Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20250515_SeedEverythingな人を救いたい
Search
yuyagi
May 19, 2025
Technology
59
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20250515_SeedEverythingな人を救いたい
内部の勉強会で使った、Pytorchのseedに関する備忘スライドです
RNGに関してミスしやすいポイントをまとめています
yuyagi
May 19, 2025
Other Decks in Technology
See All in Technology
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
2
160
AI時代における最適なQA組織の作り方
ymty
3
460
初めてのDatabricks勉強会
taka_aki
2
240
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
300
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
410
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
200
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
160
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
180
Foxgloveについて 実際にExtensionを開発して公開するまでの話 / About Foxglove: The Story of Developing and Releasing an Extension
ry0_ka
0
180
cccccc
moznion
0
1.8k
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
yakumo
2
670
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
0
3.6k
Featured
See All Featured
The SEO Collaboration Effect
kristinabergwall1
1
500
Site-Speed That Sticks
csswizardry
13
1.2k
We Have a Design System, Now What?
morganepeng
55
8.2k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
230
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
Why Our Code Smells
bkeepers
PRO
340
58k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Transcript
Seed Everythingな人を救いたい Yuyagi
自己紹介 ◆ データサイエンティスト 新規事業/データ活用系プロジェクトを担当 YuYagi ◆ Kagle Master - 信号処理系のコンペ参加が多め(画像、音響、センサ等)
(気分転換に未知のジャンルもやってみたい)
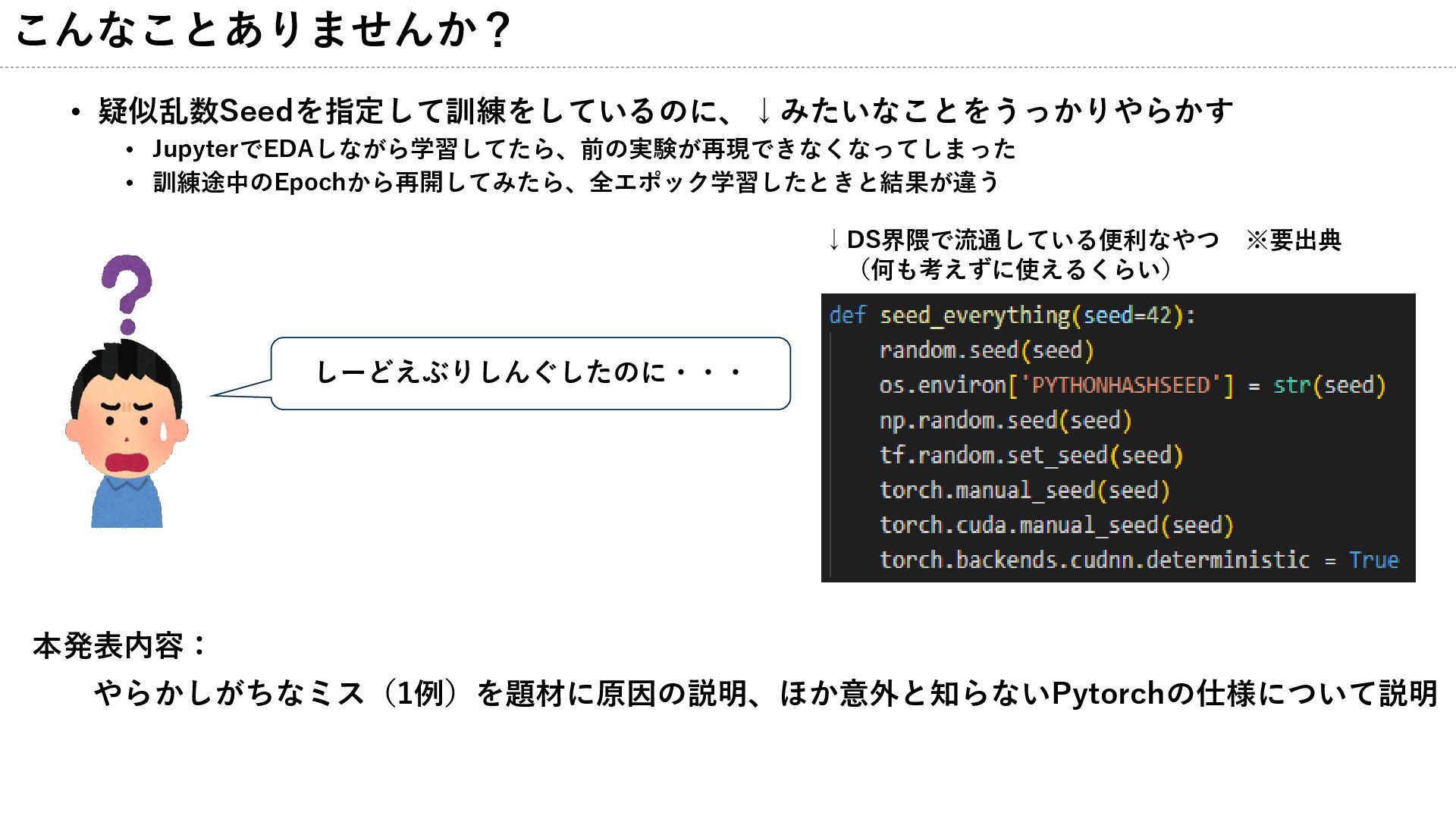
こんなことありませんか? • 疑似乱数Seedを指定して訓練をしているのに、↓みたいなことをうっかりやらかす • JupyterでEDAしながら学習してたら、前の実験が再現できなくなってしまった • 訓練途中のEpochから再開してみたら、全エポック学習したときと結果が違う しーどえぶりしんぐしたのに・・・ ↓DS界隈で流通している便利なやつ ※要出典
(何も考えずに使えるくらい) 本発表内容: やらかしがちなミス(1例)を題材に原因の説明、ほか意外と知らないPytorchの仕様について説明
目次 • 疑似乱数とは? • よくあるミスとその原因 → Epochの途中から再開すると結果が変わってしまう、という例を題材に原因を説明 ・さらなる注意ポイント → DataLoaderのWorker数を増やすと、Workerごとに別のシードが設定される?!
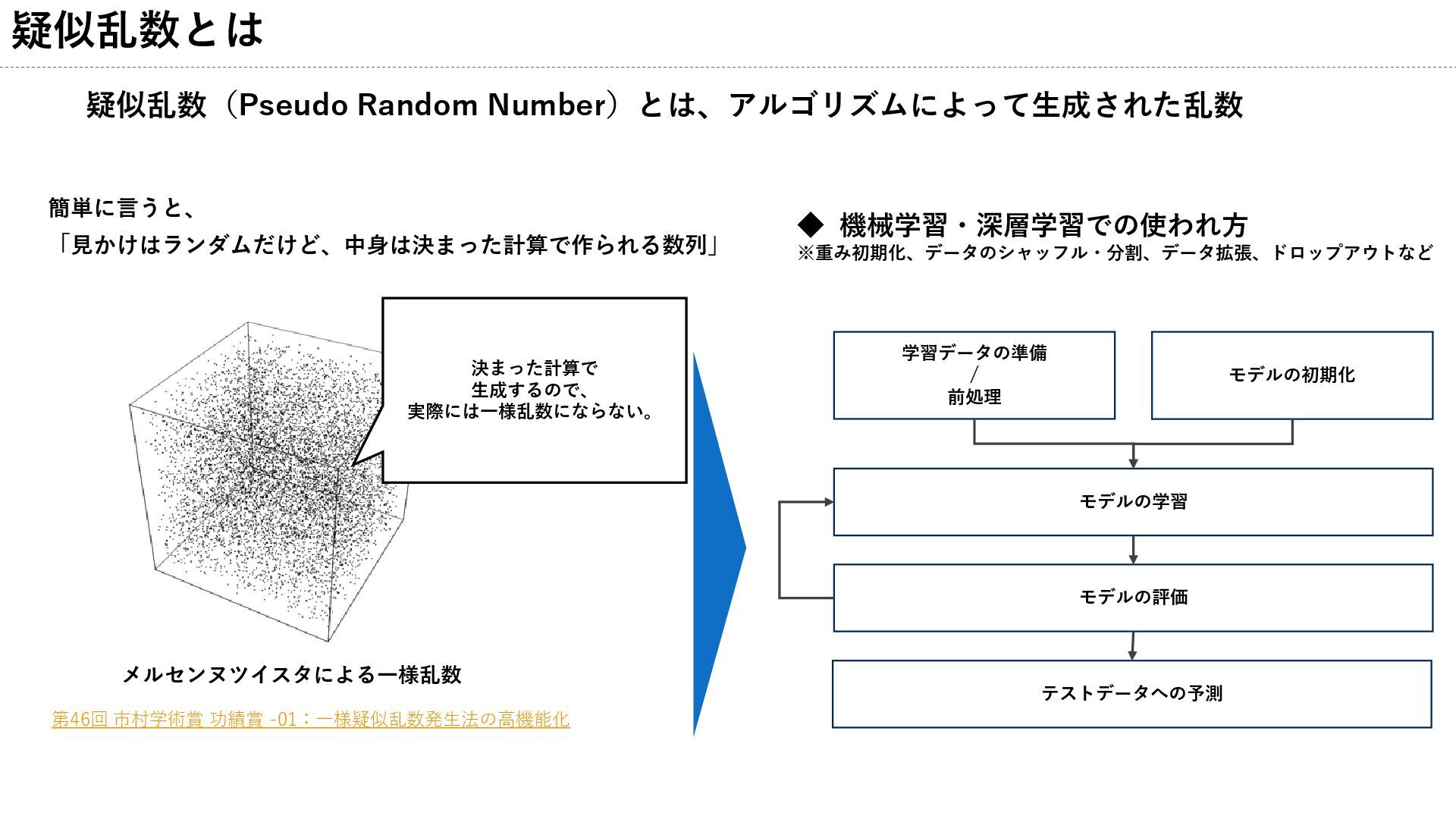
疑似乱数とは 簡単に言うと、 「見かけはランダムだけど、中身は決まった計算で作られる数列」 疑似乱数(Pseudo Random Number)とは、アルゴリズムによって生成された乱数 モデルの初期化 学習データの準備 / 前処理
モデルの学習 モデルの評価 テストデータへの予測 ◆ 機械学習・深層学習での使われ方 ※重み初期化、データのシャッフル・分割、データ拡張、ドロップアウトなど 第46回 市村学術賞 功績賞 -01:一様疑似乱数発生法の高機能化 決まった計算で 生成するので、 実際には一様乱数にならない。 メルセンヌツイスタによる一様乱数
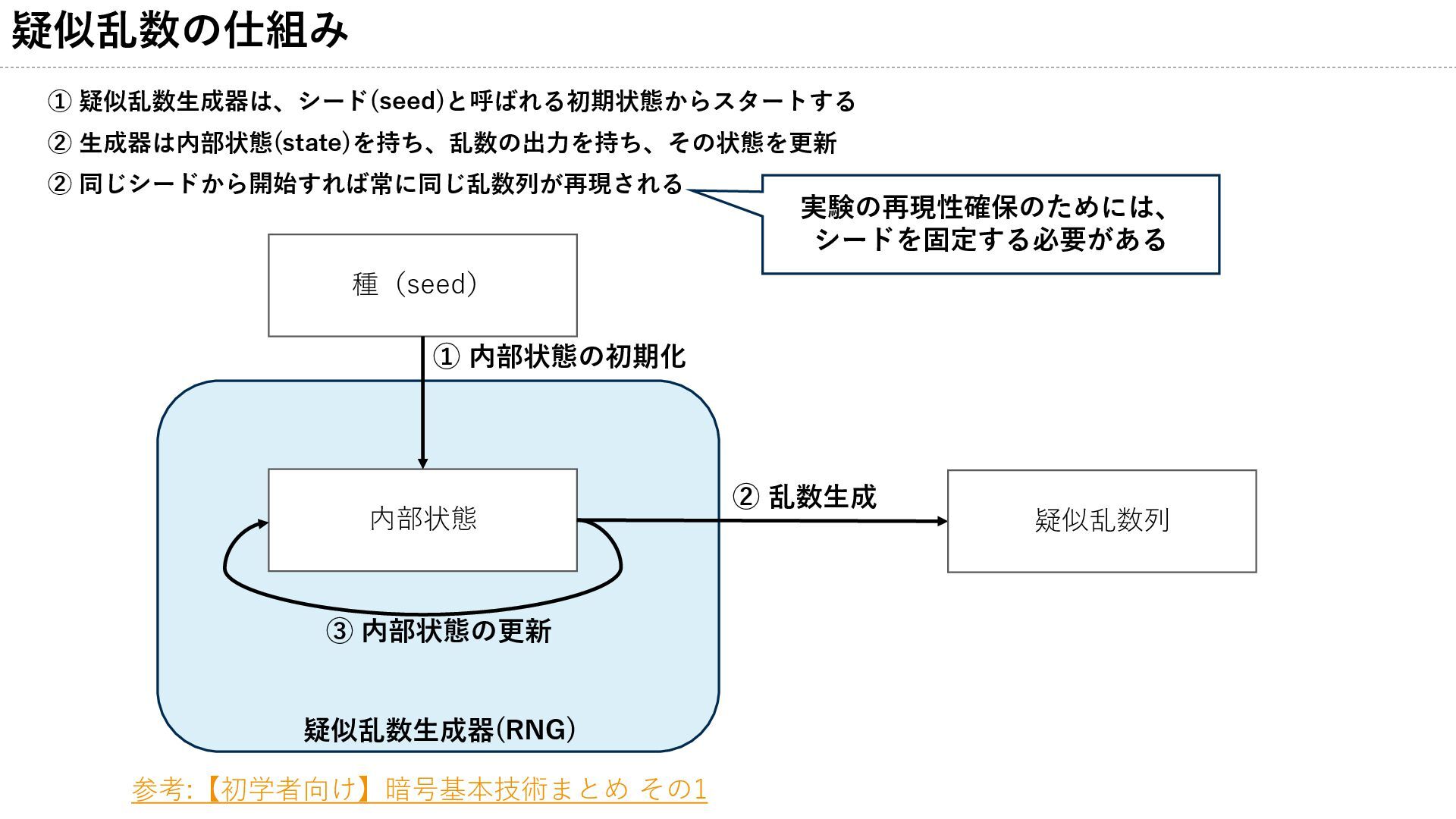
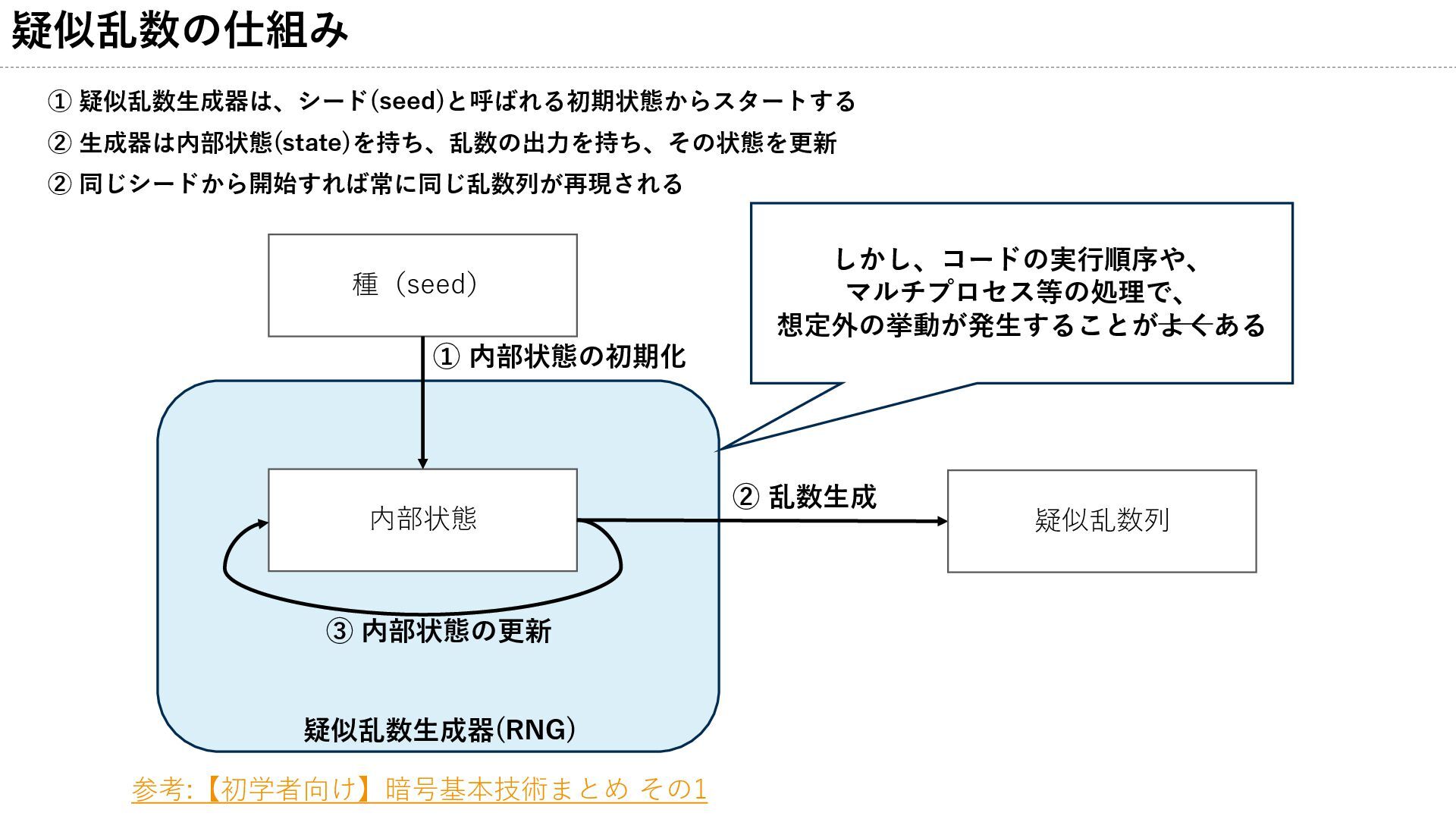
疑似乱数の仕組み ① 疑似乱数生成器は、シード(seed)と呼ばれる初期状態からスタートする ② 生成器は内部状態(state)を持ち、乱数の出力を持ち、その状態を更新 ② 同じシードから開始すれば常に同じ乱数列が再現される 種(seed) 内部状態 疑似乱数列
疑似乱数生成器(RNG) ① 内部状態の初期化 ② 乱数生成 ③ 内部状態の更新 参考:【初学者向け】暗号基本技術まとめ その1 実験の再現性確保のためには、 シードを固定する必要がある
疑似乱数の仕組み 種(seed) 内部状態 疑似乱数列 疑似乱数生成器(RNG) ① 内部状態の初期化 ② 乱数生成 しかし、コードの実行順序や、
マルチプロセス等の処理で、 想定外の挙動が発生することがよくある ③ 内部状態の更新 ① 疑似乱数生成器は、シード(seed)と呼ばれる初期状態からスタートする ② 生成器は内部状態(state)を持ち、乱数の出力を持ち、その状態を更新 ② 同じシードから開始すれば常に同じ乱数列が再現される 参考:【初学者向け】暗号基本技術まとめ その1
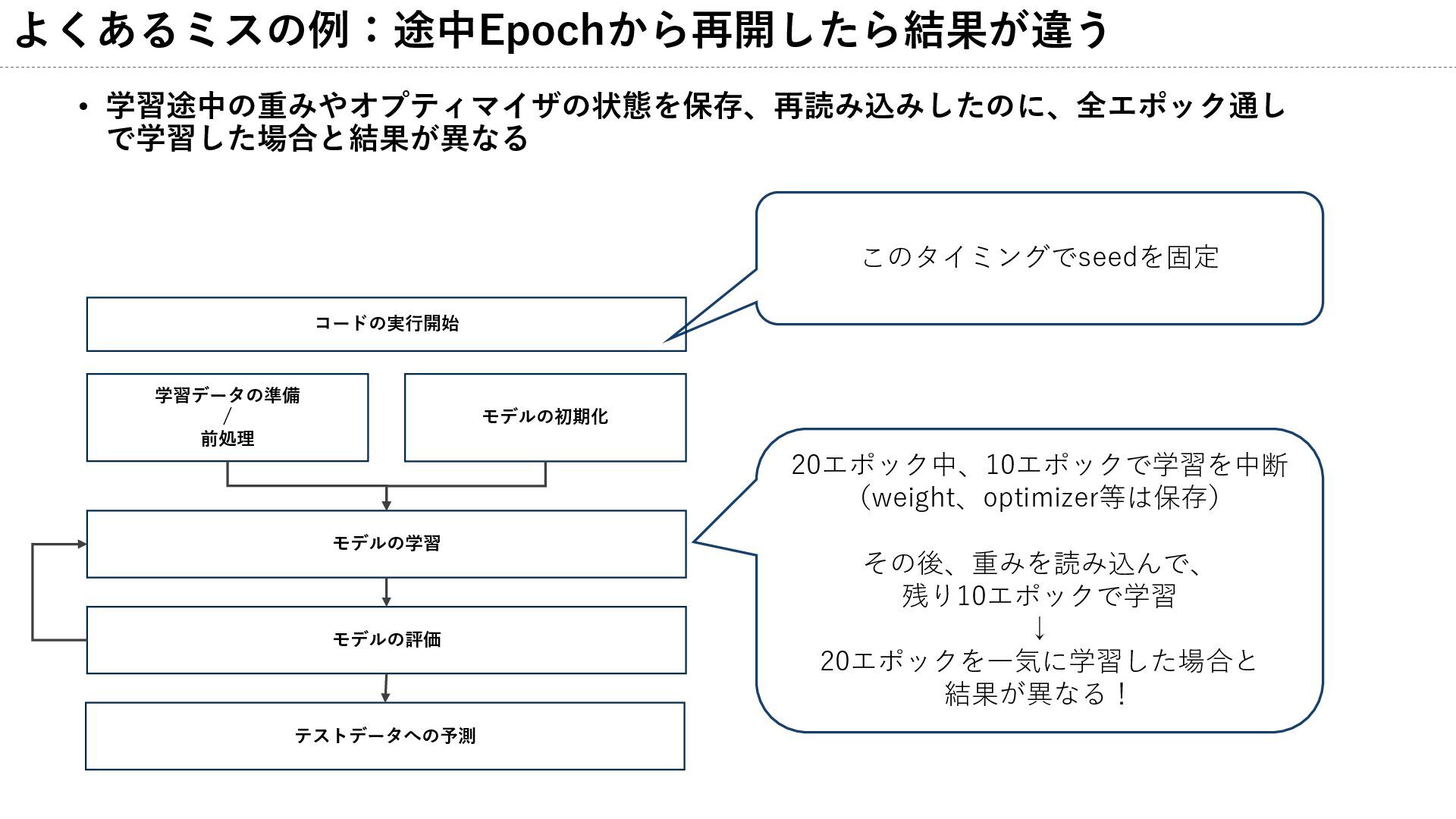
よくあるミスの例:途中Epochから再開したら結果が違う • 学習途中の重みやオプティマイザの状態を保存、再読み込みしたのに、全エポック通し で学習した場合と結果が異なる モデルの初期化 学習データの準備 / 前処理 モデルの学習 モデルの評価
テストデータへの予測 このタイミングでseedを固定 コードの実行開始 20エポック中、10エポックで学習を中断 (weight、optimizer等は保存) その後、重みを読み込んで、 残り10エポックで学習 ↓ 20エポックを一気に学習した場合と 結果が異なる!
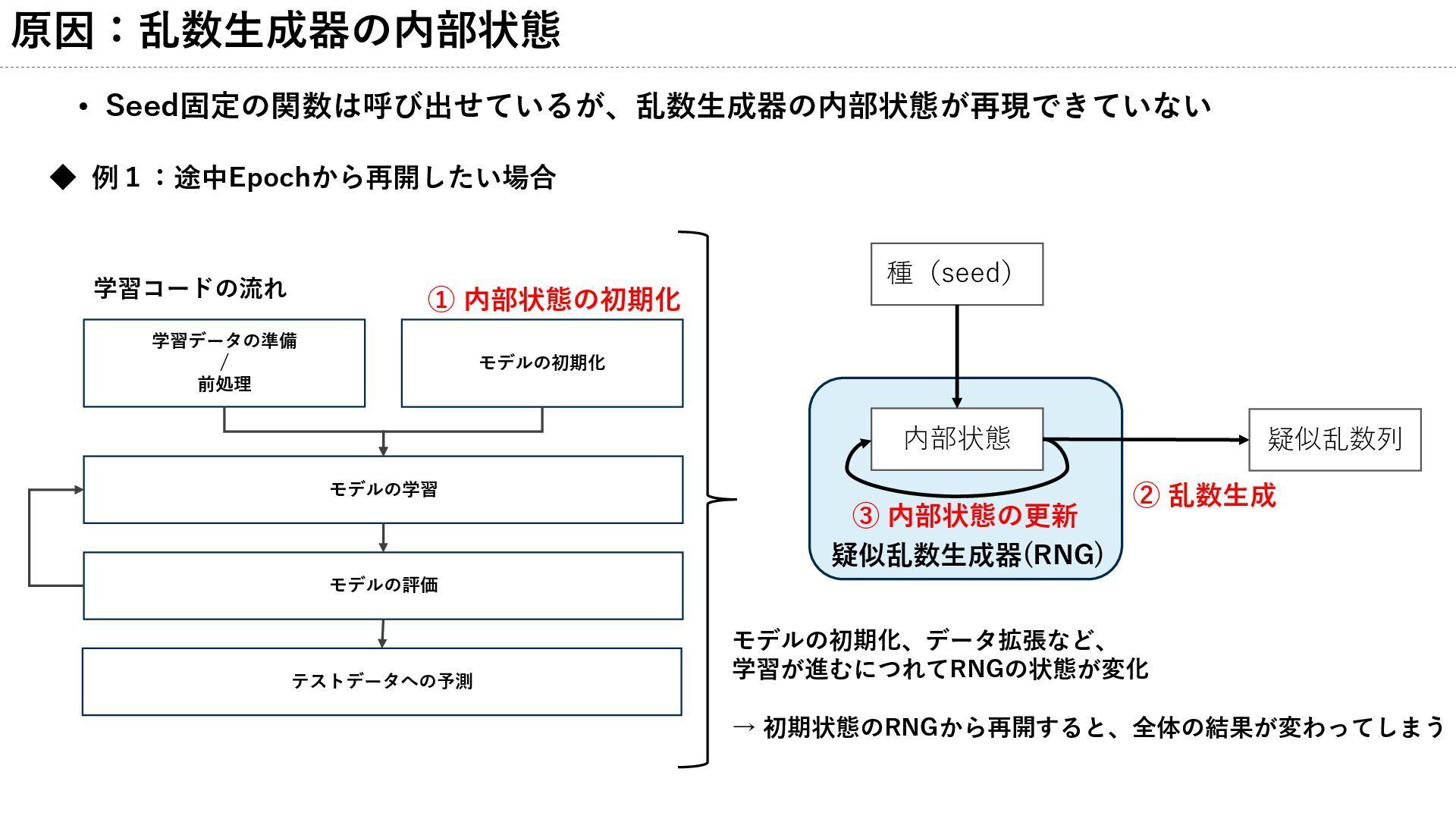
原因:乱数生成器の内部状態 • Seed固定の関数は呼び出せているが、乱数生成器の内部状態が再現できていない モデルの初期化 学習データの準備 / 前処理 モデルの学習 モデルの評価 テストデータへの予測
◆ 例1:途中Epochから再開したい場合 種(seed) 内部状態 疑似乱数列 疑似乱数生成器(RNG) ② 乱数生成 ③ 内部状態の更新 学習コードの流れ ① 内部状態の初期化 モデルの初期化、データ拡張など、 学習が進むにつれてRNGの状態が変化 → 初期状態のRNGから再開すると、全体の結果が変わってしまう
ポイントと対処方法:内部状態について ✓Python、Numpy、pytorchライブラリはそれぞれのアルゴリズムで疑似乱数を計算 ✓ライブラリごとに別のRNGをつかっているため、それぞれが内部状態を持つ ✓内部状態は取得・読み込みすることができる → 途中Epochから再開する場合は、これらの内部状態も保存して読み込むとよい Numpy Python Pytorch Seed
固定 メソッド Random.seed(seed) np.random.seed(seed) torch.manual_ seed(seed) RNGの 取得 読み込み random.getstate() random.setstate(state) numpy.random.get_state() numpy.random.set_state(state) torch.get_rng_st ate() torch.set_rng_st ate(state) 採用 アルゴ リズム メルセンヌツイスタ PCG64(numpy 1.17+) メルセンヌ ツイスタ torch.cuda.man ual_seed(seed) torch.cuda.get_rng _state_all() torch.cuda.set_rng _state_all(state) Philox CPU GPU
さらなる注意ポイント:乱数シードの有効範囲 • シードの固定はメインプロセスでのみされていて、別プロセスには自動では適用されない → 学習中にマルチプロセスな処理を行う場合は注意が必要 ※学習コードの中では、データを取り出す際に、マルチプロセスな処理を行うことが多い ◆ よくある現象: Pytorch DataLoaderのWorkerを増減したら、結果が変化
・並列でデータを取り出すために、num_worker > 0に設定する場合、 処理がマルチプロセスになるので注意が必要 . num_workers>0の時、 データの取り出し専用の別のプロセスが立ち上がる この時、Pytorch側でseed固定してくれるような実装だが、 仕様が少しわかりづらい・・・(次頁) モデルの初期化 学習データの準備 / 前処理 モデルの学習 モデルの評価 テストデータへの予測
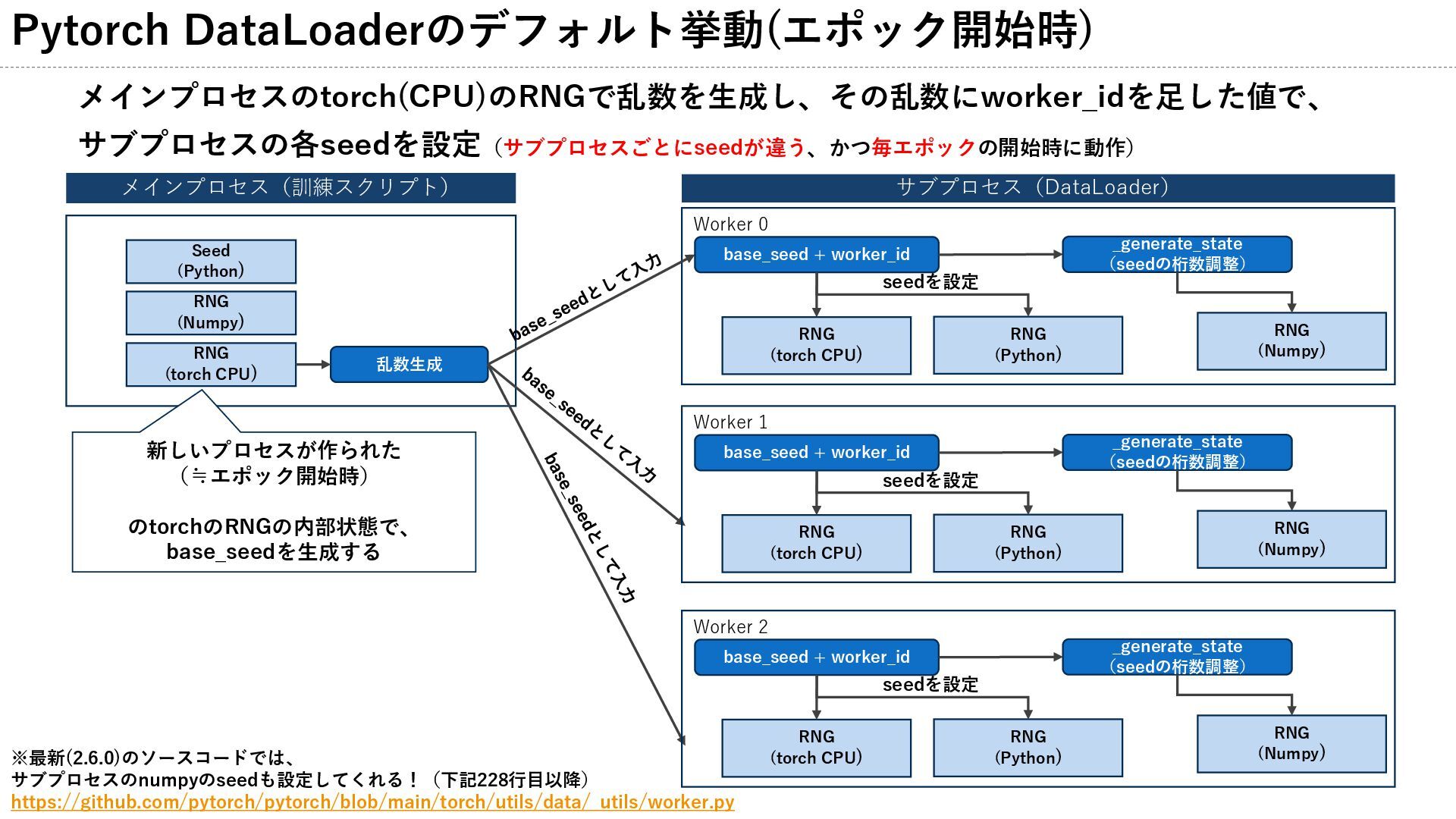
Pytorch DataLoaderのデフォルト挙動(エポック開始時) メインプロセスのtorch(CPU)のRNGで乱数を生成し、その乱数にworker_idを足した値で、 サブプロセスの各seedを設定(サブプロセスごとにseedが違う、かつ毎エポックの開始時に動作) Worker 0 メインプロセス(訓練スクリプト) サブプロセス(DataLoader) Seed (Python)
RNG (Numpy) RNG (torch CPU) RNG (Python) RNG (Numpy) RNG (torch CPU) 乱数生成 base_seed + worker_id seedを設定 _generate_state (seedの桁数調整) Worker 1 RNG (Python) RNG (Numpy) RNG (torch CPU) base_seed + worker_id seedを設定 _generate_state (seedの桁数調整) Worker 2 RNG (Python) RNG (Numpy) RNG (torch CPU) base_seed + worker_id seedを設定 _generate_state (seedの桁数調整) ※最新(2.6.0)のソースコードでは、 サブプロセスのnumpyのseedも設定してくれる!(下記228行目以降) https://github.com/pytorch/pytorch/blob/main/torch/utils/data/_utils/worker.py 新しいプロセスが作られた (≒エポック開始時) のtorchのRNGの内部状態で、 base_seedを生成する
なぜサブプロセスごとに、異なるseedを使っているのか? • Workerごとの乱数生成器だと、まったく同じ乱数が生成されるため → 具体的な例としては、同じエポック内で、同じデータ変換が何度も実行される CourseDropOut CourseDropOut
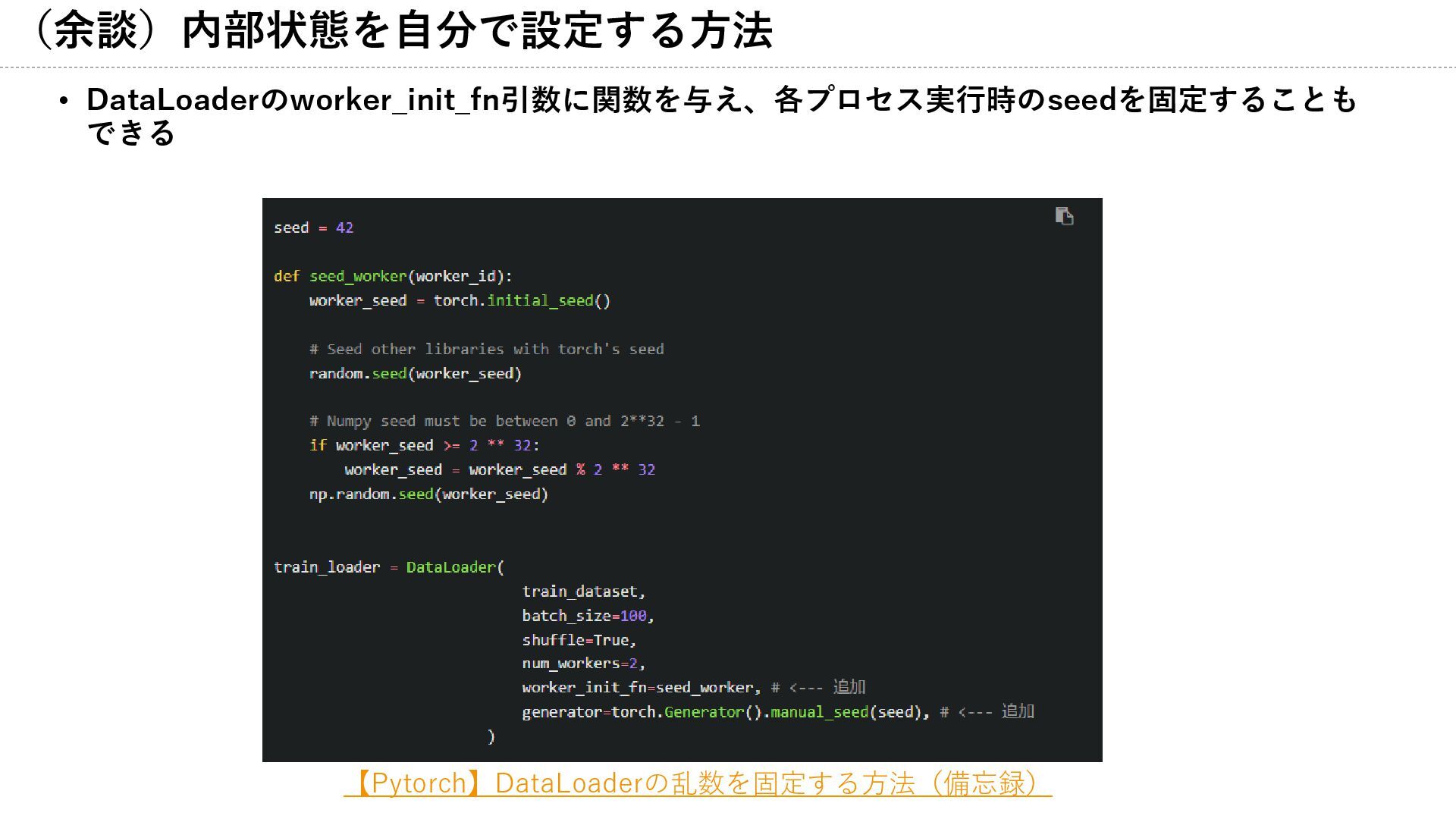
(余談)内部状態を自分で設定する方法 • DataLoaderのworker_init_fn引数に関数を与え、各プロセス実行時のseedを固定することも できる 【Pytorch】DataLoaderの乱数を固定する方法(備忘録)
結局どうするべきか? [単一プロセス(worker=0)] ✓一気通貫で全エポック訓練する場合は、基本的にseed_everythingだけやればOK ※ ただし、乱数生成器の状態が同じになるように気を付ける ✓エポックの途中から訓練する場合は、訓練途中の各ライブラリのRNGを読み込めばOK [マルチプロセスの場合(worker>0)] ✓一気通貫で全エポック訓練する場合は、こちらもseed_everythingだけやればOK ※ workerの設定によっては結果も若干変わるので注意
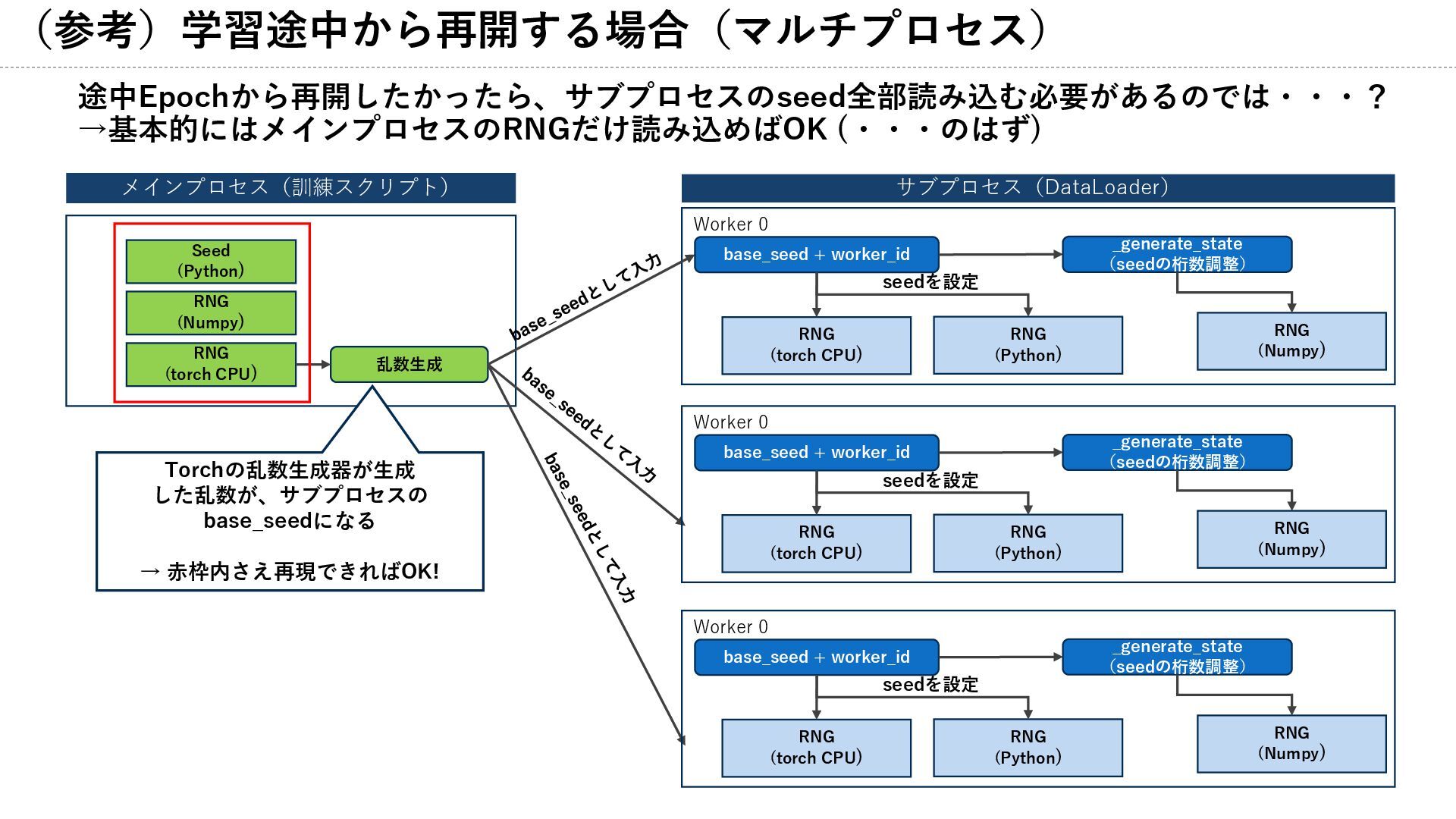
(疑問) 途中Epochから再開したかったら、サブプロセスのseed全部読み込む必要があるのでは・・・? →基本的にはメインプロセスのRNGだけ読み込めばOK (・・・のはず)
(参考)学習途中から再開する場合(マルチプロセス) 途中Epochから再開したかったら、サブプロセスのseed全部読み込む必要があるのでは・・・? →基本的にはメインプロセスのRNGだけ読み込めばOK (・・・のはず) Worker 0 メインプロセス(訓練スクリプト) サブプロセス(DataLoader) Seed (Python)
RNG (Numpy) RNG (torch CPU) RNG (Python) RNG (Numpy) RNG (torch CPU) 乱数生成 base_seed + worker_id seedを設定 _generate_state (seedの桁数調整) Worker 0 RNG (Python) RNG (Numpy) RNG (torch CPU) base_seed + worker_id seedを設定 _generate_state (seedの桁数調整) Worker 0 RNG (Python) RNG (Numpy) RNG (torch CPU) base_seed + worker_id seedを設定 _generate_state (seedの桁数調整) Torchの乱数生成器が生成 した乱数が、サブプロセスの base_seedになる → 赤枠内さえ再現できればOK!
終わりに 読んでいただいてありがとうございました! 実験で試したことを実行できるノートブックです↓ https://github.com/yu-yagi/random_seed_experment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![結局どうするべきか? [単一プロセス(worker=0)] ✓一気通貫で全エポック訓練する場合は、基本的にseed_everythingだけやればOK ※ ただし、乱数生成器の状態が同じになるように気を付ける ✓エポックの途中から訓練する場合は、訓練途中の各ライブラリのRNGを読み込めばOK [マルチプロセスの場合(worker>0)] ✓一気通貫で全エポック訓練する場合は、こちらもseed_everythingだけやればOK ※ workerの設定によっては結果も若干変わるので注意](https://files.speakerdeck.com/presentations/2b81e0a58eab4b7dbb6d33daa257f426/slide_14.jpg){kind=link}
{kind=link}
{kind=link}