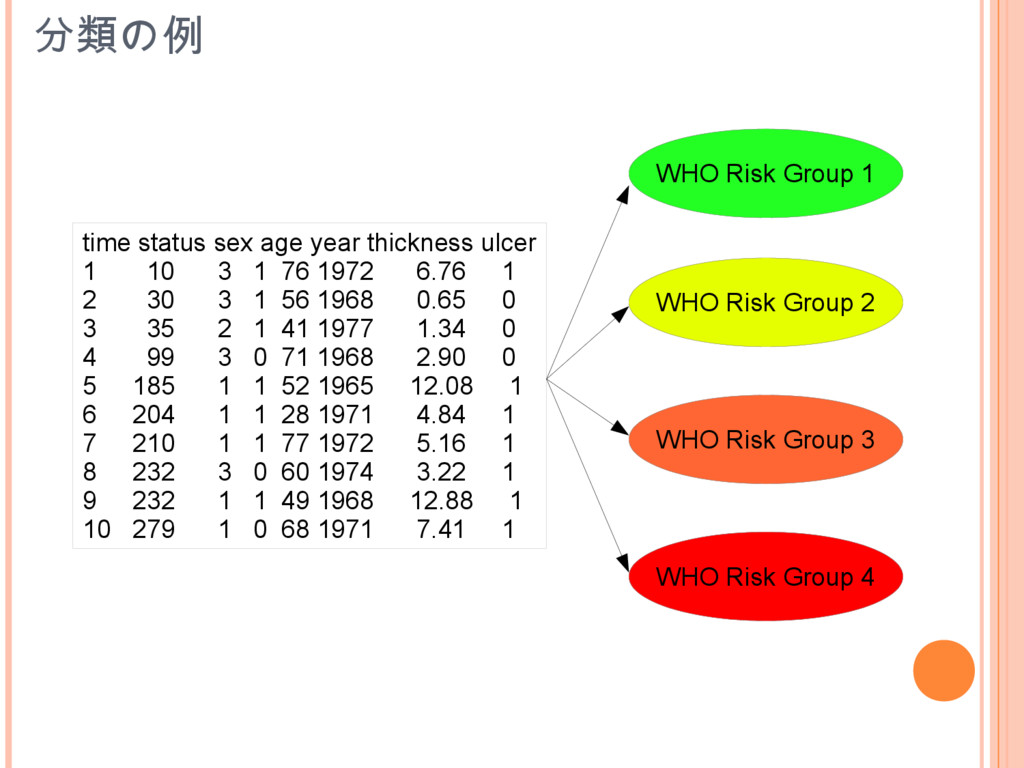
分類の例 WHO Risk Group 1 WHO Risk Group 2 WHO
Risk Group 3 WHO Risk Group 4 time status sex age year thickness ulcer 1 10 3 1 76 1972 6.76 1 2 30 3 1 56 1968 0.65 0 3 35 2 1 41 1977 1.34 0 4 99 3 0 71 1968 2.90 0 5 185 1 1 52 1965 12.08 1 6 204 1 1 28 1971 4.84 1 7 210 1 1 77 1972 5.16 1 8 232 3 0 60 1974 3.22 1 9 232 1 1 49 1968 12.88 1 10 279 1 0 68 1971 7.41 1
データを片付ける pregnant glucose pressure triceps insulin mass pedigree age diabetes
1 6 148 72 35 NA 33.6 0.627 50 pos 2 1 85 66 29 NA 26.6 0.351 31 neg 3 8 183 64 NA NA 23.3 0.672 32 pos 4 1 89 66 23 94 28.1 0.167 21 neg 5 0 137 40 35 168 43.1 2.288 33 pos 6 5 116 74 NA NA 25.6 0.201 30 neg > install.packages("MASS") > library(MASS) > data(PimaIndiansDiabetes2) > indians = na.omit(PimaIndiansDiabetes2) > indians = indians[,c(2,5,9)] glucose insulin diabetes 4 89 94 neg 5 137 168 pos 7 78 88 pos 9 197 543 pos 14 189 846 pos 15 166 175 pos
訓練例とテスト例を分ける learning.sample = sample(x=1:nrow(indians),size=nrow(indians)/2) learning.set = indians[learning.sample,] sample(x, size, replace
= FALSE, prob = NULL) x=[1,2...392],size=196 [1] 120 321 292 11 49 318 ... glucose insulin diabetes 317 89 94 neg 318 137 168 pos 319 78 88 pos 320 197 543 pos 321 189 846 pos 322 166 175 pos [[120,321,292,11,49,318...],]
訓練例とテスト例を分ける test.set = indians[-learning.set,-3] learning.set = sample(x=[1,2...392],size=196) [1] 120 321
292 11 49 318 ... glucose insulin diabetes 317 89 94 neg 318 137 168 pos 319 78 88 pos 320 197 543 pos 321 189 846 pos 322 166 175 pos [-[120,321,292,11,49,318...],-3]
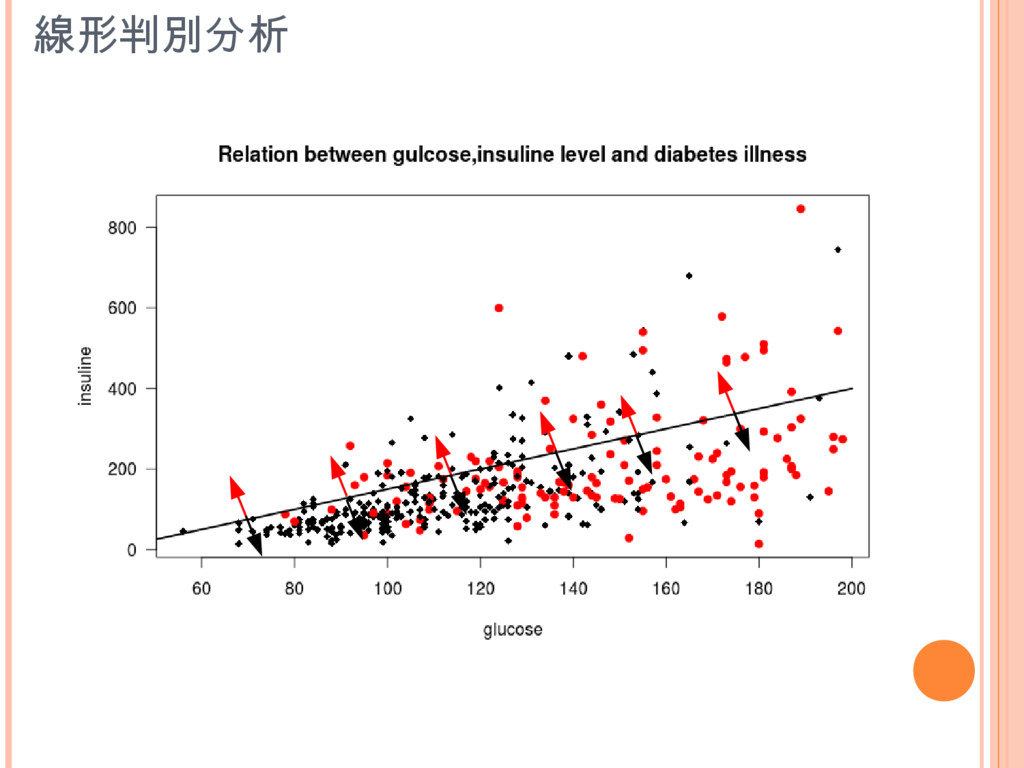
線形判別分析
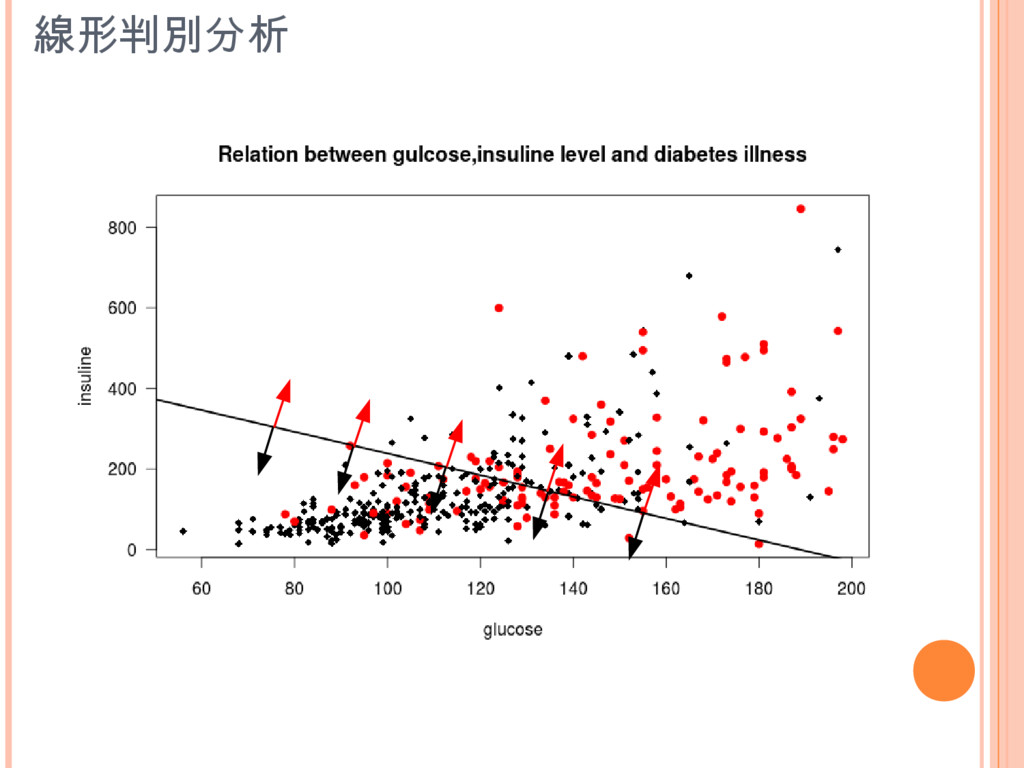
線形判別分析
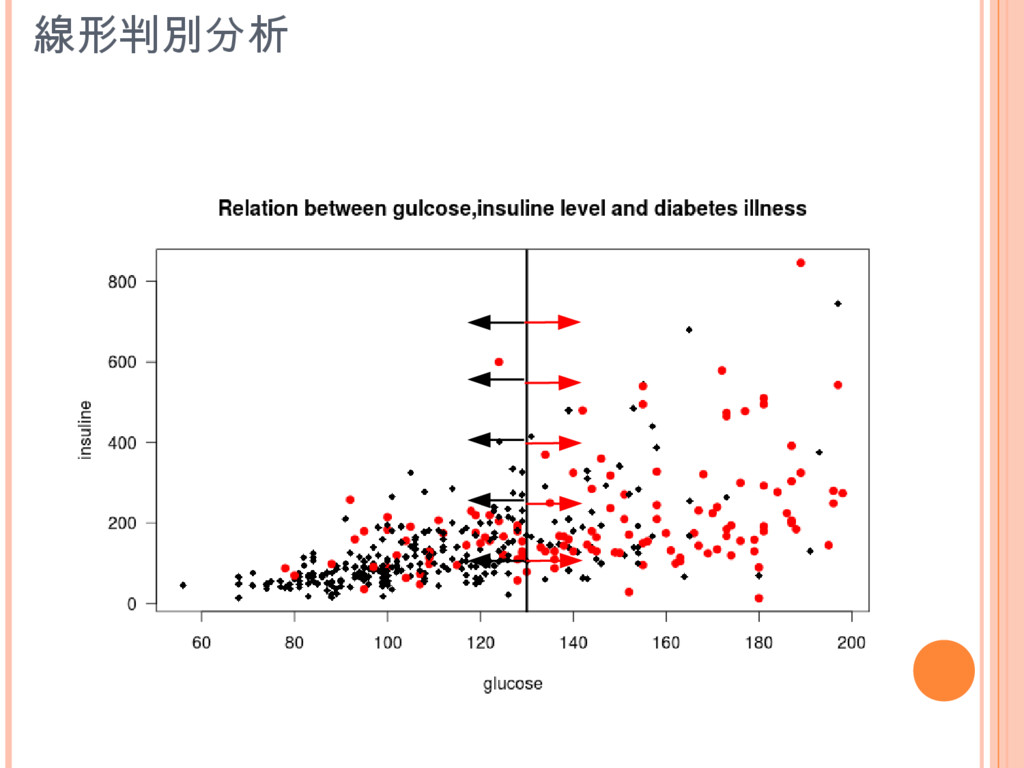
線形判別分析
線形判別分析 lin.classify = lda(indians[,1:2],grouping=indians$diabetes,subset=learning.sample) lda(x, grouping, ..., subset, na.action) [MASS]
Call: lda(diabetes ~ glucose + insulin, data = indians.formatted, subset = learning.set.sample) Prior probabilities of groups: neg pos 0.6377551 0.3622449 Group means: glucose insulin neg 113.2400 135.1520 pos 146.4366 208.0282 Coefficients of linear discriminants: LD1 glucose 0.0353017338 insulin 0.0008873364
線形判別分析 lin.class.predict = predict(lin.classify, newdata=test.set) predict (object, ...) $class [1]
neg neg pos neg neg pos neg neg neg pos neg neg neg neg neg neg neg neg neg neg neg neg neg neg neg pos neg neg neg pos neg neg neg neg [35] pos neg pos neg neg neg neg pos neg neg pos neg pos neg neg neg neg neg pos neg neg neg pos neg neg neg neg neg pos neg neg neg neg neg [69] neg neg neg neg neg pos pos neg pos neg neg neg neg neg pos pos neg neg pos neg neg neg pos neg neg neg neg neg neg neg neg neg pos neg [103] pos neg neg pos pos neg neg neg neg neg neg neg neg pos neg neg neg neg neg neg neg neg pos neg neg neg pos neg neg pos neg neg neg neg [137] neg pos neg neg neg neg neg neg neg neg pos neg neg neg neg neg pos pos pos pos neg neg neg neg neg neg neg neg pos pos neg neg neg neg [171] pos pos pos neg neg neg neg neg neg neg pos pos neg neg neg neg pos neg neg neg pos neg neg neg neg neg Levels: neg pos $posterior neg pos 4 0.9100464 0.08995355 5 0.5700686 0.42993137 14 0.2765809 0.72341915 21 0.7073037 0.29269633 ... res.table = table(real=true.test.set,classified=lin.class.predict$class) classified real neg pos neg 102 28 pos 51 15
線形判別分析 drawparti(grouping,x,y,method=”lda”...) [klaR] drawparti(indians[,3],indians[,1],indians[,2]...) drawparti(grouping, x, y, method = "lda",
prec = 100, xlab = NULL, ylab = NULL, col.correct = "black", col.wrong = "red", col.mean = "black", col.contour = "darkgrey", gs = as.character(grouping), pch.mean = 19, cex.mean = 1.3, print.err = 0.7, legend.err = FALSE, legend.bg = "white", imageplot = TRUE, image.colors = cm.colors(nc), plot.control = list(), ...)
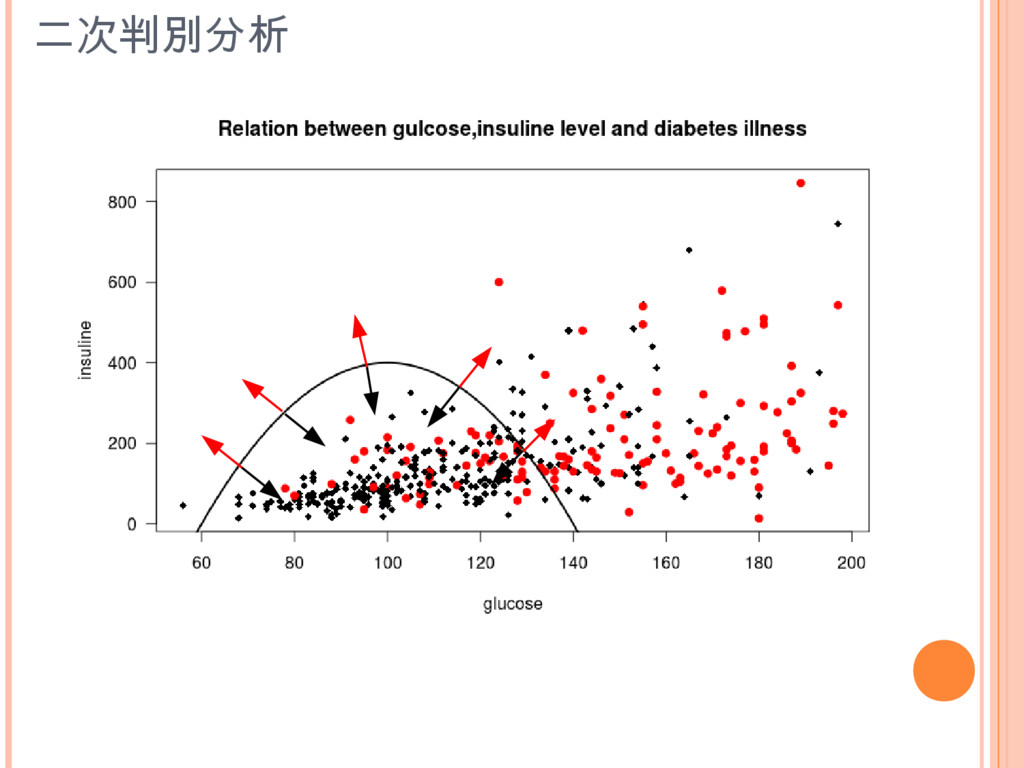
二次判別分析
quad.classify = qda(indians[,1:2],grouping=indians$diabetes,subset=learning.sample) qda(x, grouping, ..., subset, na.action) [MASS] Call:
qda(indians.formatted[, 1:2], grouping = indians.formatted$diabetes, subset = learning.set.sample) Prior probabilities of groups: neg pos 0.6377551 0.3622449 Group means: glucose insulin neg 113.2400 135.1520 pos 146.4366 208.0282 二次判別分析
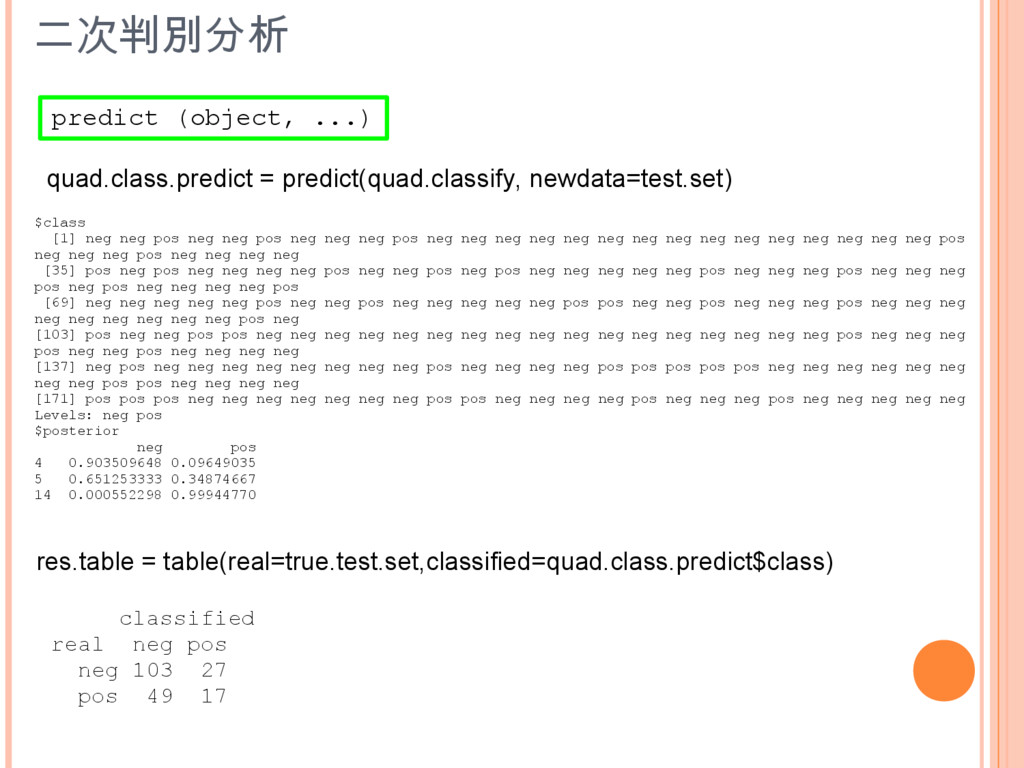
quad.class.predict = predict(quad.classify, newdata=test.set) predict (object, ...) res.table = table(real=true.test.set,classified=quad.class.predict$class)
$class [1] neg neg pos neg neg pos neg neg neg pos neg neg neg neg neg neg neg neg neg neg neg neg neg neg neg pos neg neg neg pos neg neg neg neg [35] pos neg pos neg neg neg neg pos neg neg pos neg pos neg neg neg neg neg pos neg neg neg pos neg neg neg pos neg pos neg neg neg neg pos [69] neg neg neg neg neg pos neg neg pos neg neg neg neg neg pos pos neg neg pos neg neg neg pos neg neg neg neg neg neg neg neg neg pos neg [103] pos neg neg pos pos neg neg neg neg neg neg neg neg neg neg neg neg neg neg neg neg neg pos neg neg neg pos neg neg pos neg neg neg neg [137] neg pos neg neg neg neg neg neg neg neg pos neg neg neg neg pos pos pos pos pos neg neg neg neg neg neg neg neg pos pos neg neg neg neg [171] pos pos pos neg neg neg neg neg neg neg pos pos neg neg neg neg pos neg neg neg pos neg neg neg neg neg Levels: neg pos $posterior neg pos 4 0.903509648 0.09649035 5 0.651253333 0.34874667 14 0.000552298 0.99944770 classified real neg pos neg 103 27 pos 49 17 二次判別分析
drawparti(indians[,3],indians[,1],indians[,2],method=”qda”...) 二次判別分析
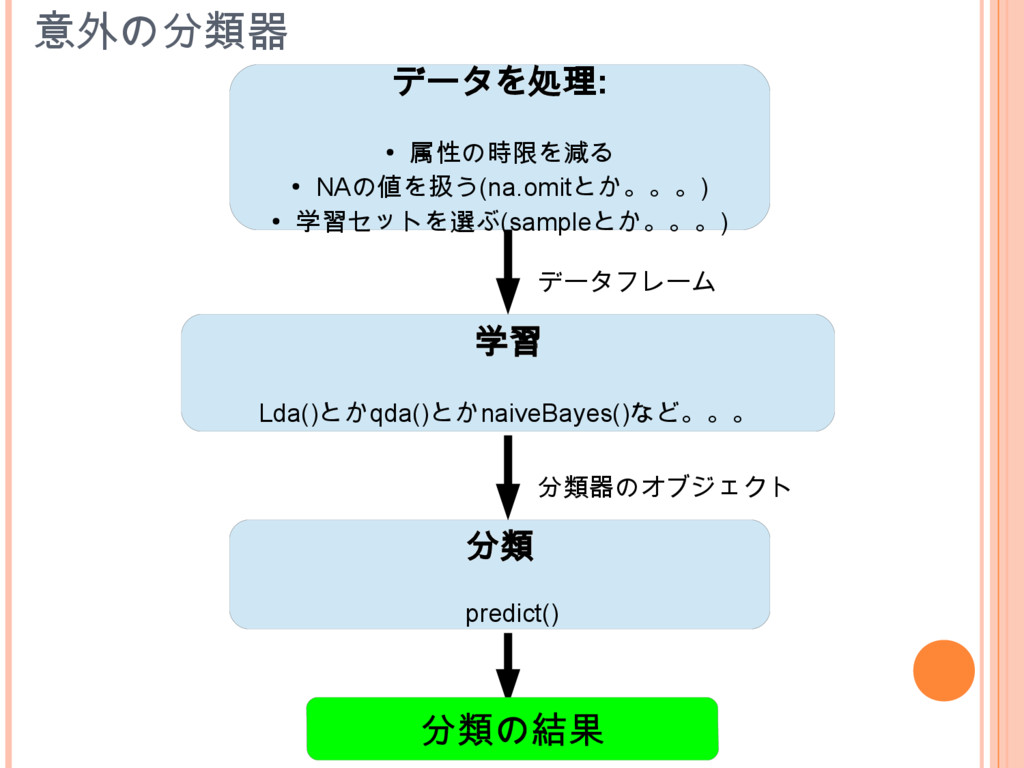
分類器 R言語のパッケージと関数 線形判別分析,二次判別分析 MASS(lda,qda) 単純バイズ分類器 e1071(naiveBayes), klaR(NaiveBayes) 決定木 tree(tree),rpart(rpart),party(cpart) Random
Forest randomForest(randomForest) k近傍法 class(knn),kknn(kknn),knncat(knncat) サポートバクターマシン e1071(svm) ニューラルネットァーク nnet(nnet) 意外の分類器
意外の分類器 データを処理: • 属性の時限を減る • NAの値を扱う(na.omitとか。。。) • 学習セットを選ぶ(sampleとか。。。) 学習 Lda()とかqda()とかnaiveBayes()など。。。
分類 predict() データフレーム 分類器のオブジェクト
R言語勉強会を参加していただいて ありがとうございました! Facebook: Paweł Rusin (
[email protected]
)
{kind=link}
![自己紹介 •Paweł Rusin (パヴェウ・ルシン) •[email protected] Facebook: Paweł Rusin ( [email protected])](https://files.speakerdeck.com/presentations/c079ad0b4f534a34ba62280f7ef3e7cf/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![訓練例とテスト例を分ける learning.sample = sample(x=1:nrow(indians),size=nrow(indians)/2) learning.set = indians[learning.sample,] sample(x, size, replace](https://files.speakerdeck.com/presentations/c079ad0b4f534a34ba62280f7ef3e7cf/slide_7.jpg){kind=link}
![訓練例とテスト例を分ける test.set = indians[-learning.set,-3] learning.set = sample(x=[1,2...392],size=196) [1] 120 321](https://files.speakerdeck.com/presentations/c079ad0b4f534a34ba62280f7ef3e7cf/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![線形判別分析 lin.classify = lda(indians[,1:2],grouping=indians$diabetes,subset=learning.sample) lda(x, grouping, ..., subset, na.action) [MASS]](https://files.speakerdeck.com/presentations/c079ad0b4f534a34ba62280f7ef3e7cf/slide_12.jpg){kind=link}
![線形判別分析 lin.class.predict = predict(lin.classify, newdata=test.set) predict (object, ...) $class [1]](https://files.speakerdeck.com/presentations/c079ad0b4f534a34ba62280f7ef3e7cf/slide_13.jpg){kind=link}
![線形判別分析 drawparti(grouping,x,y,method=”lda”...) [klaR] drawparti(indians[,3],indians[,1],indians[,2]...) drawparti(grouping, x, y, method = "lda",](https://files.speakerdeck.com/presentations/c079ad0b4f534a34ba62280f7ef3e7cf/slide_14.jpg){kind=link}
{kind=link}
![quad.classify = qda(indians[,1:2],grouping=indians$diabetes,subset=learning.sample) qda(x, grouping, ..., subset, na.action) [MASS] Call:](https://files.speakerdeck.com/presentations/c079ad0b4f534a34ba62280f7ef3e7cf/slide_16.jpg){kind=link}
{kind=link}
![drawparti(indians[,3],indians[,1],indians[,2],method=”qda”...) 二次判別分析](https://files.speakerdeck.com/presentations/c079ad0b4f534a34ba62280f7ef3e7cf/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
![R言語勉強会を参加していただいて ありがとうございました! Facebook: Paweł Rusin ([email protected])](https://files.speakerdeck.com/presentations/c079ad0b4f534a34ba62280f7ef3e7cf/slide_21.jpg){kind=link}