Machine Learning — Was ist das eigentlich, und was haben GPUs damit zu tun?
Die Präsentation ist zur Vertriebsunterstützung eines Systemhauses, um Kunden eine kurze, grundlegende Übersicht zu Machine Learning und Deep Learning zu geben, sowie aktuelle NVIDIA Tesla GPUs zu positionieren.
& größter globaler Partner — seit über 20 Jahren § Lösungshersteller mit Fokus auf Technologie (First-to-Market Strategie) § London HQ, Niederlassungen in London City, München, Mumbai, Bangalore, New York. Weitere Expansion geplant. § Experten im Lösungs- und HPC-System-Design unter Verwendung von Premium-Komponenten von Supermicro und ausgewählten Partnern § Supermicros Fastest Growing Partner Über uns
Deep Learning, Historie § Anwendungsbeispiele für Machine Learning Wo wird Machine Learning schon heute genutzt? Was bringt die Zukunft? § Hardware- und Software-Ökosystem NVIDIA Tesla und Pascal, Supermicro ANNA, NVIDIA CUDA, Anwendungskatalog Agenda
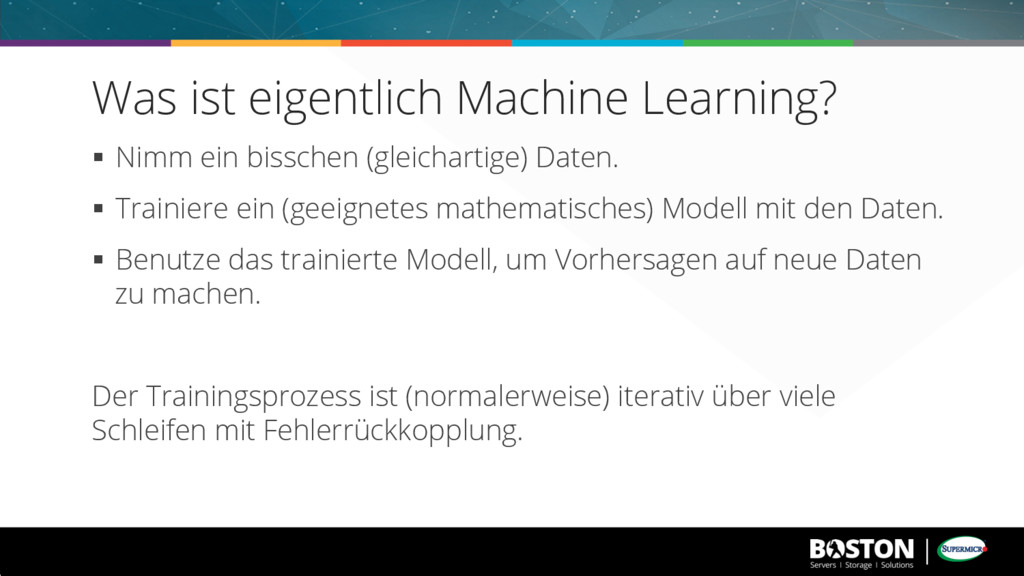
mathematisches) Modell mit den Daten. § Benutze das trainierte Modell, um Vorhersagen auf neue Daten zu machen. Der Trainingsprozess ist (normalerweise) iterativ über viele Schleifen mit Fehlerrückkopplung. Was ist eigentlich Machine Learning?
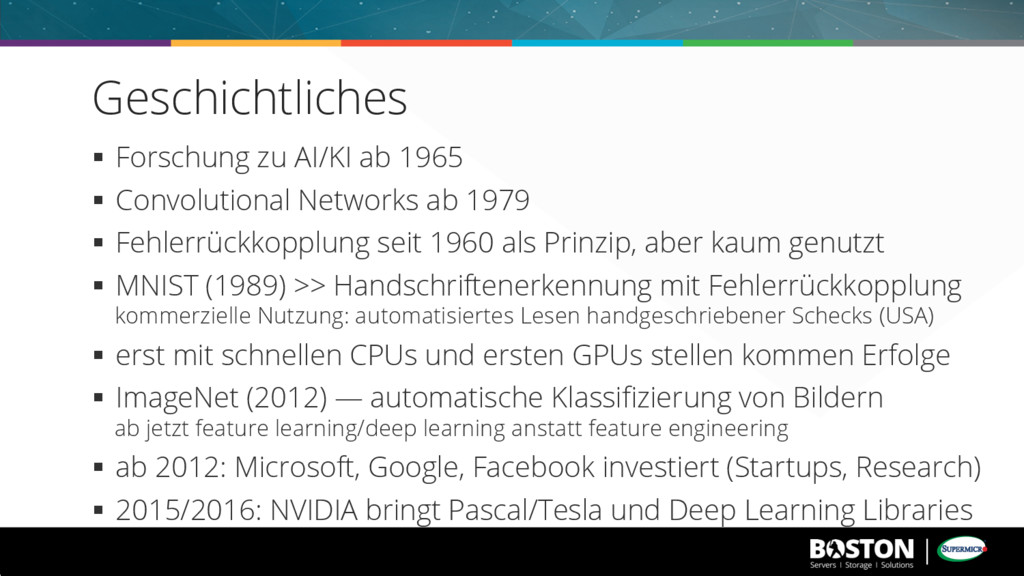
1979 § Fehlerrückkopplung seit 1960 als Prinzip, aber kaum genutzt § MNIST (1989) >> Handschriftenerkennung mit Fehlerrückkopplung kommerzielle Nutzung: automatisiertes Lesen handgeschriebener Schecks (USA) § erst mit schnellen CPUs und ersten GPUs stellen kommen Erfolge § ImageNet (2012) — automatische Klassifizierung von Bildern ab jetzt feature learning/deep learning anstatt feature engineering § ab 2012: Microsoft, Google, Facebook investiert (Startups, Research) § 2015/2016: NVIDIA bringt Pascal/Tesla und Deep Learning Libraries Geschichtliches
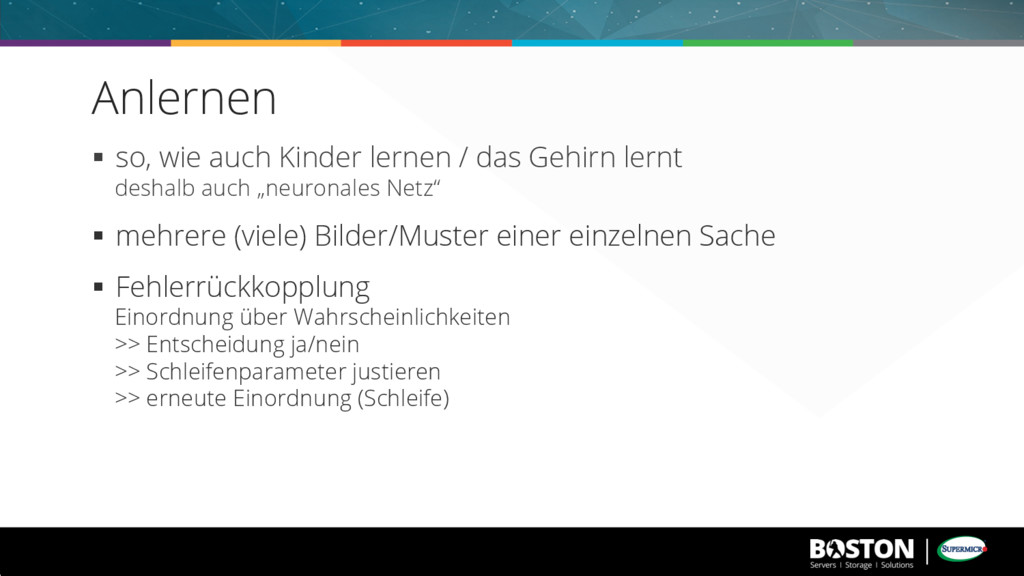
Neuron „feuert“ § derzeit ca. 5-10 hidden layer § Convolutional Networks vs. LSTM > Convolutional: Mustererkennung > LSTM: Long Short-Term Memory Zeitreihen über hunderte Zeitpunkte in die Vergangenheit Deep Learning
Spielbrett = Bild mit 19x19 Pixel § System spielt gegen sich selbst Fehlerrückkopplung, Feinabstimmung § Trainiertes neuronales Netz + Monte Carlo Search Trees Strategien, die für menschliche Spieler unmöglich oder unsinnig erscheinen, aber hohe Gewinnwahrscheinlichkeit haben § Spezialgebiet schneller erlernbar, als Lebenszeit eines Menschen ausreichen würde Beispiel: AlphaGo (Google)
https://www.youtube.com/playlist?list=PLE6Wd9FR--EfW8dtjAuPoTuPcqmOV53Fu § Deep Learning in a Nutshell 4-teilge Artikel-Serie im NVIDIA Developer Blog https://devblogs.nvidia.com/parallelforall/deep-learning-nutshell-core-concepts/ Wer Deep Learning genauer wissen will
following question: Can we translate between a language pair which the system has never seen before? An example of this would be translations between Korean and Japanese where Korean ⇄ Japanese examples were not shown to the system. Impressively, the answer is yes — it can generate reasonable Korean ⇄ Japanese translations, even though it has never been taught to do so.” https://research.googleblog.com/2016/11/zero-shot-translation-with-googles.html
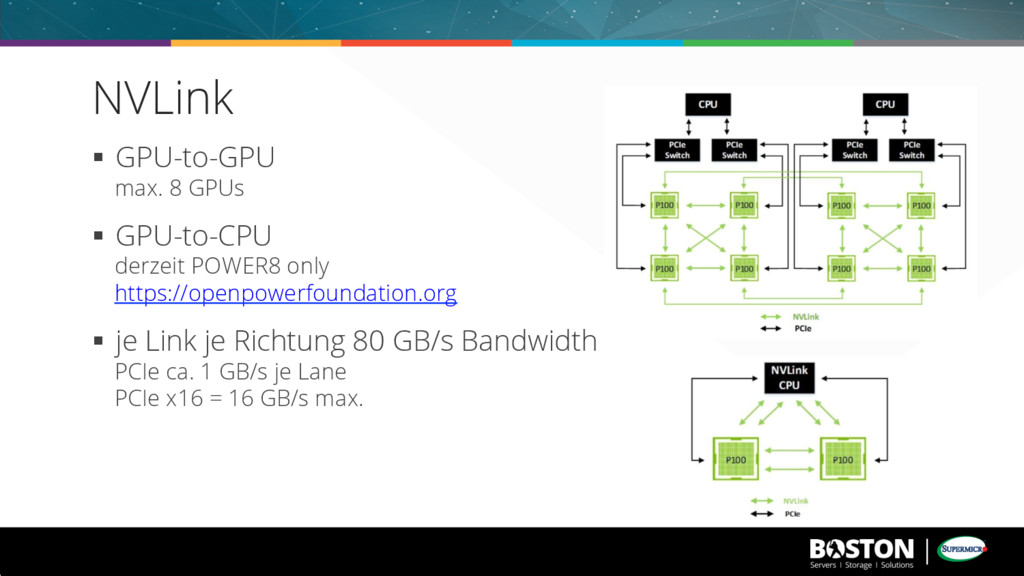
TB RAM max. 4x Tesla P100 NVLink 2x 2.5“ intern + 2x 2.5“ Hot Swap 4x PCIe (3x x8, 1x x16) § 85 TFLOPS peak (FP16) “delivers same model within days versus weeks with CPUs“ § demnächst: 8x P100 mit NVLink 2 HE vs. 3 HE NVIDIA DGX-1 10 GBE vs. 1 GBE only NVIDIA DGX-1 § bald: alternative HW-Architektur, P100 mit GPU-to-CPU NVLink Boston ANNA Pascal
SDK unterstützt alle üblichen Deep Learning Frameworks - cuDNN — Deep Learning Primitives - TensorRT — Deep Learning Inference Engine - DeepStream SDK — Deep Learning for Video Analytics - cuBLAS — Linear Algebra - cuSPARSE — Sparse Matrix Operations - NCCL — Multi-GPU Communication § https://developer.nvidia.com/deep-learning-software https://www.nvidia.com/content/gpu-applications/PDF/gpu-applications-catalog.pdf Software für P100 und Deep Learning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Kontakt +49 89 9090199-3 www.boston-itsolutions.de [email protected] BostonITsolutions @BostonGermany Boston-server-&-storage-solutions-gmbh](https://files.speakerdeck.com/presentations/7f8526f79e514125b5a87de70acb665a/slide_27.jpg){kind=link}