Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20250513_人とAIの共生とHAZの構築_DMMの4000万人基盤の_商品レビューをA...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
matsui-dmm
May 13, 2025
Technology
230
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20250513_人とAIの共生とHAZの構築_DMMの4000万人基盤の_商品レビューをAI自動承認するまで.pdf
matsui-dmm
May 13, 2025
More Decks by matsui-dmm
See All by matsui-dmm
BSDD_Human-AI_Responsibility_Separation.pdf
takahiromatsui
0
65
2026-06-24_人とAIの責務分離に基づく開発プロセスの提案.pdf
takahiromatsui
0
320
2025-06-20_人とAIの_合意領域_に基づく_信頼性スコアモデリング___レビュー自動承認と信頼構築_HAZ__.pdf
takahiromatsui
0
1.5k
20250326_生成AIによる_レビュー承認システムの実現.pdf
takahiromatsui
22
8.6k
生成AIによるレビュー承認自動化___導入後14日間のレポート_.pdf
takahiromatsui
0
780
レビュー承認業務のAI自動化の紹介.pdf
takahiromatsui
0
170
AWS_Re_Invent_2024_参加レポート.pdf
takahiromatsui
0
650
レビュー基盤のDBクラウド化対応.pdf
takahiromatsui
0
93
生成AI(Claude3.5 Sonnet)による 次世代型レビュー承認システムの実現
takahiromatsui
1
610
Other Decks in Technology
See All in Technology
Why is RC4 still being used?
tamaiyutaro
0
310
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
280
Claude Codeとハーネスについて考えてみる
oikon48
18
8.8k
知らん間に、回ってる
ming_ayami
0
330
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
1.9k
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
150
最近評価が難しくなった
maroon8021
0
260
生成AIの活用/high_school2026
okana2ki
0
110
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
160
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
120
初めてのDatabricks勉強会
taka_aki
2
240
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
750
Featured
See All Featured
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Prompt Engineering for Job Search
mfonobong
0
370
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Color Theory Basics | Prateek | Gurzu
gurzu
0
380
How to train your dragon (web standard)
notwaldorf
97
6.7k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Transcript
© DMM © DMM CONFIDENTIAL DMMの4000万人基盤で 商品レビューを自動承認するまで ― 人とAIの共生とHAZの構築 ―
合同会社DMM.com PF第1開発部 松井高宏 1
© DMM Agenda • 1章. はじめに • 2章. 商品レビューシステムの概要と課題 •
3章. 自動化までの取り組み • 4章. 自動化の成果 • 5章. 人とAIのこれから 2
© DMM 1章. はじめに 3 3
© DMM 4 松井 高宏(まつい たかひろ) • 所属: PF第1開発部 •
業務: レビュープロダクト BEエンジニア • 役職: チームリーダー • SNS:@matsui_tk 会社紹介 • なんでもやっているDMM • 60事業以上を展開するエンタメ企業 • 売上高:3600億円、従業員:4500人 自己紹介
© DMM Executive Summary 5 概要 • 商品レビューのWEB公開の可否判断(=承認業務) をAIで自動化 ◦
運営部が規約に基づき公開可否を判断 ◦ 公開誤りが企業ブランドに直結する 高リスクな業務 成果 • 年間50万件の承認業務を自動化 ◦ 【Before】 月150時間/公開まで7日 ◦ 【After】 6割を自動承認/公開10分以内(99.5%削減) 設計思想 • 「人とAIの共生」がテーマ、安全で段階的な自動化を推進 展望 • 将来的には8割までの自動化見込み レビュー承認業務の自動化プロジェクト
© DMM 2章. 商品レビューシステム 概要と課題 6 6
© DMM 7 2章.システム概要 • PF開発部:DMMの60以上の事業で使うレビューを共通機能として提供 • 運営部:レビューを審査・承認・WEB公開(コンテンツ・モデレーション) 共通機能 PF開発部
運営部 WEB公開 商品レビュー
© DMM *コンテンツモデレーションとは • 不適切な投稿を監視し、安全なWEB環境を維持する業務 • SNS普及により重要性が急上昇 ◦ 総務省による誹謗中傷に関するワーキンググループも毎年、開催 8
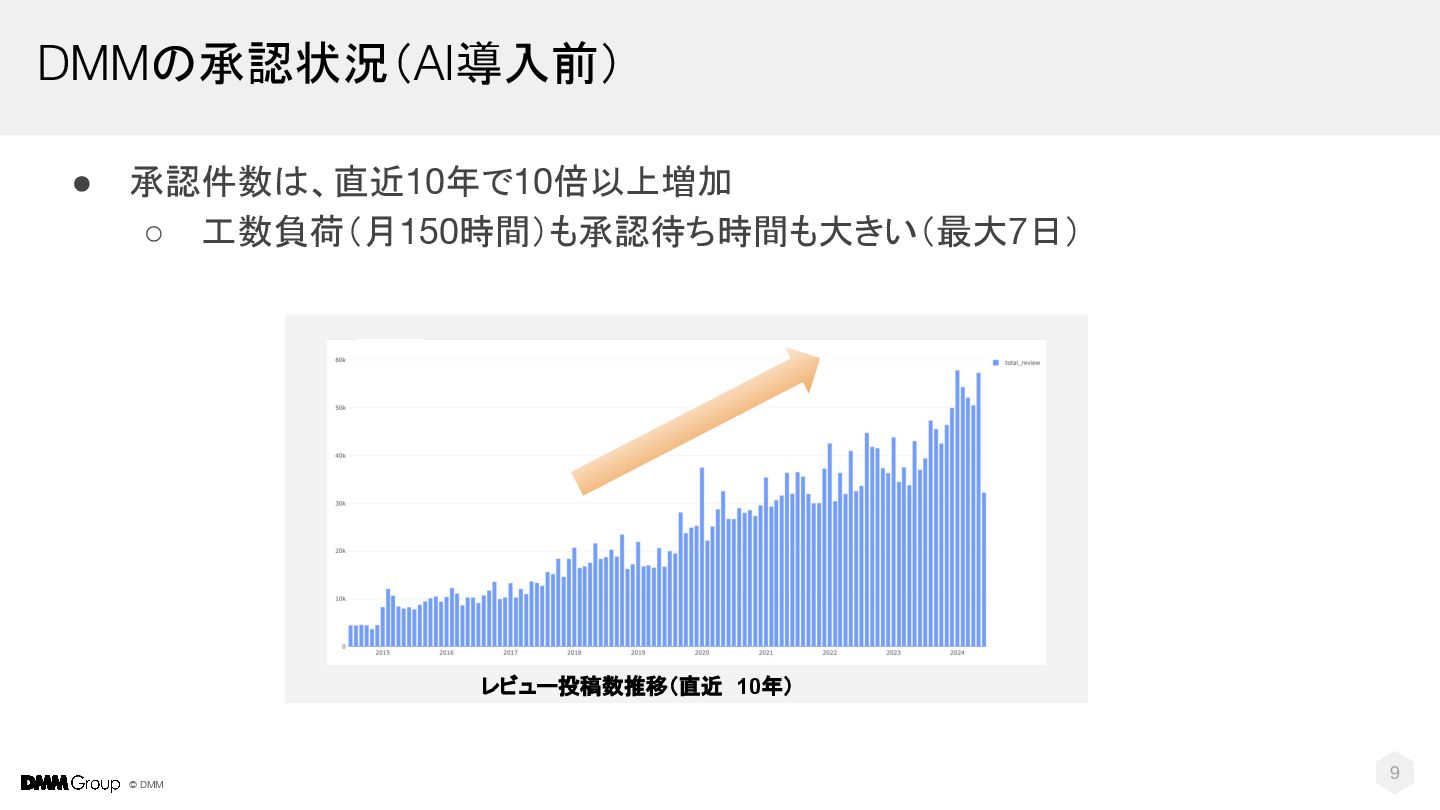
© DMM 9 • 承認件数は、直近10年で10倍以上増加 ◦ 工数負荷(月150時間)も承認待ち時間も大きい(最大7日) レビュー投稿数推移(直近 10年) DMMの承認状況(AI導入前)
© DMM 10 • 自社規約に基づき審査するが、文脈やニュアンスで承認可否が異なる ◦ 「下手すぎ、二度と出ないで」→ NG(攻撃的) ◦ 「下手だが、改善余地あり」 →
OK(批判的だが許容) • この自然言語の曖昧さが、従来、自動化を困難にしていた レビュー審査の難しさ 誹謗中傷 「ゴミ」「◦ね」「糞」 苦情 「サイト運営が最悪」 意味不明 「ああああああ」 購入非推奨 「商品は詐欺」「偽物です」 📌 審査NGの文言例
© DMM 11 生成AI導入検討 • 直近で生成AIの言語解析力が高まり、ニュアンス把握も可能になった • そこで今回、レビュー承認業務への生成AI導入を提案しました! 📌 生成AIによるメリット
工数削減 承認作業を大幅に削減 ✂ スピード向上 最大1週間の待機時間がリアルタイム化 ⚡ 基準の一貫性 判断のブレがなくなる 📏 拡張性 投稿数増にも安定運用が可能 📈
© DMM 生成AI活用した重要な理由 ── 継続性 × 説明可能性 (XAI) ── 12
• 継続性 ◦ AI専門家でなくても継続し、改善できるシンプルさ ◦ BEエンジニア中心のチームでも全員改善が可能 • 説明可能性( XAI) ◦ 「〇〇が規約違反に該当」 とAIが説明できる為、現場が納得する ◦ 従来:レビューの理由説明が技術的にも難しく、 また人が対応する場合も多くの工数がかかってしまった
© DMM 3章. 自動化までの取り組み 13
© DMM Phase1 Phase2 Phase3 Phase4
Phase5 導入準備 (PoC) 承認支援 システム構築 精度向上 (HITL) 自動化 戦略 自動化シス テム構築 自動化までの5フェーズ 14 • 承認システムの自動化の実現は計5段階を経て 10ヶ月かけて実現 ◦ 承認支援システム (人主導) :AIの判断結果を参考に人が最終承認 ◦ 自動化システム (AI主導) :人の介在がない完全自動のシステム
© DMM Phase1 導入準備(PoC) Ph1 導入準備(PoC) Ph2 承認支援システム構築 Ph3 精度向上
Ph4 自動化戦略 Ph5 自動化システム構築 ▶ 15
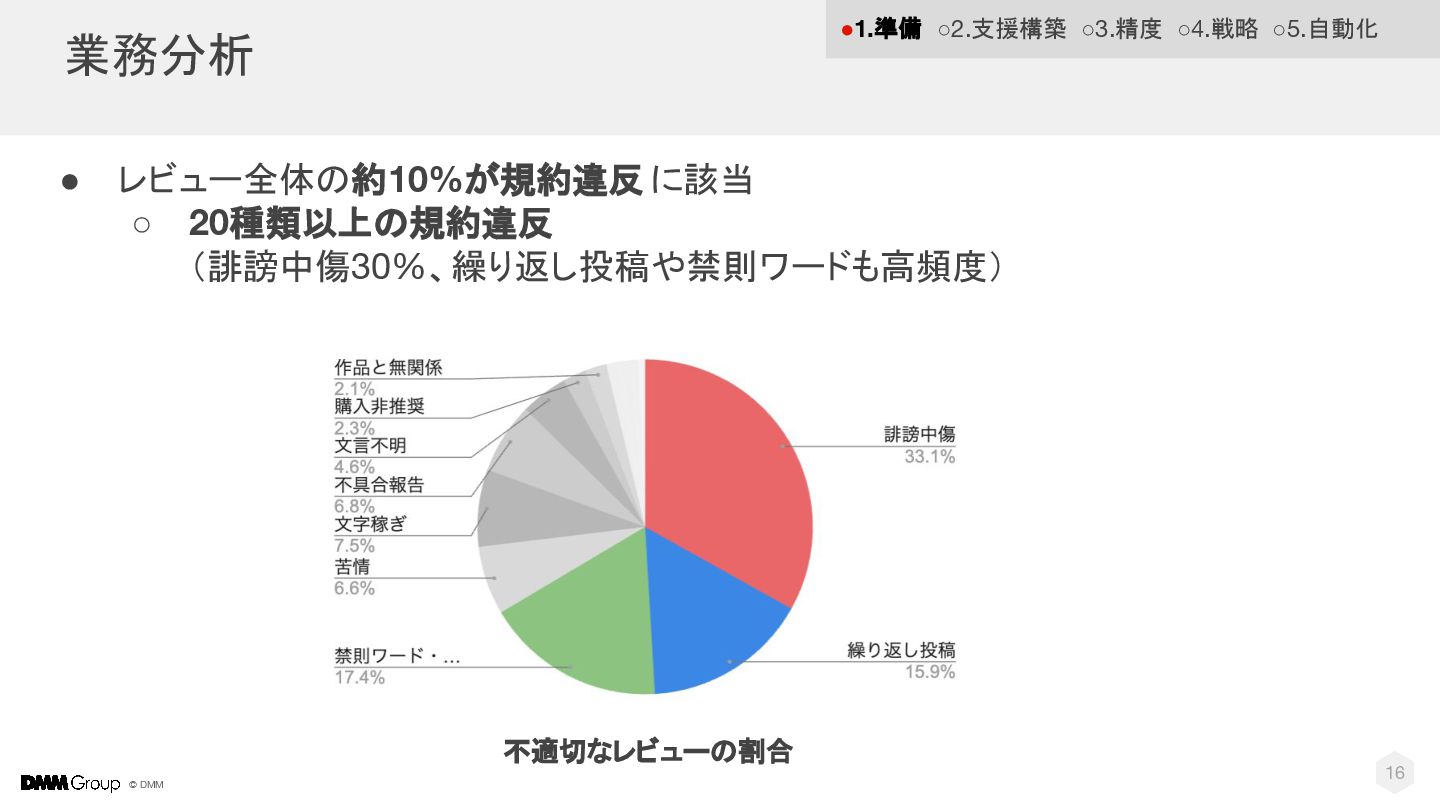
© DMM 業務分析 16 不適切なレビューの割合 • レビュー全体の約10%が規約違反 に該当 ◦ 20種類以上の規約違反
(誹謗中傷30%、繰り返し投稿や禁則ワードも高頻度) •1.準備 ◦2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
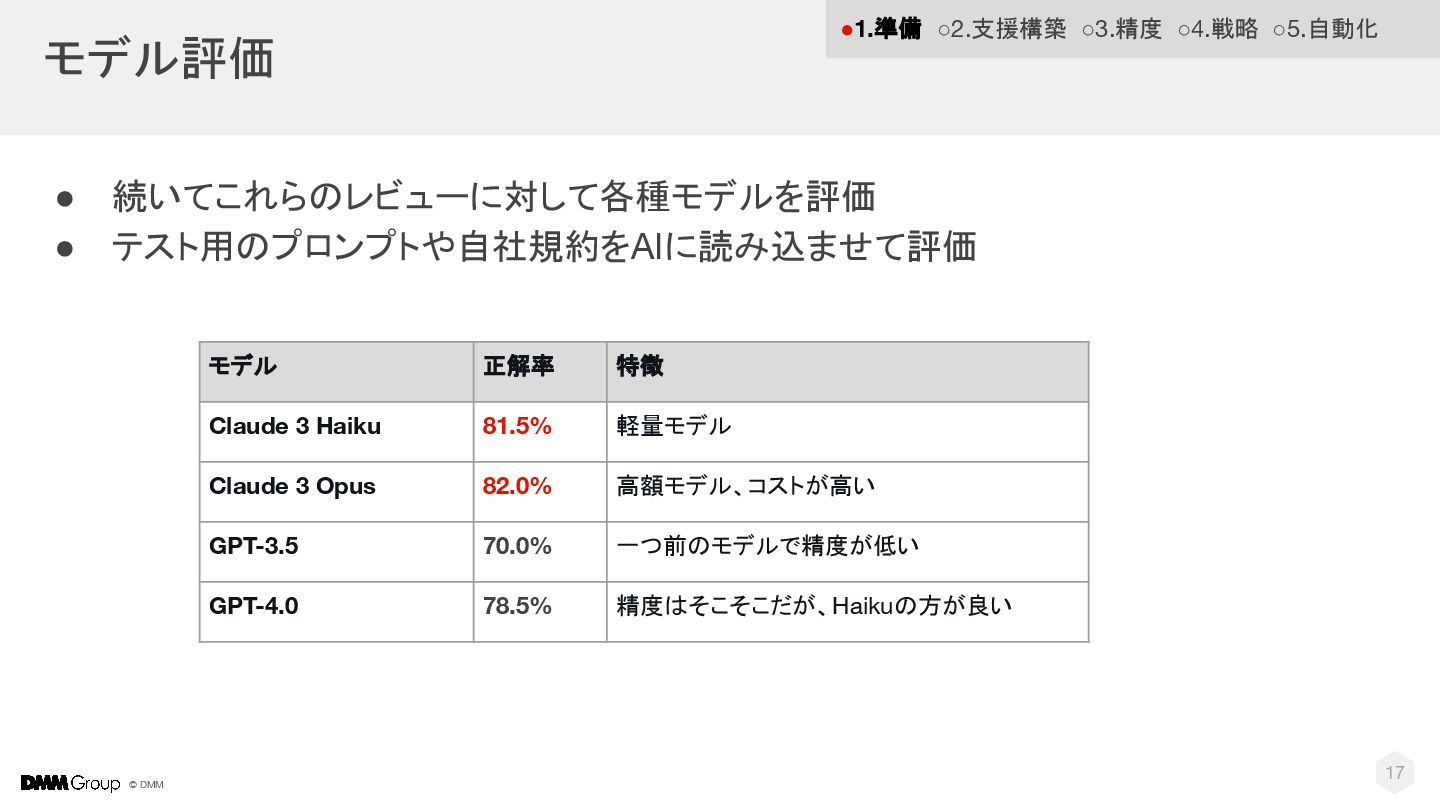
© DMM モデル評価 17 • 続いてこれらのレビューに対して各種モデルを評価 • テスト用のプロンプトや自社規約をAIに読み込ませて評価 モデル 正解率
特徴 Claude 3 Haiku 81.5% 軽量モデル Claude 3 Opus 82.0% 高額モデル、コストが高い GPT-3.5 70.0% 一つ前のモデルで精度が低い GPT-4.0 78.5% 精度はそこそこだが、Haikuの方が良い •1.準備 ◦2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
© DMM 18 *テストプロンプト # 役割 - あなたはレビューを審査するエージェントです。 # 評価プロセス
- レビュー情報の内容を把握してください。 - 判断項目を順に評価してください。 - 該当する可能性がある場合は、NGと出力します。 # 判断基準 - 誤解を招く可能性のある表現 - 過度に攻撃的/下品な表現 # 出力形式 <output> <result>判定結果</result> <score>スコア</score> <reason>理由の説明</reason> <category>該当カテゴリ(N001)</category> </output> •1.準備 ◦2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
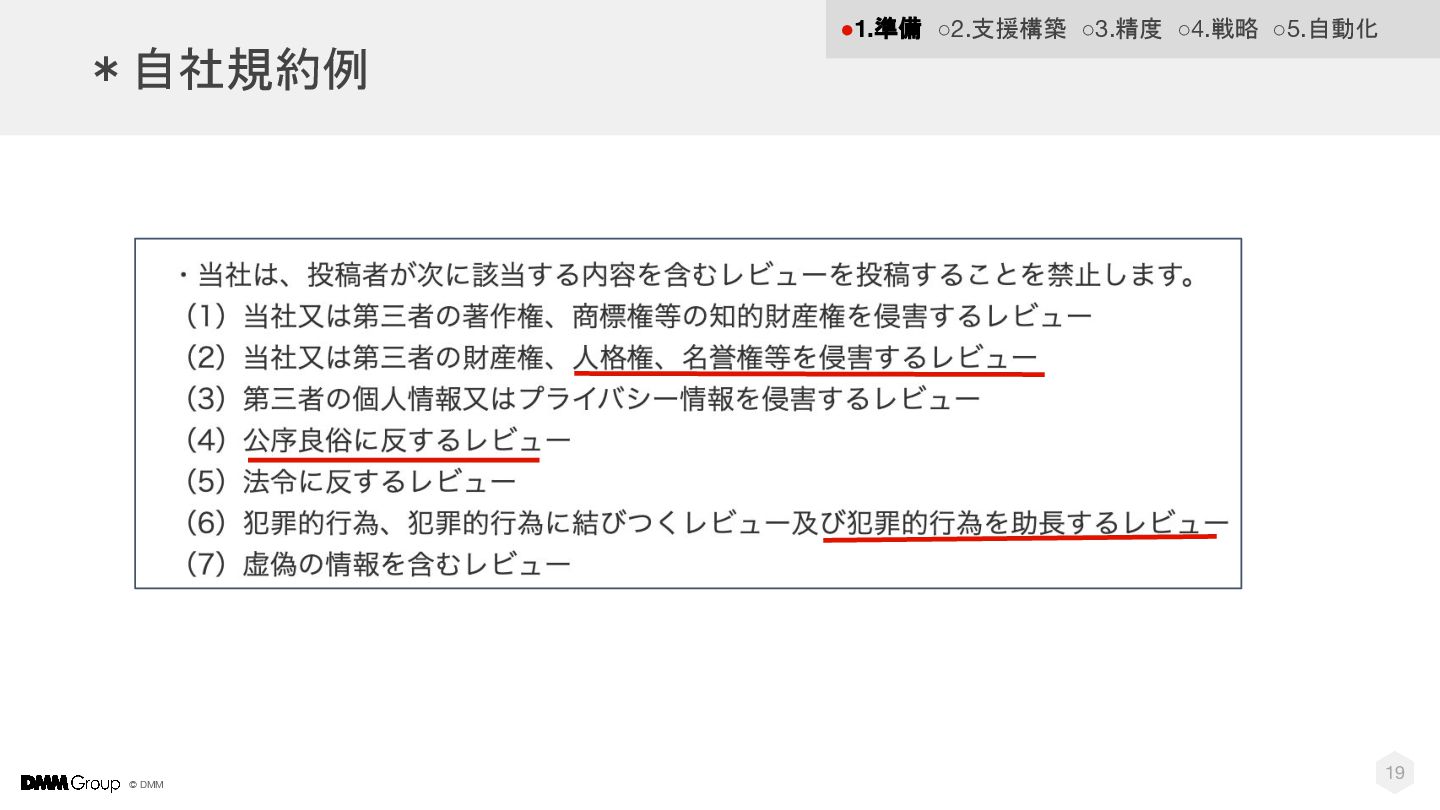
© DMM *自社規約例 19 •1.準備 ◦2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
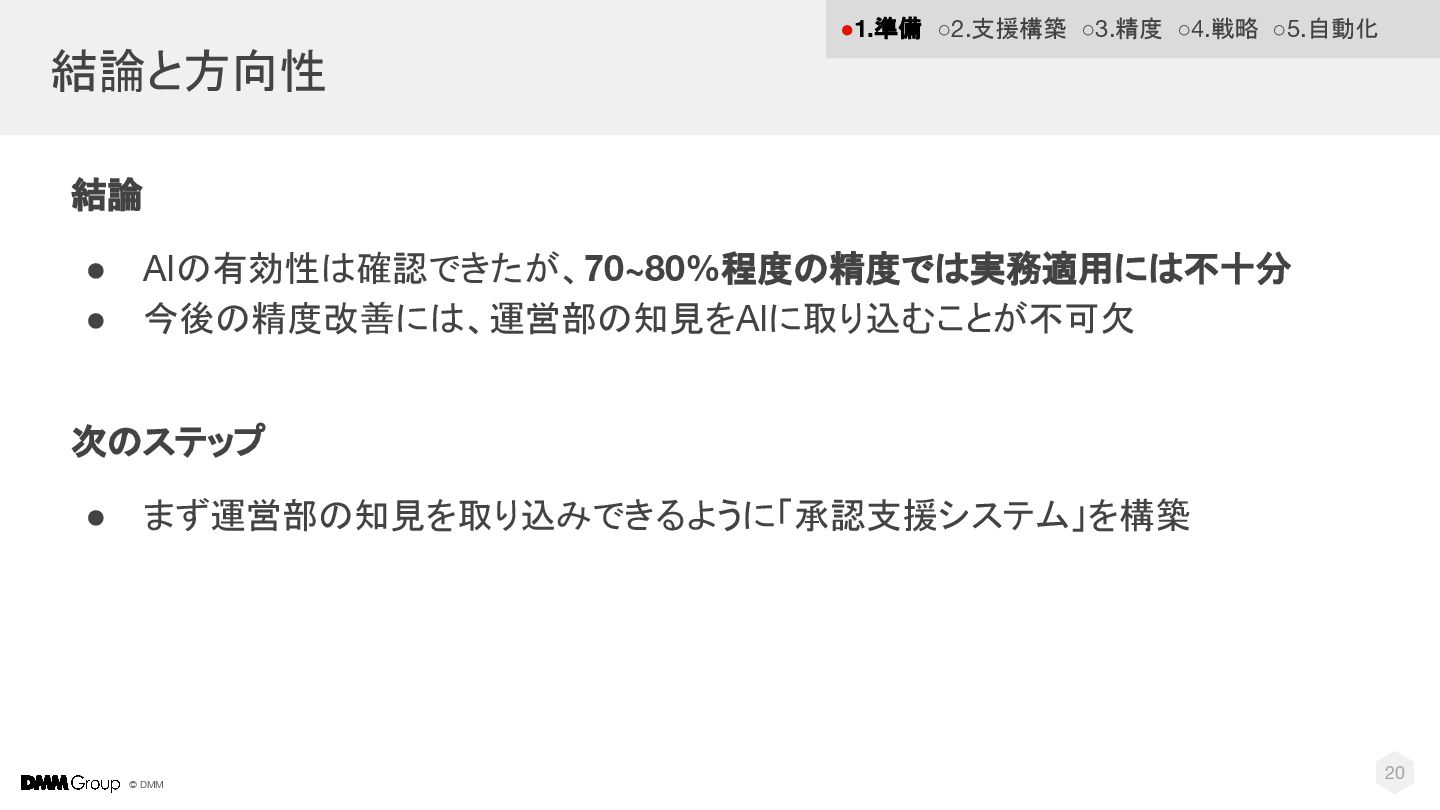
© DMM 20 結論と方向性 結論 • AIの有効性は確認できたが、70~80%程度の精度では実務適用には不十分 • 今後の精度改善には、運営部の知見をAIに取り込むことが不可欠 次のステップ
• まず運営部の知見を取り込みできるように「承認支援システム」を構築 •1.準備 ◦2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
© DMM Phase2 承認支援システムの構築 Ph1 導入準備(PoC) Ph2 承認支援システム構築 Ph3 精度向上
Ph4 自動化戦略 Ph5 自動化システム構築 ▶ 21
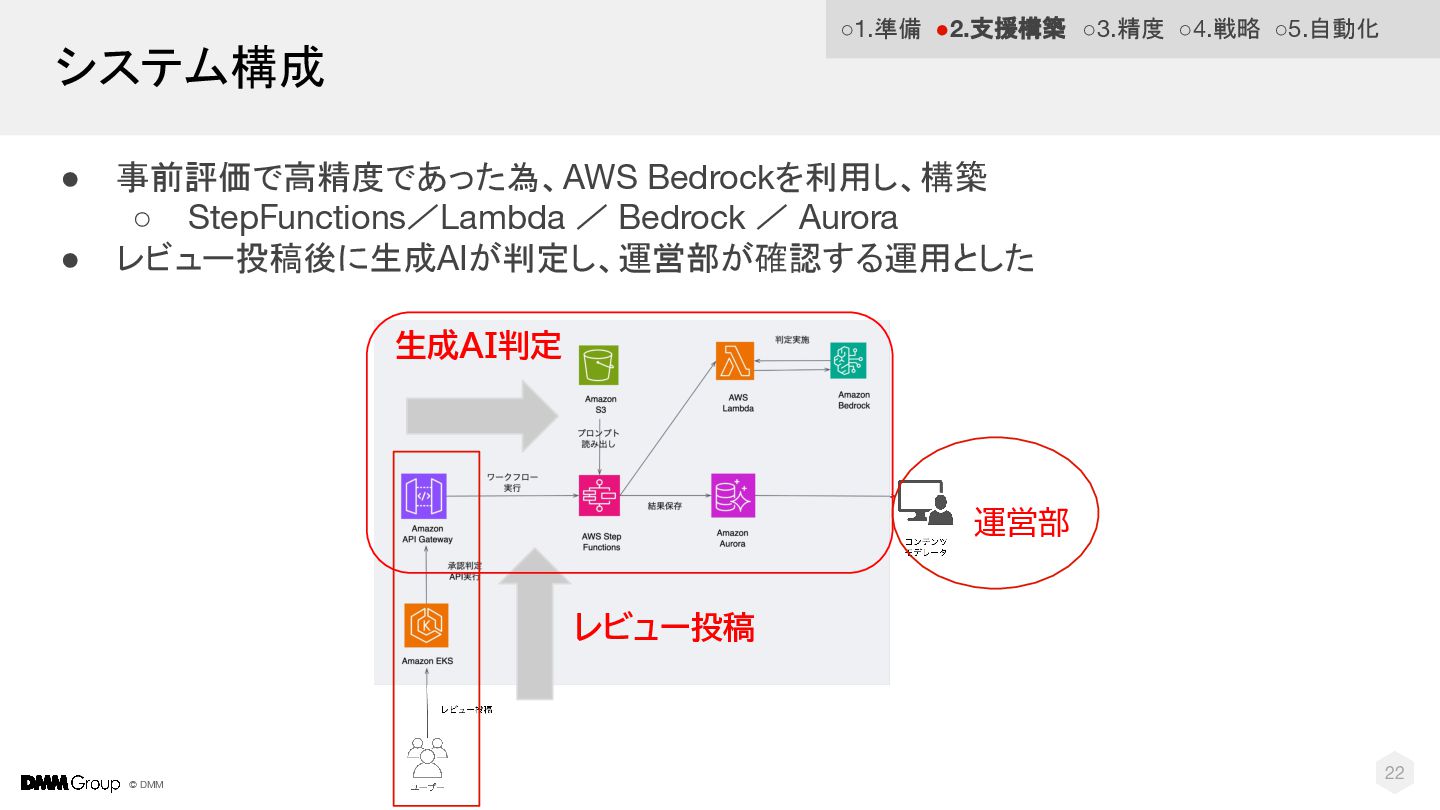
© DMM 22 システム構成 • 事前評価で高精度であった為、AWS Bedrockを利用し、構築 ◦ StepFunctions/Lambda /
Bedrock / Aurora • レビュー投稿後に生成AIが判定し、運営部が確認する運用とした レビュー投稿 生成AI判定 運営部 ◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
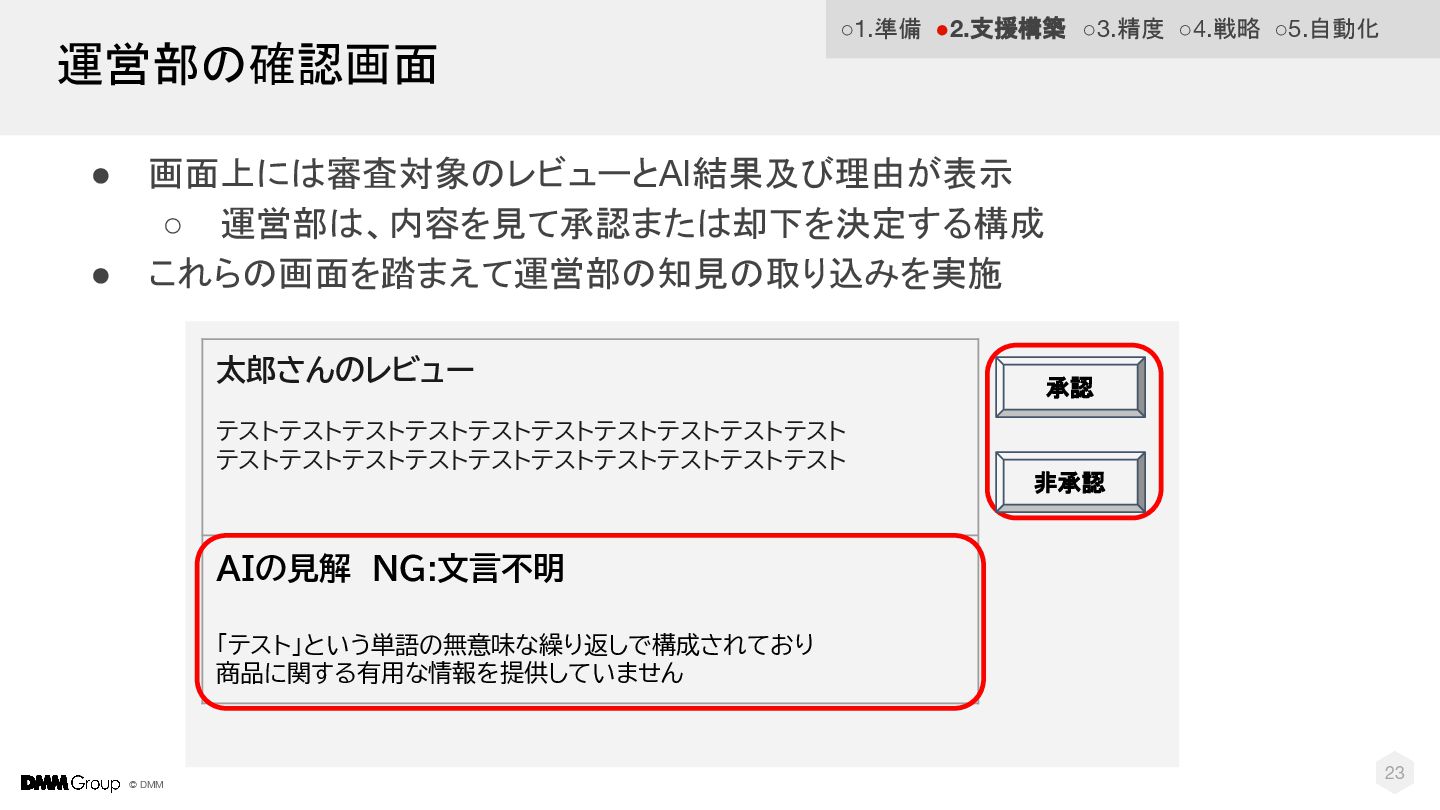
© DMM 運営部の確認画面 太郎さんのレビュー テストテストテストテストテストテストテストテストテストテスト テストテストテストテストテストテストテストテストテストテスト AIの見解 NG:文言不明 「テスト」という単語の無意味な繰り返しで構成されており 商品に関する有用な情報を提供していません •
画面上には審査対象のレビューとAI結果及び理由が表示 ◦ 運営部は、内容を見て承認または却下を決定する構成 • これらの画面を踏まえて運営部の知見の取り込みを実施 承認 非承認 23 ◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
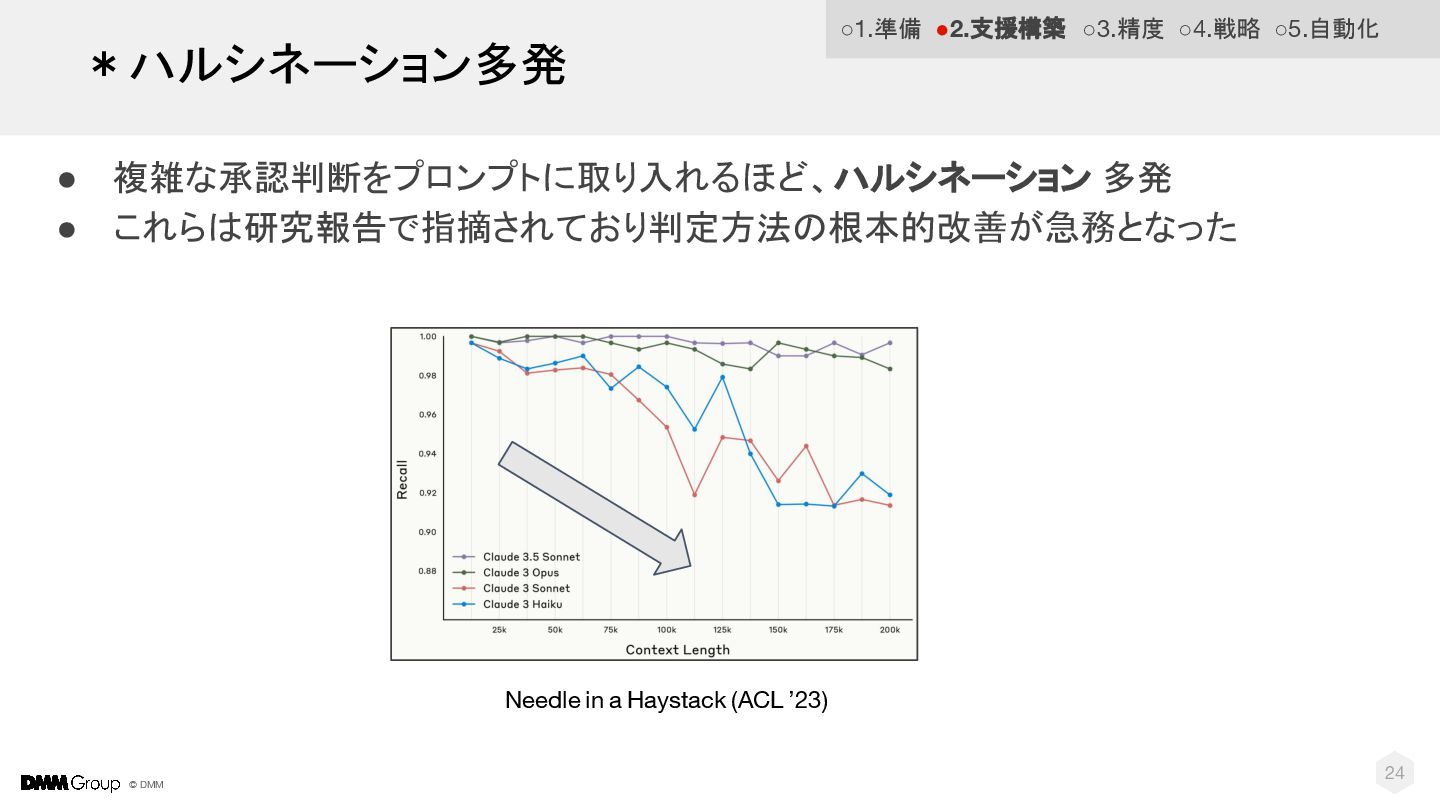
© DMM 24 *ハルシネーション多発 • 複雑な承認判断をプロンプトに取り入れるほど、ハルシネーション 多発 • これらは研究報告で指摘されており判定方法の根本的改善が急務となった Needle in a Haystack (ACL ’23)
◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
© DMM 25 Agentic Workflow の構築 • Before:1つのAIがすべての承認判断を一括で担う構成(モノリシック) • 解決策:承認判断を役割で分離し、複数のステップで個別AIに判断させる方針
「AgenticWorkflow:LLM版マイクロサービスアーキテクチャ」 ステップ A ステップ B ステップ C 判断結果 AIも役割分離すれば、 迷わず判断が可能 ◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
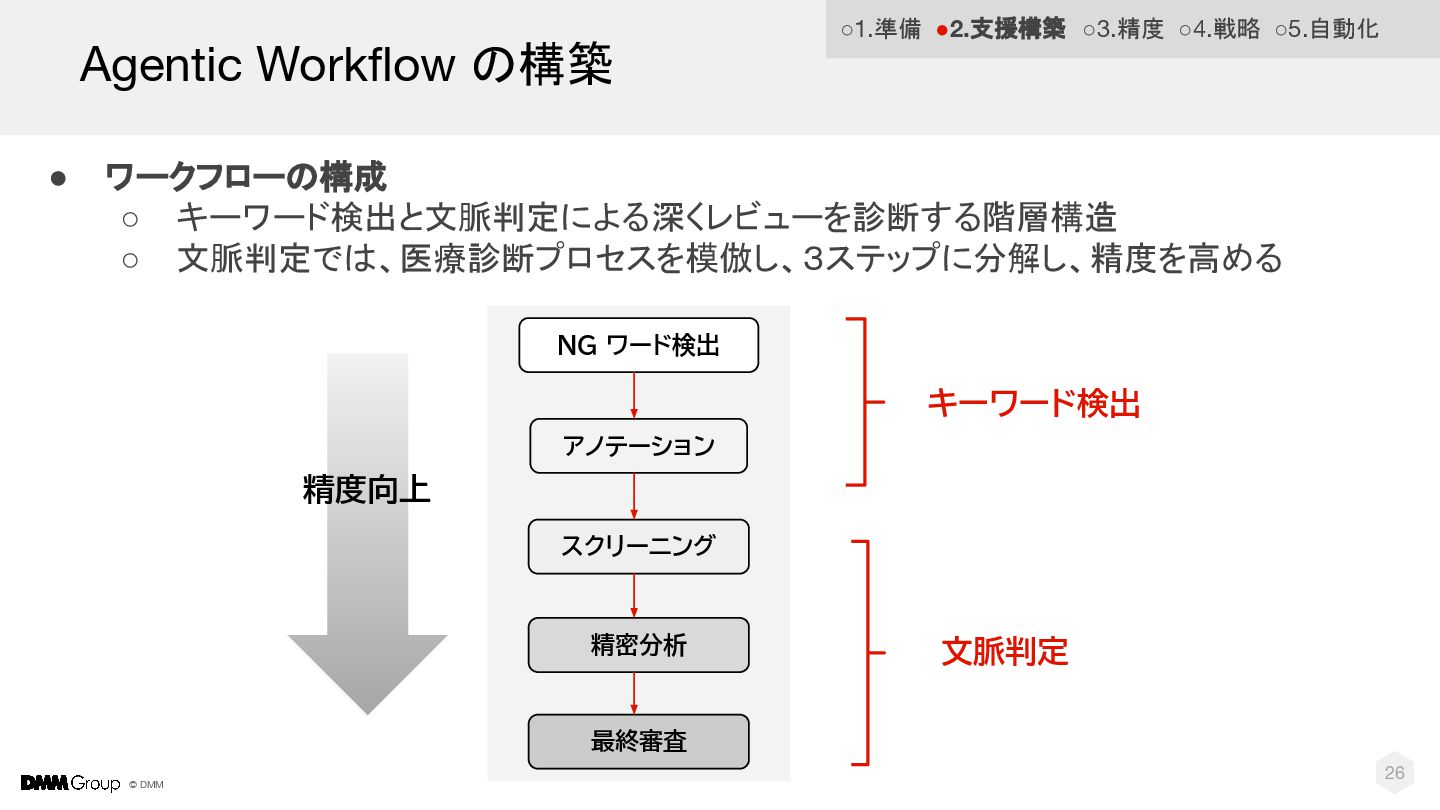
© DMM キーワード検出 文脈判定 Agentic Workflow の構築 精度向上 • ワークフローの構成
◦ キーワード検出と文脈判定による深くレビューを診断する階層構造 ◦ 文脈判定では、医療診断プロセスを模倣し、3ステップに分解し、精度を高める NG ワード検出 最終審査 精密分析 アノテーション スクリーニング 26 ◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
© DMM 27 アノテーション • 不適切な可能性のある語彙を検出し、マーク • 判定結果はその後のステップで利用 NGワード検出 •
NGワード検出されると、即時NG判定終了 例)出演者はクソだ → 出演者は*クソ*だ 例)きのう、◦ねと言われた -> NG *各ステップの例 最終審査 精密分析 スクリーニング アノテーション NG ワード検出 ◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
© DMM 28 スクリーニング • 簡易検査項目に従い 問題点を洗い出すステップ • 検査異常なければ、判定終了 •
異常があれば精密分析へ # 簡易検査 N001. 誹謗中傷に該当するか N002. プライバシー侵害に該当するか N003. 不明な文言が存在するか N004. 著作権侵害の可能性があるか N005. 過度な暴力的表現が含まるか ・・ 例) 出演者は*クソ*だ → N001の誹謗中傷に該当 NG ワード検 出 アノテーショ ン スクリーニング 最終審査 精密分析 アノテーション NG ワード検出 スクリーニング *各ステップの例 ◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
© DMM 29 精密分析 • 該当したカテゴリを 専用プロンプトで分析 • 大量サンプルで分析 N001:
誹謗中傷 # NG基準 - N001-01: 製作者の特徴を侮辱する表現 - N001-02: 攻撃的または下品な言葉遣い - N001-03: 作品や製作陣を不当に貶める表現 # NGサンプル - "太りすぎ、クソすぎる 頭悪すぎ" - "下手すぎ。素人以下。二度と見たくない" - "視聴者をバカにしてる。低レベル" NG ワード検 出 アノテーショ ン スクリーニング 最終審査 精密分析 アノテーション NG ワード検出 スクリーニング *各ステップの例 例) 出演者は*クソ*だ → 誹謗中傷の観点で精密分析 ◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
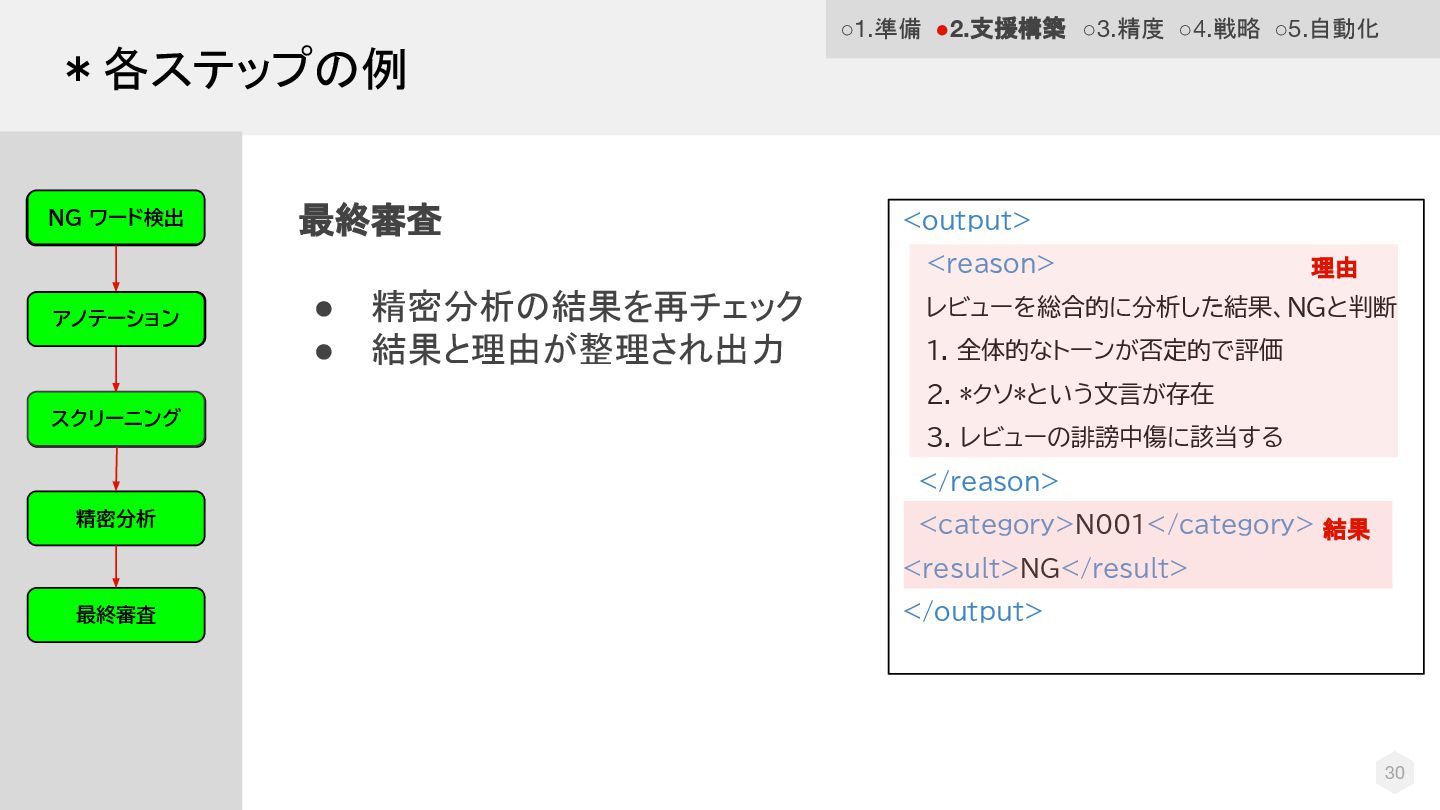
© DMM 30 最終審査 • 精密分析の結果を再チェック • 結果と理由が整理され出力 <output> <reason>
レビューを総合的に分析した結果、NGと判断 1. 全体的なトーンが否定的で評価 2. *クソ*という文言が存在 3. レビューの誹謗中傷に該当する </reason> <category>N001</category> <result>NG</result> </output> NG ワード検 出 最終審査 精密分析 アノテーショ ン スクリーニング アノテーション NG ワード検出 スクリーニング *各ステップの例 ◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化 理由 結果
© DMM • 大多数はスクリーニングで終了、不適切な可能性のレビューのみ精密分析 • 必要箇所に大量のトークンを使用する構成でコスト最適も実現 判定数減 NG ワード検出 最終審査
精密分析 アノテーション スクリーニング *補足:コスト最適化も実現 31 終 了 問題あり 問題なし
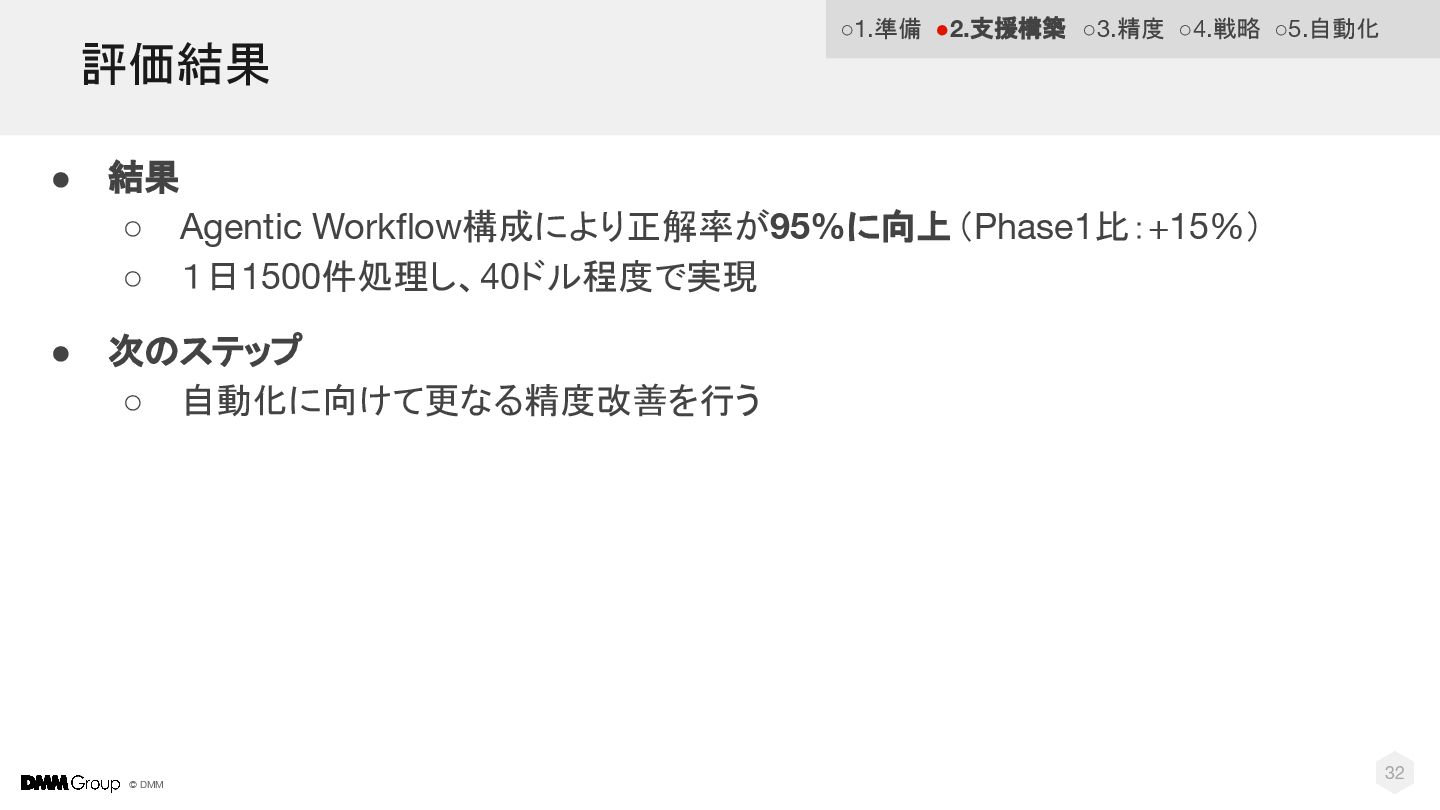
© DMM 32 • 結果 ◦ Agentic Workflow構成により正解率が95%に向上(Phase1比:+15%) ◦ 1日1500件処理し、40ドル程度で実現
• 次のステップ ◦ 自動化に向けて更なる精度改善を行う 評価結果 ◦1.準備 •2.支援構築 ◦3.精度 ◦4.戦略 ◦5.自動化
© DMM Phase3 精度向上(HITL) Ph1 導入準備(PoC) Ph2 承認支援システム構築 Ph3 精度向上
Ph4 自動化戦略 Ph5 自動化システム構築 ▶ 33
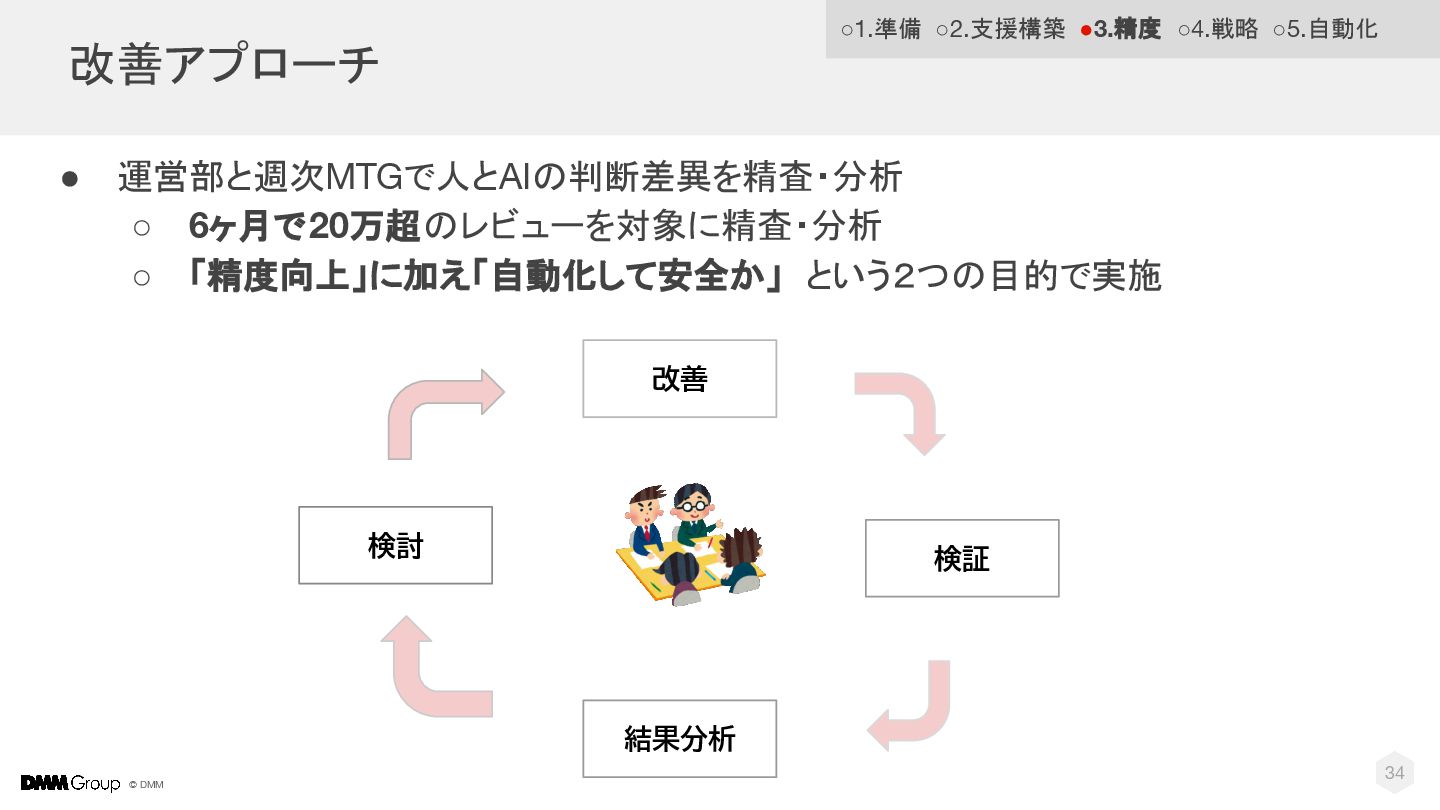
© DMM 34 改善アプローチ • 運営部と週次MTGで人とAIの判断差異を精査・分析 ◦ 6ヶ月で20万超のレビューを対象に精査・分析 ◦ 「精度向上」に加え「自動化して安全か」
という2つの目的で実施 検討 改善 検証 結果分析 ◦1.準備 ◦2.支援構築 •3.精度 ◦4.戦略 ◦5.自動化
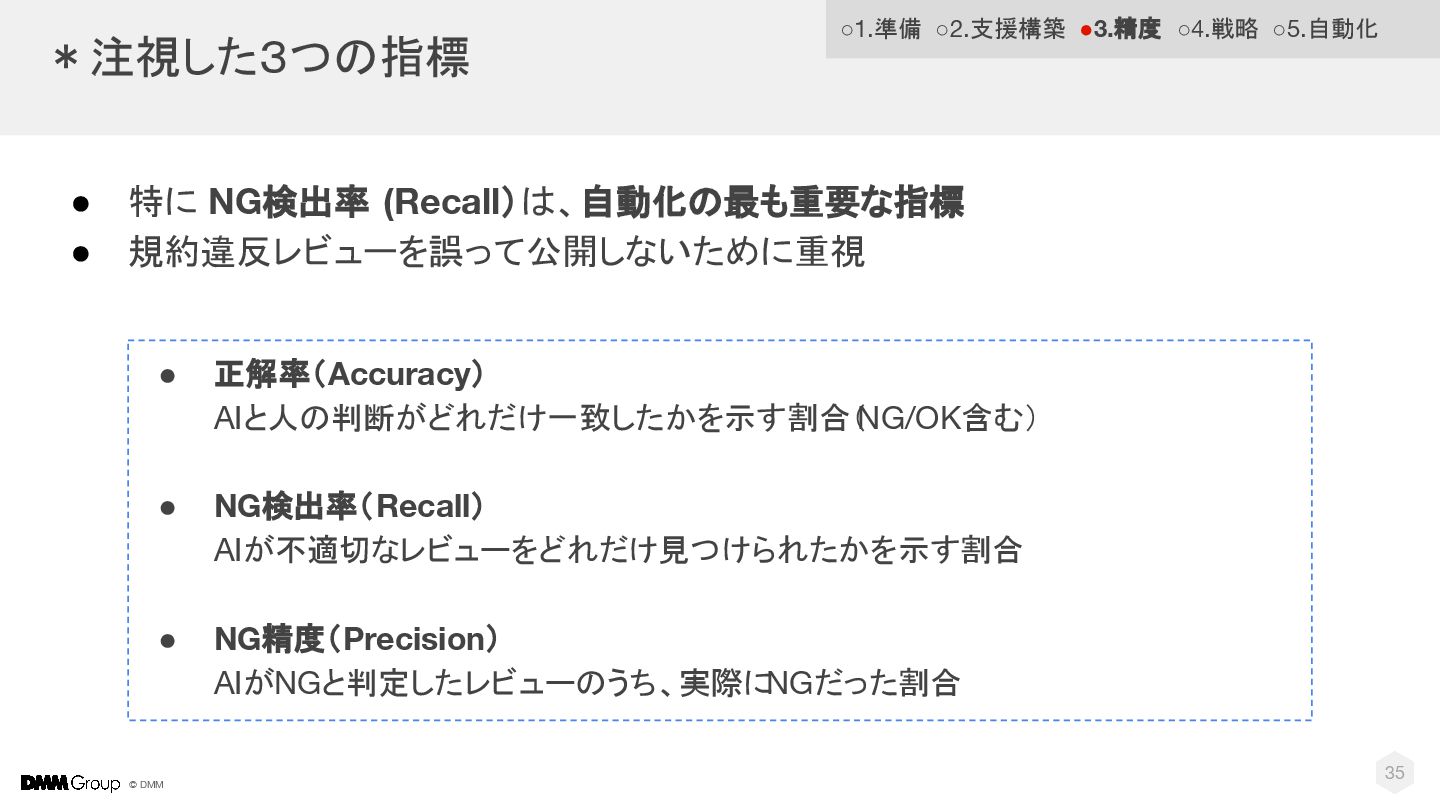
© DMM *注視した3つの指標 • 特に NG検出率 (Recall)は、自動化の最も重要な指標 • 規約違反レビューを誤って公開しないために重視 35
• 正解率(Accuracy) AIと人の判断がどれだけ一致したかを示す割合( NG/OK含む) • NG検出率(Recall) AIが不適切なレビューをどれだけ見つけられたかを示す割合 • NG精度(Precision) AIがNGと判定したレビューのうち、実際に NGだった割合 ◦1.準備 ◦2.支援構築 •3.精度 ◦4.戦略 ◦5.自動化
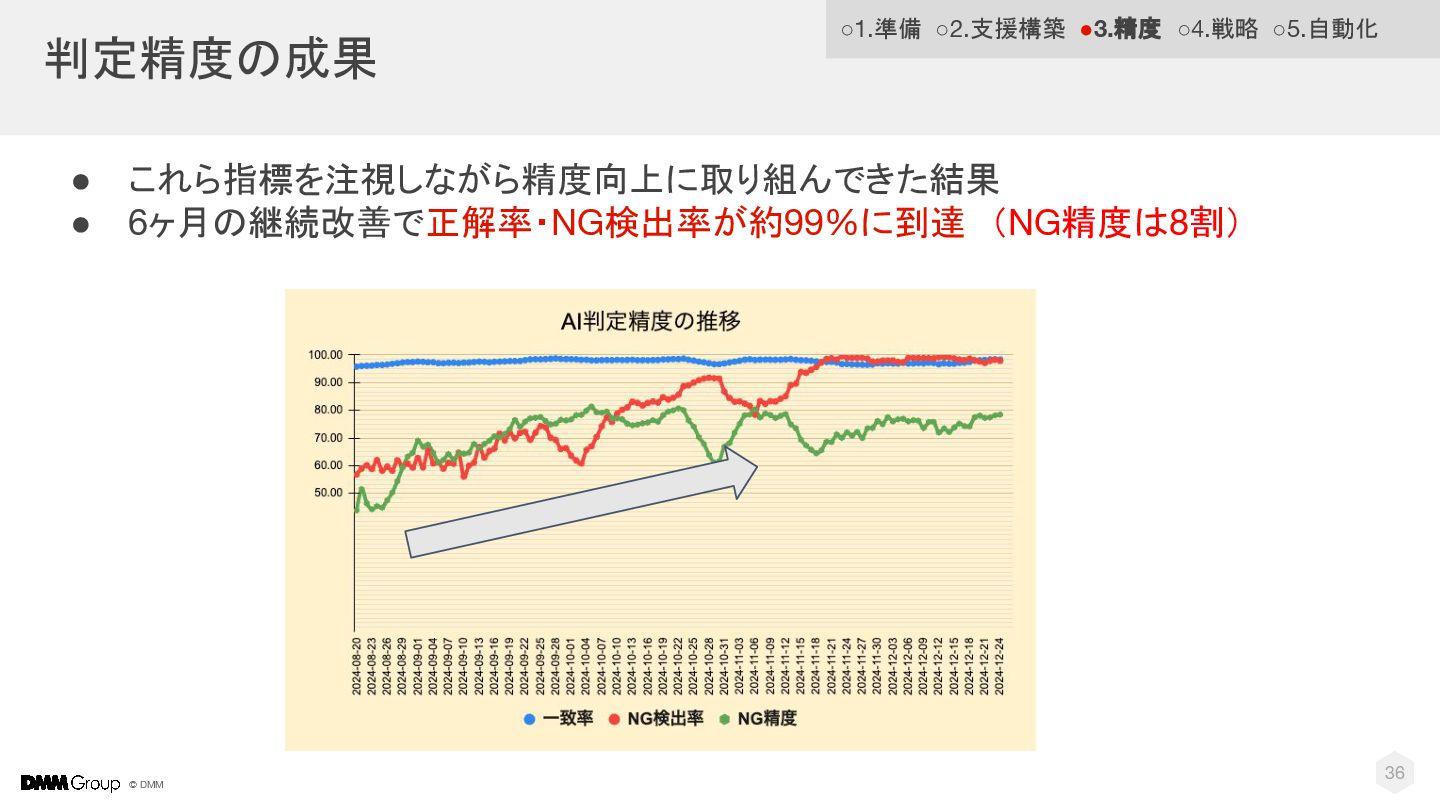
© DMM 判定精度の成果 • これら指標を注視しながら精度向上に取り組んできた結果 • 6ヶ月の継続改善で正解率・NG検出率が約99%に到達 (NG精度は8割) 36 ◦1.準備 ◦2.支援構築
•3.精度 ◦4.戦略 ◦5.自動化
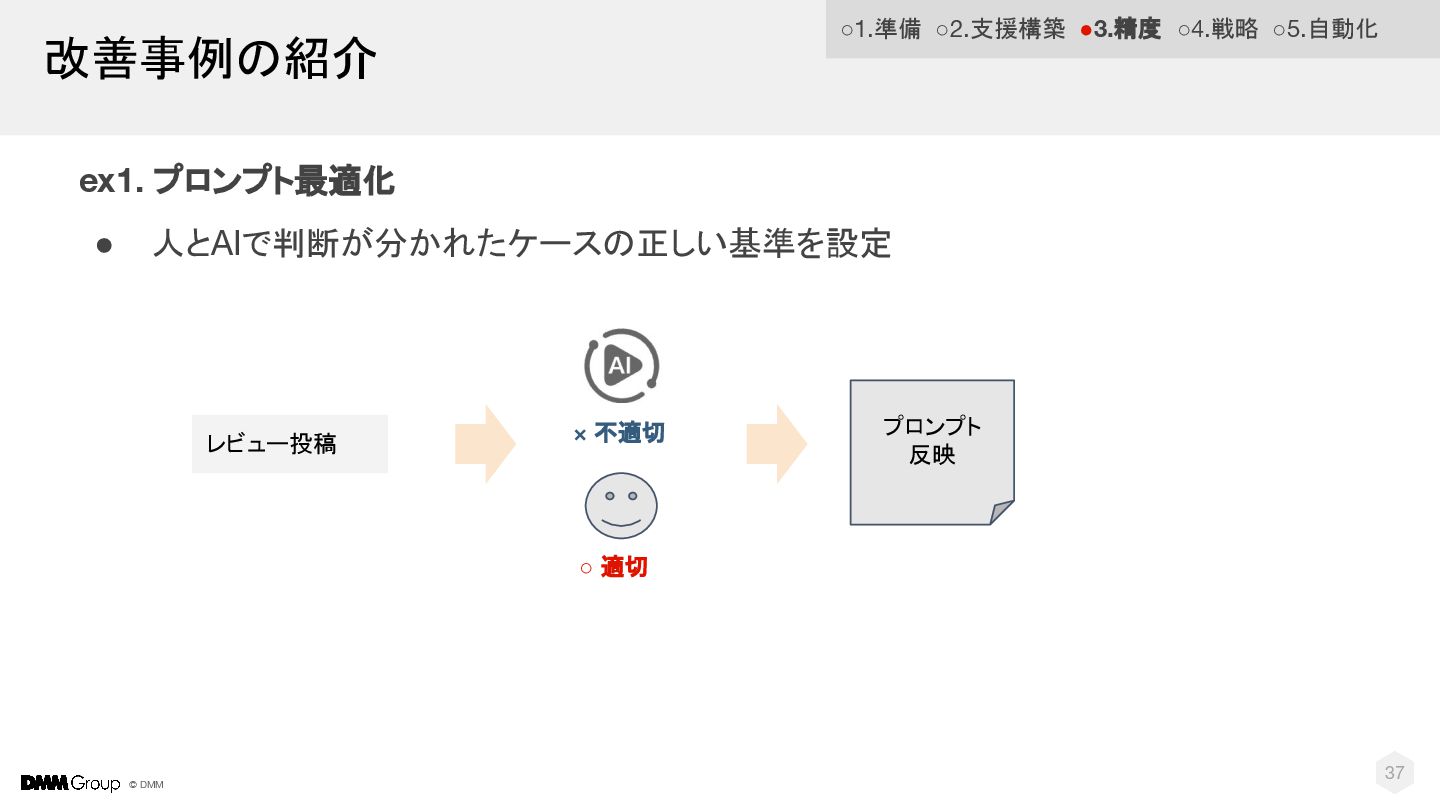
© DMM 改善事例の紹介 37 ex1. プロンプト最適化 • 人とAIで判断が分かれたケースの正しい基準を設定 ◦ 適切
× 不適切 レビュー投稿 プロンプト 反映 ◦1.準備 ◦2.支援構築 •3.精度 ◦4.戦略 ◦5.自動化
© DMM 改善事例の紹介 ex2. モデルのバージョンアップ対応 • 新モデル登場で安価で性能の高いモデルが使用可能となった ◦ Claude3.7のモデルを適用(現在)
38 ◦1.準備 ◦2.支援構築 •3.精度 ◦4.戦略 ◦5.自動化
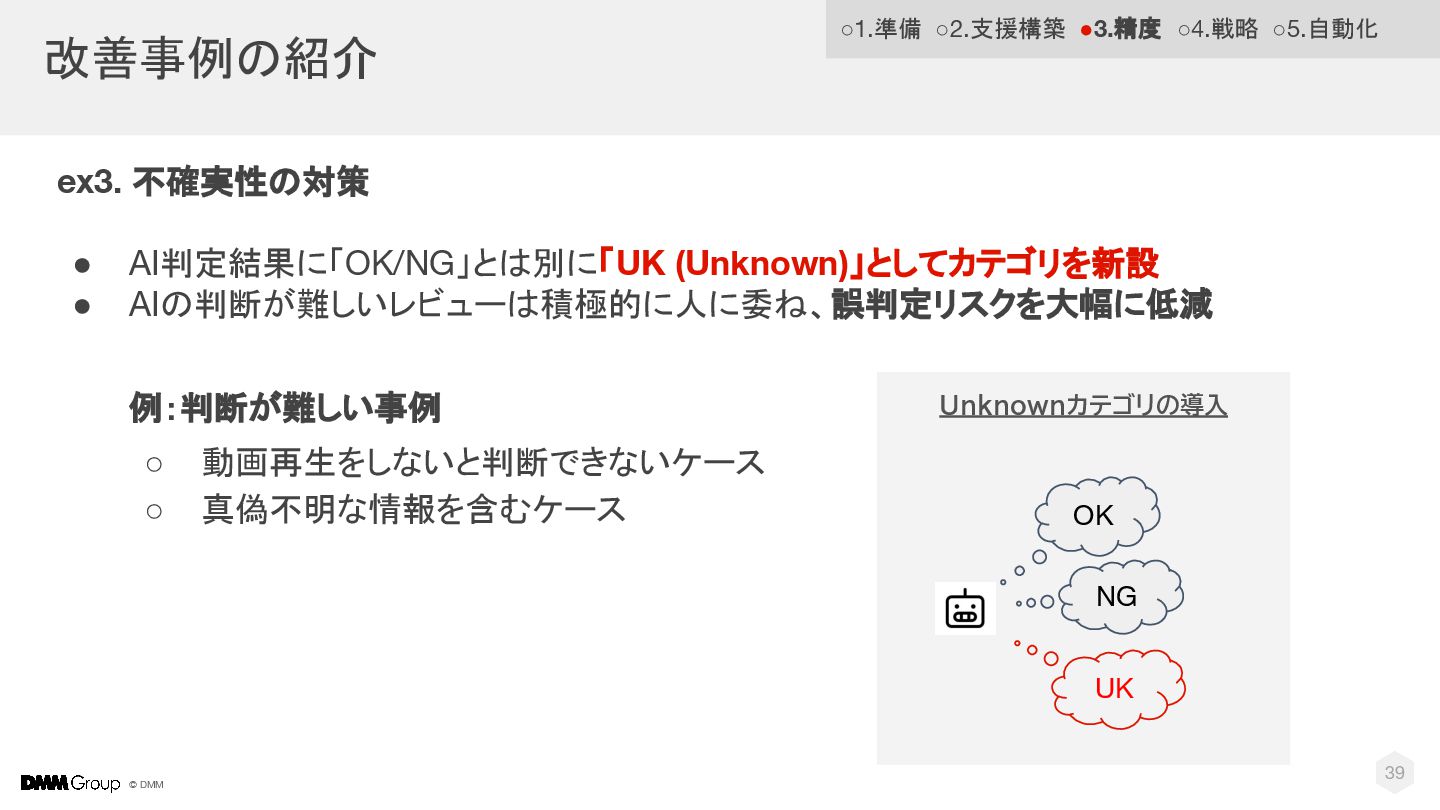
© DMM 改善事例の紹介 39 ex3. 不確実性の対策 • AI判定結果に「OK/NG」とは別に「UK (Unknown)」としてカテゴリを新設 •
AIの判断が難しいレビューは積極的に人に委ね、誤判定リスクを大幅に低減 例:判断が難しい事例 ◦ 動画再生をしないと判断できないケース ◦ 真偽不明な情報を含むケース Unknownカテゴリの導入 OK NG UK ◦1.準備 ◦2.支援構築 •3.精度 ◦4.戦略 ◦5.自動化
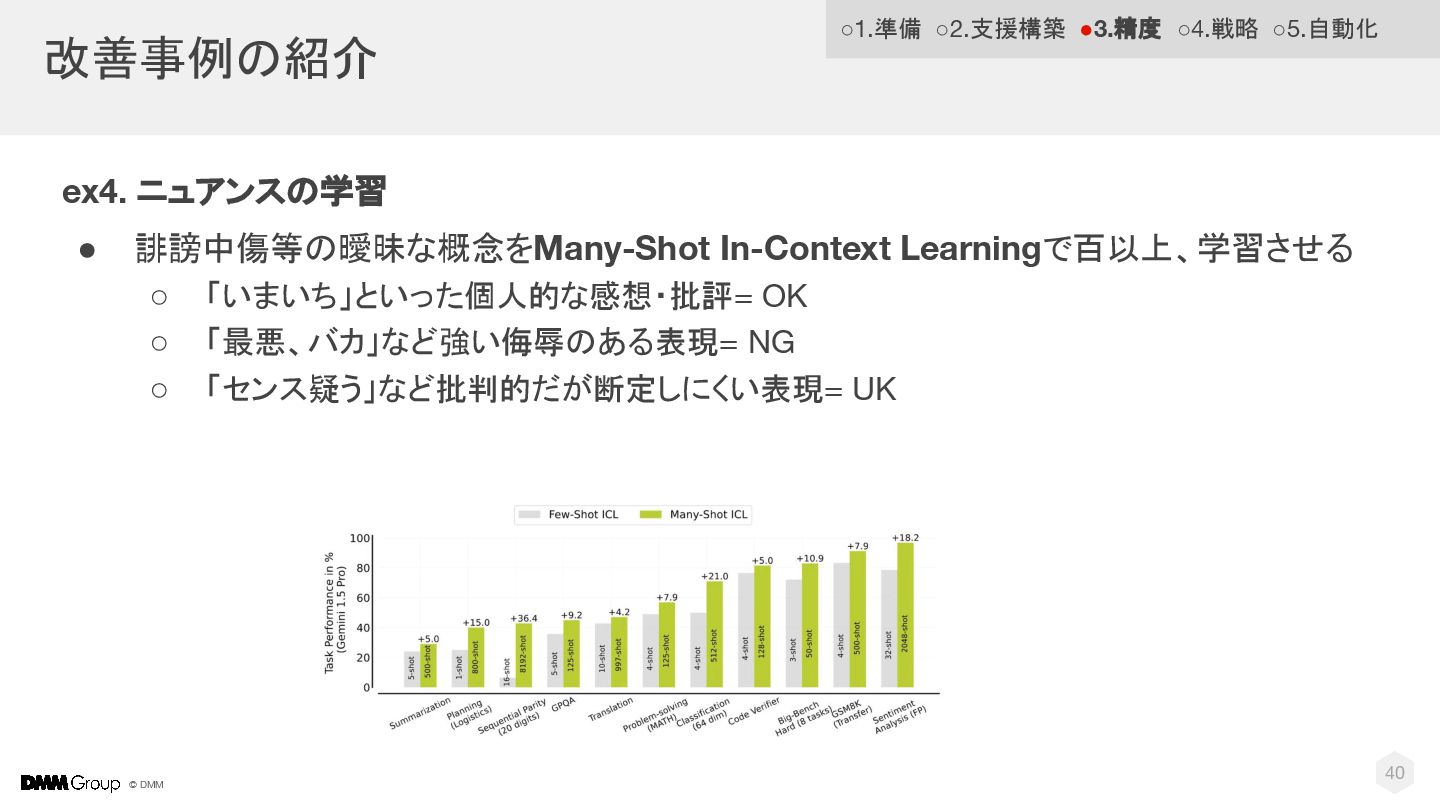
© DMM 改善事例の紹介 40 ex4. ニュアンスの学習 • 誹謗中傷等の曖昧な概念をMany-Shot In-Context Learningで百以上、学習させる
◦ 「いまいち」といった個人的な感想・批評 = OK ◦ 「最悪、バカ」など強い侮辱のある表現 = NG ◦ 「センス疑う」など批判的だが断定しにくい表現 = UK ◦1.準備 ◦2.支援構築 •3.精度 ◦4.戦略 ◦5.自動化
© DMM これらの複合策が相互に作用 6ヶ月で99%の精度を達成 自動化への大きな足掛かりとなった 41 41
© DMM 42 しかし・・ • 99%を達成するも、残る 1%の人との判断差異が自動化の障壁に ◦ これらに重大リスクは確認できなかった ◦
しかしLLMの自動承認自体が、前例がなく、誰も判断できない • 新たな戦略構築の必要性に迫られた
© DMM Phase4 自動化戦略(HAZ) Ph1 導入準備(PoC) Ph2 承認支援システム構築 Ph3 精度向上(HITL)
Ph4 自動化戦略 Ph5 自動化システム構築 ▶ 43
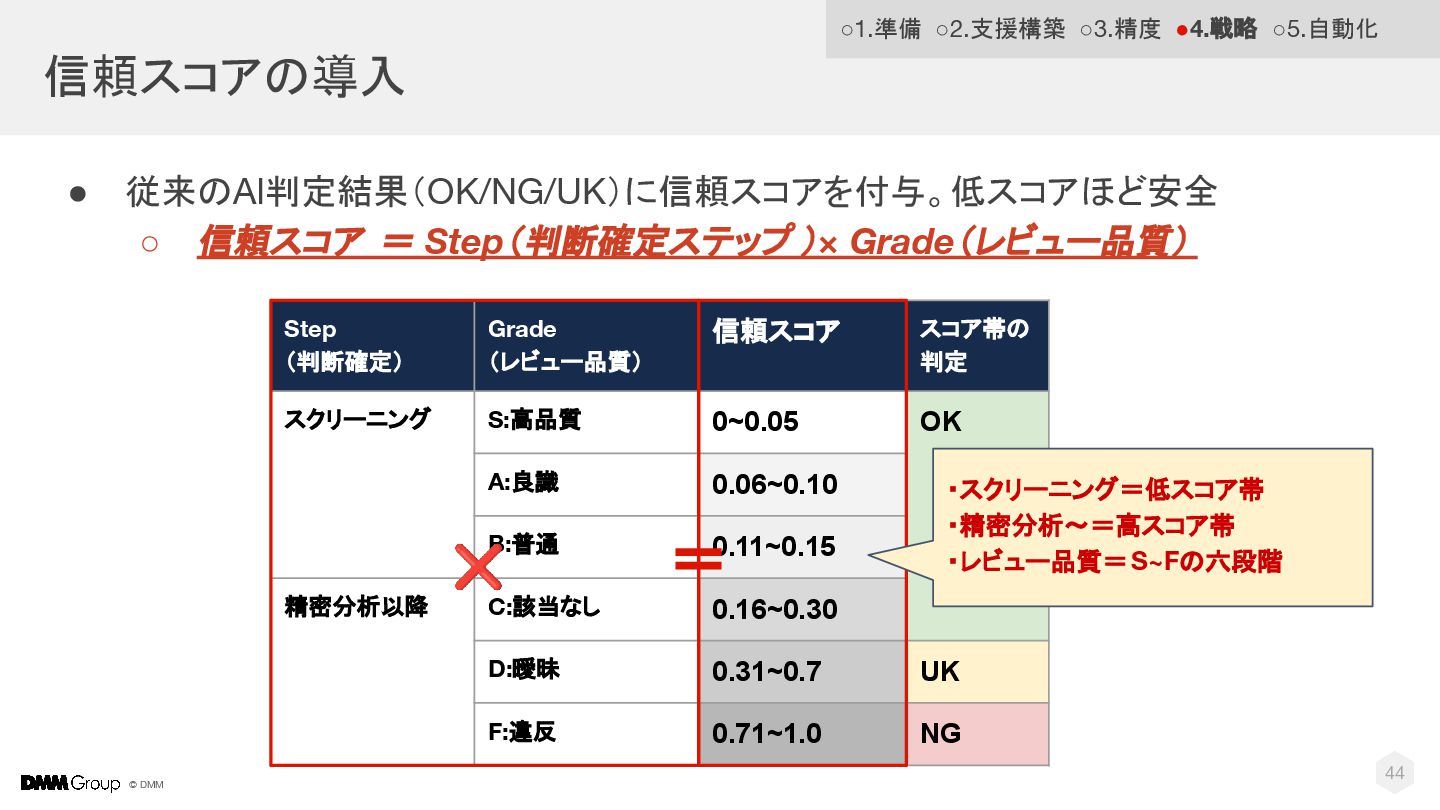
© DMM 信頼スコアの導入 • 従来のAI判定結果(OK/NG/UK)に信頼スコアを付与。低スコアほど安全 ◦ 信頼スコア = Step(判断確定ステップ )×
Grade(レビュー品質) Step (判断確定) Grade (レビュー品質) 信頼スコア スコア帯の 判定 スクリーニング S:高品質 0~0.05 OK A:良識 0.06~0.10 B:普通 0.11~0.15 精密分析以降 C:該当なし 0.16~0.30 D:曖昧 0.31~0.7 UK F:違反 0.71~1.0 NG 44 ◦1.準備 ◦2.支援構築 ◦3.精度 •4.戦略 ◦5.自動化 = ❌ ・スクリーニング=低スコア帯 ・精密分析〜=高スコア帯 ・レビュー品質=S~Fの六段階
© DMM 45 信頼スコアの導入 • この信頼スコアを分析 ◦ 信頼スコアが0.15以下は、人の判断と 100%一致 (直近2ヶ月)
◦ 全体の70%のレビューが該当 してることが判明 ◦1.準備 ◦2.支援構築 ◦3.精度 •4.戦略 ◦5.自動化
© DMM S:高品質 0~0.05 A:良質 0.06~0.10 B:標準的 0.11~0.15 C:該当なし 0.16~0.30
D:曖昧 0.31~0.7 F:違反 0.71~1.0 46 信頼スコアの導入 • つまり信頼スコア = 0.15を基準としてAIと人の承認を分ける • これで実質約7割のレビューが自動化が可能 • この領域を 「人とAIの信頼を積み重ねた領域 =HAZ」として自動化を決定 ◦1.準備 ◦2.支援構築 ◦3.精度 •4.戦略 ◦5.自動化 AIが自動承認 人が承認
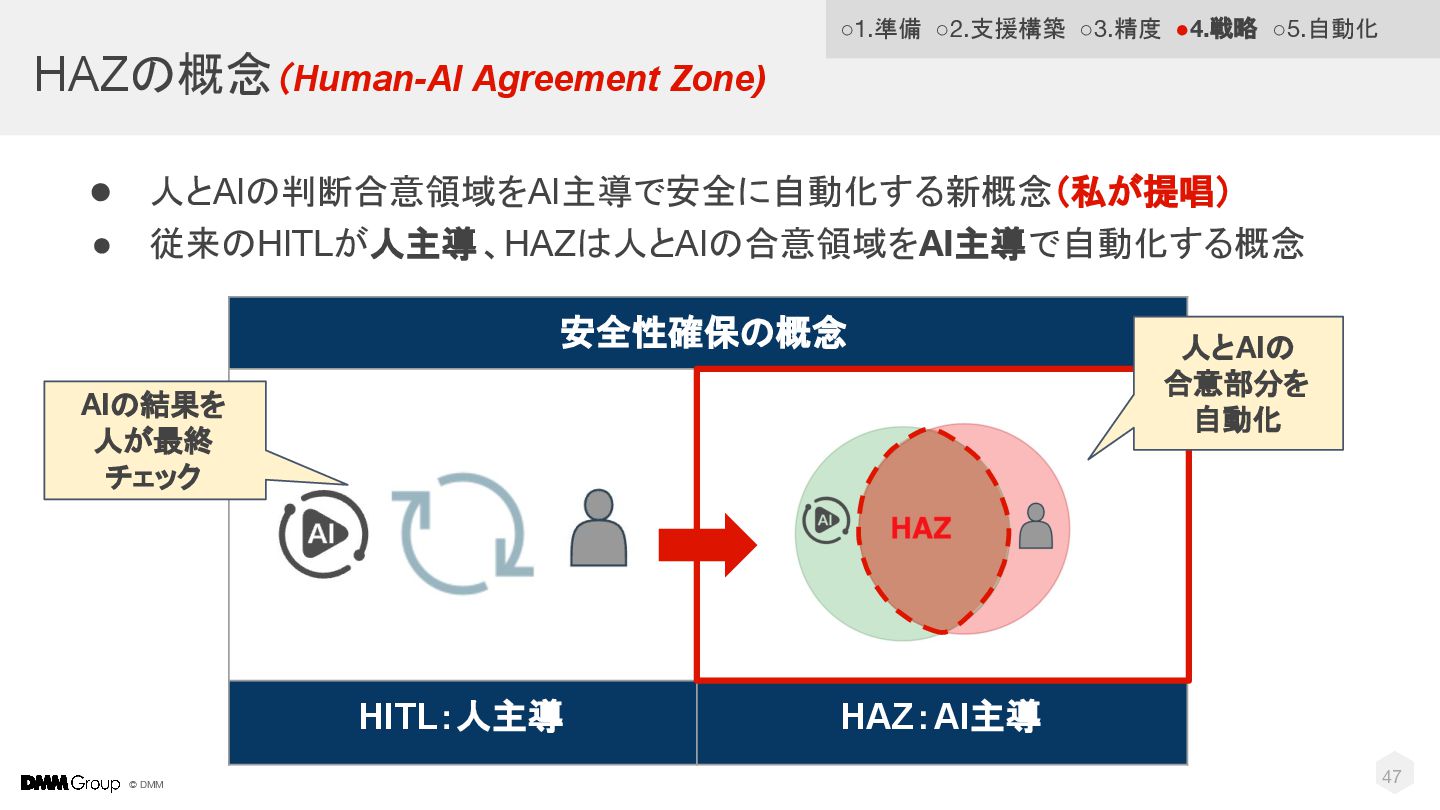
© DMM HAZの概念(Human-AI Agreement Zone) • 人とAIの判断合意領域をAI主導で安全に自動化する新概念(私が提唱) • 従来のHITLが人主導、HAZは人とAIの合意領域をAI主導で自動化する概念 47
安全性確保の概念 HITL:人主導 HAZ:AI主導 ◦1.準備 ◦2.支援構築 ◦3.精度 •4.戦略 ◦5.自動化 AIの結果を 人が最終 チェック 人とAIの 合意部分を 自動化
© DMM Human-AI Agreement Zone: HAZ • AI主導で安全な自動化を実現 •
様々な業務に適用可能 (自動承認に限らず) • 国内では類を見ない汎用フレームワーク 48 *自動運転は条件付きの特化型であり、HAZとは汎用性の性質が異なる
© DMM Phase5 自動化システムの構築 49 Ph1 導入準備(PoC) Ph2 承認支援システム構築 Ph3
精度向上 Ph4 自動化戦略 Ph5 自動化システム構築 ▶ 49
© DMM • 承認支援システムを拡張し、自動化システムの環境を構築 • 安全対策のため環境は完全に分離 50 システム拡張 レビュー投稿 拡張
【承認支援システム】 【自動化システム】 ◦1.準備 ◦2.支援構築 ◦3.精度 ◦4.戦略 •5.自動化
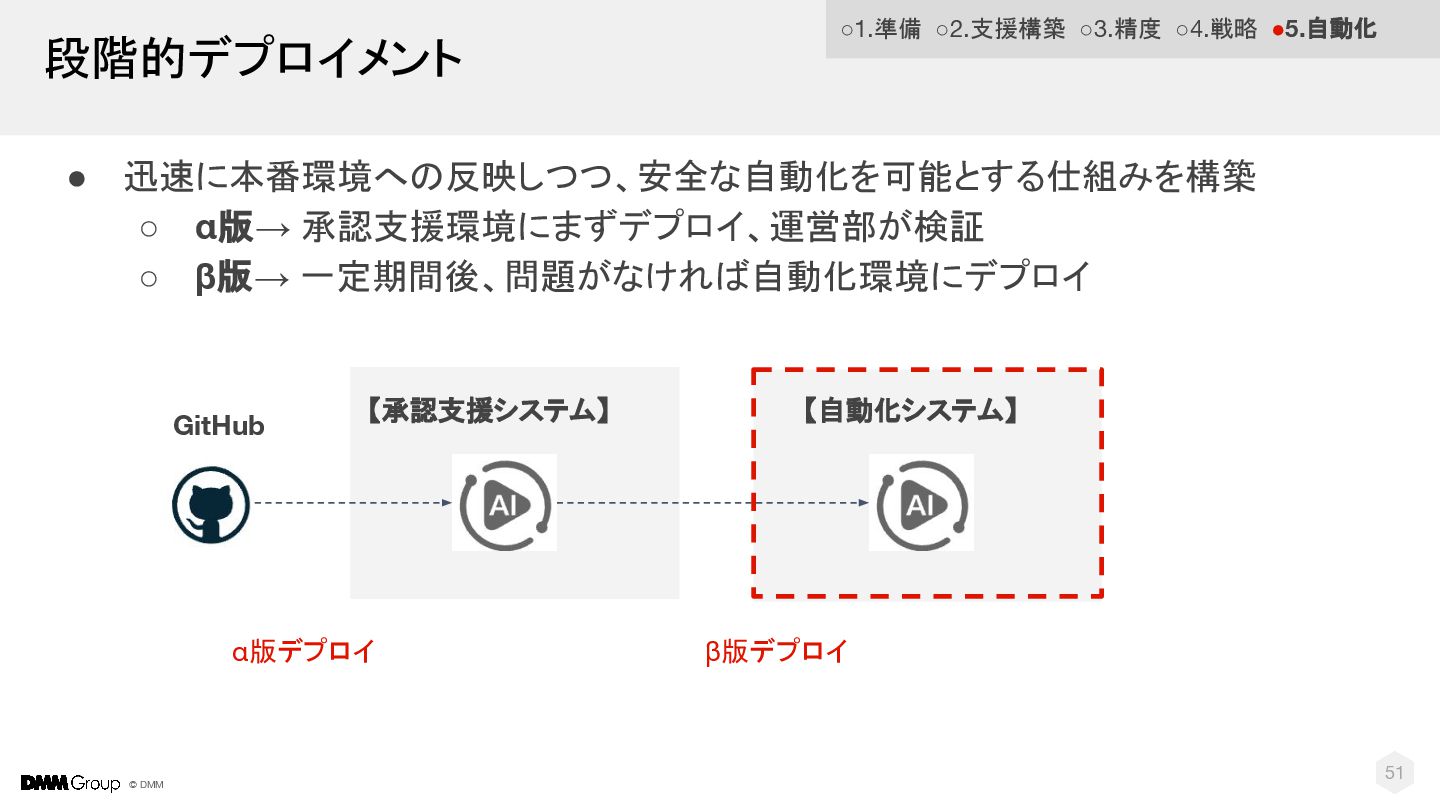
© DMM • 迅速に本番環境への反映しつつ、安全な自動化を可能とする仕組みを構築 ◦ α版→ 承認支援環境にまずデプロイ、運営部が検証 ◦ β版→ 一定期間後、問題がなければ自動化環境にデプロイ
51 段階的デプロイメント 【承認支援システム】 【自動化システム】 GitHub α版デプロイ β版デプロイ ◦1.準備 ◦2.支援構築 ◦3.精度 ◦4.戦略 •5.自動化
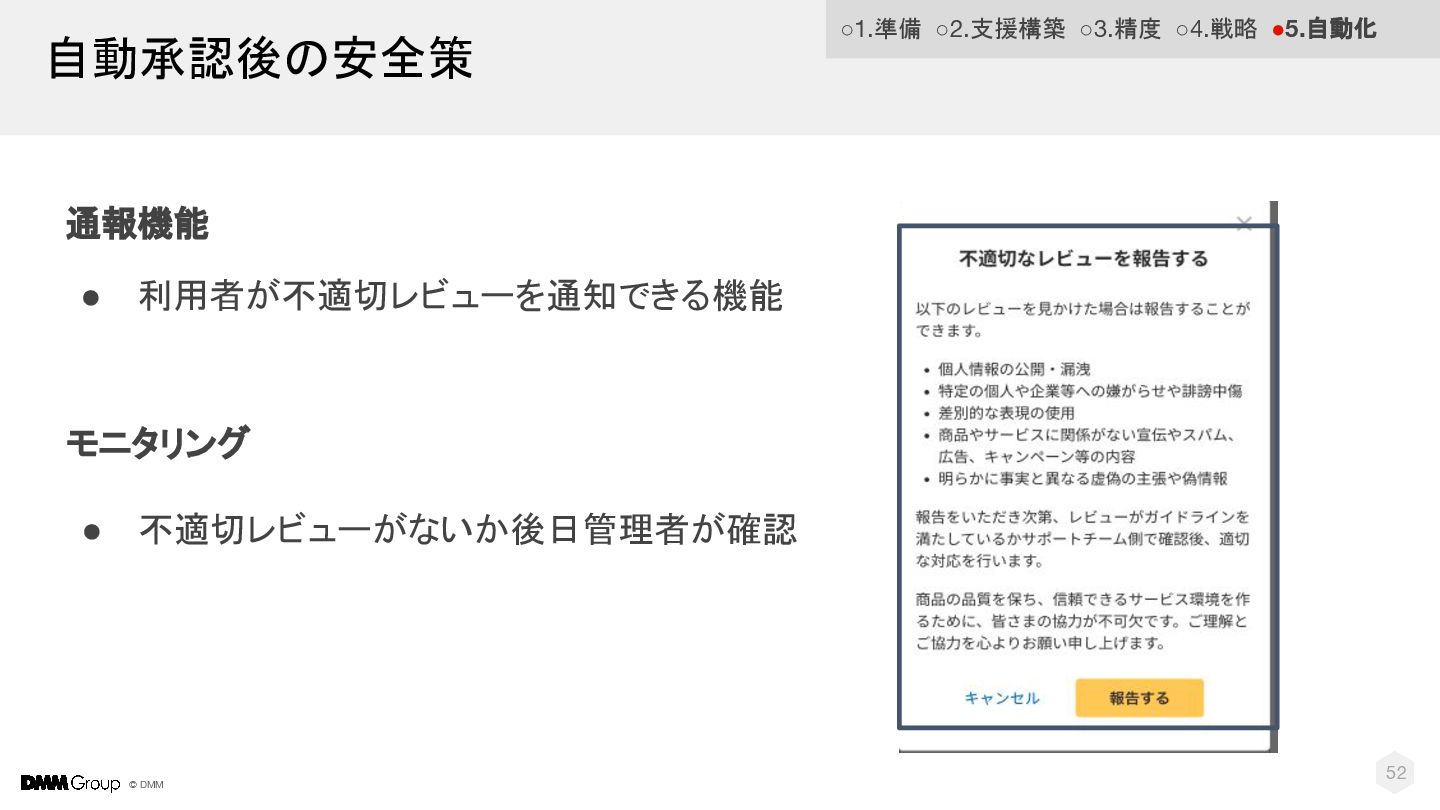
© DMM 52 自動承認後の安全策 通報機能 • 利用者が不適切レビューを通知できる機能 モニタリング • 不適切レビューがないか後日管理者が確認
◦1.準備 ◦2.支援構築 ◦3.精度 ◦4.戦略 •5.自動化
© DMM 4章. 自動化の成果 53 53
© DMM 自動化の範囲 • まず初回導入のため特定のサービス(例:電子書籍、動画配信 など)に限定 • HAZ領域では理論上70%の自動化が可能だが、最大60%とした 54 S:高品質
0~0.05 A:良質 0.06~0.10 B:標準的 0.11~0.15 C:該当なし 0.16~0.30 D:曖昧 0.31~0.7 F:違反 0.71~1.0 AIが自動承認 人が承認
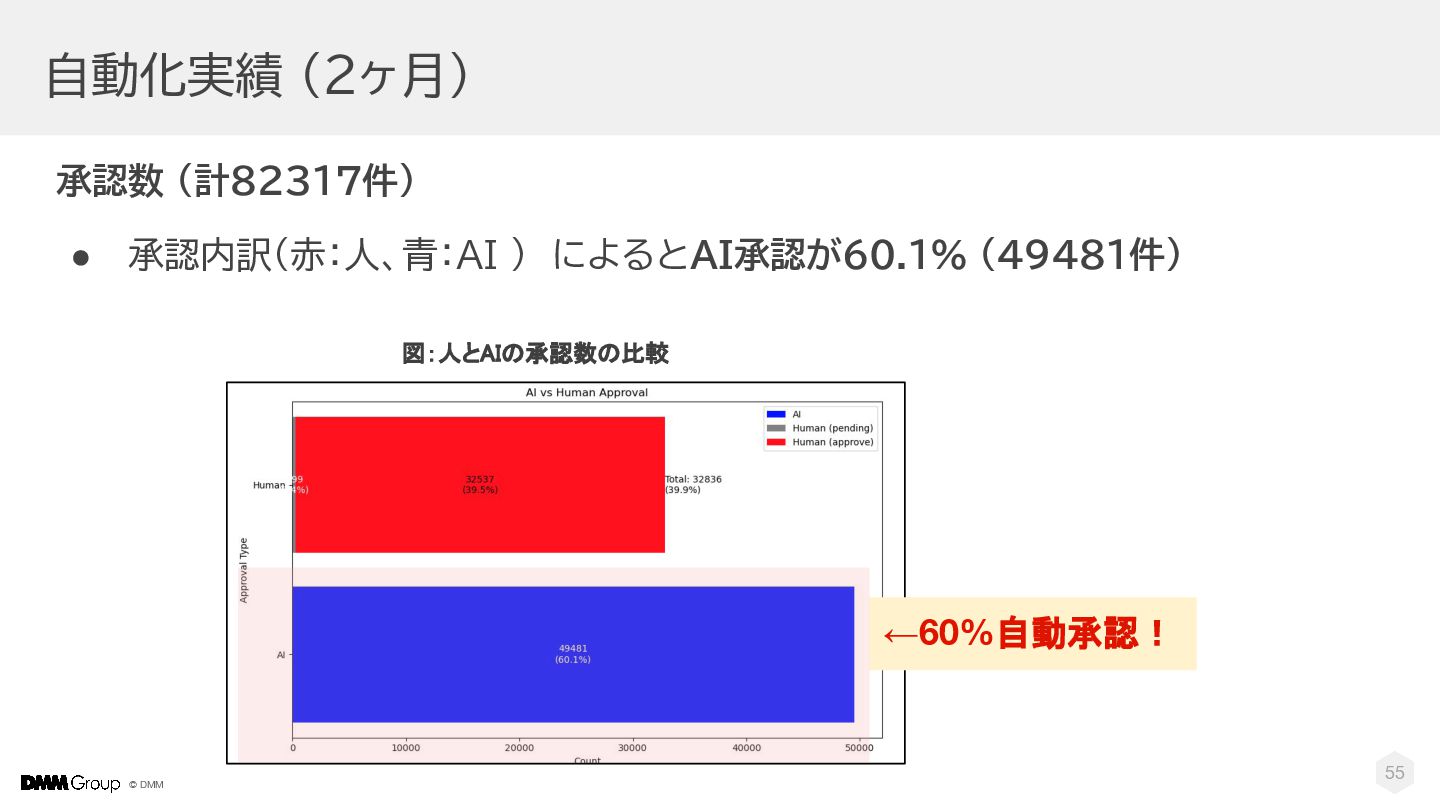
© DMM 55 自動化実績 (2ヶ月) 図:人とAIの承認数の比較 ←60%自動承認! 承認数 (計82317件) •
承認内訳(赤:人、青:AI ) によるとAI承認が60.1% (49481件)
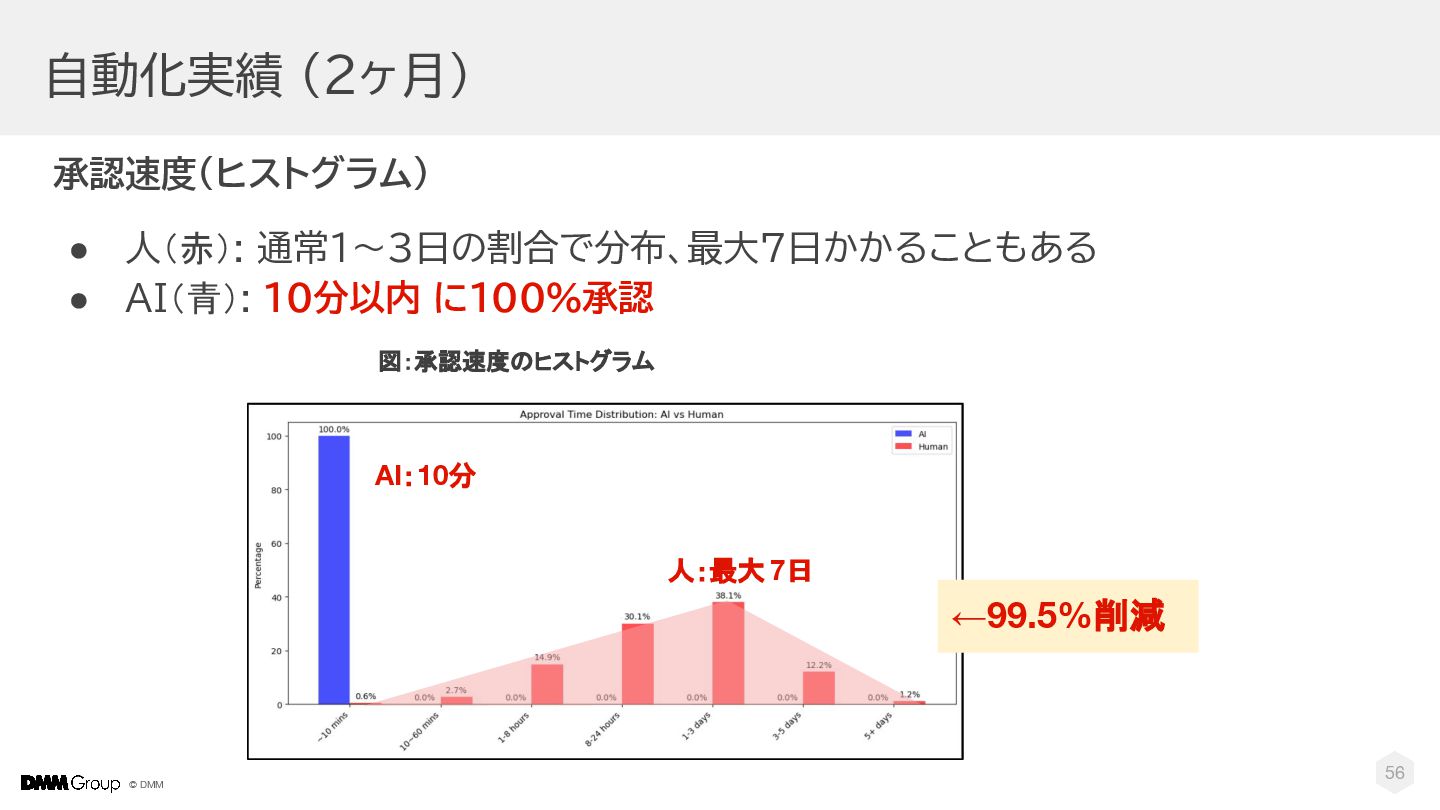
© DMM 56 自動化実績 (2ヶ月) 承認速度(ヒストグラム) • 人(赤): 通常1〜3日の割合で分布、最大7日かかることもある •
AI(青): 10分以内 に100%承認 図:承認速度のヒストグラム 人:最大 7日 AI:10分 ←99.5%削減
© DMM 57 他部門フィードバック • 運営部 :「最初は絶対に無理と思ったが 、実現がすごい! 」 • サポート部
:「導入後も、ユーザー・クレームが一切ない! 」 実際の声 • 作業量が大幅に減り 、負担が軽くなった • 作業時間が半分近く短縮され、効率が上がった • 導入前は不安だったが、思った以上に効果が出た • 空いた時間で、他業務にも積極的に取り組めるようになった • さらなる自動化拡大にも期待 したい
© DMM 成果 • レビュー承認の6割を完全自動化 • 公開時間を最大1週間 → 10分以内に短縮( 99.5%削減)
自動化成功の鍵 • 段階的な協調 :いきなり自動化せず、人とAIの段階的な協調 • 責務分離の原則 : AIの判断工程を細分化し誤判定を抑制 • HITLの活用 :人の結果をFBし、精度を向上 • HAZの導入 :人とAIの合意領域を自動化 まとめ 58 〜 プロジェクト報告は、一旦終 〜
© DMM 6章. 人とAIのこれから 〜未来構想と人間中心宣言〜 59 59
© DMM 役割共有モデル - 人とAIの関係 - 60 • 人とAIの関係性に着目した「役割共有モデル 」を独自に定義
◦ レベルが上がるごとに、AIの判断の実行比重が大きくなる構造 • 本プロジェクトの中でLv2(補助型) → Lv3(合意型)へ自然に進化 人とAIの役割共有モデル(独自定義) Lv1 Lv2 Lv3 Lv4 Lv5 指示型 補助型 合意型 改善型 自律型 人が操作 (単発実行) 人が主導 (HITL) AIと合意 (HAZ) AIが学習 (RHLF) AIが主導 (A2A)
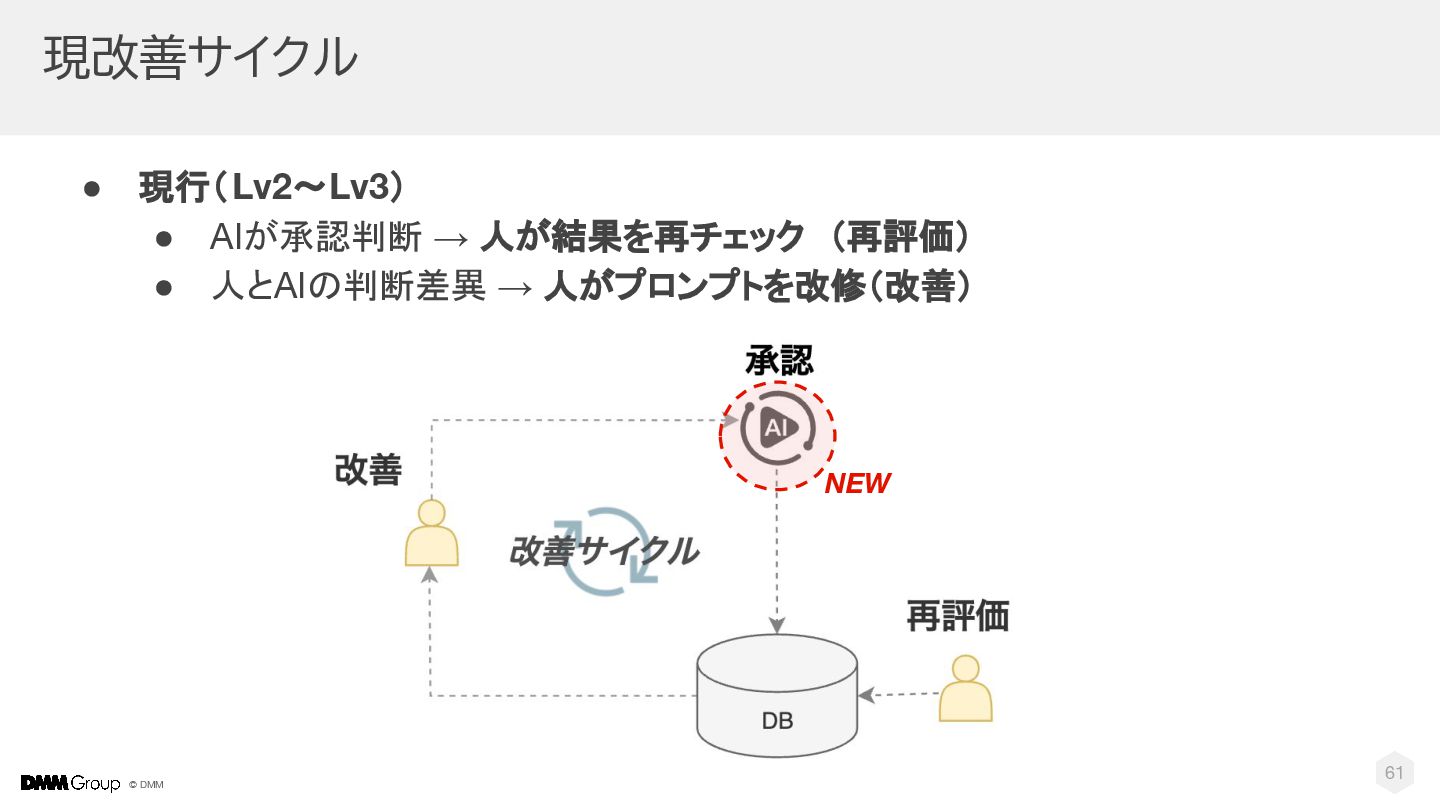
© DMM 現改善サイクル • 現行(Lv2〜Lv3) • AIが承認判断 → 人が結果を再チェック (再評価) •
人とAIの判断差異 → 人がプロンプトを改修(改善) 61 NEW
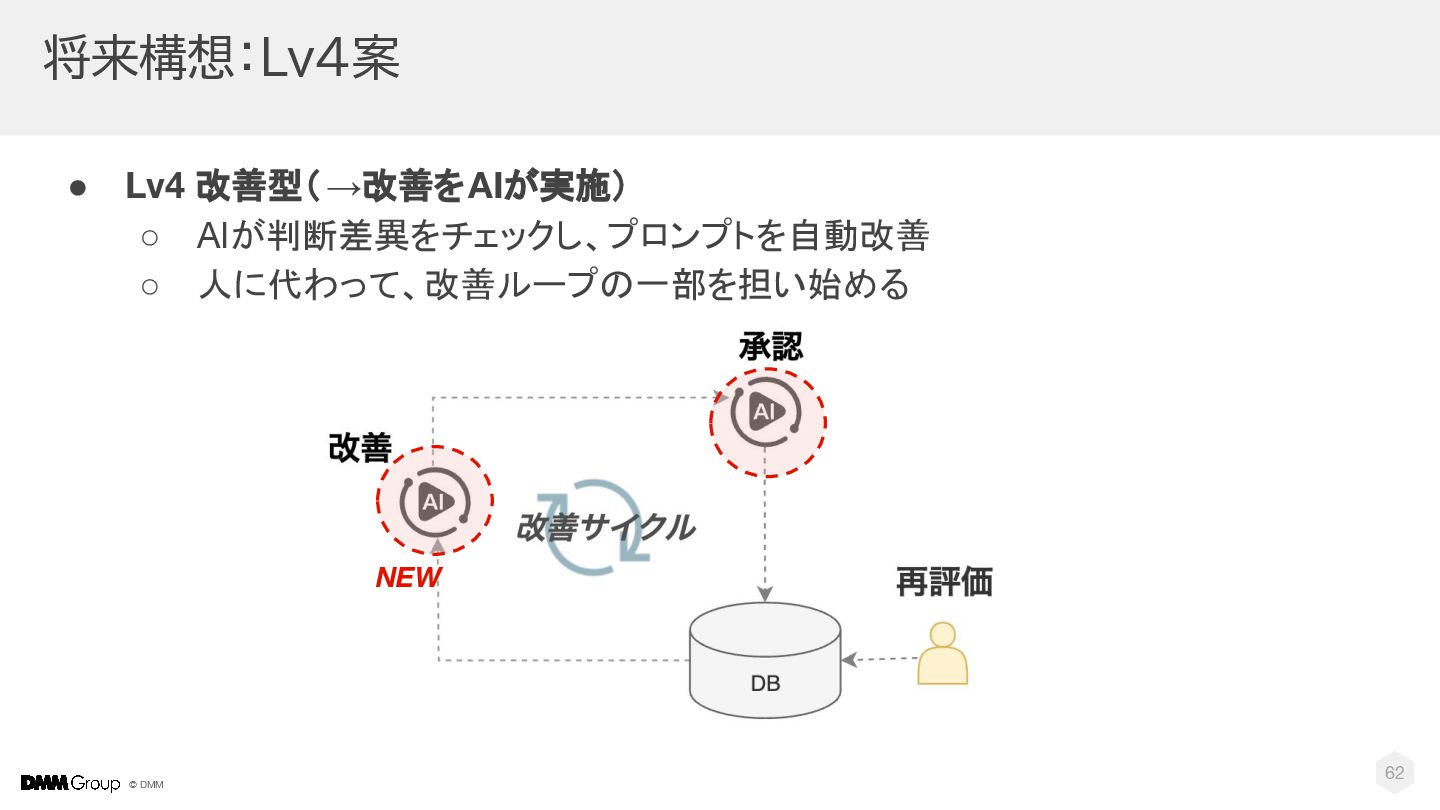
© DMM 将来構想:Lv4案 • Lv4 改善型(→改善をAIが実施) ◦ AIが判断差異をチェックし、プロンプトを自動改善 ◦ 人に代わって、改善ループの一部を担い始める
62 NEW
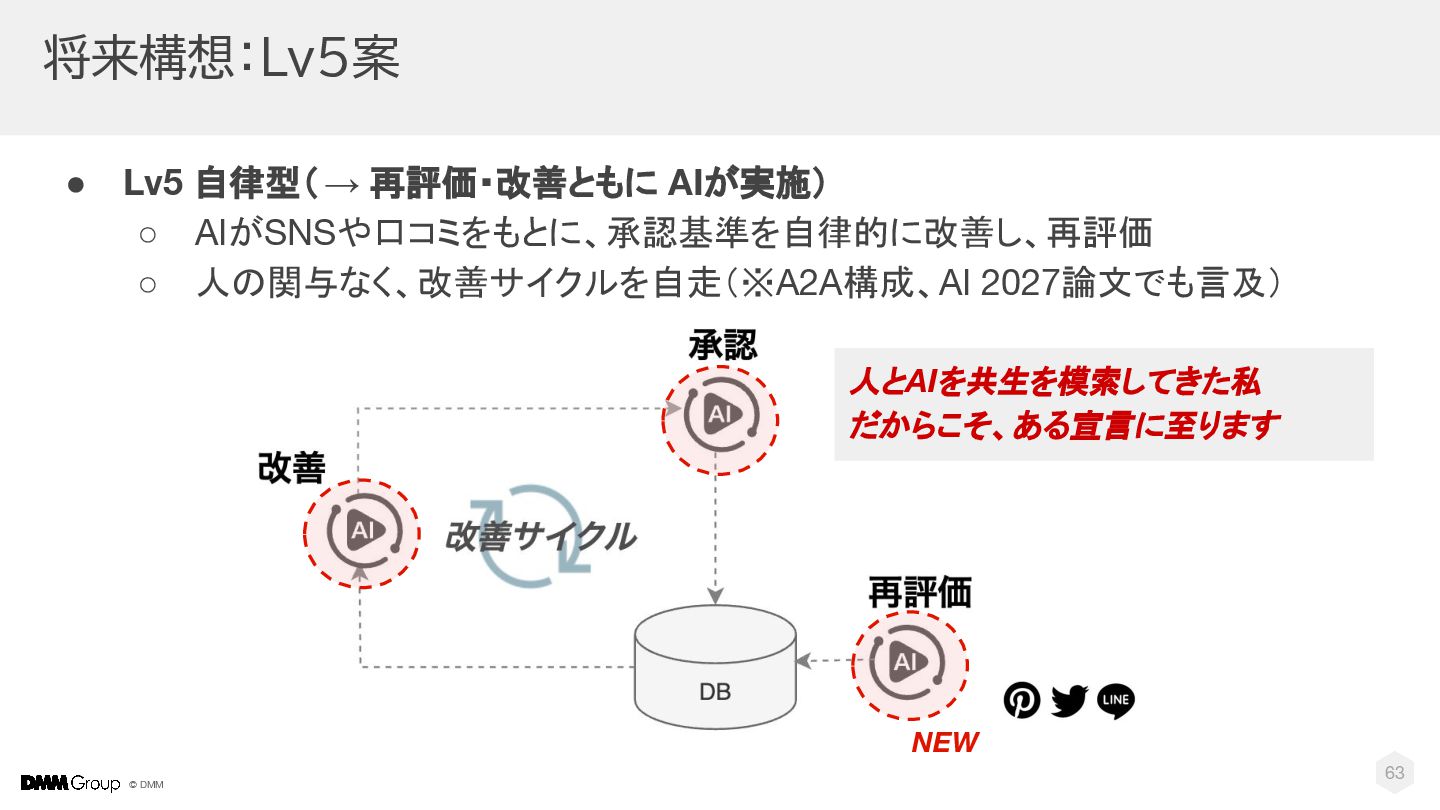
© DMM 将来構想:Lv5案 • Lv5 自律型(→ 再評価・改善ともに AIが実施) ◦ AIがSNSや口コミをもとに、承認基準を自律的に改善し、再評価
◦ 人の関与なく、改善サイクルを自走(※A2A構成、AI 2027論文でも言及) 63 人とAIを共生を模索してきた私 だからこそ、ある宣言に至ります NEW
© DMM AI時代の人間中心宣言 私は必ずしも全てをAIで 代替えすべきと思いません 私たちが、大切にするのは
「人の譲れない価値観」 であり それが私たちの 「存在理由」 です
© DMM AIが最適解を導き出しても 人が考えることをやめてしまえば 「人から選択と決定の自由」 を 奪ってしまいます
それは、悲しむべき未来です AI時代の人間中心宣言
© DMM AI時代の人間中心宣言 AIの本当の目的は、 「人の可能性を広げること」 です だからこそ私たちは
自ら責任を持ち決定したことは 「仮に誤っても尊い」 と信じます
© DMM だからこそ、私は宣言します 人が主役であること – Trust in human
leadership – これがAI時代のあるべき姿です あなたは、どこまでAIに任せますか? これから共に考えていきましょう AI時代の人間中心宣言
© DMM ご清聴ありがとうございました。 68 *次月はDICOMOの学会で発表予定です 論文提出済みですので、ご期待ください
© DMM 【参考資料 - Appendix】 69
© DMM Appendix: Q&A(A-1) 質問 回答 プロンプトのバージョン管理はど のようにしていますか? GitHubで管理し、リリース後は S3に反映。
S3上でもバージョン管理、問題があればすぐにロールバック 運用面でのモニタリング方法 生成AI判定時のエラーは Slack通知で把握。 毎週、3つの精度と人との判定差分を確認、調整します。 AIの判定ミスが起きた場合の対 応プロセスは? 6ヶ月間の検証で重大なミスはゼロ 。その為、自動化できている。 週次チェックで誤判定が見つかれば、運営部と連携して修正 100%保証はできるのか? 過去データで誤判定リスクは最小化していますが、 100%保証は難しい ただ人の判断にも問題は必ずあり、絶対ではない というのが現状。実際 年間40件ほどのクレームがあり、現クレーム数より多くならいのであれば OK モデルのバージョンアップ時はど う検証しているのか? まず承認支援環境でテストし、数日~数週間のチェック 問題なければ自動承認環境に展開。 具体的な応用事例はあるか? 本システムはコンテンツモデレーション全般に応用可能です。 たとえば、問い合わせメールの自動仕分けや審査にも対応できます。 70
© DMM 質問 回答 過去レビューを学習している場合、 モデルに影響を与えるリスクは? 規約は頻繁に更新されない 。定例会で表現の追加・削除があれば見直す システム全体のコストや応答速度に どのような影響があるのか?
スクリーニングで大部分レビューを除外できている。コストは低く、応答速度も 高速である為、影響なし。またこれ以上の高速性は求めていない 生成AIの判断プロセスやプロンプト チェーンの透明性はどの程度か? 現状は各カテゴリで使用しているプロンプト内容を共有している。 実際の判定結果を見てもらうことのみ。 ManyShotContextLearningは、ど のような基準で選定する? 運営部門と協力して、サンプル選定の基準を共同でチェックしている。 「事例データベース」として作成。大量のサンプルを活用し、日々の判定精度で その効果を確認 AIの自動承認によって、従業員の役 割が失われるのではないですか? その通りです。従業員には別の作業を割り当てることになります。 付加価値の高い業務に専念できるようになり、役割の質が向上します。 71 Appendix: Q&A(A-2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}