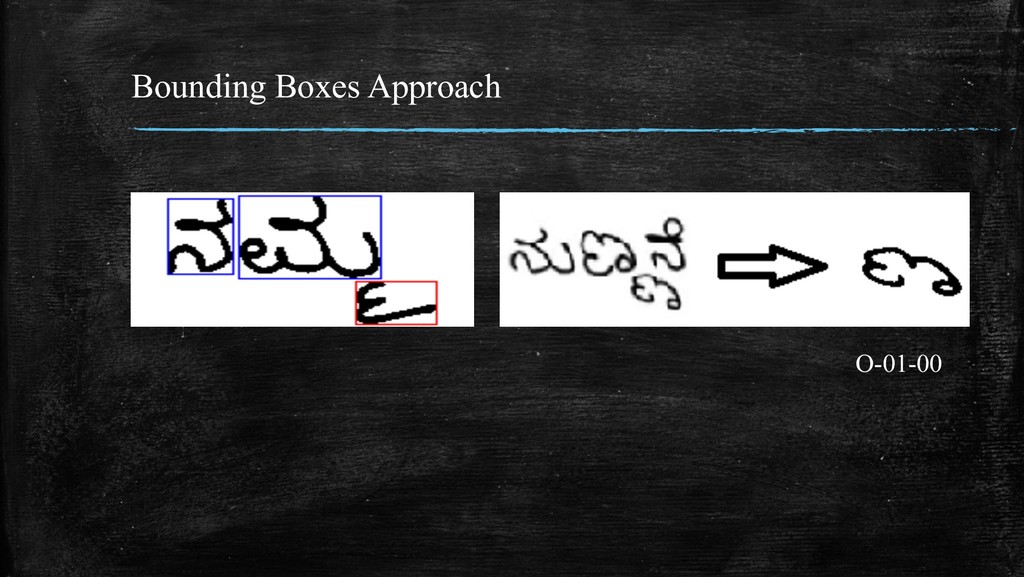
bounding boxes are each contour. 3. Ignore boxes with area less than 5% of the image area. 4. Extract corner co-ordinates of remaining boxes. 5. The bounding boxes whose top co-ordinate below half the height of the image contain an ottaksharas. 6. Since the image is parsed left-to-right, the ottaksharas can be mapped to the previous parsed character.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}