2024年4月に行われたKDDI・Supershipによる勉強会にて、Supership プロダクト開発本部 アドテクノロジーセンターの今村が講演した際のスライドです。
Supershipでは一緒に働くSuperな仲間を大募集中です!募集職種など採用情報は下記よりご参照ください。
https://supership.jp/recruit/
■講演タイトル:
Google Cloudデータ基盤 構成管理の反省と改善
■アジェンダ:
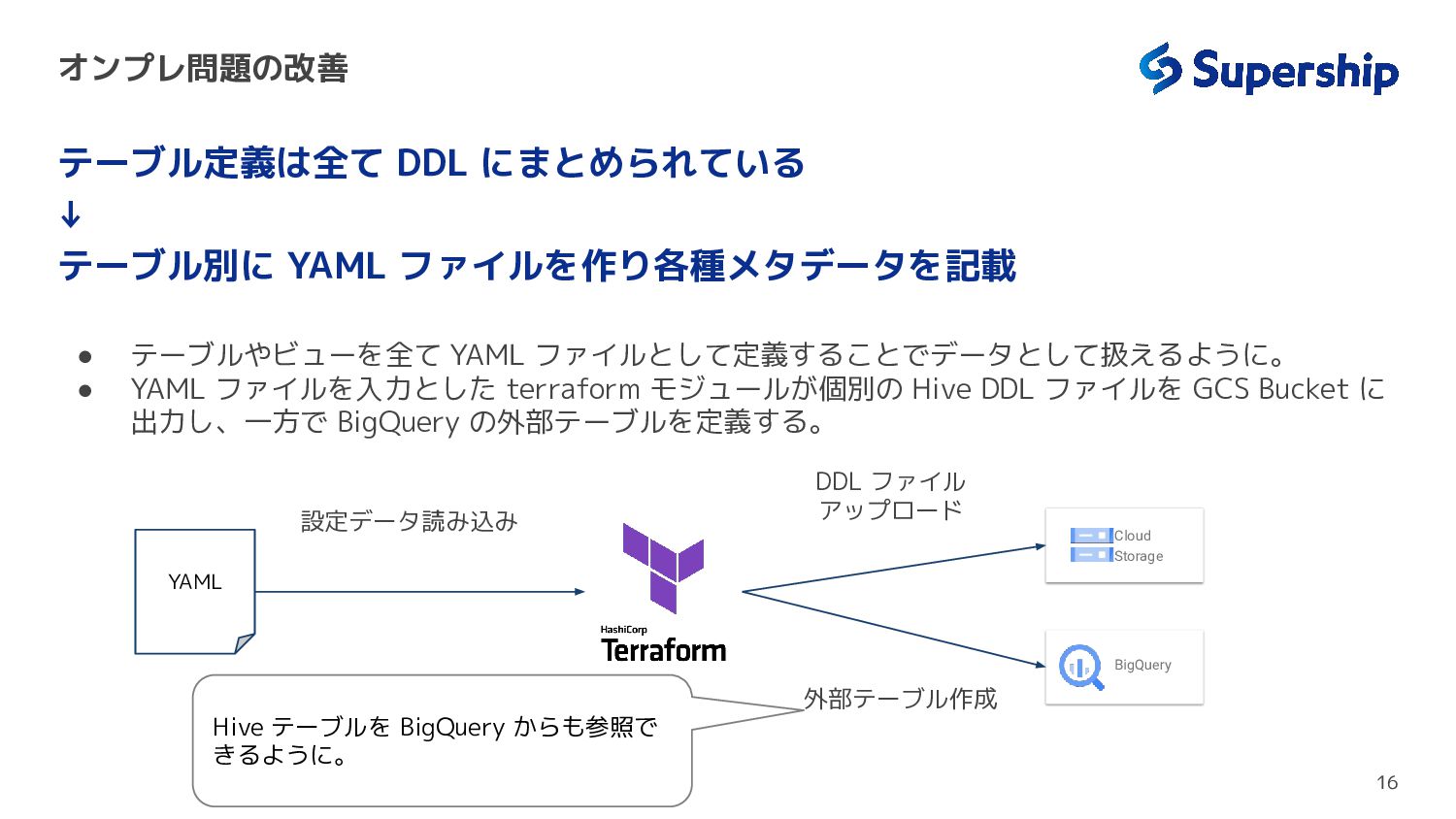
「ScaleOut DSP」におけるデータ基盤を、オンプレでの運用からGoogle Cloudを用いた運用へ移行する際の課題や改善策をスケーラビリティやアクセス管理などの観点からお話しします。
■登壇者:
Supership プロダクト開発本部 アドテクノロジーセンター
今村 豊
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}