(Télécom SudParis)
Title — The late-stage training dynamics of (stochastic) subgradient descent on homogeneous neural networks
Abstract — We analyze the implicit bias of constant step stochastic subgradient descent (SGD). We consider the setting of binary classification with homogeneous neural networks – a large class of deep neural networks with ReLu-type activation functions such as MLPs and CNNs without biases. Interpreting the dynamics of normalized SGD iterates as an Euler-like discretization of a conservative field flow that is naturally associated to the normalized classification margin, we show that normalized SGD iterates converge to the set of critical points of the normalized margin at late-stage training (i.e., assuming that the data is correctly classified with positive normalized margin). Up to our knowledge, this is the first extension of the analysis of Lyu and Li (2020) on the discrete dynamics of gradient descent to the nonsmooth and stochastic setting. Our main result applies to binary classification with exponential or logistic losses. We additionally discuss extensions to more general settings.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
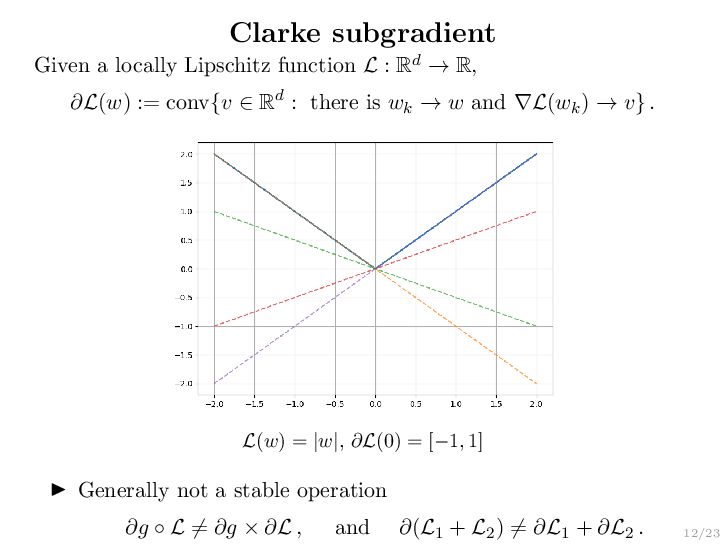{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}